
證件造假克星!基于深度學習的文檔圖像偽造攻擊
點擊下方“AI算法與圖像處理”,一起進步!
重磅干貨,第一時間送達

本文簡要介紹2021年8月TIP錄用論文“Deep Learning-based Forgery Attack on Document Images”的主要工作。該論文通過基于深度學習的技術提出了一種低成本的文檔圖像編輯算法,并通過一套網(wǎng)絡設計策略解決了現(xiàn)有文本編輯算法在復雜字符和復雜背景上進行文本編輯的局限性。文檔編輯的實際效果如下:
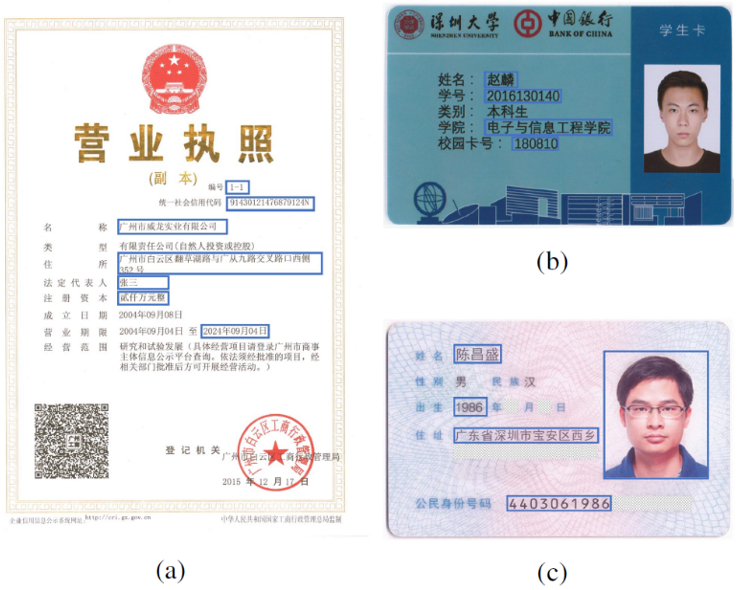
Fig. 1. Illustration of three types of document images processed by the proposed document forgery approach (ForgeNet). The edited regions are boxed out in blue.
一、研究背景
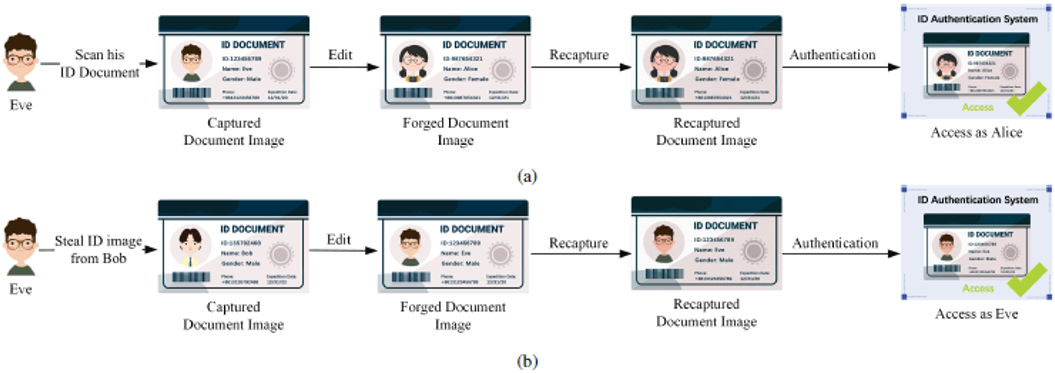
Fig. 2. Two representative forge-and-recapture attack scenarios. (a) The attacker scans his/her own identity document to obtain an identity document image and forges the document of a target identity to perform an impersonate attack. (b) The attacker steals an identity document image and forge his/her own document to obtain unauthorized access.
二、方法簡述
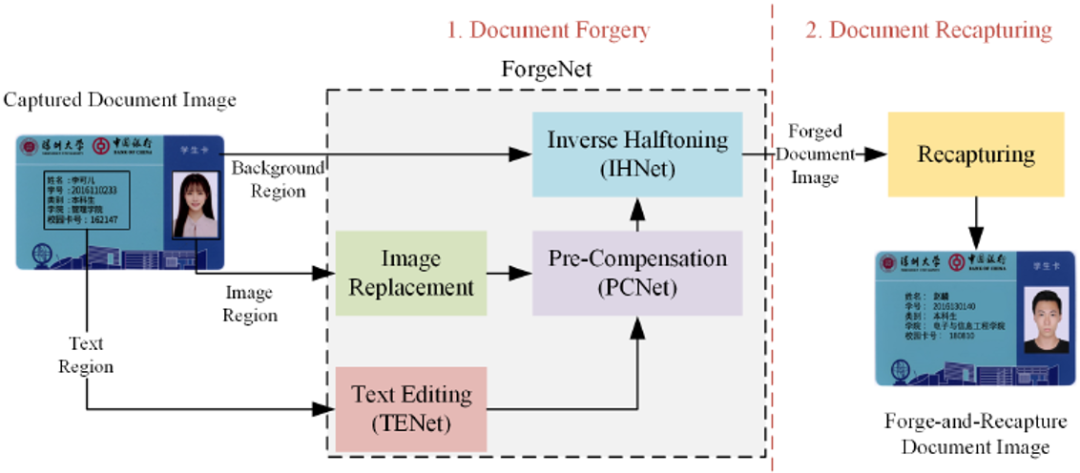
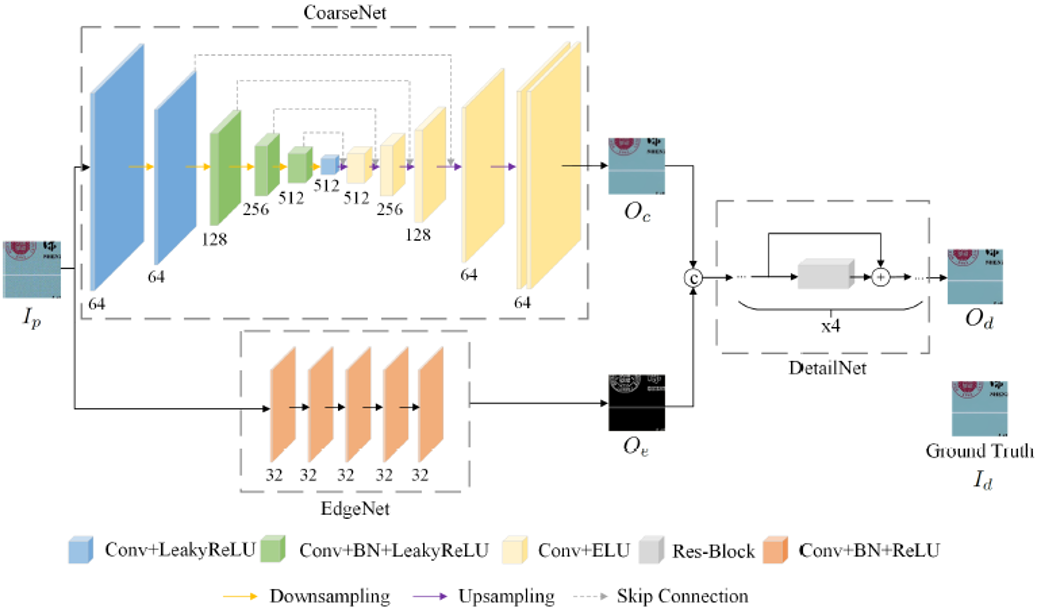
文檔偽造攻擊分為偽造(通過該論文提出的深度網(wǎng)絡ForgeNet,網(wǎng)絡框架見Fig. 3)和翻拍兩個步驟。在偽造過程中,由成像設備獲取的文檔圖像作為ForgeNet的輸入。它被分為三個區(qū)域,即文本區(qū)域、圖像區(qū)域和背景區(qū)域(不包括在前兩類中的區(qū)域)。背景區(qū)域由反半色調模塊(IHNet)處理,用以去除打印圖像中的半色調點。圖像區(qū)域中的原始照片被目標照片所取代,所得圖像被輸入到打印和掃描預補償模塊(PCNet)和IHNet。值得注意的是,PCNet引入顏色失真,并在編輯過的區(qū)域引入半色調圖案,這樣就可以補償編輯過的區(qū)域和背景區(qū)域之間的差異。文本區(qū)域隨后被輸入到文本編輯模塊(TENet)、PCNet和IHNet。經偽造網(wǎng)絡處理后,這三個區(qū)域被拼接在一起,形成一個完整的文檔圖像。最后,偽造的文檔圖像由相機或掃描儀進行翻拍,完成偽造和翻拍攻擊。
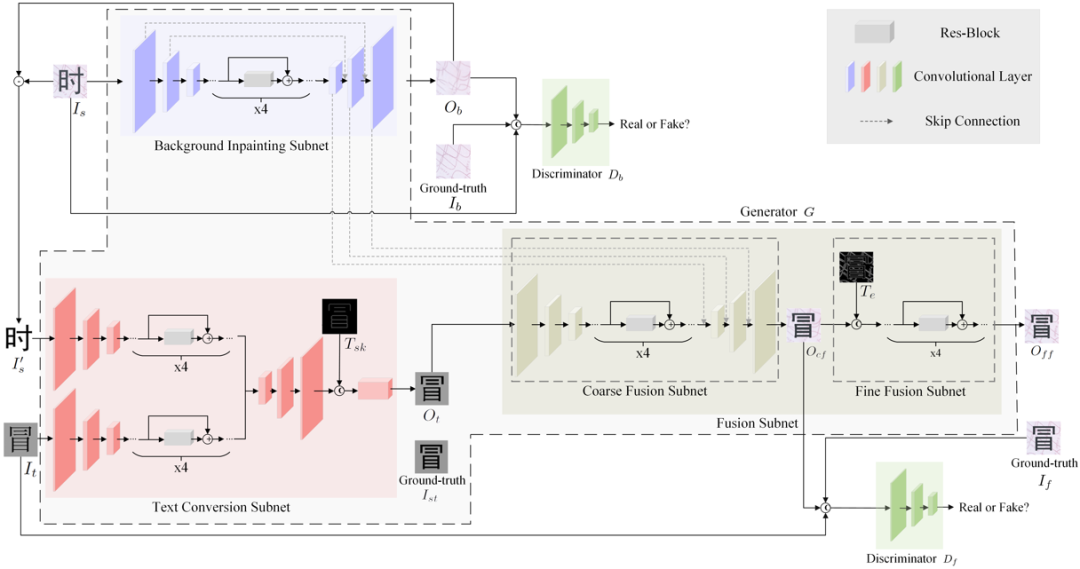
Fig. 4是文本編輯網(wǎng)絡(TENet)的框架,它由三個子網(wǎng)組成。背景填充子網(wǎng)預測原始文本區(qū)域的背景內容并進行填充;文本轉換子網(wǎng)將源圖像 I_s 的文本內容替換為輸入的目標文本圖像,同時保留原始風格;融合子網(wǎng)將前兩個子網(wǎng)的輸出合并,得到帶有目標文本和原始背景的圖像。
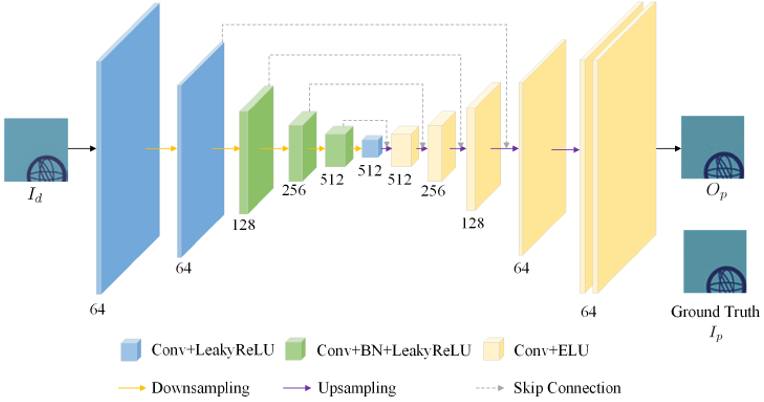
由于編輯過的文字區(qū)域沒有打印和掃描的失真,但背景區(qū)域卻經過了打印和掃描過程。如果直接拼接編輯過的文本和背景區(qū)域,二者邊緣的偽影會很明顯。所以,在合并不同區(qū)域之前,可以通過具有自動編碼器結構的PCNet(網(wǎng)絡結構如Fig. 5所示)來模擬打印-掃描過程中的強度變化和噪聲,預先補償文字區(qū)域的打印和掃描失真。
在打印和掃描后或由PCNet處理后,文檔圖像可以被視為半色調點的集群。如果圖像在沒有進行還原的情況下被重新打印和掃描,第一次和第二次打印過程中產生的半色調圖案會相互干擾并引入混疊失真。為了提高偽造和翻拍攻擊的成功率,在翻拍之前可以通過IHNet(網(wǎng)絡結構如Fig. 6所示)去除偽造文檔圖像中的半色調圖案。
三、主要實驗結果及可視化效果
作者首先評估了TENet在合成字符數(shù)據(jù)集上的性能。由于SRNet [2]最初設計用于編輯場景圖像中的英文字母和阿拉伯數(shù)字,應用于視覺翻譯和增強現(xiàn)實上,它在結構復雜的漢字上表現(xiàn)不佳,尤其是在有復雜背景的文檔中。所以作者通過對SRNet的網(wǎng)絡結構進行調整,提出了文本編輯網(wǎng)絡TENet。作者對TENet中不同于SRNet的組件進行了定性和定量的評估。SRNet和TENet的三個主要區(qū)別如下:1)對源圖像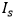 和背景填充子網(wǎng)的輸出
和背景填充子網(wǎng)的輸出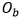 進行圖像差分操作,獲得沒有背景的樣式文本圖像
進行圖像差分操作,獲得沒有背景的樣式文本圖像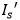 ;2)將輸入到文本骨架器,所提取的骨架圖像作為監(jiān)督信息直接輸入到文本轉換子網(wǎng);3)設計了一個考慮紋理連續(xù)性的精細融合子網(wǎng)取代通用的U-Net網(wǎng)絡結構,用來融合不同的區(qū)域。
;2)將輸入到文本骨架器,所提取的骨架圖像作為監(jiān)督信息直接輸入到文本轉換子網(wǎng);3)設計了一個考慮紋理連續(xù)性的精細融合子網(wǎng)取代通用的U-Net網(wǎng)絡結構,用來融合不同的區(qū)域。

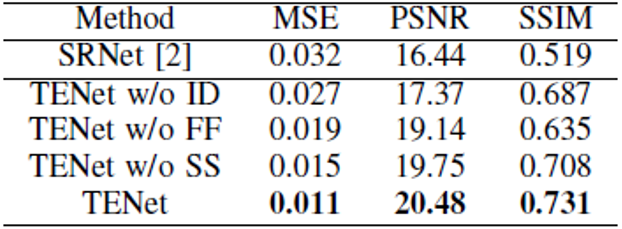
如Fig. 7 (c)-(e)中的視覺結果所示,如果去除這三個組件,都出現(xiàn)了不同程度的失真。圖像差分、精細融合網(wǎng)絡和骨架監(jiān)督的重要性分別反映在字符、背景紋理和字符骨架的質量上。定量分析(見TABLE Ⅰ)和視覺實例都充分地證明了這三個組件的重要性。
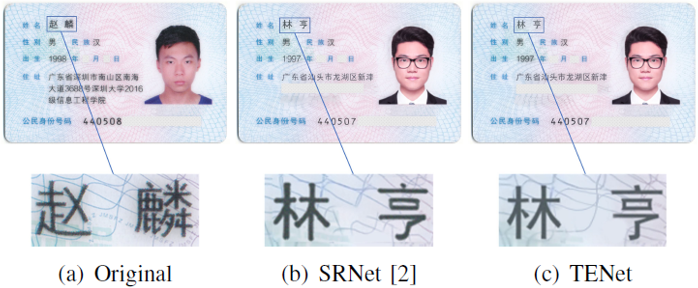
Fig. 8. Visual comparison on the identity card images.
此外,作者還選擇具有復雜背景的身份證作為目標文檔,通過單樣本和一些數(shù)據(jù)增強策略訓練文本偽造網(wǎng)絡(ForgeNet)。如Fig. 8所示,F(xiàn)orgeNet只用單樣本進行微調就取得了良好的偽造性能,而在SRNet編輯的圖像中文字和背景都出現(xiàn)了失真。
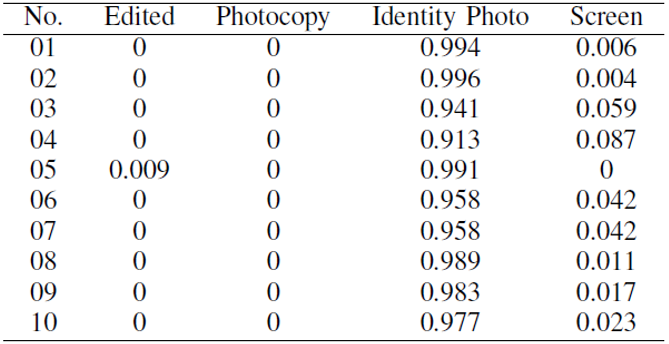
TABLE Ⅱ Identity document authentication under forge-and-recapture attack on MEGVII Face++ AI.
四、總結及討論
五、論文資源
論文地址:https://arxiv.org/abs/2102.00653
參考文獻
[1] Q. Yang, J. Huang, and W. Lin, “SwapText: Image based Texts Transfer in Scenes,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 14 700–14 709.
[2] L. Wu, C. Zhang, J. Liu, J. Han, J. Liu, E. Ding, and X. Bai, “Editing Text in the Wild,” in Proceedings of the 27th ACM International Conference on Multimedia, 2019, pp. 1500–1508.
[3] P. Roy, S. Bhattacharya, S. Ghosh, and U. Pal, “STEFANN: Scene text editor using font adaptive neural network,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 13 228–13 237.
原文作者: Lin Zhao, Changsheng Chen, Jinwu Huang
免責聲明:(1)本文僅代表撰稿者觀點,撰稿者不一定是原文作者,其個人理解及總結不一定準確及全面,論文完整思想及論點應以原論文為準。(2)本文觀點不代表本公眾號立場。
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有美顏、三維視覺、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群
個人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會分享
在「AI算法與圖像處理」公眾號后臺回復:何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經典工作的總結分析
下載2:終身受益的編程指南:Google編程風格指南
在「AI算法與圖像處理」公眾號后臺回復:c++,即可下載。歷經十年考驗,最權威的編程規(guī)范!
下載3 CVPR2021 在「AI算法與圖像處理」公眾號后臺回復:CVPR,即可下載1467篇CVPR 2020論文 和 CVPR 2021 最新論文
