
一文詳解LLM評估:大模型評測什么、在哪評測、如何評測?
自谷歌2017年發(fā)布的Transformer網(wǎng)絡(luò)結(jié)構(gòu)以來,僅用五年多時間全球已迅速成長出龐大的大模型技術(shù)群,衍生出涵蓋各種技術(shù)架構(gòu)、各種模態(tài)、各種場景的大模型家族。
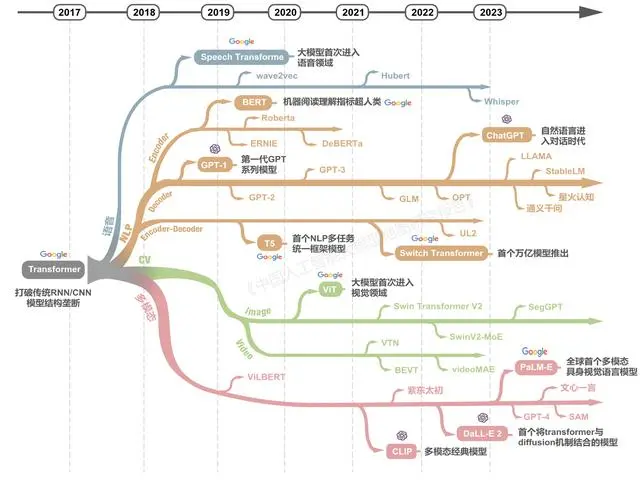
圖注:中美引領(lǐng)全球大模型發(fā)展
從全球已發(fā)布的大模型分布來看,中國和美國大幅領(lǐng)先,超過全球總數(shù)的80%,美國在大模型數(shù)量方面始終居全球最高。美國谷歌、OpenAI等機構(gòu)不斷引領(lǐng)大模型技術(shù)前沿。歐洲、俄羅斯、以色列、韓國等地越來越多的研發(fā)團隊也在投入大模型的研發(fā)。
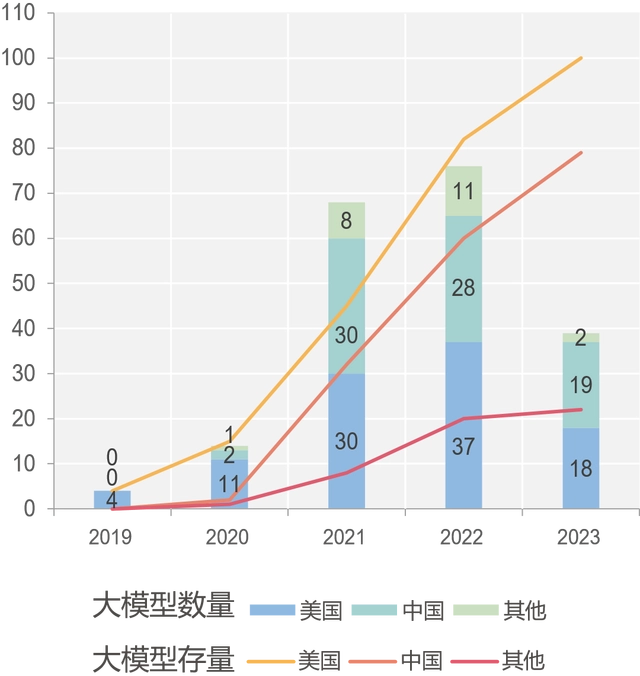
圖注:中國大模型呈現(xiàn)蓬勃發(fā)展態(tài)勢
5月,國家科技部下屬的中國科學(xué)技術(shù)信息研究所,發(fā)布了《中國人工智能大模型地圖研究報告》。內(nèi)容顯示,截至5月28日,國內(nèi)10億級參數(shù)規(guī)模以上基礎(chǔ)大模型至少已發(fā)布79個。

圖注:中國大模型分布地圖
7月,國際咨詢公司IDC發(fā)布《AI大模型技術(shù)能力評估報告2023》,調(diào)研了14家中國市場主流大模型技術(shù)廠商。IDC評估報告圍繞產(chǎn)品技術(shù)、服務(wù)生態(tài)以及行業(yè)應(yīng)用三大維度,考察大模型的10余項指標(biāo),其中“算法模型”和“行業(yè)覆蓋”成為衡量大模型能力極其重要的兩個指標(biāo)。其中,「百度文心大模型3.5」拿下12項指標(biāo)的7個滿分,綜合評分第一,算法模型第一,行業(yè)覆蓋第一。阿里云在11項指標(biāo)中獲得通用能力、服務(wù)能力、創(chuàng)新能力、生態(tài)合作等6項滿分,是唯一一家“服務(wù)能力”滿分廠商。
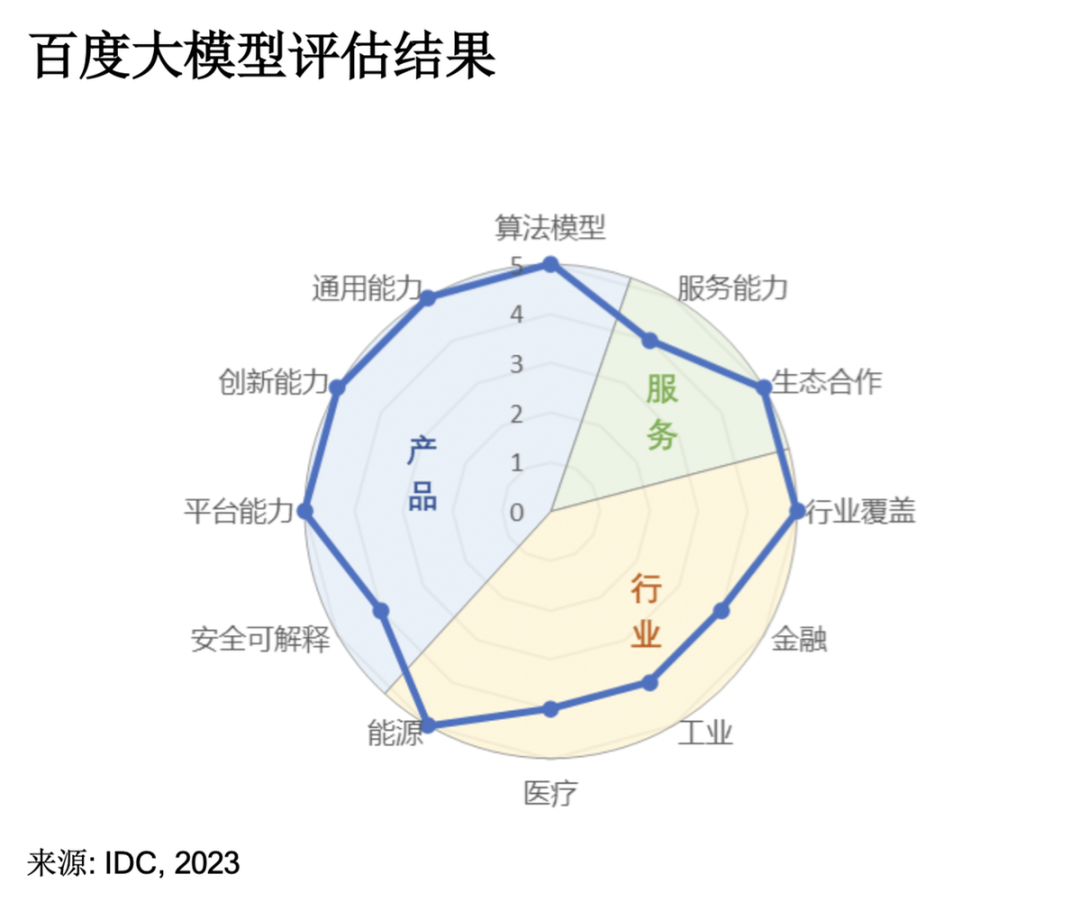

圖注:阿里巴巴大模型評估結(jié)果
ChatGPT 帶火了大模型應(yīng)用的相關(guān)研究,評測基準(zhǔn)也受到極大關(guān)注。在每個大模型貼上“技術(shù)領(lǐng)先”、“性能第一”等標(biāo)簽時,我們不免質(zhì)疑:如何直觀地評判哪一款大模型在技術(shù)和性能上更為卓越?那些宣稱“第一”的評估標(biāo)準(zhǔn)與數(shù)據(jù)來源又是怎樣的?
前不久,微軟亞洲研究院公開了介紹大模型評測領(lǐng)域的綜述文章《A Survey on Evaluation of Large Language Models》。該論文一共調(diào)研了219篇文獻,以評測對象 (what to evaluate)、評測領(lǐng)域 (where to evaluate)、評測方法 (How to evaluate)和目前的評測挑戰(zhàn)等幾大方面對大模型的評測進行了詳細(xì)的梳理和總結(jié)。

論文:A Survey on Evaluation of Large Language Models
機構(gòu):微軟亞洲研究院
論文地址:https://arxiv.org/pdf/2307.03109.pdf
開源鏈接:https://github.com/MLGroupJLU/LLM-eval-survey
大模型評測相關(guān)研究:https://llm-eval.github.io/


根據(jù)不完全統(tǒng)計(見下圖),大模型的評測方面發(fā)表的文章呈上升趨勢,越來越多的研究著眼于設(shè)計更科學(xué)、更好度量、更準(zhǔn)確的評測方式來對大模型的能力進行更深入的了解。
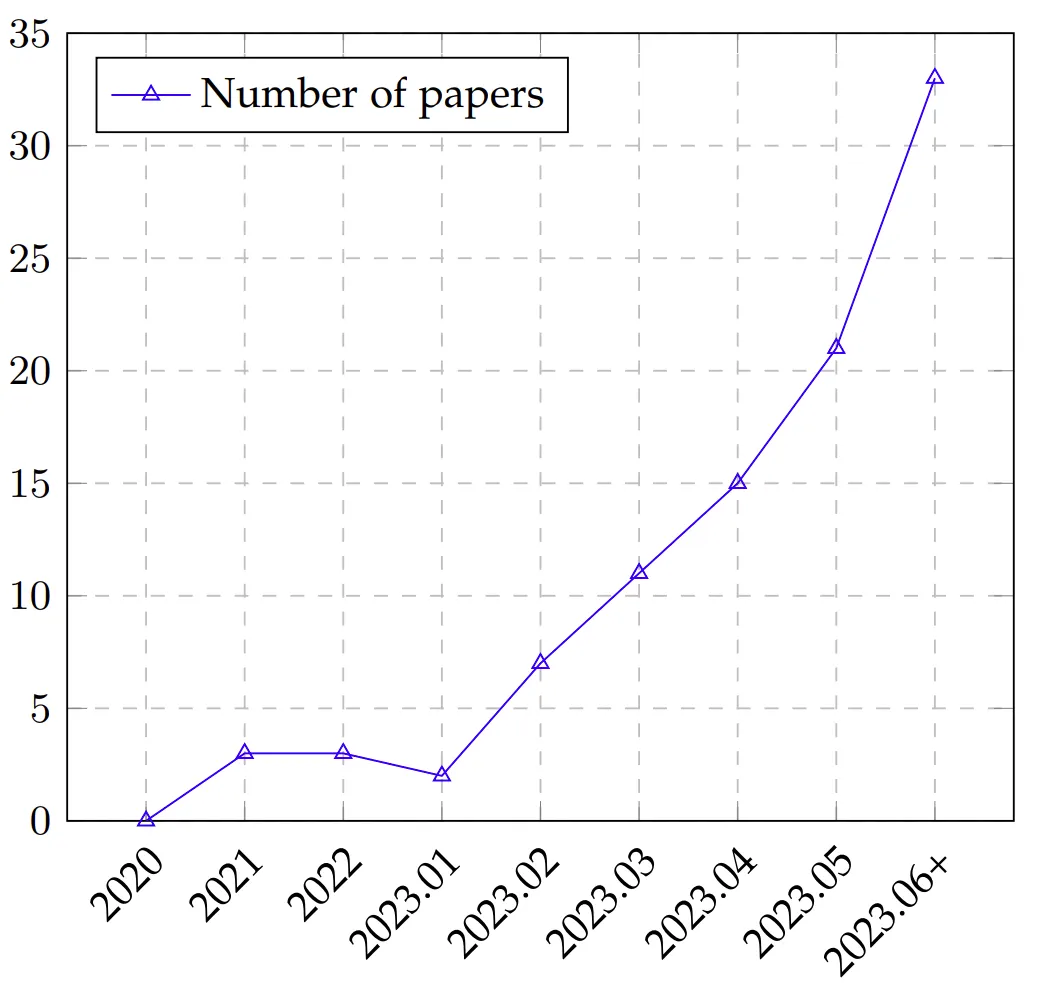
圖注:LLM 評估論文隨時間的趨勢,從 2020 年到 2023 年 6 月(6 月數(shù)據(jù)包含 7 月的部分論文)
這篇論文作為大型語言模型(Large language models, LLMs)評測的首次全面綜述,主要從三個方面對現(xiàn)有工作進行了探索:

圖注:AI 模型的評估過程
評測內(nèi)容 (What to evaluate),對海量的 LLMs 評測任務(wù)進行分類并總結(jié)評測結(jié)果;
評測領(lǐng)域 (Where to evaluate),對 LLMs 評測常用的數(shù)據(jù)集和基準(zhǔn)進行了總結(jié);
評測方法 (How to evaluate),總結(jié)了目前流行的兩種 LLMs 評測方法。
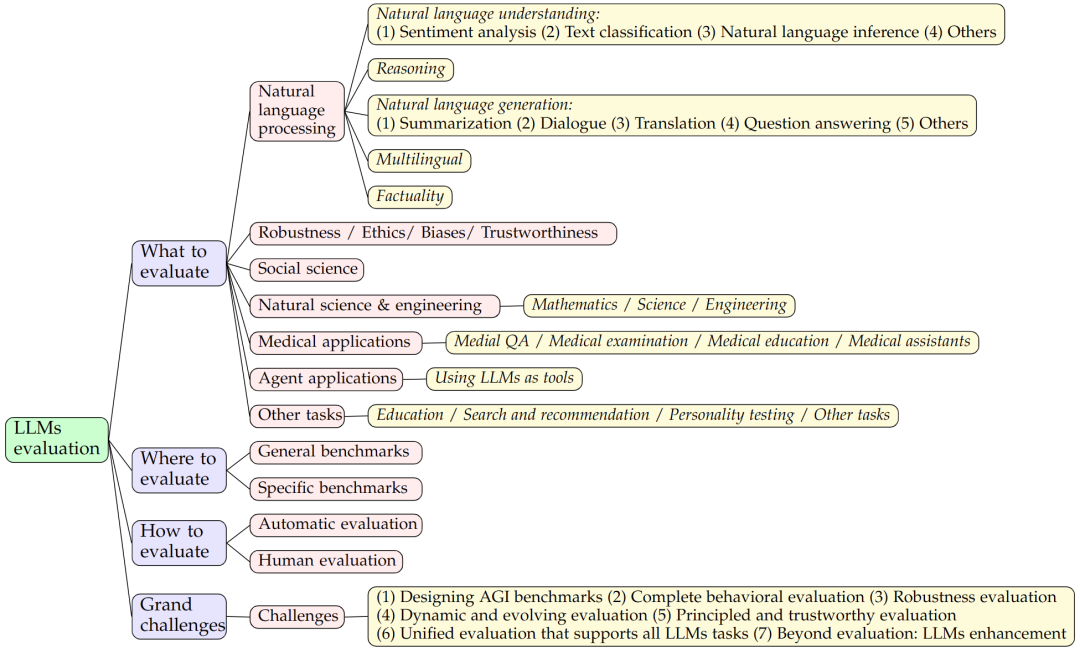
圖 1:論文研究框架
通俗來講,大模型是一個能力很強的函數(shù) f,與之前的機器學(xué)習(xí)模型并無本質(zhì)不同。那么,為什么要研究大模型的評測?大模型評測跟以前的機器學(xué)習(xí)模型評測有何不同?
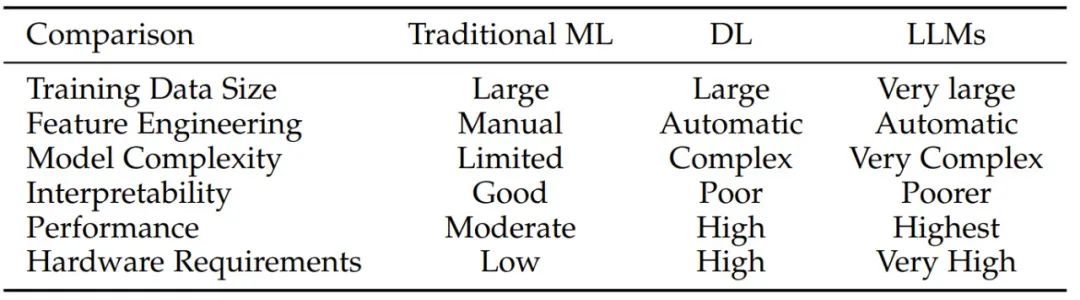
圖注:對比傳統(tǒng)機器學(xué)習(xí)、深度學(xué)習(xí)和 LLM
大型語言模型(Large language models, LLMs)背后的核心模塊是 Transformer 中的自注意力模塊,一大關(guān)鍵特性是上下文學(xué)習(xí),最初開發(fā)也是為了提升 AI 在自然語言處理任務(wù)上的性能。正因為此,大多數(shù)評估研究關(guān)注的也主要是自然語言任務(wù)。
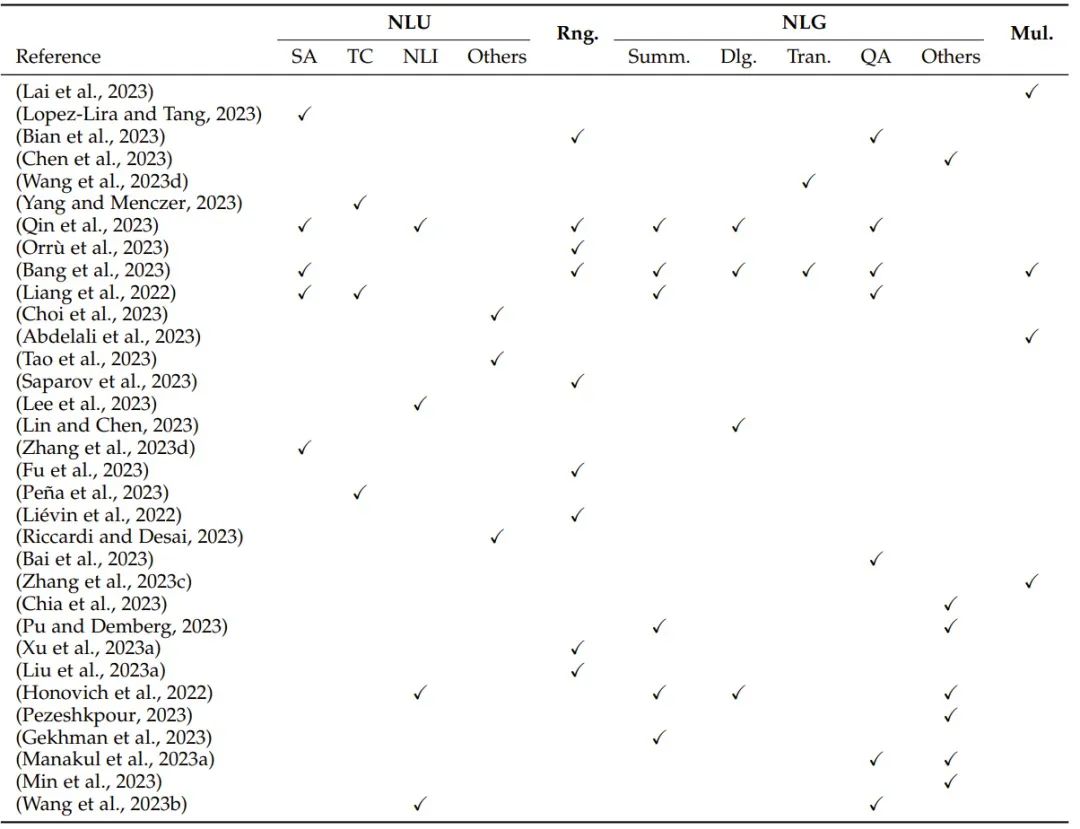
圖注:表 2:基于自然語言處理任務(wù)的評估概況:NLU(自然語言理解,包括 SA(情感分析)、TC(文本分類)、NLI(自然語言推理)和其它 NLU 任務(wù))、Rng.(推理)、NLG(自然語言生成,包括 Summ.(摘要)、Dlg.(對話)、Tran.(翻譯)、QA(問答)和其它 NLG 任務(wù))和 Mul.(多語言任務(wù))
為了更清晰地展示 LLMs 的能力水平,文章將現(xiàn)有的任務(wù)劃分為以下7個不同的類別:
自然語言處理:包括自然語言理解、推理、自然語言生成和多語言任務(wù);
魯棒性、倫理、偏見和真實性;
醫(yī)學(xué)應(yīng)用:包括醫(yī)學(xué)問答、醫(yī)學(xué)考試、醫(yī)學(xué)教育和醫(yī)學(xué)助手;
社會科學(xué)
自然科學(xué)與工程:包括數(shù)學(xué)、通用科學(xué)和工程;
代理應(yīng)用:將 LLMs 作為代理使用;
其他應(yīng)用
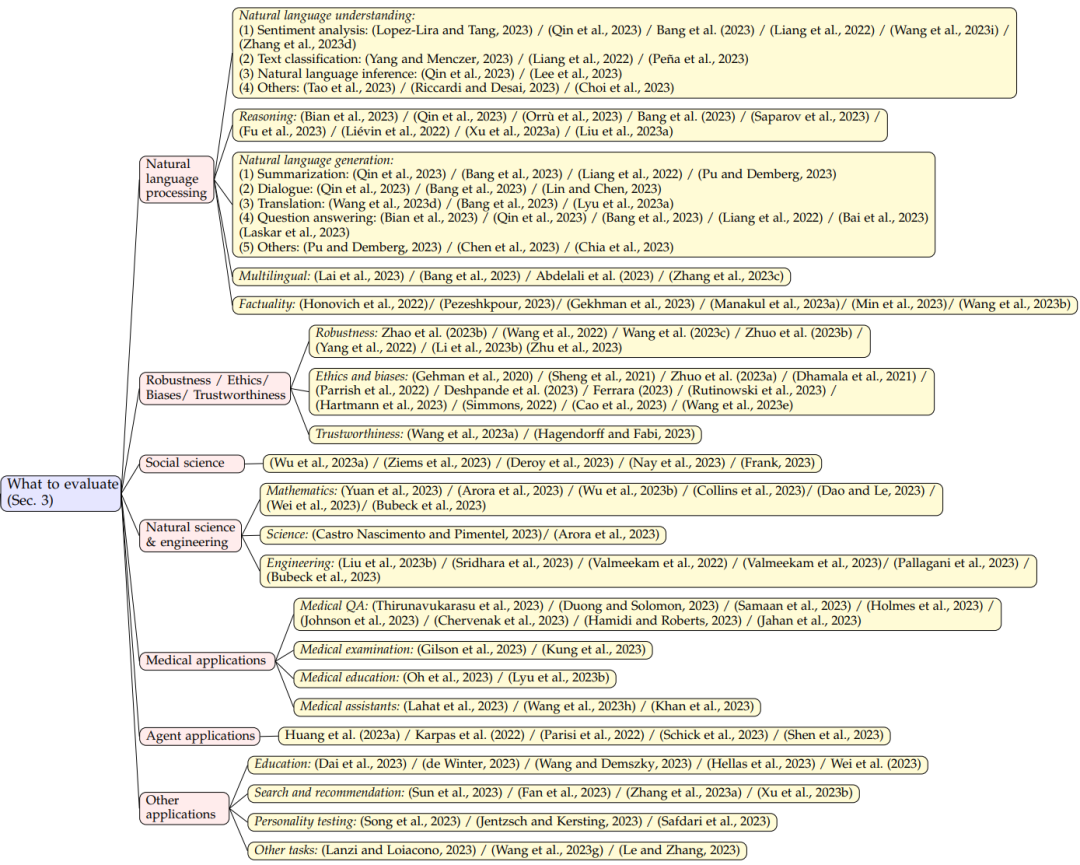
圖注:評測內(nèi)容
LLM 評估數(shù)據(jù)集的作用是測試和比較不同語言模型在各種任務(wù)上的性能。GLUE 和 SuperGLUE 等數(shù)據(jù)集的目標(biāo)是模擬真實世界的語言處理場景,其中涵蓋多種不同任務(wù),如文本分類、機器翻譯、閱讀理解和對話生成。
隨著 LLMs 基準(zhǔn)測試的不斷發(fā)展,目前已有許多受歡迎的評測基準(zhǔn)。論文一共列出了19個流行的基準(zhǔn)測試,每個都側(cè)重于不同的方面和評估標(biāo)準(zhǔn),為其各自的領(lǐng)域做出了貢獻。
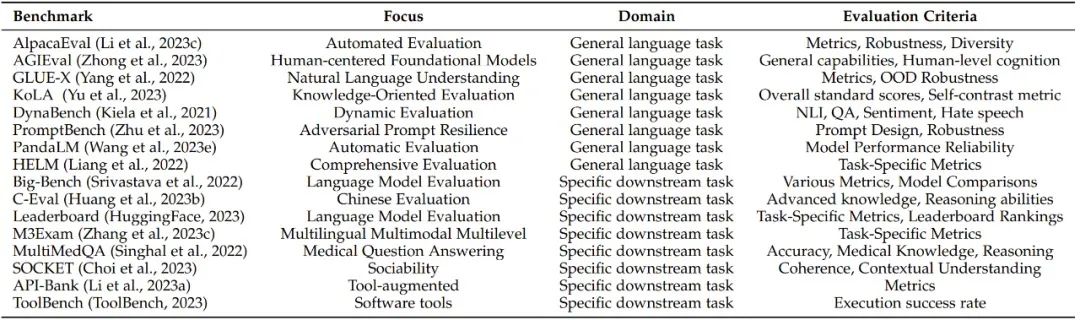
圖注:LLM 評估基準(zhǔn)概況
為了更好地總結(jié),研究員將這些基準(zhǔn)測試分為兩類:通用基準(zhǔn)(General benchmarks)和具體基準(zhǔn)(Specific benchmarks),其中不乏一些深具盛名的大模型基準(zhǔn),比如來自LMSYS Org的Chatbot Arena。
Chatbot Arena,被行業(yè)人士普遍認(rèn)為是最具公平性與廣泛接受度的平臺。LMSYS Org,是一個開放的研究組織,由加州大學(xué)伯克利分校、加州大學(xué)圣地亞哥分校和卡內(nèi)基梅隆大學(xué)合作創(chuàng)立。該評測方式的設(shè)計靈感來源于國際象棋等競技游戲中盛行的ElO評分系統(tǒng)。通過積累大量的用戶投票,它能夠更為貼近實際場景地評估各模型的綜合表現(xiàn)。
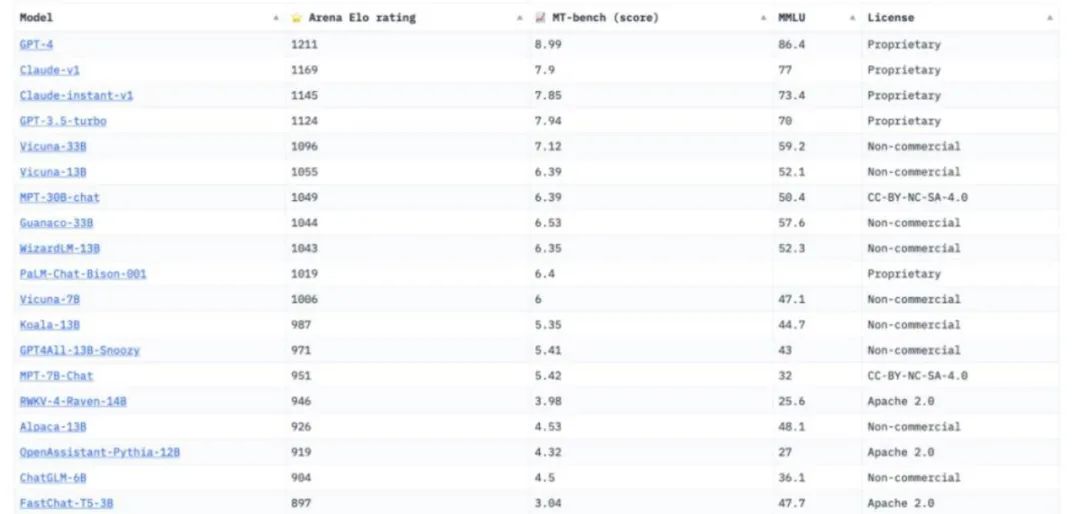
圖注:Chatbot Arena
論文中提到了通用基準(zhǔn)C-Eval,這是一個全面的中文基礎(chǔ)模型評估套件。它包含了13948個多項選擇題,涵蓋了52個不同的學(xué)科和四個難度級別,該項目由上海交通大學(xué)、清華大學(xué)、愛丁堡大學(xué)共同完成。
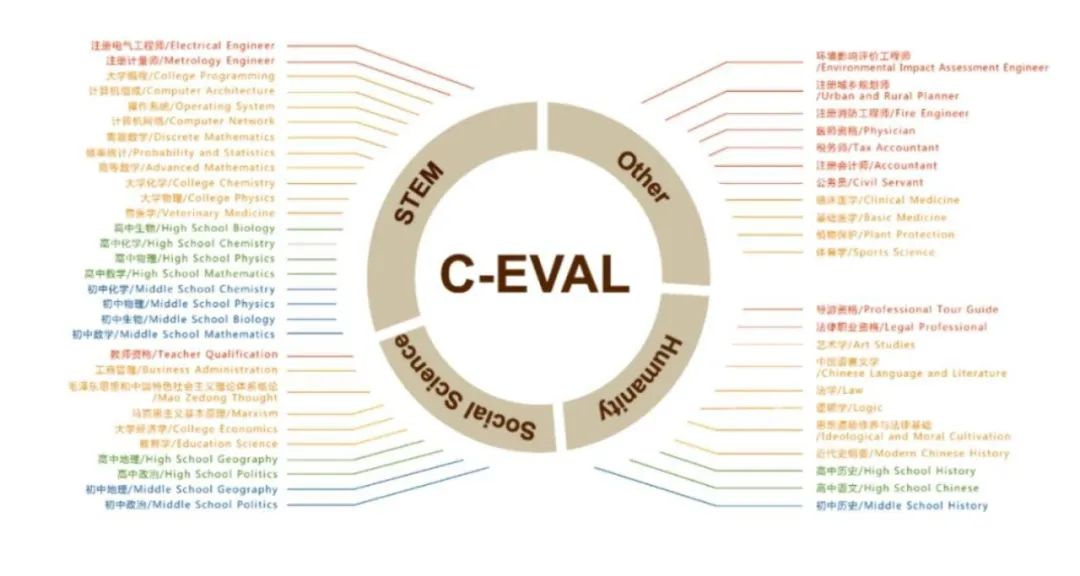
圖注:通用基準(zhǔn)C-Eval
除了通用任務(wù)的基準(zhǔn)測試外,還存在一些專為某些下游任務(wù)設(shè)計的具體基準(zhǔn)測試。譬如,MultiMedQA是一個醫(yī)學(xué)問答基準(zhǔn)測試,重點關(guān)注醫(yī)學(xué)檢查、醫(yī)學(xué)研究和消費者健康問題。
文章介紹了兩種常用的評測方法:自動評測和人工評測。
自動評測:基于計算機算法和自動生成的指標(biāo),能夠快速且高效地評測模型的性能。
人工評測:側(cè)重于人類專家的主觀判斷和質(zhì)量評測,能夠提供更深入、細(xì)致的分析和意見。
現(xiàn)有的協(xié)議不足以透徹地評估 LLM,還有許多挑戰(zhàn)有待攻克,論文對大模型評測介紹了以下7個重大挑戰(zhàn)。
設(shè)計 AGI 基準(zhǔn)測試。什么是可靠、可信任、可計算的能正確衡量 AGI 任務(wù)的評測指標(biāo)?
對完整行為進行評估。除去標(biāo)準(zhǔn)任務(wù)之外,如何衡量 AGI 在其他任務(wù),如機器人交互中的表現(xiàn)?
穩(wěn)健性評測。目前的大模型對輸入的 prompt 非常不魯棒,如何構(gòu)建更好的魯棒性評測準(zhǔn)則?
動態(tài)演化評測。大模型的能力在不斷進化、也存在記憶訓(xùn)練數(shù)據(jù)的問題。如何設(shè)計更動態(tài)更進化式的評測方法?
有原則且值得信任的評測。如何保證所設(shè)計的評測準(zhǔn)則是可信任的?
支持所有 LLM 任務(wù)的統(tǒng)一評測。大模型的評測并不是終點、如何將評測方案與大模型有關(guān)的下游任務(wù)進行融合?
超越評估:LLM 強化。評測出大模型的優(yōu)缺點之后,如何開發(fā)新的算法來增強其在某方面的表現(xiàn)?
論文總結(jié)了 LLMs 在不同任務(wù)中的成功和失敗案例。
LLM 在生成文本方面展現(xiàn)出熟練度,能生成流暢和精確的語言表達。
LLM 能出色地應(yīng)對涉及語言理解的任務(wù),比如情感分析和文本分類。
LLM 具備強大的語境理解能力,能夠生成與輸入一致的連貫回答。
LLM 在多種自然語言處理任務(wù)上的表現(xiàn)都值得稱贊,包括機器翻譯、文本生成和問答。
LLM 可能會在生成過程中展現(xiàn)出偏見和不準(zhǔn)確的問題,從而得到帶偏見的輸出。
LLM 在理解復(fù)雜邏輯和推理任務(wù)方面的能力有限,經(jīng)常在復(fù)雜的上下文中發(fā)生混淆或犯錯。
LLM 處理大范圍數(shù)據(jù)集和長時記憶的能力有限,這可能使其難以應(yīng)對很長的文本和涉及長期依賴的任務(wù)。
LLM 整合實時和動態(tài)信息的能力有限,這讓它們不太適合用于需要最新知識或快速適應(yīng)變化環(huán)境的任務(wù)。
LLM 對 prompt 很敏感,尤其是對抗性 prompt,這會激勵研究者開發(fā)新的評估方法和算法,以提升 LLM 的穩(wěn)健性。
在文本摘要領(lǐng)域,可以觀察到 LLMs 可能在特定的評測指標(biāo)上表現(xiàn)出低于標(biāo)準(zhǔn)的性能,這可能歸因于那些特定指標(biāo)的內(nèi)在限制或不足。
LLMs 在反事實任務(wù)中 的表現(xiàn)不令人滿意。
參考:
https://www.zhihu.com/question/601328258/answer/3128340188