
「掃盲」 Elasticsearch
前言
只有光頭才能變強。
文本已收錄至我的GitHub精選文章,歡迎Star:
https://github.com/ZhongFuCheng3y/3y
不知道大家的公司用Elasticsearch多不多,反正我公司的是有在用的。平時聽同事們聊天肯定避免不了不認識的技術棧,例如說:把數據放在引擎,從引擎取出數據等等。
如果對引擎不了解的同學,就壓根聽不懂他們在說什么(我就是聽不懂的一位,扎心了)。引擎一般指的是搜索引擎,現在用得比較多的就是Elasticsearch。
這篇文章主要是對Elasticsearch一個簡單的入門,沒有高深的知識和使用。至少我想做到的是:以后同事們聊引擎了,至少知道他們在講什么。

什么是Elasticsearch?
Elasticsearch is a real-time, distributed storage, search, and analytics engine
Elasticsearch 是一個實時的分布式存儲、搜索、分析的引擎。
介紹那兒有幾個關鍵字:
實時
分布式
搜索
分析
于是我們就得知道Elasticsearch是怎么做到實時的,Elasticsearch的架構是怎么樣的(分布式)。存儲、搜索和分析(得知道Elasticsearch是怎么存儲、搜索和分析的)
這些問題在這篇文章中都會有提及。
我已經寫了200多篇原創(chuàng)技術文章了,后續(xù)會寫大數據相關的文章,如果想看我其他文章的同學,不妨關注我吧。公眾號:Java3y
如果覺得我這篇文章還不錯,對你有幫助,不要吝嗇自己的贊!
為什么要用Elasticsearch
在學習一項技術之前,必須先要了解為什么要使用這項技術。所以,為什么要使用Elasticsearch呢?我們在日常開發(fā)中,數據庫也能做到(實時、存儲、搜索、分析)。
相對于數據庫,Elasticsearch的強大之處就是可以模糊查詢。
有的同學可能就會說:我數據庫怎么就不能模糊查詢了??我反手就給你寫一個SQL:
select?*?from?user?where?name?like?'%公眾號Java3y%'
這不就可以把公眾號Java3y相關的內容搜索出來了嗎?
的確,這樣做的確可以。但是要明白的是:name like %Java3y%這類的查詢是不走索引的,不走索引意味著:只要你的數據庫的量很大(1億條),你的查詢肯定會是秒級別的
如果對數據庫索引還不是很了解的同學,建議復看一下我以前的文章。我覺得我當時寫得還不賴(哈哈哈)
GitHub搜關鍵字:”索引“
而且,即便給你從數據庫根據模糊匹配查出相應的記錄了,那往往會返回大量的數據給你,往往你需要的數據量并沒有這么多,可能50條記錄就足夠了。
還有一個就是:用戶輸入的內容往往并沒有這么的精確,比如我從Google輸入ElastcSeach(打錯字),但是Google還是能估算我想輸入的是Elasticsearch
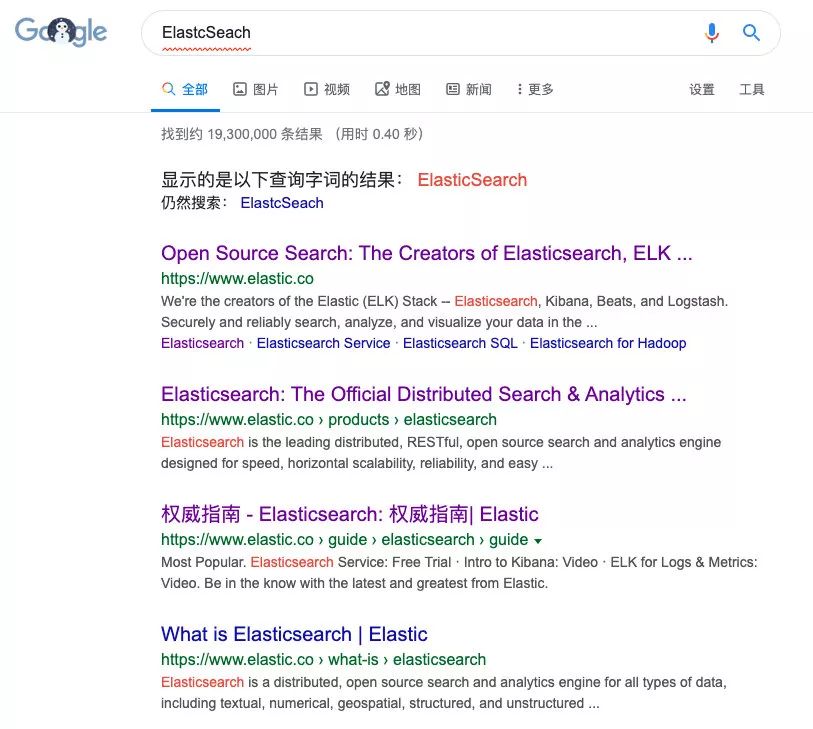
而Elasticsearch是專門做搜索的,就是為了解決上面所講的問題而生的,換句話說:
Elasticsearch對模糊搜索非常擅長(搜索速度很快)
從Elasticsearch搜索到的數據可以根據評分過濾掉大部分的,只要返回評分高的給用戶就好了(原生就支持排序)
沒有那么準確的關鍵字也能搜出相關的結果(能匹配有相關性的記錄)
下面我們就來學學為什么Elasticsearch可以做到上面的幾點。
Elasticsearch的數據結構
眾所周知,你要在查詢的時候花得更少的時間,你就需要知道他的底層數據結構是怎么樣的;舉個例子:
樹型的查找時間復雜度一般是O(logn)
鏈表的查找時間復雜度一般是O(n)
哈希表的查找時間復雜度一般是O(1)
….不同的數據結構所花的時間往往不一樣,你想要查找的時候要快,就需要有底層的數據結構支持
從上面說Elasticsearch的模糊查詢速度很快,那Elasticsearch的底層數據結構是什么呢?我們來看看。
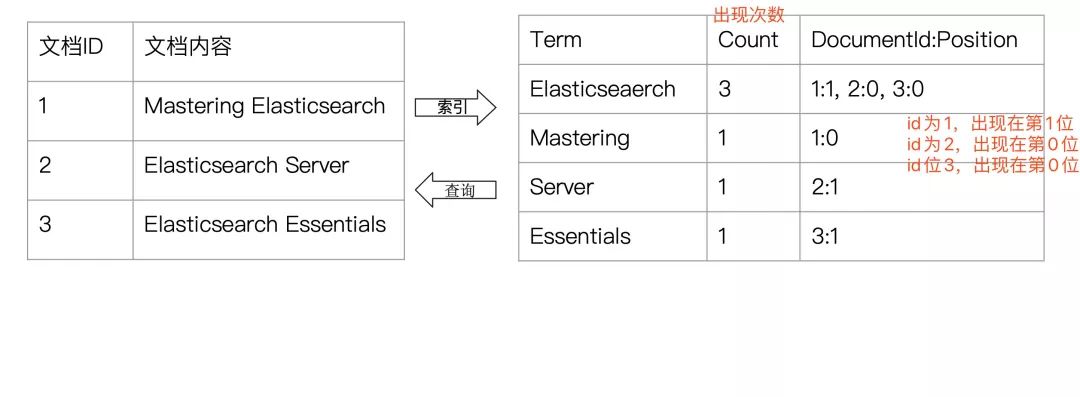
我們根據“完整的條件”查找一條記錄叫做正向索引;我們一本書的章節(jié)目錄就是正向索引,通過章節(jié)名稱就找到對應的頁碼。

首先我們得知道為什么Elasticsearch為什么可以實現快速的“模糊匹配”/“相關性查詢”,實際上是你寫入數據到Elasticsearch的時候會進行分詞。
還是以上圖為例,上圖出現了4次“算法”這個詞,我們能不能根據這次詞為它找他對應的目錄?Elasticsearch正是這樣干的,如果我們根據上圖來做這個事,會得到類似這樣的結果:
算法 ?
->2,13,42,56
這代表著“算法”這個詞肯定是在第二頁、第十三頁、第四十二頁、第五十六頁出現過。這種根據某個詞(不完整的條件)再查找對應記錄,叫做倒排索引。
再看下面的圖,好好體會一下:
眾所周知,世界上有這么多的語言,那Elasticsearch怎么切分這些詞呢?,Elasticsearch內置了一些分詞器
Standard ?Analyzer 。按詞切分,將詞小寫
Simple Analyzer。按非字母過濾(符號被過濾掉),將詞小寫
WhitespaceAnalyzer。按照空格切分,不轉小寫
….等等等
Elasticsearch分詞器主要由三部分組成:
???????Character Filters(文本過濾器,去除HTML)
Tokenizer(按照規(guī)則切分,比如空格)
TokenFilter(將切分后的詞進行處理,比如轉成小寫)
顯然,Elasticsearch是老外寫的,內置的分詞器都是英文類的,而我們用戶搜索的時候往往搜的是中文,現在中文分詞器用得最多的就是IK。
扯了一大堆,那Elasticsearch的數據結構是怎么樣的呢?看下面的圖:
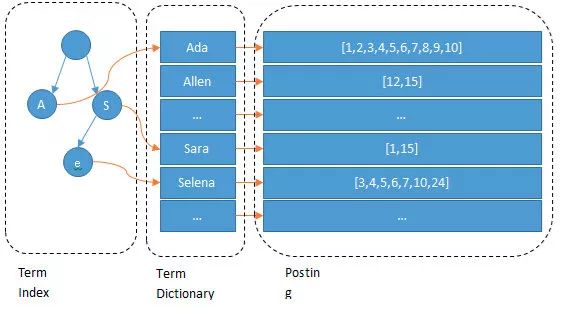
我們輸入一段文字,Elasticsearch會根據分詞器對我們的那段文字進行分詞(也就是圖上所看到的Ada/Allen/Sara..),這些分詞匯總起來我們叫做Term Dictionary,而我們需要通過分詞找到對應的記錄,這些文檔ID保存在PostingList
在Term Dictionary中的詞由于是非常非常多的,所以我們會為其進行排序,等要查找的時候就可以通過二分來查,不需要遍歷整個Term Dictionary
由于Term Dictionary的詞實在太多了,不可能把Term Dictionary所有的詞都放在內存中,于是Elasticsearch還抽了一層叫做Term Index,這層只存儲 ?部分 ? 詞的前綴,Term Index會存在內存中(檢索會特別快)
Term Index在內存中是以FST(Finite State Transducers)的形式保存的,其特點是非常節(jié)省內存。FST有兩個優(yōu)點:
1)空間占用小。通過對詞典中單詞前綴和后綴的重復利用,壓縮了存儲空間;
2)查詢速度快。O(len(str))的查詢時間復雜度。
前面講到了Term Index是存儲在內存中的,且Elasticsearch用FST(Finite State Transducers)的形式保存(節(jié)省內存空間)。Term Dictionary在Elasticsearch也是為他進行排序(查找的時候方便),其實PostingList也有對應的優(yōu)化。
PostingList會使用Frame Of Reference(FOR)編碼技術對里邊的數據進行壓縮,節(jié)約磁盤空間。
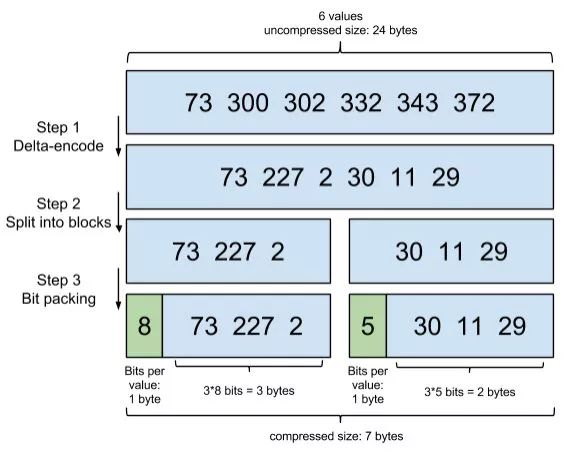
PostingList里邊存的是文檔ID,我們查的時候往往需要對這些文檔ID做交集和并集的操作(比如在多條件查詢時),PostingList使用Roaring Bitmaps來對文檔ID進行交并集操作。
使用Roaring Bitmaps的好處就是可以節(jié)省空間和快速得出交并集的結果。
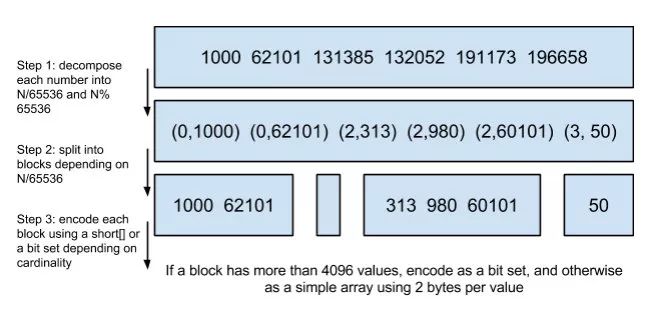
所以到這里我們總結一下Elasticsearch的數據結構有什么特點:

Elasticsearch的術語和架構
從官網的介紹我們已經知道Elasticsearch是分布式存儲的,如果看過我的文章的同學,對分布式這個概念應該不陌生了。
如果對分布式還不是很了解的同學,建議復看一下我以前的文章。我覺得我當時寫得還不賴(哈哈哈)
GitHub搜關鍵字:
”SpringCloud“,"Zookeeper","Kafka","單點登錄"
在講解Elasticsearch的架構之前,首先我們得了解一下Elasticsearch的一些常見術語。
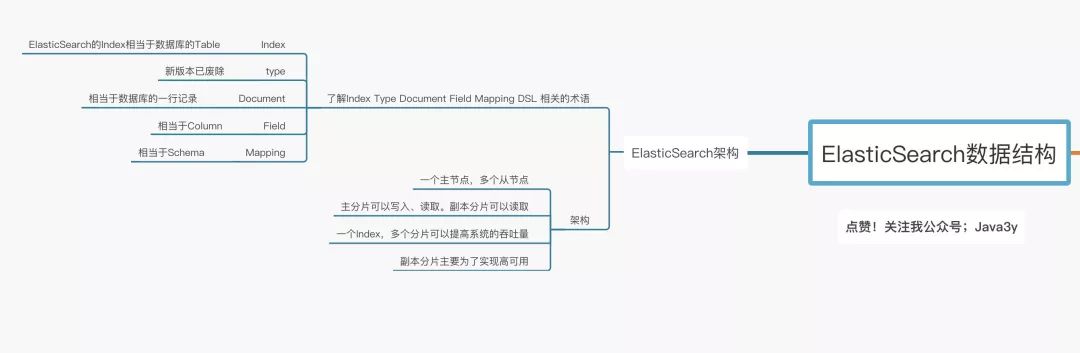
Index:Elasticsearch的Index相當于數據庫的Table
Type:這個在新的Elasticsearch版本已經廢除(在以前的Elasticsearch版本,一個Index下支持多個Type--有點類似于消息隊列一個topic下多個group的概念)
Document:Document相當于數據庫的一行記錄
Field:相當于數據庫的Column的概念
Mapping:相當于數據庫的Schema的概念
DSL:相當于數據庫的SQL(給我們讀取Elasticsearch數據的API)
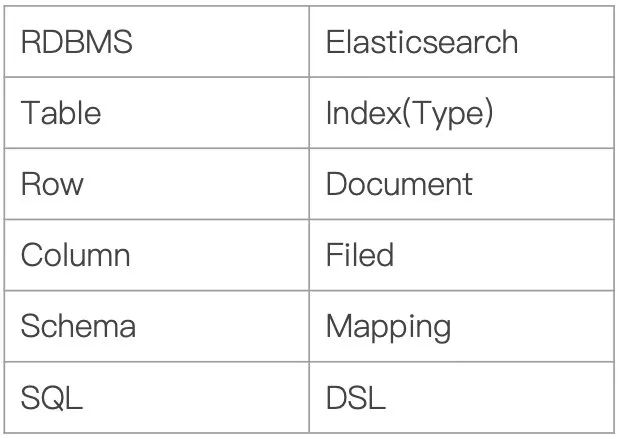
相信大家看完上面的對比圖,對Elasticsearch的一些術語就不難理解了。那Elasticsearch的架構是怎么樣的呢?下面我們來看看:
一個Elasticsearch集群會有多個Elasticsearch節(jié)點,所謂節(jié)點實際上就是運行著Elasticsearch進程的機器。
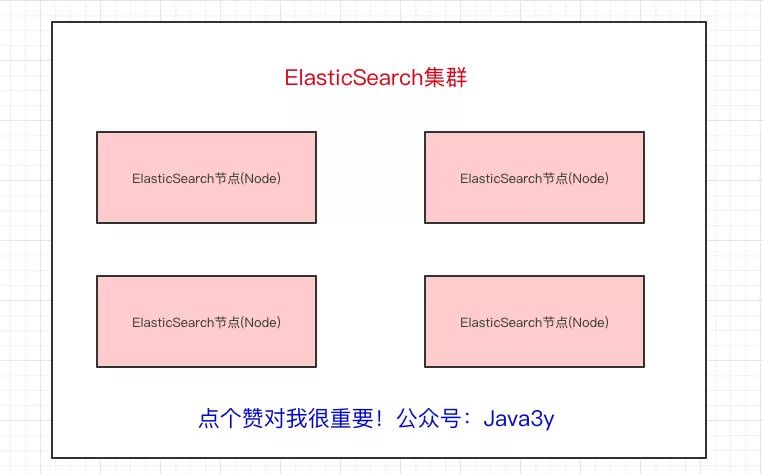
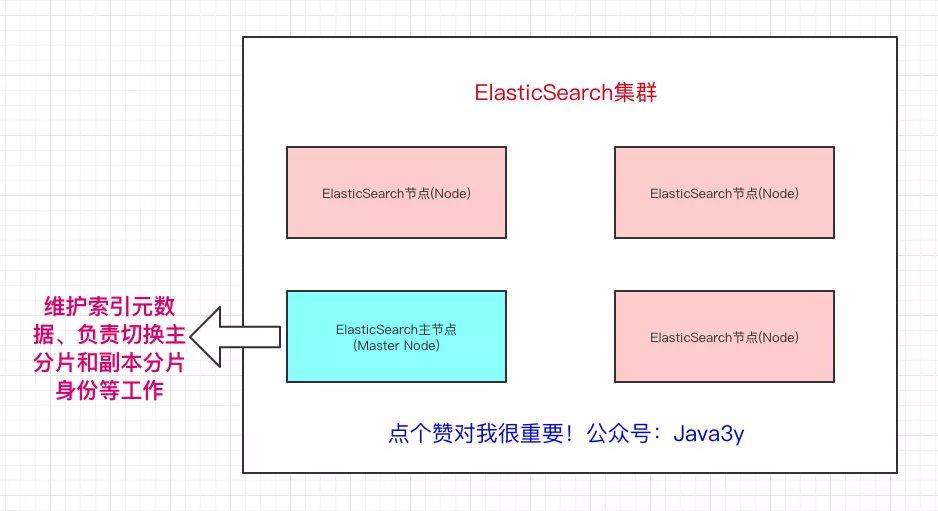
在眾多的節(jié)點中,其中會有一個Master Node,它主要負責維護索引元數據、負責切換主分片和副本分片身份等工作(后面會講到分片的概念),如果主節(jié)點掛了,會選舉出一個新的主節(jié)點。
從上面我們也已經得知,Elasticsearch最外層的是Index(相當于數據庫 表的概念);一個Index的數據我們可以分發(fā)到不同的Node上進行存儲,這個操作就叫做分片。
比如現在我集群里邊有4個節(jié)點,我現在有一個Index,想將這個Index在4個節(jié)點上存儲,那我們可以設置為4個分片。這4個分片的數據合起來就是Index的數據
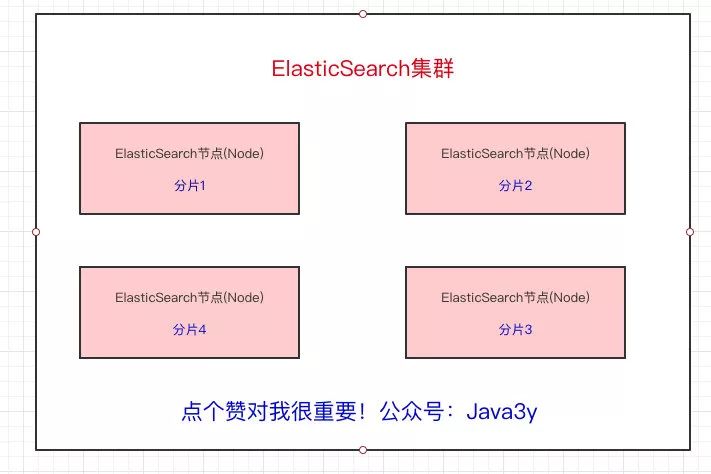
為什么要分片?原因也很簡單:
如果一個Index的數據量太大,只有一個分片,那只會在一個節(jié)點上存儲,隨著數據量的增長,一個節(jié)點未必能把一個Index存儲下來。
多個分片,在寫入或查詢的時候就可以并行操作(從各個節(jié)點中讀寫數據,提高吞吐量)
現在問題來了,如果某個節(jié)點掛了,那部分數據就丟了嗎?顯然Elasticsearch也會想到這個問題,所以分片會有主分片和副本分片之分(為了實現高可用)
數據寫入的時候是寫到主分片,副本分片會復制主分片的數據,讀取的時候主分片和副本分片都可以讀。
Index需要分為多少個主分片和副本分片都是可以通過配置設置的
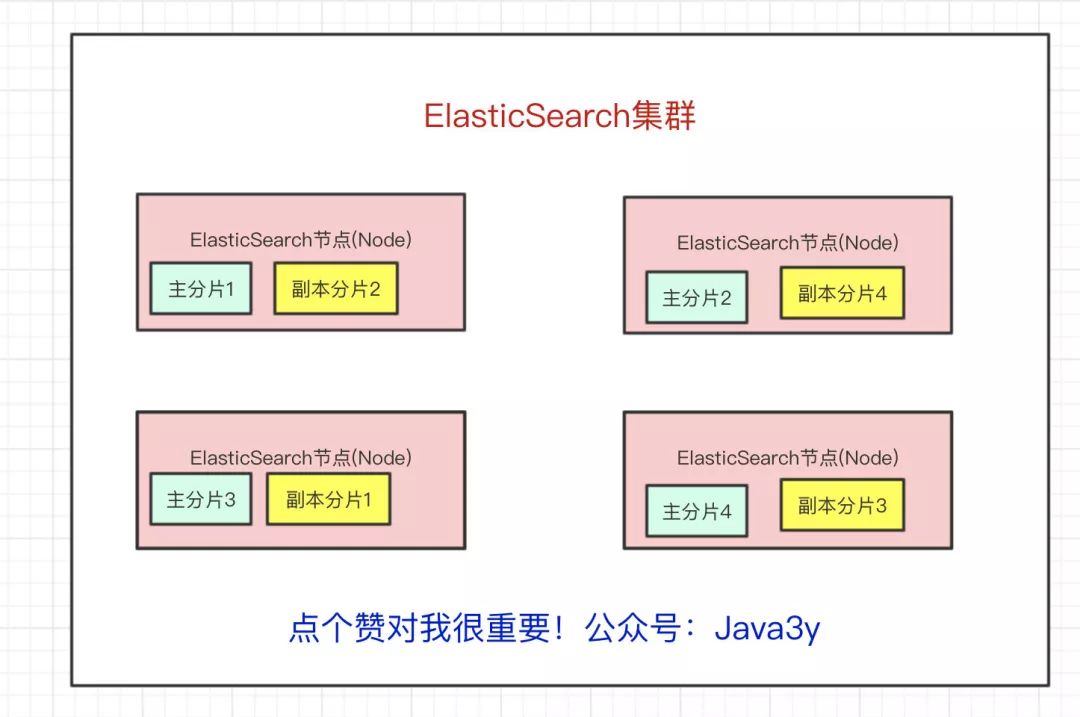
如果某個節(jié)點掛了,前面所提高的Master Node就會把對應的副本分片提拔為主分片,這樣即便節(jié)點掛了,數據就不會丟。
到這里我們可以簡單總結一下Elasticsearch的架構了:
Elasticsearch 寫入的流程
上面我們已經知道當我們向Elasticsearch寫入數據的時候,是寫到主分片上的,我們可以了解更多的細節(jié)。
客戶端寫入一條數據,到Elasticsearch集群里邊就是由節(jié)點來處理這次請求:
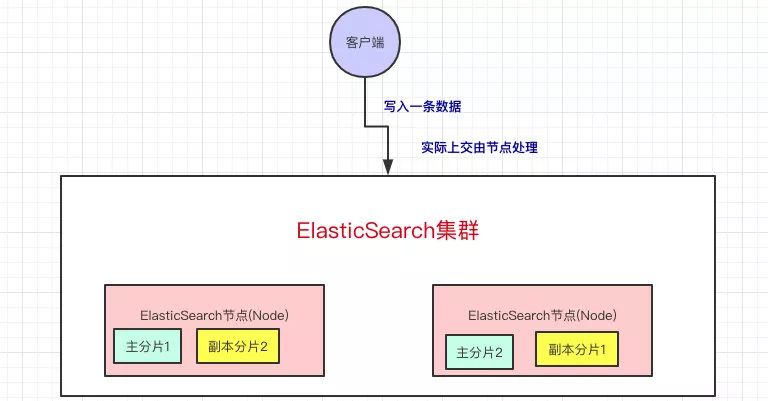
集群上的每個節(jié)點都是coordinating node(協(xié)調節(jié)點),協(xié)調節(jié)點表明這個節(jié)點可以做路由。比如節(jié)點1接收到了請求,但發(fā)現這個請求的數據應該是由節(jié)點2處理(因為主分片在節(jié)點2上),所以會把請求轉發(fā)到節(jié)點2上。
coodinate(協(xié)調)節(jié)點通過hash算法可以計算出是在哪個主分片上,然后路由到對應的節(jié)點
shard = hash(document_id) % (num_of_primary_shards)
路由到對應的節(jié)點以及對應的主分片時,會做以下的事:
將數據寫到內存緩存區(qū)
然后將數據寫到translog緩存區(qū)
每隔1s數據從buffer中refresh到FileSystemCache中,生成segment文件,一旦生成segment文件,就能通過索引查詢到了
refresh完,memory buffer就清空了。
每隔5s中,translog 從buffer flush到磁盤中
定期/定量從FileSystemCache中,結合translog內容
flush index到磁盤中。
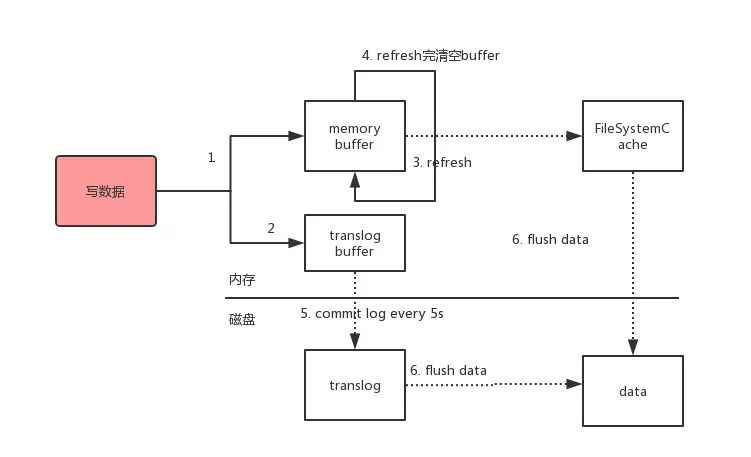
解釋一下:
Elasticsearch會把數據先寫入內存緩沖區(qū),然后每隔1s刷新到文件系統(tǒng)緩存區(qū)(當數據被刷新到文件系統(tǒng)緩沖區(qū)以后,數據才可以被檢索到)。所以:Elasticsearch寫入的數據需要1s才能查詢到
為了防止節(jié)點宕機,內存中的數據丟失,Elasticsearch會另寫一份數據到日志文件上,但最開始的還是寫到內存緩沖區(qū),每隔5s才會將緩沖區(qū)的刷到磁盤中。所以:Elasticsearch某個節(jié)點如果掛了,可能會造成有5s的數據丟失。
等到磁盤上的translog文件大到一定程度或者超過了30分鐘,會觸發(fā)commit操作,將內存中的segement文件異步刷到磁盤中,完成持久化操作。
說白了就是:寫內存緩沖區(qū)(定時去生成segement,生成translog),能夠讓數據能被索引、被持久化。最后通過commit完成一次的持久化。

等主分片寫完了以后,會將數據并行發(fā)送到副本集節(jié)點上,等到所有的節(jié)點寫入成功就返回ack給協(xié)調節(jié)點,協(xié)調節(jié)點返回ack給客戶端,完成一次的寫入。
Elasticsearch更新和刪除
Elasticsearch的更新和刪除操作流程:
給對應的
doc記錄打上.del標識,如果是刪除操作就打上delete狀態(tài),如果是更新操作就把原來的doc標志為delete,然后重新新寫入一條數據
前面提到了,每隔1s會生成一個segement 文件,那segement文件會越來越多越來越多。Elasticsearch會有一個merge任務,會將多個segement文件合并成一個segement文件。
在合并的過程中,會把帶有delete狀態(tài)的doc給物理刪除掉。

Elasticsearch查詢
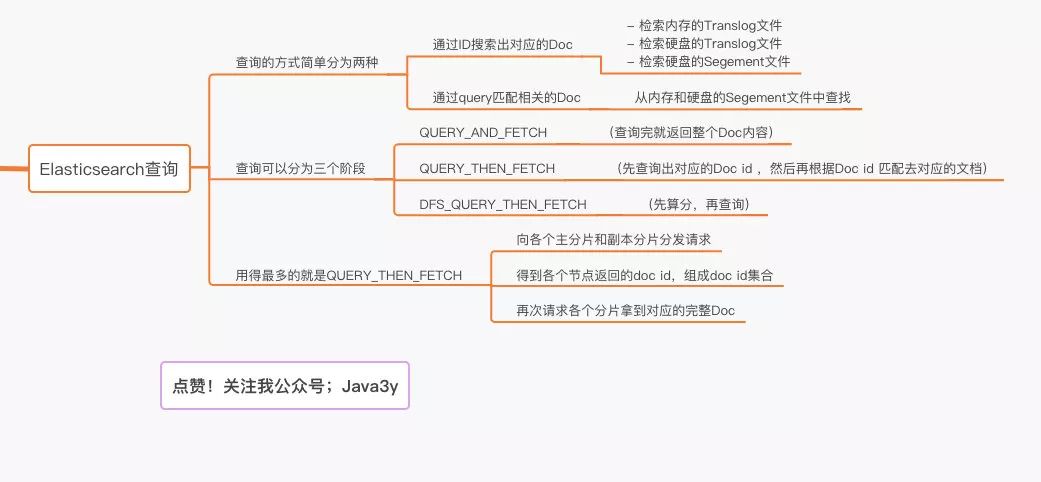
查詢我們最簡單的方式可以分為兩種:
根據ID查詢doc
根據query(搜索詞)去查詢匹配的doc
public?TopDocs?search(Query?query,?int?n);
public?Document?doc(int?docID);
根據ID去查詢具體的doc的流程是:
檢索內存的Translog文件
檢索硬盤的Translog文件
檢索硬盤的Segement文件
根據query去匹配doc的流程是:
同時去查詢內存和硬盤的Segement文件
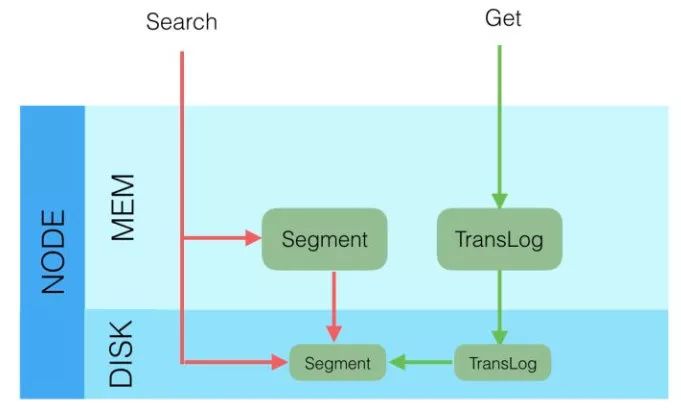
從上面所講的寫入流程,我們就可以知道:Get(通過ID去查Doc是實時的),Query(通過query去匹配Doc是近實時的)
因為segement文件是每隔一秒才生成一次的
Elasticsearch查詢又分可以為三個階段:
QUERY_AND_FETCH(查詢完就返回整個Doc內容)
QUERY_THEN_FETCH(先查詢出對應的Doc id ,然后再根據Doc id 匹配去對應的文檔)
DFS_QUERY_THEN_FETCH(先算分,再查詢)
「這里的分指的是 詞頻率和文檔的頻率(Term Frequency、Document Frequency)眾所周知,出現頻率越高,相關性就更強」
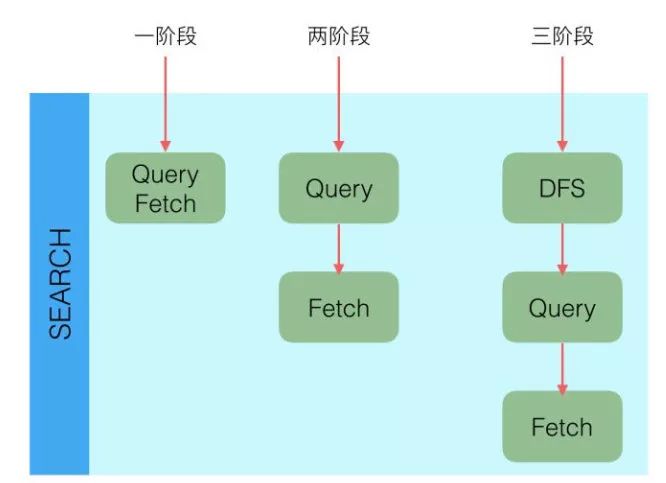
一般我們用得最多的就是QUERY_THEN_FETCH,第一種查詢完就返回整個Doc內容(QUERY_AND_FETCH)只適合于只需要查一個分片的請求。
QUERY_THEN_FETCH總體的流程流程大概是:
客戶端請求發(fā)送到集群的某個節(jié)點上。集群上的每個節(jié)點都是coordinate node(協(xié)調節(jié)點)
然后協(xié)調節(jié)點將搜索的請求轉發(fā)到所有分片上(主分片和副本分片都行)
每個分片將自己搜索出的結果
(doc id)返回給協(xié)調節(jié)點,由協(xié)調節(jié)點進行數據的合并、排序、分頁等操作,產出最終結果。接著由協(xié)調節(jié)點根據
doc id去各個節(jié)點上拉取實際的document數據,最終返回給客戶端。
Query Phase階段時節(jié)點做的事:
協(xié)調節(jié)點向目標分片發(fā)送查詢的命令(轉發(fā)請求到主分片或者副本分片上)
數據節(jié)點(在每個分片內做過濾、排序等等操作),返回
doc id給協(xié)調節(jié)點
Fetch Phase階段時節(jié)點做的是:
協(xié)調節(jié)點得到數據節(jié)點返回的
doc id,對這些doc id做聚合,然后將目標數據分片發(fā)送抓取命令(希望拿到整個Doc記錄)數據節(jié)點按協(xié)調節(jié)點發(fā)送的
doc id,拉取實際需要的數據返回給協(xié)調節(jié)點
主流程我相信大家也不會太難理解,說白了就是:由于Elasticsearch是分布式的,所以需要從各個節(jié)點都拉取對應的數據,然后最終統(tǒng)一合成給客戶端
只是Elasticsearch把這些活都干了,我們在使用的時候無感知而已。
最后
這篇文章主要對Elasticsearch簡單入了個門,實際使用肯定還會遇到很多坑,但我目前就到這里就結束了。
如果文章寫得有錯誤的地方,歡迎友善指正交流。等年后還會繼續(xù)更新大數據相關的入門文章,有興趣的歡迎關注我的公眾號。覺得這篇文章還行,可以給我一個贊?
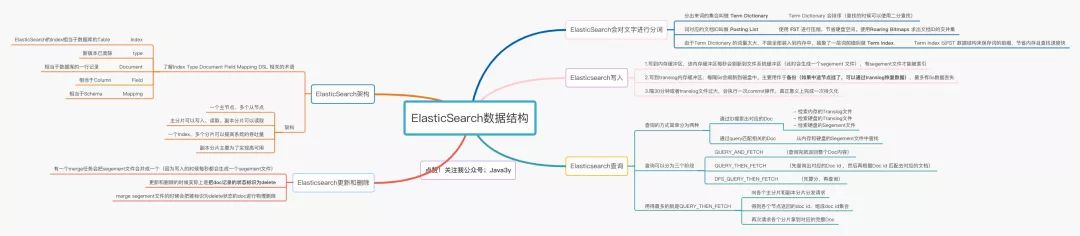
文章的Elasticsearch腦圖,在公眾號回復”ES“即可獲取。
參考資料:
lucene字典實現原理——FST
Elasticsearch性能優(yōu)化
深入分析Elastic Search的寫入過程
Elasticsearch內核解析 - 查詢篇
兩年嘔心瀝血的文章:「面試題」「基礎」「進階」這里全都有!
300多篇原創(chuàng)技術文章加入交流群學習海量視頻資源精美腦圖面試題長按掃碼可關注獲取?
在看和分享對我非常重要!