
【小白學(xué)PyTorch】13.EfficientNet詳解及PyTorch實(shí)現(xiàn)
小白學(xué)PyTorch | 12 SENet詳解及PyTorch實(shí)現(xiàn)
小白學(xué)PyTorch | 11 MobileNet詳解及PyTorch實(shí)現(xiàn)
小白學(xué)PyTorch | 10 pytorch常見(jiàn)運(yùn)算詳解
小白學(xué)PyTorch | 9 tensor數(shù)據(jù)結(jié)構(gòu)與存儲(chǔ)結(jié)構(gòu)
小白學(xué)PyTorch | 8 實(shí)戰(zhàn)之MNIST小試牛刀
小白學(xué)PyTorch | 7 最新版本torchvision.transforms常用API翻譯與講解
小白學(xué)PyTorch | 6 模型的構(gòu)建訪問(wèn)遍歷存儲(chǔ)(附代碼)
小白學(xué)PyTorch | 5 torchvision預(yù)訓(xùn)練模型與數(shù)據(jù)集全覽
小白學(xué)PyTorch | 4 構(gòu)建模型三要素與權(quán)重初始化
小白學(xué)PyTorch | 3 淺談Dataset和Dataloader
小白學(xué)PyTorch | 2 淺談?dòng)?xùn)練集驗(yàn)證集和測(cè)試集
小白學(xué)PyTorch | 1 搭建一個(gè)超簡(jiǎn)單的網(wǎng)絡(luò)
小白學(xué)PyTorch | 動(dòng)態(tài)圖與靜態(tài)圖的淺顯理解
參考目錄:
1 EfficientNet
1.1 概述
1.2 把擴(kuò)展問(wèn)題用數(shù)學(xué)來(lái)描述
1.3 實(shí)驗(yàn)內(nèi)容
1.4 compound scaling method
1.5 EfficientNet的基線模型
2 PyTorch實(shí)現(xiàn)
efficientNet的論文原文鏈接: https://arxiv.org/pdf/1905.11946.pdf
模型擴(kuò)展Model scaling一直以來(lái)都是提高卷積神經(jīng)網(wǎng)絡(luò)效果的重要方法。比如說(shuō),ResNet可以增加層數(shù)從ResNet18擴(kuò)展到ResNet200。這次,我們要介紹的是最新的網(wǎng)絡(luò)結(jié)構(gòu)——EfficientNet,就是一種標(biāo)準(zhǔn)化的模型擴(kuò)展結(jié)果,通過(guò)下面的圖,我們可以i只管的體會(huì)到EfficientNet b0-b7在ImageNet上的效果:對(duì)于ImageNet歷史上的各種網(wǎng)絡(luò)而言,可以說(shuō)EfficientNet在效果上實(shí)現(xiàn)了碾壓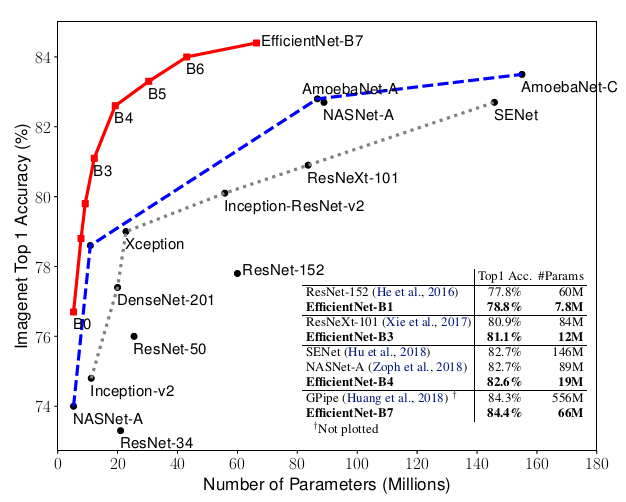
1 EfficientNet
1.1 概述
一般我們?cè)跀U(kuò)展網(wǎng)絡(luò)的時(shí)候,一般通過(guò)調(diào)成輸入圖像的大小、網(wǎng)絡(luò)的深度和寬度(卷積通道數(shù),也就是channel數(shù))。在EfficientNet之前,沒(méi)有研究工作只是針對(duì)這三個(gè)維度中的某一個(gè)維度進(jìn)行調(diào)整,因?yàn)?strong style="color: orangered;">沒(méi)錢啊!!有限的計(jì)算能力,很少有研究對(duì)這三個(gè)維度進(jìn)行綜合調(diào)整的。
EfficientNet的設(shè)想就是能否設(shè)計(jì)一個(gè)標(biāo)準(zhǔn)化的卷積網(wǎng)絡(luò)擴(kuò)展方法,既可以實(shí)現(xiàn)較高的準(zhǔn)確率,又可以充分的節(jié)省算力資源。因而問(wèn)題可以描述成,如何平衡分辨率、深度和寬度這三個(gè)維度,來(lái)實(shí)現(xiàn)拘拿及網(wǎng)絡(luò)在效率和準(zhǔn)確率上的優(yōu)化
EfficientNet給出的解決方案是提出了這個(gè)模型復(fù)合縮放方法 (compound scaling methed)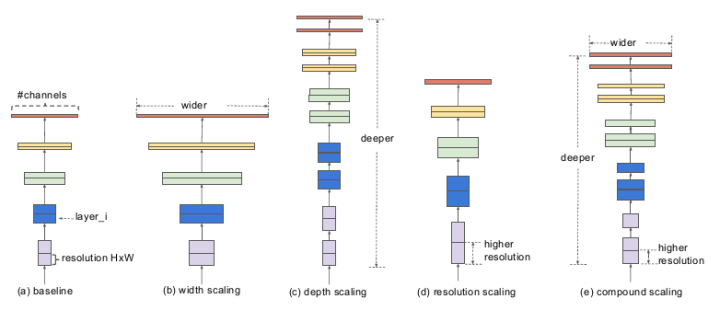 圖a是一個(gè)基線網(wǎng)絡(luò),也就是我們所說(shuō)的baseline,圖b,c,d三個(gè)網(wǎng)絡(luò)分別對(duì)該基線網(wǎng)絡(luò)的寬度、深度、和輸入分辨率進(jìn)行了擴(kuò)展,而最右邊的e圖,就是EfficientNet的主要思想,綜合寬度、深度和分辨率對(duì)網(wǎng)絡(luò)進(jìn)行符合擴(kuò)展。
圖a是一個(gè)基線網(wǎng)絡(luò),也就是我們所說(shuō)的baseline,圖b,c,d三個(gè)網(wǎng)絡(luò)分別對(duì)該基線網(wǎng)絡(luò)的寬度、深度、和輸入分辨率進(jìn)行了擴(kuò)展,而最右邊的e圖,就是EfficientNet的主要思想,綜合寬度、深度和分辨率對(duì)網(wǎng)絡(luò)進(jìn)行符合擴(kuò)展。
1.2 把擴(kuò)展問(wèn)題用數(shù)學(xué)來(lái)描述
首先,我們把整個(gè)卷積網(wǎng)絡(luò)稱為N,他的第i個(gè)卷積層可以看作下面的函數(shù)映射: Yi是輸出張量,Xi是輸入張量,假設(shè)這個(gè)Xi的維度是
Yi是輸出張量,Xi是輸入張量,假設(shè)這個(gè)Xi的維度是 通常情況,一個(gè)神經(jīng)網(wǎng)絡(luò)會(huì)有多個(gè)相同的卷積層存在,因此,我們稱多個(gè)結(jié)構(gòu)相同的卷積層為一個(gè)stage。舉個(gè)例子:ResNet可以分為5個(gè)stage,每一個(gè)stage中的卷積層結(jié)構(gòu)相同(除了第一層為降采樣層),前四個(gè)stage都是baseblock,第五個(gè)stage是fc層。不太理解的可以看這個(gè):【從零學(xué)習(xí)PyTorch】 如何殘差網(wǎng)絡(luò)resnet作為pre-model +代碼講解+殘差網(wǎng)絡(luò)resnet是個(gè)啥
通常情況,一個(gè)神經(jīng)網(wǎng)絡(luò)會(huì)有多個(gè)相同的卷積層存在,因此,我們稱多個(gè)結(jié)構(gòu)相同的卷積層為一個(gè)stage。舉個(gè)例子:ResNet可以分為5個(gè)stage,每一個(gè)stage中的卷積層結(jié)構(gòu)相同(除了第一層為降采樣層),前四個(gè)stage都是baseblock,第五個(gè)stage是fc層。不太理解的可以看這個(gè):【從零學(xué)習(xí)PyTorch】 如何殘差網(wǎng)絡(luò)resnet作為pre-model +代碼講解+殘差網(wǎng)絡(luò)resnet是個(gè)啥
總之,我們以stage為單位,將上面的卷積網(wǎng)絡(luò)N改成為: 其中,下表1...s表示stage的訊號(hào),F(xiàn)i表示對(duì)第i層的卷積運(yùn)算,Li的意思是Fi在第i個(gè)stage中有Li個(gè)一樣結(jié)構(gòu)的卷積層。
其中,下表1...s表示stage的訊號(hào),F(xiàn)i表示對(duì)第i層的卷積運(yùn)算,Li的意思是Fi在第i個(gè)stage中有Li個(gè)一樣結(jié)構(gòu)的卷積層。
Li就是深度,Li越大重復(fù)的卷積層越多,網(wǎng)絡(luò)越深; Ci就是channel數(shù)目,也就是網(wǎng)絡(luò)的寬度 Hi和Wi就是圖片的分辨率 就算如此,這也有三個(gè)參數(shù)要調(diào)整,搜索空間也是非常的大,因此EfficientNet的設(shè)想是一個(gè)卷積網(wǎng)絡(luò)所有的卷積層必須通過(guò)相同的比例常數(shù)進(jìn)行統(tǒng)一擴(kuò)展,這句話的意思是,三個(gè)參數(shù)乘上常熟倍率。所以個(gè)一個(gè)模型的擴(kuò)展問(wèn)題,就用數(shù)學(xué)語(yǔ)言描述為:  其中,d、w和r分別表示網(wǎng)絡(luò)深度、寬度和分辨率的倍率。這個(gè)算式表現(xiàn)為在給定計(jì)算內(nèi)存和效率的約束下,如何優(yōu)化參數(shù)d、w和r來(lái)實(shí)現(xiàn)最好的模型準(zhǔn)確率。
其中,d、w和r分別表示網(wǎng)絡(luò)深度、寬度和分辨率的倍率。這個(gè)算式表現(xiàn)為在給定計(jì)算內(nèi)存和效率的約束下,如何優(yōu)化參數(shù)d、w和r來(lái)實(shí)現(xiàn)最好的模型準(zhǔn)確率。
1.3 實(shí)驗(yàn)內(nèi)容
上面問(wèn)題的難點(diǎn)在于,三個(gè)倍率之間是由內(nèi)在聯(lián)系的,比如更高分辨率的圖片就需要更深的網(wǎng)絡(luò)來(lái)增大感受野的捕捉特征。因此作者做了兩個(gè)實(shí)驗(yàn)(實(shí)際應(yīng)該是做了很多的實(shí)驗(yàn))來(lái)說(shuō)明:(1) 第一個(gè)實(shí)驗(yàn),對(duì)三個(gè)維度固定了兩個(gè),只方法其中一個(gè),得到的結(jié)果如下: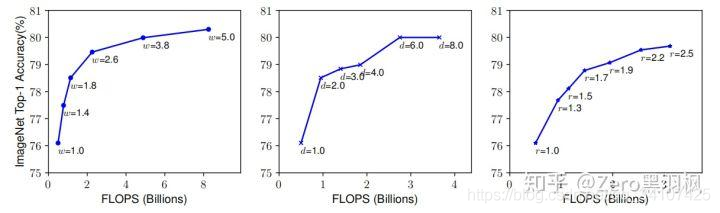 從左到右分別是只放大了網(wǎng)絡(luò)寬度(width,w為放大倍率)、網(wǎng)絡(luò)深度(depth,d為放大倍率)和圖像分辨率(resolution, r為放大倍率)。我們可以看到,單個(gè)維度的放大最高精度只有80左右,本次實(shí)驗(yàn),作者得出一個(gè)管帶你:三個(gè)維度中任一維度的放大都可以帶來(lái)精度的提升,但是隨著倍率的越來(lái)越大,提升越來(lái)越小。(2)于是作者做了第二個(gè)實(shí)驗(yàn),嘗試在不同的d,r組合下變動(dòng)w,得到下圖:
從左到右分別是只放大了網(wǎng)絡(luò)寬度(width,w為放大倍率)、網(wǎng)絡(luò)深度(depth,d為放大倍率)和圖像分辨率(resolution, r為放大倍率)。我們可以看到,單個(gè)維度的放大最高精度只有80左右,本次實(shí)驗(yàn),作者得出一個(gè)管帶你:三個(gè)維度中任一維度的放大都可以帶來(lái)精度的提升,但是隨著倍率的越來(lái)越大,提升越來(lái)越小。(2)于是作者做了第二個(gè)實(shí)驗(yàn),嘗試在不同的d,r組合下變動(dòng)w,得到下圖: 從實(shí)驗(yàn)結(jié)果來(lái)看,最高精度相比之前已經(jīng)有所提升,突破了80大關(guān)。而且組合不同,效果不同。作者又得到了一個(gè)觀點(diǎn):得到了更高的精度以及效率的關(guān)鍵是平衡網(wǎng)絡(luò)的寬度,網(wǎng)絡(luò)深度,網(wǎng)絡(luò)分辨率三個(gè)維度的縮放倍率
從實(shí)驗(yàn)結(jié)果來(lái)看,最高精度相比之前已經(jīng)有所提升,突破了80大關(guān)。而且組合不同,效果不同。作者又得到了一個(gè)觀點(diǎn):得到了更高的精度以及效率的關(guān)鍵是平衡網(wǎng)絡(luò)的寬度,網(wǎng)絡(luò)深度,網(wǎng)絡(luò)分辨率三個(gè)維度的縮放倍率
1.4 compound scaling method
這時(shí)候作者提出了這個(gè)方法
EfficientNet的規(guī)范化復(fù)合調(diào)參方法使用了一個(gè)復(fù)合系數(shù),來(lái)對(duì)三個(gè)參數(shù)進(jìn)行符合調(diào)整: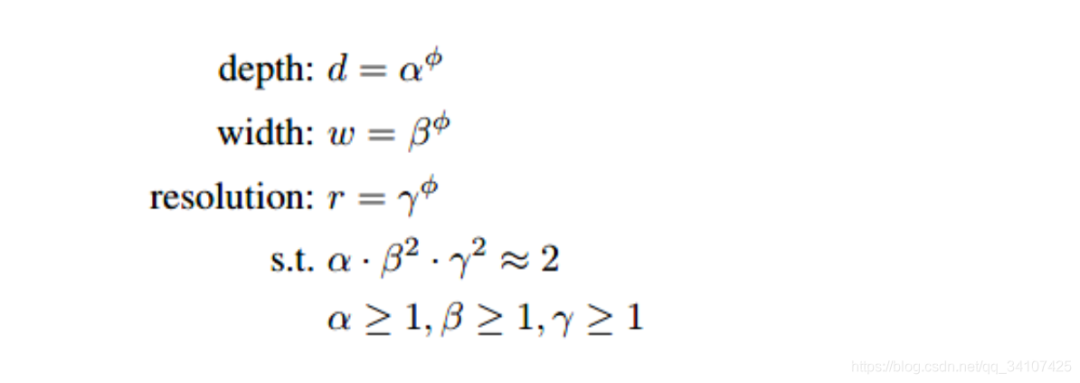 其中的都是常數(shù),可以通過(guò)網(wǎng)格搜索獲得。復(fù)合系數(shù)通過(guò)人工調(diào)節(jié)。考慮到如果網(wǎng)絡(luò)深度翻番那么對(duì)應(yīng)的計(jì)算量翻番,網(wǎng)絡(luò)寬度和圖像分辨率翻番對(duì)應(yīng)的計(jì)算量會(huì)翻4番,卷積操作的計(jì)算量與成正比,。在這個(gè)約束下,網(wǎng)絡(luò)的計(jì)算量大約是之前的倍
其中的都是常數(shù),可以通過(guò)網(wǎng)格搜索獲得。復(fù)合系數(shù)通過(guò)人工調(diào)節(jié)。考慮到如果網(wǎng)絡(luò)深度翻番那么對(duì)應(yīng)的計(jì)算量翻番,網(wǎng)絡(luò)寬度和圖像分辨率翻番對(duì)應(yīng)的計(jì)算量會(huì)翻4番,卷積操作的計(jì)算量與成正比,。在這個(gè)約束下,網(wǎng)絡(luò)的計(jì)算量大約是之前的倍
以上就是EfficientNet的復(fù)合擴(kuò)展的方式,但是這僅僅是一種模型擴(kuò)展方式,我們還沒(méi)有講到EfficientNet到底是一個(gè)什么樣的網(wǎng)絡(luò)。
1.5 EfficientNet的基線模型
EfficientNet使用了MobileNet V2中的MBCConv作為模型的主干網(wǎng)絡(luò),同時(shí)也是用了SENet中的squeeze and excitation方法對(duì)網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行了優(yōu)化。 MBCConv是mobileNet中的基本結(jié)構(gòu),關(guān)于什么是MBCconv在百度上很少有解釋,通過(guò)閱讀論文和Google這里有一個(gè)比較好的解釋:
The MBConv block is nothing fancy but an Inverted Residual Block (used in MobileNetV2) with a Squeeze and Excite block injected sometimes.
MBCconv就是一個(gè)MobileNet的倒殘差模塊,但是這個(gè)模塊中還封裝了Squeeze and Excite的方法。
總之呢,綜合了MBConv和squeeze and excitation方法的EfficientNet-B0的網(wǎng)絡(luò)結(jié)構(gòu)如下表所示: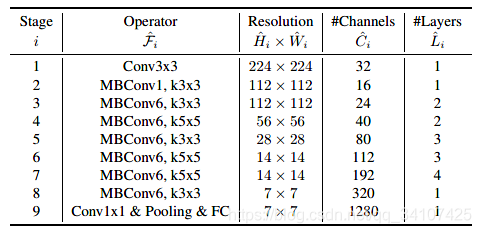 對(duì)于EfficientNet-B0這樣的一個(gè)基線網(wǎng)絡(luò),如何使用復(fù)合擴(kuò)展發(fā)對(duì)該網(wǎng)絡(luò)進(jìn)行擴(kuò)展呢?這里主要是分兩步走:還記得這個(gè)規(guī)劃問(wèn)題嗎?(1)第一步,先將復(fù)合系數(shù)固定為1,先假設(shè)有兩倍以上的計(jì)算資源可以用,然后對(duì)進(jìn)行網(wǎng)絡(luò)搜索。對(duì)于EfficientNet-B0網(wǎng)絡(luò),在約束條件為
對(duì)于EfficientNet-B0這樣的一個(gè)基線網(wǎng)絡(luò),如何使用復(fù)合擴(kuò)展發(fā)對(duì)該網(wǎng)絡(luò)進(jìn)行擴(kuò)展呢?這里主要是分兩步走:還記得這個(gè)規(guī)劃問(wèn)題嗎?(1)第一步,先將復(fù)合系數(shù)固定為1,先假設(shè)有兩倍以上的計(jì)算資源可以用,然后對(duì)進(jìn)行網(wǎng)絡(luò)搜索。對(duì)于EfficientNet-B0網(wǎng)絡(luò),在約束條件為
時(shí),分別取1.2,1.1和1.15時(shí)效果最佳。第二步是固定,通過(guò)復(fù)合調(diào)整公式對(duì)基線網(wǎng)絡(luò)進(jìn)行擴(kuò)展,得到B1到B7網(wǎng)絡(luò)。于是就有了開頭的這一張圖片,EfficientNet在ImageNet上的效果碾壓,而且模型規(guī)模比此前的GPipe小了8.4倍。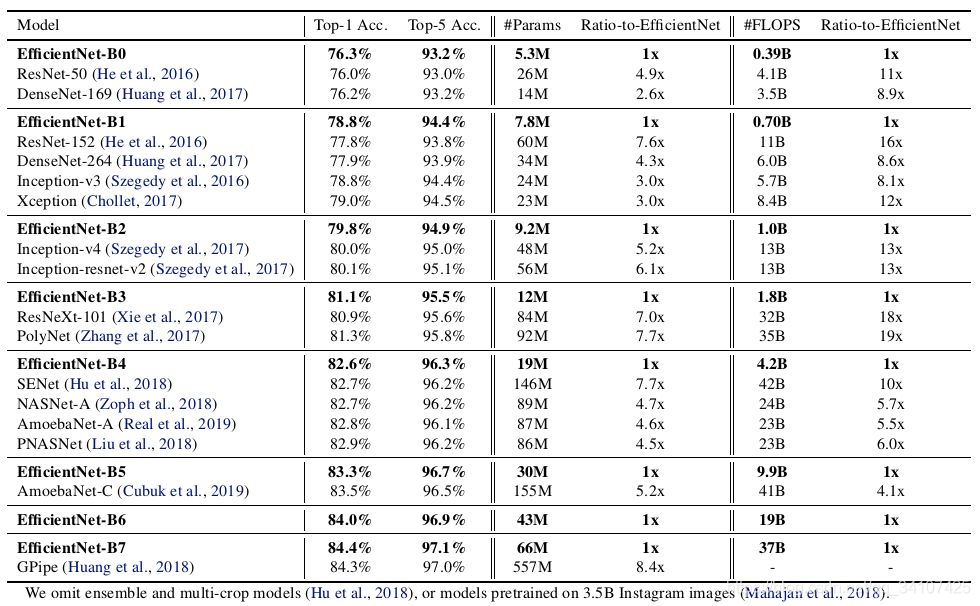
普通人來(lái)訓(xùn)練和擴(kuò)展EfficientNet實(shí)在過(guò)于昂貴,所以對(duì)于我們來(lái)說(shuō),最好的方法就是遷移學(xué)習(xí),下面我們來(lái)看如何用PyTorch來(lái)做遷移學(xué)習(xí)。
2 PyTorch實(shí)現(xiàn)
之前也提到了,在torchvision中并沒(méi)有加入efficientNet所以這里我們使用某一位大佬貢獻(xiàn)的API。有一個(gè)這樣的文件Efficient_PyTorch,里面存放了b0到b8的預(yù)訓(xùn)練模型存儲(chǔ)文件,我們將會(huì)調(diào)用這個(gè)API。因?yàn)檫@里我們沒(méi)有直接使用pip進(jìn)行安裝,所以需要將這個(gè)庫(kù)函數(shù)設(shè)置成系統(tǒng)路徑。Pycharm中很多朋友會(huì)踩著個(gè)坑,不知道如何設(shè)置成系統(tǒng)路徑: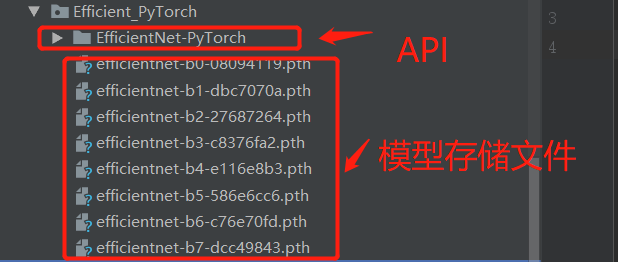
 點(diǎn)擊Sources Root之后,就可以直接import了。
點(diǎn)擊Sources Root之后,就可以直接import了。
整個(gè)代碼非常少,因?yàn)槎紝懗葾PI接口了嘛:
from?efficientnet_pytorch?import?EfficientNet
model?=?EfficientNet.from_name('efficientnet-b0')
print(model)
打印的模型可以看,我加了詳細(xì)的注解(快夸我):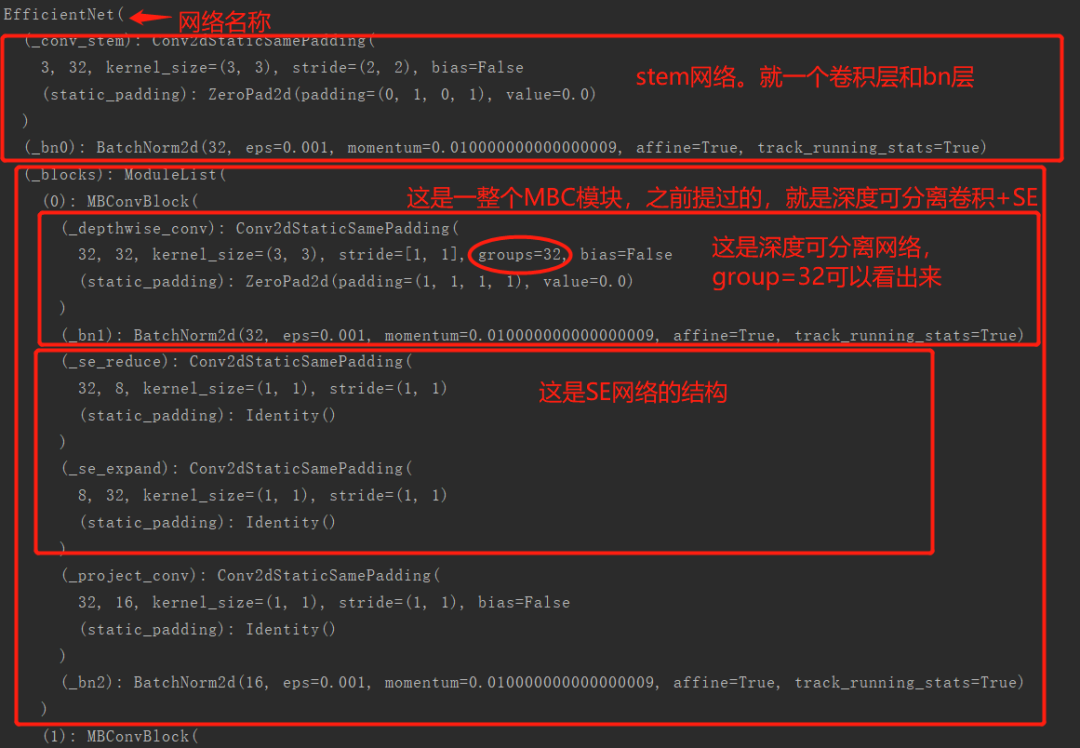
整個(gè)b0的結(jié)構(gòu)和論文中的結(jié)構(gòu)相同:從上圖中可以知道,總共有16個(gè)MBConv模塊;在第16個(gè)時(shí)候的輸出通道為320個(gè)通道; 從運(yùn)行結(jié)果來(lái)看,結(jié)構(gòu)相同。總之這就是EfficientNet的結(jié)構(gòu),原理和調(diào)用方式。
從運(yùn)行結(jié)果來(lái)看,結(jié)構(gòu)相同。總之這就是EfficientNet的結(jié)構(gòu),原理和調(diào)用方式。
往期精彩回顧
獲取一折本站知識(shí)星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/662nyZF
本站qq群704220115。
加入微信群請(qǐng)掃碼進(jìn)群(如果是博士或者準(zhǔn)備讀博士請(qǐng)說(shuō)明):