
深度學習中用于張量重塑的 MLP 和 Transformer 之間的差異圖解

來源:Deephub Imba 本文約1800字,建議閱讀5分鐘?
本文介紹在設計神經網(wǎng)絡時如何解決張量整形的問題。
計算機視覺中使用的神經網(wǎng)絡張量通常具有 NxHxWxC 的“形狀”(批次、高度、寬度、通道)。這里我們將關注空間范圍 H 和 W 中形狀的變化,為簡單起見忽略批次維度 N,保持特征通道維度 C 不變。我們將 HxW 粗略地稱為張量的“形狀”或“空間維度”。 在 pytorch 和許多其他深度學習庫的標準術語中,“重塑”不會改變張量中元素的總數(shù)。在這里,我們在更廣泛的意義上使用 重塑(reshape) 一詞,其中張量中的元素數(shù)量可能會改變。
如何使用 MLP 和 Transformers 來重塑張量?
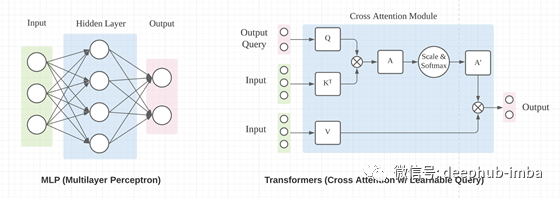
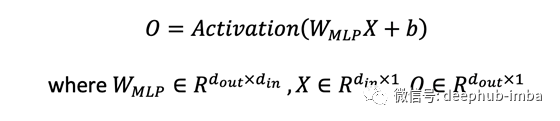
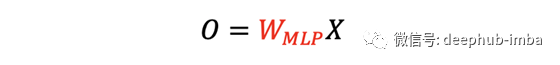
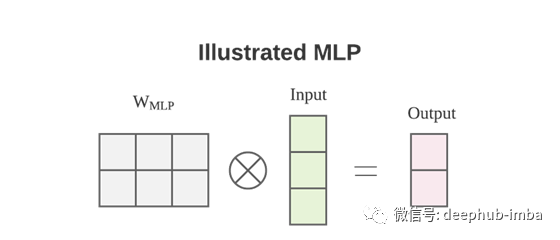
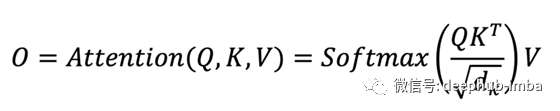
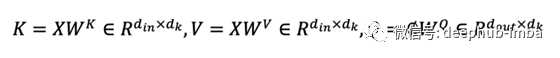
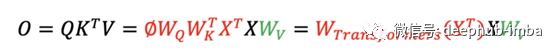
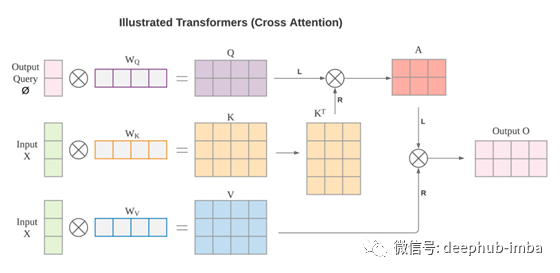
輸出 O 通過了一個額外的線性投影,將特征通道從 1 的輸入提升到 d_k 的輸出。 Transformers 中的 W 矩陣取決于輸入 X。
區(qū)別1:數(shù)據(jù)依賴
區(qū)別2:輸入順序
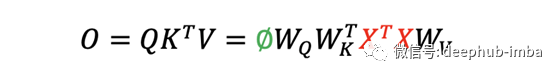


總結
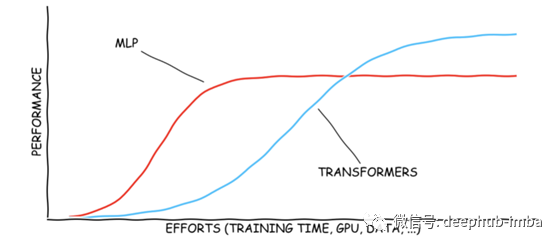
MLP 和 Transformers(交叉注意力)都可以用于張量重塑。 MLP 的重塑機制不依賴于數(shù)據(jù),而 Transformers 則依賴于數(shù)據(jù)。這種數(shù)據(jù)依賴性使 Transformer 更難訓練,但可能具有更高的上限。 注意力不編碼位置信息。自注意力是排列等變的,交叉注意力是排列不變的。MLP 對排列高度敏感,隨機排列可能會完全破壞 MLP 結果。
引用
Attention is All you Need, NeurIPS 2017 Mathematical properties of Attention in Transformers, Professor Shuiwang Ji’s class notes, TAMU
評論
圖片
表情