
端到端半監(jiān)督目標檢測框架
點擊上方“視學(xué)算法”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達
導(dǎo)讀
本文是來自阿里團隊的工作,作者團隊重新審視SSOD并提出InstantTeaching,這是一個完全端到端且有效的SSOD框架,該框架使用即時偽標簽和擴展的弱-強數(shù)據(jù)增強功能在每次訓(xùn)練迭代中進行教學(xué)。
簡單介紹一下我們CVPR 2021的一項關(guān)于半監(jiān)督目標檢測方面的工作:
Instant-Teaching: An End-to-End Semi-Supervised Object Detection Framework
論文鏈接:https://arxiv.org/pdf/2103.11402.pdf
1. 背景
1.1 為什么需要半監(jiān)督學(xué)習(xí)
這些年,數(shù)據(jù)驅(qū)動的深度學(xué)習(xí)技術(shù)在各種視覺任務(wù)中(圖像分類、目標檢測,實例分割,視頻檢測等)大展身手,屠榜各類benchmark。然而,在實際落地這些深度學(xué)習(xí)技術(shù)時,我們會發(fā)現(xiàn),模型的性能嚴重依賴帶標注的訓(xùn)練數(shù)據(jù)。比如,在不同場景上線相同功能的檢測模型時,往往需要花費較大代價獲取足夠數(shù)量的標注數(shù)據(jù)來提高模型在相應(yīng)場景下的性能。
模型對數(shù)據(jù)的依賴主要體現(xiàn)在以下兩個方面:
對應(yīng)用場景一致數(shù)據(jù)的依賴:以人體檢測模型為例,在室外數(shù)據(jù)上訓(xùn)練的檢測器,在室內(nèi)場景的檢測效果往往差強人意;在白天數(shù)據(jù)上訓(xùn)練的檢測器,在夜晚場景下的效果通常也不會很好。 對數(shù)據(jù)規(guī)模的依賴: 大數(shù)據(jù)集訓(xùn)練的模型往往比小數(shù)據(jù)集的精度要高。
雖然有標注數(shù)據(jù)的獲取成本比較高,但是我們可以非常容易的獲取海量的無標注數(shù)據(jù),如何有效利用這些無標注數(shù)據(jù)來提高模型的性能,降低模型對標注數(shù)據(jù)的依賴?半監(jiān)督學(xué)習(xí)正是研究如何高效利用無標注數(shù)據(jù)的一個熱門研究方向。
1.2 現(xiàn)有的檢測半監(jiān)督工作
目前,最先進的檢測半監(jiān)督方面的工作,主要是基于self-training以及一致性約束。下面分別介紹其中的代表性工作。
1.2.1 基于一致性約束的方案
CSD[1]是當前基于一致性約束的檢測半監(jiān)督方面的代表性工作。通過對未標注數(shù)據(jù)做弱增強(flip),組成pair對輸入給檢測模型,然后對模型預(yù)測輸出的pair結(jié)果進行一致性約束,從而盡可能利用到這些未標注數(shù)據(jù)。
1.2.2 基于self-training的方案
STAC[2]是當前基于self-training的檢測半監(jiān)督方面的代表性工作。首先所有標注數(shù)據(jù)訓(xùn)練一個Teacher模型,然后在所有未標注數(shù)據(jù)上做Inference,并通過NMS和卡閾值的方式制備pseudo labels作為未標注數(shù)據(jù)的ground truth,然后將所有標注數(shù)據(jù)和未標注數(shù)據(jù)同時加入訓(xùn)練得到最終的模型,該方法簡單有效,是當前檢測半監(jiān)督方面的SOTA工作。
2. 我們的方案: Instant-Teaching
2.1 Motivation
如下圖所示,我們提出了端到端的檢測半監(jiān)督方案Instant-Teaching和增強版Instant-Teaching*:
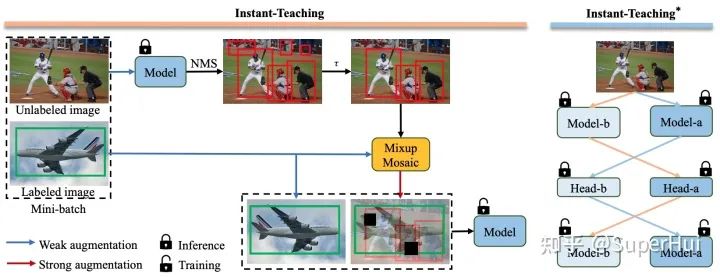
我們改進的motivation主要有三點:
我們發(fā)現(xiàn),現(xiàn)有的檢測半監(jiān)督方面的SOTA方案STAC,其偽標注pseudo labels通過離線獲得,并且在訓(xùn)練過程中是不更新的。這樣有一個問題,當訓(xùn)練的半監(jiān)督模型的精度已經(jīng)超過生成pseudo labels的模型時,繼續(xù)使用不更新的pseudo labels,會限制半監(jiān)督模型精度的進一步提升。 data augmentations 在半監(jiān)督學(xué)習(xí)中占據(jù)非常重要的位置,如何更有效的針對半監(jiān)督學(xué)習(xí)設(shè)計更適合的數(shù)據(jù)增強方式? pseudo labels中容易存在錯誤label,尤其是在訓(xùn)練初期,并且這種錯誤會在半監(jiān)督訓(xùn)練中累積,這種現(xiàn)象稱為confirmation bias問題,如何設(shè)計矯正策略去盡可能修正這些錯誤的pseudo labels?
針對這三個問題,我們的檢測半監(jiān)督方案如下:
針對問題1,我們采用在線偽標注更新的方式。隨著模型訓(xùn)練收斂,模型的精度提升的同時,在線生成的pseudo labels的質(zhì)量也會得到及時的提高,從而反過來進一步促進模型的學(xué)習(xí)。 為了更有效的對unlabel images 進行數(shù)據(jù)增強,我們采用在labeled images 和 unlabeled images 之間進行Mixup和Mosaic增強。 針對confirmation bias 問題,我們提出了Co-rectify的方案,即同時訓(xùn)練兩個模型,兩個模型分別為彼此檢查和糾正pseudo labels,從而有效抑制錯誤預(yù)測的累積,提高模型精度。值得注意的是,雖然在訓(xùn)練時,需要同時訓(xùn)練兩個模型,但是infernece時,只需要使用單個模型即可,因此,不影響模型推理的速度。
2.2 主要實驗結(jié)果
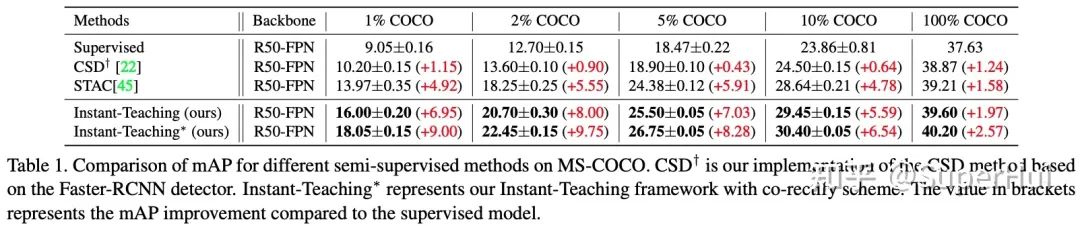
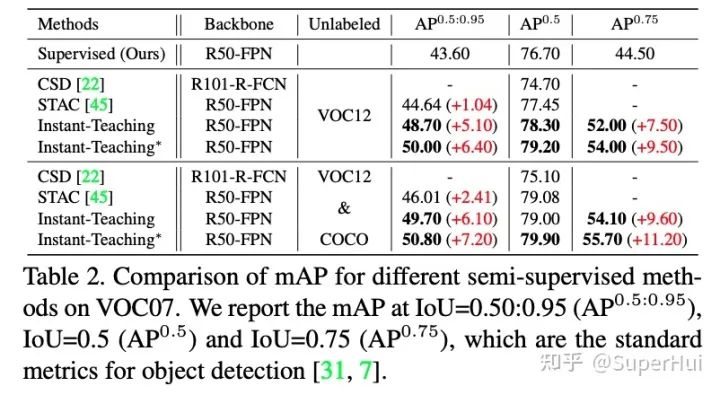
*更多實驗驗證,歡迎參考我們的論文原文:https://arxiv.org/pdf/2103.11402.pdf
[1]Consistency-based Semi-supervised Learning for Object Detection
[2]A Simple Semi-Supervised Learning Framework for Object Detection

點個在看 paper不斷!