
MySQL 如何優(yōu)化 CPU 消耗?
點(diǎn)擊上方藍(lán)色“程序猿DD”,選擇“設(shè)為星標(biāo)”
回復(fù)“資源”獲取獨(dú)家整理的學(xué)習(xí)資料!

作者 |?jiaxin
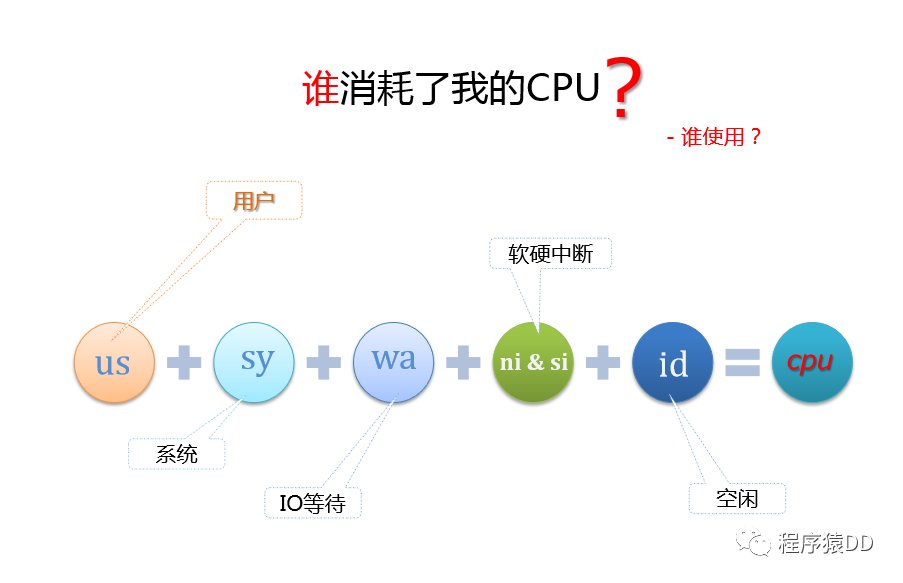
誰(shuí)在消耗cpu?
用戶+系統(tǒng)+IO等待+軟硬中斷+空閑
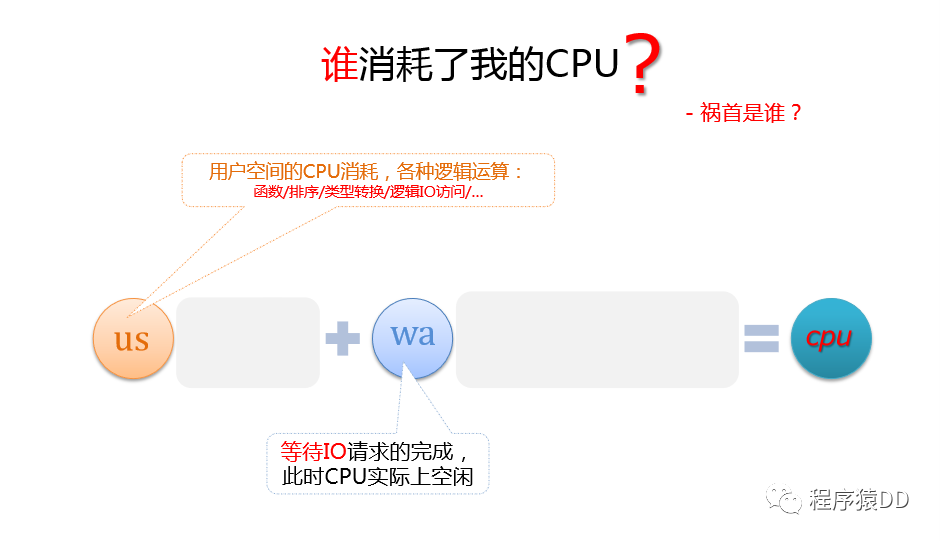
# 禍?zhǔn)资钦l(shuí)?
用戶
用戶空間CPU消耗,各種邏輯運(yùn)算
正在進(jìn)行大量tps ?
函數(shù)/排序/類型轉(zhuǎn)化/邏輯IO訪問…
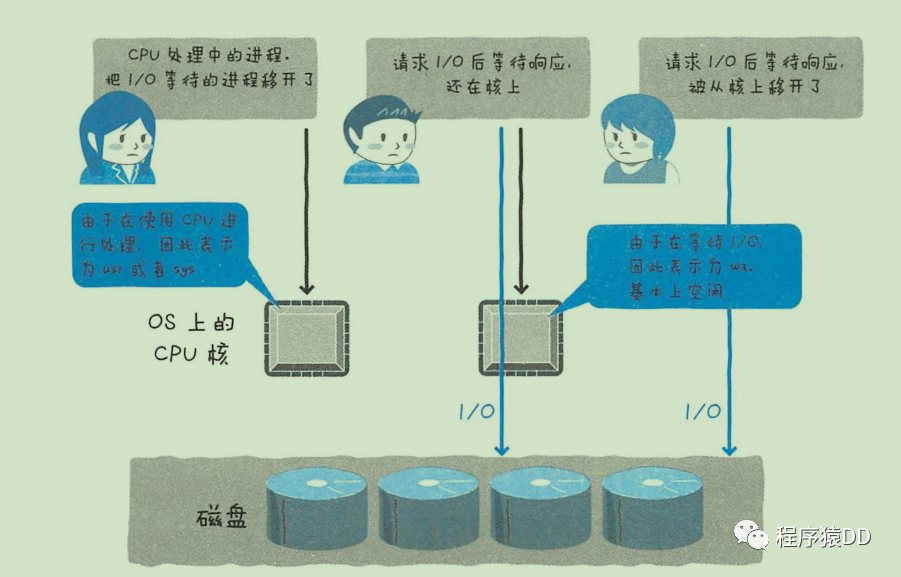
IO等待
等待IO請(qǐng)求的完成
此時(shí)CPU實(shí)際上空閑 ?
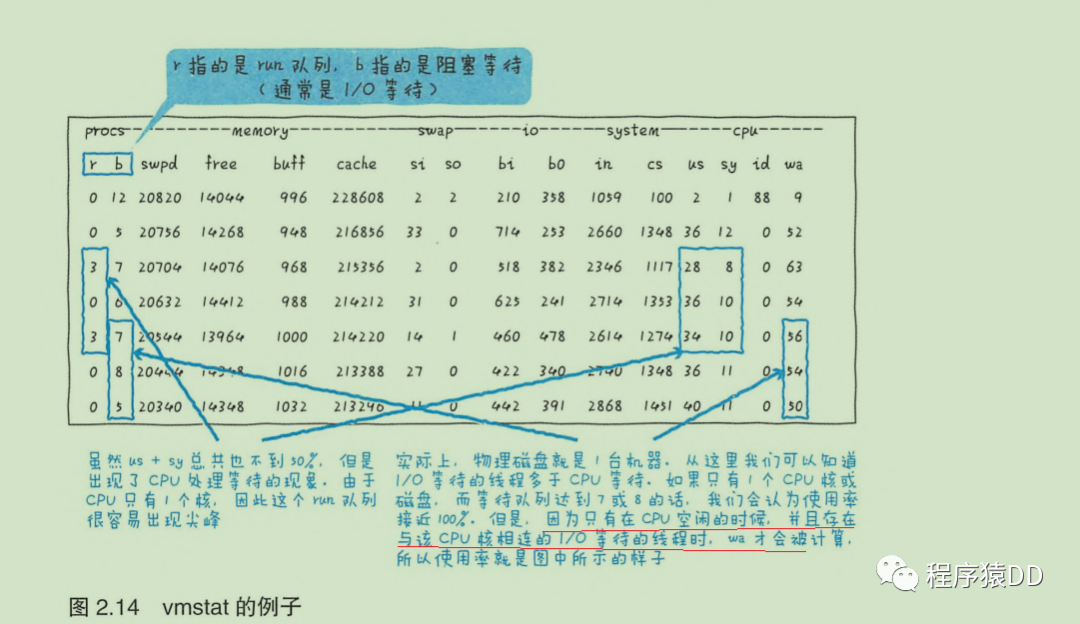
如vmstat中的wa 很高。但I(xiàn)O等待增加,wa也不一定會(huì)上升(請(qǐng)求I/O后等待響應(yīng),但進(jìn)程從核上移開了)
產(chǎn)生影響
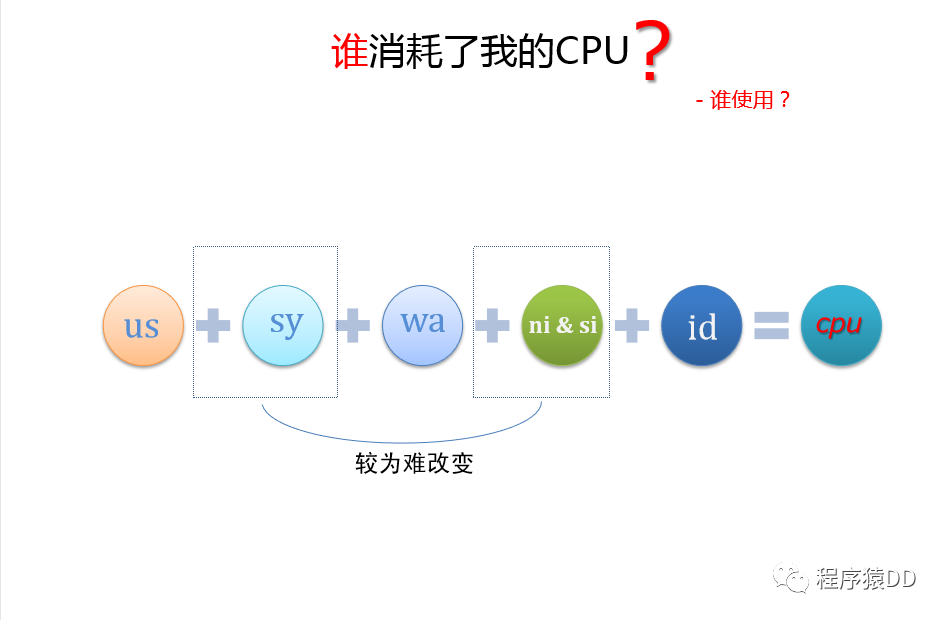
用戶和IO等待消耗了大部分cpu
吞吐量下降(tps)
查詢響應(yīng)時(shí)間增加
慢查詢數(shù)增加
對(duì)mysql的并發(fā)陡增,也會(huì)產(chǎn)生上述影響
# 如何減少CPU消耗?
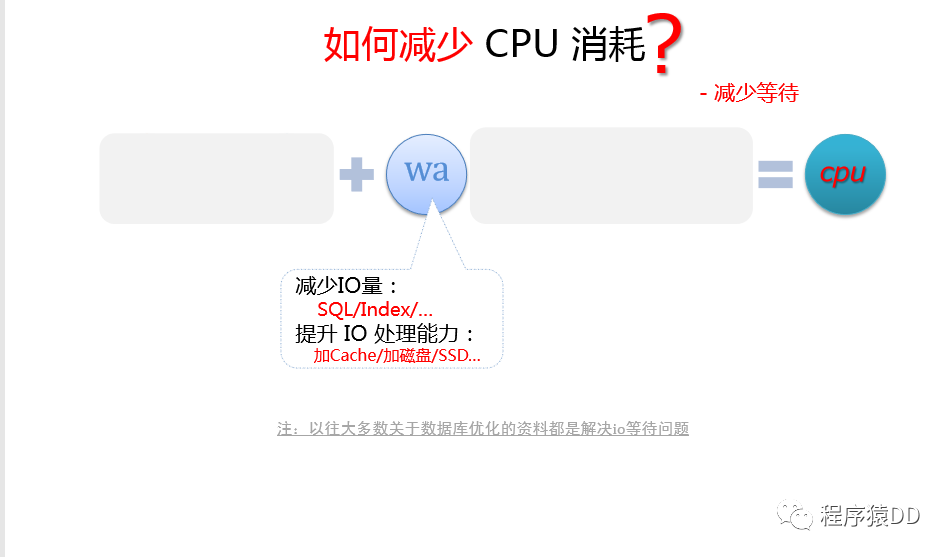
減少等待
減少IO量
SQL/index,使用合適的索引減少掃描的行數(shù)(需平衡索引的正收益和維護(hù)開銷,空間換時(shí)間)
提升IO處理能力
加cache/加磁盤/SSD
減少計(jì)算
減少邏輯運(yùn)算量
避免使用函數(shù),將運(yùn)算轉(zhuǎn)移至易擴(kuò)展的應(yīng)用服務(wù)器中 ?
如substr等字符運(yùn)算,dateadd/datesub等日期運(yùn)算,abs等數(shù)學(xué)函數(shù)減少排序,利用索引取得有序數(shù)據(jù)或避免不必要排序 ?
如union all代替 union,order by 索引字段等禁止類型轉(zhuǎn)換,使用合適類型并保證傳入?yún)?shù)類型與數(shù)據(jù)庫(kù)字段類型絕對(duì)一致,如數(shù)字用tiny/int/bigint等,必需轉(zhuǎn)換的在傳入數(shù)據(jù)庫(kù)之前在應(yīng)用中轉(zhuǎn)好
簡(jiǎn)單類型,盡量避免復(fù)雜類型,降低由于復(fù)雜類型帶來的附加運(yùn)算。更小的數(shù)據(jù)類型占用更少的磁盤、內(nèi)存、cpu緩存和cpu周期
….
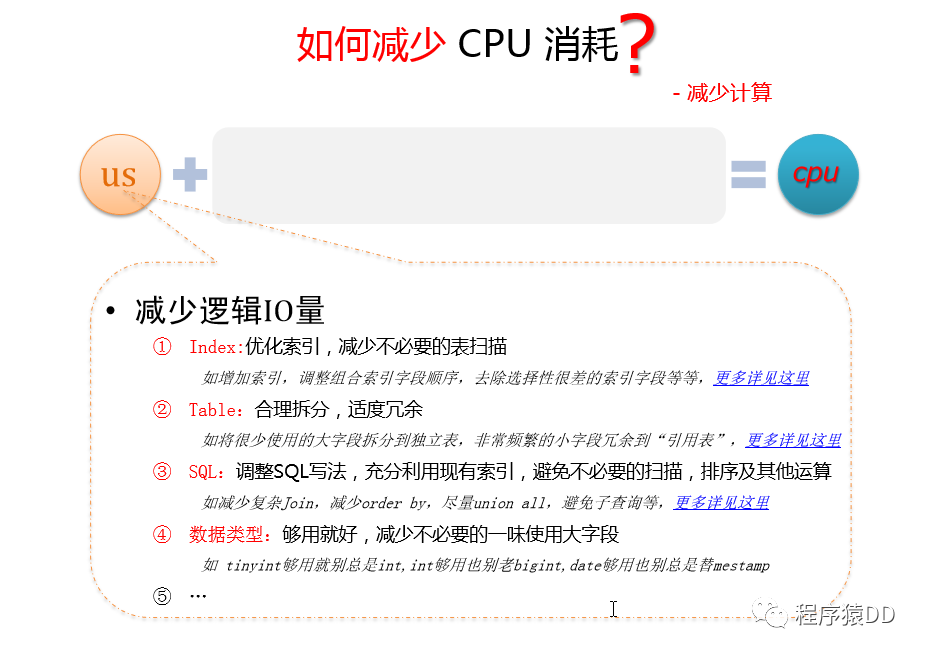
減少邏輯IO量
index,優(yōu)化索引,減少不必要的表掃描 ?
如增加索引,調(diào)整組合索引字段順序,去除選擇性很差的索引字段等等table,合理拆分,適度冗余 ?
如將很少使用的大字段拆分到獨(dú)立表,非常頻繁的小字段冗余到“引用表”SQL,調(diào)整SQL寫法,充分利用現(xiàn)有索引,避免不必要的掃描,排序及其他操作 ?
如減少?gòu)?fù)雜join,減少order by,盡量union all,避免子查詢等數(shù)據(jù)類型,夠用就好,減少不必要使用大字段 ?
如tinyint夠用就別總是int,int夠用也別老bigint,date夠用也別總是timestamp….
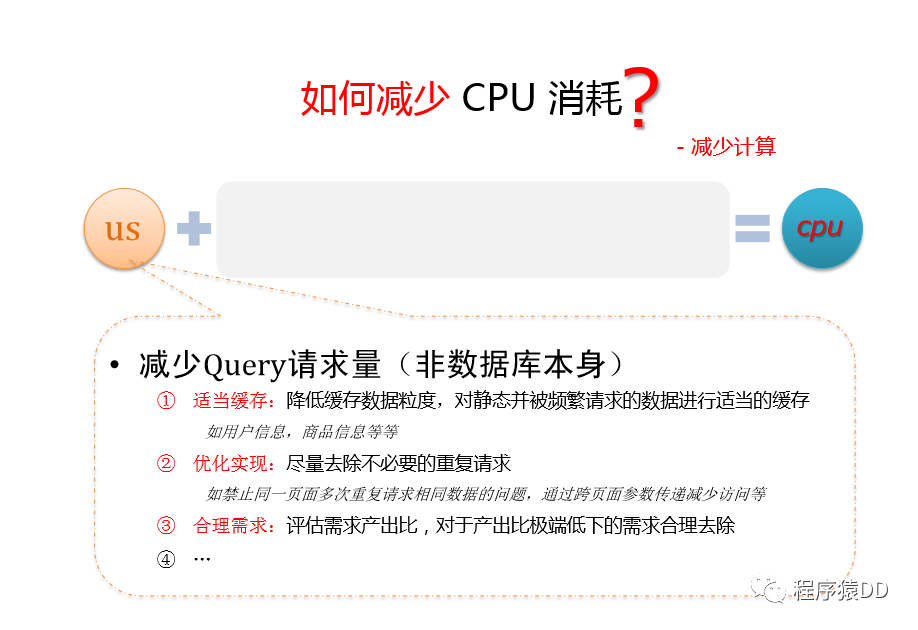
減少query請(qǐng)求量(非數(shù)據(jù)庫(kù)本身)
適當(dāng)緩存,降低緩存數(shù)據(jù)粒度,對(duì)靜態(tài)并被頻繁請(qǐng)求的數(shù)據(jù)進(jìn)行適當(dāng)?shù)木彺??
如用戶信息,商品信息等優(yōu)化實(shí)現(xiàn),盡量去除不必要的重復(fù)請(qǐng)求 ?
如禁止同一頁(yè)面多次重復(fù)請(qǐng)求相同數(shù)據(jù)的問題,通過跨頁(yè)面參數(shù)傳遞減少訪問等合理需求,評(píng)估需求產(chǎn)出比,對(duì)產(chǎn)出比極端底下的需求合理去除
….
升級(jí)cpu
若經(jīng)過減少計(jì)算和減少等待后還不能滿足需求,cpu利用率還高T_T
是時(shí)候拿出最后的殺手锏了,升級(jí)cpu,是選擇更快的cpu還是更多的cpu了?
參考
《高性能MySQL》 ? ?
《圖解性能優(yōu)化》 ? ?
大部分整理自《MySQL Tuning For CPU Bottleneck》
往期推薦
掃一掃,關(guān)注我
一起學(xué)習(xí),一起進(jìn)步