
我是如何贏得吳恩達(dá)首屆 Data-centric AI 競(jìng)賽的?

大數(shù)據(jù)文摘授權(quán)轉(zhuǎn)載自AI科技評(píng)論
編輯:黃繼彥
校對(duì):林亦霖
大賽概述

我的“數(shù)據(jù)增強(qiáng)”技術(shù)解決方案
在進(jìn)入解決方案的關(guān)鍵部分之前,我做的第一件事是遵循固定標(biāo)簽和刪除不良數(shù)據(jù)的常見(jiàn)做法。
我的“數(shù)據(jù)增強(qiáng)”技術(shù)解決方案

從訓(xùn)練數(shù)據(jù)中生成一組非常大的隨機(jī)增強(qiáng)圖像(將這些視為“候選”來(lái)源)。 訓(xùn)練初始模型并預(yù)測(cè)驗(yàn)證集。 使用另一個(gè)預(yù)訓(xùn)練模型從驗(yàn)證圖像和增強(qiáng)圖像中提取特征(即嵌入)。 對(duì)于每個(gè)錯(cuò)誤分類的驗(yàn)證圖像,利用提取的特征從增強(qiáng)圖像集中檢索最近鄰(基于余弦相似度)。將這些最近鄰增強(qiáng)圖像添加到訓(xùn)練集。我將這個(gè)過(guò)程稱為“數(shù)據(jù)增強(qiáng)”。 使用添加的增強(qiáng)圖像重新訓(xùn)練模型并預(yù)測(cè)驗(yàn)證集。 重復(fù)步驟 4-6,直到達(dá)到 10K 圖像的限制。
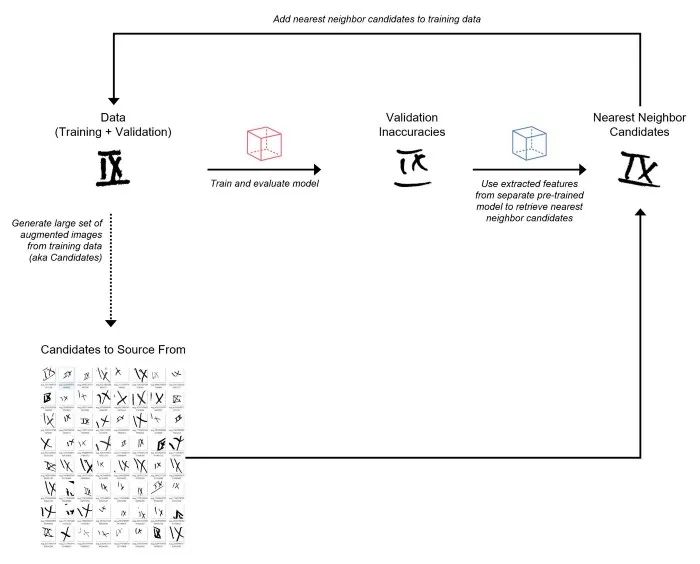
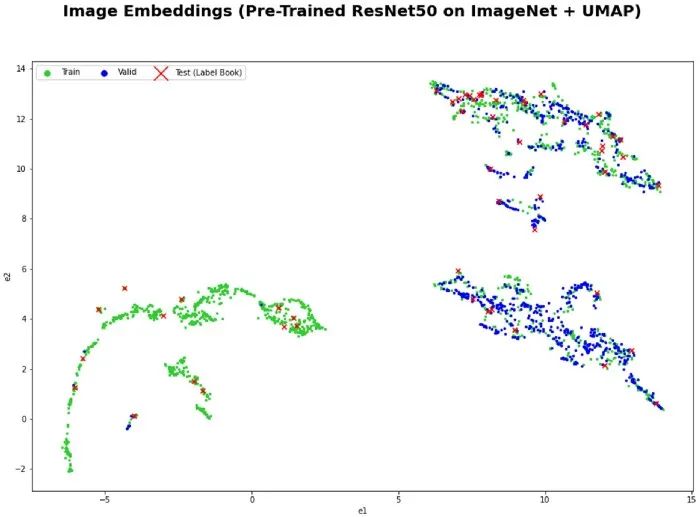
雖然我在這次競(jìng)賽中使用了增強(qiáng)圖像,但在實(shí)踐中我們可以使用任何大的圖像集作為數(shù)據(jù)源。 我從訓(xùn)練集中生成了大約 1M 的隨機(jī)增強(qiáng)圖像作為候選來(lái)源。 數(shù)據(jù)評(píng)估電子表格用于跟蹤不準(zhǔn)確(錯(cuò)誤分類的圖像)并注釋數(shù)據(jù)。另外,我還創(chuàng)建了一個(gè)帶有PostgreSQL 后端的 Label Studio 實(shí)例,但由于不必要的開(kāi)銷,我決定不將其用于本次比賽。 對(duì)于預(yù)訓(xùn)練模型,我使用了在 ImageNet 上訓(xùn)練的 ResNet50。 我使用 Annoy 包來(lái)執(zhí)行近似最近鄰搜索。 每個(gè)錯(cuò)誤分類的驗(yàn)證圖像要檢索的最近鄰的數(shù)量是一個(gè)超參數(shù)。
這項(xiàng)技術(shù)的動(dòng)機(jī)以及如何將它推廣到不同的應(yīng)用
我在原先的作品(見(jiàn) 2019 年的一篇博文)里構(gòu)建了一個(gè)電影推薦系統(tǒng),這個(gè)系統(tǒng)通過(guò)從關(guān)鍵字標(biāo)簽中提取電影嵌入并使用余弦相似度來(lái)查找彼此相似的電影。 我之前使用過(guò)預(yù)訓(xùn)練的深度學(xué)習(xí)模型將圖像表示為嵌入。 在 Andrej Karpathy 2019 年的演講中,他描述了如何有效地獲取和標(biāo)記從特斯拉車隊(duì)收集的大量數(shù)據(jù),以解決通常是邊緣情況(分布的長(zhǎng)尾)的不準(zhǔn)確問(wèn)題。 我想開(kāi)發(fā)一種以數(shù)據(jù)為中心的增強(qiáng)算法(類似于梯度增強(qiáng)),其中模型預(yù)測(cè)中的不準(zhǔn)確之處在每個(gè)步驟中通過(guò)自動(dòng)獲取與那些不準(zhǔn)確之處相似的數(shù)據(jù)來(lái)迭代解決。這就是我稱這種方法為“數(shù)據(jù)提升”的原因。

為實(shí)體(例如圖像、文本文檔)提取嵌入的預(yù)訓(xùn)練模型; 可供選擇的大量候選數(shù)據(jù)集(例如特斯拉車隊(duì)、網(wǎng)絡(luò)上大量的文本語(yǔ)料庫(kù)、合成數(shù)據(jù))。
結(jié)語(yǔ)

評(píng)論
圖片
表情