日前,吳恩達在圣誕節(jié)之際回顧了2020年AI的一些重大事件,包括AI應對新冠疫情、數(shù)據(jù)集存在種族偏見、對抗虛假信息算法、AlphaFold預測蛋白質(zhì)三維結(jié)構、1750億參數(shù)的GPT-3出現(xiàn)等等,并為大家送上節(jié)日祝福。親愛的朋友們,在過去的十年中,每年我都會飛往新加坡或香港,與我的母親一起慶祝她的12月22日的生日。今年,我們則是通過Zoom線上慶生。盡管距離遙遠,但我仍然感到很高興,我的家人們可以從美國,新加坡,香港,香港和新西蘭一起線上聚會,并演唱同步性很差的“Happy Birthday To You”。
我希望我也可以和大家一起在Zoom上通話,以祝大家節(jié)日快樂,新年快樂!
節(jié)假日期間,我經(jīng)常想一想重要的人,回顧他們?yōu)槲一蛩怂龅氖拢⒛乇硎疚覍λ麄兊母兄x。這使我感到與他們的聯(lián)系更加緊密。
我覺得在我們遠離社交的假期中思考這一點非常有價值:誰是您生活中最重要的人,您可能出于什么原因要感謝他們?無論是面對面的還是在線的,我都希望您能找到屬于自己的方式——在這個假期里培養(yǎng)于最重要的人之間的關系。Keep learning!? ?? ? ? ? ?
2020年回顧

在過去一年,一種新的具有高度傳染性的冠狀病毒破壞了人們的正常生活,它所導致的社會裂痕也威脅到了我們的共同利益。
在這一年期間,有大量的機器學習工程師參與其中,設計了用于新冠肺炎(Covid-19)診斷和治療的工具、建立了識別仇恨言論和虛假信息的模型,并指出和強調(diào)了整個AI社區(qū)偏見的存在。但是事情也有輕松的一面:這一年里可以將睡衣一鍵轉(zhuǎn)換成西裝的在家辦公工具、GPT-3語言模型、在AI輔助藝術和表演方面的引人入勝的實驗。接下來請就讓我們一起探討過去一年我們的艱辛和輝煌。1、AI加快了科學家對冠狀病毒疫苗的搜尋,全球的機器學習研究人員爭先恐后地利用AI技術來對抗冠狀病毒。2、巴黎和戛納市在公交車站、公共汽車和市場中使用計算機視覺評估了法規(guī)的遵守情況。3、多哥政府訓練一個模型以識別衛(wèi)星圖像中的貧困地區(qū),然后使用模型的輸出指導將救濟金分配給最需要的人。 攝影:環(huán)球影業(yè)集團/阿拉米4、聊天機器人提供了合成的虛擬朋友,供被疫情封鎖的人們孤獨時聊天和調(diào)情。5、對于在家工作的人們,視頻會議公司訓練AI模型來過濾背景噪音并將睡衣變成虛擬的商務正裝。6、中國許多機構合作開發(fā)了一種可在CT掃描中檢測Covid-19的模型,其準確度超過90%。該模型已在七個國家/地區(qū)部署,到目前為止,該模型的代碼已下載了超過300萬次。
攝影:環(huán)球影業(yè)集團/阿拉米4、聊天機器人提供了合成的虛擬朋友,供被疫情封鎖的人們孤獨時聊天和調(diào)情。5、對于在家工作的人們,視頻會議公司訓練AI模型來過濾背景噪音并將睡衣變成虛擬的商務正裝。6、中國許多機構合作開發(fā)了一種可在CT掃描中檢測Covid-19的模型,其準確度超過90%。該模型已在七個國家/地區(qū)部署,到目前為止,該模型的代碼已下載了超過300萬次。 相關鏈接:https://www.cell.com/cell/pdf/S0092-8674(20)30551-1.pdf7、美國生物技術公司Moderna,其疫苗于12月份獲得美國食品藥品監(jiān)督管理局的批準,它使用機器學習來優(yōu)化mRNA序列以轉(zhuǎn)化為可以測試的分子。
相關鏈接:https://www.cell.com/cell/pdf/S0092-8674(20)30551-1.pdf7、美國生物技術公司Moderna,其疫苗于12月份獲得美國食品藥品監(jiān)督管理局的批準,它使用機器學習來優(yōu)化mRNA序列以轉(zhuǎn)化為可以測試的分子。 圖源:https://www.shutterstock.com/新聞背后:AI可能仍在治療Covid-19中起重要作用。某非營利組織使用了半監(jiān)督式深度學習平臺來篩選14,000種候選抗病毒藥物。該系統(tǒng)驗證了有望用于動物試驗的四種化合物。8、在防范新冠疫情傳播中,口罩成為了絕對主力。為了讓大眾乖乖帶上口罩,人們可謂是操碎了心,AI也在這時候幫上了忙。有人開發(fā)了一套AI系統(tǒng),號稱能夠根據(jù)一個人說話的口音“聽”出是否佩戴口罩,且檢測的準確率已經(jīng)達到了78.8%。研究人員開發(fā)這項技術的初衷是,他們發(fā)現(xiàn),戴上口罩會影響語音的的效果,這是由于肌肉收縮、發(fā)聲量增加和傳輸損失引起的。如今,戴口罩已經(jīng)成為了日常。為了適應全民戴口罩的新環(huán)境,許多AI應用也在對自身進行升級。一些企業(yè)就開發(fā)出了口罩檢測模型,可以判斷人群中的個體是否有戴口罩,甚至還開發(fā)了對戴口罩人臉進行身份識別的模型。我的立場:人工智能不是萬能藥,但這種新型、高病毒性、高傳染性冠狀病毒的問世已經(jīng)成為人類利用AI對抗傳染病能力的有力試驗。當生成對抗網(wǎng)絡滲透到文化、社會和科學領域時,它們正悄悄地在網(wǎng)絡中充斥著無數(shù)的合成圖像。
圖源:https://www.shutterstock.com/新聞背后:AI可能仍在治療Covid-19中起重要作用。某非營利組織使用了半監(jiān)督式深度學習平臺來篩選14,000種候選抗病毒藥物。該系統(tǒng)驗證了有望用于動物試驗的四種化合物。8、在防范新冠疫情傳播中,口罩成為了絕對主力。為了讓大眾乖乖帶上口罩,人們可謂是操碎了心,AI也在這時候幫上了忙。有人開發(fā)了一套AI系統(tǒng),號稱能夠根據(jù)一個人說話的口音“聽”出是否佩戴口罩,且檢測的準確率已經(jīng)達到了78.8%。研究人員開發(fā)這項技術的初衷是,他們發(fā)現(xiàn),戴上口罩會影響語音的的效果,這是由于肌肉收縮、發(fā)聲量增加和傳輸損失引起的。如今,戴口罩已經(jīng)成為了日常。為了適應全民戴口罩的新環(huán)境,許多AI應用也在對自身進行升級。一些企業(yè)就開發(fā)出了口罩檢測模型,可以判斷人群中的個體是否有戴口罩,甚至還開發(fā)了對戴口罩人臉進行身份識別的模型。我的立場:人工智能不是萬能藥,但這種新型、高病毒性、高傳染性冠狀病毒的問世已經(jīng)成為人類利用AI對抗傳染病能力的有力試驗。當生成對抗網(wǎng)絡滲透到文化、社會和科學領域時,它們正悄悄地在網(wǎng)絡中充斥著無數(shù)的合成圖像。 圖源:TechtalkDeepfake出現(xiàn)在主流娛樂活動、商業(yè)廣告、政治活動中,甚至出現(xiàn)在紀錄片中,用來替換當事人的真實面貌以提供隱私保護。在喧囂中,對圖像生成器的在線前端的狂潮基本上沒有引起人們的注意。受到2019年的“ This Person Does Not Exist”(一個可以生成假的、逼真的個人肖像網(wǎng)絡應用程序)的啟發(fā),具有幽默感的工程師采用模仿現(xiàn)實世界細節(jié)的生成對抗網(wǎng)絡(GAN)。1、經(jīng)過訓練的Google Earth 可以使“This City Does Not Exist”產(chǎn)生大大小小的不存在的定居點的鳥瞰圖。
圖源:TechtalkDeepfake出現(xiàn)在主流娛樂活動、商業(yè)廣告、政治活動中,甚至出現(xiàn)在紀錄片中,用來替換當事人的真實面貌以提供隱私保護。在喧囂中,對圖像生成器的在線前端的狂潮基本上沒有引起人們的注意。受到2019年的“ This Person Does Not Exist”(一個可以生成假的、逼真的個人肖像網(wǎng)絡應用程序)的啟發(fā),具有幽默感的工程師采用模仿現(xiàn)實世界細節(jié)的生成對抗網(wǎng)絡(GAN)。1、經(jīng)過訓練的Google Earth 可以使“This City Does Not Exist”產(chǎn)生大大小小的不存在的定居點的鳥瞰圖。 AI生成的假的鳥瞰圖 ? 圖源:http://thiscitydoesnotexist.com/2、“This Horse Does Not Exist” 可以生成各種各樣的姿勢、品種和狀態(tài)的馬:? ? ? ?
AI生成的假的鳥瞰圖 ? 圖源:http://thiscitydoesnotexist.com/2、“This Horse Does Not Exist” 可以生成各種各樣的姿勢、品種和狀態(tài)的馬:? ? ? ? ? ? ?圖源:https://thishorsedoesnotexist.com/3、?“This Pizza Does Not Exist”?生成不存在的披薩,與真實的披薩相比,可能會缺少一些奶酪和醬汁的光澤感。4、用AI生成的不存在的中國山水畫,欺騙了眾多藝術愛好者。
? ? ?圖源:https://thishorsedoesnotexist.com/3、?“This Pizza Does Not Exist”?生成不存在的披薩,與真實的披薩相比,可能會缺少一些奶酪和醬汁的光澤感。4、用AI生成的不存在的中國山水畫,欺騙了眾多藝術愛好者。 論文鏈接:https://arxiv.org/pdf/2011.05552.pdf關于GAN的發(fā)展、應用和風險等問題,我曾經(jīng)對Ian Goodfellow進行了簡單的訪談。Ian Goodfellow表示,他在GAN那篇論文中就列舉了很多未來可能的研究方向,但沒有想過域到域的轉(zhuǎn)換(domain-to-domain translation),比如CycleGAN。關于GAN的用途,Ian Goodfellow認為,將GAN應用在醫(yī)學領域會更有意義,比如為牙科患者設計個性化的牙冠,以及設計藥物等等。最后,談到GAN輸出中包含的偏見,Ian Goodfellow表示:“隨著GAN生成人臉越來越逼真,GAN可以通過為其他機器學習算法生成訓練數(shù)據(jù),來抵消訓練數(shù)據(jù)中的偏見。如果你使用的語言在數(shù)據(jù)中代表性不高,則可以對其進行過度采樣。但是,我希望還有其他方法可以解決數(shù)據(jù)集中代表性不足的問題。”https://blog.deeplearning.ai/blog/the-batch-gan-special-issue-ian-goodfellow-for-real-detecting-fakes-including-minorities-synthesizing-training-data-applying-virtual-make-up三、ImageNet等數(shù)據(jù)集存在種族偏見深度學習的基本數(shù)據(jù)集開始受到廣泛關注。由于數(shù)據(jù)集的編譯、標記和使用方式的不同,導致其在模型訓練過程中會對社會邊緣化群體產(chǎn)生偏見。研究人員的審查促進了AI的改革,同時也加深了人們對AI所隱含的社會偏見的認識。今年涉及的典型案例包括:1、知名計算機視覺數(shù)據(jù)集ImageNet被推到了風口浪尖。ImageNet的創(chuàng)建者李飛飛及其同事對數(shù)據(jù)集進行了重新梳理,并刪除了WordNet詞匯數(shù)據(jù)庫帶來的種族主義、性別歧視和其他貶義標簽。? ??2、一項研究發(fā)現(xiàn),即使使用未經(jīng)標記的ImageNet數(shù)據(jù)進行訓練,其模型也可能由于數(shù)據(jù)多樣性不足而引起偏差。3、麻省理工學院計算機科學與人工智能實驗室撤回了Tiny Images數(shù)據(jù)集,原因是有外部研究人員發(fā)現(xiàn)該數(shù)據(jù)庫充斥著性暗示、種族歧視等大量不良標簽。4、用于訓練StyleGAN的數(shù)據(jù)集FlickrFaces-HQ(FFHQ)同樣缺乏足夠的多樣性。基于StyleGAN模型訓練的PULSE算法將美國黑人總統(tǒng)巴拉克·奧巴馬(Barack Obama)的肖像畫變成了白人。(PULSE可以將提高低分辨率照片轉(zhuǎn)化為高分辨率的圖像)在PULSE事件爆發(fā)后,F(xiàn)acebook首席科學家Yann LeCun和當時Google AI倫理負責人Timnit Gebru之間展開了一場辯論,爭論的焦點在于:機器學習中的社會偏見是出自AI數(shù)據(jù)集,還是AI模型?LeCun的立場是:模型在訓練“存在偏見的數(shù)據(jù)集”之前不存在偏見,也就是模型本身不存在偏見,而且有偏見的數(shù)據(jù)集是可以修改的。Gebru則表示:正如我們在信中所說的,這種偏見是在社會差異的背景下產(chǎn)生的,要消除AI系統(tǒng)的偏見,必須解決整個領域的差異。隨后,在關于偏見的進一步分歧中,Gebru和谷歌分道揚鑣。Gebru對人臉識別技術進行過深入研究,并曾就科技行業(yè)缺乏多樣性發(fā)表過言論。此次Gebru被谷歌解雇事件的起因是Gebru想要發(fā)表一篇關于大型語言模型的社會危害的論文,但被谷歌內(nèi)部否決、要求撤稿,Gebru嘗試溝通無果,控訴谷歌不尊重邊緣群體的人權。我的立場:確保數(shù)據(jù)集中的偏見在任務開始前被刪除,而這項重要的工作才剛剛開始。https://blog.deeplearning.ai/blog/the-batch-ais-progress-problem-recognizing-masked-faces-mapping-underwater-ecosystems-augmenting-feature全球新冠疫情和有爭議的美國大選掀起了一場虛假信息風暴,大型AI科技公司均受到了影響。面對來自公眾日益增加的壓力——阻止煽動性謊言,F(xiàn)acebook、Google的YouTube部門以及Twitter在爭相更新其推薦引擎。據(jù)了解,紀錄片Netflix對他們進行了嚴厲的痛斥;美國國會議員對他們展開了調(diào)查;民意測驗顯示,他們已經(jīng)失去了大多數(shù)美國人的信任。這幾家公司嘗試通過各種算法和策略解決虛假信息問題,例如:1、在發(fā)現(xiàn)了數(shù)百個包含AI生成的虛假頭像的用戶個人資料后,F(xiàn)acebook嚴厲打擊了被認為有誤導性的操縱媒體,并徹底禁止了Deepfake視頻。該公司繼續(xù)開發(fā)深度學習工具,以檢測仇恨言論,導致偏見的模因以及有關Covid-19的錯誤信息。2、YouTube開發(fā)了一個分類器來識別所謂的邊界內(nèi)容:包括仇恨言論、宣傳陰謀論、醫(yī)學錯誤信息以及其他想法的視頻。3、Facebook和Twitter關閉了他們認為是擾亂國家宣傳活動的賬戶。4、這三家公司在含有美國大選誤導性信息內(nèi)容中均添加了免責聲明。Twitter采取了最嚴格的政策,直接舉報了特朗普的虛假推文。不過,他們顯然沒有做出觸及底線的更改。而且其改革可能也不會持續(xù)很久,因為他們采取的政策有的已經(jīng)松懈,有的已經(jīng)發(fā)生了適得其反的效果。比如:
論文鏈接:https://arxiv.org/pdf/2011.05552.pdf關于GAN的發(fā)展、應用和風險等問題,我曾經(jīng)對Ian Goodfellow進行了簡單的訪談。Ian Goodfellow表示,他在GAN那篇論文中就列舉了很多未來可能的研究方向,但沒有想過域到域的轉(zhuǎn)換(domain-to-domain translation),比如CycleGAN。關于GAN的用途,Ian Goodfellow認為,將GAN應用在醫(yī)學領域會更有意義,比如為牙科患者設計個性化的牙冠,以及設計藥物等等。最后,談到GAN輸出中包含的偏見,Ian Goodfellow表示:“隨著GAN生成人臉越來越逼真,GAN可以通過為其他機器學習算法生成訓練數(shù)據(jù),來抵消訓練數(shù)據(jù)中的偏見。如果你使用的語言在數(shù)據(jù)中代表性不高,則可以對其進行過度采樣。但是,我希望還有其他方法可以解決數(shù)據(jù)集中代表性不足的問題。”https://blog.deeplearning.ai/blog/the-batch-gan-special-issue-ian-goodfellow-for-real-detecting-fakes-including-minorities-synthesizing-training-data-applying-virtual-make-up三、ImageNet等數(shù)據(jù)集存在種族偏見深度學習的基本數(shù)據(jù)集開始受到廣泛關注。由于數(shù)據(jù)集的編譯、標記和使用方式的不同,導致其在模型訓練過程中會對社會邊緣化群體產(chǎn)生偏見。研究人員的審查促進了AI的改革,同時也加深了人們對AI所隱含的社會偏見的認識。今年涉及的典型案例包括:1、知名計算機視覺數(shù)據(jù)集ImageNet被推到了風口浪尖。ImageNet的創(chuàng)建者李飛飛及其同事對數(shù)據(jù)集進行了重新梳理,并刪除了WordNet詞匯數(shù)據(jù)庫帶來的種族主義、性別歧視和其他貶義標簽。? ??2、一項研究發(fā)現(xiàn),即使使用未經(jīng)標記的ImageNet數(shù)據(jù)進行訓練,其模型也可能由于數(shù)據(jù)多樣性不足而引起偏差。3、麻省理工學院計算機科學與人工智能實驗室撤回了Tiny Images數(shù)據(jù)集,原因是有外部研究人員發(fā)現(xiàn)該數(shù)據(jù)庫充斥著性暗示、種族歧視等大量不良標簽。4、用于訓練StyleGAN的數(shù)據(jù)集FlickrFaces-HQ(FFHQ)同樣缺乏足夠的多樣性。基于StyleGAN模型訓練的PULSE算法將美國黑人總統(tǒng)巴拉克·奧巴馬(Barack Obama)的肖像畫變成了白人。(PULSE可以將提高低分辨率照片轉(zhuǎn)化為高分辨率的圖像)在PULSE事件爆發(fā)后,F(xiàn)acebook首席科學家Yann LeCun和當時Google AI倫理負責人Timnit Gebru之間展開了一場辯論,爭論的焦點在于:機器學習中的社會偏見是出自AI數(shù)據(jù)集,還是AI模型?LeCun的立場是:模型在訓練“存在偏見的數(shù)據(jù)集”之前不存在偏見,也就是模型本身不存在偏見,而且有偏見的數(shù)據(jù)集是可以修改的。Gebru則表示:正如我們在信中所說的,這種偏見是在社會差異的背景下產(chǎn)生的,要消除AI系統(tǒng)的偏見,必須解決整個領域的差異。隨后,在關于偏見的進一步分歧中,Gebru和谷歌分道揚鑣。Gebru對人臉識別技術進行過深入研究,并曾就科技行業(yè)缺乏多樣性發(fā)表過言論。此次Gebru被谷歌解雇事件的起因是Gebru想要發(fā)表一篇關于大型語言模型的社會危害的論文,但被谷歌內(nèi)部否決、要求撤稿,Gebru嘗試溝通無果,控訴谷歌不尊重邊緣群體的人權。我的立場:確保數(shù)據(jù)集中的偏見在任務開始前被刪除,而這項重要的工作才剛剛開始。https://blog.deeplearning.ai/blog/the-batch-ais-progress-problem-recognizing-masked-faces-mapping-underwater-ecosystems-augmenting-feature全球新冠疫情和有爭議的美國大選掀起了一場虛假信息風暴,大型AI科技公司均受到了影響。面對來自公眾日益增加的壓力——阻止煽動性謊言,F(xiàn)acebook、Google的YouTube部門以及Twitter在爭相更新其推薦引擎。據(jù)了解,紀錄片Netflix對他們進行了嚴厲的痛斥;美國國會議員對他們展開了調(diào)查;民意測驗顯示,他們已經(jīng)失去了大多數(shù)美國人的信任。這幾家公司嘗試通過各種算法和策略解決虛假信息問題,例如:1、在發(fā)現(xiàn)了數(shù)百個包含AI生成的虛假頭像的用戶個人資料后,F(xiàn)acebook嚴厲打擊了被認為有誤導性的操縱媒體,并徹底禁止了Deepfake視頻。該公司繼續(xù)開發(fā)深度學習工具,以檢測仇恨言論,導致偏見的模因以及有關Covid-19的錯誤信息。2、YouTube開發(fā)了一個分類器來識別所謂的邊界內(nèi)容:包括仇恨言論、宣傳陰謀論、醫(yī)學錯誤信息以及其他想法的視頻。3、Facebook和Twitter關閉了他們認為是擾亂國家宣傳活動的賬戶。4、這三家公司在含有美國大選誤導性信息內(nèi)容中均添加了免責聲明。Twitter采取了最嚴格的政策,直接舉報了特朗普的虛假推文。不過,他們顯然沒有做出觸及底線的更改。而且其改革可能也不會持續(xù)很久,因為他們采取的政策有的已經(jīng)松懈,有的已經(jīng)發(fā)生了適得其反的效果。比如:- 今年6月,《華爾街日報》報道說,一些Facebook高管已經(jīng)停止使用部分監(jiān)管工具。該公司后來撤銷了在選舉期間使用的修改算法,因為它促進了某些新聞源的知名度。Facebook不夠誠意的做法已經(jīng)導致了一些員工辭職。
- YouTube采用的算法成功減少了虛假信息內(nèi)容的創(chuàng)作者的訪問量。但是,它也增加了某些經(jīng)常傳播同樣可疑信息的大型實體網(wǎng)站的訪問量。
我的立場:在這場貓和老鼠的游戲中,目前尚無明確的方法能夠贏得那些造謠者或虛假內(nèi)容傳播者,但是貓在這場游戲中必須保持領先的地位,否則將會失去公眾的信任,或者遭到監(jiān)管機構的調(diào)查。??五、AlphaFold預測蛋白質(zhì)三維結(jié)構
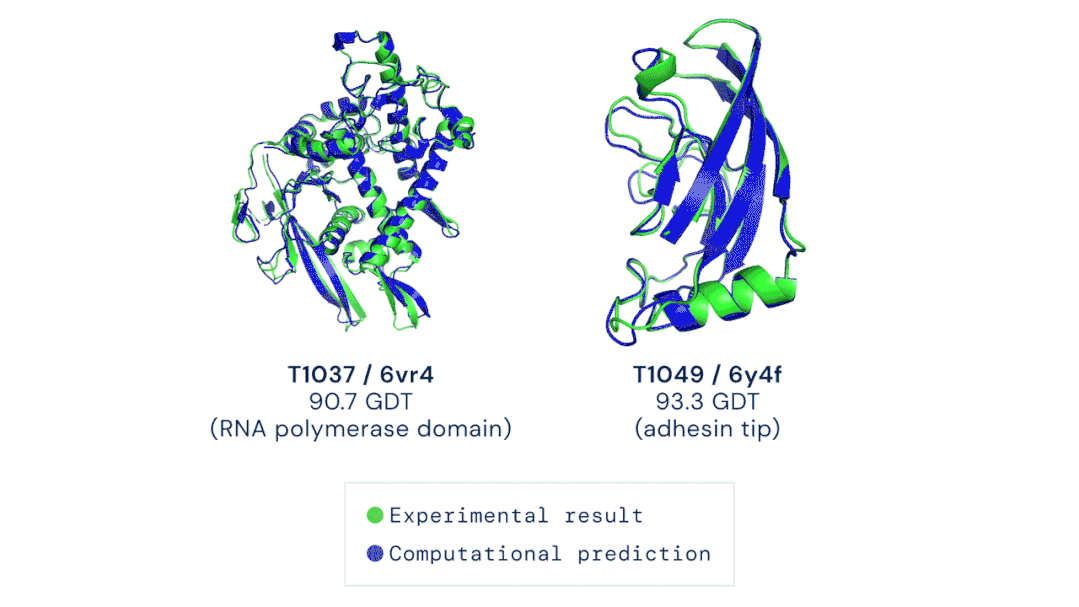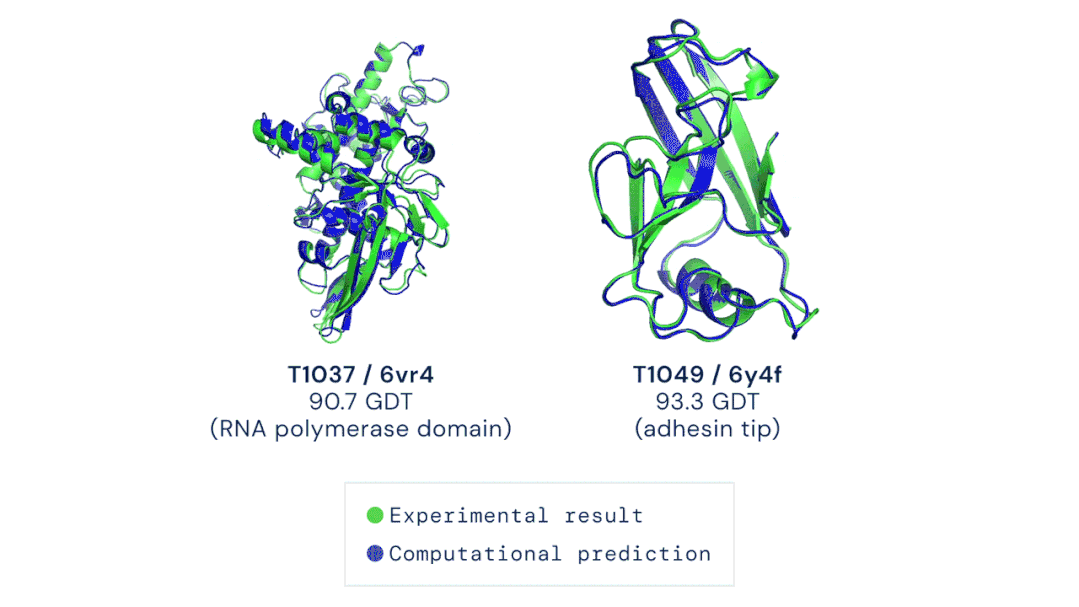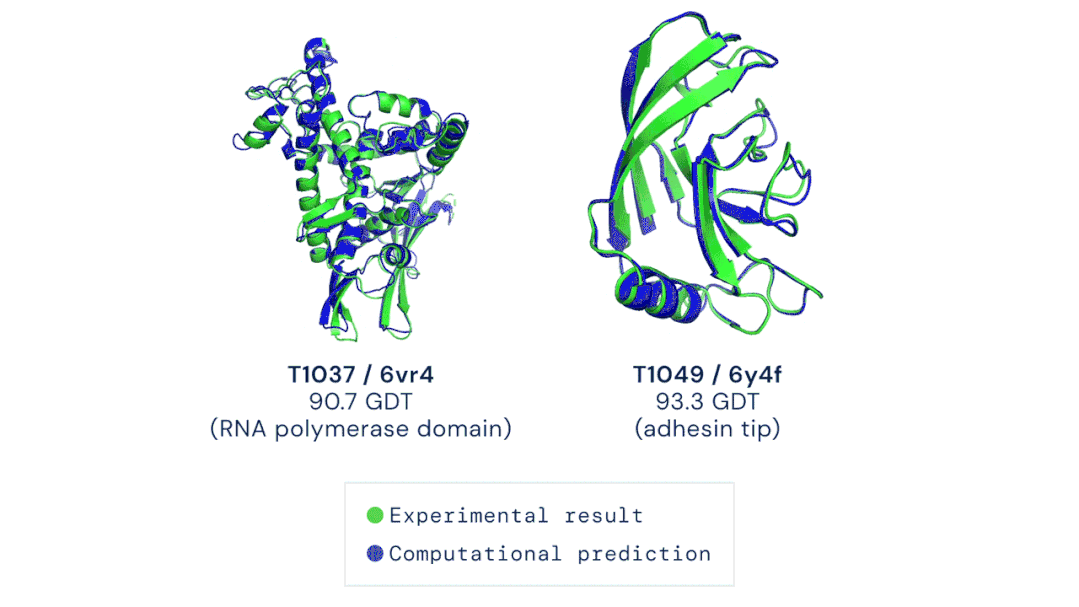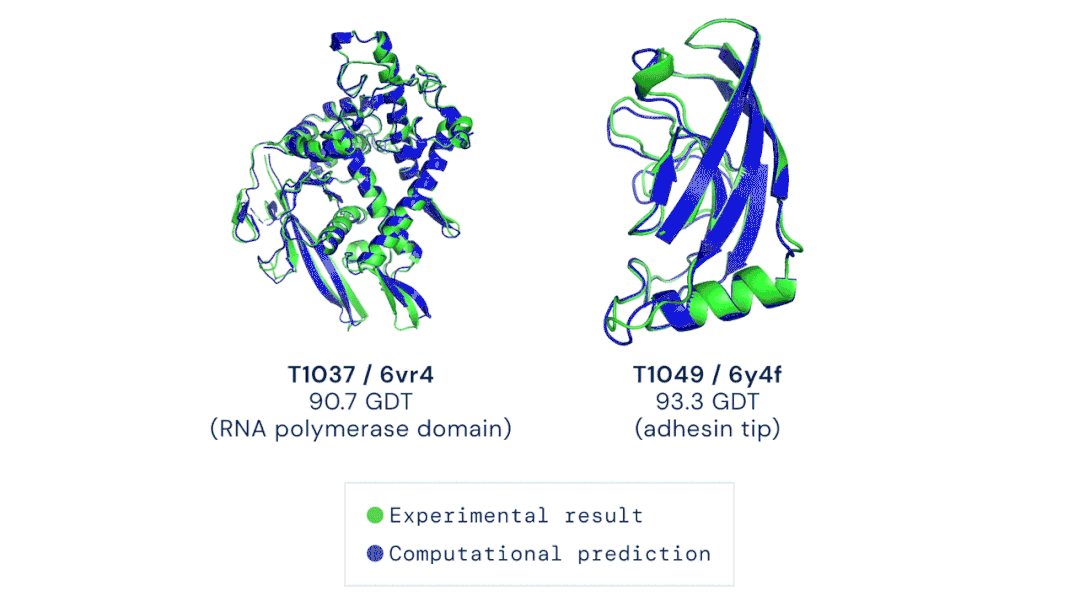
AI在醫(yī)學領域的制度阻礙逐漸減少,為深度學習在醫(yī)療設備和治療中的廣泛應用奠定了基礎。前不久,DeepMind的AlphaFold2 模型在短短幾個小時內(nèi)就確定了蛋白質(zhì)的三維結(jié)構,其對研發(fā)新型藥物的承諾和對生物學的洞察迅速引起了人們的關注。具體而言,是DeepMind的第二代AlphaFold 在國際蛋白質(zhì)結(jié)構預測競賽(CASP)上擊敗了其余的參會選手,能夠精確地基于氨基酸序列,預測蛋白質(zhì)的3D結(jié)構。其準確性可以與使用冷凍電子顯微鏡(CryoEM)、核磁共振或 X 射線晶體學等實驗技術解析的3D結(jié)構相媲美。據(jù)了解,醫(yī)療機構已經(jīng)采取了行動將此類技術納入了主流醫(yī)學實踐中。以下制度上的轉(zhuǎn)變提高了醫(yī)療AI的知名度,也讓它越來越受到認可:1、美國最大的醫(yī)療保險公司已同意向某些使用了機器學習設備的醫(yī)生提供補償。2、美國食品藥品監(jiān)督管理局(FDA)批準了幾種新的基于AI的治療方法和設備,例如心臟超聲檢查系統(tǒng)。3、一個跨學科的國際醫(yī)學專家小組介紹了兩個協(xié)議:Spirit和Consort,該協(xié)議旨在確保基于AI的臨床試驗能夠遵循最佳實踐,同時,便于外部評審人驗證試驗成果并進行報告。我的立場:AI在醫(yī)學中的應用要求醫(yī)生和醫(yī)院重新組織其工作流程,這在一定程度上延緩了AI應用的進度。一旦FDA和醫(yī)療保障制度變得更加明朗,臨床醫(yī)生就會獲得更大的動力去做出改變以適應它們。更多信息:Deeplearning AI醫(yī)療專刊包括深度學習在診斷、預防和治療方面的應用,以及AI醫(yī)學教父Eric Topol的獨家專訪。https://blog.deeplearning.ai/blog/the-batch-ai-for-medicine-special-eric-topols-planetary-health-system-discovering-drugs-diagnosing-heart-disease-predicting-infections-alexa-for-doctors自然語言處理的神經(jīng)網(wǎng)絡規(guī)模越來越大,功能也越來越豐富、有趣。例如GPT-3可以用來寫作畫圖、敲代碼、玩游戲等,被網(wǎng)友們玩出了50多種新用法。GPT-3是OpenAI打造的包含1750億參數(shù)的文本生成器,它展示了自然語言處理方面的持續(xù)進步。同時,它展現(xiàn)了機器學習領域的廣泛趨勢:模型參數(shù)呈指數(shù)增長,無監(jiān)督學習成為主流,且越來越普遍。?? 圖源:Musings about Librarianship1、GPT-3的寫作能力比上一代GPT-2更加強大,以至于用它來撰寫博客文章和Reddit評論時,成功欺騙了很多人類讀者。另外,也有很多人以不同的方式展現(xiàn)了GPT-3的創(chuàng)造性,例如撰寫哲學文章、與歷史人物對話。? ?
圖源:Musings about Librarianship1、GPT-3的寫作能力比上一代GPT-2更加強大,以至于用它來撰寫博客文章和Reddit評論時,成功欺騙了很多人類讀者。另外,也有很多人以不同的方式展現(xiàn)了GPT-3的創(chuàng)造性,例如撰寫哲學文章、與歷史人物對話。? ? 圖注:AI生成的哲學文章2、語言模型促進了商業(yè)工具的發(fā)展,例如幫助Apple自動更正功能區(qū)分不同語言;讓Amazon的語音小助手Alexa能夠跟隨對話內(nèi)容切換;更新機器人律師,對非法稱呼美國公民的電話銷售商提起訴訟。3、OpenAI的GPT-2能夠訓練像素數(shù)據(jù)生成(即iGPT),iGPT通過填充部分模糊的內(nèi)容以生成怪異的圖像。我的立場:語言模型顯然越大越好,但它還不止于此。iGPT預示著在圖像和文字上訓練的模型(至少在OpenAI的工作中),它可能比2020年的大型語言模型更聰明、更怪異。更多信息:NLP特刊包括有關如何消除偏見,以及對NLP先驅(qū)Noam Shazeer的獨家采訪。https://blog.deeplearning.ai/blog/the-batch-nlp-special-issue-powerful-techniques-from-amazon-apple-facebook-google-microsoft-salesforce
圖注:AI生成的哲學文章2、語言模型促進了商業(yè)工具的發(fā)展,例如幫助Apple自動更正功能區(qū)分不同語言;讓Amazon的語音小助手Alexa能夠跟隨對話內(nèi)容切換;更新機器人律師,對非法稱呼美國公民的電話銷售商提起訴訟。3、OpenAI的GPT-2能夠訓練像素數(shù)據(jù)生成(即iGPT),iGPT通過填充部分模糊的內(nèi)容以生成怪異的圖像。我的立場:語言模型顯然越大越好,但它還不止于此。iGPT預示著在圖像和文字上訓練的模型(至少在OpenAI的工作中),它可能比2020年的大型語言模型更聰明、更怪異。更多信息:NLP特刊包括有關如何消除偏見,以及對NLP先驅(qū)Noam Shazeer的獨家采訪。https://blog.deeplearning.ai/blog/the-batch-nlp-special-issue-powerful-techniques-from-amazon-apple-facebook-google-microsoft-salesforce2021年展望
與吳恩達的2020年回顧相呼應,Highland Capital Partners 風險投資家 Rob Toews 對 2021 年 AI 的領域?qū)l(fā)生什么提出了 10 個大膽預測,包含了從學術研究、監(jiān)管等各個領域。其中兩者提到的話題有很多重合的部分,比如Deepfake、GPT-3、AlphaFold等,基于這些事物在今年的關注度,相信讀者也不會感到意外,以下節(jié)選7個供讀者參考。
以下內(nèi)容轉(zhuǎn)載自學術頭條
1、Deepfake 騙局將引發(fā)廣泛的混亂和錯誤信息

Deepfake 技術正在迅速改進和擴散。加蓬和巴西最近發(fā)生的事件,反映出了該技術在政治領域具有的破壞力。2021 年將是 Deepfake 內(nèi)容在美國成為主流的一年,有相當一小部分人最初認為它是真實的。Deepfake 所引起破壞的,很可能就是一個公眾人物發(fā)表具有爭議評論的視頻。
作為回應,一些政策制定者將加大呼吁力度,認為大型科技公司必須負責監(jiān)管 Deepfake 技術在其平臺上的傳播。
2、有關聯(lián)邦學習的學術研究將激增
對于消費者和監(jiān)管機構而言,數(shù)據(jù)隱私的保護正成為一個日益緊迫的問題。因此,保護隱私的 AI 方法將繼續(xù)成為構建機器學習模型的最可持續(xù)的方式。這些方法中最突出的是聯(lián)邦學習(Federated Learning)。
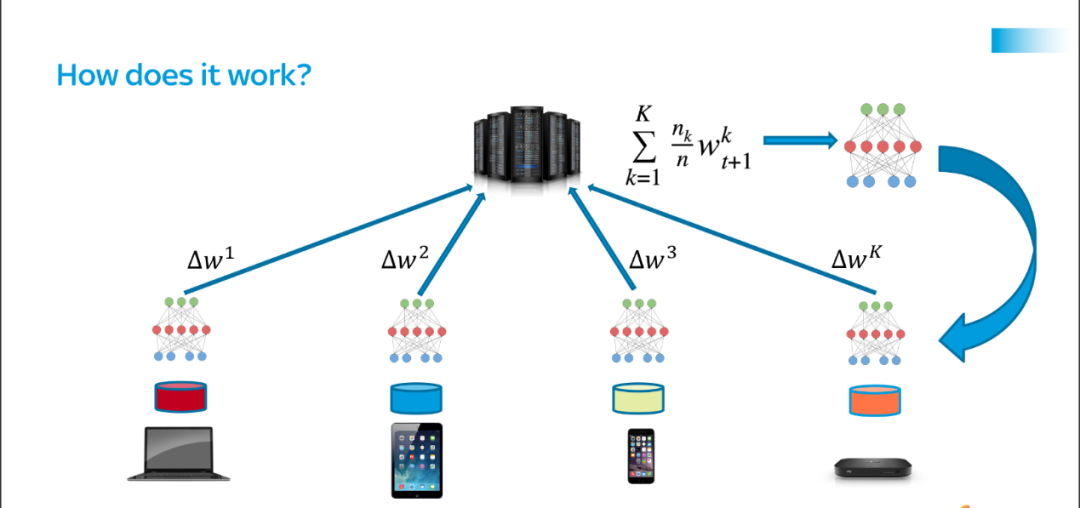 (來源:Proandroidde)
(來源:Proandroidde)
據(jù)谷歌學術(Google Scholar)統(tǒng)計,有關聯(lián)邦學習的學術研究論文數(shù)量已經(jīng)從 2018 年的 254 篇增加到 2019 年的 1340 篇,到 2020 年該領域的論文發(fā)表數(shù)量達到了 3940 篇。這種指數(shù)級的增長將持續(xù)下去:到 2021 年,將發(fā)表超過 10000 篇關于聯(lián)邦學習主題的研究論文。
3、AI 芯片初創(chuàng)公司將被大型半導體公司超高價收購
專為 AI 工作負載而打造的硅基芯片,是半導體行業(yè)的未來。英特爾去年以 20 億美元收購 Habana Labs 就是對這一趨勢的認可。為了防止自身受到干擾,另一家傳統(tǒng)芯片制造商將在 2021 年大舉收購一家 AI 芯片初創(chuàng)公司。
 (來源:Designnews)
(來源:Designnews)
最可能的收購目標:Graphcore、Cerebras、SambaNova
最有可能的收購者:NVIDIA、AMD、Qualcomm、Intel
4、AI 藥物公司將被大型制藥公司以超高價收購
大型制藥公司已經(jīng)意識到這樣一個事實,即機器學習提供了革新藥物發(fā)現(xiàn)和開發(fā)的潛力。2021 年,一家主要的制藥公司將出資收購一家 AI 藥物初創(chuàng)公司,將其技術和人才引入到公司內(nèi)部。
 (來源:Nature)
(來源:Nature)
最可能的收購目標:Recursion、Exscientia、Insitro、Atomwise
最有可能的收購方:Bayer、GlaxoSmithKline、Novartis、Bristol Myers Squibb、Eli Lilly、Gilead
5、GPT-4?參數(shù)將超過一萬億
OpenAI 在 2019 年發(fā)布了 GPT-2,它擁有 15 億個參數(shù),這是第一個具有超過 10 億個參數(shù)的非線性規(guī)劃(NLP)模型。當時,這被認為是驚人的模型。2020 年,OpenAI 在全球發(fā)布了 GPT-3,其參數(shù)高達 1750 億。

第一個參數(shù)超過 1 萬億的模型最有可能來自 OpenAI,并命名為 GPT-4。其他可能突破萬億參數(shù)模型大關的組織包括 Microsoft、NVIDIA、Facebook 和 Google。
隨著第一個參數(shù)超過 1 萬億的模型發(fā)布,模型 “軍備競賽” 將在 2021 年繼續(xù)。
6、AI 將成為監(jiān)管機構反壟斷調(diào)查的重要部分
今年,美國和歐洲的監(jiān)管機構對亞馬遜、蘋果、Facebook 和 Google 正式發(fā)起了反壟斷訴訟。到目前為止,監(jiān)管機構在闡述針對科技巨頭的反壟斷案件時,并沒有明確關注 AI。
 圖 | 多家公司參加反壟斷調(diào)查(來源:Venture Beat)
圖 | 多家公司參加反壟斷調(diào)查(來源:Venture Beat)
在未來的一年里,預計監(jiān)管機構將開始更頻繁地關注、提及 AI,闡述這些公司如何以及為什么不公平地扼殺競爭。核心討論的地方是,這些公司的數(shù)據(jù)壟斷讓它們在開發(fā)有效的機器學習算法方面擁有不可逾越的優(yōu)勢。
7、生物將繼續(xù)是機器學習最熱門、最具變革性的領域
這是這個列表中最不可預測的部分,同時它也是這個列表中最重要的預測。
 圖 | AlphaFold 解決蛋白質(zhì)結(jié)構問題(來源:Edward Kinsman)
圖 | AlphaFold 解決蛋白質(zhì)結(jié)構問題(來源:Edward Kinsman)
無論是在學術研究、創(chuàng)業(yè)投資和主流媒體關注方面,生物學都將日益成為應用人工智能影響最大的領域。DeepMind 上個月的歷史性 AlphaFold 成就,其影響將需要數(shù)年才能完全發(fā)揮出來。而當前這些 AI 在生物領域的成果,僅僅是人類通過將計算方法和機器學習應用于生物學奧秘實現(xiàn)成就的開端。
https://blog.deeplearning.ai/blog/the-batch-biggest-ai-stories-of-2020-covid-triage-fun-with-gans-disinfo-whack-a-mole-gpt-superstar-imagenet-recall-fda-approvals?utm_source=Social&utm_medium=Twitter&utm_campaign=TheBatch_12.23.20https://www.forbes.com/sites/robtoews/2020/12/22/10-ai-predictions-for-2021/
往期精彩:
【原創(chuàng)首發(fā)】機器學習公式推導與代碼實現(xiàn)30講.pdf
【原創(chuàng)首發(fā)】深度學習語義分割理論與實戰(zhàn)指南.pdf
?談中小企業(yè)算法崗面試
?算法工程師研發(fā)技能表
?真正想做算法的,不要害怕內(nèi)卷
?技術學習不能眼高手低
?技術人要學會自我營銷
?做人不能過擬合
求個在看