
全網(wǎng)都在說一個錯誤的結(jié)論(文末送書)

大家在背 MySQL 八股文的時候,是不是經(jīng)常看到這句話。
聯(lián)合索引的最左匹配原則會一直向右匹配直到遇到范圍查詢(>、<、between、like) 就會停止匹配。
我隨手在網(wǎng)上搜了下, 基本全部都是這個結(jié)論,似乎這個結(jié)論大家都耳濡目染了,應(yīng)該大多數(shù)人都覺得這個結(jié)論是正確的吧。
我在昨晚折騰了幾個實驗,發(fā)現(xiàn)這個結(jié)論并不全對!去掉 「between 和 like 」這個結(jié)論就沒問題了。
經(jīng)過實驗的證明,我得出的結(jié)論是這樣的:
接下來,我會用幾個實驗例子來說明這個結(jié)論。

B+Tree 索引
首先,先來認識下 B+Tree 索引。
MySQL 的 InnoDB 存儲引擎會為每一張數(shù)據(jù)庫表創(chuàng)建一個「聚簇索引」來保存表的數(shù)據(jù),聚簇索引默認使用的是 B+Tree 索引。
為了讓大家理解 B+Tree 索引的存儲和查詢的過程,接下來我通過一個簡單例子,說明一下 B+Tree 索引在存儲數(shù)據(jù)中的具體實現(xiàn)。
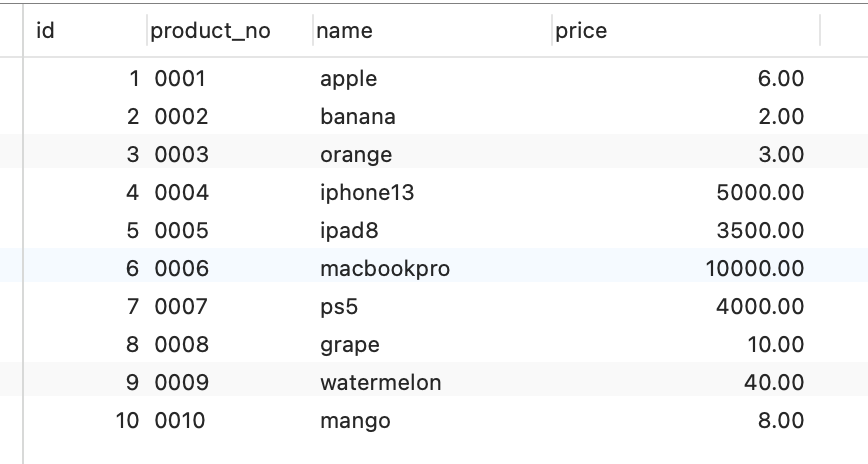
假設(shè)有一張商品表,表里有這些數(shù)據(jù):
這些數(shù)據(jù),存儲在 B+Tree 索引時是長什么樣子的?
B+Tree 是一種多叉樹,葉子節(jié)點才存放數(shù)據(jù),非葉子節(jié)點只存放索引,而且每個節(jié)點里的數(shù)據(jù)是按主鍵值(id)順序存放的,每一層父節(jié)點的索引值都會出現(xiàn)在下層子節(jié)點的索引值中,因此在葉子節(jié)點中,包括了所有的索引值信息,并且每一個葉子節(jié)點都指向下一個葉子節(jié)點,形成一個鏈表,便于范圍查詢。
聚簇索引的 B+Tree 如圖所示:
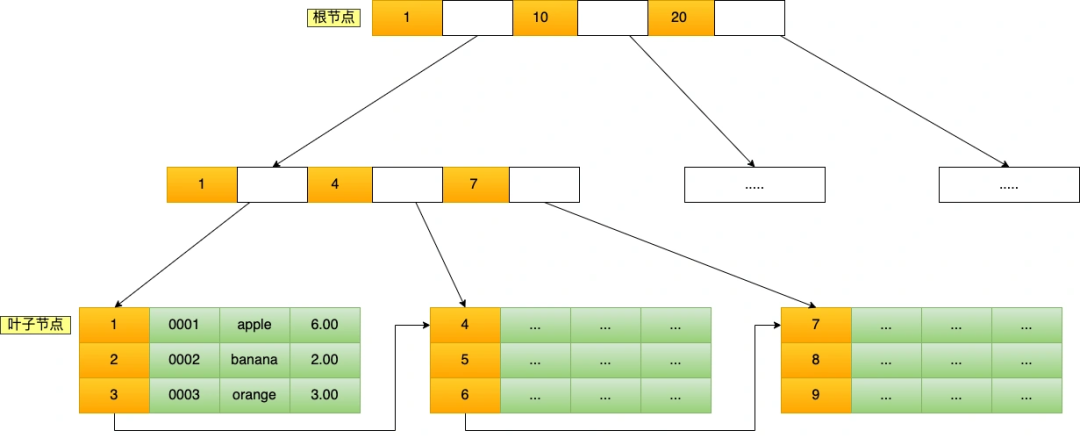
假設(shè),執(zhí)行了 select * from t_product where id = 5 查詢語句,該查詢語句的條件是找到 id(主鍵)為 5 的這條記錄。因為 B+Tree 是一個有序的數(shù)據(jù)結(jié)構(gòu),所以可以通過二分查找算法快速定位到這條記錄,這也就是我們常說的索引查詢,具體過程如下:
從根節(jié)點開始,將 5 與根節(jié)點的索引數(shù)據(jù) (1,10,20) 比較,5 在 1 和 10 之間,根據(jù)二分查找算法,找到第二層的索引數(shù)據(jù) (1,4,7); 在第二層的索引數(shù)據(jù) (1,4,7)中進行查找,因為 5 在 4 和 7 之間,根據(jù)二分查找算法,找到第三層的索引數(shù)據(jù)(4,5,6); 在葉子節(jié)點的索引數(shù)據(jù)(4,5,6)中進行查找,然后我們找到了索引值為 5 的這條記錄。
聚簇索引只能用于主鍵字段的快速查詢,如果想實現(xiàn)「非主鍵字段」的快速查詢,我們就要針對「非主鍵字段」創(chuàng)建索引,這種索引稱作為「二級索引」。二級索引同樣基于 B+Tree 實現(xiàn)的,不過二級索引的葉子節(jié)點存放的是主鍵值,不是實際數(shù)據(jù)。
我這里將前面的商品表中的 product_no (商品編碼)字段設(shè)置為二級索引,那么二級索引的 B+Tree 如下圖,其中非葉子的索引值是 product_no(圖中橙色部分),葉子節(jié)點存儲的數(shù)據(jù)是主鍵值(圖中綠色部分)。
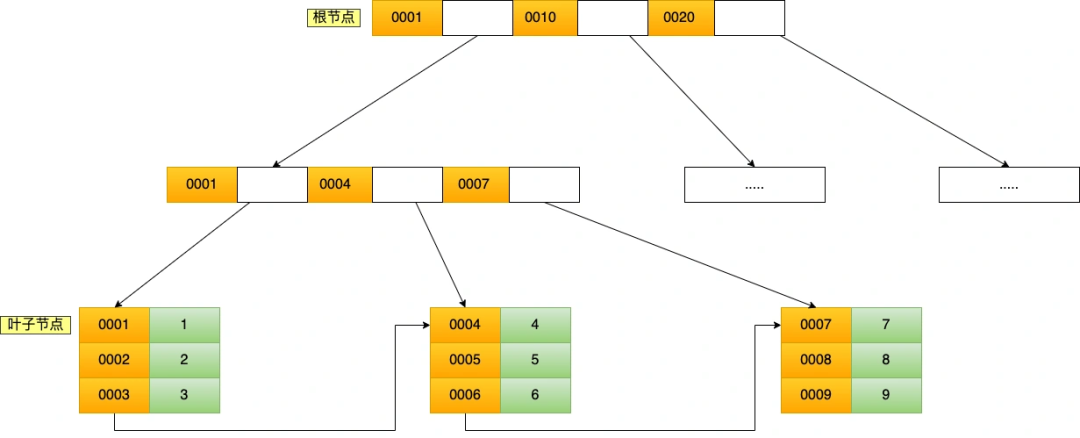 如果我用 product_no 二級索引查詢商品,如下查詢語句:
如果我用 product_no 二級索引查詢商品,如下查詢語句:
select * from product where product_no = '0002';
會先在二級索引的 B+Tree 中快速查找到 product_no 為 0002 的二級索引記錄,然后獲取主鍵值,然后利用主鍵值在主鍵索引的 B+Tree 中快速查詢到對應(yīng)的葉子節(jié)點,然后獲取完整的記錄。這個過程叫「回表」,也就是說要查兩個 B+Tree 才能查到數(shù)據(jù)。如下圖:
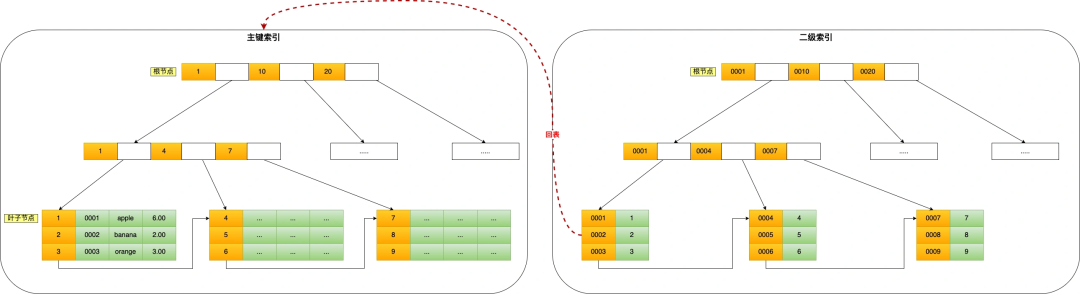
不過,當查詢的數(shù)據(jù)是能在二級索引的 B+Tree 的葉子節(jié)點里查詢到,這時就不用再查主鍵索引查,比如下面這條查詢語句:
select id from product where product_no = '0002';
這種在二級索引的 B+Tree 就能查詢到結(jié)果的過程就叫作「覆蓋索引」,也就是只需要查一個 B+Tree 就能找到數(shù)據(jù)。
什么是聯(lián)合索引?
前文我將 product_no 字段設(shè)置為了索引,這種二級索引只有一個字段。如果將多個字段組合成一個索引,那么這種二級索引就被稱為聯(lián)合索引。
比如,將商品表中的 product_no 和 name 字段組合成聯(lián)合索引`(product_no, name)``,創(chuàng)建聯(lián)合索引的方式如下:
CREATE INDEX index_product_no_name ON product(product_no, name);
聯(lián)合索引 ``(product_no, name)` 的 B+Tree 示意圖如下:
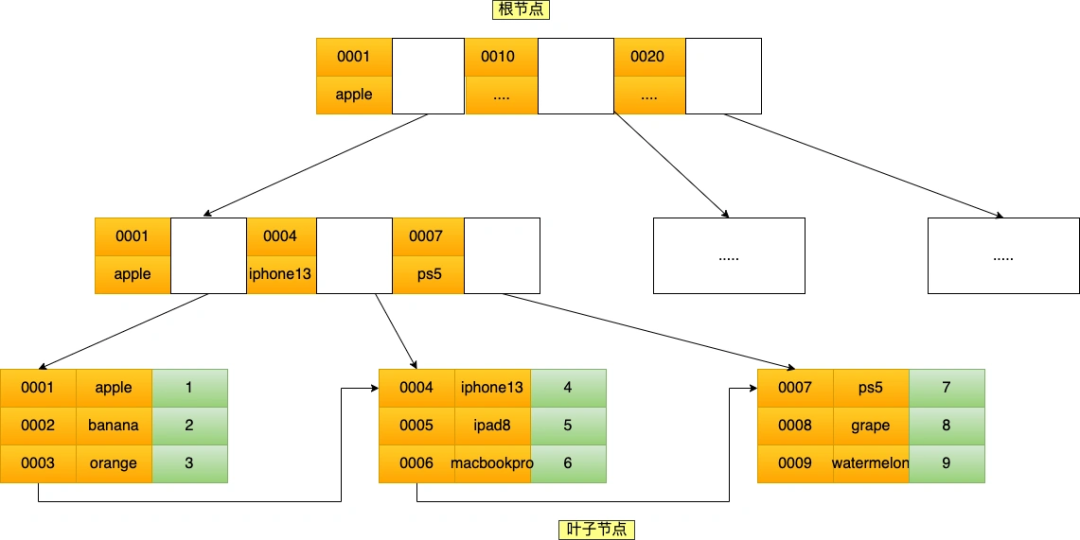
可以看到,聯(lián)合索引的非葉子節(jié)點用兩個字段的值作為 B+Tree 的索引值。
聯(lián)合索引的 B+Tree 是先按 product_no 進行排序,然后再 product_no 相同的情況再按 name 字段排序。記住這句話,很重要!
最左匹配原則
使用聯(lián)合索引時,存在最左匹配原則,也就是按照最左優(yōu)先的方式進行索引的匹配。
在使用聯(lián)合索引進行查詢的時候,如果不遵循「最左匹配原則」,聯(lián)合索引會失效,這樣就無法利用到索引快速查詢的特性了。
比如,如果創(chuàng)建了一個 (a, b, c) 聯(lián)合索引,如果查詢條件是以下這幾種,就可以利用聯(lián)合索引:
where a=1; where a=1 and b=2 and c=3; where a=1 and b=2;
需要注意的是,因為有查詢優(yōu)化器,所以 a 字段在 where 子句的順序并不重要。但是,如果查詢條件是以下這幾種,因為不符合最左匹配原則,所以就無法匹配上聯(lián)合索引,聯(lián)合索引就會失效:
where b=2; where c=3; where b=2 and c=3;
上面這些查詢條件之所以會失效,是因為(a, b, c) 聯(lián)合索引,是先按 a 排序,在 a 相同的情況再按 b 排序,在 b 相同的情況再按 c 排序。所以,b 和 c 是全局無序,局部相對有序的,這樣在沒有遵循最左匹配原則的情況下,是無法利用到索引的。
我這里舉聯(lián)合索引(a,b)的例子,該聯(lián)合索引的 B+ Tree 如下:
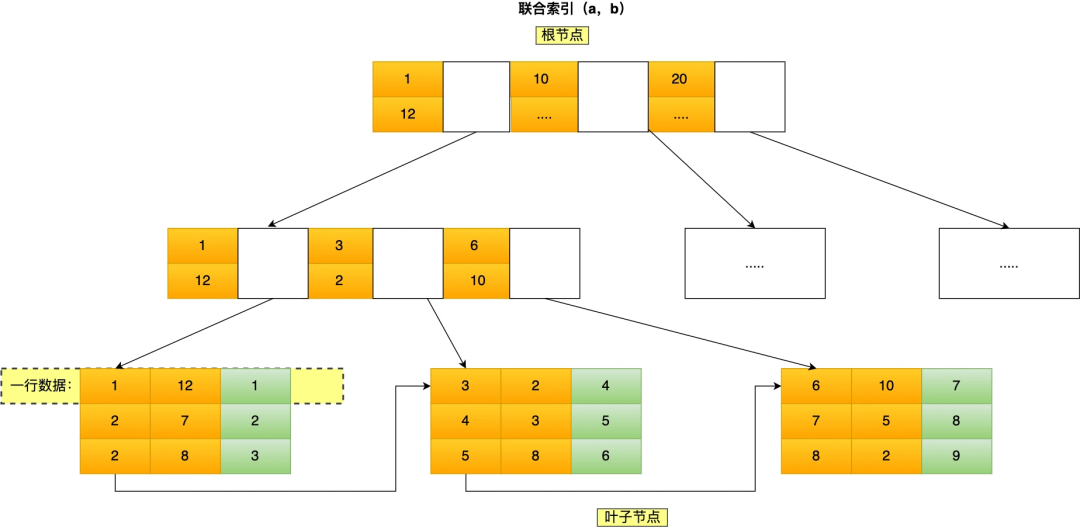
可以看到,a 是全局有序的(1, 2, 2, 3, 4, 5, 6, 7 ,8),而 b 是全局是無序的(12,7,8,2,3,8,10,5,2)。因此,直接執(zhí)行 where b = 2 這種查詢條件沒有辦法利用聯(lián)合索引的,利用索引的前提是索引里的 key 是有序的。
只有在 a 相同的情況才,b 才是有序的,比如 a 等于 2 的時候,b 的值為(7,8),這時就是有序的,這個有序狀態(tài)是局部的,因此,執(zhí)行 where a = 2 and b = 7 這種查詢條件時, a 和 b 字段能用到聯(lián)合索引的,也就是聯(lián)合索引生效了。
聯(lián)合索引范圍查詢
聯(lián)合索引有一些特殊情況,并不是查詢過程使用了聯(lián)合索引查詢,就代表聯(lián)合索引中的所有字段都用到了聯(lián)合索引進行索引查詢,也就是可能存在部分字段用到聯(lián)合索引的 B+Tree,部分字段沒有用到聯(lián)合索引的 B+Tree 的情況。
這種特殊情況就發(fā)生在范圍查詢。也就是文章開頭的那句話:聯(lián)合索引的最左匹配原則會一直向右匹配直到遇到「范圍查詢」就會停止匹配。也就是范圍查詢的字段可以用到聯(lián)合索引,但是范圍查詢字段的后面的字段無法用到聯(lián)合索引。
范圍查詢有很多種,那到底是哪些范圍查詢會導(dǎo)致聯(lián)合索引的最左匹配原則會停止匹配呢?
接下來,舉例幾個范圍查詢的例子,下面的實驗案例是基于 MySQL 8.0 做的。
例子一
Q1: select * from t_table where a > 1 and b = 2,聯(lián)合索引(a, b)哪一個字段用到了聯(lián)合索引的 B+Tree?
由于聯(lián)合索引(二級索引)是先按照 a 字段的值排序的,所以符合 a > 1 條件的二級索引記錄肯定是相鄰的,于是在進行索引掃描的時候,可以定位到符合 a > 1 條件的第一條記錄,然后沿著記錄所在的鏈表向后掃描,直到某條記錄不符合 a > 1 條件位置。所以 a 字段可以在聯(lián)合索引的 B+Tree 中進行索引查詢。
但是在符合 a > 1 條件的二級索引記錄的范圍里,b 字段的值是無序的。
比如,下圖的聯(lián)合索引的 B+ Tree 里:
下面這三條記錄的 a 字段的值都符合 a > 1 查詢條件,而 b 字段的值是無序的:
a 字段值為 5 的記錄,該記錄的 b 字段值為 8; a 字段值為 6 的記錄,該記錄的 b 字段值為 10; a 字段值為 7 的記錄,該記錄的 b 字段值為 5;
因此,我們不能根據(jù)查詢條件 b = 2 來進一步減少需要掃描的記錄數(shù)量(b 字段無法利用聯(lián)合索引進行索引查詢的意思)。
所以在執(zhí)行 Q1 這條查詢語句的時候,對應(yīng)的掃描區(qū)間是 (2, + ∞),形成該掃描區(qū)間的邊界條件是 a > 1,與 b = 2 無關(guān)。
因此,Q1 這條查詢語句只有 a 字段用到了聯(lián)合索引進行索引查詢,而 b 字段并沒有使用到聯(lián)合索引。
我們也可以在執(zhí)行計劃中的 key_len 知道這一點,在使用聯(lián)合索引進行查詢的時候,通過 key_len 我們可以知道優(yōu)化器具體使用了多少個字段的查詢條件來形成掃描區(qū)間的邊界條件。
舉例個例子 ,a 和 b 都是 int 類型且不為 NULL 的字段,那么 Q1 這條查詢語句執(zhí)行計劃如下:

可以看到 key_len 為 4 字節(jié)(如果字段允許為 NULL,就在字段類型占用的字節(jié)數(shù)上加 1,也就是 5 字節(jié)),說明只有 a 字段用到了聯(lián)合索引進行索引查詢,而且可以看到,即使 b 字段沒用到聯(lián)合索引,key 為 idx_a_b,說明 Q1 查詢語句使用了 idx_a_b 聯(lián)合索引。
通過 Q1 查詢語句我們可以知道,a 字段使用了 > 進行范圍查詢,聯(lián)合索引的最左匹配原則在遇到 a 字段的范圍查詢( >)后就停止匹配了,因此 b 字段并沒有使用到聯(lián)合索引。
例子二
Q2: select * from t_table where a >= 1 and b = 2,聯(lián)合索引(a, b)哪一個字段用到了聯(lián)合索引的 B+Tree?
Q2 和 Q1 的查詢語句很像,唯一的區(qū)別就是 a 字段的查詢條件「大于等于」。
由于聯(lián)合索引(二級索引)是先按照 a 字段的值排序的,所以符合 >= 1 條件的二級索引記錄肯定是相鄰,于是在進行索引掃描的時候,可以定位到符合 >= 1 條件的第一條記錄,然后沿著記錄所在的鏈表向后掃描,直到某條記錄不符合 a>= 1 條件位置。所以 a 字段可以在聯(lián)合索引的 B+Tree 中進行索引查詢。
雖然在符合 a>= 1 條件的二級索引記錄的范圍里,b 字段的值是「無序」的,但是對于符合 a = 1 的二級索引記錄的范圍里,b 字段的值是「有序」的(因為對于聯(lián)合索引,是先按照 a 字段的值排序,然后在 a 字段的值相同的情況下,再按照 b 字段的值進行排序)。
于是,在確定需要掃描的二級索引的范圍時,當二級索引記錄的 a 字段值為 1 時,可以通過 b = 2 條件減少需要掃描的二級索引記錄范圍(b 字段可以利用聯(lián)合索引進行索引查詢的意思)。也就是說,從符合 a = 1 and b = 2 條件的第一條記錄開始掃描,而不需要從第一個 a 字段值為 1 的記錄開始掃描。
所以,Q2 這條查詢語句 a 和 b 字段都用到了聯(lián)合索引進行索引查詢。
我們也可以在執(zhí)行計劃中的 key_len 知道這一點。執(zhí)行計劃如下:

可以看到 key_len 為 8 字節(jié),說明優(yōu)化器使用了 2 個字段的查詢條件來形成掃描區(qū)間的邊界條件,也就是 a 和 b 字段都用到了聯(lián)合索引進行索引查詢。
通過 Q2 查詢語句我們可以知道,雖然 a 字段使用了 >= 進行范圍查詢,但是聯(lián)合索引的最左匹配原則并沒有在遇到 a 字段的范圍查詢( >=)后就停止匹配了,b 字段還是可以用到了聯(lián)合索引的。
例子三
Q3: SELECT * FROM t_table WHERE a BETWEEN 2 AND 8 AND b = 2,聯(lián)合索引(a, b)哪一個字段用到了聯(lián)合索引的 B+Tree?
Q3 查詢條件中 a BETWEEN 2 AND 8 的意思是查詢 a 字段的值在 2 和 8 之間的記錄。
不同的數(shù)據(jù)庫對 BETWEEN ... AND 處理方式是有差異的。在 MySQL 中,BETWEEN 包含了 value1 和 value2 邊界值,類似于 >= and =<。而有的數(shù)據(jù)庫則不包含 value1 和 value2 邊界值(類似于 > and <)。
這里我們只討論 MySQL。由于 MySQL 的 BETWEEN 包含 value1 和 value2 邊界值,所以類似于 Q2 查詢語句,因此 Q3 這條查詢語句 a 和 b 字段都用到了聯(lián)合索引進行索引查詢。
我們也可以在執(zhí)行計劃中的 key_len 知道這一點。執(zhí)行計劃如下:

可以看到 key_len 為 8 字節(jié),說明優(yōu)化器使用了 2 個字段的查詢條件來形成掃描區(qū)間的邊界條件,也就是 a 和 b 字段都用到了聯(lián)合索引進行索引查詢。
通過 Q3 查詢語句我們可以知道,雖然 a 字段使用了 BETWEEN 進行范圍查詢,但是聯(lián)合索引的最左匹配原則并沒有在遇到 a 字段的范圍查詢( BETWEEN)后就停止匹配了,b 字段還是可以用到了聯(lián)合索引的。
例子四
Q4: SELECT * FROM t_user WHERE name like 'j%' and age = 22,聯(lián)合索引(name, age)哪一個字段用到了聯(lián)合索引的 B+Tree?
由于聯(lián)合索引(二級索引)是先按照 name 字段的值排序的,所以前綴為 ‘j’ 的 name 字段的二級索引記錄都是相鄰的, 于是在進行索引掃描的時候,可以定位到符合前綴為 ‘j’ 的 name 字段的第一條記錄,然后沿著記錄所在的鏈表向后掃描,直到某條記錄的 name 前綴不為 ‘j’ 為止。
所以 a 字段可以在聯(lián)合索引的 B+Tree 中進行索引查詢,形成的掃描區(qū)間是['j','k')。注意, j 是閉區(qū)間。如下圖:
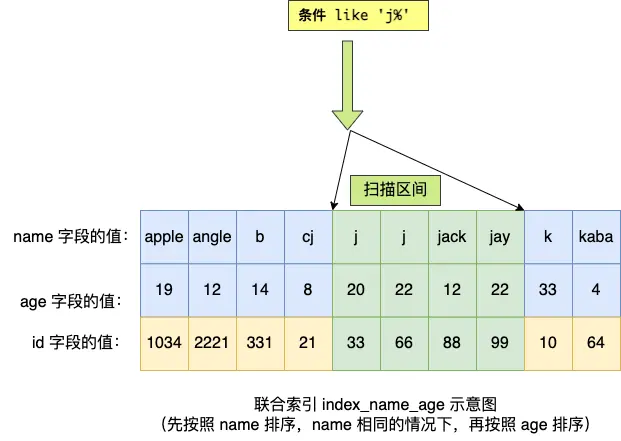
雖然在符合前綴為 ‘j’ 的 name 字段的二級索引記錄的范圍里,age 字段的值是「無序」的,但是對于符合 name = j 的二級索引記錄的范圍里,age字段的值是「有序」的(因為對于聯(lián)合索引,是先按照 name 字段的值排序,然后在 name 字段的值相同的情況下,再按照 age 字段的值進行排序)。
于是,在確定需要掃描的二級索引的范圍時,當二級索引記錄的 name 字段值為 ‘j’ 時,可以通過 age = 22 條件減少需要掃描的二級索引記錄范圍(age 字段可以利用聯(lián)合索引進行索引查詢的意思)。也就是說,從符合 name = 'j' and age = 22 條件的第一條記錄時開始掃描,而不需要從第一個 name 為 j 的記錄開始掃描 。如下圖的右邊:
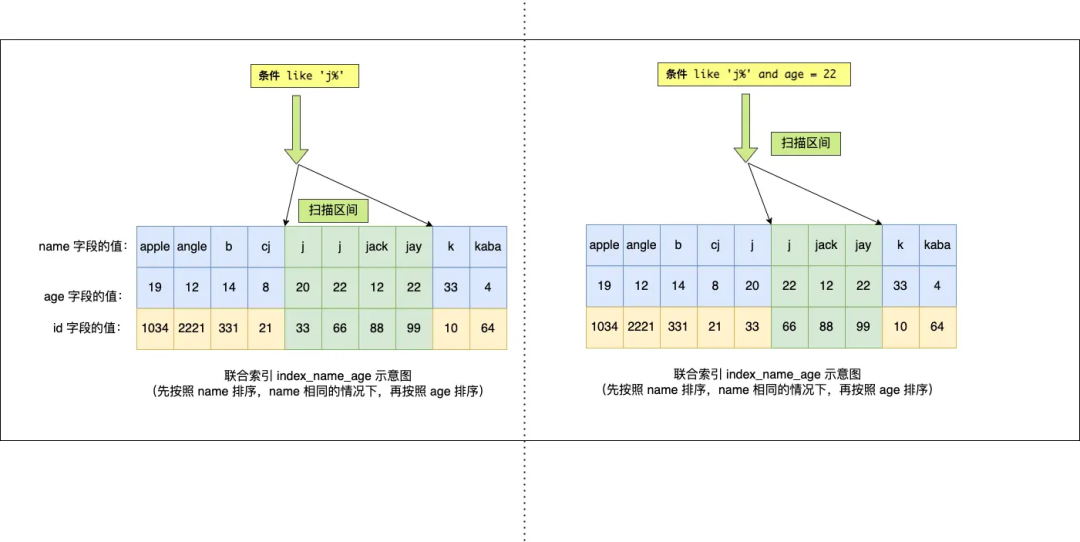
所以,Q4 這條查詢語句 a 和 b 字段都用到了聯(lián)合索引進行索引查詢。
我們也可以在執(zhí)行計劃中的 key_len 知道這一點。本次例子中:
name 字段的類型是 varchar(30) 且不為 NULL,數(shù)據(jù)庫表使用了 utf8mb4 字符集,一個字符集為 utf8mb4 的字符是 4 個字節(jié),因此 name 字段的實際數(shù)據(jù)最多占用的存儲空間長度是 120 字節(jié)(30 x 4),然后因為 name 是變長類型的字段,需要再加 2,也就是 name 的 key_len 為 122。 age 字段的類型是 int 且不為 NULL,key_len 為 4。
Q4 查詢語句的執(zhí)行計劃如下:

可以看到 key_len 為 126 字節(jié),name 的 key_len 為 122,age 的 key_len 為 4,說明優(yōu)化器使用了 2 個字段的查詢條件來形成掃描區(qū)間的邊界條件,也就是 name 和 age 字段都用到了聯(lián)合索引進行索引查詢。
通過 Q4 查詢語句我們可以知道,雖然 name 字段使用了 like 前綴匹配進行范圍查詢,但是聯(lián)合索引的最左匹配原則并沒有在遇到 name 字段的范圍查詢( like 'j%')后就停止匹配了,age 字段還是可以用到了聯(lián)合索引的。
小結(jié)
網(wǎng)上傳來穿去這句話:「聯(lián)合索引的最左匹配原則會一直向右匹配直到遇到范圍查詢(>、<、between、like) 就會停止匹配」并不是對的。
經(jīng)過實驗的證明,我得出的結(jié)論是這樣的:
聯(lián)合索引的最左匹配原則,在遇到范圍查詢(如 >、<)的時候,就會停止匹配,也就是范圍查詢的字段可以用到聯(lián)合索引,但是在范圍查詢字段后面的字段無法用到聯(lián)合索引。注意,對于 >=、<=、BETWEEN、like 前綴匹配的范圍查詢,并不會停止匹配。
好了,講完了,怎么樣,是不是又被我裝到了
Python客棧聯(lián)合北京大學(xué)出版社送書啦~~
01
Web安全攻防從入門到精通
推薦理由:
一本真正從漏洞靶場、項目案例來指導(dǎo)讀者提高Web安全、漏洞利用技術(shù)與滲透測試技巧的圖書。本書以新手實操為出發(fā)點,搭建漏洞靶場:解析攻防原理+詳解攻防手法+構(gòu)建完整攻防體系。
本書從一開始便對Web開發(fā)基礎(chǔ)和靶場搭建做了詳細介紹,結(jié)合紅日安全團隊的漏洞挖掘和評估項目實戰(zhàn)經(jīng)驗對各種實戰(zhàn)技術(shù)進行分析,便于讀者理解書中講到的項目評估攻防案例的底層邏輯




新媒體運營基礎(chǔ)教程
新媒體全能實戰(zhàn)規(guī)劃教材,新媒體運營入門經(jīng)典:用戶運營+產(chǎn)品運營+內(nèi)容運營+活動運營+社群運營+數(shù)據(jù)化運營,零基礎(chǔ)起步,帶你快速玩轉(zhuǎn)新媒體!內(nèi)容全面、案例豐富的基礎(chǔ)教程,幫你從小白升級到大神

小紅書運營:爆款內(nèi)容+實操案例+高效種草+引流變現(xiàn)
從零開始運營小紅書:4大引流方法+5大案例剖析+6大內(nèi)容創(chuàng)作要點,深入解析小紅書頭部博主運營案例,助你全方面掌握小紅書運營的底層邏輯,看這一本書就夠了。本書作者秋葉大叔指導(dǎo)的學(xué)員入局小紅書幾個月就收獲了數(shù)萬粉絲,打造出多篇爆款筆記,為剛剛?cè)刖中〖t書或正在觀望的待入局者提供了切實可行的經(jīng)驗。
活動截止時我們將從本文的留言中選出5位幸運粉絲贈送書籍~
注意哦,每人每月僅限一本書籍~
活動截止時間:2022年10月20日16:00整
兌獎截止時間:2022年10月21日16:00整
點擊關(guān)注公眾號,閱讀更多精彩內(nèi)容
