
美團外賣實時數(shù)倉建設(shè)實踐

01 實時場景
02 實時技術(shù)及架構(gòu)
1. 實時計算技術(shù)選型
2. 實時架構(gòu)
03 業(yè)務(wù)痛點
04 數(shù)據(jù)特點與應(yīng)用場景
05 實時數(shù)倉架構(gòu)設(shè)計
1. 實時架構(gòu):流批結(jié)合的探索
2. 實時數(shù)倉架構(gòu)設(shè)計
06 實時平臺化建設(shè)
1. 實時基礎(chǔ)層功能
2. 實時特征生產(chǎn)功能
3. SLA建設(shè)
4. 實時OLAP方案
07 實時應(yīng)用案例
01 實時場景
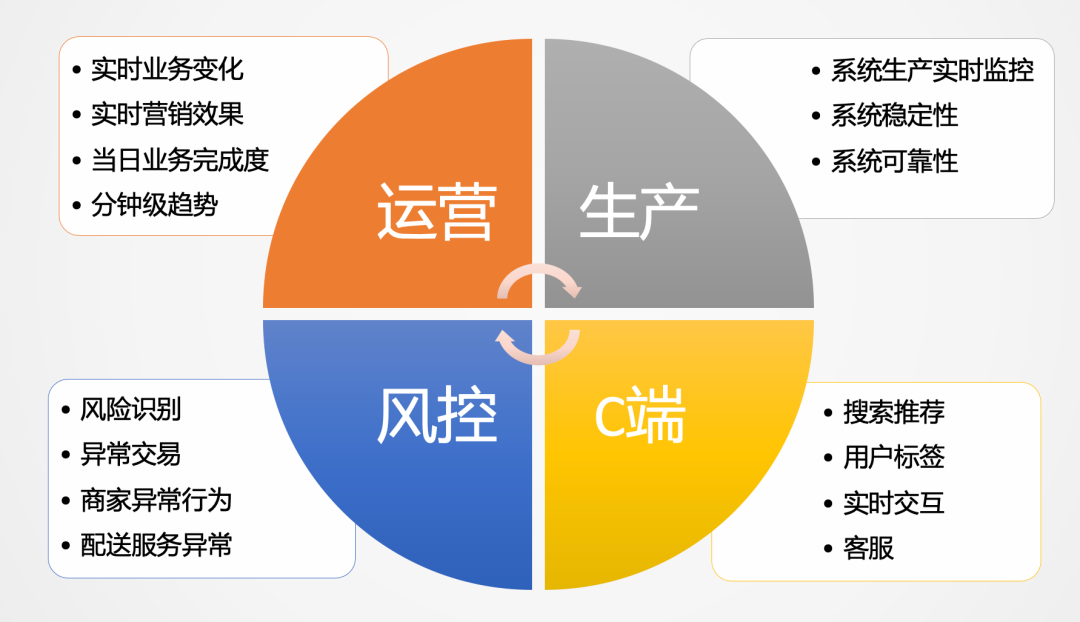
實時數(shù)據(jù)在美團外賣的場景是非常多的,主要有以下幾個方面:
運營層面:比如實時業(yè)務(wù)變化,實時營銷效果,當日營業(yè)情況以及當日分時業(yè)務(wù)趨勢分析等。 生產(chǎn)層面:比如實時系統(tǒng)是否可靠,系統(tǒng)是否穩(wěn)定,實時監(jiān)控系統(tǒng)的健康狀況等。 C端用戶:比如搜索推薦排序,需要實時行為、特點等特征變量的生產(chǎn),給用戶推薦更加合理的內(nèi)容。 風(fēng)控側(cè):實時風(fēng)險識別、反欺詐、異常交易等,都是大量應(yīng)用實時數(shù)據(jù)的場景。
02 實時技術(shù)及架構(gòu)
1. 實時計算技術(shù)選型
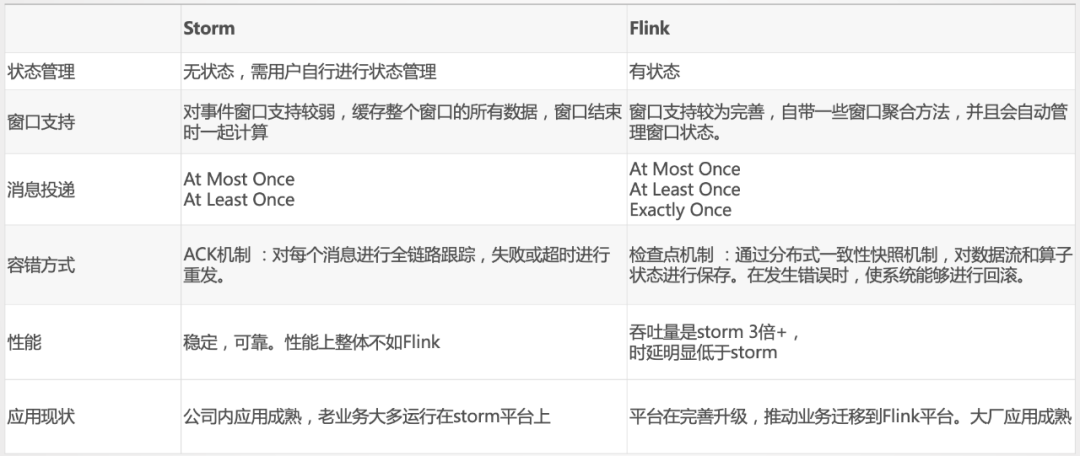
美團外賣依托于美團整體的基礎(chǔ)數(shù)據(jù)體系建設(shè),從技術(shù)成熟度來講,公司前幾年主要用的是Storm。當時的Storm,在性能穩(wěn)定性、可靠性以及擴展性上也是無可替代的。但隨著Flink越來越成熟,從技術(shù)性能上以及框架設(shè)計優(yōu)勢上已經(jīng)超越了Storm,從趨勢來講就像Spark替代MR一樣,Storm也會慢慢被Flink替代。當然,從Storm遷移到Flink會有一個過程,我們目前有一些老的任務(wù)仍然運行在Storm上,也在不斷推進任務(wù)遷移。
2. 實時架構(gòu)
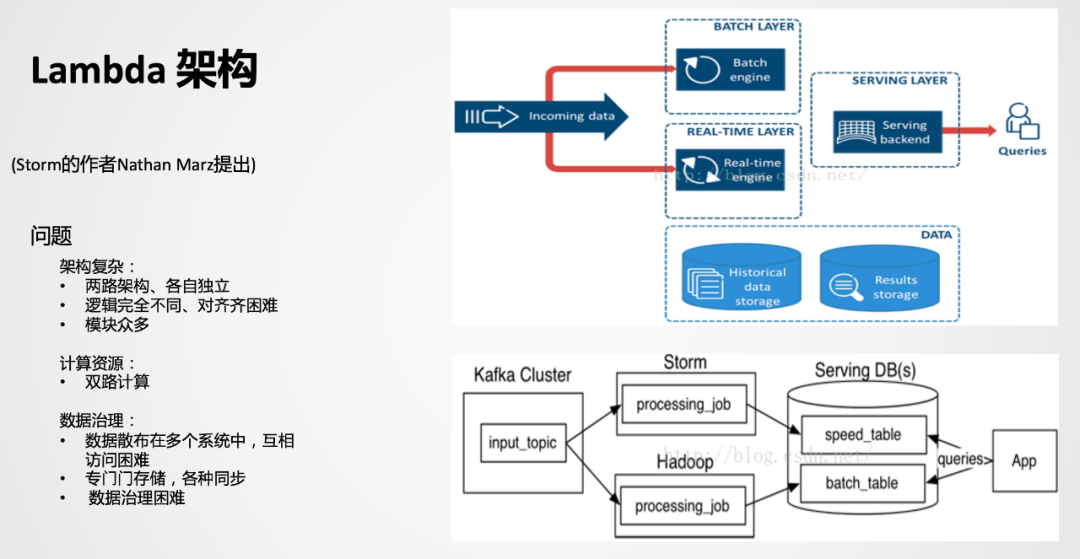
Lambda是比較經(jīng)典的一款架構(gòu),以前實時的場景不是很多,以離線為主,當附加了實時場景后,由于離線和實時的時效性不同,導(dǎo)致技術(shù)生態(tài)是不一樣的。而Lambda架構(gòu)相當于附加了一條實時生產(chǎn)鏈路,在應(yīng)用層面進行一個整合,雙路生產(chǎn),各自獨立。在業(yè)務(wù)應(yīng)用中,順理成章成為了一種被采用的方式。
② Kappa架構(gòu)

03 業(yè)務(wù)痛點
首先,在外賣業(yè)務(wù)上,我們遇到了一些問題和挑戰(zhàn)。在業(yè)務(wù)早期,為了滿足業(yè)務(wù)需要,一般是Case By Case地先把需求完成。業(yè)務(wù)對于實時性要求是比較高的,從時效性的維度來說,沒有進行中間層沉淀的機會。在這種場景下,一般是拿到業(yè)務(wù)邏輯直接嵌入,這是能想到的簡單有效的方法,在業(yè)務(wù)發(fā)展初期這種開發(fā)模式也比較常見。
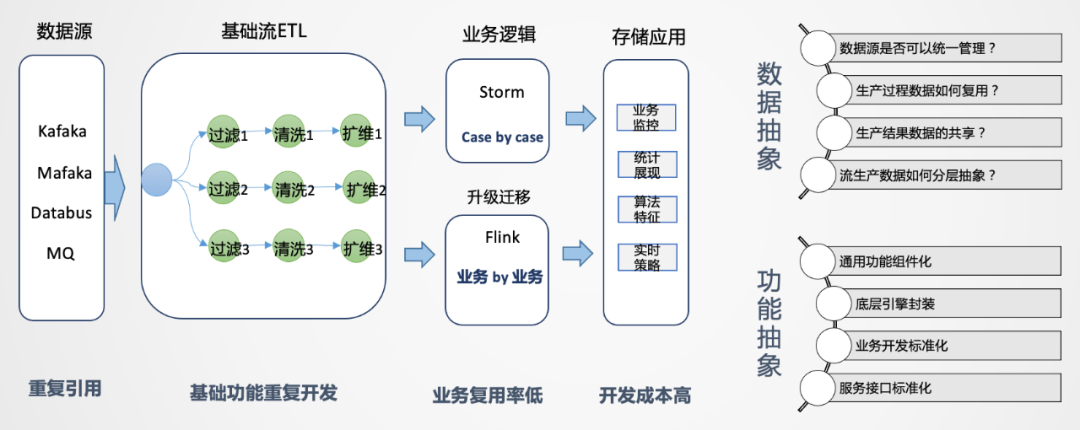
如上圖所示,拿到數(shù)據(jù)源后,我們會經(jīng)過數(shù)據(jù)清洗、擴維,通過Storm或Flink進行業(yè)務(wù)邏輯處理,最后直接進行業(yè)務(wù)輸出。把這個環(huán)節(jié)拆開來看,數(shù)據(jù)源端會重復(fù)引用相同的數(shù)據(jù)源,后面進行清洗、過濾、擴維等操作,都要重復(fù)做一遍。唯一不同的是業(yè)務(wù)的代碼邏輯是不一樣的,如果業(yè)務(wù)較少,這種模式還可以接受,但當后續(xù)業(yè)務(wù)量上去后,會出現(xiàn)誰開發(fā)誰運維的情況,維護工作量會越來越大,作業(yè)無法形成統(tǒng)一管理。而且所有人都在申請資源,導(dǎo)致資源成本急速膨脹,資源不能集約有效利用,因此要思考如何從整體來進行實時數(shù)據(jù)的建設(shè)。
04 數(shù)據(jù)特點與應(yīng)用場景
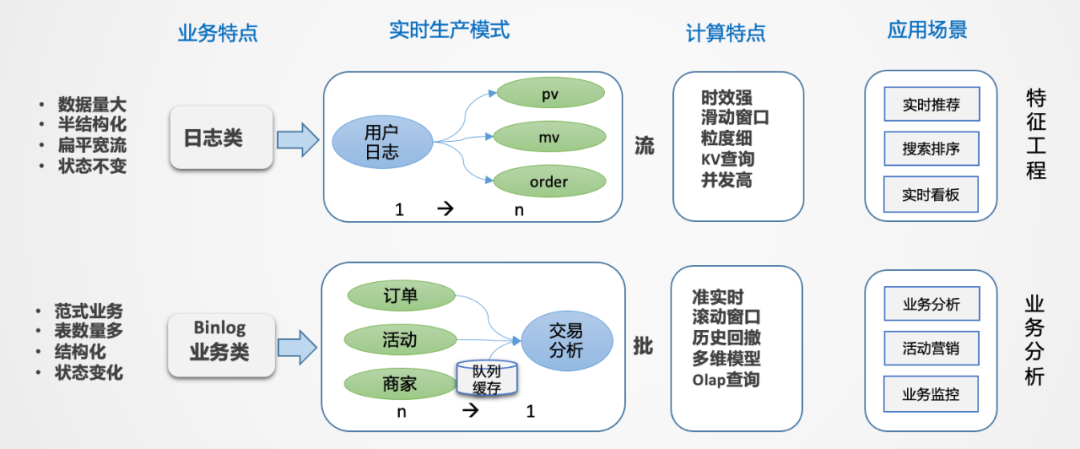
那么如何來構(gòu)建實時數(shù)倉呢?首先要進行拆解,有哪些數(shù)據(jù),有哪些場景,這些場景有哪些共同特點,對于外賣場景來說一共有兩大類,日志類和業(yè)務(wù)類。
日志類:數(shù)據(jù)量特別大,半結(jié)構(gòu)化,嵌套比較深。日志類的數(shù)據(jù)有個很大的特點,日志流一旦形成是不會變的,通過埋點的方式收集平臺所有的日志,統(tǒng)一進行采集分發(fā),就像一顆樹,樹根非常大,推到前端應(yīng)用的時候,相當于從樹根到樹枝分叉的過程(從1到n的分解過程)。如果所有的業(yè)務(wù)都從根上找數(shù)據(jù),看起來路徑最短,但包袱太重,數(shù)據(jù)檢索效率低。日志類數(shù)據(jù)一般用于生產(chǎn)監(jiān)控和用戶行為分析,時效性要求比較高,時間窗口一般是5min或10min,或截止到當前的一個狀態(tài),主要的應(yīng)用是實時大屏和實時特征,例如用戶每一次點擊行為都能夠立刻感知到等需求。 業(yè)務(wù)類:主要是業(yè)務(wù)交易數(shù)據(jù),業(yè)務(wù)系統(tǒng)一般是自成體系的,以Binlog日志的形式往下分發(fā),業(yè)務(wù)系統(tǒng)都是事務(wù)型的,主要采用范式建模方式。特點是結(jié)構(gòu)化,主體非常清晰,但數(shù)據(jù)表較多,需要多表關(guān)聯(lián)才能表達完整業(yè)務(wù),因此是一個n到1的集成加工過程。
業(yè)務(wù)的多狀態(tài)性:業(yè)務(wù)過程從開始到結(jié)束是不斷變化的,比如從下單->支付->配送,業(yè)務(wù)庫是在原始基礎(chǔ)上進行變更的,Binlog會產(chǎn)生很多變化的日志。而業(yè)務(wù)分析更加關(guān)注最終狀態(tài),由此產(chǎn)生數(shù)據(jù)回撤計算的問題,例如10點下單,13點取消,但希望在10點減掉取消單。 業(yè)務(wù)集成:業(yè)務(wù)分析數(shù)據(jù)一般無法通過單一主體表達,往往是很多表進行關(guān)聯(lián),才能得到想要的信息,在實時流中進行數(shù)據(jù)的合流對齊,往往需要較大的緩存處理且復(fù)雜。 分析是批量的,處理過程是流式的:對單一數(shù)據(jù),無法形成分析,因此分析對象一定是批量的,而數(shù)據(jù)加工是逐條的。
05 實時數(shù)倉架構(gòu)設(shè)計
1. 實時架構(gòu):流批結(jié)合的探索
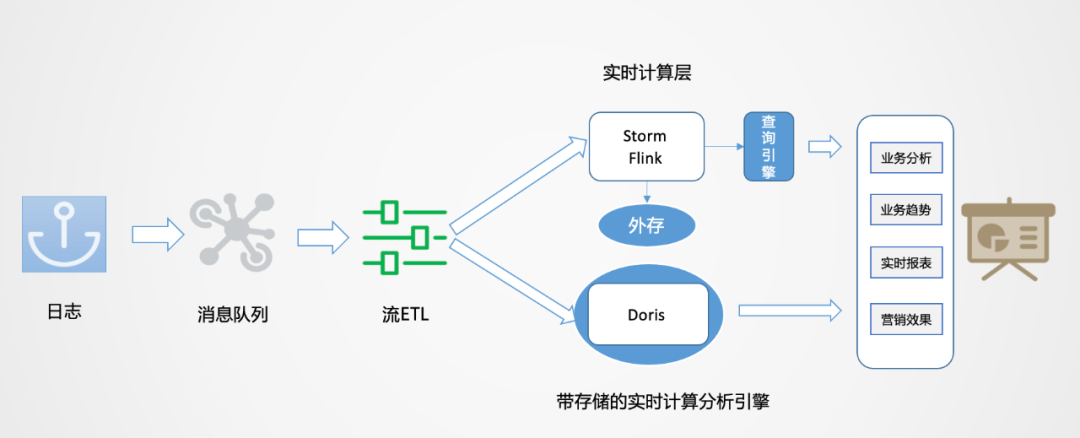
如上圖所示,數(shù)據(jù)從日志統(tǒng)一采集到消息隊列,再到數(shù)據(jù)流的ETL過程,作為基礎(chǔ)數(shù)據(jù)流的建設(shè)是統(tǒng)一的。之后對于日志類實時特征,實時大屏類應(yīng)用走實時流計算。對于Binlog類業(yè)務(wù)分析走實時OLAP批處理。
2. 實時數(shù)倉架構(gòu)設(shè)計
數(shù)據(jù)源:在數(shù)據(jù)源的層面,離線和實時在數(shù)據(jù)源是一致的,主要分為日志類和業(yè)務(wù)類,日志類又包括用戶日志、DB日志以及服務(wù)器日志等。 實時明細層:在明細層,為了解決重復(fù)建設(shè)的問題,要進行統(tǒng)一構(gòu)建,利用離線數(shù)倉的模式,建設(shè)統(tǒng)一的基礎(chǔ)明細數(shù)據(jù)層,按照主題進行管理,明細層的目的是給下游提供直接可用的數(shù)據(jù),因此要對基礎(chǔ)層進行統(tǒng)一的加工,比如清洗、過濾、擴維等。 匯總層:匯總層通過Flink或Storm的簡潔算子直接可以算出結(jié)果,并且形成匯總指標池,所有的指標都統(tǒng)一在匯總層加工,所有人按照統(tǒng)一的規(guī)范管理建設(shè),形成可復(fù)用的匯總結(jié)果。
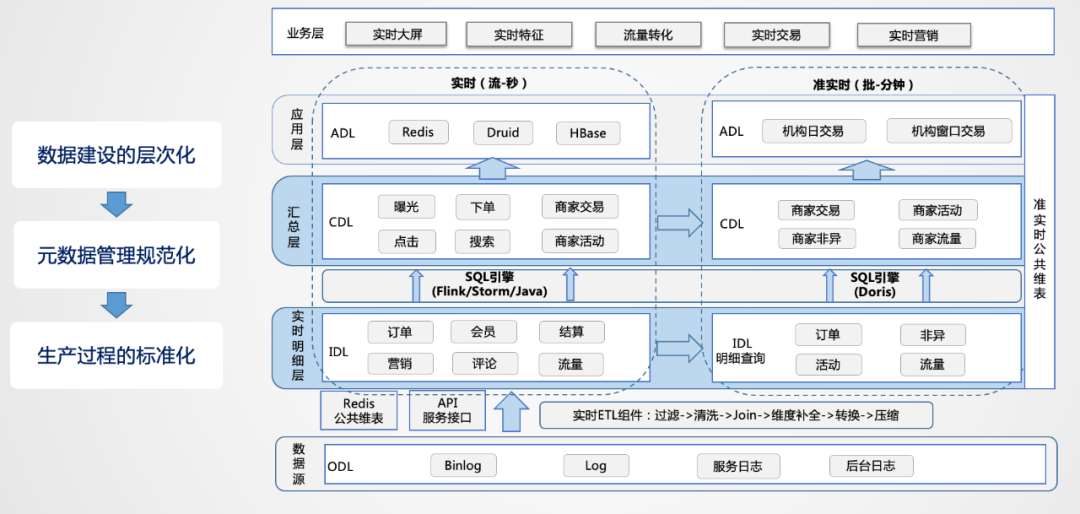
總結(jié)起來,從整個實時數(shù)倉的建設(shè)角度來講,首先數(shù)據(jù)建設(shè)的層次化要先建出來,先搭框架,然后定規(guī)范,每一層加工到什么程度,每一層用什么樣的方式,當規(guī)范定義出來后,便于在生產(chǎn)上進行標準化的加工。由于要保證時效性,設(shè)計的時候,層次不能太多,對于實時性要求比較高的場景,基本可以走上圖左側(cè)的數(shù)據(jù)流,對于批量處理的需求,可以從實時明細層導(dǎo)入到實時OLAP引擎里,基于OLAP引擎自身的計算和查詢能力進行快速的回撤計算,如上圖右側(cè)的數(shù)據(jù)流。
06 實時平臺化建設(shè)
架構(gòu)確定之后,我們后面考慮的是如何進行平臺化的建設(shè),實時平臺化建設(shè)是完全附加于實時數(shù)倉管理之上進行的。
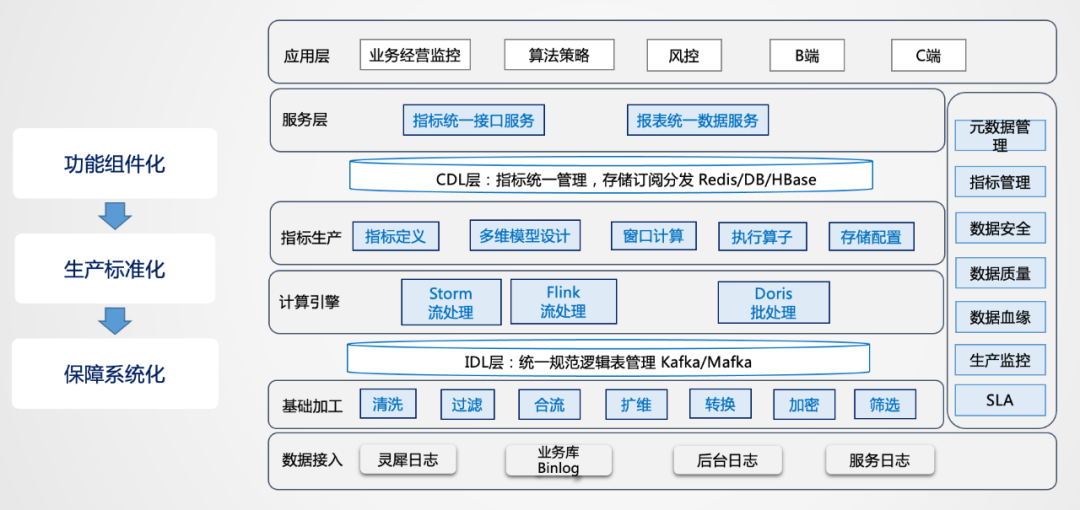
首先進行功能的抽象,把功能抽象成組件,這樣就可以達到標準化的生產(chǎn),系統(tǒng)化的保障就可以更深入的建設(shè),對于基礎(chǔ)加工層的清洗、過濾、合流、擴維、轉(zhuǎn)換、加密、篩選等功能都可以抽象出來,基礎(chǔ)層通過這種組件化的方式構(gòu)建直接可用的數(shù)據(jù)結(jié)果流。這會產(chǎn)生一個問題,用戶的需求多樣,為了滿足了這個用戶,如何兼容其他的用戶,因此可能會出現(xiàn)冗余加工的情況。從存儲的維度來講,實時數(shù)據(jù)不存歷史,不會消耗過多的存儲,這種冗余是可以接受的,通過冗余的方式可以提高生產(chǎn)效率,是一種以空間換時間思想的應(yīng)用。
1. 實時基礎(chǔ)層功能
實時基礎(chǔ)層的建設(shè)要解決一些問題。首先是一條流重復(fù)讀的問題,一條Binlog打過來,是以DB包的形式存在的,用戶可能只用其中一張表,如果大家都要用,可能存在所有人都要接這個流的問題。解決方案是可以按照不同的業(yè)務(wù)解構(gòu)出來,還原到基礎(chǔ)數(shù)據(jù)流層,根據(jù)業(yè)務(wù)的需要做成范式結(jié)構(gòu),按照數(shù)倉的建模方式進行集成化的主題建設(shè)。
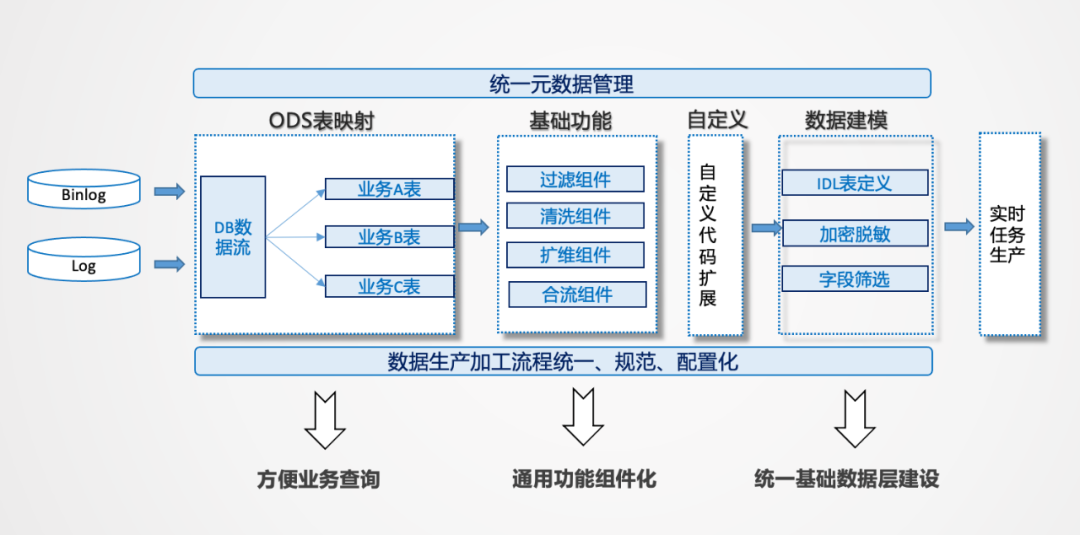
2. 實時特征生產(chǎn)功能
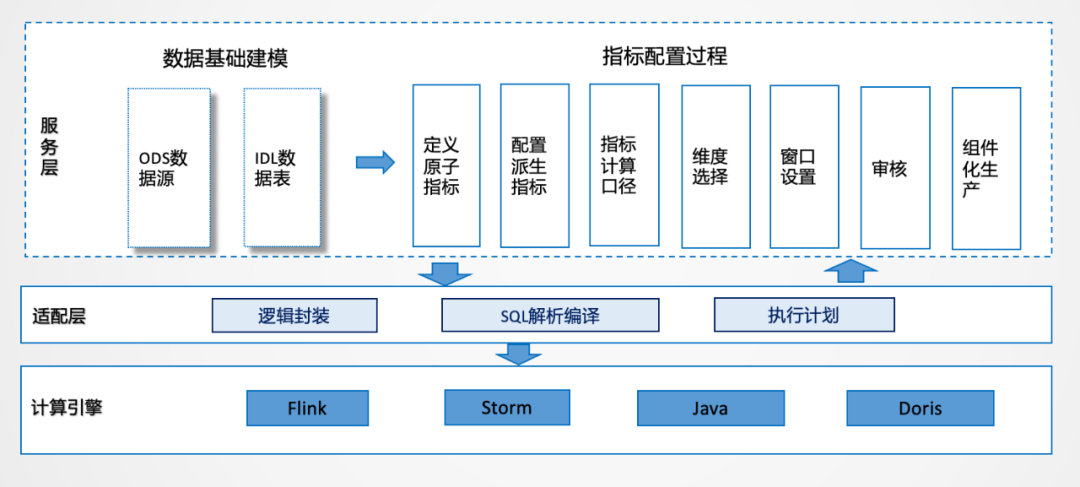
在功能層面,把指標管理的思想融合進去,原子指標、派生指標,標準計算口徑,維度選擇,窗口設(shè)置等操作都可以通過配置化的方式,這樣可以統(tǒng)一解析生產(chǎn)邏輯,進行統(tǒng)一封裝。
3. SLA建設(shè)

在實時生產(chǎn)中,由于鏈路非常長,無法控制所有鏈路,但是可以控制自己作業(yè)的效率,所以作業(yè)SLA也是必不可少的。
4. 實時OLAP方案
Binlog業(yè)務(wù)還原復(fù)雜:業(yè)務(wù)變化很多,需要某個時間點的變化,因此需要進行排序,并且數(shù)據(jù)要存起來,這對于內(nèi)存和CPU的資源消耗都是非常大的。 Binlog業(yè)務(wù)關(guān)聯(lián)復(fù)雜:流式計算里,流和流之間的關(guān)聯(lián),對于業(yè)務(wù)邏輯的表達是非常困難的。
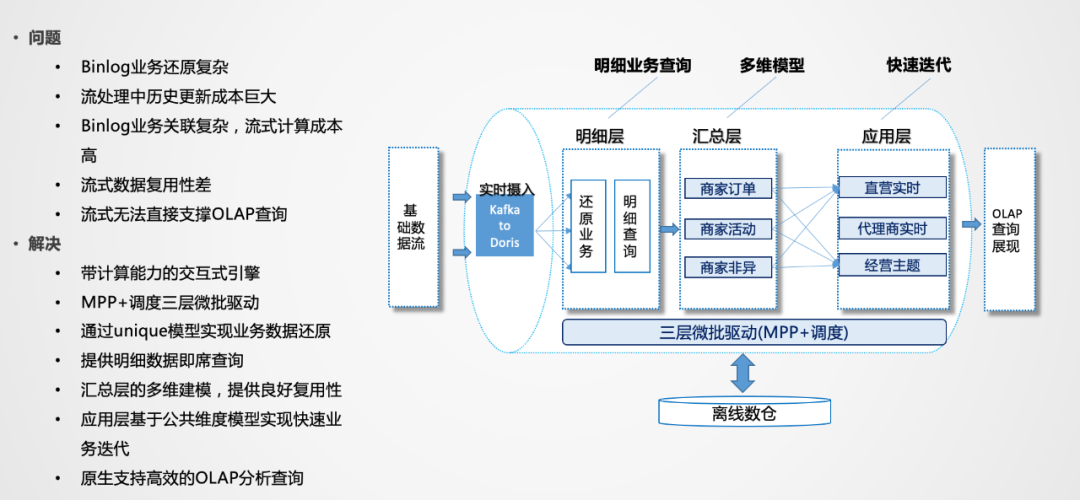
我們這邊采用的是Doris作為高性能的OLAP引擎,由于業(yè)務(wù)數(shù)據(jù)產(chǎn)生的結(jié)果和結(jié)果之間還需要進行衍生計算,Doris可以利用Unique模型或聚合模型快速還原業(yè)務(wù),還原業(yè)務(wù)的同時還可以進行匯總層的聚合,也是為了復(fù)用而設(shè)計。應(yīng)用層可以是物理的,也可以是邏輯化視圖。
07 實時應(yīng)用案例
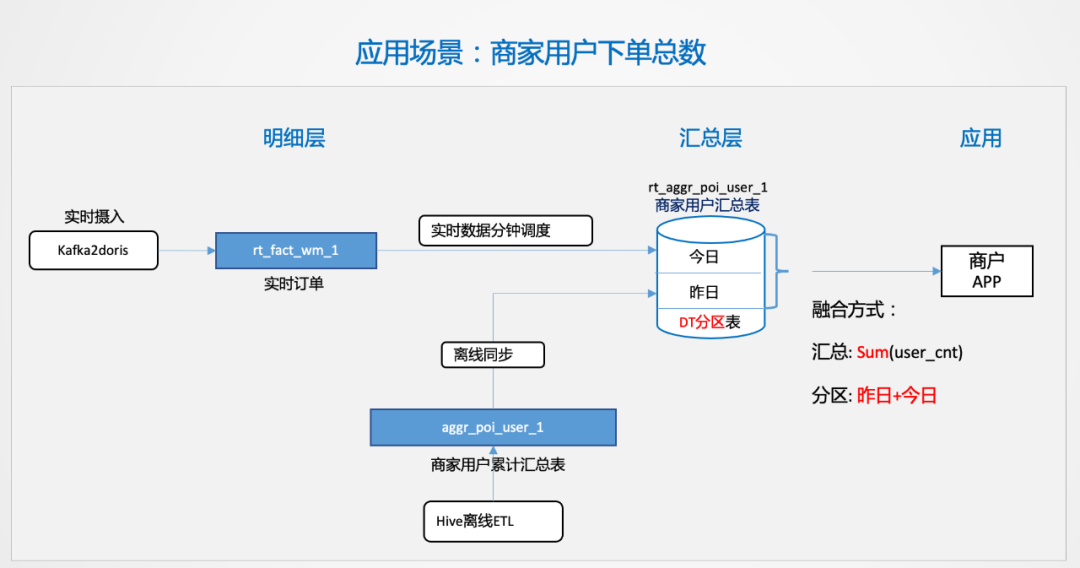
這種場景看起來比較簡單,難點在于商家的量上來之后,很多簡單的問題都會變得復(fù)雜。后續(xù),我們也會通過更多的業(yè)務(wù)輸入,沉淀出更多的業(yè)務(wù)場景,抽象出來形成統(tǒng)一的生產(chǎn)方案和功能,以最小化的實時計算資源支撐多樣化的業(yè)務(wù)需求,這也是未來我們需要達到的目的。