
無需深度學(xué)習(xí)即可提取圖像特征
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

圖像分類是數(shù)據(jù)科學(xué)中最熱門的領(lǐng)域之一,在本文中,我們將分享一些將圖像轉(zhuǎn)換為特征向量的技術(shù),可以在每個(gè)分類模型中使用。
VATbox,作為n一個(gè)我們所暗示的,涉及增值稅問題(以及更多)的發(fā)票世界的問題之一是,我想知道有多少發(fā)票是一個(gè)形象?為了簡化問題,我們將問一個(gè)二元問題,圖像中是否有一張發(fā)票或同一圖像中有多張發(fā)票?為什么不使用文本(例如TF-IDF)?為什么只使用圖像像素作為輸入?因此,有時(shí)我們沒有可靠的OCR,有時(shí)OCR花費(fèi)了我們金錢,我們不確定我們是否要使用它。.當(dāng)然,對于本文來說,演示經(jīng)典方法從圖像中提取特征的力量。
import cv2gray_image = cv2.imread(image_path, 0)img = image.load_img(image_path, target_size=(self.IMG_SIZE, self.IMG_SIZE))
想象一下,你們正在密切注視著圖像,可以看到附近的像素。因此,如果我們的圖像包含文本,則可以看到單詞之間和行之間的白色像素。如果我們的意圖是(至少在這種情況下)決定圖像中是否有一張發(fā)票,我們可以從一定距離看圖像-這將有助于忽略圖像中的“無聊”空白。
# scale parameter – the relative size of the reduced image after the reduction.image_width = int(gray_image.shape[1] * scale_percent)image_height = int(gray_image.shape[0] * scale_percent)dim = (width, height)gray_reduced_image = cv2.resize(gray_image, dim, interpolation=cv2.INTER_NEAREST)cv2.imshow('image', resized)cv2.waitKey(0)
我們可以這樣考慮-每個(gè)圖像的多個(gè)發(fā)票或單個(gè)發(fā)票之間的差異可以轉(zhuǎn)換為圖像中的信息量,因此,我們可以期望每個(gè)類別中的平均熵得分不同。
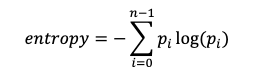
其中n是灰度級的總和(8位圖像為256),p是像素具有灰度級i的概率。
from sklearn.metrics.cluster import entropyentropy1 = entropy(gray_image)entropy2 = entropy(gray_reduced_image)
Dbscan算法具有在圖像空間中查找密集區(qū)域并將其分配給一個(gè)群集的能力。它的最大優(yōu)點(diǎn)是它可以自行確定數(shù)據(jù)中的類數(shù)。我們將從dbscan模型創(chuàng)建3個(gè)功能:
類的數(shù)量(這里的假設(shè)是,類的數(shù)量過多將表明圖像中的發(fā)票數(shù)量眾多)。 噪聲像素的數(shù)量。 模型中的輪廓分?jǐn)?shù)(輪廓分?jǐn)?shù)衡量每個(gè)像素的分類程度,我們將取所有像素的平均輪廓分?jǐn)?shù))
from sklearn.cluster import DBSCANfrom sklearn import metricsthr, imgage = cv2.threshold(gray_reduced_image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)img_df = pd.DataFrame(img).unstack().reset_index().rename(columns={'level_0': 'y', 'level_1': 'x'})img_df = img_df[img_df[0] == 0]X = image_df[['y', 'x']]db = DBSCAN(eps=1, min_samples=5).fit(X)# plt.scatter(image_df['y'], image_df['x'], c=db.labels_, s=3)# plt.show(block=False)core_samples_mask = np.zeros_like(db.labels_, dtype=bool)core_samples_mask[db.core_sample_indices_] = Truelabels = db.labels_# Number of clusters in labels, ignoring noise if present.n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)n_noise_ = list(labels).count(-1)image_df['class'] = labels# print('Estimated number of clusters: %d' % n_clusters_)# print('Estimated number of noise points: %d' % n_noise_)# print("Silhouette Coefficient: %0.3f" %metrics.silhouette_score(image_df, labels))features = pd.Series([n_clusters_, n_noise_, metrics.silhouette_score(image_df, labels)])
我們(灰度)圖像中的每個(gè)像素的值都在0到255之間(在我們的示例中,零被視為白色,而255被視為黑色)。如果要計(jì)算“零”交叉,則需要對圖像進(jìn)行閾值處理—即設(shè)置一個(gè)值,以使較高的值將分類為255(黑色),而較低的值將分類為0(白色)。在我們的案例中,我使用了Otsu閾值。在執(zhí)行圖像閾值處理之后,我們將獲得零和一作為像素,我們可以將其視為數(shù)據(jù)幀并將每一列和每一行相加:
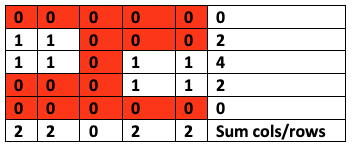
現(xiàn)在,假設(shè)1代表文本區(qū)域(黑色像素),0代表空白區(qū)域(白色像素)。現(xiàn)在,我們可以計(jì)算每行/列總和從任何正數(shù)變?yōu)榱愕拇螖?shù)。
img = img / 255df = pd.DataFrame(img)pixels_sum_dim1 = (1 - img_df).sum()pixels_sum_dim2 = (1 - img_df).T.sum()zero_corssings1 = pixels_sum_dim1[pixels_sum_dim1 == 0].reset_index()['index'].rolling(2).apply(np.diff).dropna()zero_corssings1 = zero_corssings1[zero_corssings1 != 1]num_zero1 = zero_corssings1.shape[0]zero_corssings2 = pixels_sum_dim2[pixels_sum_dim2 == 0].reset_index()['index'].rolling(2).apply(np.diff).dropna()zero_corssings2 = zero_corssings2[zero_corssings2 != 1]num_zero2 = zero_corssings2.shape[0]features = pd.Series([num_zero1, num_zero2])
如果我們將圖像視為信號,則可以使用信號處理工具箱中的一些工具。我們將使用重新采樣的想法來創(chuàng)建更多功能。
怎么做?首先,我們需要將圖像從矩陣轉(zhuǎn)換為一維向量。其次,由于每個(gè)圖像都有不同的形狀,因此我們需要為所有圖像設(shè)置一個(gè)重采樣大小-在本例中。
使用插值,我們可以將信號表示為一個(gè)連續(xù)函數(shù),然后我們將對其進(jìn)行重新采樣,采樣之間的間隔為

其中x表示圖像信號,C表示要重采樣的點(diǎn)數(shù)。
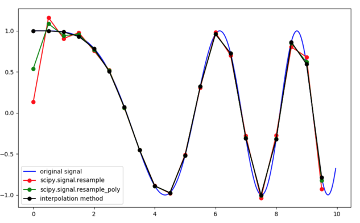
from scipy.signal import resampledim1_normalized_hist = pd.Series(resample(df.sum(), 16))dim2_normalized_hist = pd.Series(resample(df.T.sum(), 16))print(dim1_normalized_hist)print(dim2_normalized_hist)
離散余弦變換(DCT)用在不同頻率振蕩的余弦函數(shù)之和表示數(shù)據(jù)點(diǎn)的有限序列。DCT與DFT(離散傅立葉變換)不同,只有實(shí)部。DCT,尤其是DCT-II,通常用于信號和圖像處理,尤其是用于有損壓縮,因?yàn)樗哂袕?qiáng)大的“能量壓縮”特性。在典型的應(yīng)用中,大多數(shù)信號信息傾向于集中在DCT的幾個(gè)低頻分量中。我們可以在圖像和轉(zhuǎn)置圖像上計(jì)算DCT向量,并取前k個(gè)元素。
from scipy.fftpack import dctdim1_dct = pd.Series(dct(df.sum())[0:8]).to_frame().Tdim2_dct = pd.Series(dct(df.T.sum())[0:8]).to_frame().Tdim1_normalize_dct = pd.Series(normalize(dim1_dct)[0].tolist())dim2_normalize_dct = pd.Series(normalize(dim2_dct)[0].tolist())print(dim1_normalize_dct)print(dim2_normalize_dct)
如今,CNN的使用正在增長,在本文中,我們試圖解釋和演示一些以老式方式從圖像創(chuàng)建特征的經(jīng)典方法,了解圖像處理的基礎(chǔ)是一種很好的做法,因?yàn)橛袝r(shí)它更容易比將其推入網(wǎng)中更準(zhǔn)確。本文是對圖像的處理以及如何使用像素并從像素中提取知識的介紹,也許是對大腦的刺激。
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細(xì)分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~