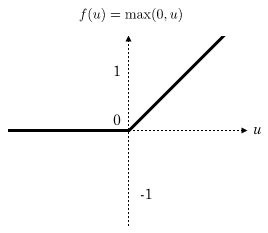
這一篇文章的主題是深度學(xué)習(xí)在基因組學(xué)中的應(yīng)用情況的。文章較長(zhǎng),讀完要花些時(shí)間,不過我的建議是通讀第一部分——關(guān)于如何進(jìn)行模型訓(xùn)練的內(nèi)容,讀完后你應(yīng)該可以理解機(jī)器學(xué)習(xí)模型的訓(xùn)練過程和邏輯,剩下的部分可以挑重點(diǎn)的看。
基因組學(xué)其實(shí)是一門將數(shù)據(jù)驅(qū)動(dòng)作為主要研究手段的學(xué)科,機(jī)器學(xué)習(xí)方法和統(tǒng)計(jì)學(xué)方法在基因組學(xué)中的應(yīng)用一直都比較廣泛。不過現(xiàn)在多組學(xué)數(shù)據(jù)進(jìn)一步激增——這個(gè)從目前逐漸增多的各類大規(guī)模人群基因組項(xiàng)目上可以看出來,這其實(shí)帶來了新的挑戰(zhàn)——就是數(shù)據(jù)挖掘的難度增加了。我們要高效地從多組學(xué)數(shù)據(jù)中挖掘出有價(jià)值的信息,那么就需要掌握更富有表現(xiàn)力的方法,這個(gè)時(shí)候深度學(xué)習(xí)就成了一個(gè)合適的選擇。因?yàn)榫湍壳皝碚f深度學(xué)習(xí)本身就適合用來挖掘大量的、多維度數(shù)據(jù)背后的潛在規(guī)則,它也已經(jīng)改變了多個(gè)計(jì)算機(jī)領(lǐng)域,包括圖片識(shí)別、人臉識(shí)別、機(jī)器翻譯、自然語言處理等。近年來深度學(xué)習(xí)在基因組學(xué)領(lǐng)域也有了不少的研究和應(yīng)用,我這篇文章主要基于 Nature Reviews Genetics 上《Deep learning- new computational modelling techniques for genomics》的內(nèi)容,同時(shí)我也做了一些額外的補(bǔ)充,目的是和大家一起梳理一下目前深度學(xué)習(xí)在基因組學(xué)研究方面的應(yīng)用情況。- 第一,介紹有監(jiān)督學(xué)習(xí)中四個(gè)主要的神經(jīng)網(wǎng)絡(luò),分別是:全連接網(wǎng)絡(luò)、深度卷積、循環(huán)卷積和圖卷積,同時(shí)解釋了如何將它們用來抽取基因組數(shù)據(jù)中常見的 Pattern;
- 第二,介紹多任務(wù)學(xué)習(xí)和多模態(tài)學(xué)習(xí),這是兩種適合于集成多維數(shù)據(jù)集的建模方法;
- 第三,討論遷移學(xué)習(xí),這是一種可以從現(xiàn)有模型中開發(fā)新模型的技術(shù)。這個(gè)方法對(duì)于多組學(xué)的研究和應(yīng)用來說有著實(shí)際的價(jià)值;
- 第四,討論自動(dòng)編碼器(Autoencoder, AE)和生成對(duì)抗網(wǎng)絡(luò)(generative adversarial networks,GANs)這兩個(gè)非監(jiān)督學(xué)習(xí)方法。
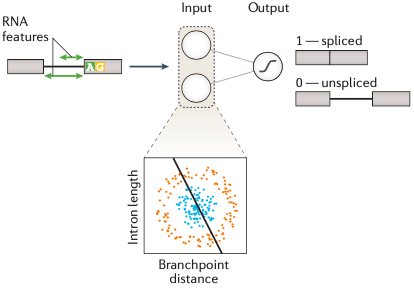
好,接下來,我將逐一展開介紹這四個(gè)方面的內(nèi)容,同時(shí)為了讓你可以更好地理解這篇文章,我穿插補(bǔ)充了一些關(guān)于機(jī)器學(xué)習(xí)的背景知識(shí)。這一部分的內(nèi)容與有監(jiān)督學(xué)習(xí)有關(guān),因此我們要先了解什么是“有監(jiān)督學(xué)習(xí)”。圖1 是有監(jiān)督學(xué)習(xí)的一個(gè)示意圖:圖1. 有監(jiān)督學(xué)習(xí)示意圖簡(jiǎn)單來說,有監(jiān)督學(xué)習(xí)的過程是輸入樣本的特征值(這個(gè)特征值可以是一個(gè)值,也可以由是一系列值構(gòu)成的向量),然后預(yù)測(cè)出樣本屬于哪一個(gè)結(jié)果標(biāo)簽(或叫做“標(biāo)注”)。比如 圖1 是一個(gè)預(yù)測(cè) RNA 剪接位點(diǎn)的例子,這里模型要依據(jù)樣本的特征值(如:位點(diǎn)序列信息、位置、內(nèi)含子長(zhǎng)度等)進(jìn)行計(jì)算得到一個(gè)是否為剪接位點(diǎn)的預(yù)測(cè)結(jié)果。另外,圖1 其實(shí)是一個(gè)由邏輯回歸組成的單層神經(jīng)網(wǎng)絡(luò)分類模型。
所以,有監(jiān)督學(xué)習(xí)是一種需要使用標(biāo)簽化數(shù)據(jù)進(jìn)行訓(xùn)練,然后推斷出輸入特征和結(jié)果標(biāo)簽之間函數(shù)映射關(guān)系的機(jī)器學(xué)習(xí)方法,模型的訓(xùn)練數(shù)據(jù)需要有明確的結(jié)果標(biāo)簽,否則不能訓(xùn)練。搞清楚定義之后,那有監(jiān)督機(jī)器學(xué)習(xí)是如何進(jìn)行模型訓(xùn)練的呢?所謂訓(xùn)練其實(shí)就是求解模型參數(shù)。這個(gè)過程具體是如何實(shí)現(xiàn)的呢?
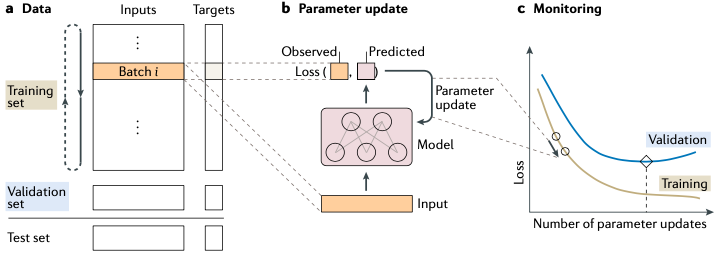 圖2. 模型訓(xùn)練這個(gè)訓(xùn)練過程一共三步(圖2)——這也是絕大多數(shù)機(jī)器學(xué)習(xí)算法進(jìn)行模型訓(xùn)練的方式,具體如下:首先,要將訓(xùn)練數(shù)據(jù)分割為三個(gè)集合,分別是:訓(xùn)練集,驗(yàn)證集和測(cè)試集(如圖2.a) 。其中,訓(xùn)練集用于模型參數(shù)的計(jì)算,驗(yàn)證集用于模型性能評(píng)估和超參調(diào)整,目的是為了保障模型可以在現(xiàn)有數(shù)據(jù)條件下達(dá)到最好的結(jié)果,而測(cè)試集則是用來評(píng)測(cè)最終模型的綜合性能。2. 使用訓(xùn)練集數(shù)據(jù)計(jì)算模型參數(shù)還是以圖2為例——我們這里圖2是一個(gè)神經(jīng)網(wǎng)絡(luò)模型,訓(xùn)練開始時(shí),首先要給這個(gè)網(wǎng)絡(luò)中的各個(gè)參數(shù)進(jìn)行一次隨機(jī)初始化,然后再代入訓(xùn)練數(shù)據(jù)去迭代更新模型參數(shù)。每一次的迭代時(shí),通常都是隨機(jī)地從訓(xùn)練集中抽取一小撮數(shù)據(jù)(圖2.a中的Batch)代入模型進(jìn)行計(jì)算——注意這個(gè)過程非常重要,然后和真實(shí)結(jié)果比較獲得函數(shù)損失量。在神經(jīng)網(wǎng)絡(luò)的訓(xùn)練中目前要通過反向傳播算法做梯度運(yùn)算獲得能讓模型的參數(shù)往損失函數(shù)最小化的方向走的值,模型的參數(shù)要依據(jù)這個(gè)極值的結(jié)果進(jìn)行更新。接著再重新到訓(xùn)練數(shù)據(jù)中隨機(jī)抽取另一小撮的數(shù)據(jù)集重復(fù)這一輪迭代,直到損失函數(shù)收斂。
圖2. 模型訓(xùn)練這個(gè)訓(xùn)練過程一共三步(圖2)——這也是絕大多數(shù)機(jī)器學(xué)習(xí)算法進(jìn)行模型訓(xùn)練的方式,具體如下:首先,要將訓(xùn)練數(shù)據(jù)分割為三個(gè)集合,分別是:訓(xùn)練集,驗(yàn)證集和測(cè)試集(如圖2.a) 。其中,訓(xùn)練集用于模型參數(shù)的計(jì)算,驗(yàn)證集用于模型性能評(píng)估和超參調(diào)整,目的是為了保障模型可以在現(xiàn)有數(shù)據(jù)條件下達(dá)到最好的結(jié)果,而測(cè)試集則是用來評(píng)測(cè)最終模型的綜合性能。2. 使用訓(xùn)練集數(shù)據(jù)計(jì)算模型參數(shù)還是以圖2為例——我們這里圖2是一個(gè)神經(jīng)網(wǎng)絡(luò)模型,訓(xùn)練開始時(shí),首先要給這個(gè)網(wǎng)絡(luò)中的各個(gè)參數(shù)進(jìn)行一次隨機(jī)初始化,然后再代入訓(xùn)練數(shù)據(jù)去迭代更新模型參數(shù)。每一次的迭代時(shí),通常都是隨機(jī)地從訓(xùn)練集中抽取一小撮數(shù)據(jù)(圖2.a中的Batch)代入模型進(jìn)行計(jì)算——注意這個(gè)過程非常重要,然后和真實(shí)結(jié)果比較獲得函數(shù)損失量。在神經(jīng)網(wǎng)絡(luò)的訓(xùn)練中目前要通過反向傳播算法做梯度運(yùn)算獲得能讓模型的參數(shù)往損失函數(shù)最小化的方向走的值,模型的參數(shù)要依據(jù)這個(gè)極值的結(jié)果進(jìn)行更新。接著再重新到訓(xùn)練數(shù)據(jù)中隨機(jī)抽取另一小撮的數(shù)據(jù)集重復(fù)這一輪迭代,直到損失函數(shù)收斂。反向傳播算法是神經(jīng)網(wǎng)絡(luò)模型的基礎(chǔ),沒有這個(gè)算法就無法高效地實(shí)現(xiàn)梯度下降算法中梯度值的計(jì)算。
這種訓(xùn)練時(shí)僅從訓(xùn)練集里隨機(jī)抽取一小撮數(shù)據(jù)集的做法與一次性使用整個(gè)訓(xùn)練集的做法相比有兩個(gè)好處:- 第一,模型訓(xùn)練所需的內(nèi)存將比較恒定。因?yàn)椴槐貙⒋罅康臄?shù)據(jù)一次性加載到內(nèi)存里,因此,模型能不受計(jì)算機(jī)的內(nèi)存所限,可以使用盡可能大的訓(xùn)練集數(shù)據(jù),訓(xùn)練過程的可拓展性比較高;
- 第二,在機(jī)器學(xué)習(xí)領(lǐng)域其實(shí)已經(jīng)證明,這種小批量數(shù)據(jù)集的方法會(huì)給模型帶來一定程度的隨機(jī)波動(dòng),而這種波動(dòng)有利于模型性能的提升。
3. 通過驗(yàn)證集調(diào)整模型的超參所謂超參,就是“超級(jí)參數(shù)”,它是模型中一個(gè)(或一些)需要人為設(shè)定的外部參數(shù),而且是無法通過訓(xùn)練集進(jìn)行訓(xùn)練的,只能進(jìn)行手動(dòng)調(diào)整。比如,我們要在進(jìn)行模型訓(xùn)練之前,先給模型的某部分乘上某一個(gè)固定的常數(shù)/向量,這個(gè)常數(shù)/向量無法訓(xùn)練,它就是“超參”。通常只能一邊調(diào)整一邊在驗(yàn)證集上評(píng)估結(jié)果,最后留下一個(gè)“看起來”能夠最準(zhǔn)確貼近驗(yàn)證結(jié)果的參數(shù)。這是一個(gè)很繁瑣的過程,需要多次嘗試,直至模型性能不再出現(xiàn)改善為止。調(diào)超參一直都是機(jī)器學(xué)習(xí)模型訓(xùn)練的一個(gè)難點(diǎn)。
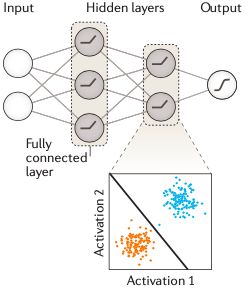
當(dāng)你完成最后的調(diào)參之后,用另一個(gè)獨(dú)立數(shù)據(jù)——也就是這里的測(cè)試集,綜合評(píng)估這個(gè)最佳模型的性能,主要是看看是否存在過擬合或者功效不足的情況,沒問題之后就可以用到項(xiàng)目中了。以上,就是訓(xùn)練一個(gè)神經(jīng)網(wǎng)絡(luò)模型的主要過程。再次強(qiáng)調(diào)一次:一共是三步,分別是:分割數(shù)據(jù)、使用訓(xùn)練集計(jì)算模型參數(shù)、通過驗(yàn)證集調(diào)整模型超參并用測(cè)試數(shù)據(jù)綜合評(píng)估最終模型的性能。了解了以上背景內(nèi)容之后,我們就可以轉(zhuǎn)入深度學(xué)習(xí)的內(nèi)容了。對(duì)于很多比較簡(jiǎn)單的問題而言,一個(gè)單層的神經(jīng)網(wǎng)絡(luò)通常是可以滿足要求的。但對(duì)于維度更多、更復(fù)雜的生物學(xué)問題來說,單層是不夠用的,只能通過更復(fù)雜的模型才能處理這類數(shù)據(jù)。圖3是一個(gè)多層神經(jīng)網(wǎng)絡(luò)模型的示意圖。圖3. 一個(gè)多層神經(jīng)網(wǎng)絡(luò)示意圖這個(gè)網(wǎng)絡(luò)有兩層,而且你可以看到中間一層不與輸出層相連接,對(duì)于輸出來說是一個(gè)不可見的“層”,所以也被稱為隱藏層,它的作用是將上一層的輸入數(shù)據(jù)做轉(zhuǎn)換,將其映射到一個(gè)可以對(duì)特征值進(jìn)行線性分離的空間,然后通過激活函數(shù)進(jìn)行非線性化,再給到后一層作為輸入。這個(gè)模型是深度神經(jīng)網(wǎng)絡(luò)的雛形,當(dāng)你的模型有許多個(gè)中間隱藏層(>2)時(shí),這個(gè)模型就稱之為深度神經(jīng)網(wǎng)絡(luò)模型。深度神經(jīng)網(wǎng)絡(luò)使用隱藏層來自動(dòng)學(xué)習(xí)非線性特征的各類變換。模型里的每一個(gè)隱藏層都可以是多個(gè)線性模型疊加一個(gè)激活函數(shù)所構(gòu)成,激活函數(shù)非常重要,它起到了將線性模型非線性化的作用,否則你的模型就無法通過非線性的形式描述真實(shí)世界的生物學(xué)問題(因?yàn)檫@些問題本身通常就是線性模型無法解答的)。目前深度學(xué)習(xí)中用得最多的激活函數(shù)是ReLU,這是一個(gè)線性整流函數(shù)(負(fù)數(shù)賦值為0,正數(shù)不變):深度學(xué)習(xí)模型的訓(xùn)練也和上面所術(shù)的過程一致。區(qū)別就在于,它涉及的參數(shù)多,需要更多的訓(xùn)練數(shù)據(jù)和更長(zhǎng)的時(shí)間才能得到理想的結(jié)果。對(duì)于我們來說深度神經(jīng)網(wǎng)絡(luò)的構(gòu)建和訓(xùn)練可以用專門的深度學(xué)習(xí)框架來實(shí)現(xiàn),比如:TensorFlow、PyTorch和Keras等。在說完上面的關(guān)于模型訓(xùn)練的內(nèi)容之后,接下來要說的是第一部分中的第一個(gè)概念:全連接網(wǎng)絡(luò)層(Fully connected layer)。全連接網(wǎng)絡(luò)層一般是深度學(xué)習(xí)模型的倒數(shù)第二、第三層,它在網(wǎng)絡(luò)中主要起分類器的作用,本質(zhì)上就是將前面各層訓(xùn)練得到的特征空間線性地變換到另一個(gè)特征空間(即,結(jié)果空間——其實(shí)就是結(jié)果集)中。結(jié)果空間的每一個(gè)維度都會(huì)受到源空間所有維度的影響,數(shù)據(jù)被利用得很充分,所以可以很準(zhǔn)確地將獲得分類結(jié)果。這么說比較抽象的話,可以通俗理解為,經(jīng)過全連接層的計(jì)算之后,目標(biāo)預(yù)測(cè)結(jié)果就是前面各層結(jié)果的加權(quán)和了。以全連接層結(jié)成的神經(jīng)網(wǎng)絡(luò)也叫全連接神經(jīng)網(wǎng)絡(luò),全連接神經(jīng)網(wǎng)絡(luò)在基因組學(xué)里也都有所應(yīng)用,比如一開始我提到的剪接位點(diǎn)預(yù)測(cè),還有致病突變預(yù)測(cè)、基因表達(dá)預(yù)測(cè)特定基因區(qū)域內(nèi)順式調(diào)控元件的預(yù)測(cè)等,但全連接層神經(jīng)網(wǎng)絡(luò)運(yùn)算量很大。深度卷積神經(jīng)網(wǎng)絡(luò)
接下來,我們用深度卷積神經(jīng)網(wǎng)絡(luò)(也就是CNN)作為例子,介紹序列模式特征的發(fā)現(xiàn)過程。如圖5 所示,這個(gè)模型要通過神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)TAL1-GATA1轉(zhuǎn)錄因子復(fù)合物的結(jié)合親和力。
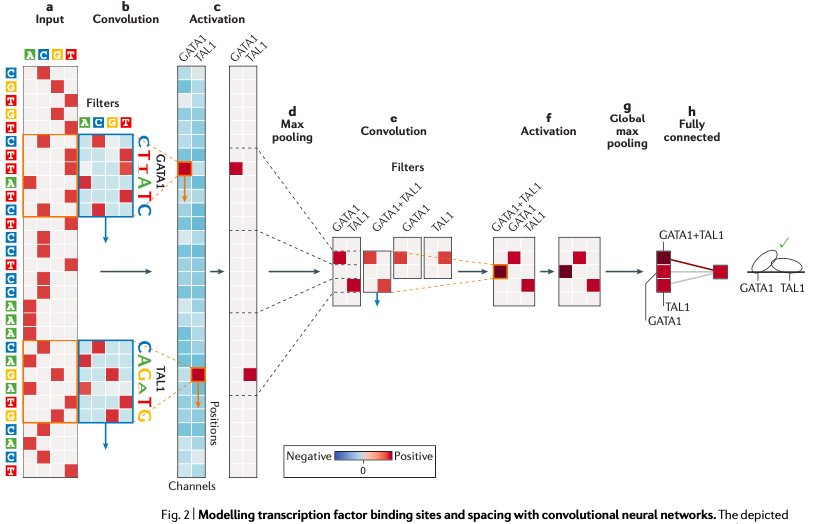 圖5. 基于CNN的序列模式特征檢測(cè)圖中,從左到右,第一層分別以 GATA1 和 TAL1 轉(zhuǎn)錄因子的位置為權(quán)重濾波器,滑動(dòng)掃描整個(gè) DNA 序列,然后卷積計(jì)算每一個(gè)掃描框中的結(jié)果形成一個(gè)權(quán)重矩陣(b-c),再使用 ReLU 激活函數(shù)——這個(gè)激活函數(shù)會(huì)將負(fù)值重新賦為0,正值則保持不變,進(jìn)一步做運(yùn)算。然后再用最大池化操作(圖中的Max pooling),獲取位置軸上各個(gè)連續(xù)窗口內(nèi)的最大加權(quán)結(jié)果,再傳入下一個(gè)卷積層進(jìn)行新一輪的運(yùn)算和特征訓(xùn)練,過程與第一個(gè)卷積層類似,最后再經(jīng)過一個(gè)全連接層,得到最終想要的預(yù)測(cè)結(jié)果。目前利用 CNN 對(duì)序列特征預(yù)測(cè)轉(zhuǎn)錄因子結(jié)合位點(diǎn)的方法有三個(gè),分別是DeepBind、DeepSEA和Basset。而且這是目前 CNN 在基因組序列特征預(yù)測(cè)方面做的比較成功的例子。
圖5. 基于CNN的序列模式特征檢測(cè)圖中,從左到右,第一層分別以 GATA1 和 TAL1 轉(zhuǎn)錄因子的位置為權(quán)重濾波器,滑動(dòng)掃描整個(gè) DNA 序列,然后卷積計(jì)算每一個(gè)掃描框中的結(jié)果形成一個(gè)權(quán)重矩陣(b-c),再使用 ReLU 激活函數(shù)——這個(gè)激活函數(shù)會(huì)將負(fù)值重新賦為0,正值則保持不變,進(jìn)一步做運(yùn)算。然后再用最大池化操作(圖中的Max pooling),獲取位置軸上各個(gè)連續(xù)窗口內(nèi)的最大加權(quán)結(jié)果,再傳入下一個(gè)卷積層進(jìn)行新一輪的運(yùn)算和特征訓(xùn)練,過程與第一個(gè)卷積層類似,最后再經(jīng)過一個(gè)全連接層,得到最終想要的預(yù)測(cè)結(jié)果。目前利用 CNN 對(duì)序列特征預(yù)測(cè)轉(zhuǎn)錄因子結(jié)合位點(diǎn)的方法有三個(gè),分別是DeepBind、DeepSEA和Basset。而且這是目前 CNN 在基因組序列特征預(yù)測(cè)方面做的比較成功的例子。循環(huán)卷積神經(jīng)網(wǎng)絡(luò)
介紹完CNN之后,我們開始探討循環(huán)卷積神經(jīng)網(wǎng)絡(luò)——簡(jiǎn)稱RNN。鑒于它的特征,目前它主要在基因組遠(yuǎn)端調(diào)控預(yù)測(cè)方面有所運(yùn)用。這是因?yàn)?RNN 相比于 CNN,它更加適合用于處理序列化的數(shù)據(jù),包括時(shí)間序列數(shù)據(jù)、語言數(shù)據(jù)、文字翻譯以及 DNA 序列數(shù)據(jù),而且 RNN 對(duì)每一段序列單元都使用相同的操作,參數(shù)之間由一定的方式進(jìn)行共享。
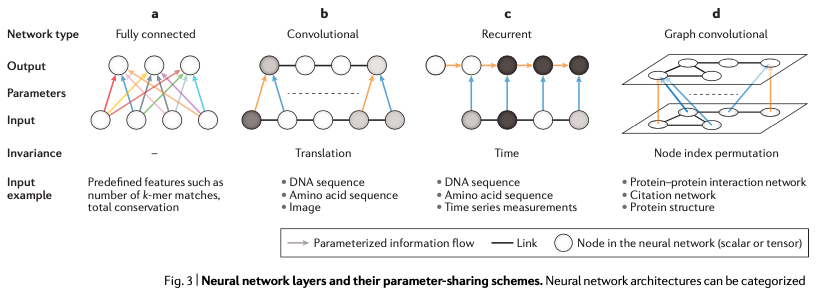 圖6. RNN鑒于 RNN 模型的這些特點(diǎn),它既可以有效地在DNA序列的任意位置上進(jìn)行開放讀碼框的預(yù)測(cè),也可以用來識(shí)別某類特定的輸入序列,比如起始密碼子預(yù)測(cè)、終止密碼子預(yù)測(cè)等。相比于CNN,RNN模型的主要優(yōu)勢(shì)在于,RNN模型可以很自然地處理長(zhǎng)度變化很大的DNA序列,比如mRNA序列就很適合通過RNN模型來進(jìn)行處理和分析。如果CNN要達(dá)到類似的效果,需要作出很多繁瑣的模型調(diào)整。不過,由于 RNN 只能對(duì)序列進(jìn)行從前到后的順序操作,因此也不太容易進(jìn)行并行化處理,這就導(dǎo)致它的速度要比 CNN 模型慢很多。在基因組學(xué)的應(yīng)用方面,RNN 主要是用在單細(xì)胞 DNA 甲基化預(yù)測(cè)、RNA binding protein預(yù)測(cè)和表觀遺傳學(xué)中DNA長(zhǎng)序列可及性的預(yù)測(cè)(也就是長(zhǎng)序列調(diào)控的預(yù)測(cè))。如果你對(duì)這一塊感興趣可以試試 deepTarget/deepMiRGene,它們就是干這些事情的。此外,最近有一項(xiàng)研究發(fā)現(xiàn),RNN模型還可用在測(cè)序數(shù)據(jù)的堿基識(shí)別(即Base-calling)。這在三代測(cè)序數(shù)據(jù)的Base-calling中有應(yīng)用,DeepNano 就是通過構(gòu)造合適的 RNN 模型對(duì) Oxford Nanopore 測(cè)序儀所產(chǎn)出的長(zhǎng)讀長(zhǎng)測(cè)序序列進(jìn)行堿基識(shí)別的方法。圖卷積神經(jīng)網(wǎng)絡(luò)模型(GCN)圖6(d),在基因組學(xué)中涉及的應(yīng)用還很少。它比較合適的應(yīng)用場(chǎng)景是蛋白質(zhì)之間互作用的網(wǎng)絡(luò)或者基因與基因之間的調(diào)控網(wǎng)絡(luò)上。因?yàn)檫@兩個(gè)方面的網(wǎng)絡(luò),在邏輯上都將是以圖結(jié)構(gòu)的形式呈現(xiàn)。圖卷積神經(jīng)網(wǎng)絡(luò)通過圖中代表個(gè)體特征的節(jié)點(diǎn)和節(jié)點(diǎn)與節(jié)點(diǎn)之間的連接性來實(shí)行機(jī)器學(xué)習(xí)任務(wù)。雖然應(yīng)用還比較少,但GCN實(shí)際上提供了一種分析圖結(jié)構(gòu)數(shù)據(jù)的新方法,值得在基因組學(xué)中進(jìn)行更多的嘗試和應(yīng)用,比如可以嘗試?yán)盟鼇斫鉀Q腫瘤亞型的分類等。第二部分要介紹的內(nèi)容是“多任務(wù)學(xué)習(xí)和多模態(tài)學(xué)習(xí)”。之所以涉及到這個(gè)方面,是因?yàn)榛驍?shù)據(jù)實(shí)際上并非只有 DNA 序列這一類遺傳方面的數(shù)據(jù),還涉及到轉(zhuǎn)錄組、表觀組修飾、蛋白組等多組學(xué)數(shù)據(jù),而且數(shù)據(jù)在彼此之間存在著一定的內(nèi)在關(guān)系。如何處理和整合這些多組學(xué)數(shù)據(jù)就涉及到“多任務(wù)和多模態(tài)學(xué)習(xí)”這個(gè)問題了。在多模態(tài)學(xué)習(xí)模型的構(gòu)成中,它有一個(gè)總損失函數(shù),它的值是各個(gè)模態(tài)數(shù)據(jù)損失函數(shù)之和或者加權(quán)和,這取決于各個(gè)模態(tài)之間損失函數(shù)的結(jié)果是否差異巨大。下面圖7.a-c 是一個(gè)多任務(wù)和多模態(tài)學(xué)習(xí)的示意圖。這類模型的訓(xùn)練往往比較困難,因?yàn)樾枰瑫r(shí)優(yōu)化學(xué)習(xí)網(wǎng)絡(luò)中多個(gè)不同的損失函數(shù),并且往往還得做出合適的取舍,每一個(gè)取舍都要有合理的內(nèi)在理由。而且如果不同的類型的數(shù)據(jù)之間,出現(xiàn)了較為嚴(yán)重的權(quán)重失衡的話——比如出現(xiàn)”一超無強(qiáng)”的情況,那么最終的模型可能僅能代表一小撮數(shù)據(jù)的結(jié)果,這就會(huì)讓模型出現(xiàn)嚴(yán)重偏差。
圖6. RNN鑒于 RNN 模型的這些特點(diǎn),它既可以有效地在DNA序列的任意位置上進(jìn)行開放讀碼框的預(yù)測(cè),也可以用來識(shí)別某類特定的輸入序列,比如起始密碼子預(yù)測(cè)、終止密碼子預(yù)測(cè)等。相比于CNN,RNN模型的主要優(yōu)勢(shì)在于,RNN模型可以很自然地處理長(zhǎng)度變化很大的DNA序列,比如mRNA序列就很適合通過RNN模型來進(jìn)行處理和分析。如果CNN要達(dá)到類似的效果,需要作出很多繁瑣的模型調(diào)整。不過,由于 RNN 只能對(duì)序列進(jìn)行從前到后的順序操作,因此也不太容易進(jìn)行并行化處理,這就導(dǎo)致它的速度要比 CNN 模型慢很多。在基因組學(xué)的應(yīng)用方面,RNN 主要是用在單細(xì)胞 DNA 甲基化預(yù)測(cè)、RNA binding protein預(yù)測(cè)和表觀遺傳學(xué)中DNA長(zhǎng)序列可及性的預(yù)測(cè)(也就是長(zhǎng)序列調(diào)控的預(yù)測(cè))。如果你對(duì)這一塊感興趣可以試試 deepTarget/deepMiRGene,它們就是干這些事情的。此外,最近有一項(xiàng)研究發(fā)現(xiàn),RNN模型還可用在測(cè)序數(shù)據(jù)的堿基識(shí)別(即Base-calling)。這在三代測(cè)序數(shù)據(jù)的Base-calling中有應(yīng)用,DeepNano 就是通過構(gòu)造合適的 RNN 模型對(duì) Oxford Nanopore 測(cè)序儀所產(chǎn)出的長(zhǎng)讀長(zhǎng)測(cè)序序列進(jìn)行堿基識(shí)別的方法。圖卷積神經(jīng)網(wǎng)絡(luò)模型(GCN)圖6(d),在基因組學(xué)中涉及的應(yīng)用還很少。它比較合適的應(yīng)用場(chǎng)景是蛋白質(zhì)之間互作用的網(wǎng)絡(luò)或者基因與基因之間的調(diào)控網(wǎng)絡(luò)上。因?yàn)檫@兩個(gè)方面的網(wǎng)絡(luò),在邏輯上都將是以圖結(jié)構(gòu)的形式呈現(xiàn)。圖卷積神經(jīng)網(wǎng)絡(luò)通過圖中代表個(gè)體特征的節(jié)點(diǎn)和節(jié)點(diǎn)與節(jié)點(diǎn)之間的連接性來實(shí)行機(jī)器學(xué)習(xí)任務(wù)。雖然應(yīng)用還比較少,但GCN實(shí)際上提供了一種分析圖結(jié)構(gòu)數(shù)據(jù)的新方法,值得在基因組學(xué)中進(jìn)行更多的嘗試和應(yīng)用,比如可以嘗試?yán)盟鼇斫鉀Q腫瘤亞型的分類等。第二部分要介紹的內(nèi)容是“多任務(wù)學(xué)習(xí)和多模態(tài)學(xué)習(xí)”。之所以涉及到這個(gè)方面,是因?yàn)榛驍?shù)據(jù)實(shí)際上并非只有 DNA 序列這一類遺傳方面的數(shù)據(jù),還涉及到轉(zhuǎn)錄組、表觀組修飾、蛋白組等多組學(xué)數(shù)據(jù),而且數(shù)據(jù)在彼此之間存在著一定的內(nèi)在關(guān)系。如何處理和整合這些多組學(xué)數(shù)據(jù)就涉及到“多任務(wù)和多模態(tài)學(xué)習(xí)”這個(gè)問題了。在多模態(tài)學(xué)習(xí)模型的構(gòu)成中,它有一個(gè)總損失函數(shù),它的值是各個(gè)模態(tài)數(shù)據(jù)損失函數(shù)之和或者加權(quán)和,這取決于各個(gè)模態(tài)之間損失函數(shù)的結(jié)果是否差異巨大。下面圖7.a-c 是一個(gè)多任務(wù)和多模態(tài)學(xué)習(xí)的示意圖。這類模型的訓(xùn)練往往比較困難,因?yàn)樾枰瑫r(shí)優(yōu)化學(xué)習(xí)網(wǎng)絡(luò)中多個(gè)不同的損失函數(shù),并且往往還得做出合適的取舍,每一個(gè)取舍都要有合理的內(nèi)在理由。而且如果不同的類型的數(shù)據(jù)之間,出現(xiàn)了較為嚴(yán)重的權(quán)重失衡的話——比如出現(xiàn)”一超無強(qiáng)”的情況,那么最終的模型可能僅能代表一小撮數(shù)據(jù)的結(jié)果,這就會(huì)讓模型出現(xiàn)嚴(yán)重偏差。
 圖7. 多任務(wù)與多模態(tài)學(xué)習(xí)模型基因組學(xué)領(lǐng)域,已經(jīng)成功應(yīng)用多任務(wù)學(xué)習(xí)和多模態(tài)學(xué)習(xí)的一個(gè)場(chǎng)景是對(duì)多種不同的分子表型的預(yù)測(cè),比如前面提到的轉(zhuǎn)錄因子結(jié)合位點(diǎn)、組蛋白標(biāo)記、DNA可及性分析和不同組織中的基因表達(dá)等這一類與轉(zhuǎn)錄組學(xué)和表觀基因組學(xué)相關(guān)的多組學(xué)研究。遷移學(xué)習(xí)與上述內(nèi)容都不同,它是一種解決訓(xùn)練數(shù)據(jù)稀缺問題的機(jī)器學(xué)習(xí)方法。因?yàn)閿?shù)據(jù)稀缺或者數(shù)據(jù)缺失的情況下,從頭訓(xùn)練整個(gè)模型可能是不可行的。那么一個(gè)取而代之的方法就是使用相似結(jié)構(gòu)的任務(wù),以及由它訓(xùn)練得到的模型的大多數(shù)參數(shù)來初始化我們的目標(biāo)模型。你可以理解為,這是一種將先驗(yàn)知識(shí)整合到新模型中的機(jī)器學(xué)習(xí)方法,它可以在一定程度上解決訓(xùn)練數(shù)據(jù)不足的問題。比如 圖8 這個(gè)例子,你可以看到在這個(gè)例子中,源模型的數(shù)據(jù)很充足,且源模型中第一個(gè)子模型的結(jié)構(gòu)和預(yù)測(cè)結(jié)果的形式都跟目標(biāo)模型相似(都是橢圓),那么這時(shí)我們就可以將源模型里這個(gè)子模型的相關(guān)參數(shù)遷移到下方的目標(biāo)模型里,對(duì)目標(biāo)模型進(jìn)行初始化,接著再利用有限的訓(xùn)練數(shù)據(jù)對(duì)目標(biāo)模型進(jìn)行更新就可以了。
圖7. 多任務(wù)與多模態(tài)學(xué)習(xí)模型基因組學(xué)領(lǐng)域,已經(jīng)成功應(yīng)用多任務(wù)學(xué)習(xí)和多模態(tài)學(xué)習(xí)的一個(gè)場(chǎng)景是對(duì)多種不同的分子表型的預(yù)測(cè),比如前面提到的轉(zhuǎn)錄因子結(jié)合位點(diǎn)、組蛋白標(biāo)記、DNA可及性分析和不同組織中的基因表達(dá)等這一類與轉(zhuǎn)錄組學(xué)和表觀基因組學(xué)相關(guān)的多組學(xué)研究。遷移學(xué)習(xí)與上述內(nèi)容都不同,它是一種解決訓(xùn)練數(shù)據(jù)稀缺問題的機(jī)器學(xué)習(xí)方法。因?yàn)閿?shù)據(jù)稀缺或者數(shù)據(jù)缺失的情況下,從頭訓(xùn)練整個(gè)模型可能是不可行的。那么一個(gè)取而代之的方法就是使用相似結(jié)構(gòu)的任務(wù),以及由它訓(xùn)練得到的模型的大多數(shù)參數(shù)來初始化我們的目標(biāo)模型。你可以理解為,這是一種將先驗(yàn)知識(shí)整合到新模型中的機(jī)器學(xué)習(xí)方法,它可以在一定程度上解決訓(xùn)練數(shù)據(jù)不足的問題。比如 圖8 這個(gè)例子,你可以看到在這個(gè)例子中,源模型的數(shù)據(jù)很充足,且源模型中第一個(gè)子模型的結(jié)構(gòu)和預(yù)測(cè)結(jié)果的形式都跟目標(biāo)模型相似(都是橢圓),那么這時(shí)我們就可以將源模型里這個(gè)子模型的相關(guān)參數(shù)遷移到下方的目標(biāo)模型里,對(duì)目標(biāo)模型進(jìn)行初始化,接著再利用有限的訓(xùn)練數(shù)據(jù)對(duì)目標(biāo)模型進(jìn)行更新就可以了。
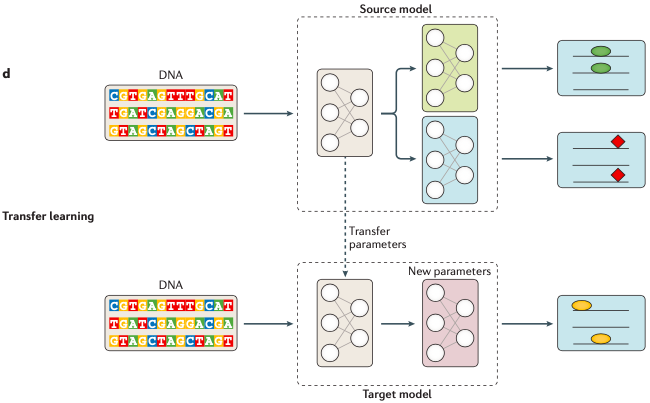 圖8. 遷移學(xué)習(xí)在基因組學(xué)中,遠(yuǎn)程調(diào)控的預(yù)測(cè)模型就應(yīng)用到了遷移學(xué)習(xí)。不過遷移學(xué)習(xí)在組學(xué)方面的應(yīng)用還缺少深入的研究,比如目前依然不清楚應(yīng)該如何選擇合適的源模型、以及源模型中有哪些參數(shù)適合共享到目標(biāo)模型中等。這個(gè)問題對(duì)于深度學(xué)習(xí)來說是天生的,但它關(guān)系著深度學(xué)習(xí)是否適合被充分應(yīng)用到生命健康領(lǐng)域。我們知道深度學(xué)習(xí)模型的一個(gè)問題是黑盒子效應(yīng)——我們無法得知模型的具體訓(xùn)練細(xì)節(jié)以及中間特征參數(shù)的變化。這對(duì)于基因組學(xué)研究來說是不利的,這是因?yàn)榻M學(xué)研究最后的服務(wù)對(duì)象是我們?nèi)祟愖陨淼慕】担?span style="color: rgb(123, 127, 131);">特別是重大的健康問題),沒有人真的愿意將重大的健康問題交給一個(gè)沒人理解的黑盒子處理,所以我們還是有必要對(duì)深度學(xué)習(xí)模型的可解釋性進(jìn)行一定的研究。但遺憾的是目前對(duì)深度學(xué)習(xí)模型的黑盒子效應(yīng),似乎尚未有特別有效的解密方法。目前主要是通過不斷給出示例數(shù)據(jù),探查輸入和輸出結(jié)果之間的關(guān)系來推測(cè)和評(píng)估模型所用到的特征和權(quán)重,給出特征重要性評(píng)分(Feature important score),可用的方法包括:歸因分?jǐn)?shù)、相關(guān)性系數(shù)或權(quán)重共享系數(shù)等。不過在深度學(xué)習(xí)領(lǐng)域,最近有一個(gè)稱為DCell的模型,它提出了一種稱為“可見神經(jīng)網(wǎng)絡(luò)”的技術(shù),通過它可以檢查神經(jīng)網(wǎng)絡(luò)的訓(xùn)練情況,進(jìn)而再改善神級(jí)網(wǎng)絡(luò)的可解釋性。最后這部分討論非監(jiān)督學(xué)習(xí)在基因組學(xué)方面應(yīng)用的問題,這里主要介紹自動(dòng)編碼機(jī)(Autoencoder, AE)和生成對(duì)抗網(wǎng)絡(luò)(generative adversarial networks,GANs)這兩類非監(jiān)督學(xué)習(xí)方法,其中生成對(duì)抗網(wǎng)絡(luò)在基因組學(xué)的首次應(yīng)用是在單細(xì)胞基因組研究中。非監(jiān)督學(xué)習(xí)與有監(jiān)督學(xué)習(xí)不同,它的訓(xùn)練數(shù)據(jù)并不需要標(biāo)記。模型的目的是通過學(xué)習(xí)數(shù)據(jù)集中有用的特征和屬性來表征整個(gè)數(shù)據(jù)集的結(jié)構(gòu)。最典型、最被熟知的非監(jiān)督學(xué)習(xí)方法就是k-means聚類和降維算法(如PCA、tSNE)。神經(jīng)網(wǎng)絡(luò)也有類似的方法,比如自動(dòng)編碼機(jī)(AE),就是一種能夠?qū)?shù)據(jù)嵌入到一個(gè)含有隱藏瓶頸層的低維空間中并對(duì)原始數(shù)據(jù)進(jìn)行重建的方法,如圖9所示。這個(gè)方法很特別,而且非常有用的一點(diǎn)是它能夠?qū)υ紨?shù)據(jù)進(jìn)行有效的“降噪”!這是因?yàn)榫W(wǎng)絡(luò)中間有一個(gè)維度較低的瓶頸層存在,它會(huì)迫使網(wǎng)絡(luò)在學(xué)習(xí)的過程中盡可能提取更有用的特征,那些不重要的特征變化會(huì)被自動(dòng)遺漏。而且,在該瓶頸層中的數(shù)據(jù)已經(jīng)實(shí)現(xiàn)了降維,這個(gè)正好可以與PCA相呼應(yīng)。另外,自動(dòng)編碼機(jī)適合用于缺失數(shù)據(jù)的填補(bǔ),特別是可以用來填補(bǔ)基因芯片數(shù)據(jù)的缺失值和處理RNA-seq中基因表達(dá)數(shù)據(jù)中的異常值處理。另一個(gè)非監(jiān)督神經(jīng)網(wǎng)絡(luò)是生成模型。生成模型不同于前面提到的方法,它的目的是學(xué)習(xí)數(shù)據(jù)的生成過程。代表性的例子就是生成對(duì)抗網(wǎng)絡(luò)(GANs)和可變自動(dòng)編碼器(VAEs)。其中,VAEs方法可以生成新的隨機(jī)樣本,可以用在單細(xì)胞和RNA-seq數(shù)據(jù)中,用來協(xié)助尋找統(tǒng)計(jì)意義的結(jié)果。GANs是另一種生成模型,它包含一個(gè)鑒別器和一個(gè)生成器網(wǎng)絡(luò)。這兩個(gè)網(wǎng)絡(luò)會(huì)進(jìn)行共同訓(xùn)練,生成器用來生成真實(shí)的數(shù)據(jù)點(diǎn),而鑒別器則用于區(qū)分樣本是真實(shí)的或是由生成器所生成,圖9(c)也是對(duì)該過程的一個(gè)描述。不過目前GANs,在基因組學(xué)中的應(yīng)用非常有限,目前只看到在設(shè)計(jì)和蛋白質(zhì)相關(guān)的DNA探針方面有所應(yīng)用。關(guān)于目前深度學(xué)習(xí)在基因組學(xué)方面的應(yīng)用和研究情況就介紹到這里了。在未來深度學(xué)習(xí)肯定是會(huì)深刻影響這個(gè)領(lǐng)域的,具體來說主要有三個(gè)方面:
圖8. 遷移學(xué)習(xí)在基因組學(xué)中,遠(yuǎn)程調(diào)控的預(yù)測(cè)模型就應(yīng)用到了遷移學(xué)習(xí)。不過遷移學(xué)習(xí)在組學(xué)方面的應(yīng)用還缺少深入的研究,比如目前依然不清楚應(yīng)該如何選擇合適的源模型、以及源模型中有哪些參數(shù)適合共享到目標(biāo)模型中等。這個(gè)問題對(duì)于深度學(xué)習(xí)來說是天生的,但它關(guān)系著深度學(xué)習(xí)是否適合被充分應(yīng)用到生命健康領(lǐng)域。我們知道深度學(xué)習(xí)模型的一個(gè)問題是黑盒子效應(yīng)——我們無法得知模型的具體訓(xùn)練細(xì)節(jié)以及中間特征參數(shù)的變化。這對(duì)于基因組學(xué)研究來說是不利的,這是因?yàn)榻M學(xué)研究最后的服務(wù)對(duì)象是我們?nèi)祟愖陨淼慕】担?span style="color: rgb(123, 127, 131);">特別是重大的健康問題),沒有人真的愿意將重大的健康問題交給一個(gè)沒人理解的黑盒子處理,所以我們還是有必要對(duì)深度學(xué)習(xí)模型的可解釋性進(jìn)行一定的研究。但遺憾的是目前對(duì)深度學(xué)習(xí)模型的黑盒子效應(yīng),似乎尚未有特別有效的解密方法。目前主要是通過不斷給出示例數(shù)據(jù),探查輸入和輸出結(jié)果之間的關(guān)系來推測(cè)和評(píng)估模型所用到的特征和權(quán)重,給出特征重要性評(píng)分(Feature important score),可用的方法包括:歸因分?jǐn)?shù)、相關(guān)性系數(shù)或權(quán)重共享系數(shù)等。不過在深度學(xué)習(xí)領(lǐng)域,最近有一個(gè)稱為DCell的模型,它提出了一種稱為“可見神經(jīng)網(wǎng)絡(luò)”的技術(shù),通過它可以檢查神經(jīng)網(wǎng)絡(luò)的訓(xùn)練情況,進(jìn)而再改善神級(jí)網(wǎng)絡(luò)的可解釋性。最后這部分討論非監(jiān)督學(xué)習(xí)在基因組學(xué)方面應(yīng)用的問題,這里主要介紹自動(dòng)編碼機(jī)(Autoencoder, AE)和生成對(duì)抗網(wǎng)絡(luò)(generative adversarial networks,GANs)這兩類非監(jiān)督學(xué)習(xí)方法,其中生成對(duì)抗網(wǎng)絡(luò)在基因組學(xué)的首次應(yīng)用是在單細(xì)胞基因組研究中。非監(jiān)督學(xué)習(xí)與有監(jiān)督學(xué)習(xí)不同,它的訓(xùn)練數(shù)據(jù)并不需要標(biāo)記。模型的目的是通過學(xué)習(xí)數(shù)據(jù)集中有用的特征和屬性來表征整個(gè)數(shù)據(jù)集的結(jié)構(gòu)。最典型、最被熟知的非監(jiān)督學(xué)習(xí)方法就是k-means聚類和降維算法(如PCA、tSNE)。神經(jīng)網(wǎng)絡(luò)也有類似的方法,比如自動(dòng)編碼機(jī)(AE),就是一種能夠?qū)?shù)據(jù)嵌入到一個(gè)含有隱藏瓶頸層的低維空間中并對(duì)原始數(shù)據(jù)進(jìn)行重建的方法,如圖9所示。這個(gè)方法很特別,而且非常有用的一點(diǎn)是它能夠?qū)υ紨?shù)據(jù)進(jìn)行有效的“降噪”!這是因?yàn)榫W(wǎng)絡(luò)中間有一個(gè)維度較低的瓶頸層存在,它會(huì)迫使網(wǎng)絡(luò)在學(xué)習(xí)的過程中盡可能提取更有用的特征,那些不重要的特征變化會(huì)被自動(dòng)遺漏。而且,在該瓶頸層中的數(shù)據(jù)已經(jīng)實(shí)現(xiàn)了降維,這個(gè)正好可以與PCA相呼應(yīng)。另外,自動(dòng)編碼機(jī)適合用于缺失數(shù)據(jù)的填補(bǔ),特別是可以用來填補(bǔ)基因芯片數(shù)據(jù)的缺失值和處理RNA-seq中基因表達(dá)數(shù)據(jù)中的異常值處理。另一個(gè)非監(jiān)督神經(jīng)網(wǎng)絡(luò)是生成模型。生成模型不同于前面提到的方法,它的目的是學(xué)習(xí)數(shù)據(jù)的生成過程。代表性的例子就是生成對(duì)抗網(wǎng)絡(luò)(GANs)和可變自動(dòng)編碼器(VAEs)。其中,VAEs方法可以生成新的隨機(jī)樣本,可以用在單細(xì)胞和RNA-seq數(shù)據(jù)中,用來協(xié)助尋找統(tǒng)計(jì)意義的結(jié)果。GANs是另一種生成模型,它包含一個(gè)鑒別器和一個(gè)生成器網(wǎng)絡(luò)。這兩個(gè)網(wǎng)絡(luò)會(huì)進(jìn)行共同訓(xùn)練,生成器用來生成真實(shí)的數(shù)據(jù)點(diǎn),而鑒別器則用于區(qū)分樣本是真實(shí)的或是由生成器所生成,圖9(c)也是對(duì)該過程的一個(gè)描述。不過目前GANs,在基因組學(xué)中的應(yīng)用非常有限,目前只看到在設(shè)計(jì)和蛋白質(zhì)相關(guān)的DNA探針方面有所應(yīng)用。關(guān)于目前深度學(xué)習(xí)在基因組學(xué)方面的應(yīng)用和研究情況就介紹到這里了。在未來深度學(xué)習(xí)肯定是會(huì)深刻影響這個(gè)領(lǐng)域的,具體來說主要有三個(gè)方面:- 第一,協(xié)助對(duì)非編碼區(qū)變異的功能進(jìn)行預(yù)測(cè),這是目前傳統(tǒng)方法做得比較差的一個(gè)方面;
- 第二,深度學(xué)習(xí)是一種完全由數(shù)據(jù)驅(qū)動(dòng)的方法,它會(huì)進(jìn)一步革新當(dāng)前的生物信息學(xué)工具,我可以將它稱為新生信,這個(gè)也是目前最熱的,除了文章中所提到的新算法之外,變異檢測(cè)算法DeepVariants和Clair也屬于這一方面;
- 第三,高效揭示多組學(xué)中高維數(shù)據(jù)的更多結(jié)構(gòu)。
除此之外,對(duì)于未來還有一個(gè)非常重要的領(lǐng)域,那就是因果推斷。不管是傳統(tǒng)的機(jī)器學(xué)習(xí)方法,或是現(xiàn)在的深度學(xué)習(xí)方法,都很難用于預(yù)測(cè)數(shù)據(jù)之間的因果聯(lián)系,而因果關(guān)系對(duì)于生命科學(xué)研究來說十分重要,目前雖有過一些嘗試——比如孟德爾隨機(jī),但其實(shí)都比較初步。總的來說,這是一個(gè)很值得我們?nèi)ミM(jìn)一步探索的地方,可以從零開始,而這也是我們的機(jī)會(huì)!
最后還有一句話:不要迷信模型。模型是解決問題的工具,用好工具是我們的追求,但問題的解決應(yīng)以人為本。
參考文獻(xiàn)
Deep learning- new computational modelling techniques for genomics
What I cannot create, I do not understand.- Richard P.Feynman(理查德.菲利普斯.費(fèi)曼)
機(jī)器學(xué)習(xí)系列教程
從隨機(jī)森林開始,一步步理解決策樹、隨機(jī)森林、ROC/AUC、數(shù)據(jù)集、交叉驗(yàn)證的概念和實(shí)踐。
文字能說清的用文字、圖片能展示的用、描述不清的用公式、公式還不清楚的寫個(gè)簡(jiǎn)單代碼,一步步理清各個(gè)環(huán)節(jié)和概念。
再到成熟代碼應(yīng)用、模型調(diào)參、模型比較、模型評(píng)估,學(xué)習(xí)整個(gè)機(jī)器學(xué)習(xí)需要用到的知識(shí)和技能。
機(jī)器學(xué)習(xí)算法 - 隨機(jī)森林之決策樹初探(1)
機(jī)器學(xué)習(xí)算法-隨機(jī)森林之決策樹R 代碼從頭暴力實(shí)現(xiàn)(2)
機(jī)器學(xué)習(xí)算法-隨機(jī)森林之決策樹R 代碼從頭暴力實(shí)現(xiàn)(3)
機(jī)器學(xué)習(xí)算法-隨機(jī)森林之理論概述
隨機(jī)森林拖了這么久,終于到實(shí)戰(zhàn)了。先分享很多套用于機(jī)器學(xué)習(xí)的多種癌癥表達(dá)數(shù)據(jù)集 https://file.biolab.si/biolab/supp/bi-cancer/projections/。
機(jī)器學(xué)習(xí)算法-隨機(jī)森林初探(1)
機(jī)器學(xué)習(xí) 模型評(píng)估指標(biāo) - ROC曲線和AUC值
機(jī)器學(xué)習(xí) - 訓(xùn)練集、驗(yàn)證集、測(cè)試集
機(jī)器學(xué)習(xí) - 隨機(jī)森林手動(dòng)10 折交叉驗(yàn)證
一個(gè)函數(shù)統(tǒng)一238個(gè)機(jī)器學(xué)習(xí)R包,這也太贊了吧
基于Caret和RandomForest包進(jìn)行隨機(jī)森林分析的一般步驟 (1)
Caret模型訓(xùn)練和調(diào)參更多參數(shù)解讀(2)
機(jī)器學(xué)習(xí)相關(guān)書籍分享
基于Caret進(jìn)行隨機(jī)森林隨機(jī)調(diào)參的4種方式
送你一個(gè)在線機(jī)器學(xué)習(xí)網(wǎng)站,真香!
UCI機(jī)器學(xué)習(xí)數(shù)據(jù)集
機(jī)器學(xué)習(xí)第17篇 - 特征變量篩選(1)
機(jī)器學(xué)習(xí)第18篇 - 基于隨機(jī)森林的Boruta特征變量篩選(2)
機(jī)器學(xué)習(xí)系列補(bǔ)充:數(shù)據(jù)集準(zhǔn)備和更正YSX包
機(jī)器學(xué)習(xí)第20篇 - 基于Boruta選擇的特征變量構(gòu)建隨機(jī)森林
機(jī)器學(xué)習(xí)第21篇 - 特征遞歸消除RFE算法 理論
RFE篩選出的特征變量竟然是Boruta的4倍之多
更多特征變量卻未能帶來隨機(jī)森林分類效果的提升
一圖感受各種機(jī)器學(xué)習(xí)算法