
三種大模型架構(gòu)
Transformers構(gòu)成了革命性的大語言模型的骨干。
雖然像GPT4、llama2和Falcon這樣的LLM在各種任務(wù)上似乎表現(xiàn)出色,但LLM在某個特定任務(wù)上的性能是底層架構(gòu)的直接結(jié)果。
有三種不同的Transformer架構(gòu)變體為不同的LLM提供動力。
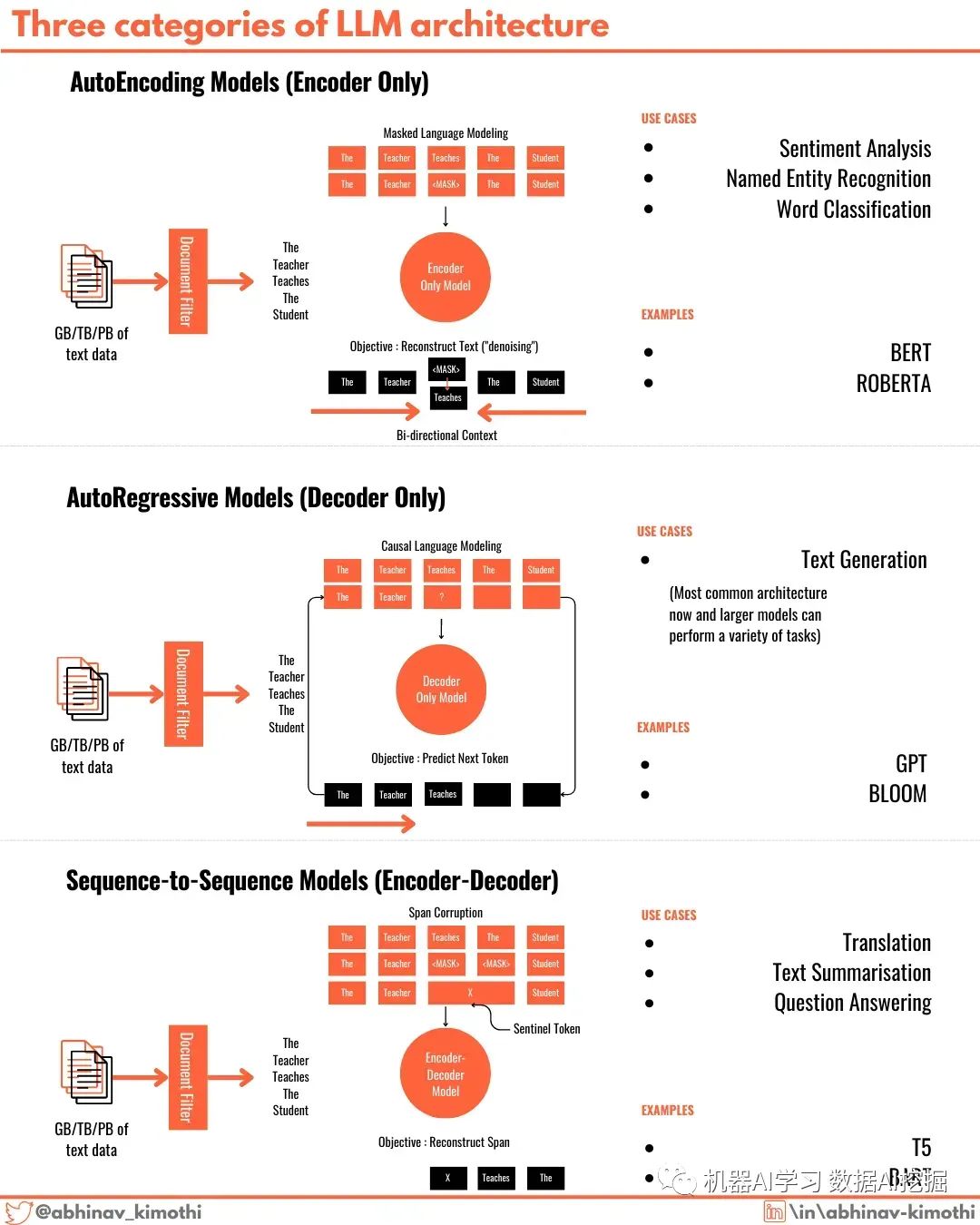
1?? 自編碼器(Autoencoders)- 在自編碼器中,預(yù)訓(xùn)練后會丟棄Transformer的解碼器部分,只使用編碼器生成輸出。廣泛流行的BERT和RoBERTa模型就是基于這種架構(gòu)構(gòu)建的,并在情感分析和文本分類任務(wù)上表現(xiàn)良好。這些模型使用一種稱為MLM或掩碼語言建模的過程進(jìn)行訓(xùn)練。
2?? 自回歸模型(Autoregressors)- 像GPT系列、bloom等現(xiàn)代LLM是自回歸模型。在這種架構(gòu)中,保留解碼器部分,預(yù)訓(xùn)練后丟棄編碼器部分。雖然文本生成是自回歸模型最適用的場景,但它們在各種任務(wù)上表現(xiàn)出色。大多數(shù)現(xiàn)代LLM都是自回歸模型。這些模型使用一種稱為因果語言建模的過程進(jìn)行訓(xùn)練。
3?? 序列到序列模型(Sequence-to-Sequence)- Transformer模型的起源是序列到序列模型。這些模型同時具有編碼器和解碼器部分,并且可以通過多種方式進(jìn)行訓(xùn)練。其中一種方法是跨度損壞和重建。這些模型最適合于語言翻譯任務(wù)。T5和BART系列的模型就是序列到序列模型
推薦閱讀:
世界的真實(shí)格局分析,地球人類社會底層運(yùn)行原理
不是你需要中臺,而是一名合格的架構(gòu)師(附各大廠中臺建設(shè)PPT)
企業(yè)IT技術(shù)架構(gòu)規(guī)劃方案
論數(shù)字化轉(zhuǎn)型——轉(zhuǎn)什么,如何轉(zhuǎn)?
【中臺實(shí)踐】華為大數(shù)據(jù)中臺架構(gòu)分享.pdf