
基于深度學(xué)習(xí)的圖像增強(qiáng)綜述

極市導(dǎo)讀
本文介紹了近年來比較經(jīng)典的圖像增強(qiáng)模型,并分析其優(yōu)缺點(diǎn)。 >>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿
這篇博客主要介紹之前看過的一些圖像增強(qiáng)的論文,針對普通的圖像,比如手機(jī)拍攝的那種,比低光照圖像增強(qiáng)任務(wù)更簡單。
介紹
圖像增強(qiáng)的定義非常廣泛,一般來說,圖像增強(qiáng)是有目的地強(qiáng)調(diào)圖像的整體或局部特性,例如改善圖像的顏色、亮度和對比度等,將原來不清晰的圖像變得清晰或強(qiáng)調(diào)某些感興趣的特征,擴(kuò)大圖像中不同物體特征之間的差別,抑制不感興趣的特征,提高圖像的視覺效果。傳統(tǒng)的圖像增強(qiáng)已經(jīng)被研究了很長時(shí)間,現(xiàn)有的方法可大致分為三類,空域方法是直接對像素值進(jìn)行處理,如直方圖均衡,伽馬變換;頻域方法是在某種變換域內(nèi)操作,如小波變換;混合域方法是結(jié)合空域和頻域的一些方法。傳統(tǒng)的方法一般比較簡單且速度比較快,但是沒有考慮到圖像中的上下文信息等,所以取得效果不是很好。
近年來,卷積神經(jīng)網(wǎng)絡(luò)在很多低層次的計(jì)算機(jī)視覺任務(wù)中取得了巨大突破,包括圖像超分辨、去模糊、去霧、去噪、圖像增強(qiáng)等。對比于傳統(tǒng)方法,基于CNN的一些方法極大地改善了圖像增強(qiáng)的質(zhì)量。現(xiàn)有的方法大多是有監(jiān)督的學(xué)習(xí),對于一張?jiān)紙D像和一張目標(biāo)圖像,學(xué)習(xí)它們之間的映射關(guān)系,來得到增強(qiáng)后的圖像。但是這樣的數(shù)據(jù)集比較少,很多都是人為調(diào)整的,因此需要自監(jiān)督或弱監(jiān)督的方法來解決這一問題。本文介紹了近年來比較經(jīng)典的圖像增強(qiáng)模型,并分析其優(yōu)缺點(diǎn)。
DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks
這是ICCV2017年的一篇文章,Ignatov等人自己構(gòu)建了一個(gè)大的數(shù)據(jù)集(DPED),包含6K多張照片,使用三部手機(jī)和一部單反在多種戶外條件下同時(shí)拍攝得到。然后作者針對這三個(gè)成對的數(shù)據(jù)集,提出了一種新的圖像增強(qiáng)算法。通過學(xué)習(xí)手機(jī)拍攝的照片和單反照片之間的映射關(guān)系來將手機(jī)拍攝的照片提升到單反水平,這是一個(gè)端到端的訓(xùn)練,不需要額外的監(jiān)督和人為添加特征。其網(wǎng)絡(luò)結(jié)構(gòu)采用的是GAN模型,如下:
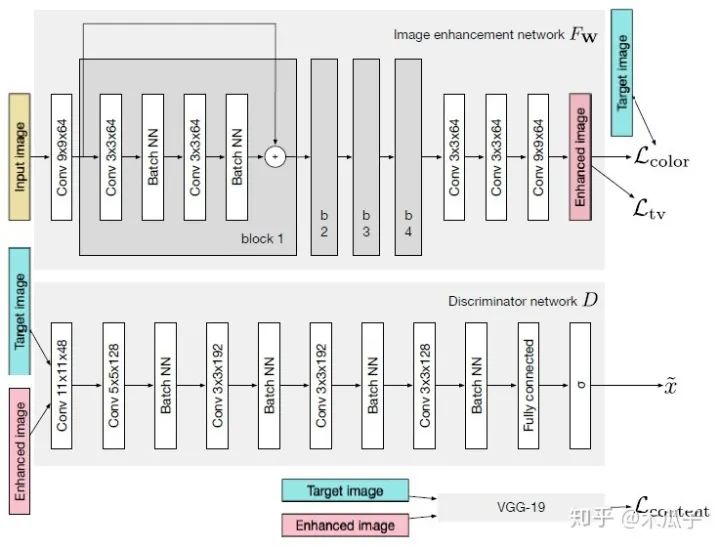
如圖所示,GAN主要由兩個(gè)網(wǎng)絡(luò)組成,一個(gè)生成網(wǎng)絡(luò)G和一個(gè)判別網(wǎng)絡(luò)D,整個(gè)網(wǎng)絡(luò)是一個(gè)對抗的過程,G不斷生成能欺騙D的數(shù)據(jù),D不斷提高自己辨別真假的能力,直到達(dá)到一個(gè)均衡狀態(tài)。這里的輸入圖像是手機(jī)拍攝的照片,目標(biāo)圖像是單反拍攝的照片,它們是一一對映的關(guān)系。生成器CNN結(jié)構(gòu),首先輸入一張圖像,經(jīng)過一個(gè)卷積層預(yù)處理后,使用了4個(gè)殘差塊,再經(jīng)過3個(gè)卷積層得到增強(qiáng)后的圖像;判別器CNN用于判斷增強(qiáng)后的圖像和目標(biāo)圖像的真假,生成器生成的圖像要盡可能地欺騙判別器,這樣就表明生成的圖像與目標(biāo)圖像越接近,也就是增強(qiáng)后的圖像效果越好。
圖像增強(qiáng)的主要難點(diǎn)之一是輸入圖像與輸出圖像不能密集匹配(pixel-to-pixel),因此標(biāo)準(zhǔn)的均方誤差不太適用,本文的另一個(gè)貢獻(xiàn)是提出了復(fù)合的損失函數(shù),包含內(nèi)容、紋理和色彩三部分。
色彩損失用于衡量增強(qiáng)后圖像與目標(biāo)圖像的色彩差異,對圖像先做高斯模糊再計(jì)算它們的歐式距離,這樣的好處是可以消除紋理和內(nèi)容的影響來評估兩圖像間的亮度、對比度和主要顏色差異,可以寫成如下形式:
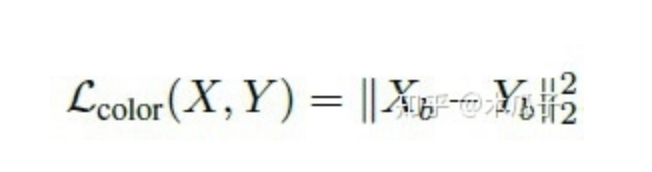
其中,Xb, Yb分別是為X,Y經(jīng)過模糊的圖像,如下:
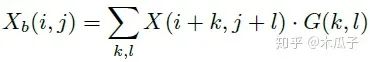
二維高斯模糊算子可以寫成如下形式,其中A=0.053, μ=0, σ=3,
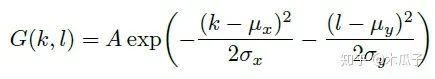
使用生成對抗網(wǎng)絡(luò)(GANs)來衡量紋理質(zhì)量,因此紋理損失定義為:
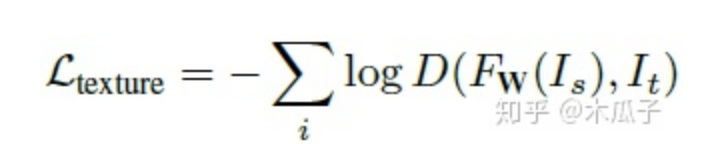
FW ,D分別表示生成和判別網(wǎng)絡(luò)。
計(jì)算預(yù)訓(xùn)練好的VGG19網(wǎng)絡(luò)ReLU層后激活的feature map的歐式距離作為內(nèi)容損失,可以保留語義信息,定義為:
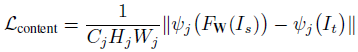
此外,還使用全變分(TV)來增強(qiáng)生成圖像的空間平滑性,由于它占的權(quán)重比較小,不會(huì)影響圖像的高頻部分,且可以抑制一定程度的椒鹽噪聲,定義為:
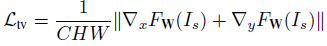
總的損失函數(shù)為:
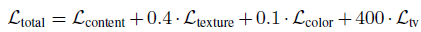
最終要優(yōu)化的目標(biāo)函數(shù)如下,W為網(wǎng)絡(luò)要學(xué)習(xí)的參數(shù),L為總的損失函數(shù),
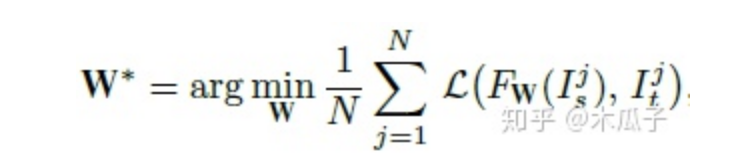
最后的結(jié)果如下:
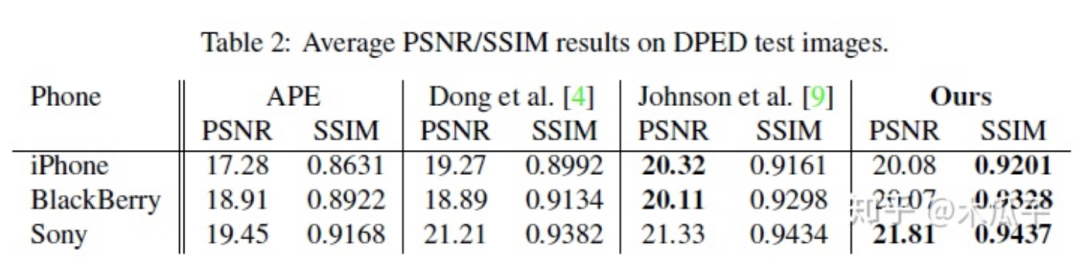

這篇文章提出了一個(gè)照片增強(qiáng)的算法,將手機(jī)照片提升到單反水平,使用的數(shù)據(jù)集DPED均為自然圖像,有實(shí)際的應(yīng)用價(jià)值。但也存在一些問題,有一些復(fù)原后的圖像存在色彩偏差或者對比度過高,顯得不太自然。此外,文中使用GAN在復(fù)原高頻信息時(shí)不可避免地會(huì)放大噪聲。最大的缺點(diǎn)是它對每種不同手機(jī)的數(shù)據(jù)集都要重新訓(xùn)練,是一個(gè)強(qiáng)監(jiān)督的過程,通用性不強(qiáng),后續(xù)的工作也對這一算法進(jìn)行了改進(jìn),提出了一種弱監(jiān)督的方法。
WESPE: Weakly Supervised Photo Enhancer for Digital Cameras
這是CVPR Workshops2018上的一篇文章,是基于上一篇論文的改進(jìn),同一個(gè)作者寫的。上一篇論文中最大的局限性是它對每一個(gè)數(shù)據(jù)集都要重新訓(xùn)練一個(gè)模型,不具有通用性,因此這篇文章中,作者提出一個(gè)新的弱監(jiān)督的網(wǎng)絡(luò)模型WESPE,輸入數(shù)據(jù)和輸出數(shù)據(jù)分別為低質(zhì)量圖像和高質(zhì)量的圖像,但它們在內(nèi)容上不需要對應(yīng),使用一個(gè)傳遞性的CNN-GAN結(jié)構(gòu)來學(xué)習(xí)它們之間的映射關(guān)系,其網(wǎng)絡(luò)結(jié)構(gòu)如下:

我們的目標(biāo)是要學(xué)習(xí)源圖像X到目標(biāo)圖像Y映射關(guān)系,如圖所示,這個(gè)網(wǎng)絡(luò)包含一個(gè)生成器映射 一個(gè)逆生成映射 , 這里的G可以看成圖像增強(qiáng)器,可視為退化器,為了保證x與 widetildex 內(nèi)容的一致性,使用VGG19計(jì)算內(nèi)容損失,這樣就可以避免成對的需要內(nèi)容完全一致的數(shù)據(jù)集。右側(cè)的兩個(gè)判別器Dc, Dt分別用于判別增強(qiáng)后圖像與目標(biāo)圖像在顏色和紋理上的差異,最后計(jì)算TV損失來得到較平滑的圖像。
內(nèi)容一致性損失,計(jì)算原圖x與 idetildex 在VGG19上某一高 維feature map的L2范數(shù),計(jì)算公式如下:
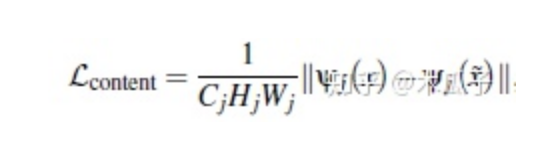
判別器顏色損失,計(jì)算增強(qiáng)后的圖像與目標(biāo)圖像高斯模糊后的差異,如下:
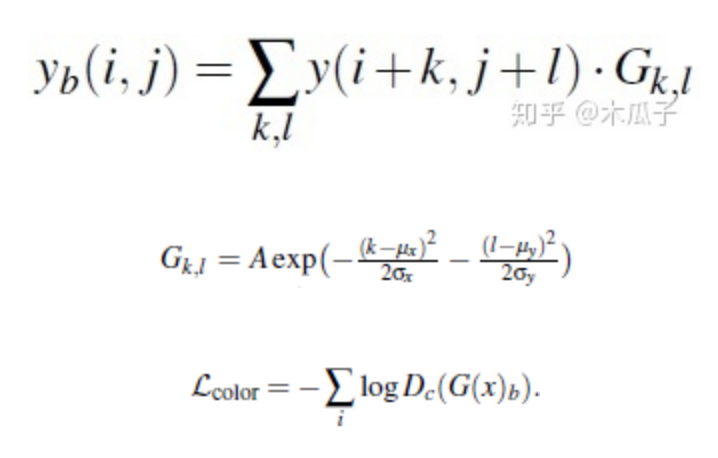
判別器紋理損失,比較增強(qiáng)后圖像與目標(biāo)圖像在灰度狀態(tài)下的損失,定義為:
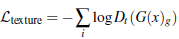
TV損失,為了使生成后的圖像比較平滑,定義為:
總的損失為:
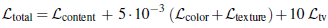
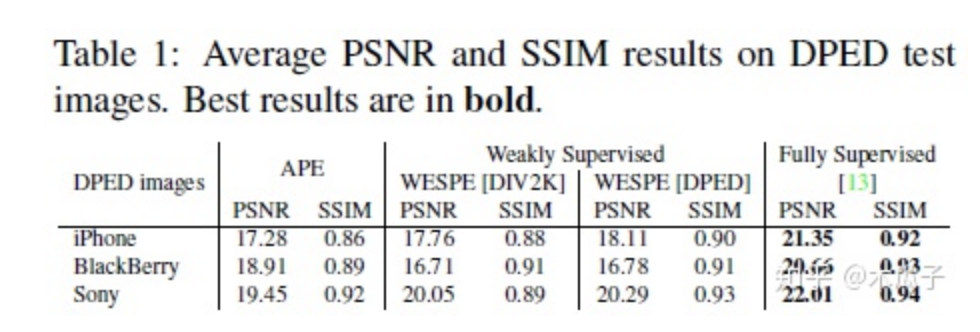
實(shí)驗(yàn)結(jié)果如下:

本文提出的算法WESPE是一種弱監(jiān)督的方式,因此它可以適用于任何戶外的數(shù)據(jù)集,不需要成對的增強(qiáng)圖像來訓(xùn)練,還用到的數(shù)據(jù)集有以下幾種:

總的來說,這篇文章最大的貢獻(xiàn)是提出了這種弱監(jiān)督的方式來增強(qiáng)低質(zhì)量的圖像,雖然它的PSNR和SSIM結(jié)果跟強(qiáng)監(jiān)督的相比還存在一定的差距,但它的創(chuàng)新點(diǎn)還是很有借鑒意義的。
Deep Photo Enhancer: Unpaired Learning for Image Enhancement from Photographs with GANs
這是CVPR2018的一篇文章,作者首次提出了用GANs實(shí)現(xiàn)無監(jiān)督的照片增強(qiáng),但這里的無監(jiān)督并不是完全不需要數(shù)據(jù)對,同上一篇論文一樣,是指用到的數(shù)據(jù)集并不是在內(nèi)容上一致的。本文中使用的two-way GAN與CycleGAN的結(jié)構(gòu)相似,在MIT-Adobe 5K數(shù)據(jù)集上取得了較好的結(jié)果,超過了第一篇論文的方法。首先看一下two-way GAN與1-way GAN結(jié)構(gòu)的差別:
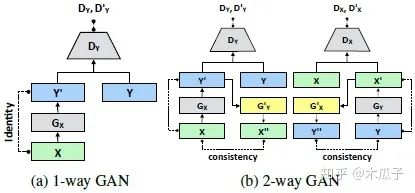
圖中(a)為標(biāo)準(zhǔn)的GAN, X代表源域, Y表示目標(biāo)域,給定輸入x,經(jīng)過生成器Gx得到增強(qiáng)后的圖像y', 判別器Dy用于區(qū)分增強(qiáng)后的圖像y'和目標(biāo)圖像y。為了得到更好的結(jié)果,加強(qiáng)循環(huán)一致性,就提出了這種two-way GAN, 通常包含一個(gè)前向映射 和一個(gè)后向映射 。前向映射中, 先經(jīng)過生成器Gx得到增強(qiáng)后的圖像y', 得到y(tǒng)'后再經(jīng)過一個(gè)生成器G'y映射到源域x', , 檢查x與x”的一致性; 判別器區(qū)分y與y'。在反向過程中, y先經(jīng)過生 成器Gy得到退化的圖像x', '再經(jīng)過一個(gè)生成器G'x得到增強(qiáng)后的圖y', 檢查y與y'的一致性; 判別器區(qū)分x與x'。
GAN中的生成器Gx也就是最后的照片增強(qiáng)器,在U-Net的基礎(chǔ)上加入全局特征,作者認(rèn)為全局特征包含一些高維特征,如場景類別、目標(biāo)類別、整體的光照條件等,有利于單個(gè)像素的局部調(diào)整。完整的網(wǎng)絡(luò)結(jié)構(gòu)如下:
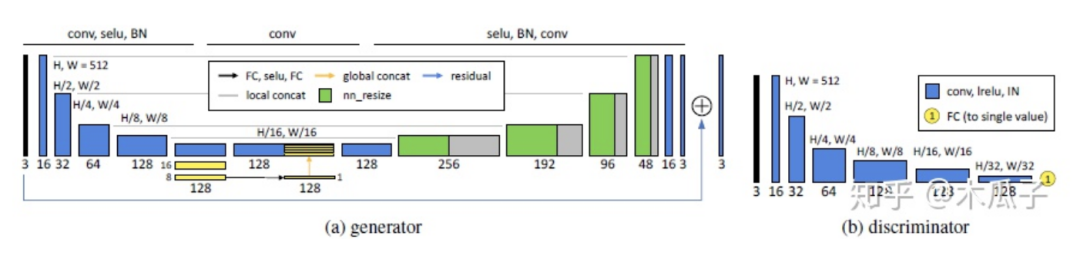
文中作者對比了多種GAN方法,WGAN-GP效果最好,但它的表現(xiàn)依賴于梯度懲罰項(xiàng)的參數(shù),因此作者提出了一種自適應(yīng)的方法AWGAN(Adaptive WGAN),通過實(shí)驗(yàn)證明了將AWGAN擴(kuò)展到2-way GAN中比1-way GAN效果更好。為了使生成器能適應(yīng)不同的數(shù)據(jù)分布,使用獨(dú)立的batch normalization層,也就是說除了批歸一化層,其余所有的生成器共享相同的層和參數(shù)。
目標(biāo)函數(shù)包含三部分損失,第一部分為恒等映射,保證輸入圖像x與增強(qiáng)后的圖y內(nèi)容相似,但因?yàn)槭?-way GAN存在配對的映射y到x’,定義為I:
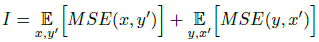
第二部分為循環(huán)一致性損失C,定義為:
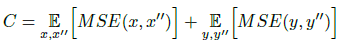
第三部分是生成對抗損失,判別器AD,生成器AG,定義為:
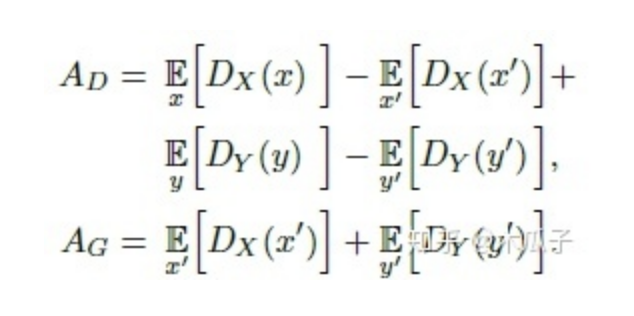
訓(xùn)練判別器時(shí),加上梯度懲罰項(xiàng)P,
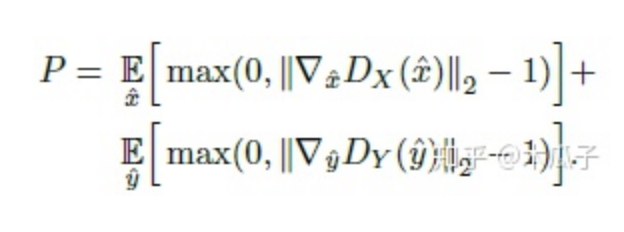
這一項(xiàng)滿足了Wasserstein distance的1-Lipschitz約束。
最終要優(yōu)化的為:
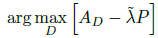
其中λ ?為使用AWGAN得到的自適應(yīng)權(quán)重參數(shù)。
生成器損失優(yōu)化下式得到:
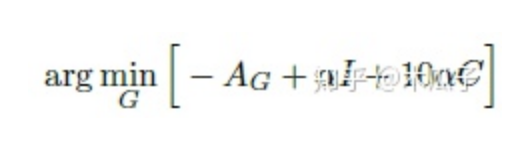
本文中采用的數(shù)據(jù)集為MIT Adobe 5K,作者將它劃分為三部分,第一部分為2250張圖像及其對應(yīng)的修飾后圖像用于有監(jiān)督的訓(xùn)練;第二部分是第一部分中2250張圖像及另外的修飾后的圖像,這樣就保證了輸入圖像與輸出圖像內(nèi)容上是不同的,用于無監(jiān)督訓(xùn)練;第三部分500張圖像用來測試。
最后的實(shí)驗(yàn)結(jié)果如下:
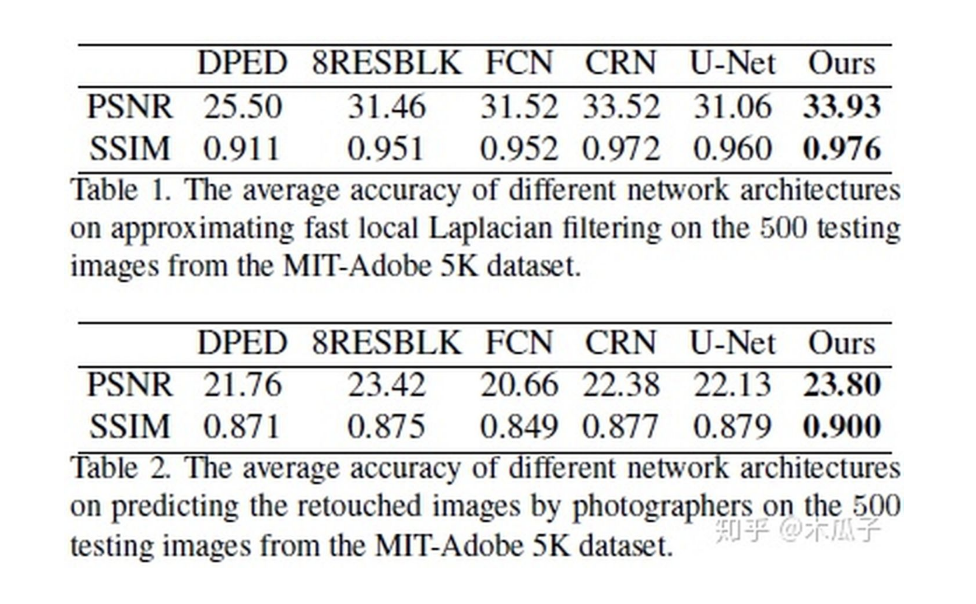

除了比較PSNR/SSIM,文中還采用了問卷調(diào)查的形式,其中HDR模型取得了最好的結(jié)果,從上面的圖也可以看出它的效果比較好,色彩比較鮮艷,但該模型存在一定的局限性,一些用于訓(xùn)練的HDR圖像是色調(diào)映射得到的,會(huì)產(chǎn)生光暈效應(yīng);若輸入圖像比較暗或包含噪聲,本文的模型會(huì)放大噪聲。此外,該模型還可以有一些其他應(yīng)用,如圖像分割、臥室圖像合成等,取得了不錯(cuò)的效果。總的來說,這篇論文給我們提供了一種“無監(jiān)督”做圖像增強(qiáng)的方法,并且使用U-Net加入全局特征,自適應(yīng)權(quán)重的WGAN和獨(dú)立的BN層來學(xué)習(xí)具有用戶期望特征的圖像。
Classification-Driven Dynamic Image Enhancement
這是CVPR2018的一篇文章,基于分類的動(dòng)態(tài)圖像增強(qiáng),這個(gè)論文首次將圖像增強(qiáng)任務(wù)與分類結(jié)合起來,不同于現(xiàn)有的圖像增強(qiáng)方法去評判增強(qiáng)后圖像的感知質(zhì)量,而是用分類結(jié)果的準(zhǔn)確性來衡量圖像增強(qiáng)的質(zhì)量,在沒有很好的評價(jià)指標(biāo)的情況下,作者Vivek Sharma等人提出了這樣的模型,讓我們從high-level的角度來對圖像進(jìn)行增強(qiáng),是一種創(chuàng)新和突破。
本文的主要貢獻(xiàn)是聯(lián)合優(yōu)化一個(gè)CNN用于增強(qiáng)和分類,我們通過動(dòng)態(tài)卷積自適應(yīng)地增強(qiáng)圖像中的特征來實(shí)現(xiàn)這一目標(biāo),使得CNN結(jié)構(gòu)能夠選擇性地增強(qiáng)那些有助于提高圖像分類的特征。網(wǎng)絡(luò)的整體結(jié)構(gòu)如下:
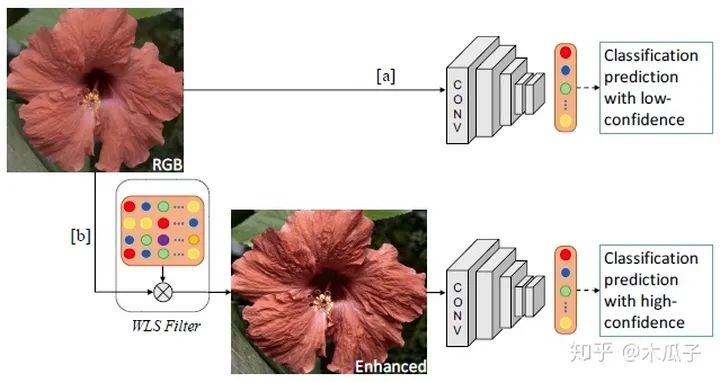
給定一張輸入圖像,不是直接用CNN進(jìn)行分類,而是先用WLS濾波器對圖像細(xì)節(jié)進(jìn)行增強(qiáng),再對其進(jìn)行分類,這樣可以提高分類的可信度。本文的目標(biāo)是學(xué)習(xí)一種動(dòng)態(tài)圖像增強(qiáng)網(wǎng)絡(luò)來提高分類準(zhǔn)確度,但不是近似特定的增強(qiáng)方法。為此,文中給出了三種CNN結(jié)構(gòu)。
動(dòng)態(tài)增強(qiáng)濾波器:
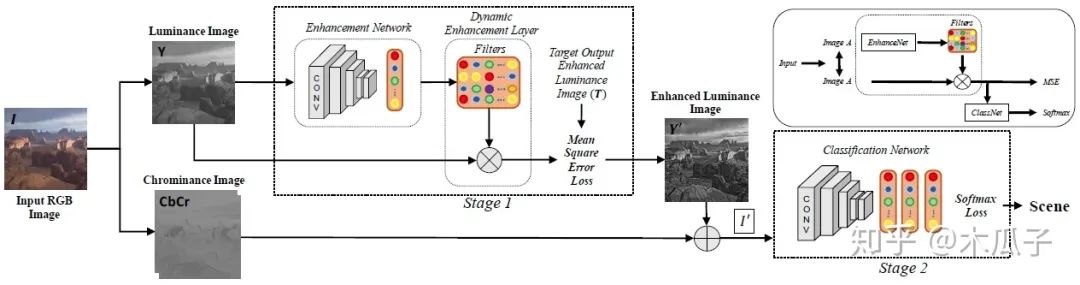
由圖可知,對于一張輸入的RGB圖像I,先把它轉(zhuǎn)化成亮度-色度(luminance-sschrominance)Y CbCr 彩色空間,增強(qiáng)算法用于RGB圖像的亮度通道,可以使得過濾器修改整體色調(diào)屬性和圖像銳度,而不影響顏色。再加上色度通道的圖像可以得到增強(qiáng)后的圖像I’,之后增強(qiáng)后的圖像輸入分類網(wǎng)絡(luò)中進(jìn)行分類。其中的目標(biāo)圖像作者采用了5種經(jīng)典的方法對其進(jìn)行增強(qiáng),分別為:(1) weighted least squares (WLS) filter, (2) bilateral filter (BF), (3) image sharpening filter (Imsharp), (4) guided filter (GF) ,(5)histogram equalization (HistEq),均使用其默認(rèn)參數(shù)。但在該模型中,每個(gè)數(shù)據(jù)集一次只使用其中一種增強(qiáng)方法,且對每一張輸入圖像,都動(dòng)態(tài)得產(chǎn)生特定的濾波器參數(shù)。這里的卷積網(wǎng)絡(luò)用了AlexNet,GoogleNet, VGG-VD, VGG-16和BN-Inception這五個(gè)模型進(jìn)行測試,其中BN-Inception在分類中表現(xiàn)最好,因此在后續(xù)實(shí)驗(yàn)中作為默認(rèn)結(jié)構(gòu)。分類網(wǎng)絡(luò)中的全連接層和分類層的參數(shù)均使用預(yù)訓(xùn)練好的網(wǎng)絡(luò)微調(diào)得到。
該網(wǎng)絡(luò)的loss有兩部分組成,用于增強(qiáng)的MSE loss和用于分類的softmax loss,用SGD優(yōu)化器聯(lián)合優(yōu)化這兩部分損失,總的損失函數(shù)如下:

其中,MSE loss計(jì)算的是增強(qiáng)后的亮度圖像與用傳統(tǒng)方法增強(qiáng)后的目標(biāo)圖像的均方誤差。a為分類網(wǎng)絡(luò)中最后一個(gè)全連接層的輸出,y為圖像I的真實(shí)標(biāo)簽,C為分類數(shù)量。聯(lián)合優(yōu)化使得損失梯度可以從ClassNet中反向傳播至EnhanceNet,來優(yōu)化濾波器的參數(shù)。
靜態(tài)濾波器:
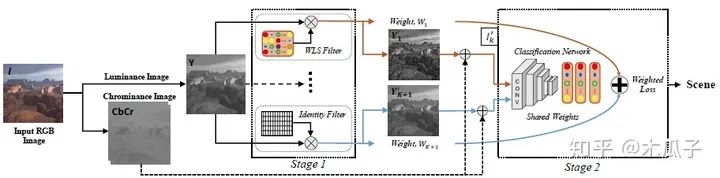
在該結(jié)構(gòu)中,靜態(tài)濾波器由第一種結(jié)構(gòu)中所有的動(dòng)態(tài)濾波器的平均得到,每個(gè)濾波器的權(quán)重相等,均為1/K=0.2(K=5);同時(shí),由于增強(qiáng)后的圖像可能比原始圖像效果還差,因此這邊使用一個(gè)恒等濾波器來產(chǎn)生一張?jiān)紙D像,再將它們與色度圖像相加得到增強(qiáng)后的RGB圖像以及它們的權(quán)重,這個(gè)權(quán)重表明增強(qiáng)方法對輸入圖像的重要性。在分類網(wǎng)絡(luò)中,輸入為5種方法增強(qiáng)后的圖像和原始圖像及其對應(yīng)權(quán)重和標(biāo)簽,輸出為圖像類別。和第一種方法一樣,分類網(wǎng)絡(luò)中的全連接層和分類層的參數(shù)均使用預(yù)訓(xùn)練好的網(wǎng)絡(luò)微調(diào)得到。
這里的損失為權(quán)值與softmax損失的加權(quán)和,帶權(quán)重的loss可寫成如下形式:
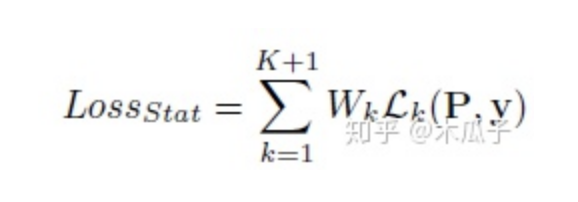
其中,K=5,前K個(gè)權(quán)重相等,均為0.2,第K+1個(gè)原始RGB圖像的權(quán)重設(shè)為1.
多動(dòng)態(tài)濾波器:

這個(gè)網(wǎng)絡(luò)結(jié)構(gòu)與第一種結(jié)構(gòu)比較相似,針對每種增強(qiáng)方法使用K個(gè)增強(qiáng)網(wǎng)絡(luò)動(dòng)態(tài)地產(chǎn)生K個(gè)濾波器,不同于第二種方法中取相同的權(quán)重,這里的權(quán)值根據(jù)均方誤差來決定,增強(qiáng)后的圖像誤差越小,則權(quán)重越大,其計(jì)算公式如下:

同樣,這邊也加入恒等濾波器得到原始圖像,且權(quán)值為1。其損失函數(shù)在第二種結(jié)構(gòu)的基礎(chǔ)上加入MSE來聯(lián)合優(yōu)化這K個(gè)增強(qiáng)網(wǎng)絡(luò),公式如下:
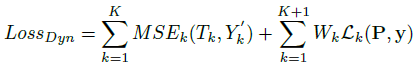
通過這種方式來訓(xùn)練網(wǎng)絡(luò)可以使這些濾波器更好地增強(qiáng)圖像的結(jié)構(gòu),以便于提高圖像的準(zhǔn)確率。
實(shí)驗(yàn)結(jié)果如下:
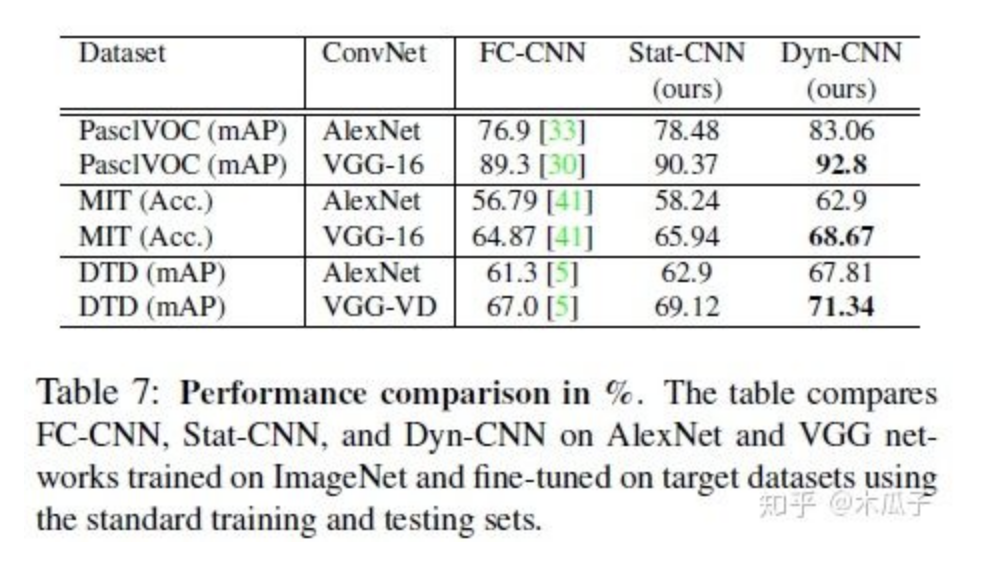
總的來說,本文提出了一種CNN結(jié)構(gòu)能效仿一系列的增強(qiáng)濾波器,通過端到端的學(xué)習(xí)來提高圖像分類,由于一般的圖像增強(qiáng)方法沒有評判標(biāo)準(zhǔn),所以將圖像增強(qiáng)與分類任務(wù)結(jié)合起來,以提高圖像分類正確率作為圖像增強(qiáng)的標(biāo)準(zhǔn),更具有實(shí)際意義。但這種方法存在一些問題,文中使用五種傳統(tǒng)的增強(qiáng)方法來得到目標(biāo)圖像,所以增強(qiáng)網(wǎng)絡(luò)學(xué)習(xí)到的結(jié)果最好也是接近這幾種方法的結(jié)果,且文中沒有具體研究這些增強(qiáng)后的圖像,所以不知道它的效果到底如何,只能說明有助于圖像的分類。
Range Scaling Global U-Net for Perceptual Image Enhancement on Mobile Devices
這是ECCV-PIRM2018(Perceptual Image Enhancement on Smartphones Challenge)挑戰(zhàn)賽中,圖像增強(qiáng)任務(wù)第一名的論文,主要用于處理手機(jī)等小型移動(dòng)設(shè)備上的圖像增強(qiáng)。現(xiàn)有的圖像增強(qiáng)方法在亮度、顏色、對比度、細(xì)節(jié)、噪聲抑制等方面對低質(zhì)量圖像進(jìn)行了改進(jìn),但由于移動(dòng)設(shè)備處理速度慢、內(nèi)存消耗大,很少能解決感知圖像增強(qiáng)的問題,已有的一些方法也很難直接遷移到手機(jī)上使用。移動(dòng)設(shè)備上的感知圖像增強(qiáng),尤其是智能手機(jī),最近引起了越來越多的工業(yè)界和學(xué)術(shù)圈興趣,因此本文提出了一個(gè)尺度縮放的全局U-Net網(wǎng)絡(luò)(Range Scaling Global U-Net,RSGUNet)用于移動(dòng)設(shè)備上的圖像增強(qiáng)。
這篇文章的網(wǎng)絡(luò)結(jié)構(gòu)如下:
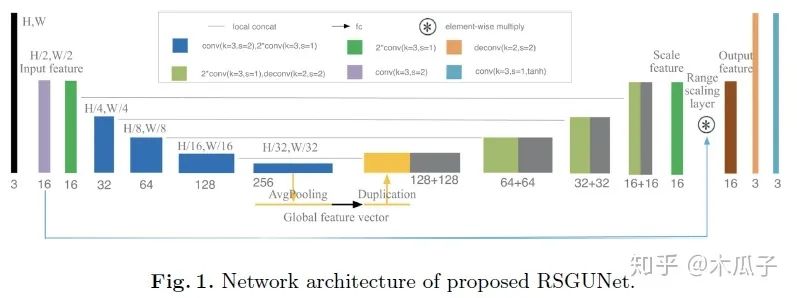
主體框架是U-Net,可以利用不同分辨率下圖像的feature map。在此基礎(chǔ)上本文做出了兩點(diǎn)改進(jìn),一是引入全局特征來減少視覺偽影,二是使用range scaling layer代替residuals,也就是逐個(gè)元素相乘,而不是相加。作者通過實(shí)驗(yàn)發(fā)現(xiàn)這兩點(diǎn)創(chuàng)新可以緩解增強(qiáng)后圖像的視覺偽影。這里的全局特征向量可以看成是一個(gè)正則化器,用于懲罰會(huì)導(dǎo)致視覺偽影的低分辨率特征,且使用avgpooling來提取全局特征比使用全連接層所需要的參數(shù)量更少。Range scaling layer可以實(shí)現(xiàn)像素強(qiáng)度的逐像素縮放,相比于傳統(tǒng)的residual-learning殘差學(xué)習(xí)網(wǎng)絡(luò),本文提出的RSGUNet網(wǎng)絡(luò)能力更強(qiáng),它能學(xué)習(xí)到更精細(xì)、更復(fù)雜的低質(zhì)量圖像到高質(zhì)量圖像的映射關(guān)系。
Loss函數(shù)的設(shè)計(jì)包括L1 loss, MS-SSIM loss, VGG loss, GAN loss and total variation loss。
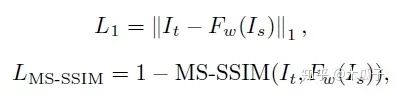
L1 loss可以獲得色彩和亮度信息;MS-SSIM loss可以保留更多高頻信息,有實(shí)驗(yàn)證明,這兩個(gè)loss組合比L2 loss的效果要好。
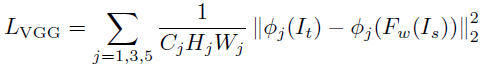
VGG loss保證了增強(qiáng)后圖像和目標(biāo)圖像特征表現(xiàn)的相似性,它是在預(yù)訓(xùn)練好的VGG計(jì)算多個(gè)層之間feature map歐式距離的均值得到的。
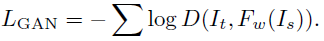
GAN loss可以近似兩幅圖像之間的感知距離,因此最小化GAN loss可以使得生成的圖像更加真實(shí)。
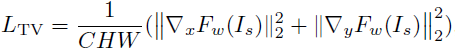
TV loss可以有效抑制高頻噪聲。
總的loss為這些loss的加權(quán)和:
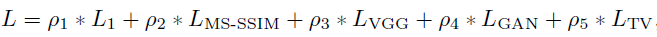
實(shí)驗(yàn)中用到的數(shù)據(jù)集是DPED中iPhone和Canon這個(gè)數(shù)據(jù)對,訓(xùn)練集為160000個(gè)100*100的patch,驗(yàn)證集為43000個(gè)patch,測試的時(shí)候用的是400張?jiān)瓐D,作者對比了一些方法,結(jié)果如下:
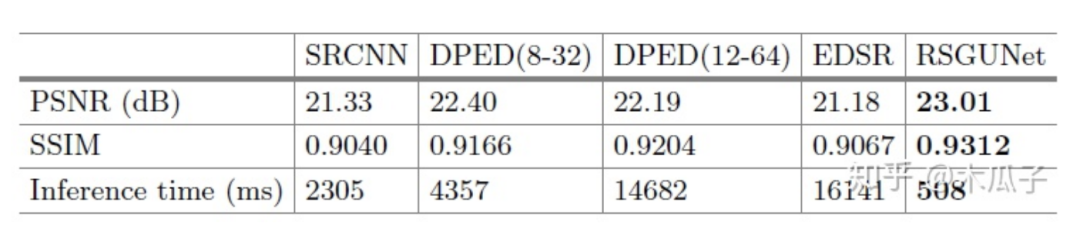
可視化結(jié)果如下:

PRIM2018圖像增強(qiáng)挑戰(zhàn)賽的結(jié)果如下:
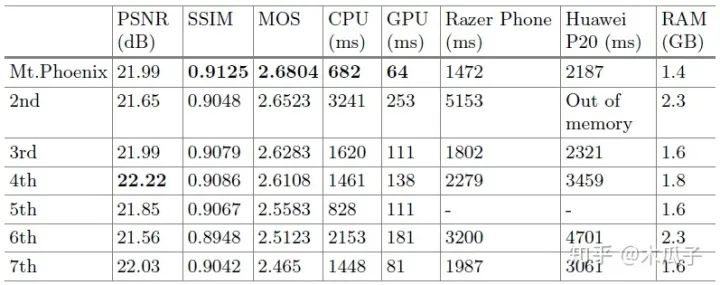
這篇論文也存在一些問題,它在大多數(shù)圖像上表現(xiàn)較好,但少數(shù)增強(qiáng)后的圖像比較黑或者模糊,原因可能是U-Net的下采樣操作,但實(shí)驗(yàn)結(jié)果中沒有發(fā)現(xiàn)偽影。總的來說,本文提出的結(jié)構(gòu)在主觀上和客觀上都取得了較好的效果,且計(jì)算復(fù)雜度大大降低,適用于移動(dòng)設(shè)備上的圖像增強(qiáng)。這篇文章也給我們提供了一個(gè)新的研究方向,探索新的、輕量級的網(wǎng)絡(luò)結(jié)構(gòu)來實(shí)現(xiàn)實(shí)時(shí)的圖像增強(qiáng)任務(wù)。
Fast Perceptual Image Enhancement
這篇文章跟上一篇一樣,也是ECCV-PRIM2018年挑戰(zhàn)賽的,在圖像增強(qiáng)任務(wù)上獲得第二名,它是在這邊介紹的第一篇論文的模型作為baseline,在它的基礎(chǔ)上改進(jìn)了生成器模型,判別器模型和loss函數(shù)的設(shè)計(jì)都跟baseline一樣,但其速度大大提升,因此可以適用于移動(dòng)設(shè)備上。
來看一下baseline和這篇論文的生成器模型:

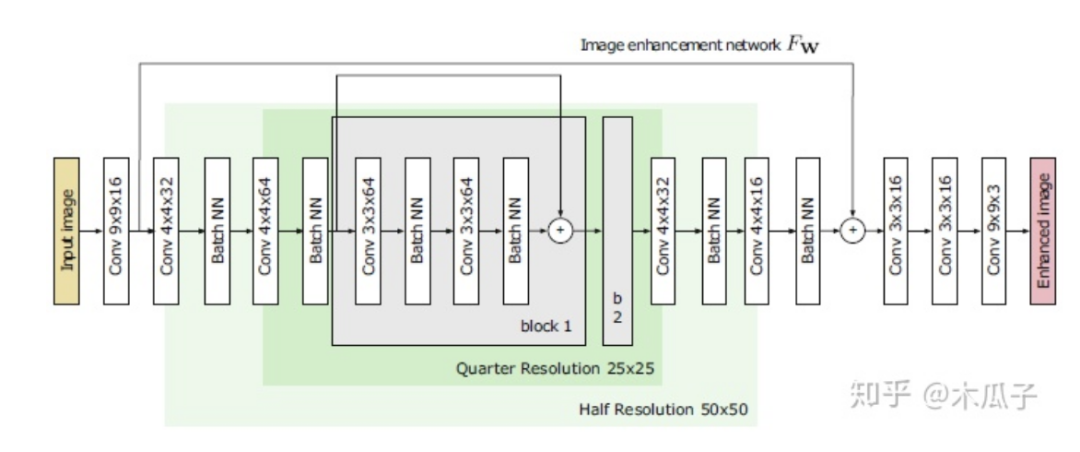
通過對比可以發(fā)現(xiàn),block的數(shù)量從4變成了2,第一層和最后幾層的通道數(shù)都大大減少,降低模型的復(fù)雜度。此外,為了進(jìn)一步減少計(jì)算時(shí)間,還做了一個(gè)改進(jìn)就是空間分辨率的減少,多出來的4*4*32和4*4*64其實(shí)是一個(gè)下采樣(strided convolutional layers),每次卷積后feature map的大小就減半,在兩個(gè)residual block后的兩個(gè)卷積層相當(dāng)于是兩個(gè)上采樣層(transposed convolution layers),將特征恢復(fù)到原始分辨率。在每個(gè)分辨率下,通過skip connection將相同分辨率的feature map學(xué)習(xí)一個(gè)殘差,便于網(wǎng)絡(luò)學(xué)習(xí)。作者對比了不同的卷積核大小、通道數(shù)及block數(shù)對模型性能與速度的影響,結(jié)果如下:
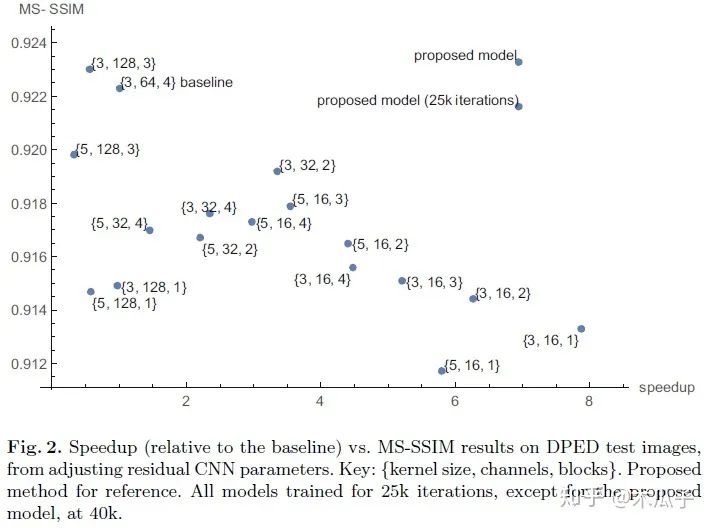
可以看到,本文提出的模型在不影響性能的情況下,實(shí)現(xiàn)了baseline近6.3倍的加速。雖然該模型由于上采樣過程會(huì)引入輕微的棋盤偽影,但它是一個(gè)不損失圖像質(zhì)量的更快的模型,本文采用的數(shù)據(jù)集也是DPED,測試結(jié)果如下:
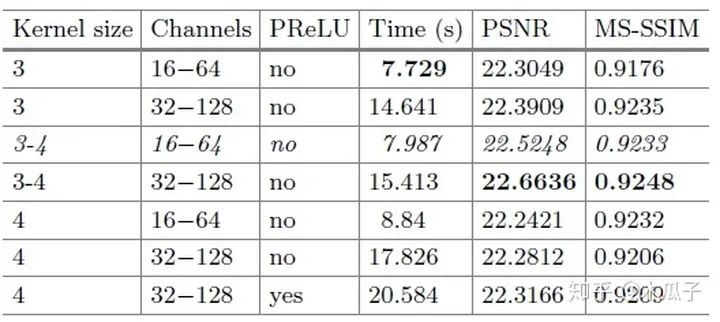
作者對不通道卷積核大小、通道數(shù)以及激活函數(shù)進(jìn)行了實(shí)驗(yàn),最終權(quán)衡了效果和速度,選擇了第三行的參數(shù)作為網(wǎng)絡(luò)結(jié)構(gòu)。
可視化結(jié)果如下:

與baseline相比,本文的方法生成的圖像在某些方面更加精細(xì),在邊緣處沒有色彩偽影,且減少噪聲,紋理更清晰。從整體上來說,這篇文章的創(chuàng)新的不是很大,在baseline基礎(chǔ)上網(wǎng)絡(luò)結(jié)構(gòu)的沒有特別大的改動(dòng),但它的計(jì)算速度明顯提升,這就表明了基于卷積神經(jīng)網(wǎng)絡(luò)的圖像增強(qiáng)已經(jīng)可以產(chǎn)生適用于移動(dòng)設(shè)備的高質(zhì)量的結(jié)果。
Deep Networks for Image-to-Image Translation with Mux and Demux Layers
這篇論文是ECCV-PRIM2018年挑戰(zhàn)賽圖像增強(qiáng)任務(wù)的第三名,雖然結(jié)果沒有之前兩篇的好,但創(chuàng)新點(diǎn)比較大。第一,這篇論文提出了一種shuffle pixel的上采樣和下采樣層,分別稱為Mux and Demux layers,可以直接在CNN中使用,和標(biāo)準(zhǔn)的池化操作相比,這種方式可以保持輸入信息不丟失;第二,提出了一種的CNN結(jié)構(gòu),將Mux,Demux,DenseNet結(jié)合起來,在低分辨率下處理feature map,效率比較高;第三,本文在DPED方法基礎(chǔ)上引入了一個(gè)加權(quán)的L1 loss和上下文損失,(contextual loss),為了驗(yàn)證,使用NIQE index來提高圖像的感知質(zhì)量。
先來看一下Demux和Mux layer,結(jié)構(gòu)如下:
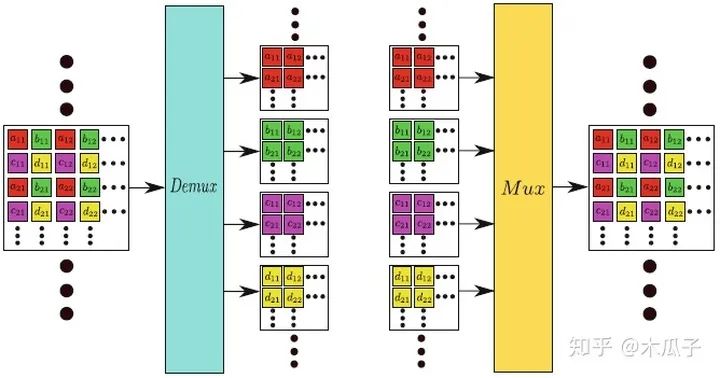
Mux layer類似于pixel shuffling layer,能直接處理feature map產(chǎn)生一個(gè)新的feature map,可以直接在卷積神經(jīng)網(wǎng)絡(luò)中當(dāng)成一個(gè)上采樣層。Mux先把輸入分為幾個(gè)小組,每組四個(gè)feature map,按上述規(guī)則重新排列,輸出的feature map長寬分別為輸入的兩倍,數(shù)量為輸入的1/4。Demux可以看成網(wǎng)絡(luò)中的下采樣操作,是Mux的逆過程,其feature map數(shù)量是輸入的4倍,長寬分別為輸入的1/2。標(biāo)準(zhǔn)的下采樣操作如max pooling, average pooling, strided convolutional 是不可逆的,但本文中提出的這種方式?jīng)]有改變?nèi)魏蜗袼刂担礇]有丟失輸入信息,這是提高深度學(xué)習(xí)模型性能的關(guān)鍵之一。
本文的網(wǎng)絡(luò)結(jié)構(gòu)包含一個(gè)生成器和一個(gè)判別器,判別器和DPED中的結(jié)構(gòu)一樣,生成器有兩種不同的結(jié)構(gòu),如下:
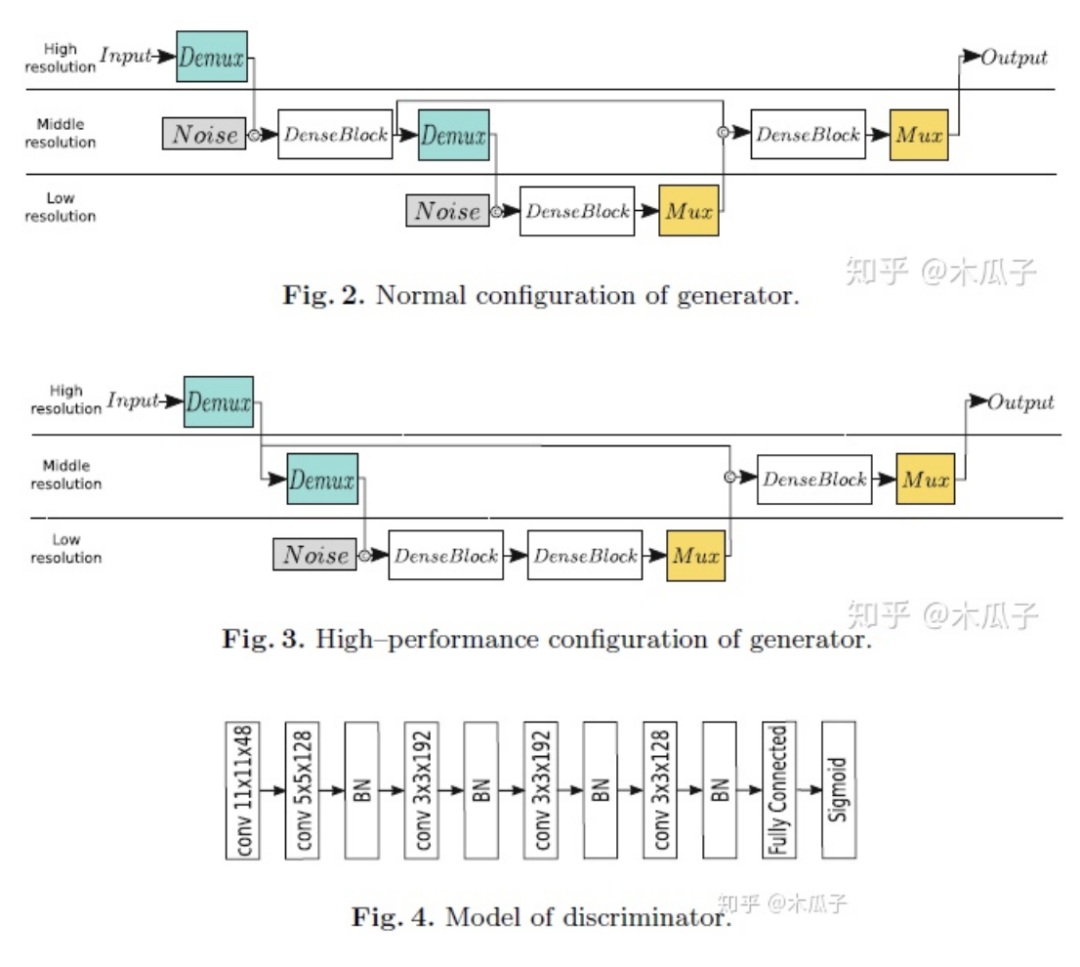
從圖2中可以看出,生成器處理三種分辨率,輸入一張RGB圖像先經(jīng)過下采樣,為了生成高頻細(xì)節(jié)和高感知質(zhì)量的圖像,每次下采樣后引入噪聲通道,然后輸入到DenseBlock進(jìn)行處理,再經(jīng)過一次相同的操作,之后兩次上采樣得到輸出的RGB圖像,在每個(gè)卷積層后使用instance normalization來調(diào)整feature map的全局參數(shù)。圖3中,直接對輸入圖像做兩次下采樣操作,得到的feature map比較小,可以減少計(jì)算復(fù)雜性且提高模型性能。圖4判別器網(wǎng)絡(luò)包含五個(gè)卷積層,每個(gè)接著一個(gè)LeakyReLU和BN,第1,2,5個(gè)卷積層的步長分別為4,2,2。
Loss函數(shù)在DPED的基礎(chǔ)上引入了一個(gè)加權(quán)的L1 loss,如下:

分別計(jì)算R,G,B三個(gè)通道的L1損失,參數(shù)使用的是YUV色彩空間轉(zhuǎn)換的系數(shù)。
還有和一個(gè)上下文損失(Contextual Loss),如下:
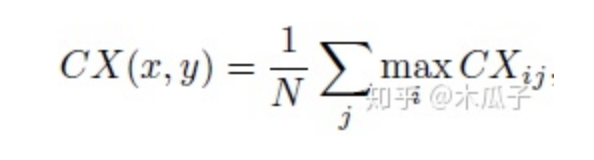
其中CXij表示兩個(gè)特征之間的相似性,定義為:

Dij表示xi, yi之間的余弦距離,eps=0.00001, h>0為帶寬系數(shù),最終的上下文損失為:

DPED中的4個(gè)損失函數(shù)分別如下:
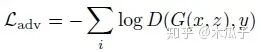
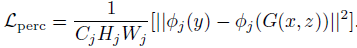
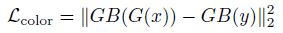

總的損失為:

系數(shù)分別為:5000,10,10,0.5,2000。
在DPED上的實(shí)驗(yàn)結(jié)果如下:
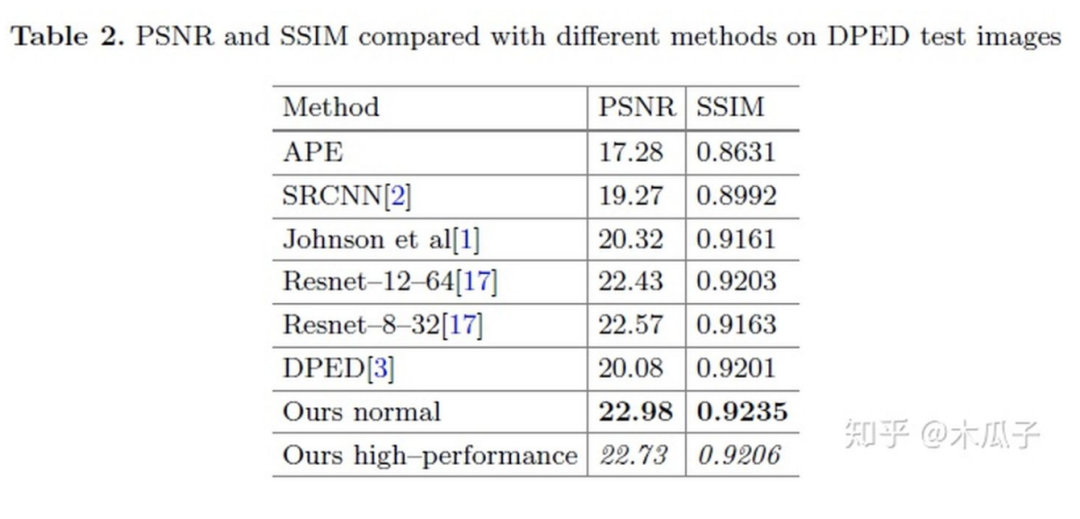
在衡量圖像的PSNR和SSIM之外,本文還引入了一種新的評價(jià)機(jī)制NIQE。Natural Image Quality Evaluator(NIQE)是一種盲圖像質(zhì)量指數(shù),它基于一組已知的統(tǒng)計(jì)特征,這些特征對自然圖像遵循多元高斯分布。它可以在沒有任何參考圖像的情況下量化自然或真實(shí)圖像的外觀,提供類似于人類評估的感知質(zhì)量指數(shù)。其值越小,則表示圖像感知質(zhì)量越好,可以看到本文的結(jié)果所得的NIQE最低。

可視化結(jié)果如下:

從圖中可以看出,DPED的結(jié)果局部過亮,本文中的方法比其他方法更能平衡對比度和細(xì)節(jié),得到高質(zhì)量的感知圖像。但也存在局限性,當(dāng)輸入圖像過亮或者曝光過度的時(shí)候就很難成功轉(zhuǎn)化為高質(zhì)量圖像,這可能是數(shù)據(jù)集的影響,DPED中只包含低亮度的圖像,因此可以在訓(xùn)練中加入一些自適應(yīng)和擴(kuò)展的數(shù)據(jù)集。
總的來說,本文提出了新的上采樣和下采樣操作,引入了兩個(gè)新的損失函數(shù)和NIQE這個(gè)評價(jià)機(jī)制,并在實(shí)驗(yàn)中加入噪聲通道,可以有效提高圖像感知質(zhì)量,在低分辨率下處理圖像,也使得模型復(fù)雜度大大降低,適用于手機(jī)等移動(dòng)設(shè)備。
本文亮點(diǎn)總結(jié)
如果覺得有用,就請分享到朋友圈吧!
公眾號(hào)后臺(tái)回復(fù)“pytorch”獲取Pytorch 官方書籍英文版電子版~

# CV技術(shù)社群邀請函 #
備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳)
即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動(dòng)駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動(dòng)交流~
