
手摸手Go 深入剖析sync.Pool
如果能夠?qū)⑺袃?nèi)存都分配到棧上無疑性能是最佳的,但不幸的是我們不可避免需要使用堆上分配的內(nèi)存。我們可以優(yōu)化使用堆內(nèi)存時的性能損耗嗎?答案是肯定的。Go同步包中,sync.Pool提供了保存和訪問一組臨時對象并復(fù)用它們的能力。
對于一些創(chuàng)建成本昂貴、頻繁使用的臨時對象,使用sync.Pool可以減少內(nèi)存分配,降低GC壓力。因?yàn)?code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;color: rgb(30, 107, 184);background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;">Go的gc算法是根據(jù)標(biāo)記清除改進(jìn)的三色標(biāo)記法,如果頻繁創(chuàng)建大量臨時對象,勢必給GC標(biāo)記帶來負(fù)擔(dān),CPU也很容易出現(xiàn)毛刺現(xiàn)象。當(dāng)然需要注意的是:存儲在Pool中的對象隨時都可能在不被通知的情況下被移除。所以并不是所有頻繁使用、創(chuàng)建昂貴的對象都適用,比如DB連接、線程池。
Talk is cheap,Show me your code
因?yàn)?code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;color: rgb(30, 107, 184);background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;">Go1.13版本后對sync.Pool做了優(yōu)化,放棄了利用sync.Mutex加鎖的方式該用CAS加帶環(huán)形數(shù)組的雙向鏈表的方式來實(shí)現(xiàn),本文基于Go1.15.8最新穩(wěn)定版本分析。
基本使用
package?main
import?"sync"
type?Person?struct?{
?Age?int
}
//?初始化pool
var?personPool?=?sync.Pool{
?New:?func()?interface{}?{
??return?new(Person)
?},
}
func?main()?{
?//?獲取一個實(shí)例
?newPerson?:=?personPool.Get().(*Person)
?//?回收對象?以備其他協(xié)程使用
?defer?personPool.Put(newPerson)
?newPerson.Age?=?25
}
使用起來比較簡單大概分三步:
初始化Pool
提供一個New函數(shù),當(dāng)Pool中未緩存該對象時調(diào)用
使用 Get從緩存池中獲取對象,接著進(jìn)行業(yè)務(wù)邏輯處理即可使用完畢 利用 Put將對象交還給緩存池
需要注意的是:跟sync.Mutex一樣sync.Pool第一次使用之后是不允許被拷貝的。
那sync.Pool對性能優(yōu)化真的有這么大魔力嗎?Benchmark之
import?(
?"testing"
)
func?BenchmarkWithoutPool(b?*testing.B)?{
?var?p?*Person
?b.ReportAllocs()
?b.ResetTimer()
?for?i?:=?0;?i???for?j?:=?0;?j?10000;?j++?{
???p?=?new(Person)
???p.Age?=?30
??}
?}
}
func?BenchmarkWithPool(b?*testing.B)?{
?var?p?*Person
?b.ReportAllocs()
?b.ResetTimer()
?for?i?:=?0;?i???for?j?:=?0;?j?10000;?j++?{
???p?=?personPool.Get().(*Person)
???p.Age?=?30
???personPool.Put(p)
??}
?}
}
基準(zhǔn)測試結(jié)果:
BenchmarkWithoutPool
BenchmarkWithoutPool-8????????7630?????135523?ns/op????80000?B/op????10000?allocs/op
BenchmarkWithPool
BenchmarkWithPool-8????????9865?????126072?ns/op????????0?B/op????????0?allocs/op
工作原理
沒有啥一張圖搞不定的
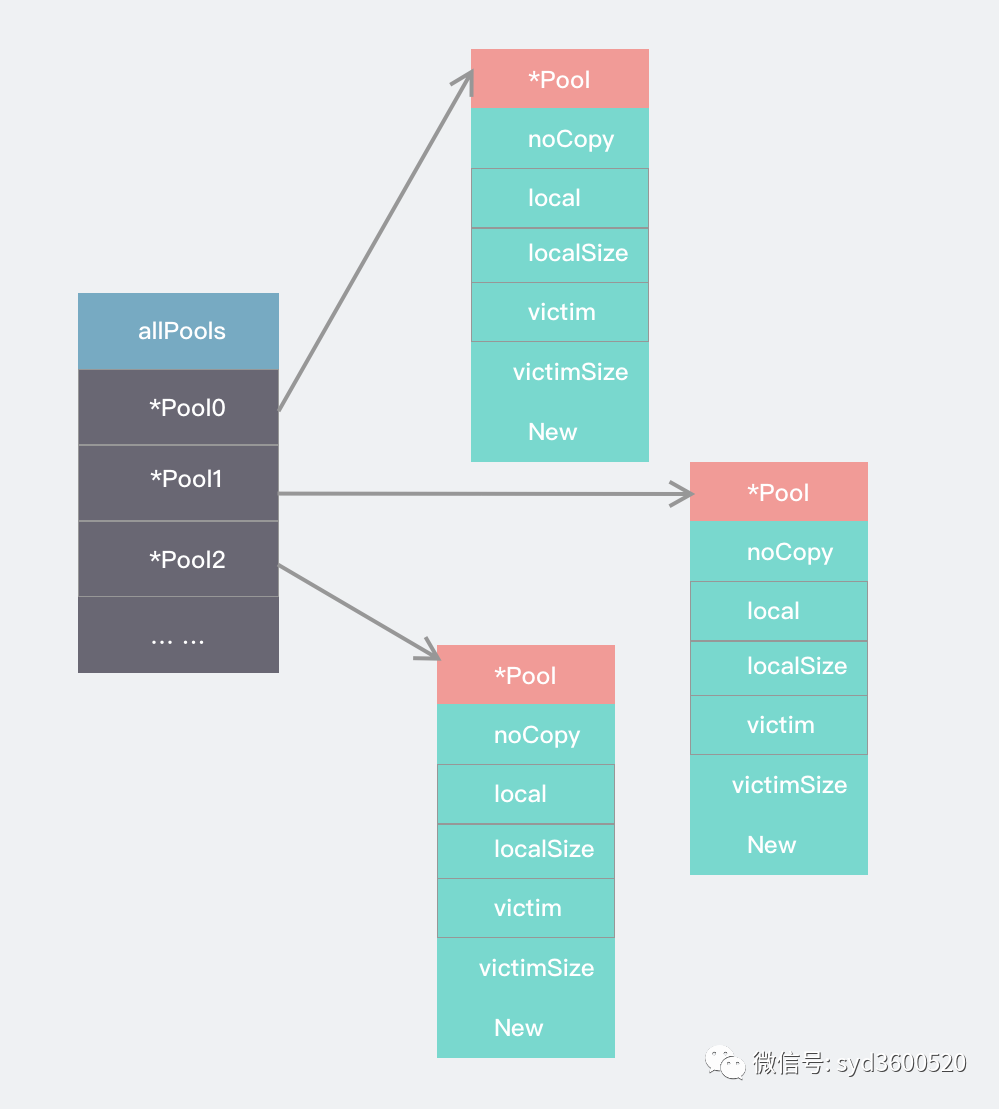
如果不行 那就再來一張
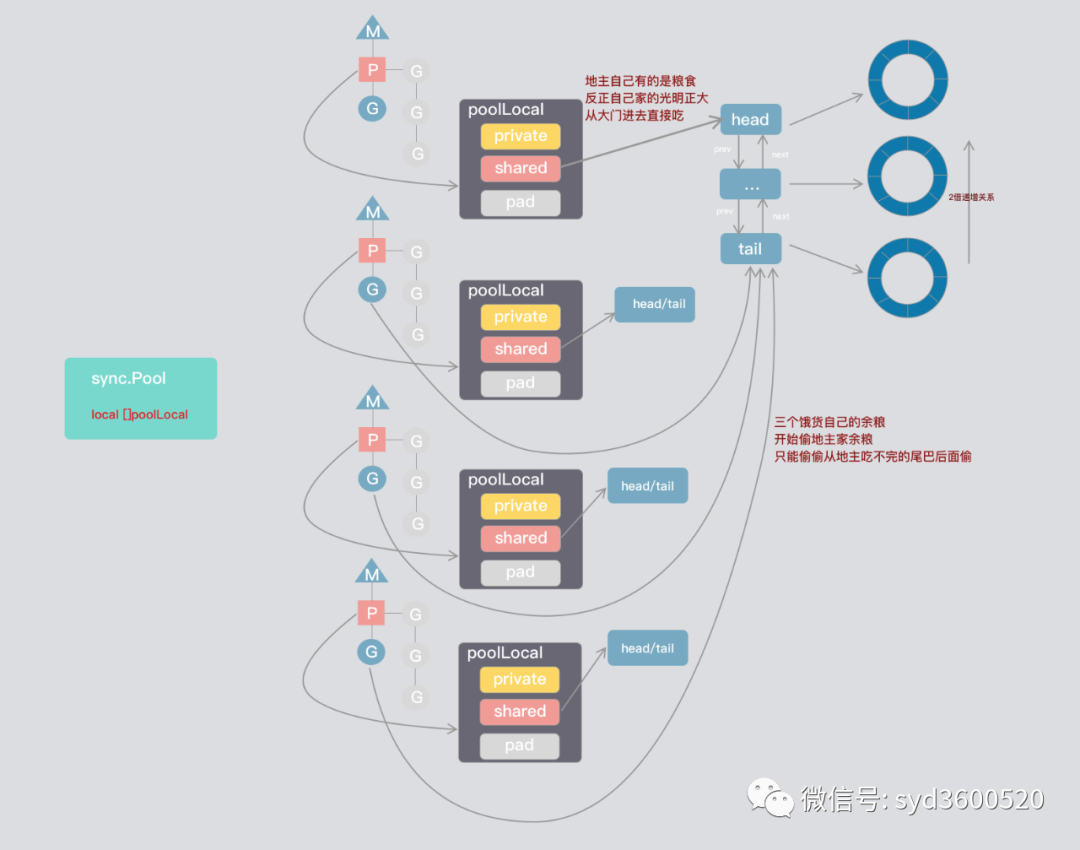
sync.Pool 數(shù)據(jù)結(jié)構(gòu)
type?Pool?struct?{
?noCopy?noCopy
?//?實(shí)際指向[]poolLocal?每個P對應(yīng)一個poolLocal?數(shù)組大小取決于P的數(shù)量?runtime.GOMAXPROCS(0)
?local?????unsafe.Pointer?
?localSize?uintptr????????//?[]poolLocal的大小
?victim?????unsafe.Pointer?//?local?from?previous?cycle
?victimSize?uintptr????????//?size?of?victims?array
??
??//當(dāng)緩存池?zé)o對應(yīng)對象時調(diào)用
?New?func()?interface{}
}
相較于Go1.13之前版本,sync.Pool的結(jié)構(gòu)體中新增了victim、victimSize字段
sync.Pool主要維護(hù)了一個sync.poolLocal的數(shù)組,數(shù)組大小由runtime.GOMAXPROCS(0)決定。
type?poolLocal?struct?{
?poolLocalInternal
?//?Prevents?false?sharing?on?widespread?platforms?with
?//?128?mod?(cache?line?size)?=?0?.
?pad?[128?-?unsafe.Sizeof(poolLocalInternal{})%128]byte
}
//?Local?per-P?Pool?appendix.
type?poolLocalInternal?struct?{
?private?interface{}?//?只能被對應(yīng)的P使用
?shared??poolChain???//?本地的P可以從Head?進(jìn)行pushHead/popHead?其他的P可以popTail.
}
poolLocal內(nèi)部又由P私有空間private和共享空間shared。共享空間是一個雙端隊列,雙端隊列每個節(jié)點(diǎn)又對應(yīng)著一個環(huán)形數(shù)組,聽著貌似有點(diǎn)兒繞,老規(guī)矩上圖:
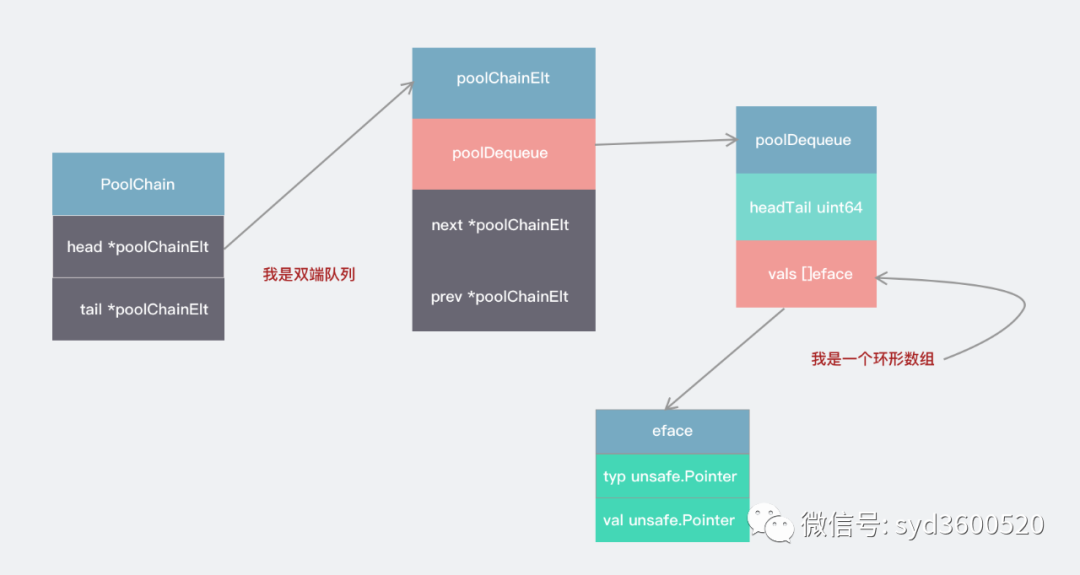
poolDequeue算是個邏輯上的環(huán)形數(shù)組,字段vals存儲著實(shí)際的值,出于操作原子性的考慮,headTail字段將首尾索引融合在一起,高32位為head的索引下標(biāo),低32位為tail的索引下標(biāo),head和tail指向同一位置則表示環(huán)形數(shù)組為空。

代碼佐證:
func?(d?*poolDequeue)?unpack(ptrs?uint64)?(head,?tail?uint32)?{
?const?mask?=?1<1
?head?=?uint32((ptrs?>>?dequeueBits)?&?mask)
?tail?=?uint32(ptrs?&?mask)
?return
}
func?(d?*poolDequeue)?pack(head,?tail?uint32)?uint64?{
?const?mask?=?1<1
?return?(uint64(head)?<??uint64(tail&mask)
}
sync.Pool實(shí)際使用過程中又將poolDequeue進(jìn)行了包裝,因?yàn)閿?shù)組大小是固定,所以為了讓他大小可變,將其包裝成了poolChainElt雙向鏈表。
操作方法
接下來我們來剖析一下sync.Pool幾個核心流程
獲取對象 p.Get
獲取對象,大體流程:
將當(dāng)前goroutine與P綁定并防止被搶占 具體是調(diào)用了 runtime_procPin,返回poolLocal和P的id優(yōu)先從私有空間獲取對象 若私有空間沒有,則嘗試從共享區(qū)域獲取 若共享區(qū)域也沒拿到,則嘗試從別人那邊“偷”來一個 若偷都偷不到,那么自己手動New一個
func?(p?*Pool)?Get()?interface{}?{
??//?將當(dāng)前goroutine與P進(jìn)行綁定?runtime_procPin禁用搶占
??//?返回poolLocal與P的id
?l,?pid?:=?p.pin()
?x?:=?l.private?//嘗試直接從私有空間拿
?l.private?=?nil
?if?x?==?nil?{
????//從共享區(qū)域頭部拿
??x,?_?=?l.shared.popHead()
??if?x?==?nil?{
??????//直接實(shí)在沒有?嘗試去別人那邊看看能不能偷個
???x?=?p.getSlow(pid)
??}
?}
??//?解除搶占禁用
?runtime_procUnpin()
??//?都沒有?那只好自己New一個
?if?x?==?nil?&&?p.New?!=?nil?{
??x?=?p.New()
?}
?return?x
}
那么我們來看看goroutine 是怎么跟P綁定的
func?(p?*Pool)?pin()?(*poolLocal,?int)?{
?pid?:=?runtime_procPin()
??//?pinSlow中我們先存儲local再存儲localSize,這里我們以相反順序加載
??//?因?yàn)槲覀円呀?jīng)禁用了搶占?GC這期間不會發(fā)生?因此我們需要觀察local的大小至少跟localSize一樣
?s?:=?atomic.LoadUintptr(&p.localSize)?//?load-acquire
?l?:=?p.local??????????????????????????//?load-consume
?if?uintptr(pid)???return?indexLocal(l,?pid),?pid
?}
??//?運(yùn)行過程中可能會存在調(diào)整P的情況?或者GC了
?return?p.pinSlow()
}
這里我們先調(diào)用runtime_procPin(),為啥它這么牛逼,不僅讓P不會被搶占,還讓GC為之折腰?
番外:禁止搶占
func?runtime_procPin()?int
//go:linkname?sync_runtime_procPin?sync.runtime_procPin
//go:nosplit
func?sync_runtime_procPin()?int?{
?return?procPin()
}
//go:nosplit
func?procPin()?int?{
?_g_?:=?getg()
?mp?:=?_g_.m
?mp.locks++
?return?int(mp.p.ptr().id)
}
正如所見,兜兜轉(zhuǎn)轉(zhuǎn)實(shí)際綁定goroutine和P、禁用搶占交給了procPin。procPin首先從TLS或?qū)S眉拇嫫髂玫疆?dāng)前的goroutine,然后獲取當(dāng)前gorountine綁定的物理線程,并對物理線程的locks屬性自增操作。這意味什么呢?
這里可能涉及到一些goroutine調(diào)度的內(nèi)容,Go runtime調(diào)度是一個GPM模型。G為調(diào)度的基本單元,P可以理解為運(yùn)行G的邏輯CPU M為系統(tǒng)線程。何為搶占?
即,將m綁定的P給占用,因?yàn)?code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;color: rgb(30, 107, 184);background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;">Go runtime中99.9%的任務(wù)都需要P才能執(zhí)行任務(wù)。Go運(yùn)行時調(diào)度主要存在兩種搶占的情況:
第一種情況,進(jìn)行系統(tǒng)調(diào)用的 G,因?yàn)榇嬖谧枞瞪档仍谀抢飼容^浪費(fèi)計算資源,為了讓其他goroutine不被餓死第二種情況,如果一個 G運(yùn)行時間太長,P中其他G得不到執(zhí)行也會餓死
搶占實(shí)現(xiàn)
Go中的搶占是sysmon實(shí)現(xiàn)的。對 沒錯就是runtime.main里的那個sysmon也是唯一一個脫離GPM模型只需GM即可運(yùn)行的特例。sysmon中包含了netpool、retake、forcegc、scavengeheap,這里搶占我們需要關(guān)注下retake。
//go:nowritebarrierrec
func?sysmon()?{
??...
?//?retake?P's?blocked?in?syscalls
??//?and?preempt?long?running?G's
??if?retake(now)?!=?0?{
???idle?=?0
??}?else?{
???idle++
??}
??...
}
func?retake(now?int64)?uint32?{
?...?
if?s?==?_Prunning?||?s?==?_Psyscall?{
???//?Preempt?G?if?it's?running?for?too?long.
???t?:=?int64(_p_.schedtick)
???if?int64(pd.schedtick)?!=?t?{
????pd.schedtick?=?uint32(t)
????pd.schedwhen?=?now
???}?else?if?pd.schedwhen+forcePreemptNS?<=?now?{//G運(yùn)行時間超過forcePreemptNS
????preemptone(_p_)
????//?In?case?of?syscall,?preemptone()?doesn't
????//?work,?because?there?is?no?M?wired?to?P.
????sysretake?=?true
???}
??...
}
P處于運(yùn)行中或系統(tǒng)調(diào)用,檢查G運(yùn)行時間是否超過forcePreemptNS(10ms),超過則調(diào)用preemptone(_p_)搶占這個P
func?preemptone(_p_?*p)?bool?{
?mp?:=?_p_.m.ptr()
?if?mp?==?nil?||?mp?==?getg().m?{
??return?false
?}
?gp?:=?mp.curg
?if?gp?==?nil?||?gp?==?mp.g0?{
??return?false
?}
?gp.preempt?=?true
?//?Every?call?in?a?go?routine?checks?for?stack?overflow?by
?//?comparing?the?current?stack?pointer?to?gp->stackguard0.
?//?Setting?gp->stackguard0?to?StackPreempt?folds
?//?preemption?into?the?normal?stack?overflow?check.
?gp.stackguard0?=?stackPreempt
?//?Request?an?async?preemption?of?this?P.
?if?preemptMSupported?&&?debug.asyncpreemptoff?==?0?{
??_p_.preempt?=?true
??preemptM(mp)
?}
?return?true
}
主要是設(shè)置兩個標(biāo)志位gp.preempt和gp.stackguard0 主要起作用的是后者。通過將goroutine的stackguard0設(shè)置為(1<<(8*sys.PtrSize) - 1)& -1314,導(dǎo)致P在執(zhí)行G下一次的函數(shù)調(diào)用時,棧空間檢查失敗(stackguard0與SP寄存器比較),進(jìn)而觸發(fā)編譯器安插的指令morestack。
//以asm_amd64.s為例
TEXT runtime·morestack(SB),NOSPLIT,$0-0
... ...
// Call newstack on m->g0's stack.
MOVQ m_g0(BX), BX
MOVQ BX, g(CX)
MOVQ (g_sched+gobuf_sp)(BX), SP
CALL runtime·newstack(SB)
CALL runtime·abort(SB) // crash if newstack returns
RET
morestack會調(diào)用newstack嘗試棧擴(kuò)容
//go:nowritebarrierrec
func?newstack()?{
??...?...
?if?preempt?{
??if?!canPreemptM(thisg.m)?{
???//?Let?the?goroutine?keep?running?for?now.
???//?gp->preempt?is?set,?so?it?will?be?preempted?next?time.
???gp.stackguard0?=?gp.stack.lo?+?_StackGuard
???gogo(&gp.sched)?//?never?return
??}
?}
?...?...?
}
//go:nosplit
func?canPreemptM(mp?*m)?bool?{
?return?mp.locks?==?0?&&?mp.mallocing?==?0?&&?mp.preemptoff?==?""?&&?mp.p.ptr().status?==?_Prunning
}
newstack在棧擴(kuò)容前會檢查搶占標(biāo)志位mp.locks!=0則不搶占。
如果搶占成功,則會繼續(xù)調(diào)用
gopreempt_m(gp)進(jìn)而調(diào)用goschedImpl(gp)將P與當(dāng)前m接觸關(guān)聯(lián),設(shè)置goroutine狀態(tài)casgstatus(gp, _Grunning, _Grunnable),然后將goroutine插入Global runnable queue 等待下次調(diào)度。
至此,應(yīng)該能徹底明白為啥runtime_procPin能夠通過修改goroutine綁定的m的locks屬性就能禁用搶占了。
但是還有個問題,為啥GC也拿它沒辦法?
關(guān)于Go的GC,大致有三種觸發(fā)方式:
gcTriggerCycle 后臺定時檢查觸發(fā),如 runtime.sysmongcTriggerTimer 自上個GC周期超過forcegcperiod納秒則觸發(fā) 如 runtime.forcegchelperg cTriggerHeap 申請的堆內(nèi)存大小達(dá)到觸發(fā)閾值 如 runtime.mallocgc
最終都會調(diào)用gcStart(trigger gcTrigger),進(jìn)而我們在GC的STW階段執(zhí)行中可以看到
func?stopTheWorldWithSema()?{
?_g_?:=?getg()
?//?If?we?hold?a?lock,?then?we?won't?be?able?to?stop?another?M
?//?that?is?blocked?trying?to?acquire?the?lock.
?if?_g_.m.locks?>?0?{
??throw("stopTheWorld:?holding?locks")
?}
?lock(&sched.lock)
?sched.stopwait?=?gomaxprocs
?atomic.Store(&sched.gcwaiting,?1)
?preemptall()
?//?stop?current?P
?_g_.m.p.ptr().status?=?_Pgcstop?//?Pgcstop?is?only?diagnostic.
?sched.stopwait--
?//?try?to?retake?all?P's?in?Psyscall?status
?for?_,?p?:=?range?allp?{
??s?:=?p.status
??if?s?==?_Psyscall?&&?atomic.Cas(&p.status,?s,?_Pgcstop)?{
???if?trace.enabled?{
????traceGoSysBlock(p)
????traceProcStop(p)
???}
???p.syscalltick++
???sched.stopwait--
??}
?}
?//?stop?idle?P's
?for?{
??p?:=?pidleget()
??if?p?==?nil?{
???break
??}
??p.status?=?_Pgcstop
??sched.stopwait--
?}
?wait?:=?sched.stopwait?>?0
?unlock(&sched.lock)
?//?wait?for?remaining?P's?to?stop?voluntarily
?if?wait?{
??for?{
???//?wait?for?100us,?then?try?to?re-preempt?in?case?of?any?races
???if?notetsleep(&sched.stopnote,?100*1000)?{
????noteclear(&sched.stopnote)
????break
???}
???preemptall()
??}
?}
?//?sanity?checks
?bad?:=?""
?if?sched.stopwait?!=?0?{
??bad?=?"stopTheWorld:?not?stopped?(stopwait?!=?0)"
?}?else?{
??for?_,?p?:=?range?allp?{
???if?p.status?!=?_Pgcstop?{
????bad?=?"stopTheWorld:?not?stopped?(status?!=?_Pgcstop)"
???}
??}
?}
?if?atomic.Load(&freezing)?!=?0?{
??//?Some?other?thread?is?panicking.?This?can?cause?the
??//?sanity?checks?above?to?fail?if?the?panic?happens?in
??//?the?signal?handler?on?a?stopped?thread.?Either?way,
??//?we?should?halt?this?thread.
??lock(&deadlock)
??lock(&deadlock)
?}
?if?bad?!=?""?{
??throw(bad)
?}
}
大致邏輯先調(diào)用preemptall()嘗試搶占所有的P,然后停掉當(dāng)前P,遍歷所有的P,如果P處于系統(tǒng)調(diào)用則直接stop掉;然后處理空閑的P;最后檢查是否存在需要等待處理的P,如果有則循環(huán)等待,并嘗試調(diào)用preemptall()
func?preemptall()?bool?{
?res?:=?false
?for?_,?_p_?:=?range?allp?{
??if?_p_.status?!=?_Prunning?{
???continue
??}
??if?preemptone(_p_)?{
???res?=?true
??}
?}
?return?res
}
到這里就很清晰了,我們又看到老朋友preemptone(_p_),顯然GC會在STW階段等下去,GC自然也無法執(zhí)行下去。
好了 剛剛兩個問題我們已經(jīng)搞清楚了。書歸正傳 runtime_procPin能禁用P被搶占,那么runtime_procUnpin自然能解除禁用。完成goroutine與P的綁定,返回了當(dāng)前P的id,如果pidpoolLocal
func?indexLocal(l?unsafe.Pointer,?i?int)?*poolLocal?{
?lp?:=?unsafe.Pointer(uintptr(l)?+?uintptr(i)*unsafe.Sizeof(poolLocal{}))
?return?(*poolLocal)(lp)
}
如果運(yùn)行時P被調(diào)整了呢?那么嘗試下p.pinSlow(),正如其名這個過程會有點(diǎn)兒慢
func?(p?*Pool)?pinSlow()?(*poolLocal,?int)?{
?//?Retry?under?the?mutex.
?//?Can?not?lock?the?mutex?while?pinned.
?runtime_procUnpin()
?allPoolsMu.Lock()
?defer?allPoolsMu.Unlock()
?pid?:=?runtime_procPin()
?//?poolCleanup?won't?be?called?while?we?are?pinned.
?s?:=?p.localSize
?l?:=?p.local
?if?uintptr(pid)???return?indexLocal(l,?pid),?pid
?}
?if?p.local?==?nil?{
??allPools?=?append(allPools,?p)
?}
?//?If?GOMAXPROCS?changes?between?GCs,?we?re-allocate?the?array?and?lose?the?old?one.
?size?:=?runtime.GOMAXPROCS(0)
?local?:=?make([]poolLocal,?size)
?atomic.StorePointer(&p.local,?unsafe.Pointer(&local[0]))?//?store-release
?atomic.StoreUintptr(&p.localSize,?uintptr(size))?????????//?store-release
?return?&local[pid],?pid
}
pinSlow()上來第一件事兒 將我們之前設(shè)置的P禁用搶占給釋放了。然后嘗試獲取全局排他鎖allPoolsMu Mutex。這也能解釋它為啥上來就釋放掉之前的禁止占用,因?yàn)楂@取當(dāng)前全局排他鎖不一定能立馬拿到啊。拿到鎖之后又開啟了禁止搶占P,接著又判斷了下uintptr(pid) < s因?yàn)槟玫芥i之前P可能已經(jīng)變化了。如果當(dāng)前p.local=nil則將p放到全局的池子allPools []*Pool里,也是為啥剛才需要等待全局排他鎖的原因。因?yàn)?code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;color: rgb(30, 107, 184);background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;">GC時會將原有的pool清理掉所以這里進(jìn)行重建,原有pool真的沒了嗎?這個就跟之前提到的victim有點(diǎn)兒關(guān)系了 等會兒一起看。
至此,我們拿到了poolLocal,接著獲取對象的順序?yàn)?/p>
首先嘗試從本地的private中獲取 如果本地沒拿到,則 x, _ = l.shared.popHead()嘗試從共享空間拿
func?(c?*poolChain)?popHead()?(interface{},?bool)?{
?d?:=?c.head
?for?d?!=?nil?{
??if?val,?ok?:=?d.popHead();?ok?{
???return?val,?ok
??}
??//?There?may?still?be?unconsumed?elements?in?the
??//?previous?dequeue,?so?try?backing?up.
??d?=?loadPoolChainElt(&d.prev)
?}
?return?nil,?false
}
共享空間是以PoolChainElt為節(jié)點(diǎn)的雙向鏈表,首先我們嘗試沿著雙向鏈表prev的方向依次調(diào)用d.popHead()嘗試從頭部拿數(shù)據(jù)
func?(d?*poolDequeue)?popHead()?(interface{},?bool)?{
?var?slot?*eface
?for?{
??ptrs?:=?atomic.LoadUint64(&d.headTail)
??head,?tail?:=?d.unpack(ptrs)
??if?tail?==?head?{
???//?Queue?is?empty.
???return?nil,?false
??}
??//?Confirm?tail?and?decrement?head.?We?do?this?before
??//?reading?the?value?to?take?back?ownership?of?this
??//?slot.
??head--
??ptrs2?:=?d.pack(head,?tail)
??if?atomic.CompareAndSwapUint64(&d.headTail,?ptrs,?ptrs2)?{
???//?We?successfully?took?back?slot.
???slot?=?&d.vals[head&uint32(len(d.vals)-1)]
???break
??}
?}
?val?:=?*(*interface{})(unsafe.Pointer(slot))
?if?val?==?dequeueNil(nil)?{
??val?=?nil
?}
?//?Zero?the?slot.?Unlike?popTail,?this?isn't?racing?with
?//?pushHead,?so?we?don't?need?to?be?careful?here.
?*slot?=?eface{}
?return?val,?true
}
邏輯也比較簡單
2.1 將headTail拆封 如果head==tail表明當(dāng)前環(huán)形數(shù)組為空,直接返回
2.2 接著將head索引減1,然后將head、tail再打包回去,通過CAS判斷當(dāng)前沒有并發(fā)修改就拿到數(shù)據(jù) 跳出循環(huán) 否則循環(huán)等待
2.3 將slot轉(zhuǎn)為interface{}類型
2.4 將slot賦值為eface{}
如果共享空間依然沒拿到,那么想辦法從其他 P那偷個吧p.getSlow(pid)
func?(p?*Pool)?getSlow(pid?int)?interface{}?{
?//?See?the?comment?in?pin?regarding?ordering?of?the?loads.
?size?:=?atomic.LoadUintptr(&p.localSize)?//?load-acquire
?locals?:=?p.local????????????????????????//?load-consume
?//?Try?to?steal?one?element?from?other?procs.
?for?i?:=?0;?i?int(size);?i++?{
??l?:=?indexLocal(locals,?(pid+i+1)%int(size))
??if?x,?_?:=?l.shared.popTail();?x?!=?nil?{
???return?x
??}
?}
?//?Try?the?victim?cache.?We?do?this?after?attempting?to?steal
?//?from?all?primary?caches?because?we?want?objects?in?the
?//?victim?cache?to?age?out?if?at?all?possible.
?size?=?atomic.LoadUintptr(&p.victimSize)
?if?uintptr(pid)?>=?size?{
??return?nil
?}
?locals?=?p.victim
?l?:=?indexLocal(locals,?pid)
?if?x?:=?l.private;?x?!=?nil?{
??l.private?=?nil
??return?x
?}
?for?i?:=?0;?i?int(size);?i++?{
??l?:=?indexLocal(locals,?(pid+i)%int(size))
??if?x,?_?:=?l.shared.popTail();?x?!=?nil?{
???return?x
??}
?}
?//?Mark?the?victim?cache?as?empty?for?future?gets?don't?bother
?//?with?it.
?atomic.StoreUintptr(&p.victimSize,?0)
?return?nil
}
3.1 拿到[]poolLocal數(shù)組,遍歷每個poolLocal,并調(diào)用l.shared.popTail() 從其共享空間的尾部拿數(shù)據(jù)
func?(c?*poolChain)?popTail()?(interface{},?bool)?{
?d?:=?loadPoolChainElt(&c.tail)
?if?d?==?nil?{
??return?nil,?false
?}
?for?{
??//?It's?important?that?we?load?the?next?pointer
??//?*before*?popping?the?tail.?In?general,?d?may?be
??//?transiently?empty,?but?if?next?is?non-nil?before
??//?the?pop?and?the?pop?fails,?then?d?is?permanently
??//?empty,?which?is?the?only?condition?under?which?it's
??//?safe?to?drop?d?from?the?chain.
??d2?:=?loadPoolChainElt(&d.next)
??if?val,?ok?:=?d.popTail();?ok?{
???return?val,?ok
??}
??if?d2?==?nil?{
???//?This?is?the?only?dequeue.?It's?empty?right
???//?now,?but?could?be?pushed?to?in?the?future.
???return?nil,?false
??}
??//?The?tail?of?the?chain?has?been?drained,?so?move?on
??//?to?the?next?dequeue.?Try?to?drop?it?from?the?chain
??//?so?the?next?pop?doesn't?have?to?look?at?the?empty
??//?dequeue?again.
??if?atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&c.tail)),?unsafe.Pointer(d),?unsafe.Pointer(d2))?{
???//?We?won?the?race.?Clear?the?prev?pointer?so
???//?the?garbage?collector?can?collect?the?empty
???//?dequeue?and?so?popHead?doesn't?back?up
???//?further?than?necessary.
???storePoolChainElt(&d2.prev,?nil)
??}
??d?=?d2
?}
}
首先拿到尾節(jié)點(diǎn),然后在死循環(huán)中沿著雙向鏈表next的方向不斷獲取PoolChainElt節(jié)點(diǎn),嘗試調(diào)用d.popTail()獲取數(shù)據(jù)
func?(d?*poolDequeue)?popTail()?(interface{},?bool)?{
?var?slot?*eface
?for?{
??ptrs?:=?atomic.LoadUint64(&d.headTail)
??head,?tail?:=?d.unpack(ptrs)
??if?tail?==?head?{
???//?Queue?is?empty.
???return?nil,?false
??}
??ptrs2?:=?d.pack(head,?tail+1)
??if?atomic.CompareAndSwapUint64(&d.headTail,?ptrs,?ptrs2)?{
???slot?=?&d.vals[tail&uint32(len(d.vals)-1)]
???break
??}
?}
?val?:=?*(*interface{})(unsafe.Pointer(slot))
?if?val?==?dequeueNil(nil)?{
??val?=?nil
?}
?slot.val?=?nil
?atomic.StorePointer(&slot.typ,?nil)
?return?val,?true
}
與popHead比較像,不同在于一個從頭部拿數(shù)據(jù)一個從尾部拿。首先依然是在死循環(huán)中先將headTail拆封,如果tai l==head表示環(huán)形數(shù)組為空,直接返回。否則將tail+1再封裝好,同CAS規(guī)避并發(fā)問題 拿到數(shù)據(jù)則跳出循環(huán),否則循環(huán)等待。
這里有一個跟popHead不同的是 先將value置為nil然后利用CAS來將typ置空操作atomic.StorePointer(&slot.typ, nil),原因很簡單,pushHead和popTail一個從頭放一個從尾拿數(shù)據(jù),一旦碰頭就會出現(xiàn)競爭。
3.2 那如果偷都偷不到,會進(jìn)行以下操作
size?=?atomic.LoadUintptr(&p.victimSize)
?if?uintptr(pid)?>=?size?{
??return?nil
?}
?locals?=?p.victim
?l?:=?indexLocal(locals,?pid)
?if?x?:=?l.private;?x?!=?nil?{
??l.private?=?nil
??return?x
?}
?for?i?:=?0;?i?int(size);?i++?{
??l?:=?indexLocal(locals,?(pid+i)%int(size))
??if?x,?_?:=?l.shared.popTail();?x?!=?nil?{
???return?x
??}
?}
?//?Mark?the?victim?cache?as?empty?for?future?gets?don't?bother
?//?with?it.
?atomic.StoreUintptr(&p.victimSize,?0)
victim cache翻譯過來叫“受害者緩存”
受害者緩存是由Norman Jouppi提出的一種提高緩存性能的硬件技術(shù)。如他的論文所述
Miss caching places a fully-associative cache between cache and its re-fill path. Misses in the cache that hit in the miss cache have a one cycle penalty, as opposed to a many cycle miss penalty without the miss cache. Victim Caching is an improvement to miss caching that loads the small fully-associative cache with victim of a miss and not the requested cache line.
大概意思就是在舊緩存和緩解重建的過程中,添加一個全關(guān)聯(lián)的緩存(保存舊緩存數(shù)據(jù))。也就是說當(dāng)一級緩存踢出的數(shù)據(jù),放到受害者緩存中。當(dāng)我們在一級緩存未命中,則可以繼續(xù)嘗試從受害者緩存中查詢。
如代碼:
size?=?atomic.LoadUintptr(&p.victimSize)
?if?uintptr(pid)?>=?size?{
??return?nil
?}
?locals?=?p.victim
?l?:=?indexLocal(locals,?pid)
?if?x?:=?l.private;?x?!=?nil?{
??l.private?=?nil
??return?x
?}
?for?i?:=?0;?i?int(size);?i++?{
??l?:=?indexLocal(locals,?(pid+i)%int(size))
??if?x,?_?:=?l.shared.popTail();?x?!=?nil?{
???return?x
??}
?}
?//?Mark?the?victim?cache?as?empty?for?future?gets?don't?bother
?//?with?it.
?atomic.StoreUintptr(&p.victimSize,?0)
如果能理解,其實(shí)還是挺簡單的,也就是
local1 ->GC ->local2 ? ? victim->local1
Local2 ->GC ->local3 ? ?victim->local2
很遺憾getSlow也沒拿到 那只好自己手動new一個了
if?x?==?nil?&&?p.New?!=?nil?{
??x?=?p.New()
?}
用完返回Pool p.Put
看完 Get,接著看下Put
func?(p?*Pool)?Put(x?interface{})?{
?if?x?==?nil?{
??return
?}
??//?將goroutine與P綁定?runtime_procPin禁用搶占?返回poolLocal
?l,?_?:=?p.pin()
?if?l.private?==?nil?{//優(yōu)先放到私有空間
??l.private?=?x
??x?=?nil
?}
?if?x?!=?nil?{?//放回共享空間
??l.shared.pushHead(x)
?}
??//?解除搶占禁用
?runtime_procUnpin()
}
基本邏輯:
如果放入對象為空 直接返回 調(diào)用 p.pin獲取poolLocal之前分析過大體類似優(yōu)先放入私有空間 若私有空間已滿 則嘗試放入共享空間 釋放P禁止占用
func?(c?*poolChain)?pushHead(val?interface{})?{
?d?:=?c.head
?if?d?==?nil?{
??//?Initialize?the?chain.
??const?initSize?=?8?//?Must?be?a?power?of?2
??d?=?new(poolChainElt)
??d.vals?=?make([]eface,?initSize)
??c.head?=?d
??storePoolChainElt(&c.tail,?d)
?}
?if?d.pushHead(val)?{
??return
?}
?newSize?:=?len(d.vals)?*?2
?if?newSize?>=?dequeueLimit?{
??//?Can't?make?it?any?bigger.
??newSize?=?dequeueLimit
?}
?d2?:=?&poolChainElt{prev:?d}
?d2.vals?=?make([]eface,?newSize)
?c.head?=?d2
?storePoolChainElt(&d.next,?d2)
?d2.pushHead(val)
}
putHead邏輯主要是將對象放到雙向鏈表的對應(yīng)節(jié)點(diǎn)的環(huán)形數(shù)組中。
先獲取雙向鏈表的head節(jié)點(diǎn) 若head節(jié)點(diǎn)為空 則初始化head節(jié)點(diǎn) 節(jié)點(diǎn)對應(yīng)環(huán)形數(shù)組初始大小為8 將對象放到環(huán)形數(shù)組中
func?(d?*poolDequeue)?pushHead(val?interface{})?bool?{
?ptrs?:=?atomic.LoadUint64(&d.headTail)
?head,?tail?:=?d.unpack(ptrs)
?if?(tail+uint32(len(d.vals)))&(1<-1)?==?head?{
??//?Queue?is?full.
??return?false
?}
?slot?:=?&d.vals[head&uint32(len(d.vals)-1)]
?typ?:=?atomic.LoadPointer(&slot.typ)
?if?typ?!=?nil?{//?popTail可能還沒處理完
??return?false
?}
?//?The?head?slot?is?free,?so?we?own?it.
?if?val?==?nil?{
??val?=?dequeueNil(nil)
?}
?*(*interface{})(unsafe.Pointer(slot))?=?val
?atomic.AddUint64(&d.headTail,?1<?return?true
}
跟popHead是相反的操作,大體也比較簡單。先判斷環(huán)形數(shù)組是否滿了,滿了則直接返回。因?yàn)?code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;color: rgb(30, 107, 184);background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;">pushHead跟popTail存在競爭關(guān)系,slot.typ不為空可能是popTail還沒處理完。
關(guān)于GC清除數(shù)據(jù)問題
pool.go中的init函數(shù)組冊了GC發(fā)生時如何清理Pool的函數(shù),調(diào)用鏈如下
gcTrigger->gcStart()->clearpools()->poolCleanup()
func?init()?{
?runtime_registerPoolCleanup(poolCleanup)
}
//go:linkname?sync_runtime_registerPoolCleanup?sync.runtime_registerPoolCleanup
func?sync_runtime_registerPoolCleanup(f?func())?{
?poolcleanup?=?f
}
func?poolCleanup()?{
?for?_,?p?:=?range?oldPools?{
??p.victim?=?nil
??p.victimSize?=?0
?}
?for?_,?p?:=?range?allPools?{
??p.victim?=?p.local
??p.victimSize?=?p.localSize
??p.local?=?nil
??p.localSize?=?0
?}
?oldPools,?allPools?=?allPools,?nil
}
邏輯很簡單 正如上面講victim說的那樣。
最后的最后,細(xì)心的你可能發(fā)現(xiàn) 還遺漏了兩個細(xì)節(jié)
noCopy
sync.Pool結(jié)構(gòu)體中noCopy其實(shí)是為了防止sync.Pool使用過程中被拷貝。至于原因應(yīng)該不用多說,因?yàn)?code style="font-size: 14px;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;color: rgb(30, 107, 184);background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;">Go并沒有提供原生的強(qiáng)制不能拷貝的方法。所以采用這種方式,讓go vet檢測報錯來實(shí)現(xiàn)。
舉個例子
type?noCopy?struct{}
//?Lock?is?a?no-op?used?by?-copylocks?checker?from?`go?vet`.
func?(*noCopy)?Lock()???{}
func?(*noCopy)?Unlock()?{}
type?People?struct?{
?noCopy?noCopy
}
func?say(p?People)?{
}
func?main()?{
?var?p?People
?say(p)
}
go?vet?demo.go
輸出:
#?command-line-arguments
./demo.go:12:12:?say?passes?lock?by?value:?command-line-arguments.People?contains?command-line-arguments.noCopy
./demo.go:18:6:?call?of?say?copies?lock?value:?command-line-arguments.People?contains?command-line-arguments.noCopy
當(dāng)然直接執(zhí)行不會報任何錯
pad
type?poolLocal?struct?{
?poolLocalInternal
?//?Prevents?false?sharing?on?widespread?platforms?with
?//?128?mod?(cache?line?size)?=?0?.
?pad?[128?-?unsafe.Sizeof(poolLocalInternal{})%128]byte
}
pad字段在這里沒有啥業(yè)務(wù)意思,目的就是為了避免偽共享問題。因?yàn)槲覀優(yōu)榱司徑庥嬎銠C(jī)CPU計算速度和內(nèi)存的讀取速度不匹配的矛盾,在他們之間增加了L1 L2 L3 高速緩存,他們比內(nèi)存小很多但是速度卻是內(nèi)存無法比擬的。
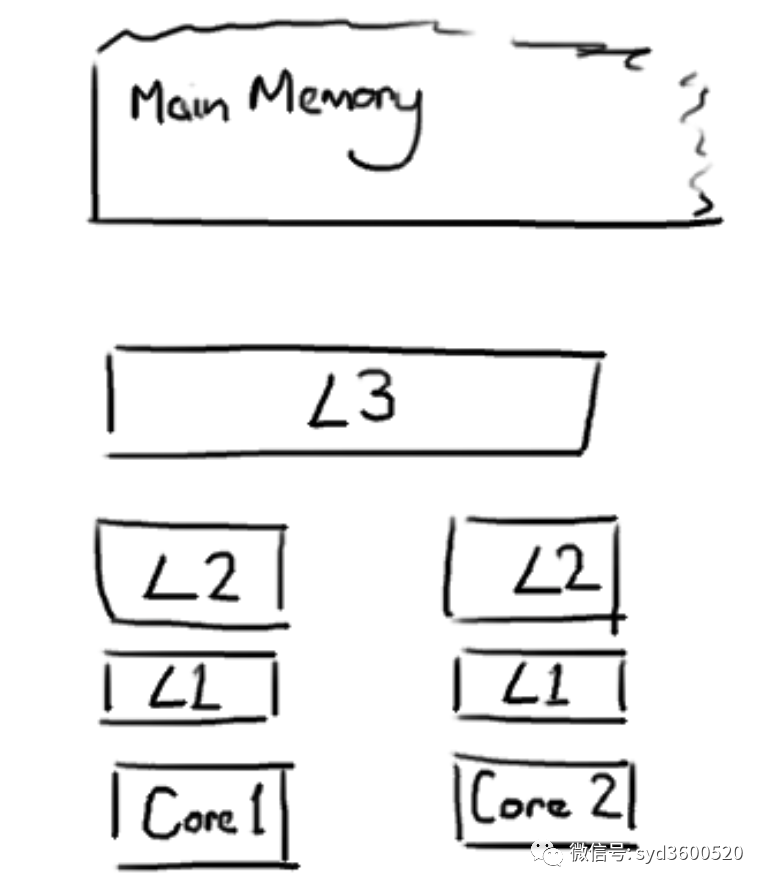
緩存系統(tǒng)中我們是以緩存行(cache line)為單位,通常大小為64字節(jié)。上面這張圖,我們可以看到L1、L2、L3三級緩存他們和內(nèi)存的讀取速度當(dāng)然取決于他們與CPU緊密程度。L1>L2>L3>內(nèi)存
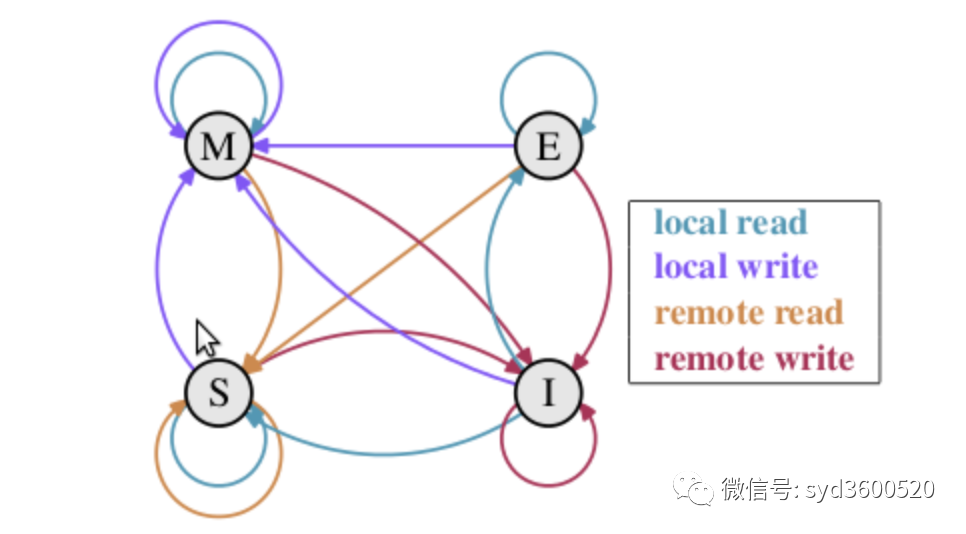
但是!我們現(xiàn)在使用的都是多核CPU的計算機(jī),如何保證多核看到的數(shù)據(jù)的一致性呢?這里我們需要談到一個協(xié)議-MESI協(xié)議,M、E、S、I分別表示緩存行的4個狀態(tài)
M(修改,Modified):本地處理器已經(jīng)修改緩存行,即是臟行,它的內(nèi)容與內(nèi)存中的內(nèi)容不一樣,并且此 cache 只有本地一個拷貝(專有);
E(專有,Exclusive):緩存行內(nèi)容和內(nèi)存中的一樣,而且其它處理器都沒有這行數(shù)據(jù);
S(共享,Shared):緩存行內(nèi)容和內(nèi)存中的一樣, 有可能其它處理器也存在此緩存行的拷貝;
I(無效,Invalid):緩存行失效, 不能使用。
他們轉(zhuǎn)換關(guān)系如下:
現(xiàn)在假設(shè)我們有以下場景
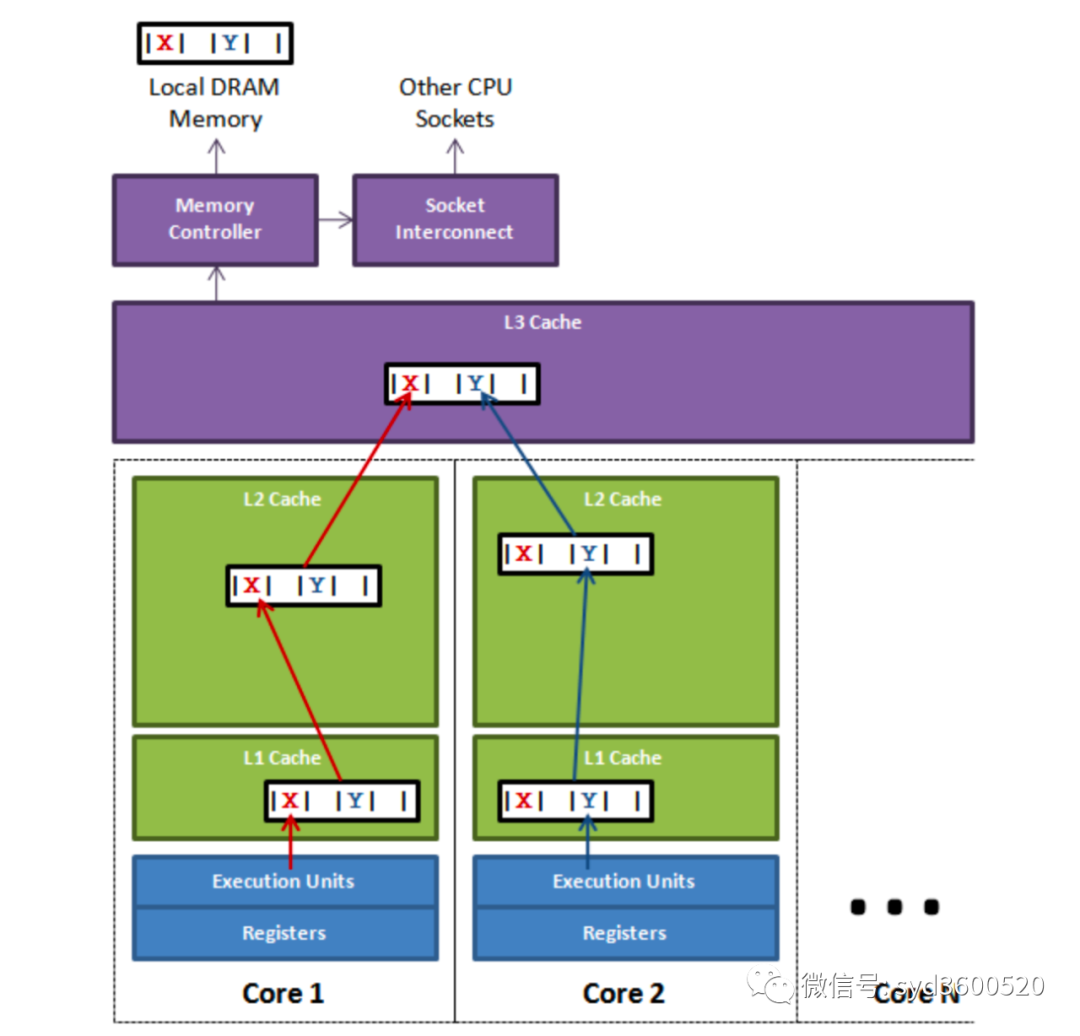
有兩個變量X、Y共享在了一個cache line中。如果core1想要更新X,core2想要更新Y,更新完他們的緩存行都變成了I狀態(tài),即L1 L2上的緩存均不可用,這時如果其他線程再要訪問X Y就只能從L3甚至從內(nèi)存拿數(shù)據(jù),其性能可想而知。
怎么解決呢?
解決偽共享的問題 業(yè)界大多采用pad填充的方式來解決,讓數(shù)據(jù)獨(dú)占一個cacheline 降低數(shù)據(jù)關(guān)聯(lián)共享的影響。比如Java8還提供了語法糖,通過添加注解@Contended自動進(jìn)行緩存行填充。
總結(jié)
sync.Pool實(shí)現(xiàn)總體比較小巧,具體思想其實(shí)其他語言也都有影子,比如Java中的ForkJoinPool。但是往往簡單設(shè)計的細(xì)節(jié)往往很值得我們?nèi)タ季繉W(xué)習(xí)一下的。總結(jié)下知識點(diǎn)還真不少:
work stealing算法 CAS如何做到lock-free 設(shè)置搶占標(biāo)志 禁止P被占用 并制止GC Victim cache 受害者緩存是怎么回事兒 noCopy是干啥的 怎么實(shí)現(xiàn)禁止拷貝 偽共享(false share) Pool GC的機(jī)制
不過這也符合Go“少即是多”的設(shè)計理念。
推薦閱讀