
【機器學習】一文徹底搞懂自動機器學習AutoML:Auto-Sklearn
本文將系統(tǒng)全面的介紹自動機器學習的其中一個常用框架: Auto-Sklearn,介紹安裝及使用,分類和回歸小案例,以及一些用戶手冊的介紹。
AutoML
自動化機器學習AutoML 是機器學習中一個相對較新的領(lǐng)域,它主要將機器學習中所有耗時過程自動化,如數(shù)據(jù)預處理、最佳算法選擇、超參數(shù)調(diào)整等,這樣可節(jié)約大量時間在建立機器學習模型過程中。
自動機器學習 AutoML: 對于 ,令 表示特征向量, 表示對應的目標值。給定訓練數(shù)據(jù)集 和從與之具有相同數(shù)據(jù)分布中得出的測試數(shù)據(jù)集 的特征向量 ,以及資源預算 和損失度量 ,AutoML 問題是自動生成測試集的預測值 ,而 ? 給出了 AutoML 問題的解 的損失值。
AutoML,是為數(shù)據(jù)集發(fā)現(xiàn)數(shù)據(jù)轉(zhuǎn)換、模型和模型配置的最佳性能管道的過程。
AutoML 通常涉及使用復雜的優(yōu)化算法(例如貝葉斯優(yōu)化)來有效地導航可能模型和模型配置的空間,并快速發(fā)現(xiàn)對給定預測建模任務最有效的方法。它允許非專家機器學習從業(yè)者快速輕松地發(fā)現(xiàn)對于給定數(shù)據(jù)集有效甚至最佳的方法,而技術(shù)背景或直接輸入很少。
使用過 sklearn 的話,對于上面定義應該不難理解。下面再結(jié)合一個流程圖來進一步理解一下。

Auto-Sklearn
Auto-Sklearn是一個開源庫,用于在 Python 中執(zhí)行 AutoML。它利用流行的 Scikit-Learn 機器學習庫進行數(shù)據(jù)轉(zhuǎn)換和機器學習算法。
它是由Matthias Feurer等人開發(fā)的。并在他們 2015 年題為“efficient and robust automated machine learning 高效且穩(wěn)健的自動化機器學習[1]”的論文中進行了描述。
… we introduce a robust new AutoML system based on scikit-learn (using 15 classifiers, 14 feature preprocessing methods, and 4 data preprocessing methods, giving rise to a structured hypothesis space with 110 hyperparameters)
我們引入了一個基于 scikit-learn 的強大的新 AutoML 系統(tǒng)(使用 15 個分類器、14 個特征預處理方法和 4 個數(shù)據(jù)預處理方法,產(chǎn)生具有 110 個超參數(shù)的結(jié)構(gòu)化假設空間)。
Auto-Sklearn 的好處在于,除了發(fā)現(xiàn)為數(shù)據(jù)集執(zhí)行的數(shù)據(jù)預處理和模型之外,它還能夠從在類似數(shù)據(jù)集上表現(xiàn)良好的模型中學習,并能夠自動創(chuàng)建性能最佳的集合作為優(yōu)化過程的一部分發(fā)現(xiàn)的模型。
This system, which we dub AUTO-SKLEARN, improves on existing AutoML methods by automatically taking into account past performance on similar datasets, and by constructing ensembles from the models evaluated during the optimization.
這個我們稱之為 AUTO-SKLEARN 的系統(tǒng)通過自動考慮過去在類似數(shù)據(jù)集上的表現(xiàn),并通過在優(yōu)化期間評估的模型構(gòu)建集成,改進了現(xiàn)有的 AutoML 方法。
Auto-Sklearn 是改進了一般的 AutoML 方法,自動機器學習框架采用貝葉斯超參數(shù)優(yōu)化方法,有效地發(fā)現(xiàn)給定數(shù)據(jù)集的性能最佳的模型管道。
這里另外添加了兩個組件:
一個用于初始化貝葉斯優(yōu)化器的元學習( meta-learning)方法優(yōu)化過程中的自動集成( automated ensemble)方法
這種元學習方法是貝葉斯優(yōu)化的補充,用于優(yōu)化 ML 框架。對于像整個 ML 框架一樣大的超參數(shù)空間,貝葉斯優(yōu)化的啟動速度很慢。通過基于元學習選擇若干個配置來用于種子貝葉斯優(yōu)化。這種通過元學習的方法可以稱為熱啟動優(yōu)化方法。再配合多個模型的自動集成方法,使得整個機器學習流程高度自動化,將大大節(jié)省用戶的時間。從這個流程來看,讓機器學習使用者可以有更多的時間來選擇數(shù)據(jù)以及思考要處理的問題本身。
貝葉斯優(yōu)化
貝葉斯優(yōu)化的原理是利用現(xiàn)有的樣本在優(yōu)化目標函數(shù)中的表現(xiàn),構(gòu)建一個后驗模型。該后驗模型上的每一個點都是一個高斯分布,即有均值和方差。若該點是已有樣本點,則均值就是該點的優(yōu)化目標函數(shù)取值,方差為0。而其他未知樣本點的均值和方差是后驗概率擬合的,不一定接近真實值。那么就用一個采集函數(shù),不斷試探這些未知樣本點對應的優(yōu)化目標函數(shù)值,不斷更新后驗概率的模型。由于采集函數(shù)可以兼顧Explore/Exploit,所以會更多地選擇表現(xiàn)好的點和潛力大的點。因此,在資源預算耗盡時,往往能夠得到不錯的優(yōu)化結(jié)果。即找到局部最優(yōu)的優(yōu)化目標函數(shù)中的參數(shù)。
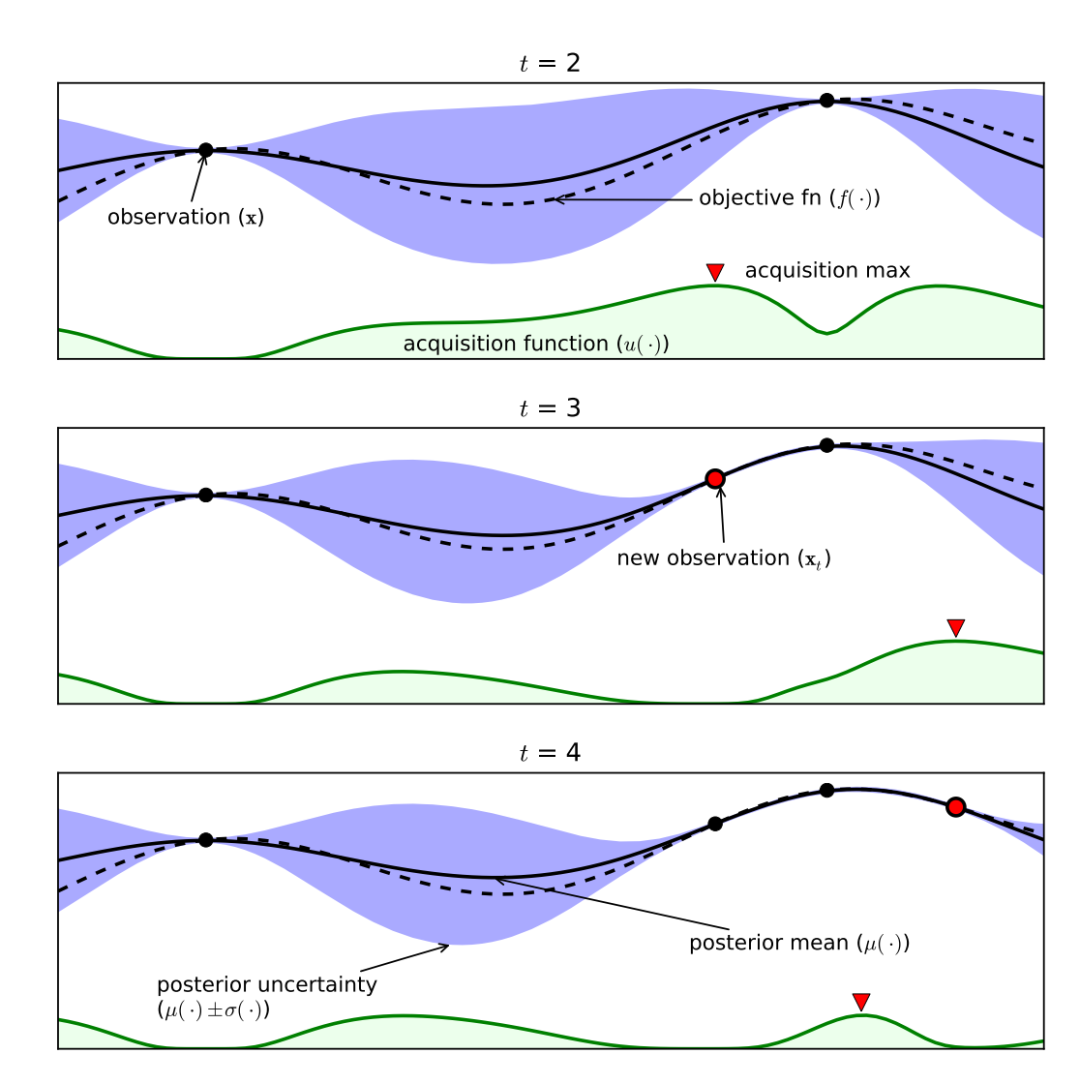
上圖是在一個簡單的 1D 問題上應用貝葉斯優(yōu)化的實驗圖,這些圖顯示了在經(jīng)過四次迭代后,高斯過程對目標函數(shù)的近似。我們以 t=3 為例分別介紹一下圖中各個部分的作用。
上圖 2 個 evaluations 黑點和一個紅色 evaluations,是三次評估后顯示替代模型的初始值估計,會影響下一個點的選擇,穿過這三個點的曲線可以畫出非常多條。黑色虛線曲線是實際真正的目標函數(shù) (通常未知)。黑色實線曲線是代理模型的目標函數(shù)的均值。紫色區(qū)域是代理模型的目標函數(shù)的方差。綠色陰影部分指的是acquisition function的值,選取最大值的點作為下一個采樣點。只有三個點,擬合的效果稍差,黑點越多,黑色實線和黑色虛線之間的區(qū)域就越小,誤差越小,代理模型越接近真實模型的目標函數(shù)。
安裝和使用 Auto-Sklearn
Auto-sklearn 提供了開箱即用的監(jiān)督型自動機器學習。從名字可以看出,auto-sklearn 是基于機器學習庫 scikit-learn 構(gòu)建的,可為新的數(shù)據(jù)集自動搜索學習算法,并優(yōu)化其超參數(shù)。因此,它將機器學習使用者從繁瑣的任務中解放出來,使其有更多時間專注于實際問題。
這里可以參考auto-sklearn官方文檔[2]。
ubuntu
>>>?sudo?apt-get?install?build-essential?swig
>>>?conda?install?gxx_linux-64?gcc_linux-64?swig
>>>?curl?`https://raw.githubusercontent.com/automl/auto-sklearn/master/requirements.txt`?|?xargs?-n?1?-L?1?pip?install
>>>?pip?install?auto-sklearn
anaconda
pip?install?auto-sklearn
安裝后,我們可以導入庫并打印版本號以確認它已成功安裝:
#?print?autosklearn?version
import?autosklearn
print('autosklearn:?%s'?%?autosklearn.__version__)
你的版本號應該相同或更高。
autosklearn:?0.6.0
根據(jù)預測任務的不同,是分類還是回歸,可以創(chuàng)建和配置 AutoSklearnClassifier[3] 或 AutoSklearnRegressor[4]類的實例,將其擬合到數(shù)據(jù)集上,僅此而已。然后可以使用生成的模型直接進行預測或保存到文件(使用pickle)以供以后使用。
AutoSklearn類參數(shù)
AutoSklearn 類提供了大量的配置選項作為參數(shù)。
默認情況下,搜索將在搜索過程中使用數(shù)據(jù)集的train-test拆分,為了速度和簡單性,這里建議使用默認值。
參數(shù)n_jobs可以設置為系統(tǒng)中的核心數(shù),如有 8 個核心,則為n_jobs=8。
一般情況下,優(yōu)化過程將持續(xù)運行,并以分鐘為單位進行測量。默認情況下,它將運行一小時。
這里建議將time_left_for_this_task參數(shù)此任務的最長時間(希望進程運行的秒數(shù))。例如,對于許多小型預測建模任務(少于 1,000 行的數(shù)據(jù)集)來說,不到 5-10 分鐘可能就足夠了。如果沒有為此參數(shù)指定任何內(nèi)容,則該過程將優(yōu)化過程將持續(xù)運行,并以分鐘為單位進行測量,將運行一小時,即60分鐘。本案例通過 per_run_time_limit 參數(shù)將分配給每個模型評估的時間限制為 30 秒。例如:
#?define?search
model?=?AutoSklearnClassifier(time_left_for_this_task=5*60,?
??????????????????????????????per_run_time_limit=30,
??????????????????????????????n_jobs=8)
另外還有其他參數(shù),如ensemble_size、initial_configurations_via_metalearning,可用于微調(diào)分類器。默認情況下,上述搜索命令會創(chuàng)建一組表現(xiàn)最佳的模型。為了避免過度擬合,我們可以通過更改設置 ensemble_size = 1 和initial_configurations_via_metalearning = 0來禁用它。我們在設置分類器時排除了這些以保持方法的簡單。
在運行結(jié)束時,可以訪問模型列表以及其他詳細信息。sprint_statistics()函數(shù)總結(jié)了最終模型的搜索和性能。
#?summarize?performance
print(model.sprint_statistics())
分類任務
在本節(jié)中,我們將使用 Auto-Sklearn 來發(fā)現(xiàn)聲納數(shù)據(jù)集的模型。
聲納數(shù)據(jù)集[5]是一個標準的機器學習數(shù)據(jù)集,由 208 行數(shù)據(jù)和 60 個數(shù)字輸入變量和一個具有兩個類值的目標變量組成,例如二進制分類。
使用具有三個重復的重復分層 10 倍交叉驗證的測試工具,樸素模型可以達到約 53% 的準確度。性能最佳的模型可以在相同的測試工具上實現(xiàn)大約 88% 的準確度。這提供了該數(shù)據(jù)集的預期性能界限。
該數(shù)據(jù)集涉及預測聲納返回是否指示巖石或模擬礦井。
#?summarize?the?sonar?dataset
from?pandas?import?read_csv
#?load?dataset
dataframe?=?read_csv(data,?header=None)
#?split?into?input?and?output?elements
data?=?dataframe.values
X,?y?=?data[:,?:-1],?data[:,?-1]
print(X.shape,?y.shape)
運行該示例會下載數(shù)據(jù)集并將其拆分為輸入和輸出元素。可以看到有 60 個輸入變量的 208 行數(shù)據(jù)。
(208, 60) (208,)
首先,將數(shù)據(jù)集拆分為訓練集和測試集,目標在訓練集上找到一個好的模型,然后評估在保留測試集上找到的模型的性能。
#?split?into?train?and?test?sets
X_train,?X_test,?y_train,?y_test?=?train_test_split(X,?y,?test_size=0.33,?random_state=1)
使用以下命令從 autosklearn 導入分類模型。
from?autosklearn.classification?import?AutoSklearnClassifier
AutoSklearnClassifier配置為使用 8 個內(nèi)核運行 5 分鐘,并將每個模型評估限制為 30 秒。
#?define?search
model?=?AutoSklearnClassifier(time_left_for_this_task=5*60,
??????????????????????????????per_run_time_limit=30,?n_jobs=8,
??????????????????????????????tmp_folder='/temp/autosklearn_classification_example_tmp')
這里提供一個臨時的日志保存路徑,我們可以在以后使用它來打印運行詳細信息。
然后在訓練數(shù)據(jù)集上執(zhí)行搜索。
#?perform?the?search
model.fit(X_train,?y_train)
報告搜索和最佳性能模型的摘要。
#?summarize
print(model.sprint_statistics())
可以使用以下命令為搜索考慮的所有模型打印排行榜。
#?leaderboard
print(model.leaderboard())
可以使用以下命令打印有關(guān)所考慮模型的信息。
print(model.show_models())
我們還可以使用SMOTE、集成學習(bagging、boosting)、NearMiss 算法等技術(shù)來解決數(shù)據(jù)集中的不平衡問題。
最后評估在測試數(shù)據(jù)集上模型的性能。
#?evaluate?best?model
y_pred?=?model.predict(X_test)
acc?=?accuracy_score(y_test,?y_pred)
print("Accuracy:?%.3f"?%?acc)
還可以打印集成的最終分數(shù)和混淆矩陣。
#?Score?of?the?final?ensemble
from?sklearn.metrics?import?accuracy_score
m1_acc_score=?accuracy_score(y_test,?y_pred)
m1_acc_score
from?sklearn.metrics?import?confusion_matrix,?accuracy_score
y_pred=?model.predict(X_test)
conf_matrix=?confusion_matrix(y_pred,?y_test)
sns.heatmap(conf_matrix,?annot=True)
在運行結(jié)束時,會打印一個摘要,顯示評估了 1,054 個模型,最終模型的估計性能為 91%。
auto-sklearn results:
Dataset name: f4c282bd4b56d4db7e5f7fe1a6a8edeb
Metric: accuracy
Best validation score: 0.913043
Number of target algorithm runs: 1054
Number of successful target algorithm runs: 952
Number of crashed target algorithm runs: 94
Number of target algorithms that exceeded the time limit: 8
Number of target algorithms that exceeded the memory limit: 0
然后在holdout數(shù)據(jù)集上評估模型,發(fā)現(xiàn)分類準確率達到了 81.2% ,這是相當熟練的。
Accuracy: 0.812
回歸任務
在本節(jié)中,使用 Auto-Sklearn 來挖掘汽車保險數(shù)據(jù)集的模型。
汽車保險數(shù)據(jù)集[6]是一個標準的機器學習數(shù)據(jù)集,由 63 行數(shù)據(jù)組成,一個數(shù)字輸入變量和一個數(shù)字目標變量。
使用具有三個重復的重復分層 10 折交叉驗證的測試工具,樸素模型可以實現(xiàn)約 66 的平均絕對誤差 (MAE)。性能最佳的模型可以在相同的測試工具上實現(xiàn)約 28 的 MAE . 這提供了該數(shù)據(jù)集的預期性能界限。
該數(shù)據(jù)集涉及根據(jù)不同地理區(qū)域的索賠數(shù)量預測索賠總額(數(shù)千瑞典克朗)。
可以使用與上一節(jié)相同的過程,盡管我們將使用AutoSklearnRegressor類而不是AutoSklearnClassifier。
默認情況下,回歸器將優(yōu)化 指標。如果需要使用平均絕對誤差或 MAE ,可以在調(diào)用fit()函數(shù)時通過metric參數(shù)指定它。
#?example?of?auto-sklearn?for?the?insurance?regression?dataset
from?pandas?import?read_csv
from?sklearn.model_selection?import?train_test_split
from?sklearn.metrics?import?mean_absolute_error
from?autosklearn.regression?import?AutoSklearnRegressor
from?autosklearn.metrics?import?mean_absolute_error?as?auto_mean_absolute_error
#?load?dataset
dataframe?=?read_csv(data,?header=None)
#?split?into?input?and?output?elements
data?=?dataframe.values
data?=?data.astype('float32')
X,?y?=?data[:,?:-1],?data[:,?-1]
#?split?into?train?and?test?sets
X_train,?X_test,?y_train,?y_test?=?train_test_split(X,?y,?
????????????????????????????????????????????????????test_size=0.33,?
????????????????????????????????????????????????????random_state=1)
#?define?search
model?=?AutoSklearnRegressor(time_left_for_this_task=5*60,?
?????????????????????????????per_run_time_limit=30,?n_jobs=8)
#?perform?the?search
model.fit(X_train,?y_train,?metric=auto_mean_absolute_error)
#?summarize
print(model.sprint_statistics())
#?evaluate?best?model
y_hat?=?model.predict(X_test)
mae?=?mean_absolute_error(y_test,?y_hat)
print("MAE:?%.3f"?%?mae)
在運行結(jié)束時,將打印一個摘要,顯示評估了 1,759 個模型,最終模型的估計性能為 29 的 MAE。
auto-sklearn results:
Dataset name: ff51291d93f33237099d48c48ee0f9ad
Metric: mean_absolute_error
Best validation score: 29.911203
Number of target algorithm runs: 1759
Number of successful target algorithm runs: 1362
Number of crashed target algorithm runs: 394
Number of target algorithms that exceeded the time limit: 3
Number of target algorithms that exceeded the memory limit: 0
保存訓練好的模型
上面訓練的分類和回歸模型可以使用 python 包 Pickle 和 JobLib 保存。然后可以使用這些保存的模型直接對新數(shù)據(jù)進行預測。我們可以將模型保存為:
1、Pickle
import?pickle
#?save?the?model?
filename?=?'final_model.sav'?
pickle.dump(model,?open(filename,?'wb'))
這里的"wb"參數(shù)意味著我們正在以二進制模式將文件寫入磁盤。此外,我們可以將此保存的模型加載為:
#load?the?model
loaded_model?=?pickle.load(open(filename,?'rb'))
result?=?loaded_model.score(X_test,?Y_test)
print(result)
這里的"rb"命令表示我們正在以二進制模式讀取文件
2、JobLib
同樣,我們可以使用以下命令將訓練好的模型保存在 JobLib 中。
import?joblib
#?save?the?model?
filename?=?'final_model.sav'
joblib.dump(model,?filename)
我們還可以稍后重新加載這些保存的模型,以預測新數(shù)據(jù)。
#?load?the?model?from?disk
load_model?=?joblib.load(filename)
result?=?load_model.score(X_test,?Y_test)
print(result)
用戶手冊地址
下面我們從幾個方面來解讀一下用戶手冊[7]。
時間和內(nèi)存限制
auto-sklearn的一個關(guān)鍵功能是限制允許scikit-learn算法使用的資源(內(nèi)存和時間)。特別是對于大型數(shù)據(jù)集(算法可能需要花費幾個小時并進行機器交換),重要的是要在一段時間后停止評估,以便在合理的時間內(nèi)取得進展。因此,設置資源限制是優(yōu)化時間和可以測試的模型數(shù)量之間的權(quán)衡。
盡管auto-sklearn減輕了手動超參數(shù)調(diào)整的速度,但用戶仍然必須設置內(nèi)存和時間限制。對于大多數(shù)數(shù)據(jù)集而言,大多數(shù)現(xiàn)代計算機上的3GB或6GB內(nèi)存限制已足夠。對于時間限制,很難給出明確的指導原則。如果可能的話,一個很好的默認值是總時限為一天,單次運行時限為30分鐘。
可以在auto-sklearn/issues/142[8]中找到更多準則。
限制搜索空間
除了使用所有可用的估計器外,還可以限制 auto-sklearn 的搜索空間。下面示例展示了如何排除所有預處理方法并將配置空間限制為僅使用隨機森林。
import?autosklearn.classification
automl?=?autosklearn.classification.AutoSklearnClassifier(
????include_estimators=["random_forest",],?
???exclude_estimators=None,
????include_preprocessors=["no_preprocessing",?],?
????exclude_preprocessors=None)
automl.fit(X_train,?y_train)
predictions?=?automl.predict(X_test)
注意: 用于標識估計器和預處理器的字符串是不帶 .py 的文件名。
關(guān)閉預處理
auto-sklearn 中的預處理分為數(shù)據(jù)預處理和特征預處理。數(shù)據(jù)預處理包括分類特征的獨熱編碼,缺失值插補以及特征或樣本的歸一化。這些步驟目前無法關(guān)閉。特征預處理是單個特征變換器,可實現(xiàn)例如特征選擇或?qū)⑻卣髯儞Q到不同空間(如PCA)。如上例所示,特征預處理可以通過設置include_preprocessors=["no_preprocessing"] 將其關(guān)閉。
重采樣策略
可以在 auto-sklearn/examples/ 中找到使用維持數(shù)據(jù)集和交叉驗證的示例。
結(jié)果檢查
Auto-sklearn 允許用戶檢查訓練的結(jié)果和產(chǎn)看相關(guān)的統(tǒng)計信息。以下示例展示了如何打印不同的統(tǒng)計信息以進行相應檢查。
import?autosklearn.classification
automl?=?autosklearn.classification.AutoSklearnClassifier()
automl.fit(X_train,?y_train)
automl.cv_results_
automl.sprint_statistics()
automl.show_models()
cv_results_返回一個字典,其中的鍵作為列標題,值作為列,可以將其導入到pandas的一個DataFrame類型數(shù)據(jù)中。sprint_statistics()可以打印出數(shù)據(jù)集名稱、使用的度量以及通過運行auto-sklearn獲得的最佳驗證分數(shù)。此外,它還會打印成功和不成功算法的運行次數(shù)。通過調(diào)用 show_models(),可以打印最終集成模型產(chǎn)生的結(jié)果。
并行計算
auto-sklearn支持通過共享文件系統(tǒng)上的數(shù)據(jù)共享來并行執(zhí)行。在這種模式下,SMAC算法通過在每次迭代后將其訓練數(shù)據(jù)寫入磁盤來共享其模型的訓練數(shù)據(jù)。在每次迭代的開始,SMAC都會加載所有新發(fā)現(xiàn)的數(shù)據(jù)點。我們提供了一個實現(xiàn)scikit-learn的n_jobs功能的示例,以及一個有關(guān)如何手動啟動多個auto-sklearn實例的示例。
在默認模式下,auto-sklearn已使用兩個核心。第一個用于模型構(gòu)建,第二個用于在每次新的機器學習模型完成訓練后構(gòu)建整體。序列示例顯示了如何以一次僅使用一個內(nèi)核的方式順序運行這些任務。
此外,根據(jù)scikit-learn和numpy的安裝,模型構(gòu)建過程最多可以使用所有內(nèi)核。這種行為是auto-sklearn所不希望的,并且很可能是由于從pypi安裝了numpy作為二進制輪子(請參見此處)。執(zhí)行export OPENBLAS_NUM_THREADS=1應該禁用這種行為,并使numpy一次僅使用一個內(nèi)核。
Vanilla auto-sklearn
auto-sklearn 主要是基于 scikit-learn 的封裝。因此,可以遵循 scikit-learn 中的持久化示例。
為了獲得在資料 Efficient and Robust Automated Machine Learning 中使用的 vanilla auto-sklearn,設置ensemble_size = 1 和 initial_configurations_via_metalearning=0。
import?autosklearn.classification
automl?=?autosklearn.classification.AutoSklearnClassifier(
????ensemble_size=1,?initial_configurations_via_metalearning=0)
集成的大小設為 1 將導致始終選擇在驗證集上的測試性能最佳的單一模型。將初始配置的元學習設置為 0,將使得 auto-sklearn 使用常規(guī)的 SMAC 算法來設置新的超參數(shù)配置。
參考資料
efficient and robust automated machine learning: https://papers.nips.cc/paper/5872-efficient-and-robust-automated-machine-learning
[2]auto-sklearn官方文檔: https://automl.github.io/auto-sklearn/master/installation.html
[3]AutoSklearnClassifier: https://automl.github.io/auto-sklearn/master/api.html#classification
[4]AutoSklearnRegressor: https://automl.github.io/auto-sklearn/master/api.html#regression
[5]聲納數(shù)據(jù)集: https://gitee.com/yunduodatastudio/picture/raw/master/data/auto-sklearn.png
[6]汽車保險數(shù)據(jù)集: https://gitee.com/yunduodatastudio/picture/raw/master/data/auto-sklearn.png
[7]用戶手冊: https://automl.github.io/auto-sklearn/master/manual.html#manual
[8]auto-sklearn/issues/142: https://github.com/automl/auto-sklearn/issues/142
[9]https://cloud.tencent.com/developer/article/1630703
[10]https://machinelearningmastery.com/auto-sklearn-for-automated-machine-learning-in-python/
往期精彩回顧
適合初學者入門人工智能的路線及資料下載 (圖文+視頻)機器學習入門系列下載 中國大學慕課《機器學習》(黃海廣主講) 機器學習及深度學習筆記等資料打印 《統(tǒng)計學習方法》的代碼復現(xiàn)專輯 AI基礎(chǔ)下載 機器學習交流qq群955171419,加入微信群請掃碼: