
Pytorch轉(zhuǎn)onnx詳解
導(dǎo)讀
?本文作者總結(jié)了自己參與Pytorch到ONNX的模型轉(zhuǎn)換轉(zhuǎn)換工作中的經(jīng)驗(yàn),主要介紹了該轉(zhuǎn)換工作的意義,模型部署的路徑以及Pytorch本身的局限。
之前幾個(gè)月參與了OpenMMlab的模型轉(zhuǎn)ONNX的工作(github account: drcut),主要目標(biāo)是支持OpenMMLab的一些模型從Pytorch到ONNX的轉(zhuǎn)換。這幾個(gè)月雖然沒(méi)做出什么成果,但是踩了很多坑,在這里記錄下來(lái),希望可以幫助其他人。
這篇是第一部分,理論篇,主要介紹了和代碼無(wú)關(guān)的一些宏觀問(wèn)題。再接下來(lái)我會(huì)專門(mén)寫(xiě)一篇實(shí)戰(zhàn)篇,針對(duì)OpenMMlab中一些具體代碼做分析,說(shuō)明Pytorch轉(zhuǎn)化ONNX過(guò)程中的一些代碼上的技巧和注意事項(xiàng)。
(1)Pytorch轉(zhuǎn)ONNX的意義
一般來(lái)說(shuō)轉(zhuǎn)ONNX只是一個(gè)手段,在之后得到ONNX模型后還需要再將它做轉(zhuǎn)換,比如轉(zhuǎn)換到TensorRT上完成部署,或者有的人多加一步,從ONNX先轉(zhuǎn)換到caffe,再?gòu)腸affe到tensorRT。原因是Caffe對(duì)tensorRT更為友好,這里關(guān)于友好的定義后面會(huì)談。
因此在轉(zhuǎn)ONNX工作開(kāi)展之前,首先必須明確目標(biāo)后端。ONNX只是一個(gè)格式,就和json一樣。只要你滿足一定的規(guī)則,都算是合法的,因此單純從Pytorch轉(zhuǎn)成一個(gè)ONNX文件很簡(jiǎn)單。但是不同后端設(shè)備接受的onnx是不一樣的,因此這才是坑的來(lái)源。
Pytorch自帶的torch.onnx.export轉(zhuǎn)換得到的ONNX,ONNXRuntime需要的ONNX,TensorRT需要的ONNX都是不同的。
這里面舉一個(gè)最簡(jiǎn)單的Maxpool的例:
Maxunpool可以被看作Maxpool的逆運(yùn)算,咱們先來(lái)看一個(gè)Maxpool的例子,假設(shè)有如下一個(gè)C*H*W的tensor(shape[2, 3, 3]),其中每個(gè)channel的二維矩陣都是一樣的,如下所示
 ?
?
在這種情況下,如果我們?cè)赑ytorch對(duì)它調(diào)用MaxPool(kernel_size=2, stride=1,pad=0)
那么會(huì)得到兩個(gè)輸出,第一個(gè)輸出是Maxpool之后的值:
 ?
?
另一個(gè)是Maxpool的Idx,即每個(gè)輸出對(duì)應(yīng)原來(lái)的哪個(gè)輸入,這樣做反向傳播的時(shí)候就可以直接把輸出的梯度傳給對(duì)應(yīng)的輸入:
 ?
?
細(xì)心的同學(xué)會(huì)發(fā)現(xiàn)其實(shí)Maxpool的Idx還可以有另一種寫(xiě)法:
? ?,
?,
即每個(gè)channel的idx放到一起,并不是每個(gè)channel單獨(dú)從0開(kāi)始。這兩種寫(xiě)法都沒(méi)什么問(wèn)題,畢竟只要反向傳播的時(shí)候一致就可以。
但是當(dāng)我在支持OpenMMEditing的時(shí)候,會(huì)涉及到Maxunpool,即Maxpool的逆運(yùn)算:輸入MaxpoolId和Maxpool的輸出,得到Maxpool的輸入。
Pytorch的MaxUnpool實(shí)現(xiàn)是接收每個(gè)channel都從0開(kāi)始的Idx格式,而Onnxruntime則相反。因此如果你希望用Onnxruntime跑一樣的結(jié)果,那么必須對(duì)輸入的Idx(即和Pytorch一樣的輸入)做額外的處理才可以。換言之,Pytorch轉(zhuǎn)出來(lái)的神經(jīng)網(wǎng)絡(luò)圖和ONNXRuntime需要的神經(jīng)網(wǎng)絡(luò)圖是不一樣的。
(2)ONNX與Caffe
主流的模型部署有兩種路徑,以TensorRT為例,一種是Pytorch->ONNX->TensorRT,另一種是Pytorch->Caffe->TensorRT。個(gè)人認(rèn)為目前后者更為成熟,這主要是ONNX,Caffe和TensorRT的性質(zhì)共同決定的
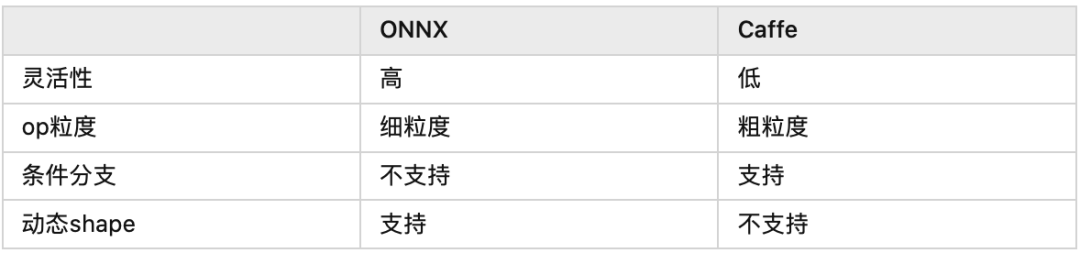
上面的表列了ONNX和Caffe的幾點(diǎn)區(qū)別,其中最重要的區(qū)別就是op的粒度。舉個(gè)例子,如果對(duì)Bert的Attention層做轉(zhuǎn)換,ONNX會(huì)把它變成MatMul,Scale,SoftMax的組合,而Caffe可能會(huì)直接生成一個(gè)叫做Multi-Head Attention的層,同時(shí)告訴CUDA工程師:“你去給我寫(xiě)一個(gè)大kernel“(很懷疑發(fā)展到最后會(huì)不會(huì)把ResNet50都變成一個(gè)層。。。)

tensor i = funcA();
if(i==0)
j = funcB(i);
else
j = funcC(i);
funcD(j);
tensor i = funcA();
coarse_func(tensor i) {
if(i==0) return funcB(i);
else return funcC(i);
}
funcD(coarse_func(i))
往期精彩:
【原創(chuàng)首發(fā)】機(jī)器學(xué)習(xí)公式推導(dǎo)與代碼實(shí)現(xiàn)30講.pdf
【原創(chuàng)首發(fā)】深度學(xué)習(xí)語(yǔ)義分割理論與實(shí)戰(zhàn)指南.pdf
?技術(shù)人要學(xué)會(huì)自我營(yíng)銷