
億級流量架構怎么做資源隔離?寫得太好了!
作者:等不到的口琴
鏈接:www.cnblogs.com/Courage129/p/14421585.html
為什么要資源隔離
常見的隔離方式有:
線程隔離
Netty主從程模型
主線程負責認證,連接,成功之后交由從線程負責連接的讀寫操作,大致如下代碼:
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup);
public void channelRead(ChannelHandlerContext ctx, Object msg) {
System.out.println("thread name=" + Thread.currentThread().getName() + " server receive msg=" + msg);
}
thread name=nioEventLoopGroup-3-1 server receive msg="..."
可以發(fā)現(xiàn)這里使用的線程其實和處理io線程是同一個;
Dubbo線程隔離模型
thread name=DubboServerHandler-192.168.1.115:20880-thread-2,...
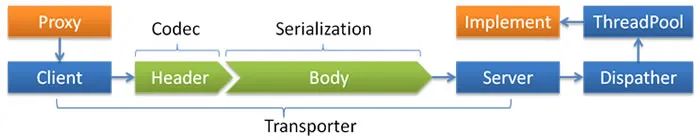
all所有消息都派發(fā)到線程池,包括請求,響應,連接事件,斷開事件,心跳等。direct所有消息都不派發(fā)到線程池,全部在 IO 線程上直接執(zhí)行。message只有請求響應消息派發(fā)到線程池,其它連接斷開事件,心跳等消息,直接在 IO 線程上執(zhí)行。execution只有請求消息派發(fā)到線程池,不含響應,響應和其它連接斷開事件,心跳等消息,直接在 IO 線程上執(zhí)行。connection在 IO 線程上,將連接斷開事件放入隊列,有序逐個執(zhí)行,其它消息派發(fā)到線程池。
Tomcat請求線程隔離
NIO模式:同步非阻塞I/O操作,是一個基于緩沖區(qū)、并能提供非阻塞I/O操作的API,它擁有比傳統(tǒng)I/O操作具有更好的并發(fā)性能。
在Tomcat7版本之后,Tomcat把連接介入和業(yè)務處理拆分成兩個線程池來處理,即:
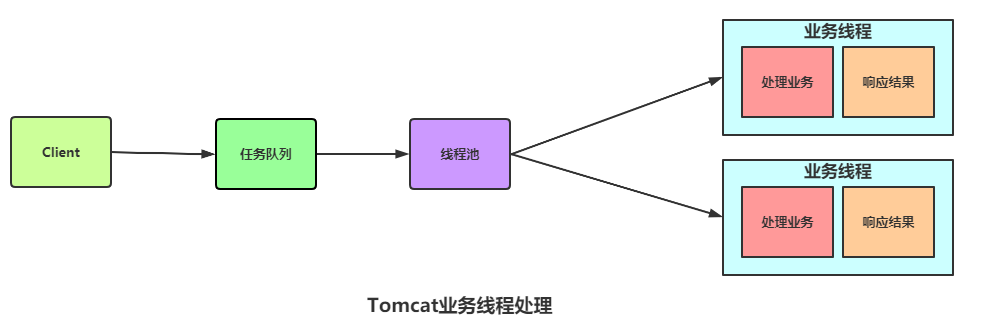
這樣做,獨立的業(yè)務或資源中如果出現(xiàn)崩潰,不會影響其他的業(yè)務線程,從而達到資源隔離和服務降級的效果。
在使用了servlet3之后,系統(tǒng)線程隔離變得更靈活了。可以劃分核心業(yè)務隊列和非核心業(yè)務隊列:
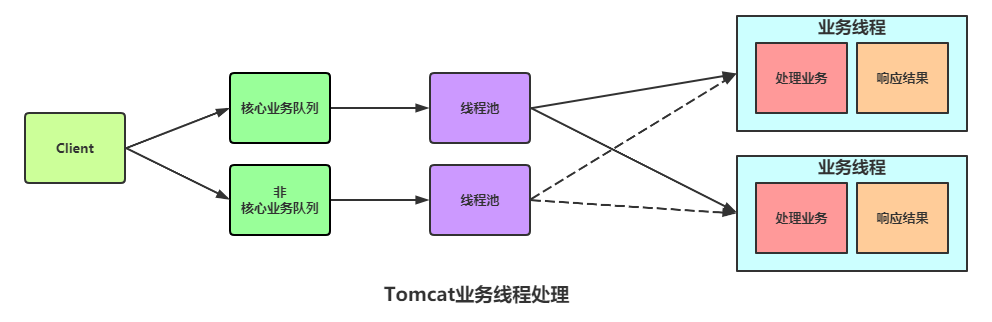
線程隔離小總結
資源一旦出現(xiàn)問題,雖然是隔離狀態(tài),想要讓資源重新可用,很難做到不重啟jvm。 線程池內部線程如果出現(xiàn)OOM、FullGC、cpu耗盡等問題也是無法控制的 線程隔離,只能保證在分配線程這個資源上進行隔離,并不能保證整體穩(wěn)定性
進程隔離
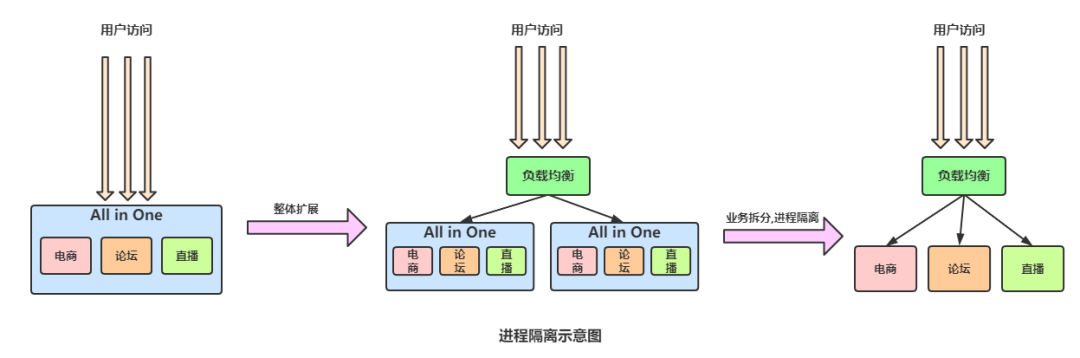
集群隔離
如果系統(tǒng)中某個業(yè)務模塊包含像搶購、秒殺、存儲I/O密集度高、網絡I/o高、計算I/O高這類需求的時候,很容易在并發(fā)量高的時候因為這種功能把整個模塊占有的資源全部耗盡,導致響應編碼甚至節(jié)點不可用。
像上圖的的拆分之后,如果某一天購物人數瞬間暴增,電商交易功能模塊可能受影響,損壞后導致電商模塊其他的瀏覽查詢也無法使用,因此就要建立集群進行隔離,具體來說就是繼續(xù)拆分模塊,將功能微服務化。
解決方案
線程池隔離與信號量隔離對比
| 隔離方式 | 是否支持超時 | 是否支持熔斷 | 隔離原理 | 是否是異步調用 | 資源消耗 |
|---|---|---|---|---|---|
| 線程池隔離 | 支持,可直接返回 | 支持,當線程池到達maxSize后,再請求會觸發(fā)fallback接口進行熔斷 | 每個服務單獨用線程池 | 可以是異步,也可以是同步。看調用的方法 | 大,大量線程的上下文切換,容易造成機器負載高 |
| 信號量隔離 | 不支持,如果阻塞,只能通過調用協(xié)議(如:socket超時才能返回) | 支持,當信號量達到maxConcurrentRequests后。再請求會觸發(fā)fallback | 通過信號量的計數器 | 同步調用,不支持異步 | 小,只是個計數器 |
信號量隔離
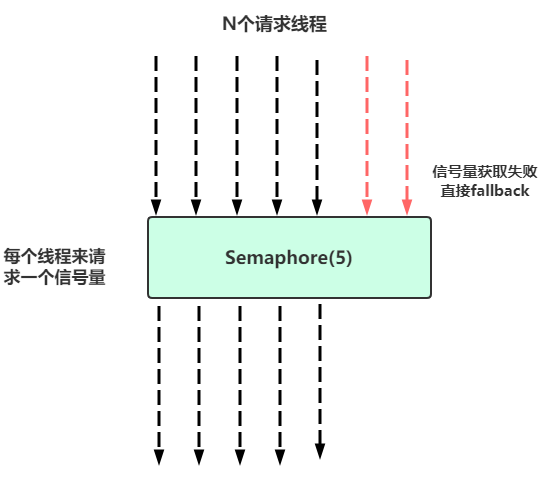
官網對信號量隔離的描述建議
HystrixCommands is when the call is so high volume (hundreds per second, per instance) that the overhead of separate threads is too high; this typically only applies to non-network calls.機房隔離
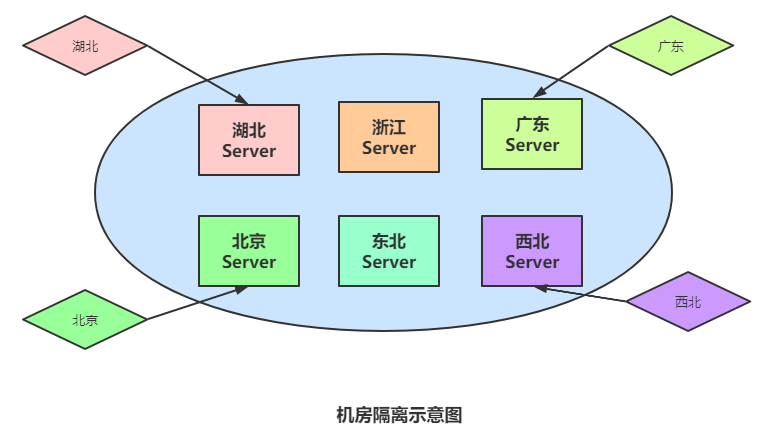
機房隔離主要目的有兩個,一方面是將不同區(qū)域的用戶數據隔離到不同的地區(qū),例如湖北的數據放在湖北的服務器,浙江的放在浙江服務器,等等,這樣能解決數據容量大,計算密集,i/o(網絡)密集度高的問題,相當于將流量分在了各個區(qū)域。
另一方面,機房隔離也是為了保證安全性,所有數據都放在一個地方,如果發(fā)生自然災害或者爆炸等災害時,數據將全都丟失,所以把服務建立整體副本(計算服務、數據存儲),在多機房內做異地多活或冷備份、是微服務數據異構的放大版本。
如果機房層面出現(xiàn)問題的時候,可以通過智能dns、httpdns、負載均衡等技術快速切換,讓區(qū)域用戶盡量不收影響。
數據讀寫隔離
通過主從模式,將mysql、redis等數據存儲服務集群化,讀寫分離,那么在寫入數據不可用的時候,也可以通過重試機制 臨時通過其他節(jié)點讀取到數據。
多節(jié)點在做子網劃分的時候,除了異地多活,還可以做數據中心,所有數據在本地機房crud 異步同步到數據中心,數據中心再去分發(fā)數據給其他機房,那么數據臨時在本地機房不可用的時候,就可以嘗試連接異地機房或數據中心。
靜態(tài)隔離
主要思路是將一些靜態(tài)資源分發(fā)在邊緣服務器中,因為日常訪問中有很多資源是不會變的,所以沒必要每次都想從主服務器上獲取,可以將這些數據保存在邊緣服務器上降低主服務器的壓力。
有一篇很詳細的講解參考:全局負載均衡與CDN內容分發(fā)
爬蟲隔離
一是限流,限制訪問的頻率;
二是將爬蟲請求轉發(fā)到固定地方。
爬蟲限流
登錄/會話限制 下載限流 訪問頻率 ip限制,黑白名單
想要分辨出來一個訪問是不是爬蟲,可以簡單的使用nginx來分析ua處理
UA介紹
User Agent 簡稱UA,就是用戶代理。通常我們用瀏覽器訪問網站,在網站的日志中,我們的瀏覽器就是一種UA。
禁止特定UA訪問,例如最近有個網站A抄襲公司主站B的內容,除了域名不同,內容、圖片等都完全是我們主站的內容。出現(xiàn)這種情況,有兩種可能:
一種是:它用爬蟲抓取公司主站B的內容并放到自己服務器上顯示;
無論怎樣,都要禁止這種行為的繼續(xù)。有兩種方法解決:
nginx不僅可以處理ua來分離流量,還可以通過更強大的openresty來完成更復雜的邏輯,實現(xiàn)一個流量網關,軟防火墻。
正文結束
1.不認命,從10年流水線工人,到谷歌上班的程序媛,一位湖南妹子的勵志故事
5.37歲程序員被裁,120天沒找到工作,無奈去小公司,結果懵了...
一個人學習、工作很迷茫?
點擊「閱讀原文」加入我們的小圈子!
