
億級流量架構(gòu),服務(wù)器如何擴容?寫得太好了!
為什么要擴容
說人話就是, 無論如何優(yōu)化性能,能達到的最大值是一定的,對于一個用戶量大的應(yīng)用,可以對服務(wù)器進行各種優(yōu)化,諸如限流、資源隔離,但是上限還是在那里,這時候就應(yīng)該改變我們的硬件,例如使用更強的CPU、更大的內(nèi)存,在前文中舉了一個學生食堂打飯的例子,如果學生多了,可以通過令牌桶算法優(yōu)先給高三學生令牌打飯,但是如果高三的學生還是很多呢?那就只有增加窗口或者食堂的數(shù)量,也就是硬件上的擴容。
擴容策略
整機硬件
組件
組件包含:
cpu
Intel、Amd ,參考頻率、線程數(shù)等
網(wǎng)卡
百兆->千兆 -> 萬兆
內(nèi)存
ECC校驗
磁盤
SCSI HDD(機械)、HHD(混合)、SATA SSD、PCI-e SSD、 MVMe SSD。想成為架構(gòu)師,這份架構(gòu)師圖譜建議看看,少走彎路。
AKF拆分原則
對于一個應(yīng)用,如果單機不足以支撐服務(wù)請求,那么可以建立諸如主主、主從等模式的集群:
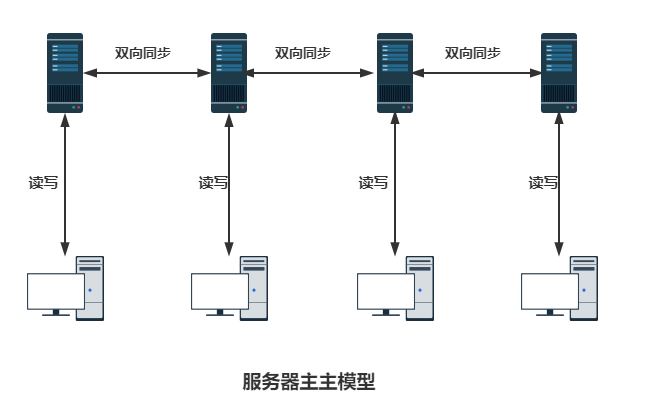
這個叫AKF原則X軸擴展,目的是將請求分流在多臺機器上,但是多臺機器中間要解決數(shù)據(jù)同步性的問題,越多的機器數(shù)據(jù)不同步的可能性越大,這也就意味著沒法無限整體復制擴容。
所以可以整理搜集服務(wù)器內(nèi)熱點的業(yè)務(wù)請求,將業(yè)務(wù)分離出來,只對熱點業(yè)務(wù)進行擴容,這就是AKF原則的Y軸拆分:
拆分擴容后存在的問題
數(shù)據(jù)共享問題 所有的服務(wù)之間數(shù)據(jù)如何共享同步,這是一個需要考慮的問題,微服務(wù)架構(gòu)中,數(shù)據(jù)不可能只有一份,沒法避免機器損壞等原因造成的數(shù)據(jù)丟失,多份數(shù)據(jù)之間如何同步?目前可供參考的解決思路是建立數(shù)據(jù)中心、搭建數(shù)據(jù)庫集群。 接口調(diào)用問題 不同的服務(wù)器之間進行調(diào)用遵循遠程調(diào)用協(xié)議RPC JAVA RMI:Java遠程方法調(diào)用,即Java RMI(Java Remote Method Invocation)是Java編程語言里,一種用于實現(xiàn)遠程過程調(diào)用的應(yīng)用程序編程接口。它使客戶機上運行的程序可以調(diào)用遠程服務(wù)器上的對象。
dubbo:提供了面向接口代理的高性能RPC調(diào)用
持久化數(shù)據(jù)雪崩問題 數(shù)據(jù)庫分庫分表 資源隔離 緩存設(shè)定數(shù)據(jù)持久化策略
高并發(fā)問題
緩存:諸如緩存擊穿、穿透、雪崩等
數(shù)據(jù)閉環(huán):為了便于理解,舉個例子,對于淘寶而言,有網(wǎng)頁版、IOS版、安卓版、還有什么一淘等等,雖然客戶端不一樣,但是展示的商品信息是相同的,也就是一件商品,無論是哪個端用的數(shù)據(jù)是一樣的,需要一套方案來解決并發(fā)下根據(jù)相同數(shù)據(jù)在不同端進行不同展示的問題,這就叫數(shù)據(jù)閉環(huán)。
數(shù)據(jù)一致性問題
這是一個難點,大意就是多個服務(wù)器之間數(shù)據(jù)如何保證一致性,同樣的商品在不同客戶端服務(wù)端端價格應(yīng)該是一樣的, 通常使用分布式鎖。
數(shù)據(jù)庫擴容:集群
分布式ID
分布式ID要求
面對分布式ID,需要滿足下面的要求:
全局唯一性:不能出現(xiàn)重復的ID號,既然是唯一標識,這是最基本的要求。 趨勢遞增:在MySQL InnoDB引擎中使用的是聚集索引,由于多數(shù)RDBMS使用B-tree的數(shù)據(jù)結(jié)構(gòu)來存儲索引數(shù)據(jù),在主鍵的選擇上面我們應(yīng)該盡量使用有序的主鍵保證寫入性能。 單調(diào)遞增:保證下一個ID一定大于上一個ID,例如事務(wù)版本號、IM增量消息、排序等特殊需求。 信息安全:如果ID是連續(xù)的,惡意用戶的扒取工作就非常容易做了,直接按照順序下載指定URL即可;如果是訂單號就更危險了,競對可以直接知道我們一天的單量。所以在一些應(yīng)用場景下,會需要ID無規(guī)則、不規(guī)則。
上述123對應(yīng)三類不同的場景,但是3和4的需求是互斥的,也就是無法使用同一個方案滿足。另外,搜索公眾號互聯(lián)網(wǎng)架構(gòu)師后臺回復“9”,獲取一份驚喜禮包。
除了對ID號碼自身的要求,業(yè)務(wù)還對ID號生成系統(tǒng)的可用性要求極高,想象一下,如果ID生成系統(tǒng)癱瘓,整個與數(shù)據(jù)有關(guān)的動作都無法執(zhí)行,會帶來一場災(zāi)難。由此總結(jié)下一個ID生成系統(tǒng)最少應(yīng)該做到如下幾點:
平均延遲和TP999延遲都要盡可能低; 可用性5個9(這是美團的要求,有些企業(yè)例如阿里要求6個9); 高QPS。
分布式ID生成策略
目前業(yè)界常用的ID生成策略有很多,例如UUID、雪花生成算法、Redis、Zookeeper等,這兒只簡單講講UUID以及Snowflake,后面要開篇詳談。
UUID生成算法
UUID(Universally Unique Identifier)的標準型式包含32個16進制數(shù)字,以連字號分為五段,形式為8-4-4-4-12的36個字符,示例:550e8400-e29b-41d4-a716-446655440000,到目前為止業(yè)界一共有5種方式生成UUID。
優(yōu)點:
性能非常高:本地生成,沒有網(wǎng)絡(luò)消耗。
缺點:
不易于存儲:UUID太長,16字節(jié)128位,通常以36長度的字符串表示,很多場景不適用。
信息不安全:基于MAC地址生成UUID的算法可能會造成MAC地址泄露,這個漏洞曾被用于尋找梅麗莎病毒的制作者位置。
ID作為主鍵時在特定的環(huán)境會存在一些問題,比如做DB主鍵的場景下,UUID就非常不適用:
① MySQL官方有明確的建議主鍵要盡量越短越好[4],36個字符長度的UUID不符合要求。
All indexes other than the clustered index are known as secondary indexes. In InnoDB, each record in a secondary index contains the primary key columns for the row, as well as the columns specified for the secondary index. InnoDB uses this primary key value to search for the row in the clustered index.If the primary key is long, the secondary indexes use more space, so it is advantageous to have a short primary key.
② 對MySQL索引不利:如果作為數(shù)據(jù)庫主鍵,在InnoDB引擎下,UUID的無序性可能會引起數(shù)據(jù)位置頻繁變 動,嚴重影響性能。
雪花生成算法
這種方案大致來說是一種以劃分命名空間(UUID也算,由于比較常見,所以單獨分析)來生成ID的一種算法,這種方案把64-bit分別劃分成多段,分開來標示機器、時間等,比如在snowflake中的64-bit分別表示如下圖(圖片來自網(wǎng)絡(luò))所示:

41-bit的時間可以表示(1L<<41)/(1000L360024*365)=69年的時間,10-bit機器可以分別表示1024臺機器。如果我們對IDC劃分有需求,還可以將10-bit分5-bit給IDC,分5-bit給工作機器。這樣就可以表示32個IDC,每個IDC下可以有32臺機器,可以根據(jù)自身需求定義。
12個自增序列號可以表示212212個ID,理論上snowflake方案的QPS約為409.6w/s,這種分配方式可以保證在任何一個IDC的任何一臺機器在任意毫秒內(nèi)生成的ID都是不同的。
這種方式的優(yōu)缺點是:
優(yōu)點:
毫秒數(shù)在高位,自增序列在低位,整個ID都是趨勢遞增的。 不依賴數(shù)據(jù)庫等第三方系統(tǒng),以服務(wù)的方式部署,穩(wěn)定性更高,生成ID的性能也是非常高的。 可以根據(jù)自身業(yè)務(wù)特性分配bit位,非常靈活。
缺點:
強依賴機器時鐘,如果機器上時鐘回撥,會導致發(fā)號重復或者服務(wù)會處于不可用狀態(tài)。
彈性擴容
熱門推薦:
PS:如果覺得我的分享不錯,歡迎大家隨手點贊、轉(zhuǎn)發(fā)、在看。