
網(wǎng)易實(shí)時(shí)數(shù)倉(cāng)實(shí)踐與展望
點(diǎn)擊上方“數(shù)據(jù)管道”,選擇“置頂星標(biāo)”公眾號(hào)
干貨福利,第一時(shí)間送達(dá)

分享嘉賓:馬進(jìn) 網(wǎng)易杭研 技術(shù)專(zhuān)家
編輯整理:張滿(mǎn)意
出品平臺(tái):DataFunTalk
1. 網(wǎng)易實(shí)時(shí)計(jì)算平臺(tái):Sloth
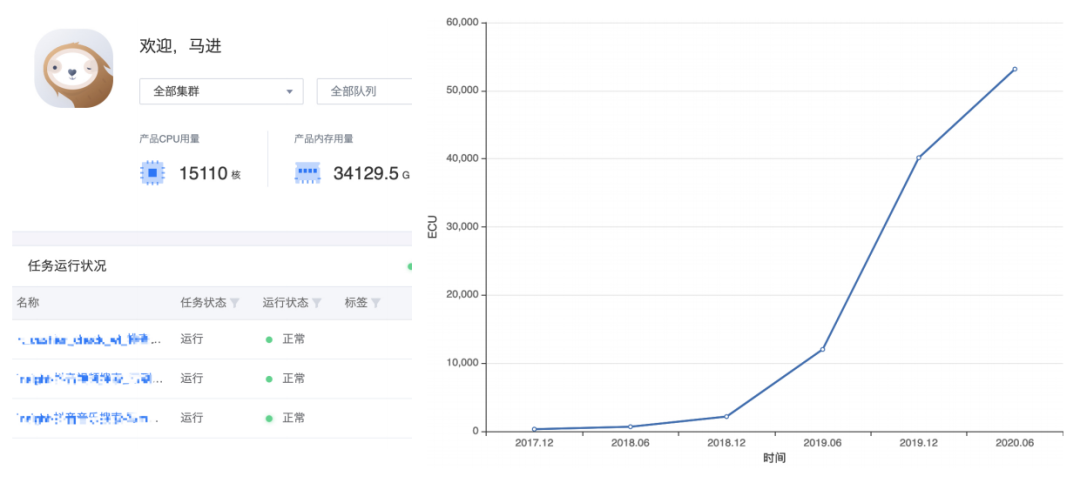
網(wǎng)易的實(shí)時(shí)計(jì)算平臺(tái)Sloth譯成中文是樹(shù)懶的意思,繼承了網(wǎng)易喜歡用動(dòng)物系命名大數(shù)據(jù)組件的風(fēng)格,如果你看過(guò)《瘋狂動(dòng)物城》,一定會(huì)對(duì)劇中的flash印象深刻。Sloth平臺(tái)的建設(shè)始于2017年12月份,至今已有3年的時(shí)間,期間平臺(tái)的彈性計(jì)算單元(ECU)規(guī)模一直呈現(xiàn)指數(shù)級(jí)增長(zhǎng),目前ECU已經(jīng)突破50000個(gè),運(yùn)行的CPU數(shù)量已經(jīng)達(dá)到15110核,內(nèi)存超過(guò)了34T。
2.?平臺(tái)架構(gòu)
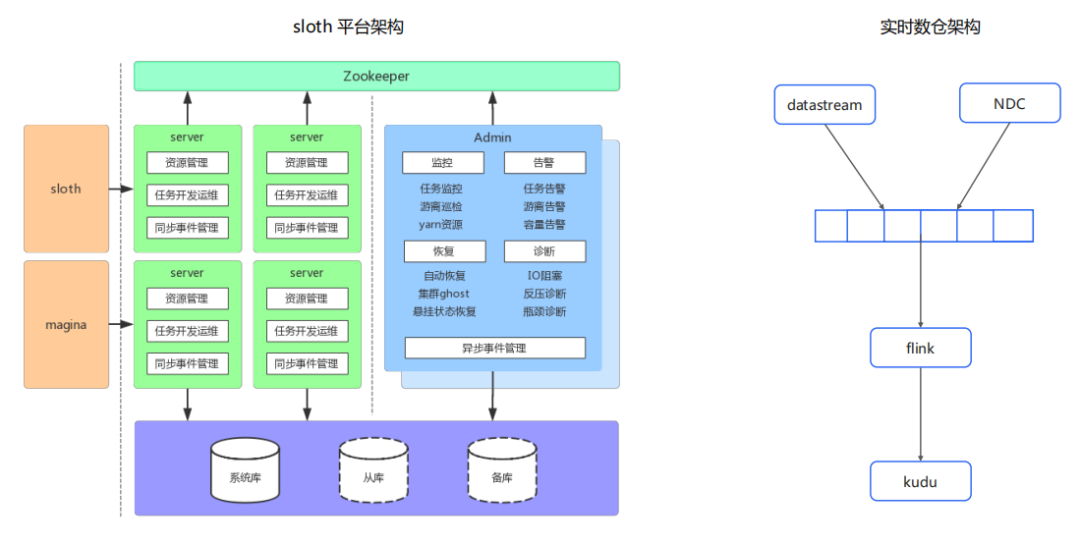
從功能的角度來(lái)看,Sloth平臺(tái)主要分成兩大塊:
Admin:主要負(fù)責(zé)一些異步的服務(wù),比如說(shuō)任務(wù)的監(jiān)控,告警,恢復(fù)和診斷。
Server:主要完成一些應(yīng)用層面的服務(wù),同時(shí)它也是一個(gè)無(wú)狀態(tài)的PAAS服務(wù),既面向我們web的終端用戶(hù),也面向大數(shù)據(jù)平臺(tái)內(nèi)部的其他模塊。從功能上來(lái)看,它負(fù)責(zé)資源的管理,任務(wù)的開(kāi)發(fā)及運(yùn)維,同步事件的管理等任務(wù)。
從數(shù)據(jù)層面來(lái)看,我們實(shí)時(shí)數(shù)倉(cāng)的架構(gòu)主要分為四個(gè)層面:
① Source層
關(guān)系型數(shù)據(jù):NDC是公司專(zhuān)門(mén)處理關(guān)系型數(shù)據(jù)的組件,它會(huì)將mysql等關(guān)系型數(shù)據(jù)庫(kù)的binlog日志解析成特殊的數(shù)據(jù)格式然后插入到我們的kafka消息隊(duì)列。
日志型數(shù)據(jù):datastream是公司的專(zhuān)門(mén)負(fù)責(zé)日志收集的平臺(tái),它會(huì)將收集的日志信息插入到我們的消息隊(duì)列。
② 消息隊(duì)列
目前我們選用的是kafka。
③ 計(jì)算層
目前我們選用的是flink來(lái)完成數(shù)據(jù)的清洗,轉(zhuǎn)換及聚合。
④ Sink層
kudu是我們主推的存儲(chǔ)格式,kudu不僅可以提供一個(gè)高效的用于數(shù)據(jù)分析的列存格式,同時(shí)也支持?jǐn)?shù)據(jù)實(shí)時(shí)的upsert及delete。當(dāng)體量比較小的時(shí)候,也可以選用mysql或者redis這種可以實(shí)時(shí)變更的存儲(chǔ)組件。
3.?一站式實(shí)時(shí)計(jì)算開(kāi)發(fā)IDE
我們主推的開(kāi)發(fā)模式是sql模式,同時(shí)我們也支持jar包模式。
我們提供高度集成的IDE,支持代碼的離線調(diào)試,線上調(diào)試,版本管理,版本比對(duì)及配置管理。
4.?一站式實(shí)時(shí)任務(wù)運(yùn)維
運(yùn)維我們主要分為三大版塊,分別是任務(wù)的運(yùn)維,服務(wù)器監(jiān)控及異常告警,下面我們分別看一下:
① 任務(wù)的運(yùn)維
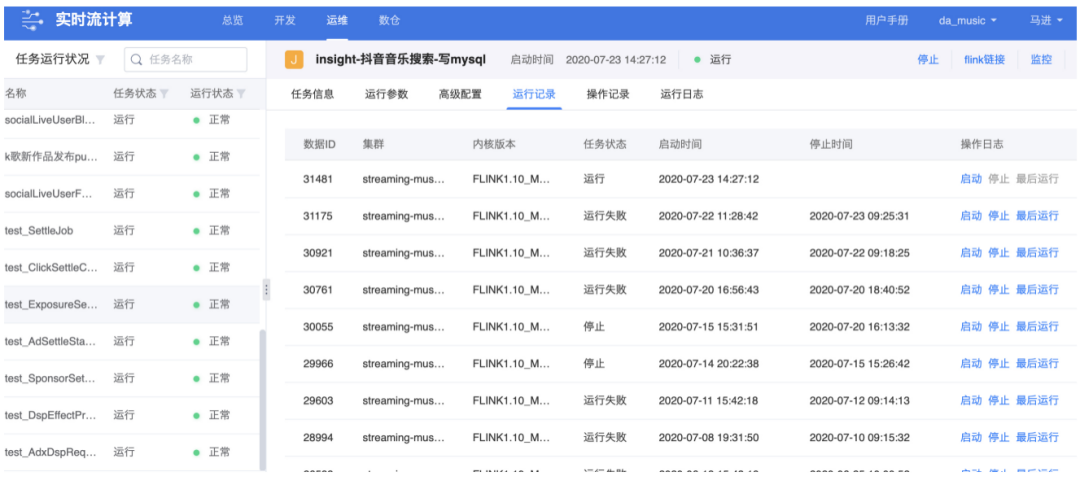
我們提供豐富的界面和菜單來(lái)支持任務(wù)的運(yùn)維工作,通過(guò)頁(yè)面的菜單點(diǎn)擊我們可以輕松的查看任務(wù)信息,運(yùn)行時(shí)的參數(shù),高級(jí)的配置,運(yùn)行記錄,操作記錄及運(yùn)行日志。
② 服務(wù)器壓力的監(jiān)控
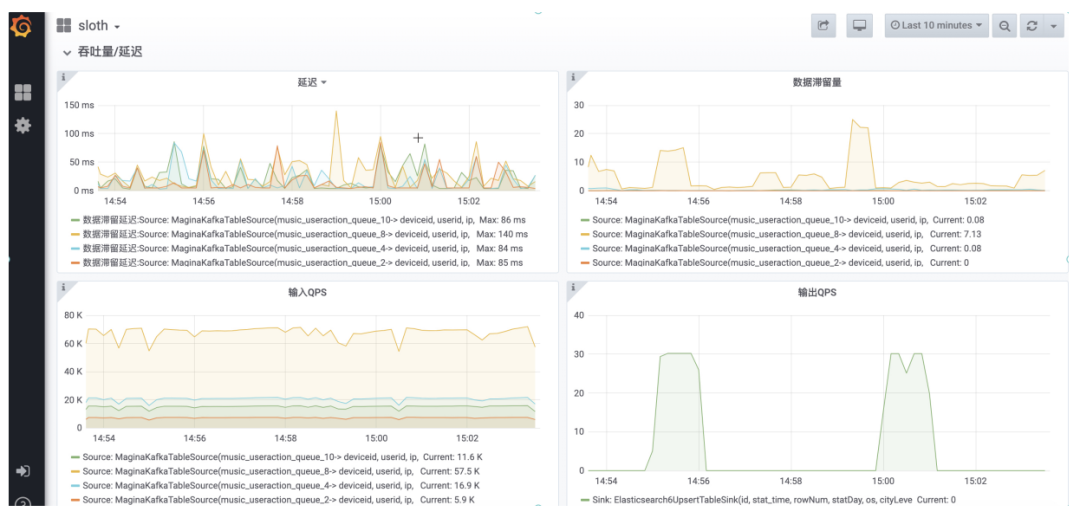
我們?cè)趃rafana的基礎(chǔ)上進(jìn)行了二次開(kāi)發(fā),圖形化的展示平臺(tái)的吞吐量,延遲,IO,QPS等關(guān)鍵信息。
③ 告警的設(shè)置
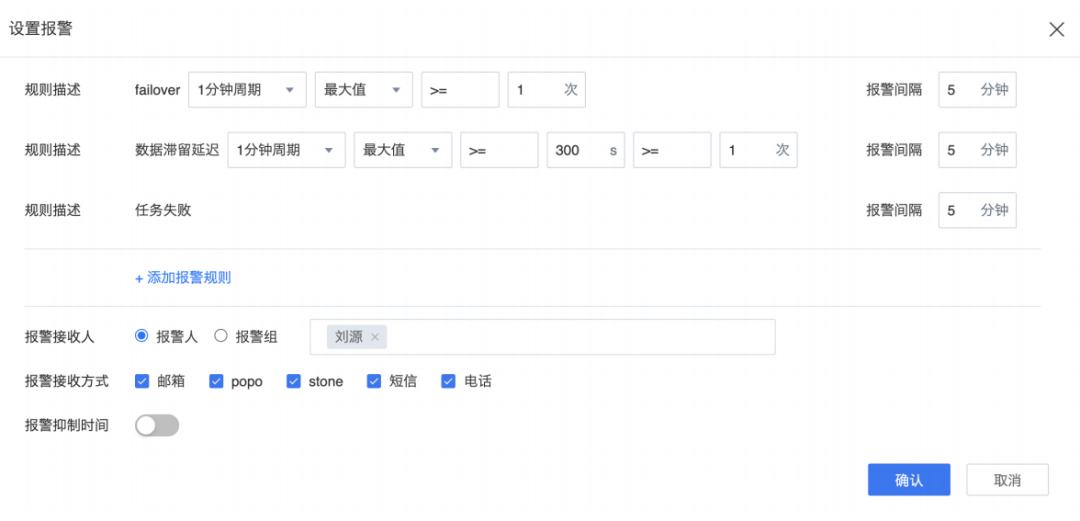
在Sloth平臺(tái)設(shè)置告警非常簡(jiǎn)單,你可以在界面上配置多個(gè)規(guī)則,比如說(shuō)任務(wù)失敗次數(shù),數(shù)據(jù)延遲超多少閥值,報(bào)警間隔,告警的接收人,發(fā)送方式等。
5.?統(tǒng)一元數(shù)據(jù)中心
無(wú)論是離線數(shù)倉(cāng)還是實(shí)時(shí)數(shù)倉(cāng),都需要做好元數(shù)據(jù)的管理工作,Sloth平臺(tái)也有統(tǒng)一的元數(shù)據(jù)中心,下面簡(jiǎn)單介紹一下我們的元數(shù)據(jù)管理方式,元數(shù)據(jù)登記以及統(tǒng)一元數(shù)據(jù)所帶來(lái)的好處。
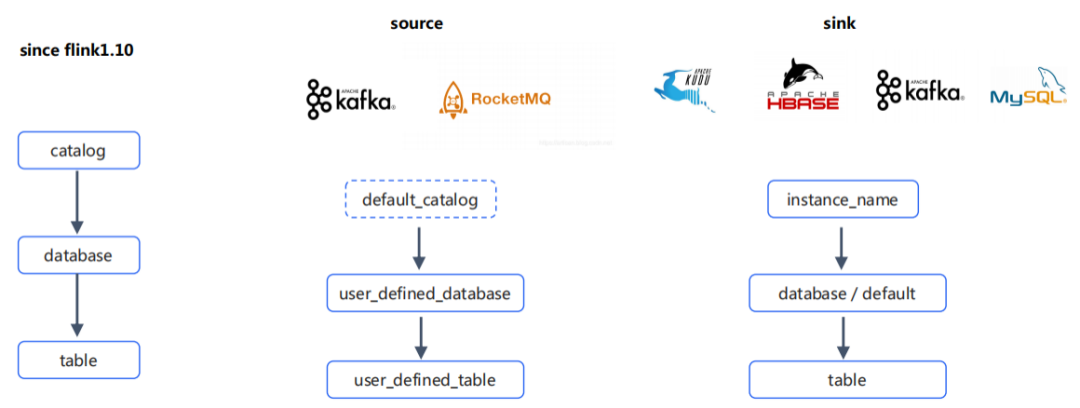
元數(shù)據(jù)管理:
Hive metastore元數(shù)據(jù)管理體系是業(yè)界公認(rèn)的標(biāo)準(zhǔn),包括flink在1.10版本之后也開(kāi)始打造自己的catalog機(jī)制,網(wǎng)易也遵循了這套邏輯,將數(shù)據(jù)統(tǒng)一分成了instance-> database -> table 的層級(jí)。
數(shù)據(jù)源登記:
對(duì)于關(guān)系型數(shù)據(jù)庫(kù),本身就有schema信息,比如說(shuō)mysql本身就有schema,database和table的概念,那么我們只需要把mysql登記進(jìn)來(lái),賦予一個(gè)instance_name,那么以后就可以通過(guò)instance_name.database.table 的方式來(lái)訪問(wèn)。
對(duì)于NOSQL類(lèi)的數(shù)據(jù)源,有些數(shù)據(jù)源沒(méi)有database的概念,比如說(shuō)hbase,我們可以指定一個(gè)default的database。
對(duì)于消息隊(duì)列,本身沒(méi)有元數(shù)據(jù),平臺(tái)本身提供一個(gè)default的catalog可以直接使用,同時(shí)用戶(hù)需要自定義database和table。
統(tǒng)一元數(shù)據(jù)所帶來(lái)的好處:
簡(jiǎn)化了開(kāi)發(fā)流程,節(jié)省了代碼量,規(guī)避了先定義DDL然后在定義DML的開(kāi)發(fā)流程
一次登記,多處復(fù)用
允許字段發(fā)生變更,通過(guò)set設(shè)置屬性,可以實(shí)現(xiàn)相同的元數(shù)據(jù)在不同的任務(wù)中具有一定的多樣性
6.?其他工作
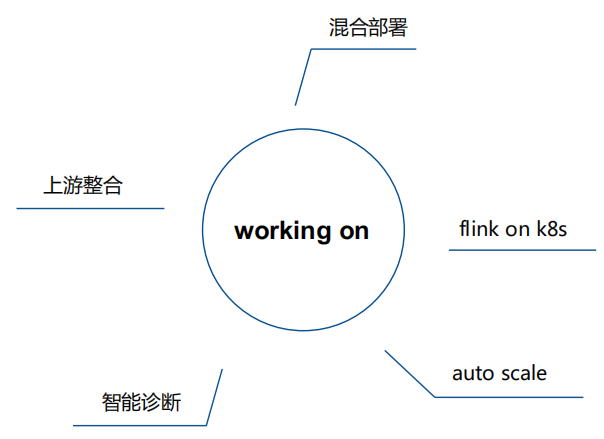
混合部署,開(kāi)展基于yarn和k8s的混合部署實(shí)踐,改善資源利用率
上游整合:對(duì)上游的數(shù)據(jù)庫(kù),只需要對(duì)數(shù)據(jù)庫(kù)地址做一次性登記,就可以將數(shù)據(jù)庫(kù)的表作為批表和流表source和flink實(shí)現(xiàn)無(wú)縫接合。省去用戶(hù)在不同系統(tǒng)之間的跳轉(zhuǎn)
自動(dòng)伸縮:根據(jù)業(yè)務(wù)流量,數(shù)據(jù)量自動(dòng)調(diào)整內(nèi)存和并發(fā)度,以適配業(yè)務(wù)流量的峰谷模型。
增強(qiáng)診斷功能,提升運(yùn)維效率,減小運(yùn)維壓力
1. 現(xiàn)狀及痛點(diǎn)分析
下面我們以一個(gè)百度熱詞統(tǒng)計(jì)案例來(lái)分析一下流式處理與批量處理的成本消耗及網(wǎng)易目前遇到的一個(gè)存儲(chǔ)痛點(diǎn)。?
①?流式處理與批量處理
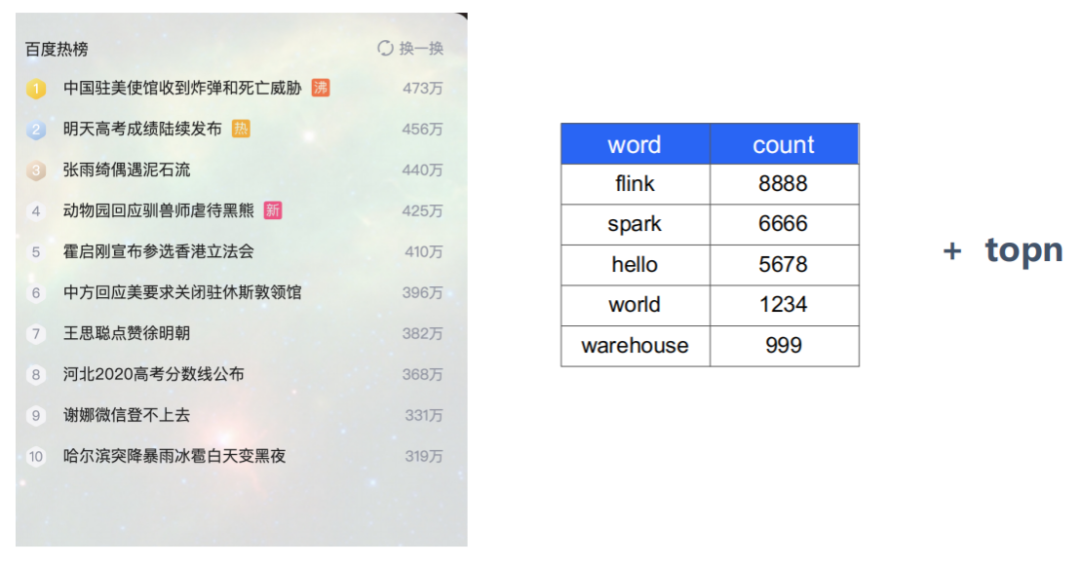
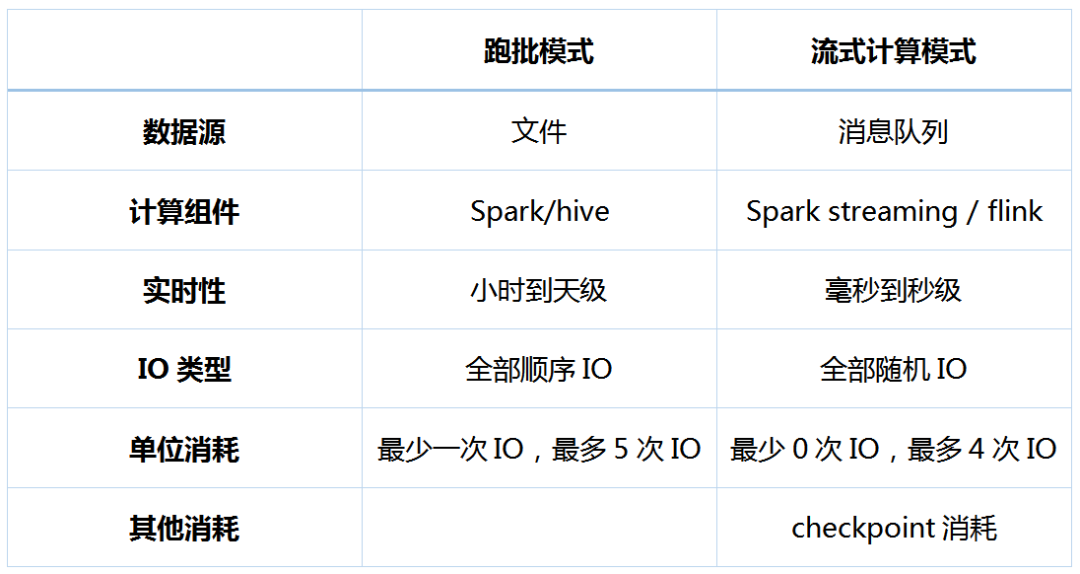
熟悉大數(shù)據(jù)的人都知道統(tǒng)計(jì)百度熱詞的過(guò)程相當(dāng)于一個(gè)wordcount + topn 操作,這個(gè)任務(wù)既可以用spark跑批模式實(shí)現(xiàn),也可以用flink流式計(jì)算實(shí)現(xiàn),下面我們來(lái)分析一下跑批模式和流式計(jì)算模式完成這個(gè)統(tǒng)計(jì)的消耗情況。
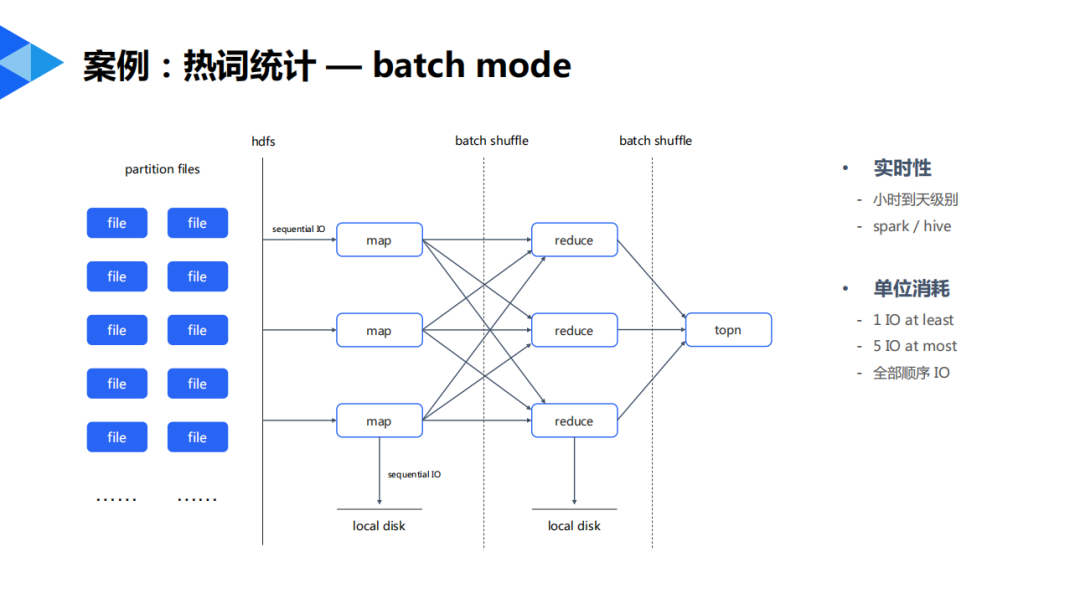
跑批模式:
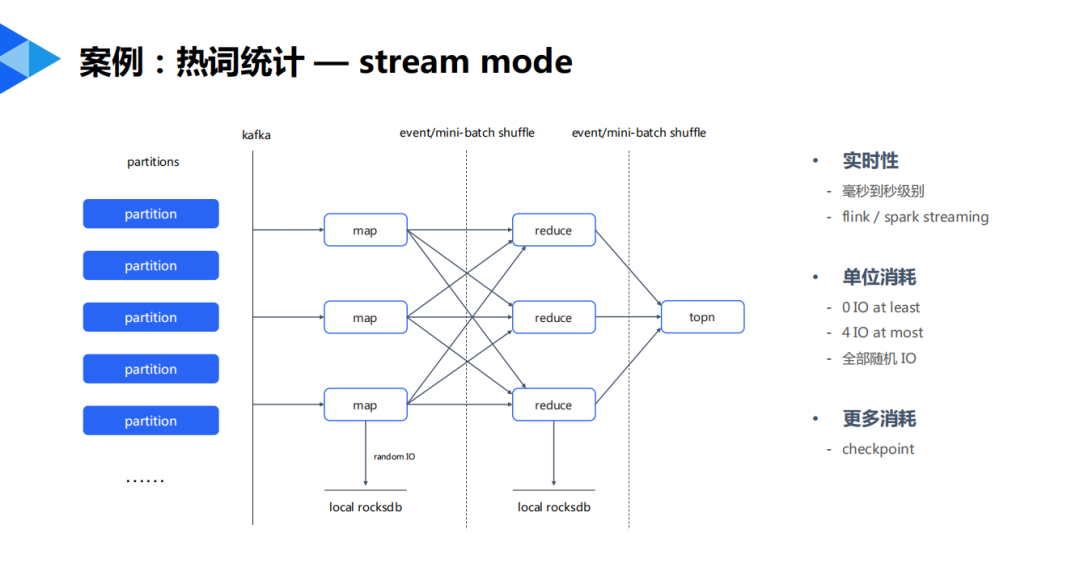
流式計(jì)算模式:
結(jié)果對(duì)比:
② Kudu痛點(diǎn)
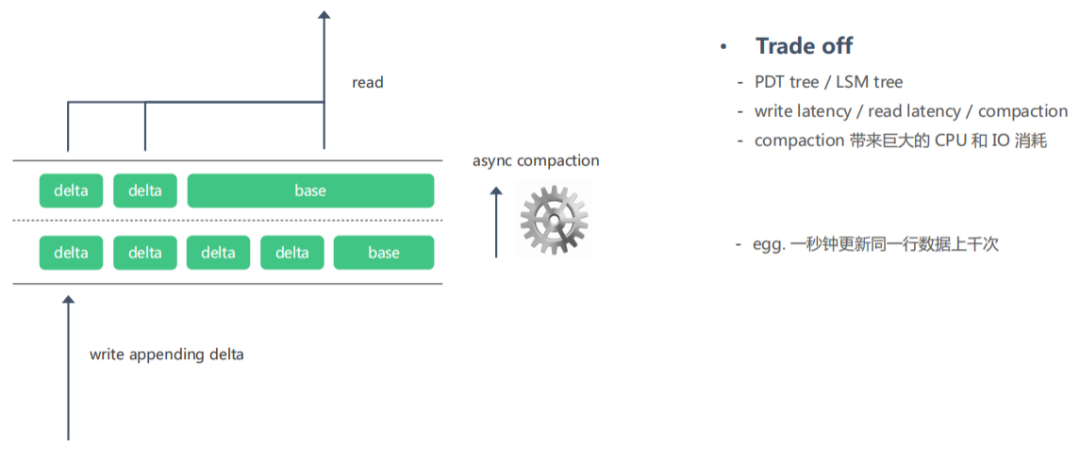
目前市面上的支持實(shí)時(shí)讀寫(xiě)的大數(shù)據(jù)存儲(chǔ)基本上采用的都是PDT tree或者LSM tree這種數(shù)據(jù)結(jié)構(gòu),這種數(shù)據(jù)結(jié)構(gòu)主要采用的是寫(xiě)優(yōu)化策略,首先數(shù)據(jù)會(huì)有一個(gè)基線版本,當(dāng)對(duì)數(shù)據(jù)進(jìn)行修改時(shí),不會(huì)立即修改基線版本的數(shù)據(jù),而是寫(xiě)入一個(gè)新版本的數(shù)據(jù),這種寫(xiě)入是采用append的模式實(shí)現(xiàn)的,所以寫(xiě)延遲非常低,那么讀取的時(shí)候我們就需要合并多個(gè)版本的數(shù)據(jù)返回最新版本的數(shù)據(jù),它的讀延遲就會(huì)比較高。所以為了照顧到讀延遲問(wèn)題,隔一段時(shí)間就需要執(zhí)行一次合并版本的操作形成一個(gè)新的基線版本,這個(gè)過(guò)程叫compaction。這種機(jī)制會(huì)帶來(lái)一個(gè)問(wèn)題,就是當(dāng)一秒鐘之內(nèi)發(fā)生大量的修改時(shí),這時(shí)數(shù)據(jù)就會(huì)有很多個(gè)版本,compaction的過(guò)程就會(huì)帶來(lái)大量的cpu和內(nèi)存消耗,這個(gè)問(wèn)題我們稱(chēng)之為寫(xiě)放大問(wèn)題。
因?yàn)閏ompaction的存在,kudu成了一個(gè)存算不分離的存儲(chǔ)系統(tǒng),它需要去綜合考慮寫(xiě)延遲,讀延遲和compaction的性能,雖然他可以實(shí)時(shí)upsert或者delete,但是極端情況下它會(huì)遇到寫(xiě)放大的問(wèn)題,而且網(wǎng)易線上也確實(shí)經(jīng)歷過(guò)這樣的事故。
③ 實(shí)時(shí)規(guī)模與成本的負(fù)相關(guān)
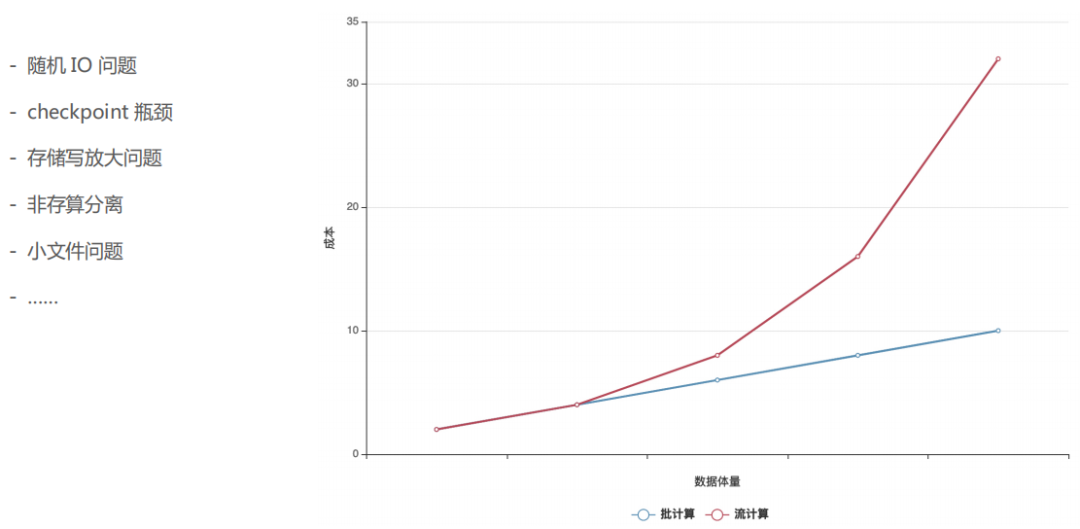
根據(jù)前面的分析,我們得到了一個(gè)結(jié)論:
批計(jì)算的成本和數(shù)據(jù)體量是呈現(xiàn)線性關(guān)系的,因?yàn)閿?shù)據(jù)體量大的情況下,由于是順序IO,我們只需要增加機(jī)器就可以解決。
而流計(jì)算的成本卻隨著數(shù)據(jù)體量的增長(zhǎng)呈現(xiàn)指數(shù)級(jí)增長(zhǎng),原因是流式計(jì)算過(guò)程中會(huì)遇到隨機(jī)IO的問(wèn)題,流式計(jì)算框架的checkpoint的瓶頸,存儲(chǔ)組件的寫(xiě)放大問(wèn)題,存算不分離的問(wèn)題,以及小文件問(wèn)題等等。
2. 展望:流批一體的配套存儲(chǔ)
基于之前的提出的這些問(wèn)題,我們展望一下如何實(shí)現(xiàn)一個(gè)流批一體的配套存儲(chǔ):
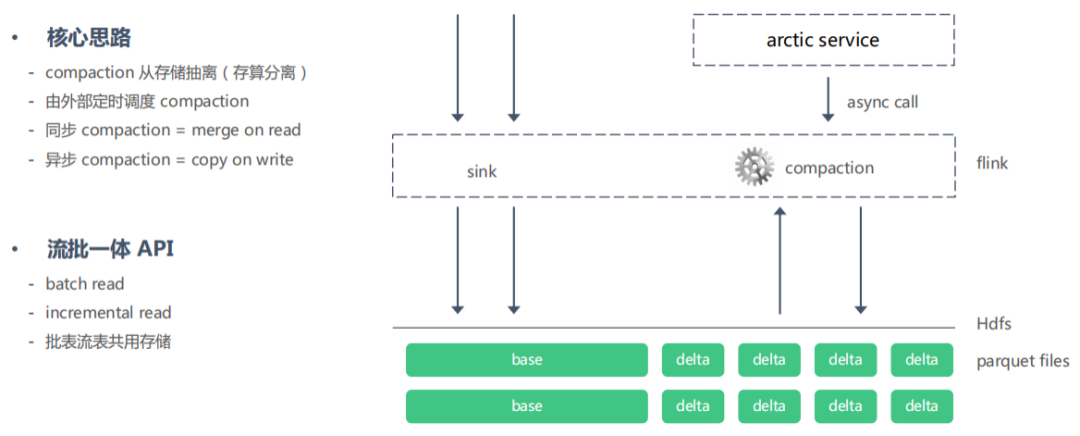
首先,我們需要實(shí)現(xiàn)存算分離,核心思路是:
把kudu的compaction操作從存儲(chǔ)端剝離出來(lái)。
把compaction操作交給外部的定時(shí)調(diào)度來(lái)完成,比如說(shuō)我們正在做的arctic服務(wù),提供分鐘級(jí)甚至是小時(shí)級(jí)的調(diào)度,犧牲掉一部分的實(shí)時(shí)性,但是提高了服務(wù)的穩(wěn)定性。拿百度熱詞這個(gè)例子,我們可以看出熱詞每秒鐘都在更新,但是我們沒(méi)有必要每秒鐘更新一下數(shù)據(jù),我一分鐘更新一下數(shù)據(jù)完全是可以的。
對(duì)于一些數(shù)據(jù)準(zhǔn)確性特別高的,我們應(yīng)該提供一種同步的compaction機(jī)制,在讀取數(shù)據(jù)的時(shí)候執(zhí)行,比如說(shuō)用flink讀取數(shù)據(jù)的時(shí)候執(zhí)行compaction后再返回,這種情況我們稱(chēng)之為merge on read。
同時(shí)也可以提供一個(gè)異步的compaction機(jī)制,這種情況下,你讀取的時(shí)候,讀取到的是上一次compaction執(zhí)行完成之后的結(jié)果,這種情況我們稱(chēng)之為copy on write。
其次,我們應(yīng)該提供一個(gè)流批一體的API:
批量讀取的api其實(shí)很好解決,我們的hdfs上的存儲(chǔ)結(jié)構(gòu)像parquet,kudu本身就是可以批量讀取的,那么什么是流式讀取的api呢?試想一下我們的消息隊(duì)列,像kafka提供了一個(gè)時(shí)間戳,我可以隨時(shí)回到這個(gè)時(shí)間戳對(duì)應(yīng)的偏移,然后消費(fèi)之后的數(shù)據(jù),所以我們的想法是只要我們給定一個(gè)起始時(shí)間就能增量的讀取某個(gè)時(shí)間點(diǎn)之后的數(shù)據(jù)就可以了,這個(gè)也類(lèi)似mysql的binlog。
無(wú)論是批量的讀取還是流式的讀取,它們的存儲(chǔ)應(yīng)該是同一套。
3. 數(shù)倉(cāng)分級(jí)

我認(rèn)為數(shù)倉(cāng)可以根據(jù)實(shí)時(shí)性的要求分成不同的等級(jí):
毫秒-秒級(jí):實(shí)時(shí)性要求最高的等級(jí),沒(méi)有調(diào)度延遲,我們把這種場(chǎng)景比喻成私家車(chē),這種情況下,道路治理是最關(guān)鍵的,要避免堵車(chē),結(jié)合我們的實(shí)時(shí)計(jì)算來(lái)講的話(huà),私家車(chē)就是一個(gè)單獨(dú)的事件,處理過(guò)程中要防止產(chǎn)生數(shù)據(jù)堆積,該級(jí)別更加注重端到端的情況,通常是一個(gè)特定的任務(wù)或者路線。
分鐘級(jí):實(shí)時(shí)性高,有一定的調(diào)度延遲,我們把這種場(chǎng)景比喻成地鐵,吞吐量比私家車(chē)交通要更高,是一種小批量運(yùn)輸,地鐵交通注重的是換乘和復(fù)用,注重優(yōu)化線路和站點(diǎn),就和我們的workflow比較類(lèi)似。
小時(shí)-天級(jí):實(shí)時(shí)性要求低,調(diào)度延遲高,我們把這種場(chǎng)景比喻成高鐵,吞吐量大,執(zhí)行速度最快的交通工具,你準(zhǔn)備數(shù)據(jù)的時(shí)間可能超過(guò)真正執(zhí)行的時(shí)間,這種就是我們傳統(tǒng)的離線數(shù)倉(cāng)的模式。
最后概括一下,如果把數(shù)倉(cāng)比喻成交通的話(huà),實(shí)時(shí)數(shù)倉(cāng)就好比是城市交通,離線數(shù)倉(cāng)就好比是城際交通。
4. 實(shí)時(shí)數(shù)倉(cāng)trade off
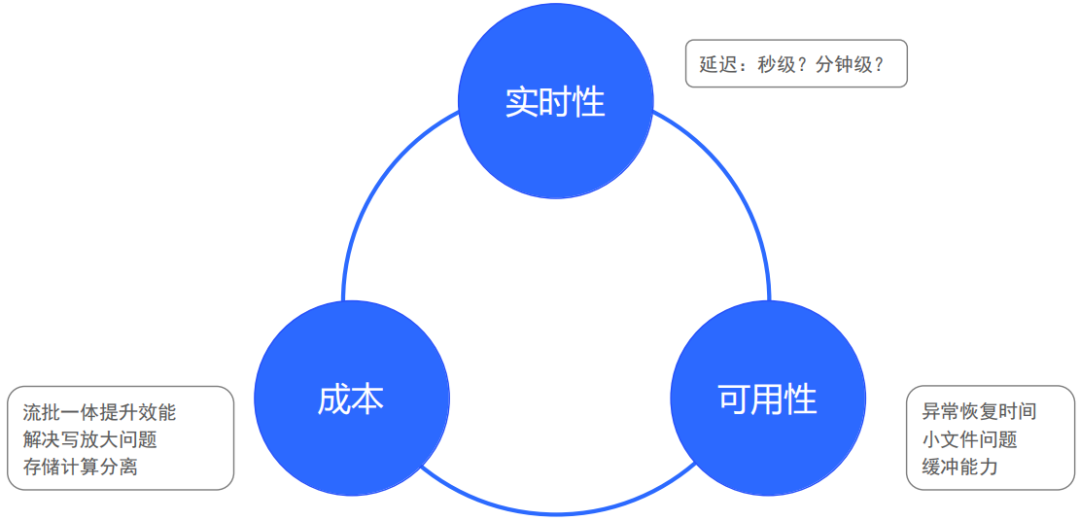
在構(gòu)建實(shí)時(shí)數(shù)倉(cāng)時(shí),我們通常需要考慮三個(gè)重要的環(huán)節(jié):
實(shí)時(shí)性,這個(gè)需要根據(jù)業(yè)務(wù)來(lái)確定延遲的等級(jí),是秒級(jí)呢?還是分鐘級(jí)?
可用性,因?yàn)樵礁叩膶?shí)時(shí)性意味著對(duì)可用性的要求越高,對(duì)異常恢復(fù)的時(shí)間要求更短,比如說(shuō)百度詞條的案例,你的實(shí)時(shí)性要求如果是分鐘級(jí)的,那么你發(fā)生故障了,一分鐘內(nèi)恢復(fù)不會(huì)產(chǎn)生太大的問(wèn)題,但是如果是秒級(jí)的話(huà),一分鐘可能就會(huì)釀成事故。同時(shí)低延遲的這種隨機(jī)IO更容易造成文件碎片化的問(wèn)題,所以我們需要對(duì)小文件進(jìn)行一個(gè)治理;在可用性方面,緩沖能力也尤為重要,我們的系統(tǒng)總會(huì)出現(xiàn)一定的峰值,比如說(shuō)雙十一0點(diǎn)的時(shí)候,流量可能是一年的峰值,但是出于成本考慮,我們不可能根據(jù)峰值無(wú)限的擴(kuò)容,因此我們要具備很強(qiáng)大的消息緩沖能力。
成本,實(shí)時(shí)計(jì)算的成本與數(shù)據(jù)體量是呈指數(shù)級(jí)增長(zhǎng)的,其中一個(gè)主要的原因就是寫(xiě)放大問(wèn)題,為了解決寫(xiě)放大問(wèn)題,我們展望了一個(gè)存算分離的存儲(chǔ)體系,降低compaction的頻率,并提供流批一體的API來(lái)提升效能。
本文主要講述了網(wǎng)易的實(shí)時(shí)數(shù)倉(cāng)的產(chǎn)品形態(tài),并結(jié)合實(shí)際的案例分析了網(wǎng)易實(shí)時(shí)數(shù)倉(cāng)目前面臨的難點(diǎn),一方面剖析了批計(jì)算與流計(jì)算各自的消耗情況,一方面剖析了現(xiàn)有存儲(chǔ)體系的存算不分離問(wèn)題,從而得出流計(jì)算的成本隨數(shù)據(jù)體量呈指數(shù)級(jí)增長(zhǎng)的結(jié)論,緊接著我們提出了一種存算分離且批流一體的存儲(chǔ)架構(gòu),通過(guò)剝離compaction,把compaction交給外部服務(wù)或者計(jì)算框架來(lái)實(shí)現(xiàn)存算分離,以及提供統(tǒng)一的API來(lái)同時(shí)支持批計(jì)算和流計(jì)算,最后我們淺談了數(shù)據(jù)倉(cāng)庫(kù)的等級(jí)劃分以及建設(shè)實(shí)時(shí)數(shù)倉(cāng)時(shí)需要考量的三個(gè)重要環(huán)節(jié)。