
新聞推薦實(shí)戰(zhàn)(四):scrapy爬蟲框架基礎(chǔ)
新聞推薦實(shí)戰(zhàn)(三):Redis基礎(chǔ)
新聞推薦實(shí)戰(zhàn)(二):MongoDB基礎(chǔ)
新聞推薦實(shí)戰(zhàn)(一):MySQL基礎(chǔ)
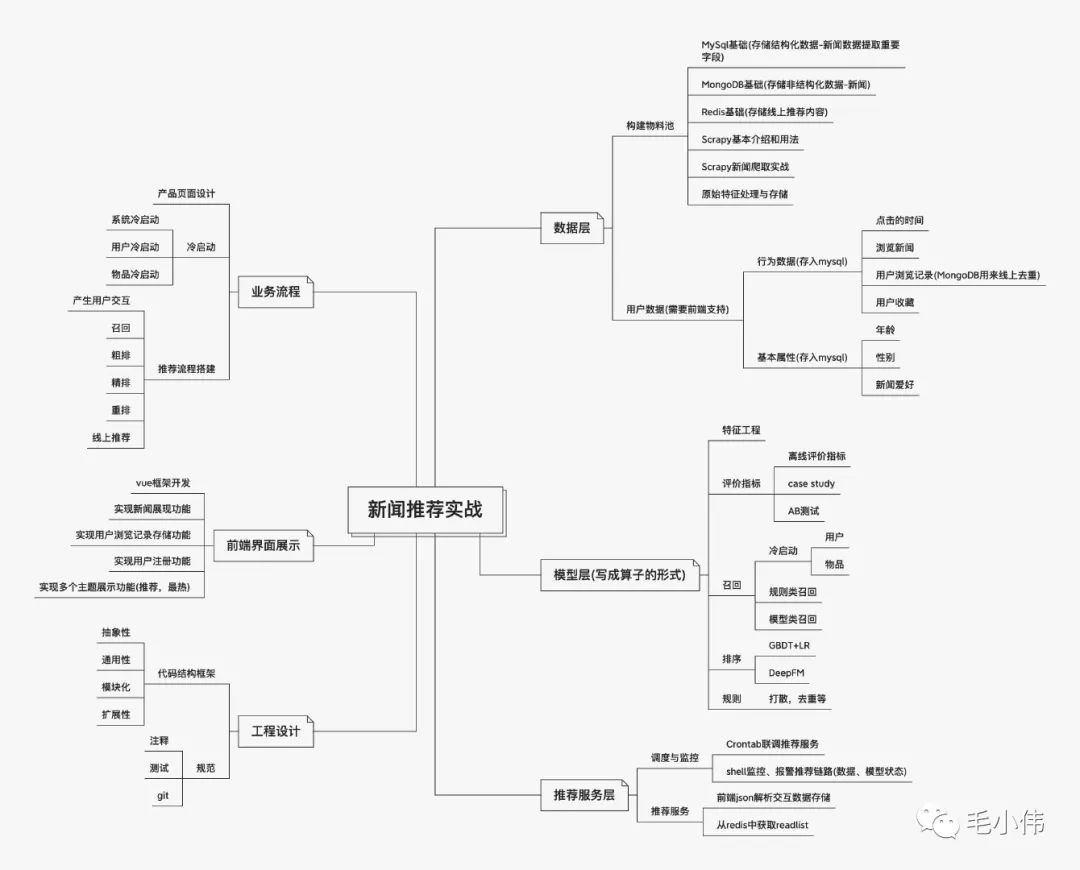
本文屬于新聞推薦實(shí)戰(zhàn)-數(shù)據(jù)層-構(gòu)建物料池之scrapy爬蟲框架基礎(chǔ)。對(duì)于開源的推薦系統(tǒng)來說數(shù)據(jù)的不斷獲取是非常重要的,scrapy是一個(gè)非常易用且強(qiáng)大的爬蟲框架,有固定的文件結(jié)構(gòu)、類和方法,在實(shí)際使用過程中我們只需要按照要求實(shí)現(xiàn)相應(yīng)的類方法,就可以完成我們的爬蟲任務(wù)。文中給出了新聞推薦系統(tǒng)中新聞爬取的實(shí)戰(zhàn)代碼,希望讀者可以快速掌握scrapy的基本使用方法,并能夠舉一反三。
Scrapy基礎(chǔ)及新聞爬取實(shí)戰(zhàn)
python環(huán)境的安裝
Scrapy的簡(jiǎn)介與安裝
參考資料
Scrapy基礎(chǔ)及新聞爬取實(shí)戰(zhàn)
python環(huán)境的安裝
python 環(huán)境,使用miniconda搭建,安裝miniconda的參考鏈接:https://blog.csdn.net/pdcfighting/article/details/111503057。
在安裝完miniconda之后,創(chuàng)建一個(gè)新聞推薦的虛擬環(huán)境,我這邊將其命名為news_rec_py3,這個(gè)環(huán)境將會(huì)在整個(gè)新聞推薦項(xiàng)目中使用。
conda?create?-n?news_rec_py3?python==3.8
Scrapy的簡(jiǎn)介與安裝
Scrapy 是一種快速的高級(jí) web crawling 和 web scraping 框架,用于對(duì)網(wǎng)站內(nèi)容進(jìn)行爬取,并從其頁面提取結(jié)構(gòu)化數(shù)據(jù)。
Ubuntu下安裝Scrapy,需要先安裝依賴Linux依賴
sudo?apt-get?install?python3?python3-dev?python3-pip?libxml2-dev?libxslt1-dev?zlib1g-dev?libffi-dev?libssl-dev
在新聞推薦系統(tǒng)虛擬conda環(huán)境中安裝scrapy
pip?install?scrapy
scrapy項(xiàng)目結(jié)構(gòu)
默認(rèn)情況下,所有scrapy項(xiàng)目的項(xiàng)目結(jié)構(gòu)都是相似的,在指定目錄對(duì)應(yīng)的命令行中輸入如下命令,就會(huì)在當(dāng)前目錄創(chuàng)建一個(gè)scrapy項(xiàng)目
scrapy?startproject?myproject
項(xiàng)目的目錄結(jié)構(gòu)如下:
myproject/
????scrapy.cfg
????
????myproject/??
????????__init__.py
????????items.py
????????middlewares.py
????????pipelines.py
????????settings.py
????????spiders/
????????????__init__.py
scrapy.cfg: 項(xiàng)目配置文件 myproject/ : 項(xiàng)目python模塊, 代碼將從這里導(dǎo)入 myproject/ items.py: 項(xiàng)目items文件, myproject/ pipelines.py: 項(xiàng)目管道文件,將爬取的數(shù)據(jù)進(jìn)行持久化存儲(chǔ) myproject/ settings.py: 項(xiàng)目配置文件,可以配置數(shù)據(jù)庫等 myproject/ spiders/: 放置spider的目錄,爬蟲的具體邏輯就是在這里實(shí)現(xiàn)的(具體邏輯寫在spider.py文件中),可以使用命令行創(chuàng)建spider,也可以直接在這個(gè)文件夾中創(chuàng)建spider相關(guān)的py文件 myproject/ middlewares:中間件,請(qǐng)求和響應(yīng)都將經(jīng)過他,可以配置請(qǐng)求頭、代理、cookie、會(huì)話維持等
spider
spider是定義一個(gè)特定站點(diǎn)(或一組站點(diǎn))如何被抓取的類,包括如何執(zhí)行抓取(即跟蹤鏈接)以及如何從頁面中提取結(jié)構(gòu)化數(shù)據(jù)(即抓取項(xiàng))。換言之,spider是為特定站點(diǎn)(或者在某些情況下,一組站點(diǎn))定義爬行和解析頁面的自定義行為的地方。
爬行器是自己定義的類,Scrapy使用它從一個(gè)網(wǎng)站(或一組網(wǎng)站)中抓取信息。它們必須繼承 Spider 并定義要做出的初始請(qǐng)求,可選的是如何跟隨頁面中的鏈接,以及如何解析下載的頁面內(nèi)容以提取數(shù)據(jù)。
對(duì)于spider來說,抓取周期是這樣的:
首先生成對(duì)第一個(gè)URL進(jìn)行爬網(wǎng)的初始請(qǐng)求,然后指定一個(gè)回調(diào)函數(shù),該函數(shù)使用從這些請(qǐng)求下載的響應(yīng)進(jìn)行調(diào)用。要執(zhí)行的第一個(gè)請(qǐng)求是通過調(diào)用 start_requests()方法,該方法(默認(rèn)情況下)生成Request中指定的URL的start_urls以及parse方法作為請(qǐng)求的回調(diào)函數(shù)。在回調(diào)函數(shù)中,解析響應(yīng)(網(wǎng)頁)并返回 item objects , Request對(duì)象,或這些對(duì)象的可迭代。這些請(qǐng)求還將包含一個(gè)回調(diào)(可能相同),然后由Scrapy下載,然后由指定的回調(diào)處理它們的響應(yīng)。在回調(diào)函數(shù)中,解析頁面內(nèi)容,通常使用 選擇器 (但您也可以使用beautifulsoup、lxml或任何您喜歡的機(jī)制)并使用解析的數(shù)據(jù)生成項(xiàng)。 最后,從spider返回的項(xiàng)目通常被持久化到數(shù)據(jù)庫(在某些 Item Pipeline )或者使用 Feed 導(dǎo)出 .
下面是官網(wǎng)給出的Demo:
import?scrapy
class?QuotesSpider(scrapy.Spider):
????name?=?"quotes"?#?表示一個(gè)spider 它在一個(gè)項(xiàng)目中必須是唯一的,即不能為不同的spider設(shè)置相同的名稱。
?
????#?必須返回請(qǐng)求的可迭代(您可以返回請(qǐng)求列表或編寫生成器函數(shù)),spider將從該請(qǐng)求開始爬行。后續(xù)請(qǐng)求將從這些初始請(qǐng)求中相繼生成。
????def?start_requests(self):
????????urls?=?[
????????????'http://quotes.toscrape.com/page/1/',
????????????'http://quotes.toscrape.com/page/2/',
????????]
????????for?url?in?urls:
????????????yield?scrapy.Request(url=url,?callback=self.parse)?#?注意,這里callback調(diào)用了下面定義的parse方法
?
????#?將被調(diào)用以處理為每個(gè)請(qǐng)求下載的響應(yīng)的方法。Response參數(shù)是 TextResponse 它保存頁面內(nèi)容,并具有進(jìn)一步有用的方法來處理它。
????def?parse(self,?response):
????????#?下面是直接從response中獲取內(nèi)容,為了更方便的爬取內(nèi)容,后面會(huì)介紹使用selenium來模擬人用瀏覽器,并且使用對(duì)應(yīng)的方法來提取我們想要爬取的內(nèi)容
????????page?=?response.url.split("/")[-2]
????????filename?=?f'quotes-{page}.html'
????????with?open(filename,?'wb')?as?f:
????????????f.write(response.body)
????????self.log(f'Saved?file?{filename}')
Xpath
XPath 是一門在 XML 文檔中查找信息的語言,XPath 可用來在 XML 文檔中對(duì)元素和屬性進(jìn)行遍歷。在爬蟲的時(shí)候使用xpath來選擇我們想要爬取的內(nèi)容是非常方便的,這里就提一下xpath中需要掌握的內(nèi)容,參考資料中的內(nèi)容更加的詳細(xì)(建議花一個(gè)小時(shí)看看)。
要了解xpath, 需要先了解一下HTML(是用來描述網(wǎng)頁的一種語言), 這個(gè)的細(xì)節(jié)就不詳細(xì)展開
劃重點(diǎn):
**xpath路徑表達(dá)式:**XPath 使用路徑表達(dá)式來選取 XML 文檔中的節(jié)點(diǎn)或者節(jié)點(diǎn)集。這些路徑表達(dá)式和我們?cè)诔R?guī)的電腦文件系統(tǒng)中看到的表達(dá)式非常相似。節(jié)點(diǎn)是通過沿著路徑 (path) 或者步 (steps) 來選取的。
了解如何使用xpath語法選取我們想要的內(nèi)容,所以需要熟悉xpath的基本語法
scrapy爬取新聞內(nèi)容實(shí)戰(zhàn)
在介紹這個(gè)項(xiàng)目之前先說一下這個(gè)項(xiàng)目的基本邏輯。
環(huán)境準(zhǔn)備:
首先Ubuntu系統(tǒng)里面需要安裝好MongoDB數(shù)據(jù)庫,這個(gè)可以參考開源項(xiàng)目MongoDB基礎(chǔ) python環(huán)境中安裝好了scrapy, pymongo包
項(xiàng)目邏輯:
每天定時(shí)從新浪新聞網(wǎng)站上爬取新聞數(shù)據(jù)存儲(chǔ)到mongodb數(shù)據(jù)庫中,并且需要監(jiān)控每天爬取新聞的狀態(tài)(比如某天爬取的數(shù)據(jù)特別少可能是哪里出了問題,需要進(jìn)行排查) 每天爬取新聞的時(shí)候只爬取當(dāng)天日期的新聞,主要是為了防止相同的新聞重復(fù)爬取(當(dāng)然這個(gè)也不能完全避免爬取重復(fù)的新聞,爬取新聞之后需要有一些單獨(dú)的去重的邏輯) 爬蟲項(xiàng)目中實(shí)現(xiàn)三個(gè)核心文件,分別是sina.py(spider),items.py(抽取數(shù)據(jù)的規(guī)范化及字段的定義),pipelines.py(數(shù)據(jù)寫入數(shù)據(jù)庫)
因?yàn)樾侣勁廊№?xiàng)目和新聞推薦系統(tǒng)是放在一起的,為了方便提前學(xué)習(xí),下面直接給出項(xiàng)目的目錄結(jié)構(gòu)以及重要文件中的代碼實(shí)現(xiàn),最終的項(xiàng)目將會(huì)和新聞推薦系統(tǒng)一起開源出來

創(chuàng)建一個(gè)scrapy項(xiàng)目:
scrapy?startproject?sinanews
實(shí)現(xiàn)item.py邏輯
#?Define?here?the?models?for?your?scraped?items
#
#?See?documentation?in:
#?https://docs.scrapy.org/en/latest/topics/items.html
import?scrapy
from?scrapy?import?Item,?Field
#?定義新聞數(shù)據(jù)的字段
class?SinanewsItem(scrapy.Item):
????"""數(shù)據(jù)格式化,數(shù)據(jù)不同字段的定義
????"""
????title?=?Field()?#?新聞標(biāo)題
????ctime?=?Field()?#?新聞發(fā)布時(shí)間
????url?=?Field()?#?新聞原始url
????raw_key_words?=?Field()?#?新聞關(guān)鍵詞(爬取的關(guān)鍵詞)
????content?=?Field()?#?新聞的具體內(nèi)容
????cate?=?Field()?#?新聞?lì)悇e
實(shí)現(xiàn)sina.py (spider)邏輯
這里需要注意的一點(diǎn),這里在爬取新聞的時(shí)候選擇的是一個(gè)比較簡(jiǎn)潔的展示網(wǎng)站進(jìn)行爬取的,相比直接去最新的新浪新聞?dòng)^光爬取新聞簡(jiǎn)單很多,簡(jiǎn)潔的網(wǎng)站大概的鏈接:https://news.sina.com.cn/roll/#pageid=153&lid=2509&k=&num=50&page=1
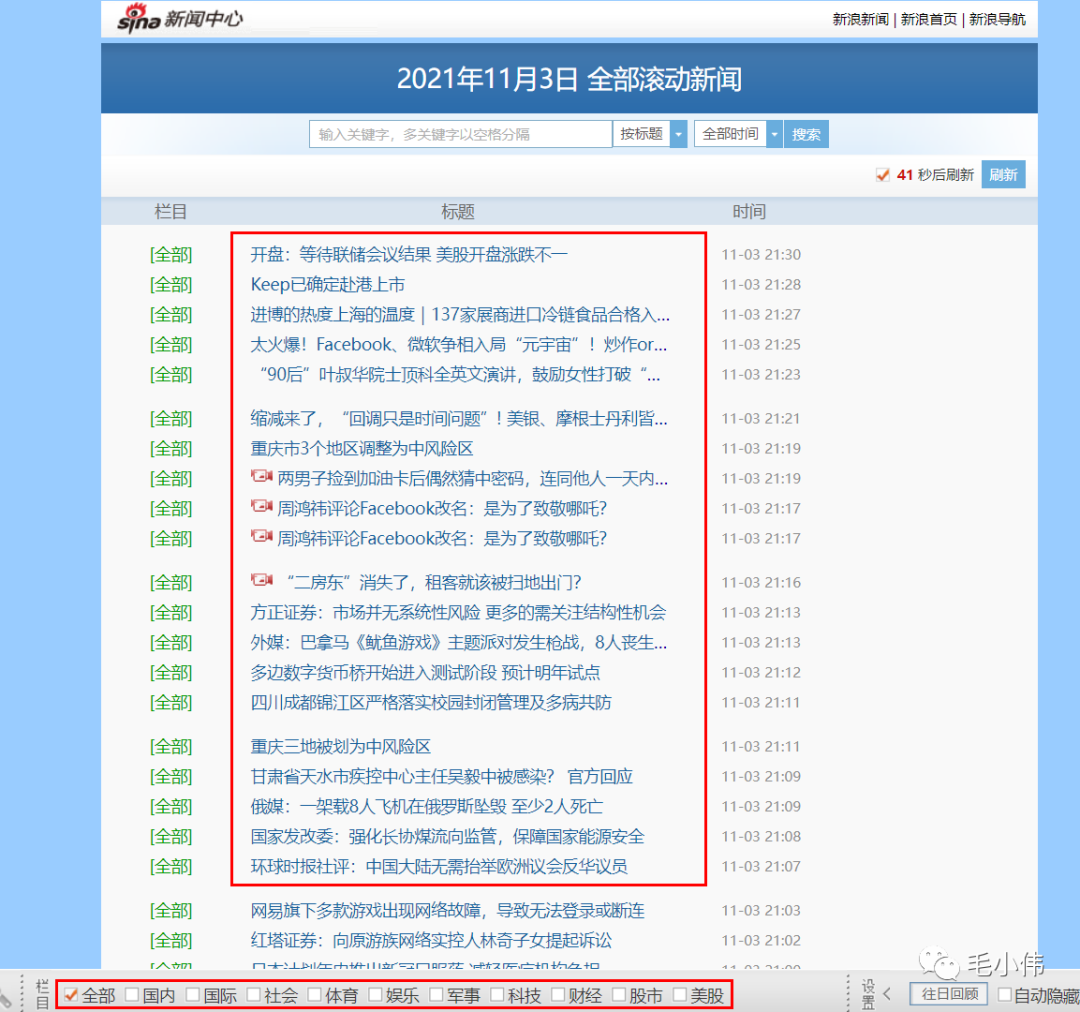
#?-*-?coding:?utf-8?-*-
import?re
import?json
import?random
import?scrapy
from?scrapy?import?Request
from?..items?import?SinanewsItem
from?datetime?import?datetime
class?SinaSpider(scrapy.Spider):
????#?spider的名字
????name?=?'sina_spider'
????def?__init__(self,?pages=None):
????????super(SinaSpider).__init__()
????????self.total_pages?=?int(pages)
????????#?base_url?對(duì)應(yīng)的是新浪新聞的簡(jiǎn)潔版頁面,方便爬蟲,并且不同類別的新聞也很好區(qū)分
????????self.base_url?=?'https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid={}&k=&num=50&page={}&r={}'
????????#?lid和分類映射字典
????????self.cate_dict?=?{
????????????"2510":??"國內(nèi)",
????????????"2511":??"國際",
????????????"2669":??"社會(huì)",
????????????"2512":??"體育",
????????????"2513":??"娛樂",
????????????"2514":??"軍事",
????????????"2515":??"科技",
????????????"2516":??"財(cái)經(jīng)",
????????????"2517":??"股市",
????????????"2518":??"美股"
????????}
????def?start_requests(self):
????????"""返回一個(gè)Request迭代器
????????"""
????????#?遍歷所有類型的論文
????????for?cate_id?in?self.cate_dict.keys():
????????????for?page?in?range(1,?self.total_pages?+?1):
????????????????lid?=?cate_id
????????????????#?這里就是一個(gè)隨機(jī)數(shù),具體含義不是很清楚
????????????????r?=?random.random()
????????????????#?cb_kwargs?是用來往解析函數(shù)parse中傳遞參數(shù)的
????????????????yield?Request(self.base_url.format(lid,?page,?r),?callback=self.parse,?cb_kwargs={"cate_id":?lid})
????
????def?parse(self,?response,?cate_id):
????????"""解析網(wǎng)頁內(nèi)容,并提取網(wǎng)頁中需要的內(nèi)容
????????"""
????????json_result?=?json.loads(response.text)?#?將請(qǐng)求回來的頁面解析成json
????????#?提取json中我們想要的字段
????????#?json使用get方法比直接通過字典的形式獲取數(shù)據(jù)更方便,因?yàn)椴恍枰幚懋惓?/span>
????????data_list?=?json_result.get('result').get('data')
????????for?data?in?data_list:
????????????item?=?SinanewsItem()
????????????item['cate']?=?self.cate_dict[cate_id]
????????????item['title']?=?data.get('title')
????????????item['url']?=?data.get('url')
????????????item['raw_key_words']?=?data.get('keywords')
????????????#?ctime?=?datetime.fromtimestamp(int(data.get('ctime')))
????????????#?ctime?=?datetime.strftime(ctime,?'%Y-%m-%d?%H:%M')
????????????#?保留的是一個(gè)時(shí)間戳
????????????item['ctime']?=?data.get('ctime')
????????????#?meta參數(shù)傳入的是一個(gè)字典,在下一層可以將當(dāng)前層的item進(jìn)行復(fù)制
????????????yield?Request(url=item['url'],?callback=self.parse_content,?meta={'item':?item})
????
????def?parse_content(self,?response):
????????"""解析文章內(nèi)容
????????"""
????????item?=?response.meta['item']
????????content?=?''.join(response.xpath('//*[@id="artibody"?or?@id="article"]//p/text()').extract())
????????content?=?re.sub(r'\u3000',?'',?content)
????????content?=?re.sub(r'[?\xa0?]+',?'?',?content)
????????content?=?re.sub(r'\s*\n\s*',?'\n',?content)
????????content?=?re.sub(r'\s*(\s)',?r'\1',?content)
????????content?=?''.join([x.strip()?for?x?in?content])
????????item['content']?=?content
????????yield?item?
數(shù)據(jù)持久化實(shí)現(xiàn),piplines.py
這里需要注意的就是實(shí)現(xiàn)SinanewsPipeline類的時(shí)候,里面很多方法都是固定的,不是隨便寫的,不同的方法又不同的功能,這個(gè)可以參考scrapy官方文檔。
#?Define?your?item?pipelines?here
#
#?Don't?forget?to?add?your?pipeline?to?the?ITEM_PIPELINES?setting
#?See:?https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#?useful?for?handling?different?item?types?with?a?single?interface
import?time
import?datetime
import?pymongo
from?pymongo.errors?import?DuplicateKeyError
from?sinanews.items?import?SinanewsItem
from?itemadapter?import?ItemAdapter
#?新聞item持久化
class?SinanewsPipeline:
????"""數(shù)據(jù)持久化:將數(shù)據(jù)存放到mongodb中
????"""
????def?__init__(self,?host,?port,?db_name,?collection_name):
????????self.host?=?host
????????self.port?=?port
????????self.db_name?=?db_name
????????self.collection_name?=?collection_name
????@classmethod????
????def?from_crawler(cls,?crawler):
????????"""自帶的方法,這個(gè)方法可以重新返回一個(gè)新的pipline對(duì)象,并且可以調(diào)用配置文件中的參數(shù)
????????"""
????????return?cls(
????????????host?=?crawler.settings.get("MONGO_HOST"),
????????????port?=?crawler.settings.get("MONGO_PORT"),
????????????db_name?=?crawler.settings.get("DB_NAME"),
????????????#?mongodb中數(shù)據(jù)的集合按照日期存儲(chǔ)
????????????collection_name?=?crawler.settings.get("COLLECTION_NAME")?+?\
????????????????"_"?+?time.strftime("%Y%m%d",?time.localtime())
????????)
????def?open_spider(self,?spider):
????????"""開始爬蟲的操作,主要就是鏈接數(shù)據(jù)庫及對(duì)應(yīng)的集合
????????"""
????????self.client?=?pymongo.MongoClient(self.host,?self.port)
????????self.db?=?self.client[self.db_name]
????????self.collection?=?self.db[self.collection_name]
????????
????def?close_spider(self,?spider):
????????"""關(guān)閉爬蟲操作的時(shí)候,需要將數(shù)據(jù)庫斷開
????????"""
????????self.client.close()
????def?process_item(self,?item,?spider):
????????"""處理每一條數(shù)據(jù),注意這里需要將item返回
????????注意:判斷新聞是否是今天的,每天只保存當(dāng)天產(chǎn)出的新聞,這樣可以增量的添加新的新聞數(shù)據(jù)源
????????"""
????????if?isinstance(item,?SinanewsItem):
????????????try:
????????????????#?TODO?物料去重邏輯,根據(jù)title進(jìn)行去重,先讀取物料池中的所有物料的title然后進(jìn)行去重
????????????????cur_time?=?int(item['ctime'])
????????????????str_today?=?str(datetime.date.today())
????????????????min_time?=?int(time.mktime(time.strptime(str_today?+?"?00:00:00",?'%Y-%m-%d?%H:%M:%S')))
????????????????max_time?=?int(time.mktime(time.strptime(str_today?+?"?23:59:59",?'%Y-%m-%d?%H:%M:%S')))
????????????????if?cur_time?>?min_time?and?cur_time?<=?max_time:
????????????????????self.collection.insert(dict(item))
????????????except?DuplicateKeyError:
????????????????"""
????????????????說明有重復(fù)
????????????????"""
????????????????pass
????????return?item
配置文件,settings.py
#?Scrapy?settings?for?sinanews?project
#
#?For?simplicity,?this?file?contains?only?settings?considered?important?or
#?commonly?used.?You?can?find?more?settings?consulting?the?documentation:
#
#?????https://docs.scrapy.org/en/latest/topics/settings.html
#?????https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#?????https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from?typing?import?Collection
BOT_NAME?=?'sinanews'
SPIDER_MODULES?=?['sinanews.spiders']
NEWSPIDER_MODULE?=?'sinanews.spiders'
#?Crawl?responsibly?by?identifying?yourself?(and?your?website)?on?the?user-agent
#USER_AGENT?=?'sinanews?(+http://www.yourdomain.com)'
#?Obey?robots.txt?rules
ROBOTSTXT_OBEY?=?True
#?Configure?maximum?concurrent?requests?performed?by?Scrapy?(default:?16)
#CONCURRENT_REQUESTS?=?32
#?Configure?a?delay?for?requests?for?the?same?website?(default:?0)
#?See?https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
#?See?also?autothrottle?settings?and?docs
#?DOWNLOAD_DELAY?=?3
#?The?download?delay?setting?will?honor?only?one?of:
#CONCURRENT_REQUESTS_PER_DOMAIN?=?16
#CONCURRENT_REQUESTS_PER_IP?=?16
#?Disable?cookies?(enabled?by?default)
#COOKIES_ENABLED?=?False
#?Disable?Telnet?Console?(enabled?by?default)
#TELNETCONSOLE_ENABLED?=?False
#?Override?the?default?request?headers:
#DEFAULT_REQUEST_HEADERS?=?{
#???'Accept':?'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
#???'Accept-Language':?'en',
#}
#?Enable?or?disable?spider?middlewares
#?See?https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES?=?{
#????'sinanews.middlewares.SinanewsSpiderMiddleware':?543,
#}
#?Enable?or?disable?downloader?middlewares
#?See?https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES?=?{
#????'sinanews.middlewares.SinanewsDownloaderMiddleware':?543,
#}
#?Enable?or?disable?extensions
#?See?https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS?=?{
#????'scrapy.extensions.telnet.TelnetConsole':?None,
#}
#?Configure?item?pipelines
#?See?https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#?如果需要使用itempipline來存儲(chǔ)item的話需要將這段注釋打開
ITEM_PIPELINES?=?{
???'sinanews.pipelines.SinanewsPipeline':?300,
}
#?Enable?and?configure?the?AutoThrottle?extension?(disabled?by?default)
#?See?https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED?=?True
#?The?initial?download?delay
#AUTOTHROTTLE_START_DELAY?=?5
#?The?maximum?download?delay?to?be?set?in?case?of?high?latencies
#AUTOTHROTTLE_MAX_DELAY?=?60
#?The?average?number?of?requests?Scrapy?should?be?sending?in?parallel?to
#?each?remote?server
#AUTOTHROTTLE_TARGET_CONCURRENCY?=?1.0
#?Enable?showing?throttling?stats?for?every?response?received:
#AUTOTHROTTLE_DEBUG?=?False
#?Enable?and?configure?HTTP?caching?(disabled?by?default)
#?See?https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED?=?True
#HTTPCACHE_EXPIRATION_SECS?=?0
#HTTPCACHE_DIR?=?'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES?=?[]
#HTTPCACHE_STORAGE?=?'scrapy.extensions.httpcache.FilesystemCacheStorage'
MONGO_HOST?=?"127.0.0.1"
MONGO_PORT?=?27017
DB_NAME?=?"SinaNews"
COLLECTION_NAME?=?"news"
監(jiān)控腳本,monitor_news.py
#?-*-?coding:?utf-8?-*-
import?sys,?time
import?pymongo
import?scrapy?
from?sinanews.settings?import?MONGO_HOST,?MONGO_PORT,?DB_NAME,?COLLECTION_NAME
if?__name__?==?"__main__":
????news_num?=?int(sys.argv[1])
????time_str?=?time.strftime("%Y%m%d",?time.localtime())
????#?實(shí)際的collection_name
????collection_name?=?COLLECTION_NAME?+?"_"?+?time_str
????
????#?鏈接數(shù)據(jù)庫
????client?=?pymongo.MongoClient(MONGO_HOST,?MONGO_PORT)
????db?=?client[DB_NAME]
????collection?=?db[collection_name]
????#?查找當(dāng)前集合中所有文檔的數(shù)量
????cur_news_num?=?collection.count()
????print(cur_news_num)
????if?(cur_news_num?????????print("the?news?nums?of?{}_{}?collection?is?less?then?{}".\
????????????format(COLLECTION_NAME,?time_str,?news_num))
運(yùn)行腳本,run_scrapy_sina.sh
#?-*-?coding:?utf-8?-*-
"""
新聞爬取及監(jiān)控腳本
"""
#?設(shè)置python環(huán)境
python="/home/recsys/miniconda3/envs/news_rec_py3/bin/python"
#?新浪新聞網(wǎng)站爬取的頁面數(shù)量
page="1"
min_news_num="1000"?#?每天爬取的新聞數(shù)量少于500認(rèn)為是異常
#?爬取數(shù)據(jù)
scrapy?crawl?sina_spider?-a?pages=${page}??
if?[?$??-eq?0?];?then
????echo?"scrapy?crawl?sina_spider?--pages?${page}?success."
else???
????echo?"scrapy?crawl?sina_spider?--pages?${page}?fail."
fi
#?檢查今天爬取的數(shù)據(jù)是否少于min_news_num篇文章,這里也可以配置郵件報(bào)警
python?monitor_news.py?${min_news_num}
if?[?$??-eq?0?];?then
????echo?"run?python?monitor_news.py?success."
else???
????echo?"run?python?monitor_news.py?fail."
fi
運(yùn)行項(xiàng)目命令
sh?run_scrapy_sina.sh
最終查看數(shù)據(jù)庫中的數(shù)據(jù):

參考資料
MongoDB基礎(chǔ)
Scrapy框架新手入門教程
scrapy中文文檔
Xpath教程
https://github.com/Ingram7/NewsinaSpider
https://www.cnblogs.com/zlslch/p/6931838.html
--end-- 掃碼即可加我微信
學(xué)習(xí)交流
老表朋友圈經(jīng)常有贈(zèng)書/紅包福利活動(dòng)