
CNN、Transformer、MLP架構(gòu)的經(jīng)驗(yàn)性分析
【GiantPandaCV導(dǎo)語】
ViT的興起挑戰(zhàn)了CNN的地位,隨之而來的是MLP系列方法。三種架構(gòu)各有特點(diǎn),為了公平地比較幾種架構(gòu),本文提出了統(tǒng)一化的框架SPACH來對比,得到了具有一定insight的結(jié)論。論文來自微軟的A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP
背景
近期Transformer MLP系列模型的出現(xiàn),增加了CV領(lǐng)域的多樣性,MLP-Mixer的出現(xiàn)表明卷積或者注意力都不是模型性能優(yōu)異的必要條件。不同架構(gòu)的模型進(jìn)行比較的過程中,會(huì)使用不同的正則化方法、訓(xùn)練技巧等,為了比較的公平性,本文提出了SPACH的統(tǒng)一框架,期望對幾種架構(gòu)進(jìn)行對比,同時(shí)探究他們各自的特點(diǎn)。
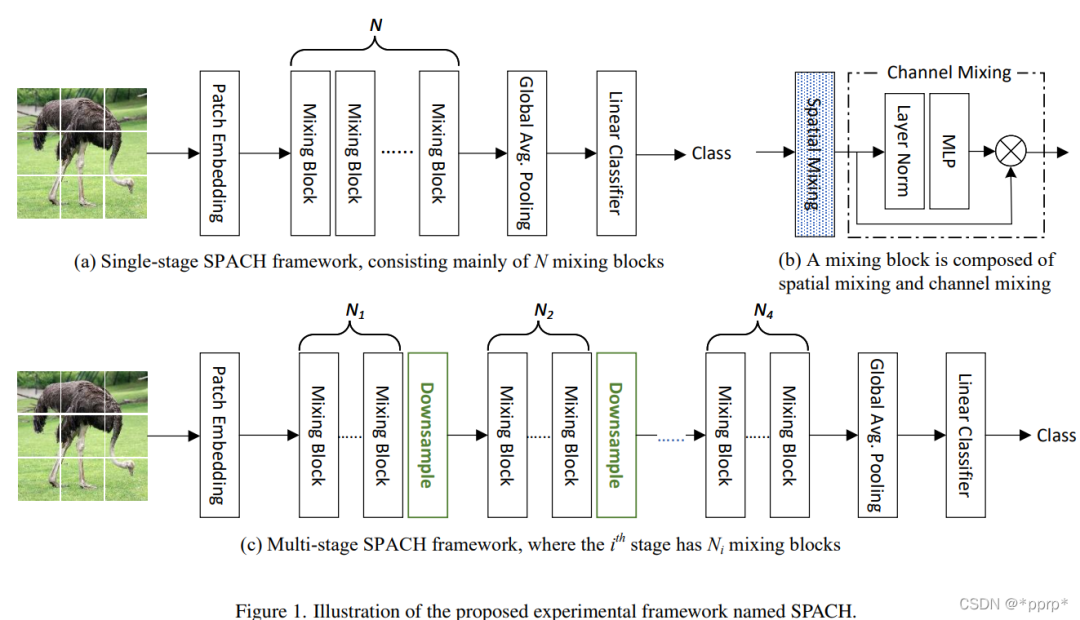
這個(gè)框架總體來說有兩種模式:多階段和單階段。每個(gè)階段內(nèi)部采用的是Mixing Block,而該Mixing Block可以是卷積層、Transformer層以及MLP層。
經(jīng)過實(shí)驗(yàn)發(fā)現(xiàn)了以下幾個(gè)結(jié)論:
多階段框架效果優(yōu)于單節(jié)段框架(通過降采樣劃分階段) 局部性建模具有高效性和重要性。 通過使用輕量級深度卷積(depth wise conv),基于卷積的模型就可以取得與Transformer模型類似的性能。 在MLP和Transformer的架構(gòu)的支路中使用一些局部的建模可以在有效提升性能同時(shí),只增加一點(diǎn)點(diǎn)參數(shù)量。 MLP在小型模型中具有非常強(qiáng)的性能表現(xiàn),但是模型容量擴(kuò)大的時(shí)候會(huì)出現(xiàn)過擬合問題,過擬合是MLP成功路上的攔路虎。 卷積操作和Transformer操作是互補(bǔ)的,卷積的泛化性能更強(qiáng),Transformer結(jié)構(gòu)模型容量更大。通過靈活組合兩者可以掌控從小到大的所有模型。
統(tǒng)一框架
本文提出一統(tǒng)MLP、Transformer、Convolution的框架:SPACH
下表展示的是各個(gè)模塊中可選的參數(shù),并提出了三種變體空間。
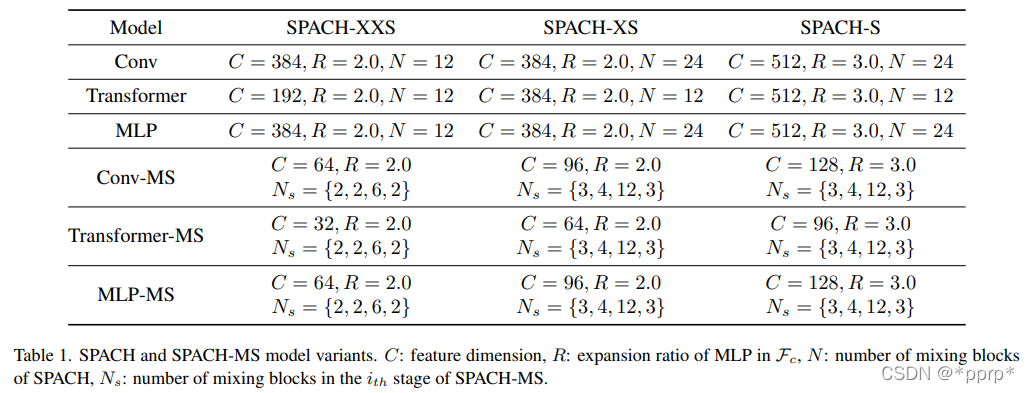
其中各個(gè)模塊設(shè)計(jì)如下:
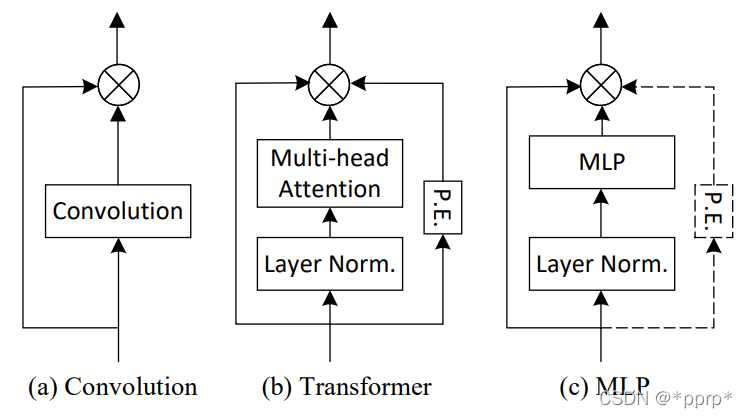
(a)展示的是卷積部分操作,使用的是3x3深度可分離卷積。 (b)展示的是Transformer模塊,使用了positional embedding(由于目前一些研究使用absolute positional embedding會(huì)導(dǎo)致模塊模型的平移不變性,因此采用Convolutional Position Encoding(CPE)。 (c)展示的是MLP模塊,參考了MLP-Mixer的設(shè)計(jì),雖然MLP-Mixer中并沒有使用Positional Embedding,但是作者發(fā)現(xiàn)通過增加輕量級的CPE能夠有效提升模型性能。
注:感覺這三種模塊的設(shè)計(jì)注入了很多經(jīng)驗(yàn)型設(shè)計(jì),比如卷積并沒有用普通卷積,用深度可分離卷積其實(shí)類似MLP中的操作,此外為MLP引入CPE的操作也非常具有技巧性。
三種模塊具有不同的屬性:
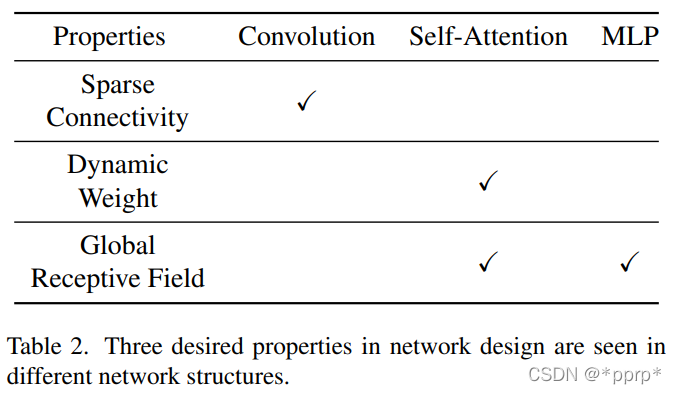
所謂dynamic weight是Transformer中可以根據(jù)圖片輸入的不同動(dòng)態(tài)控制權(quán)重,這樣的模型的容量相較CNN更高。CNN中也有這樣的趨勢,dynamic network的出現(xiàn)也是為了實(shí)現(xiàn)動(dòng)態(tài)權(quán)重。(感謝zzk老師的講解)Transformer側(cè)重是關(guān)系的學(xué)習(xí)和建模,不完全依賴于數(shù)據(jù),CNN側(cè)重模板的匹配和建模,比較依賴于數(shù)據(jù)。
| Transformer | CNN |
|---|---|
| Dynamic Attention | Multi-scale Features by multi-stage |
| Global Context Fusion | Shift,scale and distortion invariance |
| Better Generalization(學(xué)習(xí)關(guān)系,不完全依賴數(shù)據(jù)) | Local Spatial Modeling |
實(shí)驗(yàn)
實(shí)驗(yàn)設(shè)置:
數(shù)據(jù)集選擇ImageNet-1K 輸入分辨率224x224 訓(xùn)練設(shè)置參看DeiT AdamW優(yōu)化器訓(xùn)練300個(gè)epoch weight decay: 0.05 (T用的weight decay更小) learning rate:0.005 對應(yīng) 512 batch size(T用的lr更小)
結(jié)論1:multi-stage 要比 single-stage性能更好
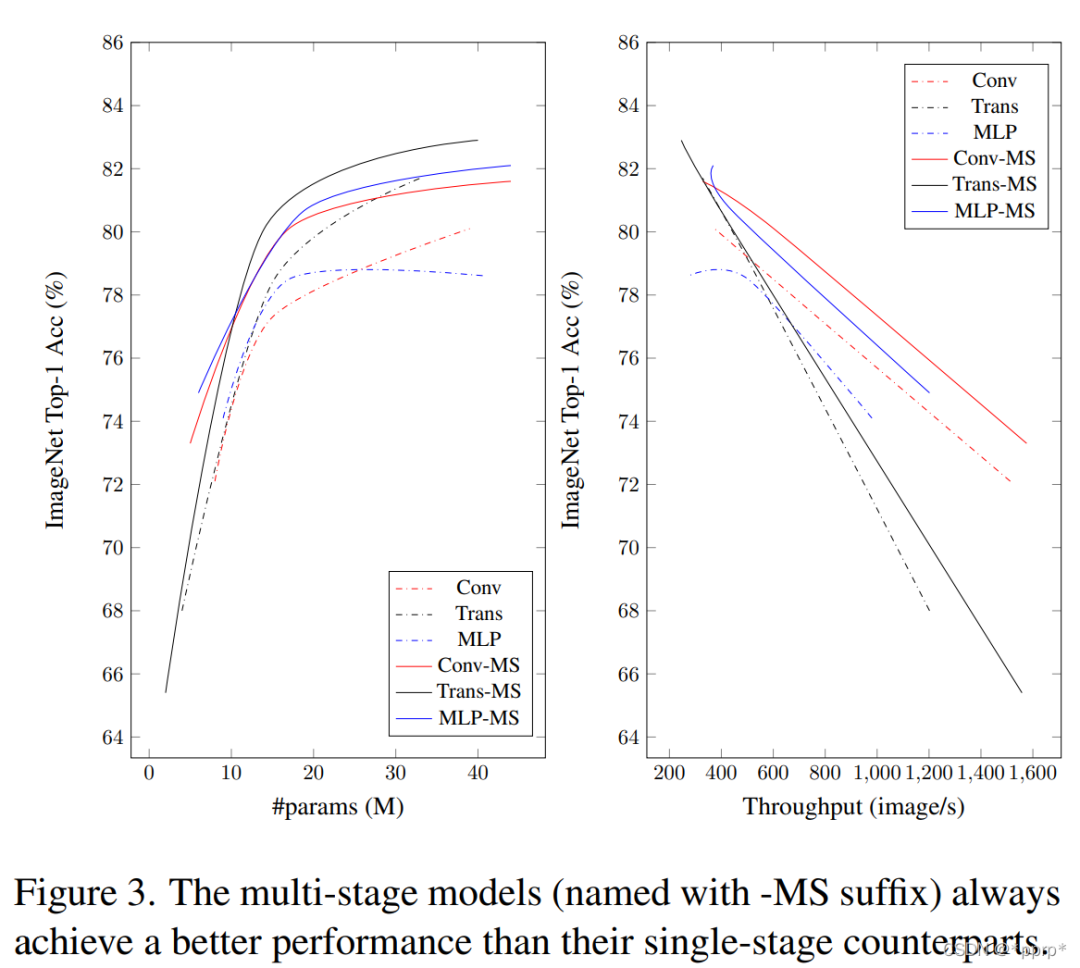
具體性能如下表所記錄,Multi-Stage能夠顯著超過Single Stage的模型。
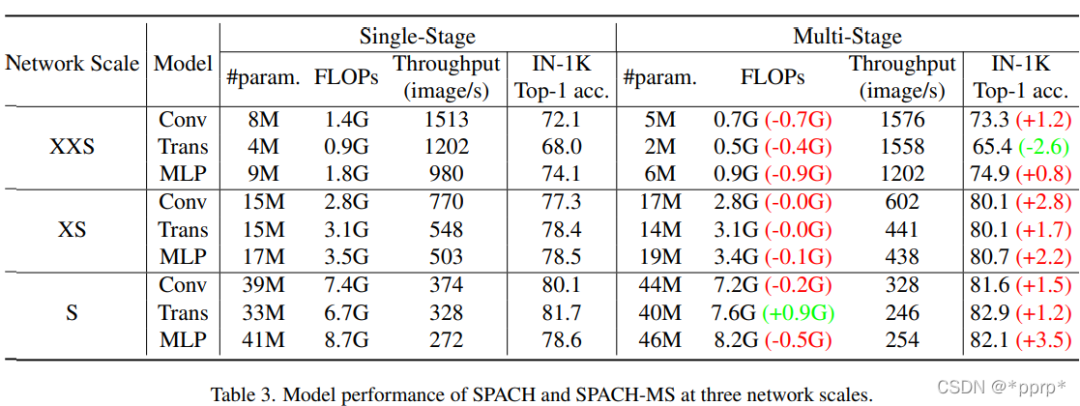
可以發(fā)現(xiàn),有一個(gè)例外,在xxs尺度下,Transformer進(jìn)度損失了2.6個(gè)百分點(diǎn),因?yàn)槎嚯A段模型恰好只有單階段模型一半的參數(shù)量和Flops。
隨著參數(shù)量的增加,模型最高精度先后由MLP、Conv、Transformer所主導(dǎo)。
結(jié)論2:局部建模非常重要
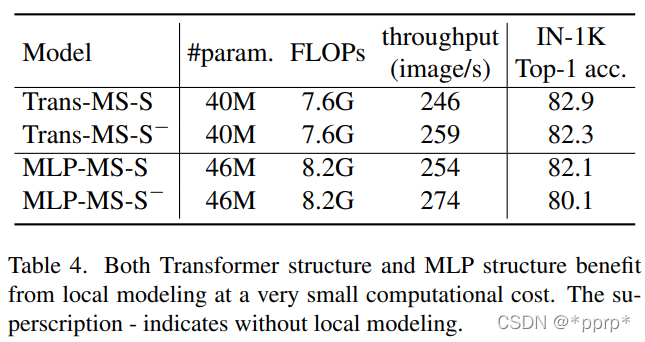
上表展示了具有局部建模以及去除局部建模的效果,可以發(fā)現(xiàn)使用卷積旁路的時(shí)候吞吐量略微降低,但是精度有顯著提高。
結(jié)論3:MLP的細(xì)節(jié)分析
MLP性能不足主要源自于過擬合問題,可以使用兩種機(jī)制來緩解這個(gè)問題。
Multi-Stage的網(wǎng)絡(luò)機(jī)制,可以從以上實(shí)驗(yàn)發(fā)現(xiàn),multi-stage能夠有效降低過擬合,提高模型性能。
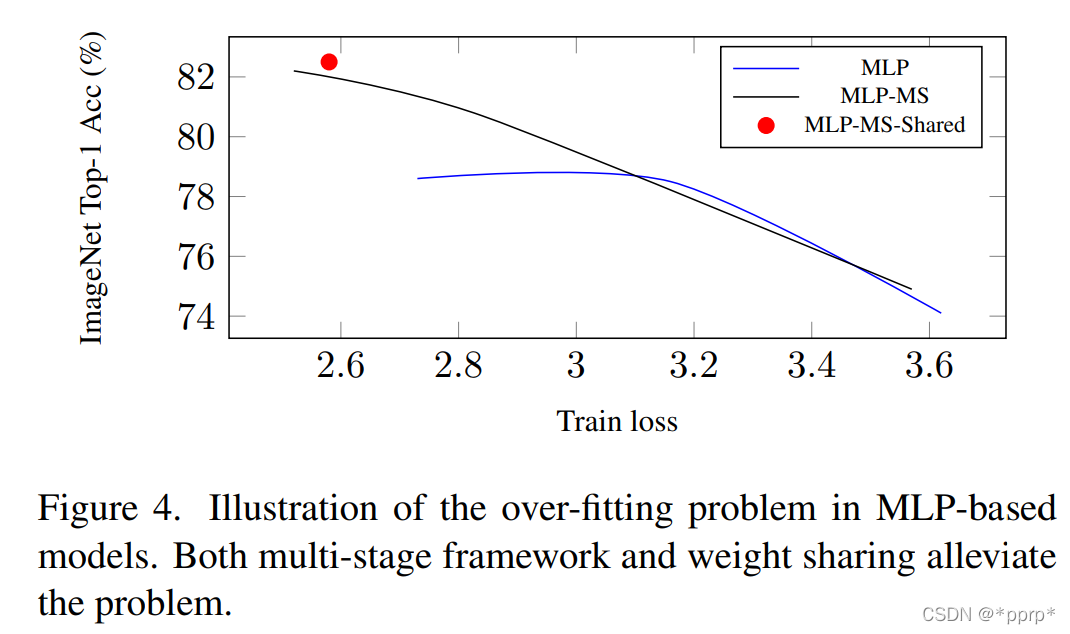
權(quán)重共享機(jī)制,MLP在模型參數(shù)量比較大的情況下容易過擬合,但是如果使用權(quán)重共享可以有效緩解過擬合問題。具體共享的方法是對于某個(gè)stage的所有Mixing Block均使用相同的MLP進(jìn)行處理。
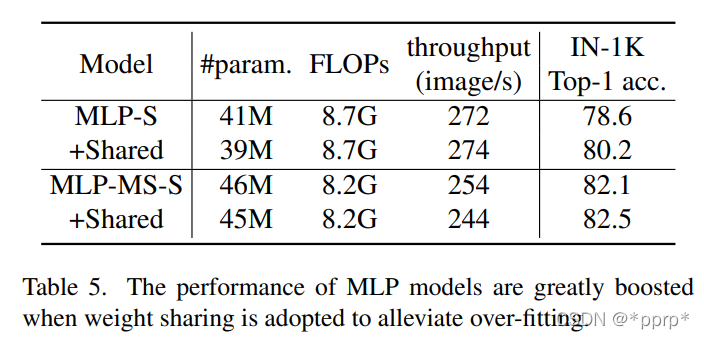
結(jié)論4:卷積與Transformer具有互補(bǔ)性
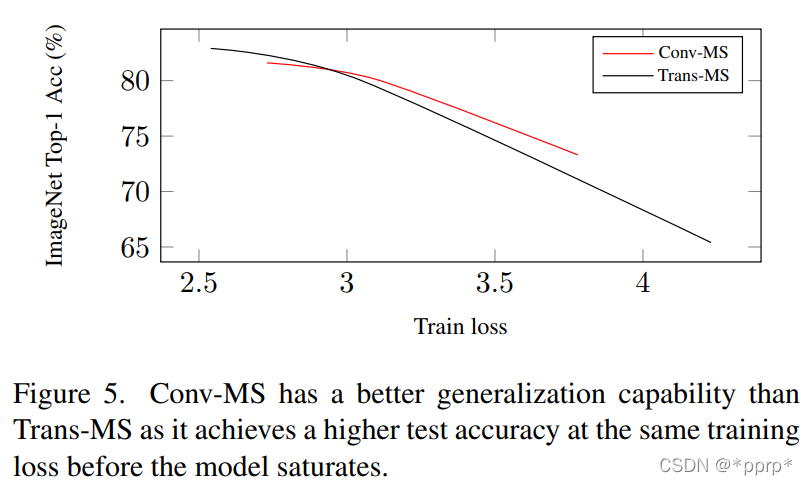
作者認(rèn)為卷積具有的泛化能力更強(qiáng),而Transformer具有更大的模型容量,如下圖所示,在Loss比較大的情況下,整體的準(zhǔn)確率是超過了Transformer空間的。
結(jié)論5:混合架構(gòu)的模型
在multi-stage的卷積網(wǎng)絡(luò)基礎(chǔ)上將某些Mixing Block替換為Transformer的Block, 并且處于對他們建模能力的考量,選擇在淺層網(wǎng)絡(luò)使用CNN,深層網(wǎng)絡(luò)使用Transformer,得到兩種模型空間:

SOTA模型比較結(jié)果:
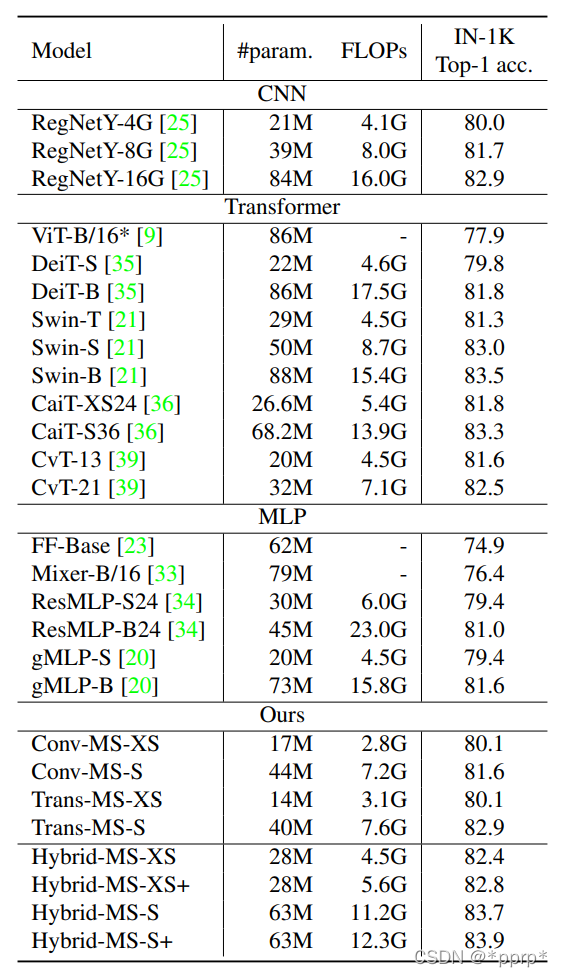
整體結(jié)論是:
Transformer能力要比MLP強(qiáng),因此不考慮使用MLP作為混合架構(gòu) 混合Transformer+CNN的架構(gòu)性能上能夠超越單獨(dú)的CNN架構(gòu)或者Transformer架構(gòu) FLOPS與ACC的權(quán)衡做的比較出色,能夠超越Swin Transformer以及NAS搜索得到的RegNet系列。
最后作者還向讀者進(jìn)行提問:
MLP性能欠佳是由于過擬合帶來的,能夠設(shè)計(jì)高性能MLP模型防止過擬合呢? 目前的分析證明卷積或者Transformer并不是一家獨(dú)大,如何用更好的方式融合兩種架構(gòu)? 是否存在MLP,CNN,Transformer之外的更有效的架構(gòu)呢?
代碼
對照下圖逐步給出各個(gè)Mixing Block:
(a)卷積模塊 ,kernel為3的深度可分離卷積
class?DWConv(nn.Module):
????def?__init__(self,?dim,?kernel_size=3):
????????super(DWConv,?self).__init__()
????????self.dim?=?dim
????????self.kernel_size?=?kernel_size
????????padding?=?(kernel_size?-?1)?//?2
????????self.net?=?nn.Sequential(Reshape2HW(),
?????????????????????????????????nn.Conv2d(dim,?dim,?kernel_size,?1,?padding,?groups=dim),
?????????????????????????????????Reshape2N())
????def?forward(self,?x):
????????x?=?self.net(x)
????????return?x
(b)Transformer
class?SpatialAttention(nn.Module):
????"""Spatial?Attention"""
????def?__init__(self,?dim,?num_heads,?qkv_bias=False,?qk_scale=None,?attn_drop=0.,?proj_drop=0.,?**kwargs):
????????super(SpatialAttention,?self).__init__()
????????head_dim?=?dim?//?num_heads
????????self.num_heads?=?num_heads
????????self.scale?=?qk_scale?or?head_dim?**?-0.5
????????self.qkv?=?nn.Linear(dim,?dim?*?3,?bias=qkv_bias)
????????self.attn_drop?=?nn.Dropout(attn_drop)
????????self.proj?=?nn.Linear(dim,?dim)
????????self.proj_drop?=?nn.Dropout(proj_drop)
????def?forward(self,?x):
????????B,?N,?C?=?x.shape
????????qkv?=?self.qkv(x)
????????qkv?=?rearrange(qkv,?"b?n?(three?heads?head_c)?->?three?b?heads?n?head_c",?three=3,?heads=self.num_heads)
????????q,?k,?v?=?qkv[0]?*?self.scale,?qkv[1],?qkv[2]
????????attn?=?(q?@?k.transpose(-2,?-1))??#?B,?head,?N,?N
????????attn?=?attn.softmax(dim=-1)
????????attn?=?self.attn_drop(attn)
????????out?=?(attn?@?v)??#?B,?head,?N,?C
????????out?=?rearrange(out,?"b?heads?n?head_c?->?b?n?(heads?head_c)")
????????out?=?self.proj(out)
????????out?=?self.proj_drop(out)
????????return?out
(c)MLP模塊,分為channel mlp和spatial mlp,與MLP-Mixer保持一致
class?ChannelMLP(nn.Module):
????"""Channel?MLP"""
????def?__init__(self,?in_features,?hidden_features=None,?out_features=None,?act_layer=nn.GELU,?drop=0.,?**kwargs):
????????super(ChannelMLP,?self).__init__()
????????out_features?=?out_features?or?in_features
????????hidden_features?=?hidden_features?or?in_features
????????self.fc1?=?nn.Linear(in_features,?hidden_features)
????????self.act?=?act_layer()
????????self.fc2?=?nn.Linear(hidden_features,?out_features)
????????self.drop?=?nn.Dropout(drop)
????????self.hidden_features?=?hidden_features
????????self.out_features?=?out_features
????def?forward(self,?x):
????????B,?N,?C?=?x.shape
????????x?=?self.fc1(x)
????????x?=?self.act(x)
????????x?=?self.drop(x)
????????x?=?self.fc2(x)
????????x?=?self.drop(x)
????????return?x
class?SpatialAttention(nn.Module):
????"""Spatial?Attention"""
????def?__init__(self,?dim,?num_heads,?qkv_bias=False,?qk_scale=None,?attn_drop=0.,?proj_drop=0.,?**kwargs):
????????super(SpatialAttention,?self).__init__()
????????head_dim?=?dim?//?num_heads
????????self.num_heads?=?num_heads
????????self.scale?=?qk_scale?or?head_dim?**?-0.5
????????self.qkv?=?nn.Linear(dim,?dim?*?3,?bias=qkv_bias)
????????self.attn_drop?=?nn.Dropout(attn_drop)
????????self.proj?=?nn.Linear(dim,?dim)
????????self.proj_drop?=?nn.Dropout(proj_drop)
????def?forward(self,?x):
????????B,?N,?C?=?x.shape
????????qkv?=?self.qkv(x)
????????qkv?=?rearrange(qkv,?"b?n?(three?heads?head_c)?->?three?b?heads?n?head_c",?three=3,?heads=self.num_heads)
????????q,?k,?v?=?qkv[0]?*?self.scale,?qkv[1],?qkv[2]
????????attn?=?(q?@?k.transpose(-2,?-1))??#?B,?head,?N,?N
????????attn?=?attn.softmax(dim=-1)
????????attn?=?self.attn_drop(attn)
????????out?=?(attn?@?v)??#?B,?head,?N,?C
????????out?=?rearrange(out,?"b?heads?n?head_c?->?b?n?(heads?head_c)")
????????out?=?self.proj(out)
????????out?=?self.proj_drop(out)
????????return?out
SPACH骨干網(wǎng)絡(luò)的構(gòu)建: MixingBlock
class?MixingBlock(nn.Module):
????def?__init__(self,?dim,
?????????????????spatial_func=None,?scaled=True,?init_values=1e-4,?shared_spatial_func=False,
?????????????????norm_layer=partial(nn.LayerNorm,?eps=1e-6),?act_layer=nn.GELU,?drop_path=0.,?cpe=True,
?????????????????num_heads=None,?qkv_bias=False,?qk_scale=None,?attn_drop=0.,?proj_drop=0.,??#?attn
?????????????????in_features=None,?hidden_features=None,?drop=0.,??#?mlp
?????????????????channel_ratio=2.0
?????????????????):
????????super(MixingBlock,?self).__init__()
????????spatial_kwargs?=?dict(act_layer=act_layer,
??????????????????????????????in_features=in_features,?hidden_features=hidden_features,?drop=drop,??#?mlp
??????????????????????????????dim=dim,?num_heads=num_heads,?qkv_bias=qkv_bias,?qk_scale=qk_scale,?attn_drop=attn_drop,?proj_drop=proj_drop??#?attn
??????????????????????????????)
????????self.valid_spatial_func?=?True
????????if?spatial_func?is?not?None:
????????????if?shared_spatial_func:
????????????????self.spatial_func?=?spatial_func
????????????else:
????????????????self.spatial_func?=?spatial_func(**spatial_kwargs)
????????????self.norm1?=?norm_layer(dim)
????????????if?scaled:
????????????????self.gamma_1?=?nn.Parameter(init_values?*?torch.ones(1,?1,?dim),?requires_grad=True)
????????????else:
????????????????self.gamma_1?=?1.
????????else:
????????????self.valid_spatial_func?=?False
????????self.channel_func?=?ChannelMLP(in_features=dim,?hidden_features=int(dim*channel_ratio),?act_layer=act_layer,
???????????????????????????????????????drop=drop)
????????self.norm2?=?norm_layer(dim)
????????self.drop_path?=?DropPath(drop_path)?if?drop_path?>?0.?else?nn.Identity()
????????self.cpe?=?cpe
????????if?cpe:
????????????self.cpe_net?=?DWConv(dim)
????def?forward(self,?x):
????????in_x?=?x
????????if?self.valid_spatial_func:
????????????x?=?x?+?self.drop_path(self.gamma_1?*?self.spatial_func(self.norm1(in_x)))
????????if?self.cpe:
????????????x?=?x?+?self.cpe_net(in_x)
????????x?=?x?+?self.drop_path(self.channel_func(self.norm2(x)))
????????return?
SPACH構(gòu)建:
class?Spach(nn.Module):
????def?__init__(self,
?????????????????num_classes=1000,
?????????????????img_size=224,
?????????????????in_chans=3,
?????????????????hidden_dim=384,
?????????????????patch_size=16,
?????????????????net_arch=None,
?????????????????act_layer=nn.GELU,
?????????????????norm_layer=partial(nn.LayerNorm,?eps=1e-6),
?????????????????stem_type='conv1',
?????????????????scaled=True,?init_values=1e-4,?drop_path_rate=0.,?cpe=True,?shared_spatial_func=False,??#?mixing?block
?????????????????num_heads=12,?qkv_bias=True,?qk_scale=None,?attn_drop=0.,?proj_drop=0.,??#?attn
?????????????????token_ratio=0.5,?channel_ratio=2.0,?drop_rate=0.,??#?mlp
?????????????????downstream=False,
?????????????????**kwargs
?????????????????):
????????super(Spach,?self).__init__()
????????self.num_classes?=?num_classes
????????self.hidden_dim?=?hidden_dim
????????self.downstream?=?downstream
????????self.stem?=?STEM_LAYER[stem_type](
????????????img_size=img_size,?patch_size=patch_size,?in_chans=in_chans,?embed_dim=hidden_dim,?downstream=downstream)
????????self.norm1?=?norm_layer(hidden_dim)
????????block_kwargs?=?dict(dim=hidden_dim,?scaled=scaled,?init_values=init_values,?cpe=cpe,
????????????????????????????shared_spatial_func=shared_spatial_func,?norm_layer=norm_layer,?act_layer=act_layer,
????????????????????????????num_heads=num_heads,?qkv_bias=qkv_bias,?qk_scale=qk_scale,?attn_drop=attn_drop,?proj_drop=proj_drop,??#?attn
????????????????????????????in_features=self.stem.num_patches,?hidden_features=int(self.stem.num_patches?*?token_ratio),?channel_ratio=channel_ratio,?drop=drop_rate)??#?mlp
????????self.blocks?=?self.make_blocks(net_arch,?block_kwargs,?drop_path_rate,?shared_spatial_func)
????????self.norm2?=?norm_layer(hidden_dim)
????????if?not?downstream:
????????????self.pool?=?Reduce('b?n?c?->?b?c',?reduction='mean')
????????????self.head?=?nn.Linear(hidden_dim,?self.num_classes)
????????self.init_weights()
????def?make_blocks(self,?net_arch,?block_kwargs,?drop_path,?shared_spatial_func):
????????if?shared_spatial_func:
????????????assert?len(net_arch)?==?1,?'`shared_spatial_func`?only?support?unitary?spatial?function'
????????????assert?net_arch[0][0]?!=?'pass',?'`shared_spatial_func`?do?not?support?pass'
????????????spatial_func?=?SPATIAL_FUNC[net_arch[0][0]](**block_kwargs)
????????else:
????????????spatial_func?=?None
????????blocks?=?[]
????????for?func_type,?depth?in?net_arch:
????????????for?i?in?range(depth):
????????????????blocks.append(MixingBlock(spatial_func=spatial_func?or?SPATIAL_FUNC[func_type],?drop_path=drop_path,
??????????????????????????????????????????**block_kwargs))
????????return?nn.Sequential(*blocks)
????def?init_weights(self):
????????for?n,?m?in?self.named_modules():
????????????_init_weights(m,?n)
????def?forward_features(self,?x):
????????x?=?self.stem(x)
????????x?=?reshape2n(x)
????????x?=?self.norm1(x)
????????x?=?self.blocks(x)
????????x?=?self.norm2(x)
????????return?x
????def?forward(self,?x):
????????x?=?self.forward_features(x)
????????x?=?self.pool(x)
????????x?=?self.head(x)
????????return?x
參考
https://github.com/microsoft/SPACH
https://zhuanlan.zhihu.com/p/411145994
https://arxiv.org/pdf/2108.13002v2.pdf
