
go 的運(yùn)行時
goroutine 定義
“Goroutine 是一個與其他 goroutines 并行運(yùn)行在同一地址空間的 Go 函數(shù)或方法。一個運(yùn)行的程序由一個或更多個 goroutine 組成。它與線程、協(xié)程、進(jìn)程等不同。它是一個 goroutine” —— Rob PikeGoroutines 在同一個用戶地址空間里并行獨立執(zhí)行 functions , channels 則用于 goroutines 間的通信和同步訪問控制。
goroutine VS thread
- 內(nèi)存占用. 創(chuàng)建一個
goroutine的棧內(nèi)存消耗為2 KB(Linux AMD64Go v1.4后),運(yùn)行過程中,如果棧空間不夠用,會自動進(jìn)行擴(kuò)容。創(chuàng)建一個thread為了盡量避免極端情況下操作系統(tǒng)線程棧的溢出,默認(rèn)會為其分配一個較大的棧內(nèi)存(1 - 8 MB棧內(nèi)存,線程標(biāo)準(zhǔn)POSIX Thread),而且還需要一個被稱為“guard page”的區(qū)域用于和其他thread的棧空間進(jìn)行隔離。而棧內(nèi)存空間一旦創(chuàng)建和初始化完成之后其大小就不能再有變化,這決定了在某些特殊場景下系統(tǒng)線程棧還是有溢出的風(fēng)險。 - 創(chuàng)建/銷毀,線程創(chuàng)建和銷毀都會有巨大的消耗,是內(nèi)核級的交互(
trap)。POSIX線程(定義了創(chuàng)建和操縱線程的一套API) 通常是在已有的進(jìn)程模型中增加的邏輯擴(kuò)展,所以線程控制和進(jìn)程控制很相似。而進(jìn)入內(nèi)核調(diào)度所消耗的性能代價比較高,開銷較大。goroutine是用戶態(tài)線程,是由go runtime管理,創(chuàng)建和銷毀的消耗非常小。 - 調(diào)度切換 拋開陷入內(nèi)核,線程切換會消耗
1000-1500納秒(上下文保存成本高,較多寄存器,公平性,復(fù)雜時間計算統(tǒng)計),一個納秒平均可以執(zhí)行12-18條指令。所以由于線程切換,執(zhí)行指令的條數(shù)會減少12000-18000。goroutine的切換約為200ns(用戶態(tài)、3個寄存器),相當(dāng)于2400-3600條指令。因此,goroutines切換成本比 ?threads要小得多。 - 復(fù)雜性 線程的創(chuàng)建和退出復(fù)雜,多個
thread間通訊復(fù)雜(share memory)。不能大量創(chuàng)建線程(參考早期的httpd),成本高,使用網(wǎng)絡(luò)多路復(fù)用,存在大量callback(參考twemproxy、nginx的代碼) 。對于應(yīng)用服務(wù)線程門檻高,例如需要做第三方庫隔離,需要考慮引入線程池等。
Goroutine 運(yùn)行原理
Go 程序的執(zhí)行由兩層組成:Go Program,Runtime,即用戶程序和運(yùn)行時。它們之間通過函數(shù)調(diào)用來實現(xiàn)內(nèi)存管理、channel 通信、goroutines 創(chuàng)建等功能。用戶程序進(jìn)行的系統(tǒng)調(diào)用都會被 Runtime 攔截,以此來幫助它進(jìn)行調(diào)度以及垃圾回收相關(guān)的工作。
M:N 模型
Go runtime 會負(fù)責(zé) goroutine 的生老病死,從創(chuàng)建到銷毀,都一手包辦。Runtime 會在程序啟動的時候。Go 創(chuàng)建 M 個線程(CPU 執(zhí)行調(diào)度的單元,內(nèi)核的 task_struct),之后創(chuàng)建的 N 個 goroutine 都會依附在這 M 個線程上執(zhí)行,即 M:N 模型。它們能夠同時運(yùn)行,與線程類似,但相比之下非常輕量。因此,程序運(yùn)行時,Goroutines的個數(shù)應(yīng)該是遠(yuǎn)大于線程的個數(shù)的(phread 是內(nèi)核線程?)。
同一個時刻,一個線程只能跑一個 goroutine。當(dāng) goroutine 發(fā)生阻塞 (chan阻塞、mutex、syscall 等等) 時,Go 會把當(dāng)前的 goroutine 調(diào)度走,讓其他 goroutine 來繼續(xù)執(zhí)行,而不是讓線程阻塞休眠,盡可能多的分發(fā)任務(wù)出去,讓 CPU 忙。
GM 調(diào)度模型
go 在1.2版本之前,調(diào)度模型使用的是 GM 調(diào)度模型。
G
goroutine 的縮寫,每次 go func() 都代表一個 G,無限制。使用 struct runtime.g,包含了當(dāng)前 goroutine 的狀態(tài)、堆棧、上下文。
M
工作線程(OS thread)也被稱為 Machine,使用 struct runtime.m,所有 M 是有線程棧的。如果不對該線程棧提供內(nèi)存的話,系統(tǒng)會給該線程棧提供內(nèi)存(不同操作系統(tǒng)提供的線程棧大小不同)
。當(dāng)指定了線程棧,則 M.stack→G.stack,M 的 PC 寄存器指向 G 提供的函數(shù),然后去執(zhí)行。
GM 調(diào)度
Go 1.2前的調(diào)度器實現(xiàn),限制了 Go 并發(fā)程序的伸縮性,尤其是對那些有高吞吐或并行計算需求的服務(wù)程序。每個 goroutine 對應(yīng)于 runtime 中的一個抽象結(jié)構(gòu):G,而 thread 作為“物理 CPU”的存在而被抽象為一個結(jié)構(gòu):M(machine)。當(dāng) goroutine 調(diào)用了一個阻塞的系統(tǒng)調(diào)用,運(yùn)行這個 goroutine 的線程就會被阻塞,這時至少應(yīng)該再創(chuàng)建/喚醒一個線程來運(yùn)行別的沒有阻塞的 goroutine 。線程這里可以創(chuàng)建不止一個,可以按需不斷地創(chuàng)建,而活躍的線程(處于非阻塞狀態(tài)的線程)的最大個數(shù)存儲在變量 GOMAXPROCS 中。
調(diào)用過程如下所示:
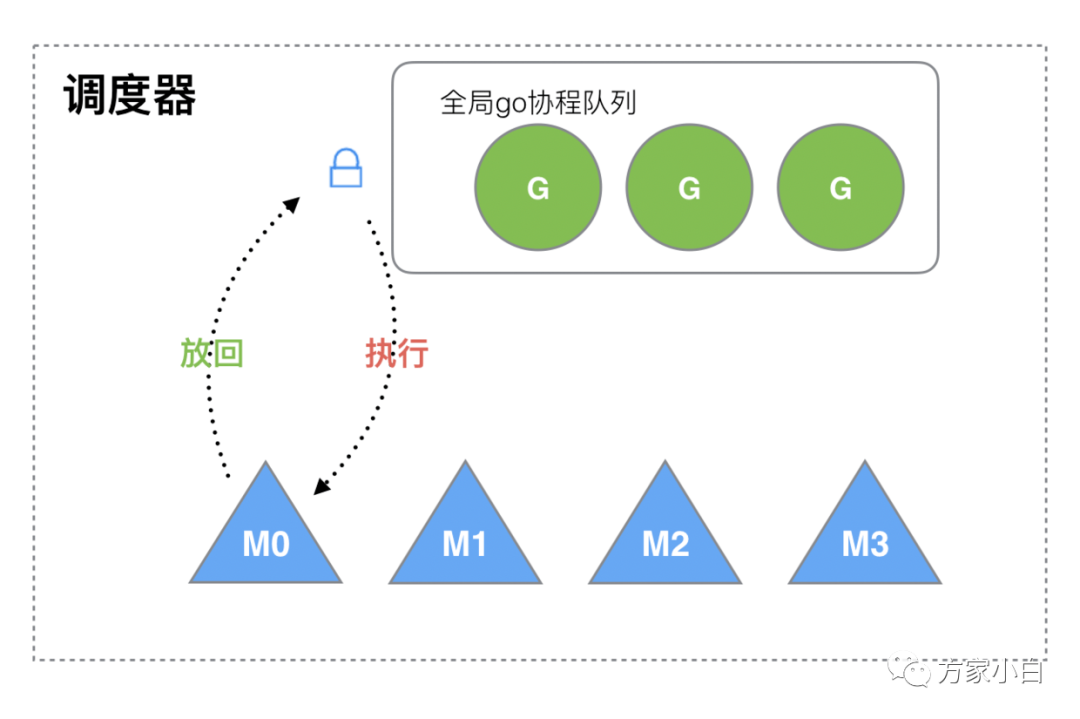
M 想要執(zhí)行、放回 G 都必須訪問全局 G 隊列,并且 M 有多個,即多線程訪問同一資源需要加鎖進(jìn)行保證互斥 / 同步,所以全局 G 隊列是有互斥鎖進(jìn)行保護(hù)的
GM 調(diào)度模型的問題
- 單一全局互斥鎖(
Sched.Lock)和集中狀態(tài)存儲 導(dǎo)致所有goroutine相關(guān)操作,比如:創(chuàng)建、結(jié)束、重新調(diào)度等都要上鎖。 Goroutine傳遞問題M經(jīng)常在M之間傳遞”可運(yùn)行”的goroutine,這導(dǎo)致調(diào)度延遲增大以及額外的性能損耗(剛創(chuàng)建的G放到了全局隊列,而不是本地 M 執(zhí)行,不必要的開銷和延遲)。Per-M持有內(nèi)存緩存 (M.mcache) 每個M持有mcache和stackalloc,然而只有在M運(yùn)行Go代碼時才需要使用的內(nèi)存(每個mcache可以高達(dá)2mb),當(dāng)M在處于syscall時并不需要。運(yùn)行Go代碼和阻塞在syscall的M的比例高達(dá)1:100,造成了很大的浪費。同時內(nèi)存親緣性也較差,G當(dāng)前在M運(yùn)行后對 M 的內(nèi)存進(jìn)行了預(yù)熱,因為現(xiàn)在G調(diào)度到同一個M的概率不高,數(shù)據(jù)局部性不好。- 嚴(yán)重的線程阻塞/解鎖
在系統(tǒng)調(diào)用的情況下,工作線程經(jīng)常被阻塞和取消阻塞,這增加了很多開銷。比如
M找不到G,此時M就會進(jìn)入頻繁阻塞/喚醒來進(jìn)行檢查的邏輯,以便及時發(fā)現(xiàn)新的G來執(zhí)行。by Dmitry Vyukov “Scalable Go Scheduler Design Doc”
GMP 調(diào)度模型
在 go 1.2 版本及以后,go 引入 GMP 調(diào)度模型
G
goroutine 的縮寫,每次 go func() 都代表一個 G,無限制。使用 struct runtime.g,包含了當(dāng)前 goroutine 的狀態(tài)、堆棧、上下文。
M
工作線程(OS thread)也被稱為 Machine,使用 struct runtime.m,所有 M 是有線程棧的。如果不對該線程棧提供內(nèi)存的話,系統(tǒng)會給該線程棧提供內(nèi)存(不同操作系統(tǒng)提供的線程棧大小不同)
。當(dāng)指定了線程棧,則 M.stack→G.stack,M 的 PC 寄存器指向 G 提供的函數(shù),然后去執(zhí)行。
P
“Processor”是一個抽象的概念,并不是真正的物理 CPU。
Dmitry Vyukov 的方案是引入一個結(jié)構(gòu) P,它代表了 M 所需的上下文環(huán)境,也是處理用戶級代碼邏輯的處理器。它負(fù)責(zé)銜接 M 和 G 的調(diào)度上下文,將等待執(zhí)行的 G 與 M 對接。當(dāng) P 有任務(wù)時需要創(chuàng)建或者喚醒一個 M 來執(zhí)行它隊列里的任務(wù)。所以 P/M 需要進(jìn)行綁定,構(gòu)成一個執(zhí)行單元。P 決定了并行任務(wù)的數(shù)量,可通過 runtime.GOMAXPROCS 來設(shè)定。在 Go1.5 之后 GOMAXPROCS 被默認(rèn)設(shè)置可用的核數(shù),而之前則默認(rèn)為1。
Runtime 起始時會啟動一些 G:垃圾回收的 G,執(zhí)行調(diào)度的 G,運(yùn)行用戶代碼的 G;并且會創(chuàng)建一個 M 用來開始 G 的運(yùn)行。隨著時間的推移,更多的 G 會被創(chuàng)建出來,更多的 M 也會被創(chuàng)建出來。
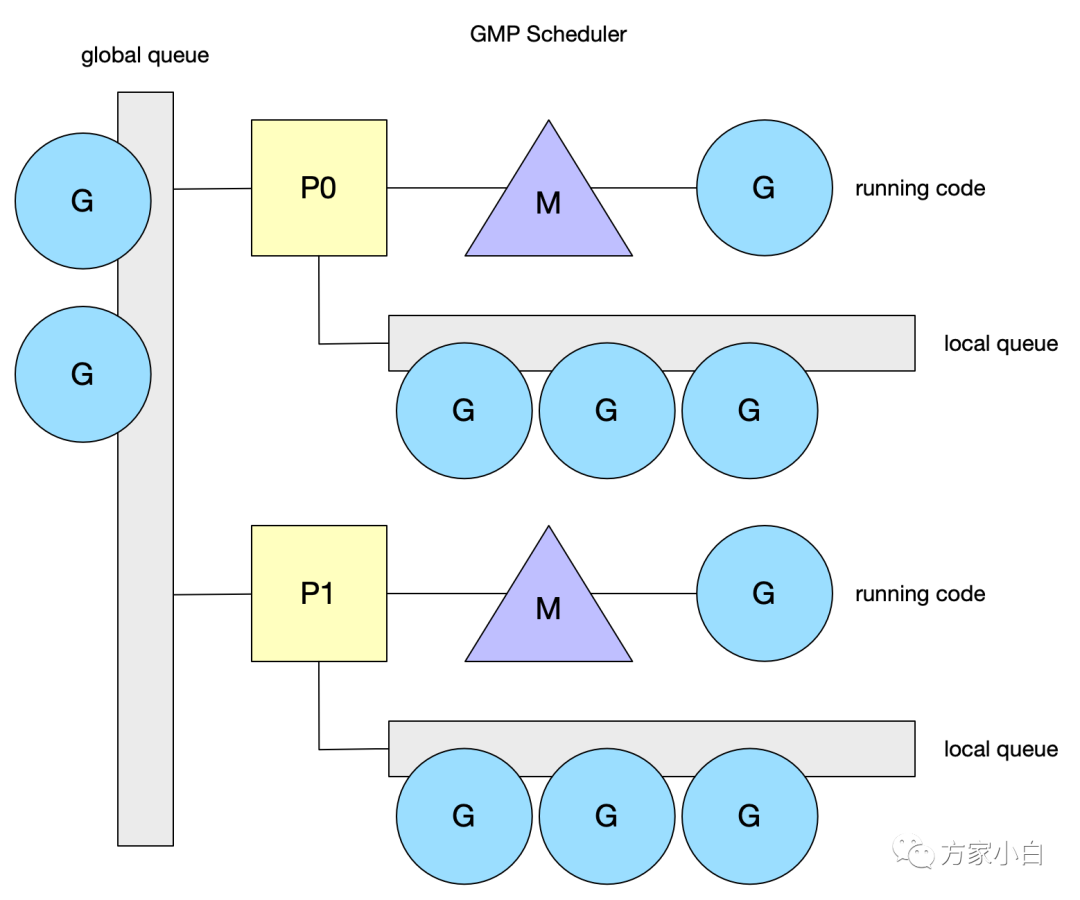
Tips: https://github.com/uber-go/automaxprocsAutomatically set GOMAXPROCS to match Linux container CPU quota.mcache/stackalloc 從 M 移到了 P,而 G 隊列也被分成兩類,保留全局 G 隊列,同時每個 P 中都會有一個本地的 G 隊列。
GMP 調(diào)度
GMP調(diào)度模型, 引入了 local queue,因為 P 的存在,runtime 并不需要做一個集中式的 goroutine 調(diào)度,每一個 M 都會在 P's local queue、global queue 或者其他 P 隊列中找 G 執(zhí)行,減少全局鎖對性能的影響。這也是 GMP Work-stealing 調(diào)度算法的核心。注意 P 的本地 G 隊列還是可能面臨一個并發(fā)訪問的場景,為了避免加鎖,這里 P 的本地隊列是一個 LockFree的隊列,竊取 G 時使用 CAS 原子操作來完成。關(guān)于LockFree 和 CAS 的知識參見 Lock-Free。
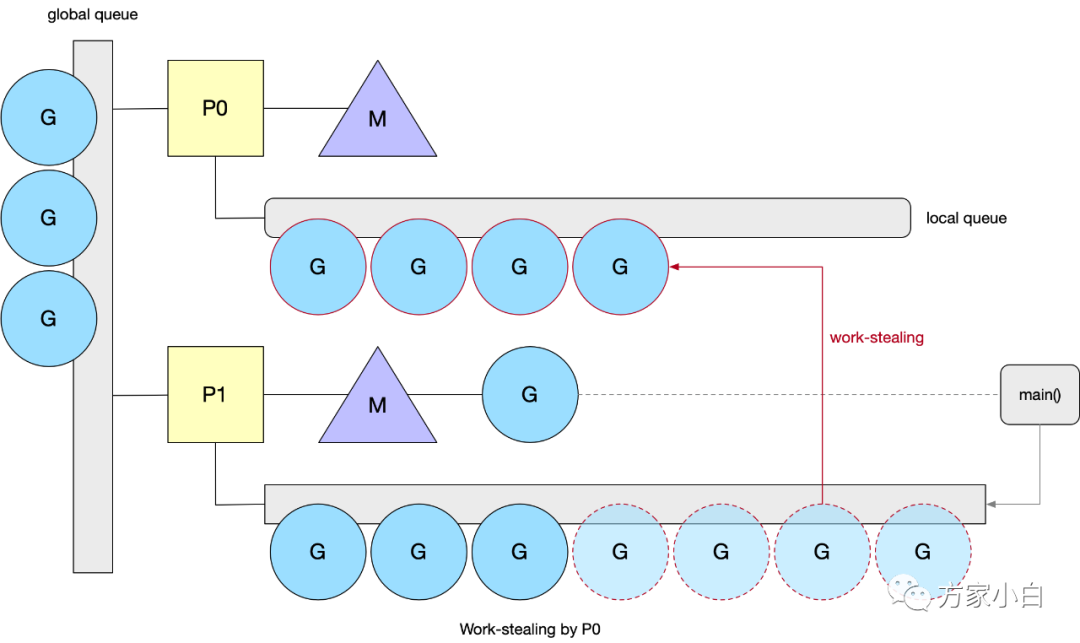
Work Stealing
當(dāng)一個 P 執(zhí)行完本地所有的 G 之后,并且全局隊列為空的時候,會嘗試挑選一個受害者 P ,從它的 G 隊列中竊取一半的 G。否則會從全局隊列中獲取(當(dāng)前個數(shù)/GOMAXPROCS)個 G 。為了保證公平性,從隨機(jī)位置上的 P 開始,而且遍歷的順序也隨機(jī)化了(選擇一個小于 GOMAXPROCS ,且和它互為質(zhì)數(shù)的步長),保證遍歷的順序也隨機(jī)化了。
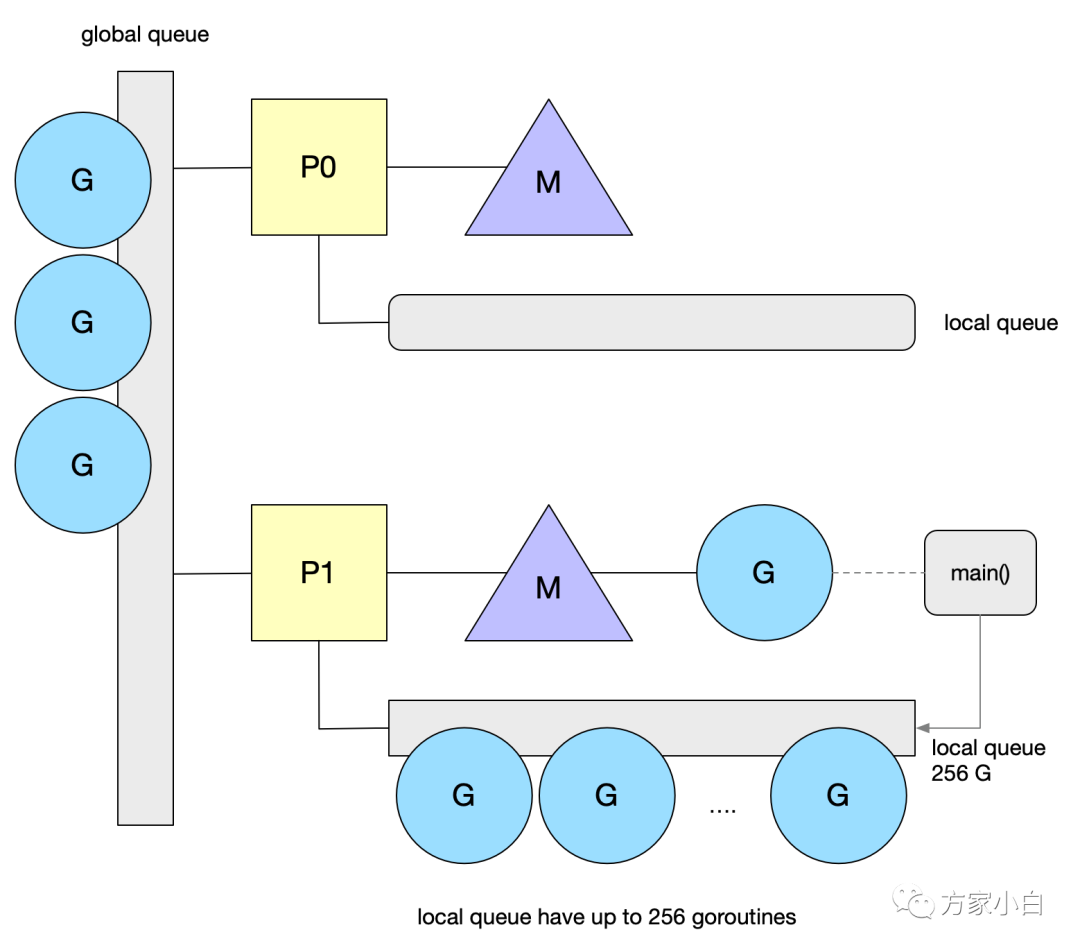
光竊取失敗時獲取是不夠的,可能會導(dǎo)致全局隊列饑餓。P 的調(diào)度算法中還會每個 N 輪調(diào)度之后就去全局隊列拿一個 G。如下圖。

誰放入的全局隊列呢
有兩種情況會把G放到全局隊列中。
- 新建
G時P的本地G隊列放不下已滿并達(dá)到256個的時候會放半數(shù)G到全局隊列去。 - 阻塞的系統(tǒng)調(diào)用返回時找不到空閑
P也會放到全局隊列。
SysCall 系統(tǒng)調(diào)用
當(dāng) G 調(diào)用 syscall 后會解綁 P,然后 M 和 G 進(jìn)入阻塞,而 P 此時的狀態(tài)就是 syscall,表明這個 P 的 G 正在 syscall 中,這時的 P 是不能被調(diào)度給別的 M 的。如果在短時間內(nèi)阻塞的 M 就喚醒了,那么 M 會優(yōu)先來重新獲取這個 P,能獲取到就繼續(xù)綁回去,這樣有利于數(shù)據(jù)的局部性。系統(tǒng)監(jiān)視器 (system monitor),稱為 sysmon,會定時掃描。在執(zhí)行 syscall 時, 如果某個 P 的 G 執(zhí)行超過一個 sysmon tick(10ms),就會把他設(shè)為 idle,重新調(diào)度給需要的 M,強(qiáng)制解綁。
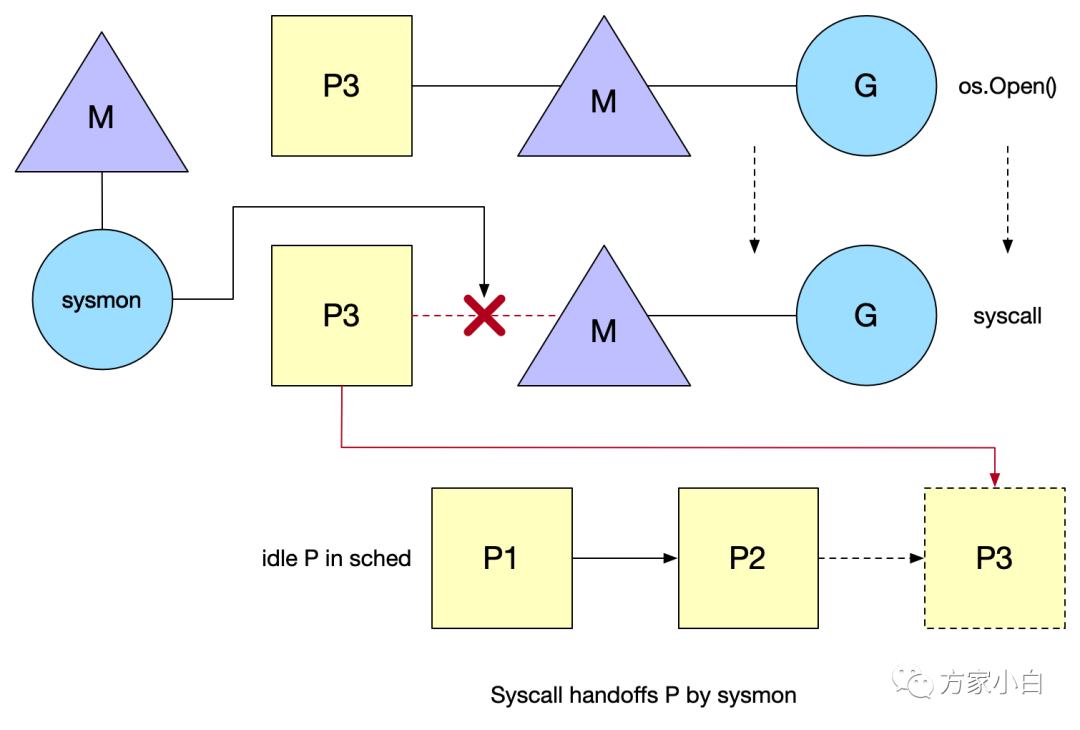
P3 和 M 脫離后目前在 idle list 中等待被綁定(處于 syscall 狀態(tài))。而 syscall 結(jié)束后 M 按照如下規(guī)則執(zhí)行直到滿足其中一個條件:
- 嘗試獲取同一個
P(P3),恢復(fù)執(zhí)行G - 嘗試獲取
idle list中的其他空閑P,恢復(fù)執(zhí)行G - 找不到空閑
P,把G放回global queue,M放回到idle list
再舉一個例子:如下圖.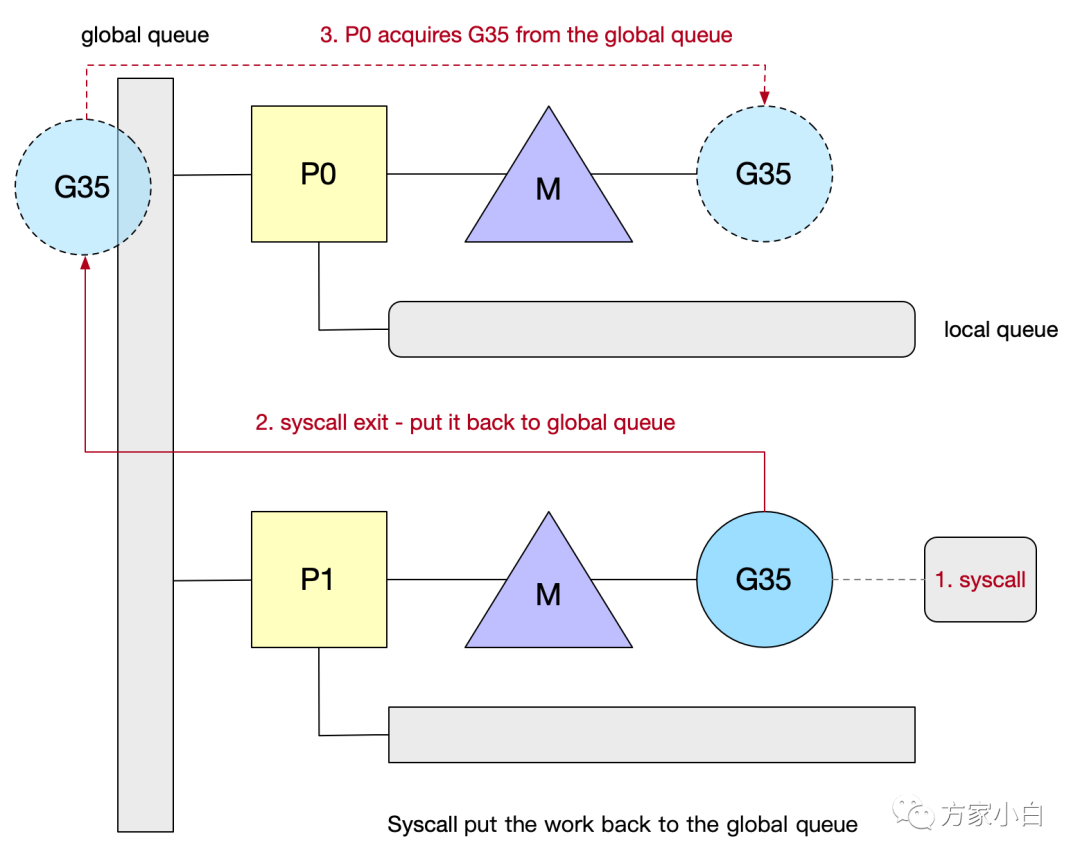
- 第一步:
G35發(fā)生了系統(tǒng)調(diào)用,長時間沒有返回。P1和M解綁。(p1不會馬上被推送到idle list, 而是經(jīng)過一段時間才會推送到idle list.) - 第二步:
G35系統(tǒng)調(diào)用完成,將G35推向了全局隊列. - 第三步:
G35被其他的P撈到了(可能P0經(jīng)過1/61輪次正好check全局隊列), 這樣G35就可以繼續(xù)執(zhí)行了。
需要注意的是:當(dāng)使用了 Syscall,Go 無法限制 Blocked OS threads 的數(shù)量:The GOMAXPROCS variable limits the number of operating system threads that can execute user-level Go code simultaneously. There is no limit to the number of threads that can be blocked in system calls on behalf of Go code; those do not count against the GOMAXPROCS limit. This package’s GOMAXPROCS function queries and changes the limit.
Tips: 使用 syscall 寫程序要認(rèn)真考慮 pthread exhaust 問題。
Spining Thread.
線程自旋是相對于線程阻塞而言的,表象就是循環(huán)執(zhí)行一個指定邏輯(調(diào)度邏輯,目的是不停地尋找 G)。這樣做的問題顯而易見,如果 G 遲遲不來,CPU 會白白浪費在這無意義的計算上。但好處也很明顯,降低了 M 的上下文切換成本,提高了性能。在兩個地方引入自旋:
- 類型1:
M不帶P的找P掛載(一有P釋放就結(jié)合) - 類型2:
M帶P的找G運(yùn)行(一有runable的G就執(zhí)行)。這種情況下會首先 按照1/61輪次的查詢global Queue, 然后再查看local Queue是否有G. 如果沒有,則去查看Global Queue, 如果沒有再去檢查 ?net poller, 看看是否有可用的goroutine. 為了避免過多浪費CPU資源,自旋的M最多只允許GOMAXPROCS(Busy P)。同時當(dāng)有類型1的自旋M存在時,類型2的自旋M就不阻塞,阻塞會釋放P,一釋放P就馬上被類型1的自旋M搶走了,沒必要。
在新 G 被創(chuàng)建、M 進(jìn)入系統(tǒng)調(diào)用、M 從空閑被激活這三種狀態(tài)變化前,調(diào)度器會確保至少有一個自旋 M 存在(喚醒或者創(chuàng)建一個 M),除非沒有空閑的 P。
為什么呢?
- 當(dāng)新
G創(chuàng)建,如果有可用P,就意味著新G可以被立即執(zhí)行,即便不在同一個P也無妨,所以我們保留一個自旋的 M(這時應(yīng)該不存在類型1的自旋只有類型2的自旋)就可以保證新 G 很快被運(yùn)行。 - 當(dāng)
M進(jìn)入系統(tǒng)調(diào)用,意味著M不知道何時可以醒來,那么M對應(yīng)的P中剩下的G就得有新的M來執(zhí)行,所以我們保留一個自旋的M來執(zhí)行剩下的G(這時應(yīng)該不存在類型2的自旋只有類型1的自旋)。 - 如果
M從空閑變成活躍,意味著可能一個處于自旋狀態(tài)的M進(jìn)入工作狀態(tài)了,這時要檢查并確保還有一個自旋M存在,以防還有G或者還有P空著的。
GMP 模型問題總結(jié)
- 單一全局互斥鎖(
Sched.Lock)和集中狀態(tài)存儲G被分成全局隊列和P的本地隊列,全局隊列依舊是全局鎖,但是使用場景明顯很少,P本地隊列使用無鎖隊列,使用原子操作來面對可能的并發(fā)場景。 Goroutine傳遞問題G創(chuàng)建時就在P的本地隊列,可以避免在G之間傳遞(竊取除外),G對P的數(shù)據(jù)局部性好; 當(dāng)G開始執(zhí)行了,系統(tǒng)調(diào)用返回后M會嘗試獲取可用P,獲取到了的話可以避免在M之間傳遞。而且優(yōu)先獲取調(diào)用阻塞前的P,所以G對M數(shù)據(jù)局部性好,G對P的數(shù)據(jù)局部性也好。Per-M持有內(nèi)存緩存 (M.mcache) 內(nèi)存mcache只存在P結(jié)構(gòu)中,P最多只有GOMAXPROCS個,遠(yuǎn)小于M的個數(shù),所以內(nèi)存沒有過多的消耗。- 嚴(yán)重的線程阻塞/解鎖
通過引入自旋,保證任何時候都有處于等待狀態(tài)的自旋 M,避免在等待可用的
P和G時頻繁的阻塞和喚醒。
syscon
sysmon 也叫監(jiān)控線程,它無需 P 也可以運(yùn)行,他是一個死循環(huán),每20us~10ms循環(huán)一次,循環(huán)完一次就 sleep 一會,為什么會是一個變動的周期呢,主要是避免空轉(zhuǎn),如果每次循環(huán)都沒什么需要做的事,那么 sleep 的時間就會加大。
- 釋放閑置超過
5分鐘的span物理內(nèi)存; - 如果超過2分鐘沒有垃圾回收,強(qiáng)制執(zhí)行;
- 將長時間未處理的
netpoll添加到全局隊列; - 向長時間運(yùn)行的
G任務(wù)發(fā)出搶占調(diào)度; - 收回因
syscall長時間阻塞的P;
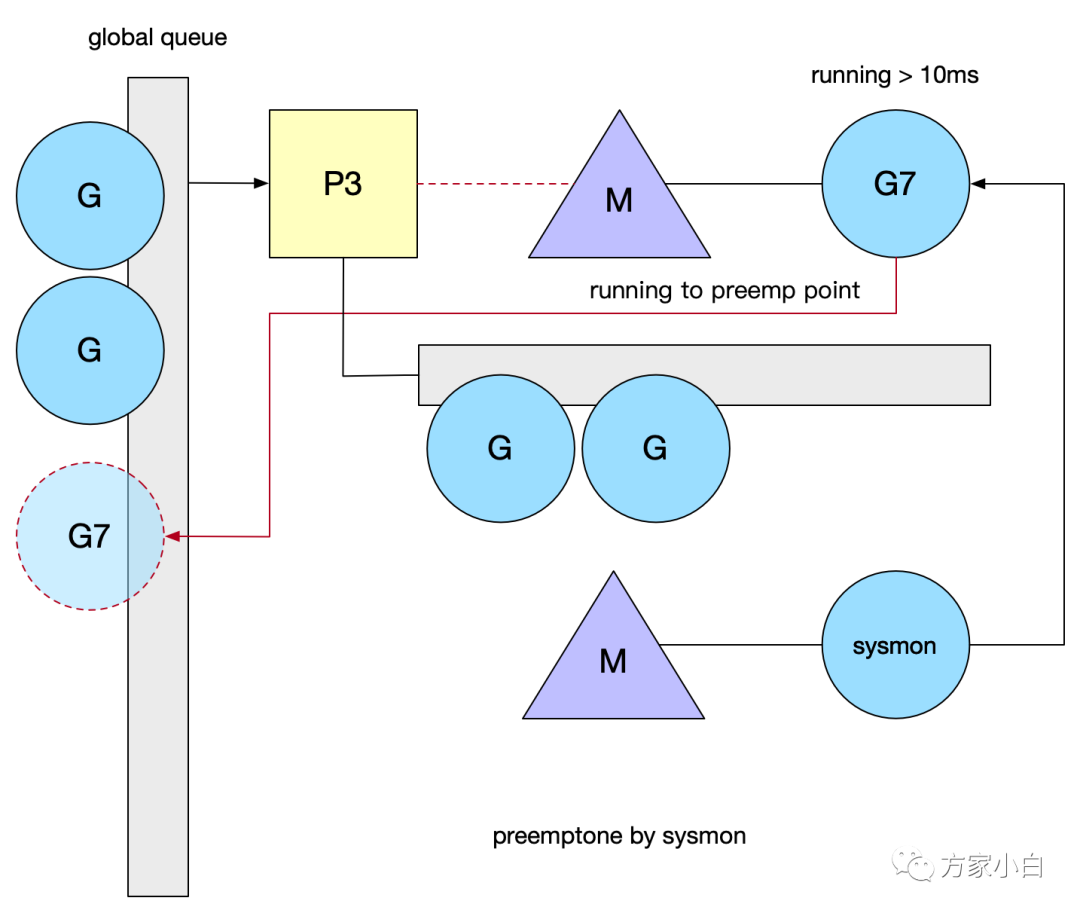
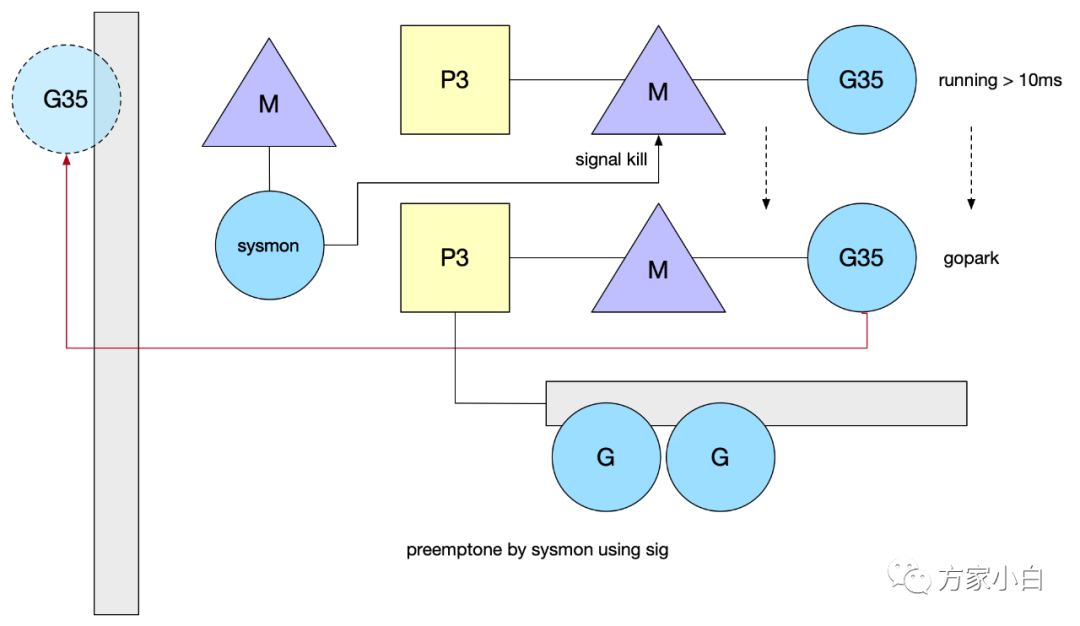
當(dāng) P 在 M 上執(zhí)行時間超過10ms,sysmon 調(diào)用 preemptone 將 G 標(biāo)記為 stackPreempt 。因此需要在某個地方觸發(fā)檢測邏輯,Go 當(dāng)前是在檢查棧是否溢出的地方判定(morestack()),M 會保存當(dāng)前 G 的上下文,重新進(jìn)入調(diào)度邏輯, 這樣就不會死循環(huán)了。死循環(huán):issues/11462信號搶占:go1.14基于信號的搶占式調(diào)度實現(xiàn)原理異步搶占,注冊 sigurg 信號,通過 sysmon 檢測,對 M 對應(yīng)的線程發(fā)送信號,觸發(fā)注冊的 handler,它往當(dāng)前 G 的 PC 中插入一條指令(調(diào)用某個方法),在處理完 handler,G 恢復(fù)后,自己把自己推到了 global queue 中。
Network poller
Go 所有的 I/O 都是阻塞的。然后通過 goroutine + channel 來處理并發(fā)。因此所有的 IO 邏輯都是直來直去的,你不再需要回調(diào),不再需要 future,要的僅僅是 step by step。這對于代碼的可讀性是很有幫助的。G 發(fā)起網(wǎng)絡(luò) I/O 操作也不會導(dǎo)致 M 被阻塞(僅阻塞G),從而不會導(dǎo)致大量 M 被創(chuàng)建出來。將異步 I/O 轉(zhuǎn)換為阻塞 I/O 的部分稱為 netpoller。打開或接受連接都被設(shè)置為非阻塞模式。如果你試圖對其進(jìn)行 I/O 操作,并且文件描述符數(shù)據(jù)還沒有準(zhǔn)備好,G 會進(jìn)入 gopark 函數(shù),將當(dāng)前正在執(zhí)行的 G 狀態(tài)保存起來,然后切換到新的堆棧上執(zhí)行新的 G。
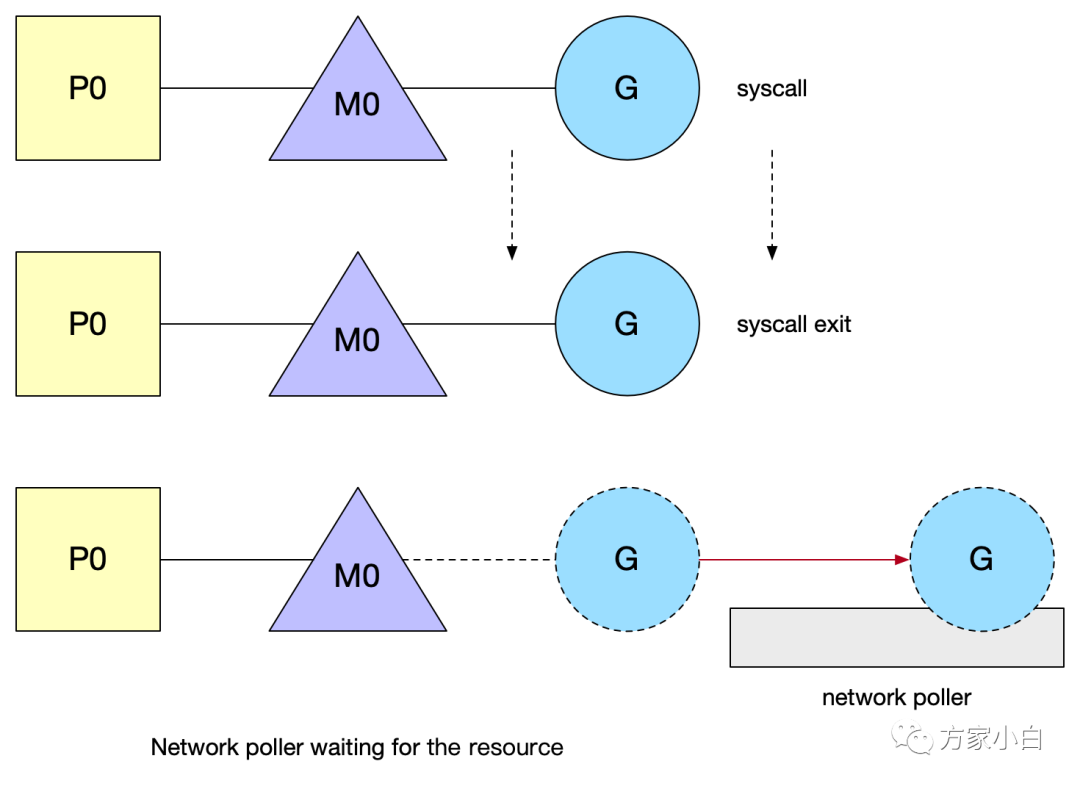
那什么時候 G 被調(diào)度回來呢?
sysmonschedule():M找G的調(diào)度函數(shù)GC:start the world調(diào)用netpoll()在某一次調(diào)度G的過程中,處于就緒狀態(tài)的fd對應(yīng)的G就會被調(diào)度回來。G的gopark狀態(tài):G置為waiting狀態(tài),等待顯示goready喚醒,在poller中用得較多,還有鎖、chan等。
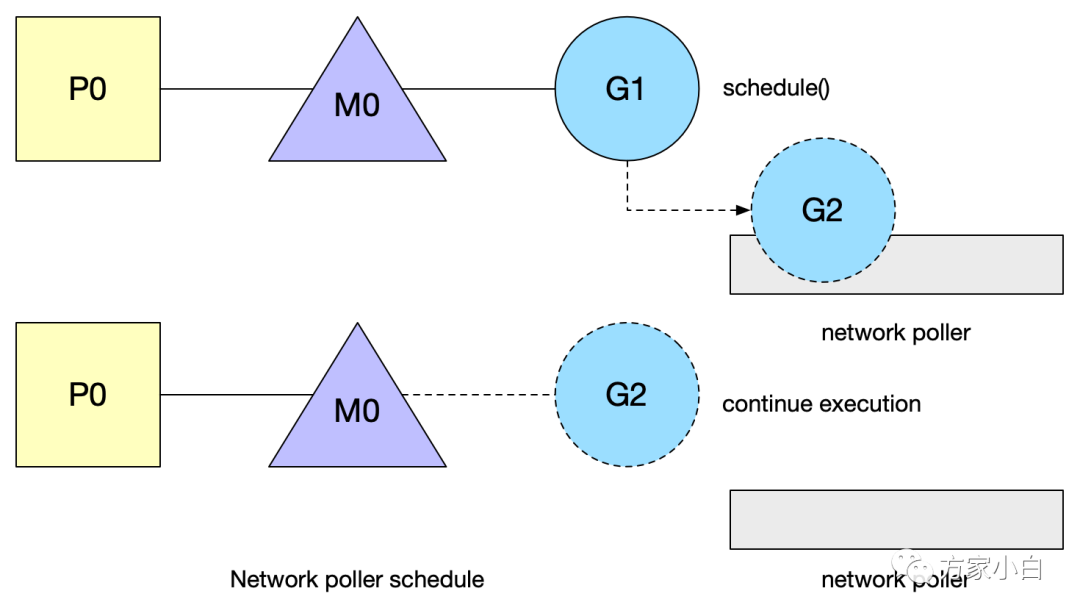
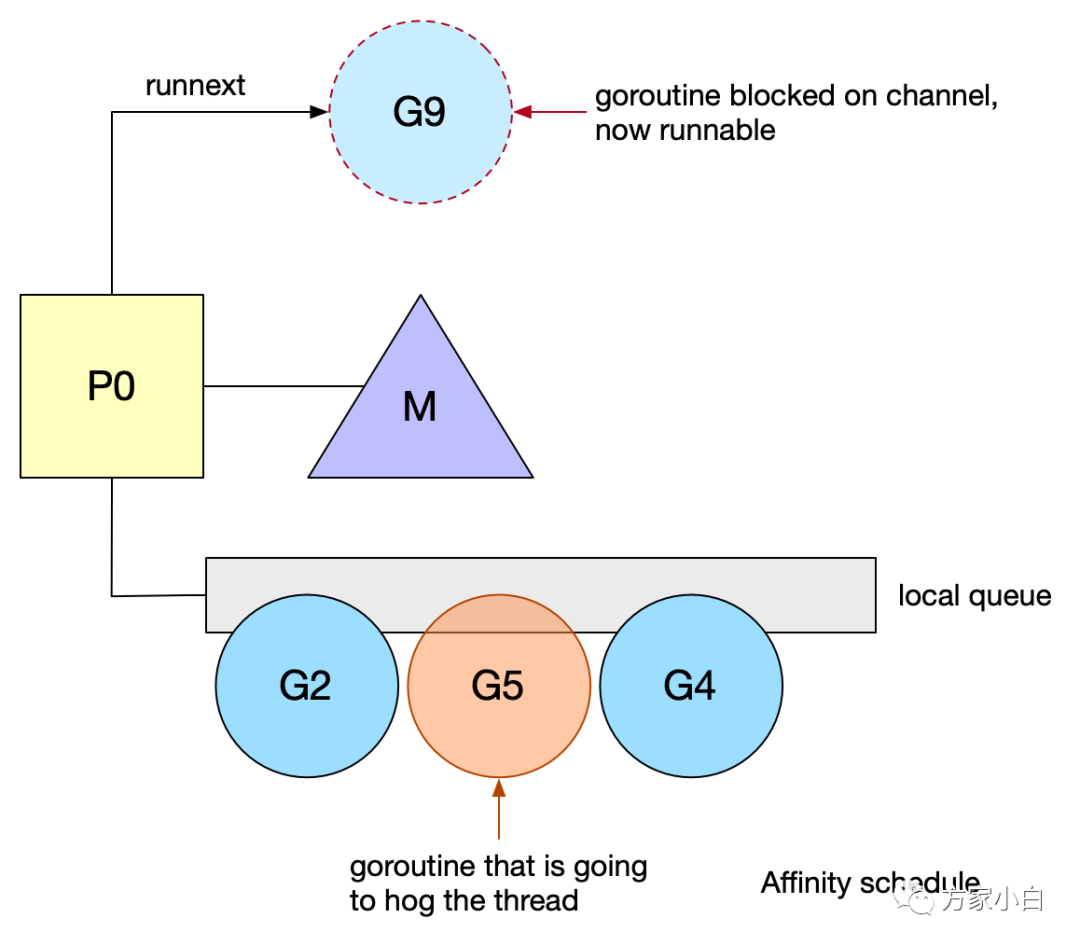
Scheduler Affinity 調(diào)度親和性
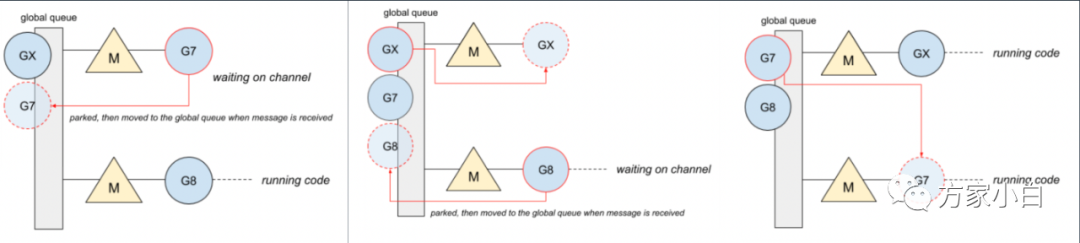
GM 調(diào)度器時代的,chan 操作導(dǎo)致的切換代價。
Goroutine#7正在等待消息,阻塞在chan。一旦收到消息,這個goroutine就被推到全局隊列。- 然后,
chan推送消息,goroutine#X將在可用線程上運(yùn)行,而goroutine#8將阻塞在chan。 goroutine#7現(xiàn)在在可用線程上運(yùn)行。在chan來回通信的goroutine會導(dǎo)致頻繁的blocks,即頻繁地在本地隊列中重新排隊。然而,由于本地隊列是FIFO實現(xiàn),如果另一個goroutine占用線程,unblock goroutine不能保證盡快運(yùn)行。同時Go親緣性調(diào)度的一些限制:Work-stealing、系統(tǒng)調(diào)用。goroutine #9在chan被阻塞后恢復(fù)。但是,它必須等待#2、#5和#4之后才能運(yùn)行。goroutine #5將阻塞其線程,從而延遲goroutine #9,并使其面臨被另一個P竊取的風(fēng)險。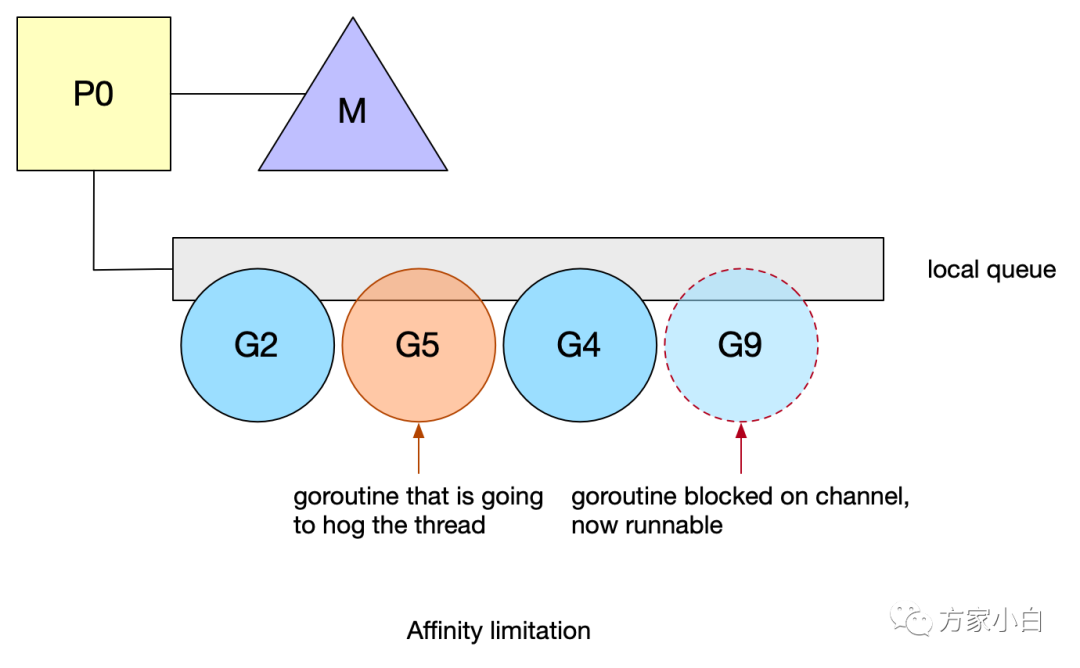
針對 communicate-and-wait 模式,進(jìn)行了親緣性調(diào)度的優(yōu)化。Go 1.5 在 P 中引入了 runnext 特殊的一個字段,可以高優(yōu)先級執(zhí)行 unblock G。goroutine #9現(xiàn)在被標(biāo)記為下一個可運(yùn)行的。這種新的優(yōu)先級排序允許 goroutine 在再次被阻塞之前快速運(yùn)行。這一變化對運(yùn)行中的標(biāo)準(zhǔn)庫產(chǎn)生了總體上的積極影響,提高了一些包的性能。
Goroutine Lifecycle
go 程序的啟動
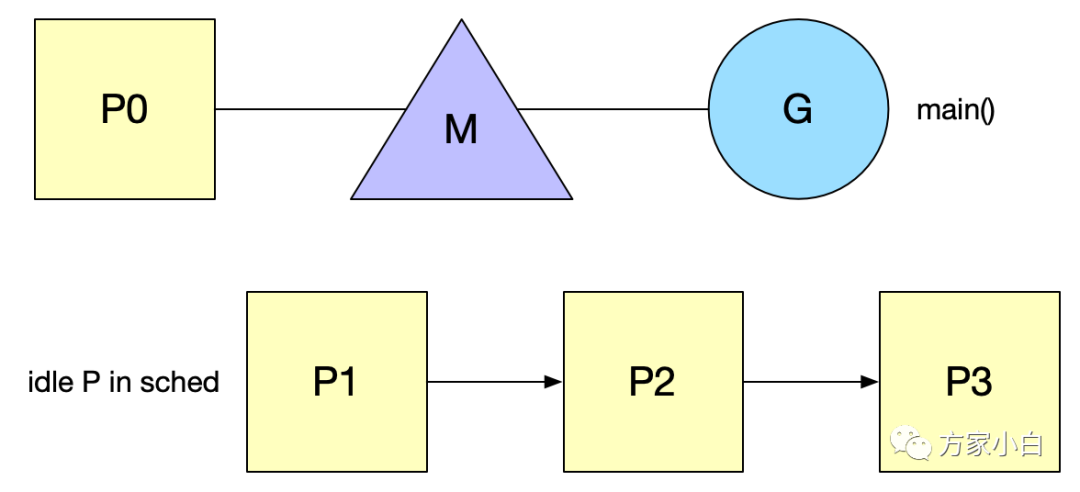
整個程序始于一段匯編,而在隨后的 runtime·rt0_go(也是匯編程序)中,會執(zhí)行很多初始化工作。

- 綁定 m0 和 g0,m0就是程序的主線程,程序啟動必然會擁有一個主線程,這個就是 m0。g0 負(fù)責(zé)調(diào)度,即 shedule() 函數(shù)。
- 創(chuàng)建 P,綁定 m0 和 p0,首先會創(chuàng)建 GOMAXPROCS 個 P ,存儲在 sched 的 空閑鏈表(pidle)。
- 新建任務(wù) g 到 p0 本地隊列,m0 的 g0 會創(chuàng)建一個 指向 runtime.main() 的 g ,并放到 p0 的本地隊列。runtime.main(): 啟動 sysmon 線程;啟動 GC 協(xié)程;執(zhí)行 init,即代碼中的各種 init 函數(shù);執(zhí)行 main.main 函數(shù)。
Os Thread 創(chuàng)建
準(zhǔn)備運(yùn)行的新 goroutine 將喚醒 P 以更好地分發(fā)工作。這個 P 將創(chuàng)建一個與之關(guān)聯(lián)的 M 綁定到一個 OS thread。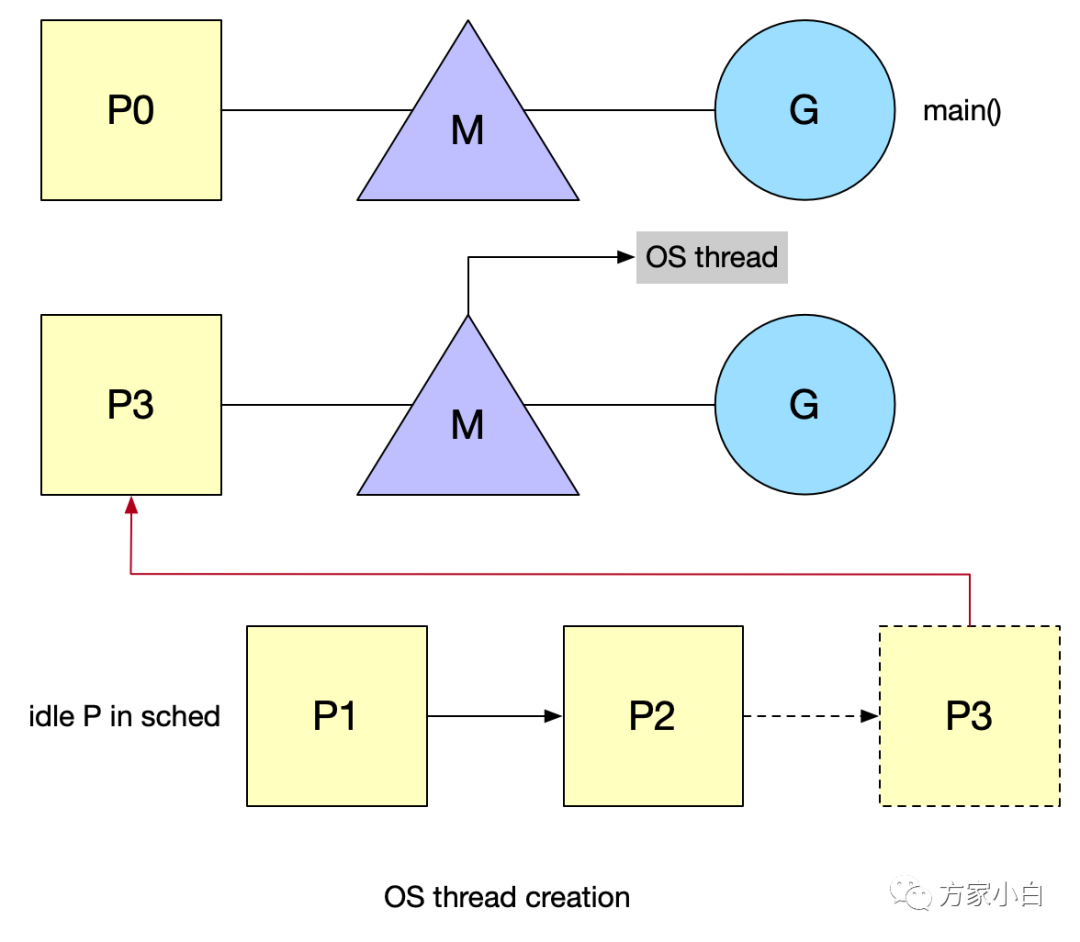
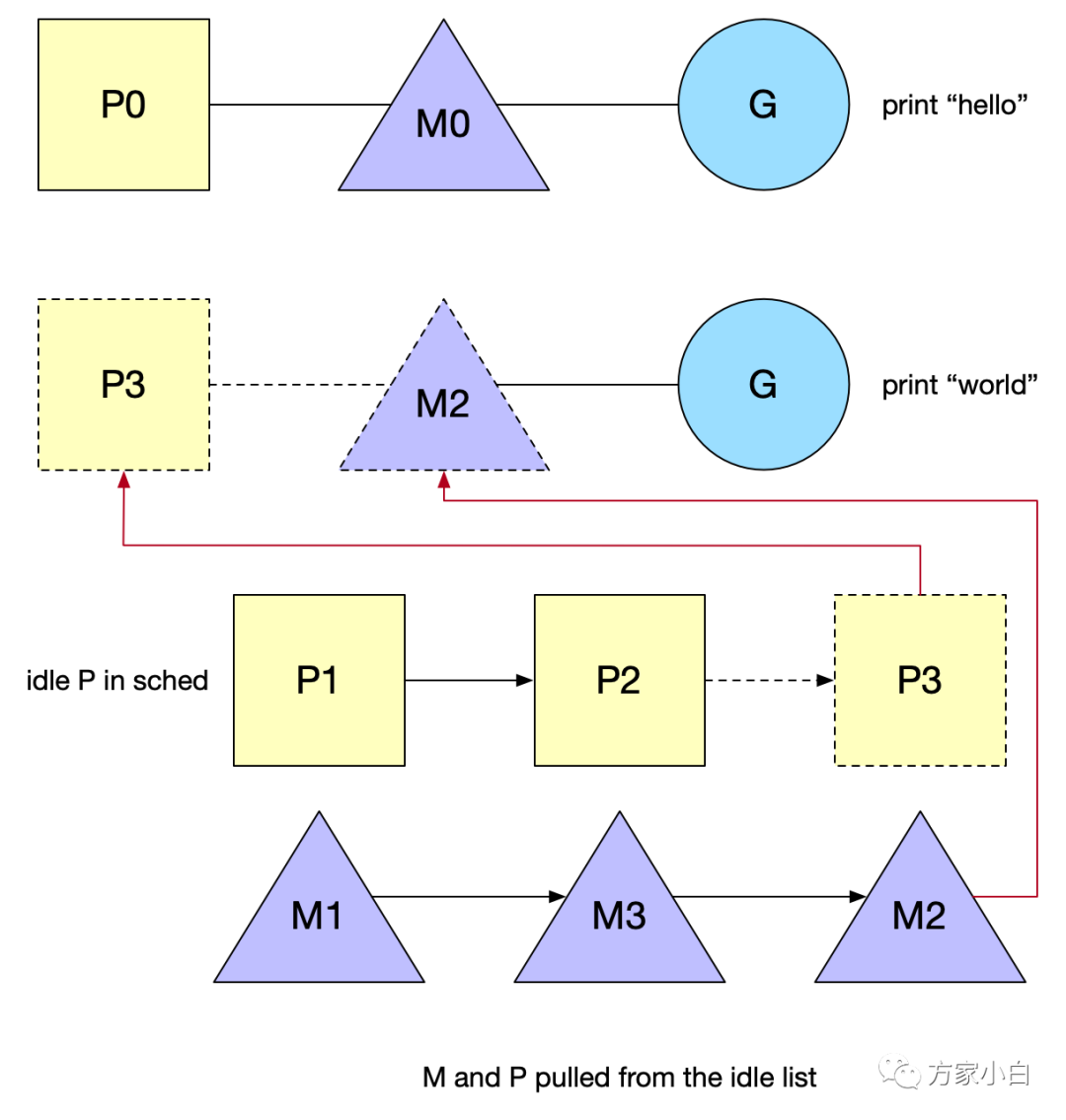
go func() 中 觸發(fā) Wakeup 喚醒機(jī)制:有空閑的 P 而沒有在 spinning 狀態(tài)的 M 時候, 需要去喚醒一個空閑(睡眠)的 M 或者新建一個。當(dāng)線程首次創(chuàng)建時,會執(zhí)行一個特殊的 G,即 g0,它負(fù)責(zé)管理和調(diào)度 G。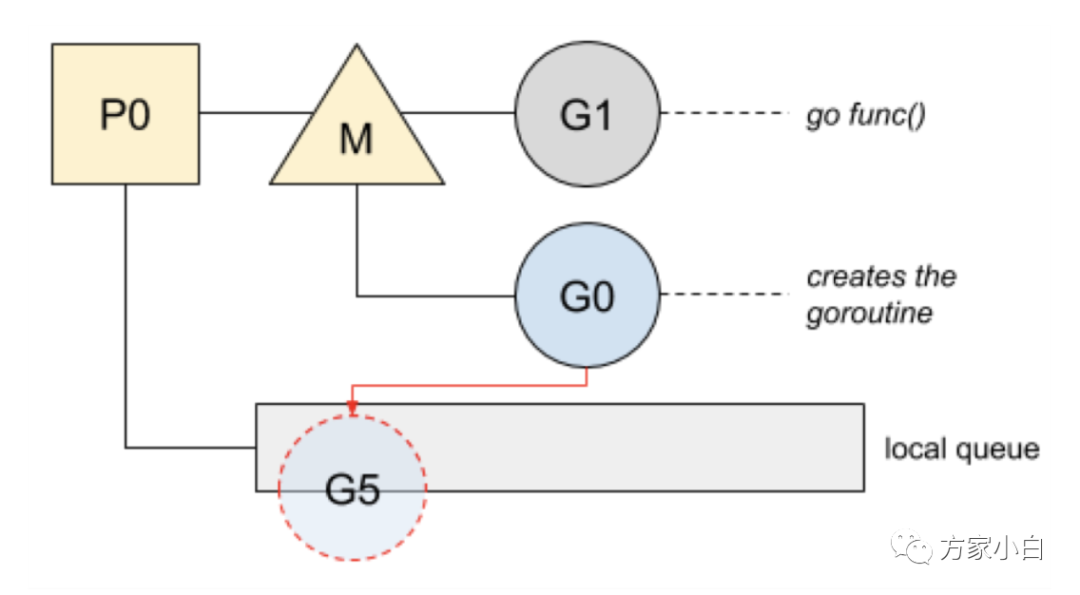
特殊的g0
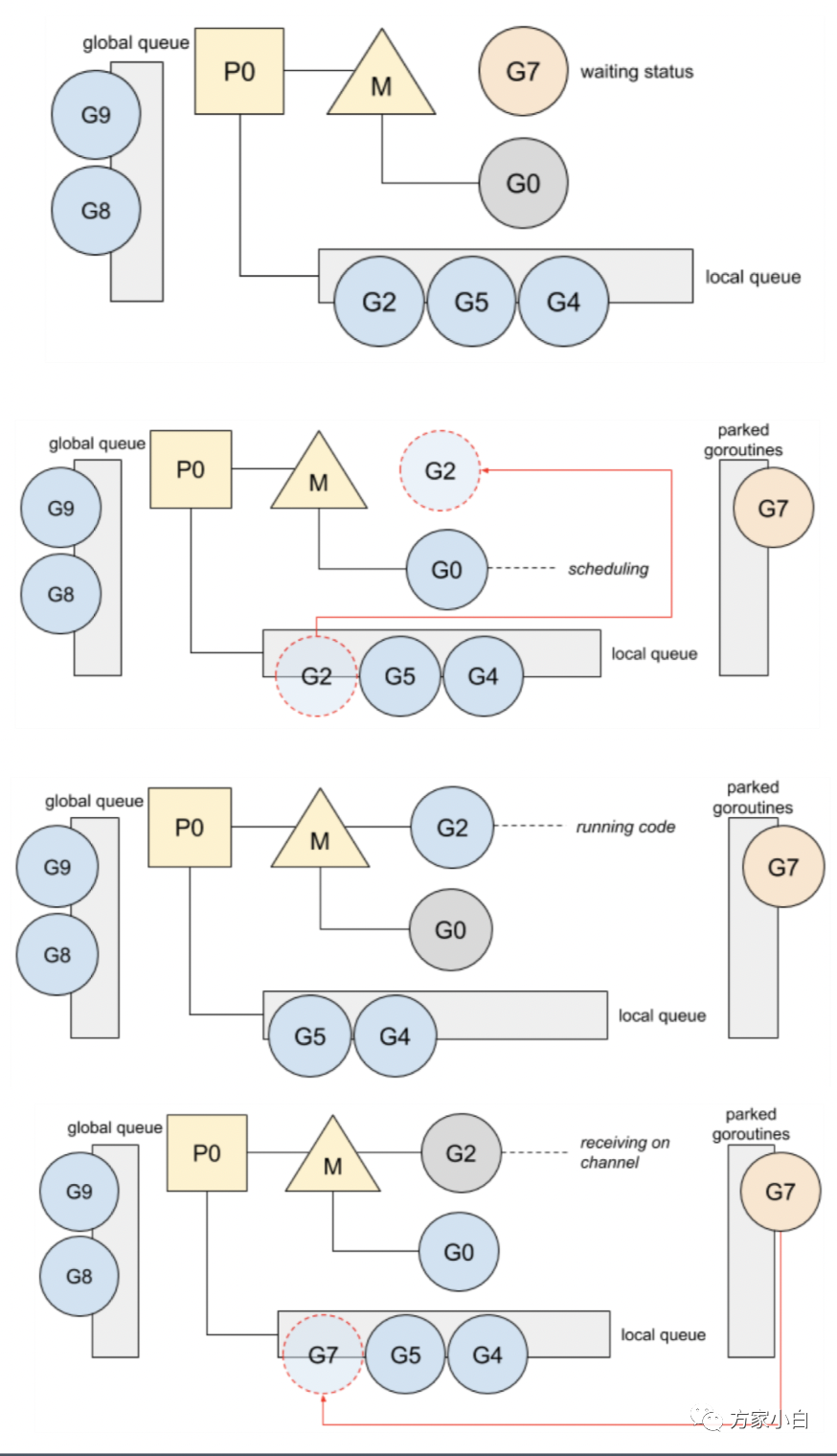
Go 基于兩種斷點將 G 調(diào)度到線程上:
- 當(dāng)
G阻塞時:系統(tǒng)調(diào)用、互斥鎖或chan。阻塞的G進(jìn)入睡眠模式/進(jìn)入隊列,并允許Go安排和運(yùn)行等待其他的G。 - 在函數(shù)調(diào)用期間,如果
G必須擴(kuò)展其堆棧。這個斷點允許Go調(diào)度另一個G并避免運(yùn)行G占用CPU。在這兩種情況下,運(yùn)行調(diào)度程序的g0將當(dāng)前G替換為另一個G,即ready to run。然后,選擇的G替換g0并在線程上運(yùn)行。與常規(guī)G相反,g0有一個固定和更大的棧。 Defer函數(shù)的分配GC收集,比如STW、掃描G的堆棧和標(biāo)記、清除操作- 棧擴(kuò)容,當(dāng)需要的時候,由
g0進(jìn)行擴(kuò)棧操作
Schedule
在 Go 中,G 的切換相當(dāng)輕便,其中需要保存的狀態(tài)僅僅涉及以下兩個:
Goroutine在停止運(yùn)行前執(zhí)行的指令,程序當(dāng)前要運(yùn)行的指令是記錄在程序計數(shù)器(PC)中的,G稍后將在同一指令處恢復(fù)運(yùn)行;G的堆棧,以便在再次運(yùn)行時還原局部變量;在切換之前,堆棧將被保存,以便在G再次運(yùn)行時進(jìn)行恢復(fù):
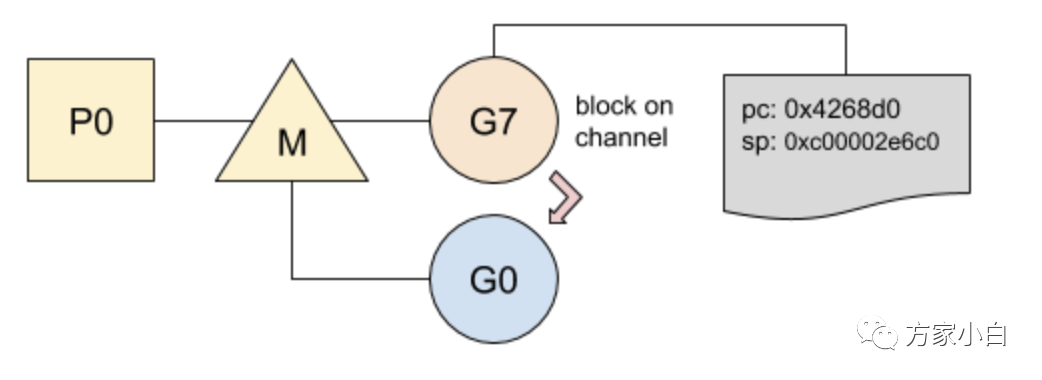
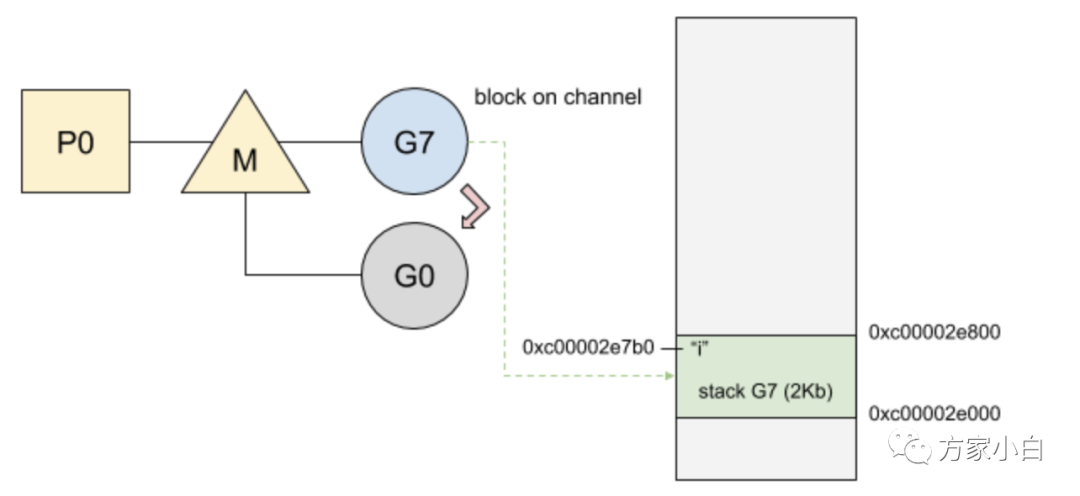
從 g 到 g0 或從 g0 到 g 的切換是相當(dāng)迅速的,它們只包含少量固定的指令(9-10ns)。相反,對于調(diào)度階段,調(diào)度程序需要檢查許多資源以便確定下一個要運(yùn)行的 G。當(dāng)前 g 阻塞在 chan 上并切換到 g0:
- 1、PC 和堆棧指針一起保存在內(nèi)部結(jié)構(gòu)中;
- 2、將 g0 設(shè)置為正在運(yùn)行的 goroutine;
- 3、g0 的堆棧替換當(dāng)前堆棧;
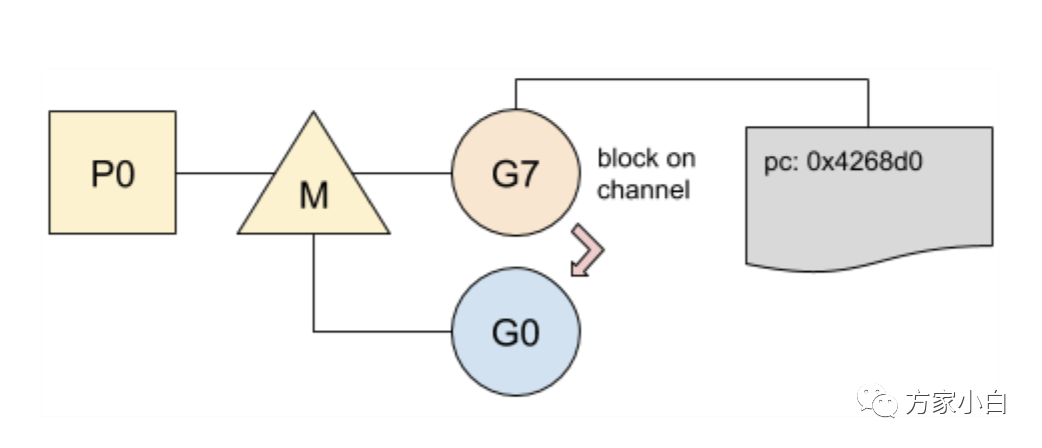
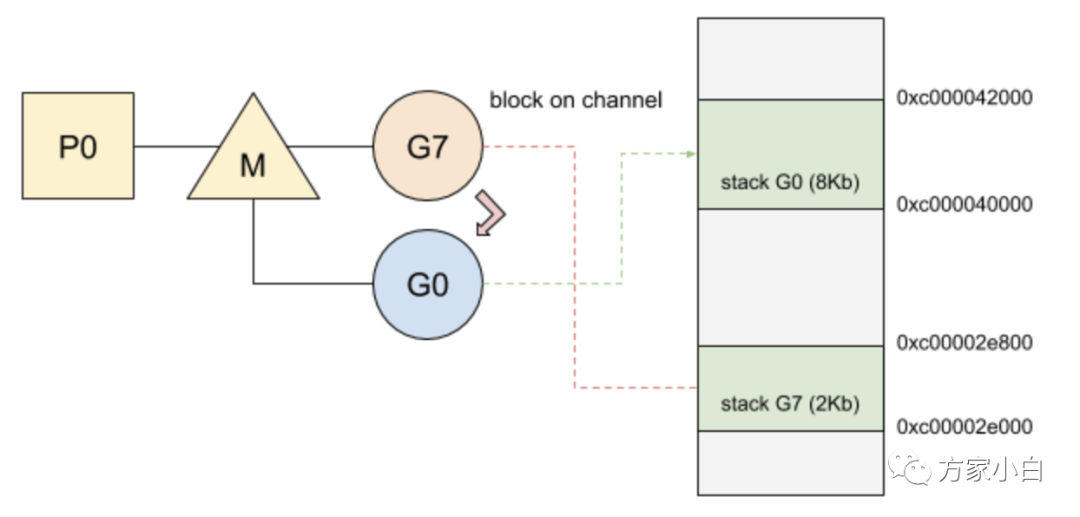
g0 尋找新的 Goroutine 來運(yùn)行g0 使用所選的 Goroutine 進(jìn)行切換:
- 1、
PC和堆棧指針是從其內(nèi)部結(jié)構(gòu)中獲取的; - 2、程序跳轉(zhuǎn)到對應(yīng)的
PC地址;

Goroutine Recycle
goroutine重用
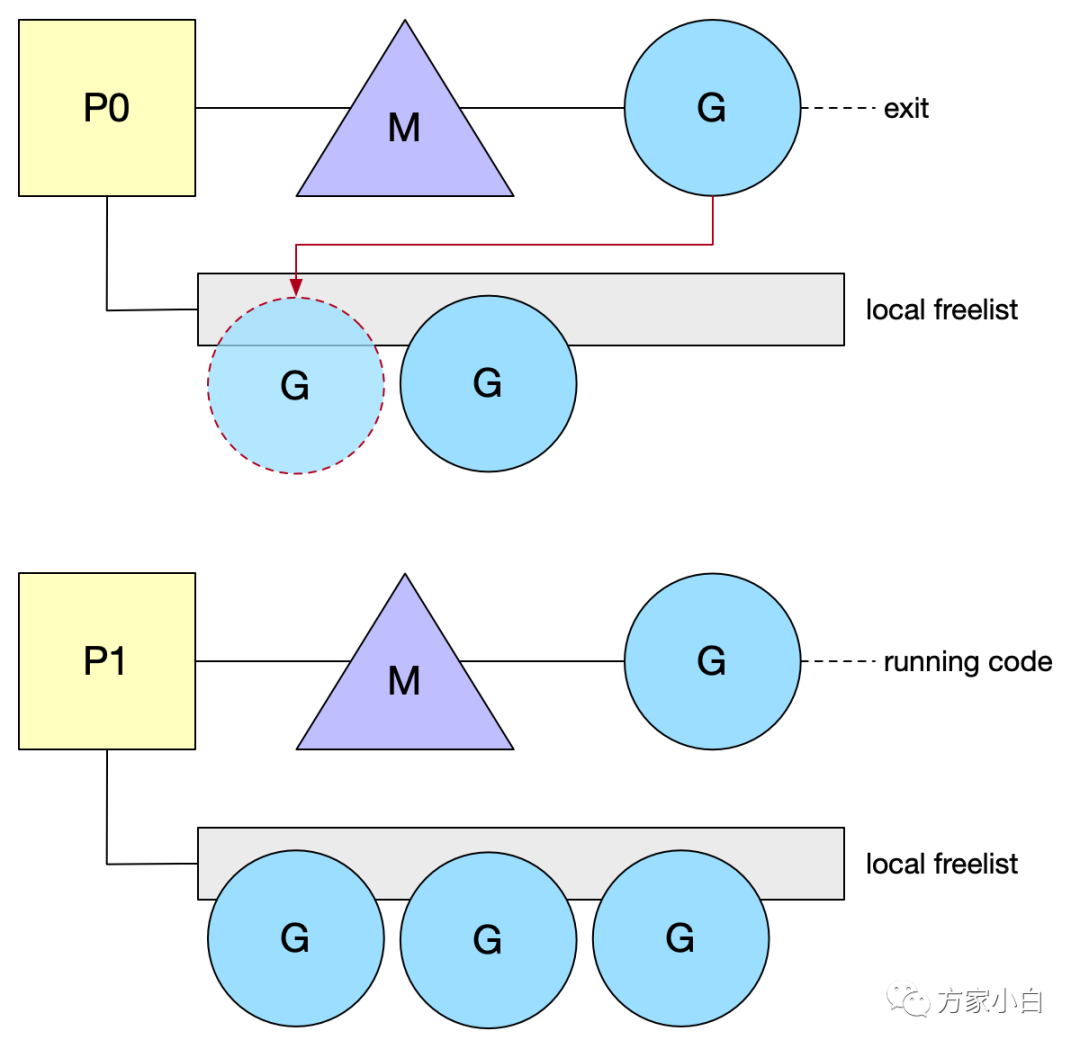
G 很容易創(chuàng)建,棧很小以及快速的上下文切換。基于這些原因,開發(fā)人員非常喜歡并使用它們。然而,一個產(chǎn)生許多 shortlive 的 G 的程序?qū)⒒ㄙM相當(dāng)長的時間來創(chuàng)建和銷毀它們。每個 P 維護(hù)一個 freelist G,保持這個列表是本地的,這樣做的好處是不使用任何鎖來 push/get 一個空閑的 G。當(dāng) G 退出當(dāng)前工作時,它將被 push 到這個空閑列表中。
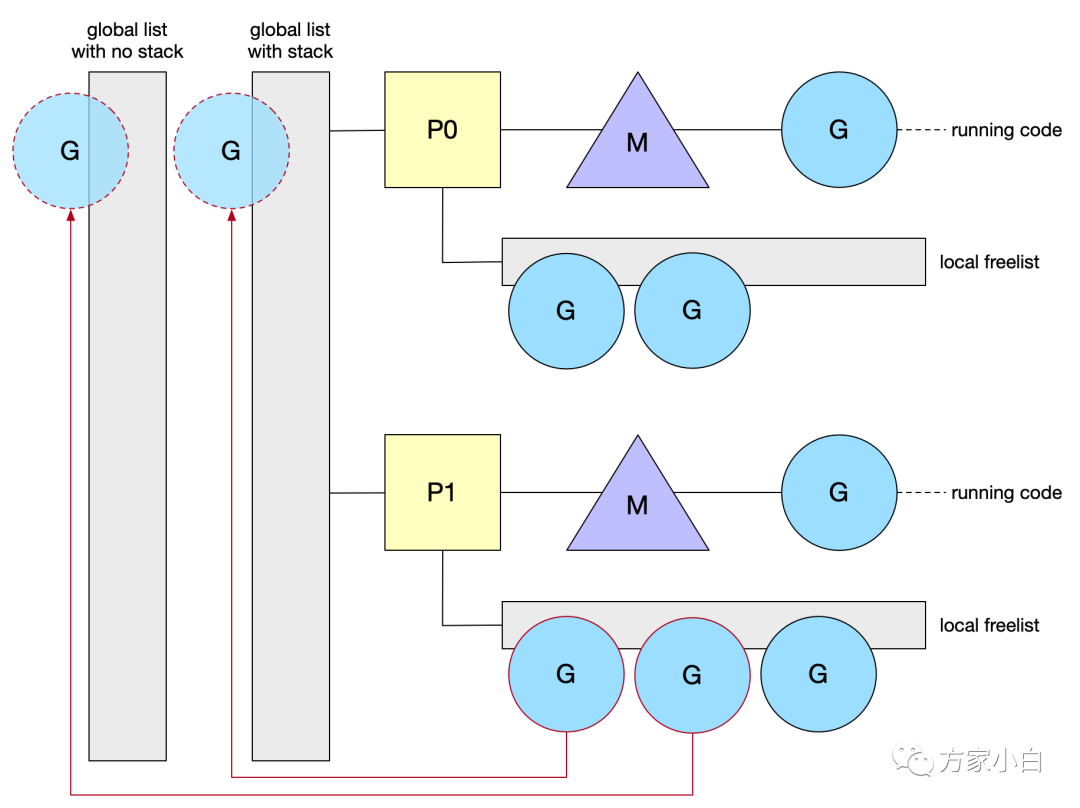
為了更好地分發(fā)空閑的 G ,調(diào)度器也有自己的列表。它實際上有兩個列表:一個包含已分配棧的 G,另一個包含釋放過堆棧的 G(無棧)。鎖保護(hù) central list,因為任何 M 都可以訪問它。當(dāng)本地列表長度超過64時,調(diào)度程序持有的列表從 P 獲取 G。然后一半的 G 將移動到中心列表(central list)。需求回收 G 是一種節(jié)省分配成本的好方法。但是,由于堆棧是動態(tài)增長的,現(xiàn)有的G 最終可能會有一個大棧。因此,當(dāng)堆棧增長(即超過2K)時,Go 不會保留這些棧。
最后
希望和你一起遇見更好的自己
看到這里啦,就點個關(guān)注再走吧~