
全卷積神經網絡(FCN)
回顧
上期我們一起學習了,關于傳統(tǒng)的目標檢測算法的大致思路,通常是利用滑動窗口進行選取目標候選框,然后利用一些算法進行特征提取,最后再扔到分類器中去檢測分類,這樣效率上來說是比較低的。
前奏 | 傳統(tǒng)目標檢測算法思路
那么今天我們一起學習一下一個解決提高檢測效率的一個方法,全卷積神經網絡(FCN),我們知道,對于一個各層參數結構都設計好的神經網絡來說,輸入的圖片大小是要求固定的,比如AlexNet,VGGNet, GoogleNet等網絡,都要求輸入固定大小的圖片才能正常工作。
而FCN的精髓就是讓一個已經設計好的網絡可以輸入任意大小的圖片。接下來,我們就一起看一下FCN和CNN有什么區(qū)別?
1. CNN和FCN網絡結構對比
CNN網絡
假如我們要設計一個用來區(qū)分貓,狗和背景的網絡,正常的CNN的網絡的架構應該是如下圖: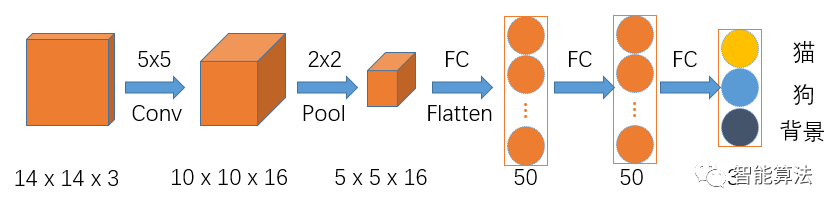
假如輸入圖片size為14x14x3的彩色圖,如上圖,首先經過一個5x5的卷積層,卷積層的輸出通道數為16,得到一個10x10x16的一組特征圖,然后經過2x2的池化層,得到5x5x16的特征圖,接著Flatten后進入兩個50個神經元的全連接層,最后輸出分類結果。
這里由于全連接層中輸入層神經元的個數是固定,這就導致反推出卷積層的輸入要求是固定的,這就不利于不同尺寸的圖片進行訓練,想要深入了解上面過程,可參考之前文章:
卷積神經網絡通俗原理
卷積神經網絡實戰(zhàn)進階(附代碼)??
FCN網絡
全卷積神經網絡,顧名思義是該網絡中全是卷積層鏈接,如下圖: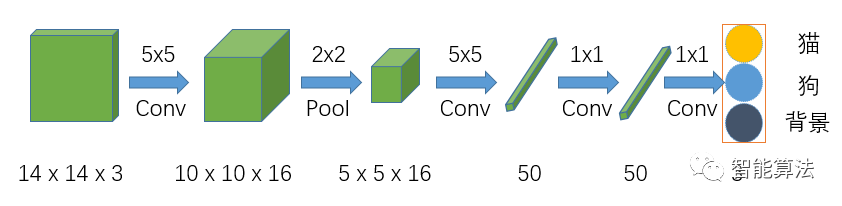
該網絡在前面兩步跟CNN的結構是一樣的,但是在CNN網絡Flatten的時候,FCN網絡將之換成了一個卷積核size為5x5,輸出通道為50的卷積層,之后的全連接層都換成了1x1的卷積層。
我們知道1x1的卷積其實就相當于全連接操作,具體可以參考之前文章:
CNN中神奇的1x1卷積
從上兩個圖比較可知全卷積網絡和CNN網絡的主要區(qū)別在于FCN將CNN中的全連接層換成了卷積操作。
換成全卷積操作后,由于沒有了全連接層的輸入層神經元個數的限制,所以卷積層的輸入可以接受不同尺寸的圖像,也就不用要求訓練圖像和測試圖像size一致。
那么問題也來了,如果輸入尺寸不一樣,那么輸出的尺寸也肯定是不同的,那么該如何去理解FCN的輸出呢?
2. FCN如何理解網絡的輸出?
特征圖尺寸變化
我們首先不考慮通道數,來看一下上面網絡中的特征圖尺寸的具體變化,如下圖,圖中綠色為卷積核,藍色為特征圖: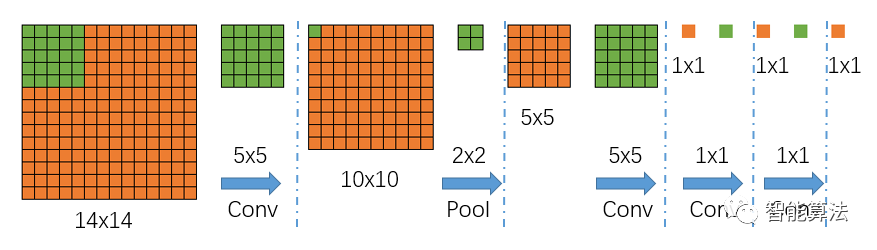
從上圖中,我們可以看到,輸入是一個14x14大小的圖片,經過一個5x5的卷積(不填充)后,得到一個10x10的特征圖,然后再經過一個2x2的池化后,尺寸縮小到一半變成5x5的特征圖,再經過一個5x5的卷積后,特征圖變?yōu)?x1,接著后面再進行兩次1x1的卷積(類似全連接操作),最終得到一個1x1的輸出結果,那么該1x1的輸出結果,就代表最前面14x14圖像區(qū)域的分類情況,如果對應到上面的貓狗和背景的分類任務,那么最后輸出的結果應該是一個1x3的矩陣,其中每個值代表14x14的輸入圖片中對應類別的分類得分。
不同尺寸的輸入圖片
好了,不是說可以接收任意尺寸的輸入嗎?我們接下來看一個大一點的圖片輸入進來,會得到什么樣的結果,如下圖: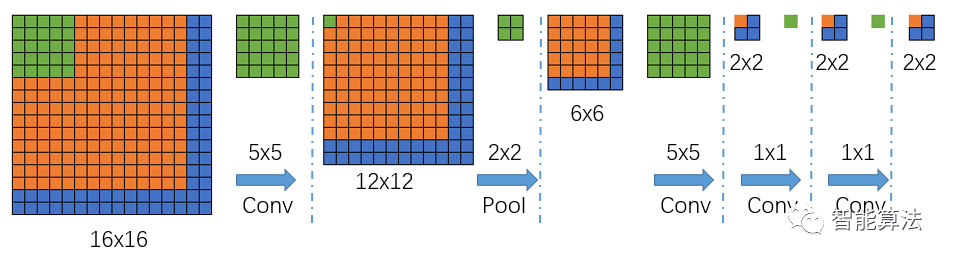
我們可以看到上面的圖,輸入尺寸由原來的14x14變成了16x16,那么經過一個5x5的卷積(不填充)后,得到一個12x12的特征圖,然后再經過一個2x2的池化后,尺寸縮小到一半變成6x6的特征圖,再經過一個5x5的卷積后,特征圖變?yōu)?x2,接著后面再進行兩次1x1的卷積(類似全連接操作),最終得到一個2x2的輸出結果,那么該2x2的輸出結果,就代表最前面16x16圖像區(qū)域的分1類情況,然而,輸出是2x2,怎么跟前面對應呢?
哪一個像素對應哪個區(qū)域呢?
我們看下圖:

根據卷積池化反推,前面圖3,我們知道,最后的輸出1x1代表了前面14x14的輸入的分類結果,那么我們根據卷積核的作用范圍可以推出,上圖中最后輸出2x2中左上角的橙色輸出就代表了16x16中的橙色區(qū)域(紅色框),依次類推,輸出2x2中右上角的藍色輸出就代表了16x16中的黃色框區(qū)域,輸出2x2中左下角的藍色輸出就代表了16x16中的黑色框區(qū)域,輸出2x2中右下角的藍色輸出就代表了16x16中的紫色框區(qū)域,其中每個框的大小都是14x14.也就是說輸出的每個值代表了輸入圖像中的一個區(qū)域的分類情況。
3. FCN如何對目標檢測進行加速?
根據上面的圖5,我們知道FCN最后的輸出,每個值都對應到輸入圖像的一個檢測區(qū)域,也就是說FCN的輸出直接反應了對應輸入圖像檢測區(qū)域的分類情況,由于圖4和圖5均沒考慮通道情況,那么我們將網絡放到一個正常的28x28x3的圖像上,考慮上特征圖的通道數,看下輸出值的對應情況,如下圖: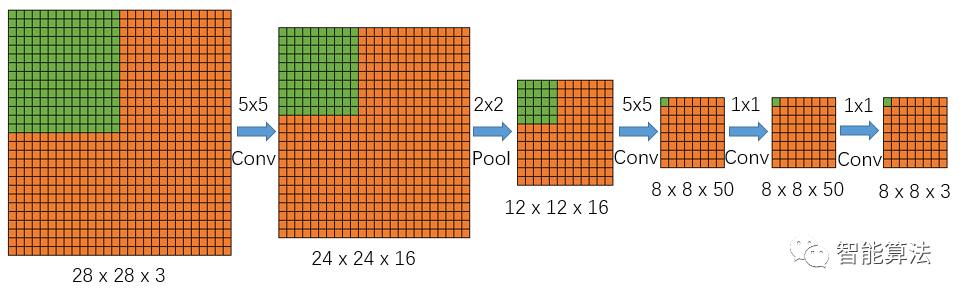
圖6 FCN如何加速
上圖中綠色區(qū)域表現了依次通過網絡后的特征圖尺寸變化情況。
跟圖5類似,因為這是一個貓狗和背景的三分類任務,所以最后輸出的圖像大小為8x8x3,以輸出圖像左上角綠色點為例,該點深度為3,對應輸入圖像的綠色區(qū)域,該點的3個值反應了輸入圖的綠色區(qū)域是分類為貓狗還是背景的得分情況。
總的來說,FCN利用了輸出結果和輸入圖像的對應關系,直接給出了輸入圖像相應區(qū)域的分類情況,取消了傳統(tǒng)目標檢測中的滑動窗口選取候選框。
FNC優(yōu)缺點
輸出結果的每個值映射到輸入圖像上的感受野的窗口是固定的,也就是檢測窗口是固定的,導致檢測效果沒那么好,但是速度卻得到了很大的提升,而且可以輸入任意尺寸的圖片,為目標檢測提供了一種新思路。
好了,這期我們學到這里,下期我們繼續(xù)深入,學習下目標檢測的評價指標都有哪些。