
淺談互聯(lián)網(wǎng)搜索之召回
一、背景
在搜索系統(tǒng)中,一般會(huì)把整個(gè)搜索系統(tǒng)劃分為召回和排序兩大子系統(tǒng)。本文會(huì)從宏觀上介紹召回系統(tǒng),并著重介紹語義召回。謹(jǐn)以此文,希望對(duì)從事和將要從事搜索行業(yè)的工作者帶來一些啟發(fā)與思考。
二、搜索系統(tǒng)召回方法
不同于推薦系統(tǒng),檢索系統(tǒng)是在輸入query的前提下,快速召回與query相關(guān)的文本,特點(diǎn)為要求是快,注重召回輕準(zhǔn)確。注意,在工業(yè)界考慮到用戶體驗(yàn),往往要求百毫秒以內(nèi)完成召回,甚至在地圖、電商類的sug 場景(邊輸入邊推薦提示)召回要求十毫秒內(nèi)完成。由此可見,召回在工業(yè)界的技術(shù)和工程要求比較高。在召回系統(tǒng)中往往采用多路召回構(gòu)建召回體系,當(dāng)前召回體系可以抽象為三大方向:
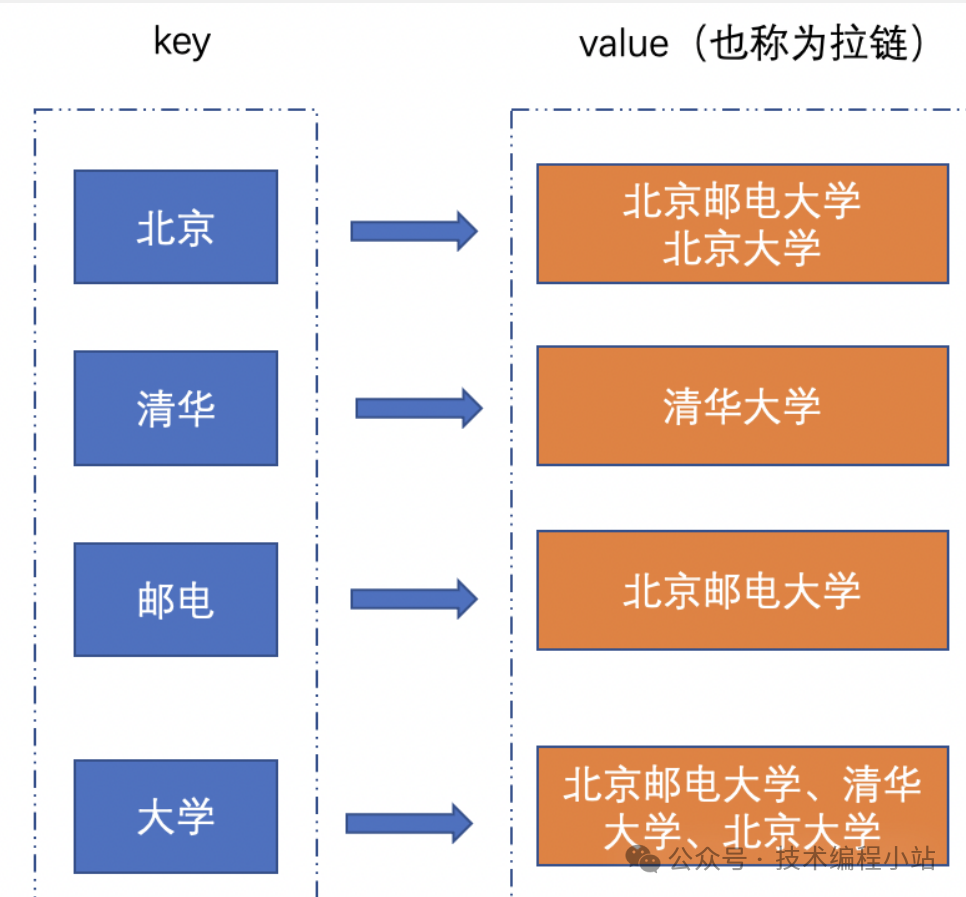
(1)倒排索引召回:倒排索引可以理解為 k,v 對(duì),對(duì)doc(文檔)分詞,每個(gè)詞可以看做 k,包含該詞的文檔可以看做 v,這樣就構(gòu)建了以詞為key的拉鏈,如下圖所示。當(dāng)用戶輸入query時(shí),根據(jù)用戶輸入query切詞粒度term進(jìn)行倒排拉鏈召回(如query 清華大學(xué),切分為清華和大學(xué)兩個(gè)term,會(huì)召回清華和大學(xué)相關(guān)文本),這是非常經(jīng)典和基礎(chǔ)的傳統(tǒng)召回方法。當(dāng)用戶輸入規(guī)范且輸入信息量較足的情況下,能夠準(zhǔn)確召回用戶所需要文檔。然而,在現(xiàn)實(shí)場景中,當(dāng)用戶存在輸入錯(cuò)誤以及輸入同義的情況下,就會(huì)存在召回率不足的問題,影響檢索體驗(yàn)。
(2)個(gè)性化召回:
基于倒排索引召回是嚴(yán)格基于文本詞粒度term結(jié)構(gòu)完成query和doc的匹配,而個(gè)性化的召回則是基于用戶行為的召回方法,最簡單的方法是統(tǒng)計(jì)用戶歷史query對(duì)文檔的點(diǎn)擊,根據(jù)點(diǎn)擊doc構(gòu)建個(gè)性化召回集合。個(gè)性化召回相對(duì)于文本召回的優(yōu)勢(shì)在于不需要精準(zhǔn)的term命中即可召回相關(guān)文檔,缺點(diǎn)在于如果相關(guān)性把握不好,會(huì)引入一些影響用戶體驗(yàn)的badcase。
(3)語義召回: 語義召回是搜索引擎發(fā)展的新趨勢(shì),能夠更加精準(zhǔn)地滿足用戶需求,因此受到了廣泛關(guān)注。語義召回是利用神經(jīng)網(wǎng)絡(luò)計(jì)算用戶輸入query和目標(biāo)doc之間的語義匹配度,并召回 top-k最相關(guān)的文檔。具體做法為,離線經(jīng)過模型對(duì) doc 向量化,并通過最近鄰建庫算法(fassi、hnsw等)構(gòu)建向量索引庫,在線通過模型對(duì)query進(jìn)行向量化,召回向量庫中相似度最高的N個(gè)文檔,這種方法雖然能夠一定程度上解決query泛化的問題,但是會(huì)因?yàn)檎倩氐臏?zhǔn)確率等問題引入雜質(zhì),召回后需要通過語義質(zhì)量控制雜質(zhì)問題。下面重點(diǎn)介紹一下語義召回。
三、語義召回
不同用戶甚至不同終端輸入千差萬別,query 往往包含漢字、拼音、阿拉伯?dāng)?shù)字,甚至五筆筆畫偏旁輸入。這些復(fù)雜的輸入組成千差萬別的query組合,對(duì)刻畫用戶搜索需求造成巨大挑戰(zhàn),當(dāng)前基于倒排索引的規(guī)則召回難以滿足這種復(fù)雜query的輸入。而語義召回是搜索引擎發(fā)展的新趨勢(shì),泛化能力甚至精準(zhǔn)召回能力近年來都變得越來越強(qiáng),因此受到了廣泛關(guān)注。下面介紹幾種搜索領(lǐng)域常見的召回方法,簡單歸納一下主要有傳統(tǒng)語義召回(DSSM雙塔為代表)、帶有場景信息的多源語義召回(圖語義召回、多模語義召回等),大模型預(yù)訓(xùn)練語義召回。具體如下:
(1)傳統(tǒng)語義召回 DSSM是一種典型的樸素雙塔召回,出自微軟,是當(dāng)前推廣搜算法最通用的向量召回算法之一。 ‘
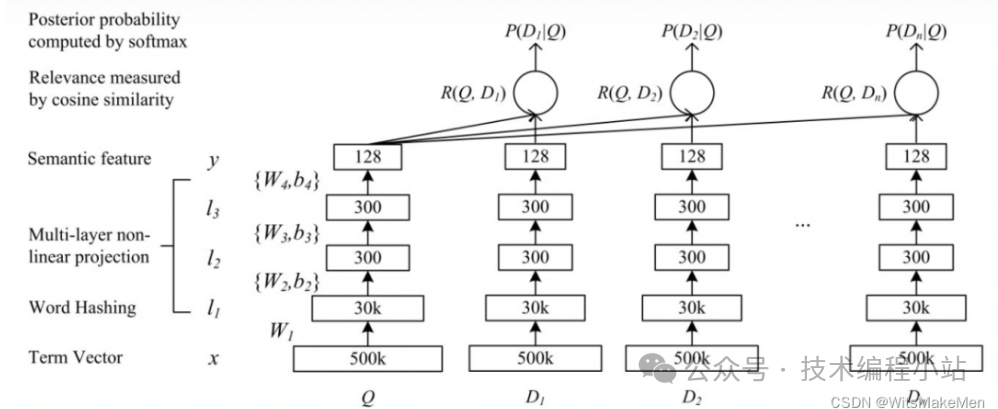
作為最典型的語義召回算法,將用戶側(cè)和文檔側(cè)特征組成的稀疏向量通過多層深度網(wǎng)絡(luò)壓縮到同一個(gè)低維向量空間,并通過余弦相似度來計(jì)算兩個(gè)語義向量的距離,最終訓(xùn)練出代表用戶和文檔在高維空間語義相似度模型。在線預(yù)測(cè)時(shí)利用訓(xùn)練好的用戶向量最近鄰檢索文檔向量返回top-k近似文檔。該方法的特點(diǎn)為用戶側(cè)和文檔側(cè)向量分離,工程落地容易,同時(shí)能夠利用深度學(xué)習(xí)的豐富表達(dá)能力,達(dá)到比較好的效果。
(2)多源語義召回 這里所謂的多源語義召回,是指融合多個(gè)場景信息,比如引入圖像的多模語義召回,引入只是圖譜的圖語義召回等。這些場景信息相當(dāng)于為模型提供輔助信息,在一些query輸入比較短語義不明確的場景中(比如搜索領(lǐng)域的sug)輔助信息尤為重要,因?yàn)槟軌蛱峁└S富的輸入表達(dá)。比如,在電商領(lǐng)域,對(duì)圖片進(jìn)行映射表達(dá)為向量;在地圖領(lǐng)域,對(duì)用戶的地理位置進(jìn)行表達(dá)作用用戶的輸入;在美食領(lǐng)域,對(duì)用戶的搜索歷史構(gòu)建只是圖譜,作為用戶的輸入,能夠達(dá)到千人千面的召回效果。
(3)大模型預(yù)訓(xùn)練語義召回 為了提升在檢索領(lǐng)域召回的效果,最近提出了使用預(yù)訓(xùn)練階段細(xì)粒度交互向粗粒度交互蒸餾的策略,訓(xùn)練出面向檢索場景的基礎(chǔ)大模型。同時(shí),進(jìn)一步以大模型為熱啟,基于海量點(diǎn)擊數(shù)據(jù)post-train的雙塔匹配、召回模型,在多項(xiàng)QT雙塔語義匹配、召回任務(wù)中取得效果提升。具有以下優(yōu)點(diǎn):充分利用海量數(shù)據(jù),尤其利用人工精標(biāo)的相關(guān)性數(shù)據(jù)進(jìn)行fine-tune,在偏文本的召回,排序等任務(wù)上取得了比較不錯(cuò)的效果。
四、總結(jié)與展望
本文介紹了搜索中的三大召回方法:倒排索引召回、個(gè)性化召回和語義召回,以及重點(diǎn)介紹了搜索領(lǐng)域召回新趨勢(shì)語義召回。倒排索引作為搜索領(lǐng)域的召回基石長久不衰,該方法簡單高效,能夠解決大多數(shù)召回場景case,但長尾Query的搜索會(huì)導(dǎo)致輸入意圖一致的相似詞無法解決。隨著語義召回的發(fā)展,不僅能夠解決長尾case,甚至具有代替倒排索引的能力,在一些大廠中,正不斷迭代語義召回,逐步下掉倒排索引,我相信在不就得將來,強(qiáng)大的語義召回會(huì)成成為搜索領(lǐng)域的主流。還是那句話,隨著新技術(shù)和新想法的不斷涌現(xiàn),搜索引擎還有很多可以完善的地方,需要你我共同建設(shè)。