
分庫(kù)分表后如何設(shè)計(jì)索引?全局索引、二級(jí)索引
大家好,我是小富~
文末送書了!!!(這本書挺貴)
分布式數(shù)據(jù)庫(kù)架構(gòu)下,索引的設(shè)計(jì)也需要做調(diào)整,否則無法充分發(fā)揮分布式架構(gòu)線性可擴(kuò)展的優(yōu)勢(shì)。今天我們就來聊聊 “在分布式數(shù)據(jù)庫(kù)架構(gòu)下,如何正確的設(shè)計(jì)索引?”
主鍵選擇
對(duì)主鍵來說,要保證在所有分片中都唯一,它本質(zhì)上就是一個(gè)全局唯一的索引。如果用大部分同學(xué)喜歡的自增作為主鍵,就會(huì)發(fā)現(xiàn)存在很大的問題。
因?yàn)樽栽霾⒉荒茉诓迦肭熬瞳@得值,而是要通過填 NULL 值,然后再通過函數(shù) last_insert_id()獲得自增的值。所以,如果在每個(gè)分片上通過自增去實(shí)現(xiàn)主鍵,可能會(huì)出現(xiàn)同樣的自增值存在于不同的分片上。
比如,對(duì)于電商的訂單表 orders,其表結(jié)構(gòu)如下(分片鍵是o_custkey,表的主鍵是o_orderkey):
CREATE?TABLE?`orders`?(
??`O_ORDERKEY`?int?NOT?NULL?auto_increment,
??`O_CUSTKEY`?int?NOT?NULL,
??`O_ORDERSTATUS`?char(1)?NOT?NULL,
??`O_TOTALPRICE`?decimal(15,2)?NOT?NULL,
??`O_ORDERDATE`?date?NOT?NULL,
??`O_ORDERPRIORITY`?char(15)?NOT?NULL,
??`O_CLERK`?char(15)?NOT?NULL,
??`O_SHIPPRIORITY`?int?NOT?NULL,
??`O_COMMENT`?varchar(79)?NOT?NULL,
??PRIMARY?KEY?(`O_ORDERKEY`),
??KEY?(`O_CUSTKEY`)
??......
)?ENGINE=InnoDB
如果把 o_orderkey 設(shè)計(jì)成上圖所示的自增,那么很可能 o_orderkey 同為 1 的記錄在不同的分片出現(xiàn),如下圖所示:
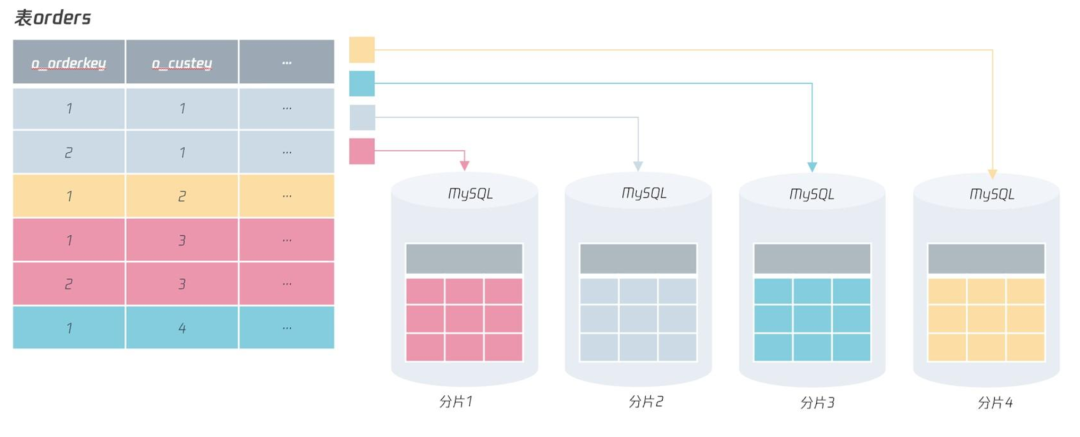
所以,在分布式數(shù)據(jù)庫(kù)架構(gòu)下,盡量不要用自增作為表的主鍵:自增性能很差、安全性不高、不適用于分布式架構(gòu)。
講到這兒,我們已經(jīng)說明白了“自增主鍵”的所有問題,那么該如何設(shè)計(jì)主鍵呢?依然還是用全局唯一的鍵作為主鍵,比如 MySQL 自動(dòng)生成的有序 UUID;業(yè)務(wù)生成的全局唯一鍵(比如發(fā)號(hào)器);或者是開源的 UUID 生成算法,比如雪花算法(但是存在時(shí)間回溯的問題)。
總之,用有序的全局唯一替代自增,是這個(gè)時(shí)代數(shù)據(jù)庫(kù)主鍵的主流設(shè)計(jì)標(biāo)準(zhǔn),如果你還停留在用自增做主鍵,或許代表你已經(jīng)落后于時(shí)代發(fā)展了。
索引設(shè)計(jì)
通過分片鍵可以把 SQL 查詢路由到指定的分片,但是在現(xiàn)實(shí)的生產(chǎn)環(huán)境中,業(yè)務(wù)還要通過其他的索引訪問表。
還是以前面的表 orders 為例,如果業(yè)務(wù)還要根據(jù) o_orderkey 字段進(jìn)行查詢,比如查詢訂單 ID 為 1 的訂單詳情:
SELECT?*?FROM?orders?WHERE?o_orderkey?=?1
我們可以看到,由于分片規(guī)則不是分片鍵,所以需要查詢 4 個(gè)分片才能得到最終的結(jié)果,如果下面有 1000 個(gè)分片,那么就需要執(zhí)行 1000 次這樣的 SQL,這時(shí)性能就比較差了。
但是,我們知道 o_orderkey 是主鍵,應(yīng)該只有一條返回記錄,也就是說,o_orderkey 只存在于一個(gè)分片中。這時(shí),可以有以下兩種設(shè)計(jì):
-
同一份數(shù)據(jù),表 orders 根據(jù) o_orderkey 為分片鍵,再做一個(gè)分庫(kù)分表的實(shí)現(xiàn);
-
在索引中額外添加分片鍵的信息。
這兩種設(shè)計(jì)的本質(zhì)都是通過冗余實(shí)現(xiàn)空間換時(shí)間的效果,否則就需要掃描所有的分片,當(dāng)分片數(shù)據(jù)非常多,效率就會(huì)變得極差。
而第一種做法通過對(duì)表進(jìn)行冗余,對(duì)于 o_orderkey 的查詢,只需要在 o_orderkey = 1 的分片中直接查詢就行,效率最高,但是設(shè)計(jì)的缺點(diǎn)又在于冗余數(shù)據(jù)量太大。
所以,改進(jìn)的做法之一是實(shí)現(xiàn)一個(gè)索引表,表中只包含 o_orderkey 和分片鍵 o_custkey,如:
CREATE?TABLE?idx_orderkey_custkey?(
??o_orderkey?INT
??o_custkey?INT,
??PRIMARY?KEY?(o_orderkey)
)
如果這張索引表很大,也可以將其分庫(kù)分表,但是它的分片鍵是 o_orderkey,如果這時(shí)再根據(jù)字段 o_orderkey 進(jìn)行查詢,可以進(jìn)行類似二級(jí)索引的回表實(shí)現(xiàn):先通過查詢索引表得到記錄 o_orderkey = 1 對(duì)應(yīng)的分片鍵 o_custkey 的值,接著再根據(jù) o_custkey 進(jìn)行查詢,最終定位到想要的數(shù)據(jù),如:
SELECT?*?FROM?orders?WHERE?o_orderkey?=?1
=>
#?step?1
SELECT?o_custkey?FROM?idx_orderkey_custkey?
WHERE?o_orderkey?=?1
#?step?2
SELECT?*?FROM?orders?
WHERE?o_custkey?=???AND?o_orderkey?=?1
這個(gè)例子是將一條 SQL 語句拆分成 2 條 SQL 語句,但是拆分后的 2 條 SQL 都可以通過分片鍵進(jìn)行查詢,這樣能保證只需要在單個(gè)分片中完成查詢操作。不論有多少個(gè)分片,也只需要查詢 2個(gè)分片的信息,這樣 SQL 的查詢性能可以得到極大的提升。
通過索引表的方式,雖然存儲(chǔ)上較冗余全表容量小了很多,但是要根據(jù)另一個(gè)分片鍵進(jìn)行數(shù)據(jù)的存儲(chǔ),依然顯得不夠優(yōu)雅。
因此,最優(yōu)的設(shè)計(jì),不是創(chuàng)建一個(gè)索引表,而是將分片鍵的信息保存在想要查詢的列中,這樣通過查詢的列就能直接知道所在的分片信息。
如果我們將訂單表 orders 的主鍵設(shè)計(jì)為一個(gè)字符串,這個(gè)字符串中最后一部分包含分片鍵的信息,如:
o_orderkey?=?string(o_orderkey?+?o_custkey)
那么這時(shí)如果根據(jù) o_orderkey 進(jìn)行查詢:
SELECT?*?FROM?Orders
WHERE?o_orderkey?=?'1000-1';
由于字段 o_orderkey 的設(shè)計(jì)中直接包含了分片鍵信息,所以我們可以直接知道這個(gè)訂單在分片1 中,直接查詢分片 1 就行。
同樣地,在插入時(shí),由于可以知道插入時(shí) o_custkey 對(duì)應(yīng)的值,所以只要在業(yè)務(wù)層做一次字符的拼接,然后再插入數(shù)據(jù)庫(kù)就行了。
這樣的實(shí)現(xiàn)方式較冗余表和索引表的設(shè)計(jì)來說,效率更高,查詢可以提前知道數(shù)據(jù)對(duì)應(yīng)的分片信息,只需 1 次查詢就能獲取想要的結(jié)果。
這樣實(shí)現(xiàn)的缺點(diǎn)是,主鍵值會(huì)變大一些,存儲(chǔ)也會(huì)相應(yīng)變大。但只要主鍵值是有序的,插入的性能就不會(huì)變差。而通過在主鍵值中保存分片信息,卻可以大大提升后續(xù)的查詢效率,這樣空間換時(shí)間的設(shè)計(jì),總體上看是非常值得的。
當(dāng)然,這里我們談的設(shè)計(jì)都是針對(duì)于唯一索引的設(shè)計(jì),如果是非唯一的二級(jí)索引查詢,那么非常可惜,依然需要掃描所有的分片才能得到最終的結(jié)果,如:
SELECT?*?FROM?Orders
WHERE?o_orderate?>=???o_orderdate?<??
因此,再次提醒你,分布式數(shù)據(jù)庫(kù)架構(gòu)設(shè)計(jì)的要求是業(yè)務(wù)的絕大部分請(qǐng)求能夠根據(jù)分片鍵定位到 1 個(gè)分片上。
如果業(yè)務(wù)大部分請(qǐng)求都需要掃描所有分片信息才能獲得最終結(jié)果,那么就不適合進(jìn)行分布式架構(gòu)的改造或設(shè)計(jì)。
最后,我們?cè)賮砘仡櫹绿詫氂脩粲唵伪淼脑O(shè)計(jì):
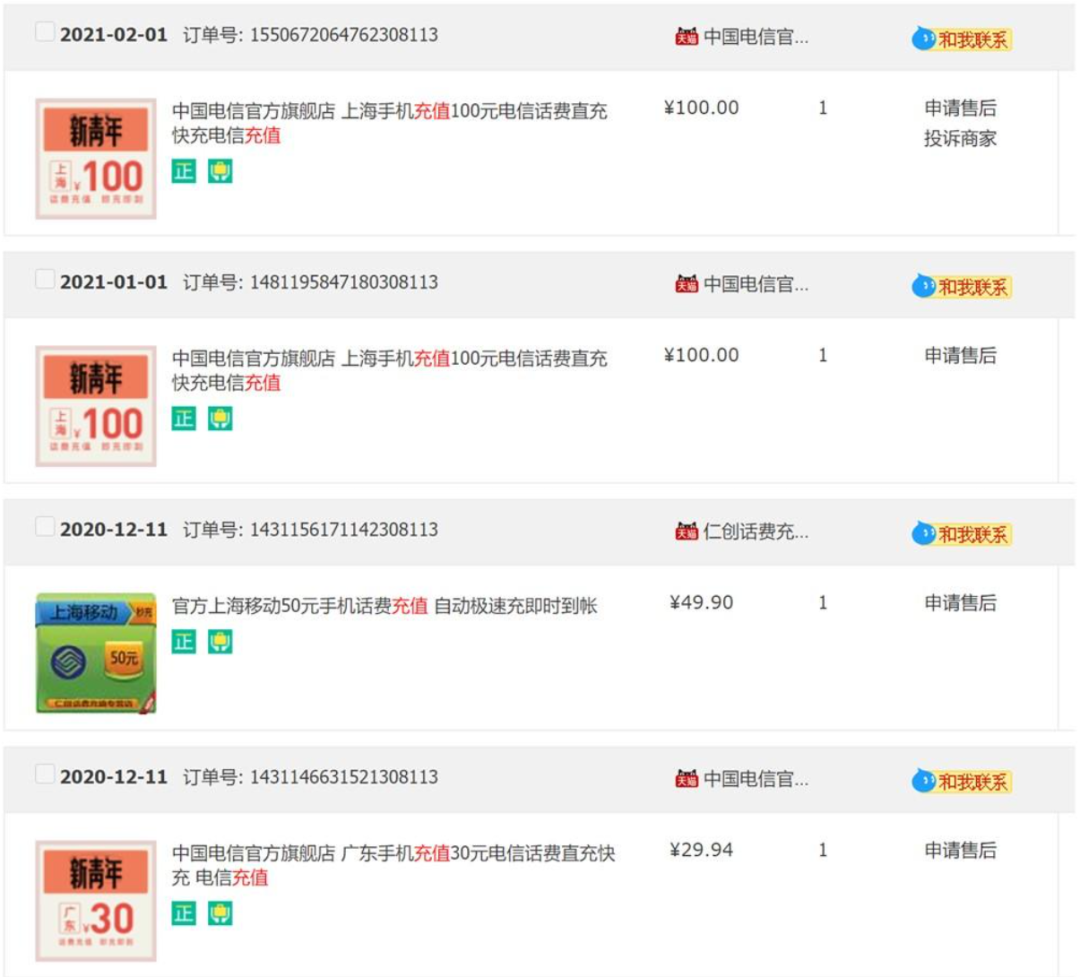
上圖是我的淘寶訂單信息,可以看到,訂單號(hào)的最后 6 位都是 308113,所以可以大概率推測(cè)出:
-
淘寶訂單表的分片鍵是用戶 ID;
-
淘寶訂單表,訂單表的主鍵包含用戶 ID,也就是分片信息。這樣通過訂單號(hào)進(jìn)行查詢,可以獲得分片信息,從而查詢 1 個(gè)分片就能得到最終的結(jié)果。
全局表
在分布式數(shù)據(jù)庫(kù)中,有時(shí)會(huì)有一些無法提供分片鍵的表,但這些表又非常小,一般用于保存一些全局信息,平時(shí)更新也較少,絕大多數(shù)場(chǎng)景僅用于查詢操作。
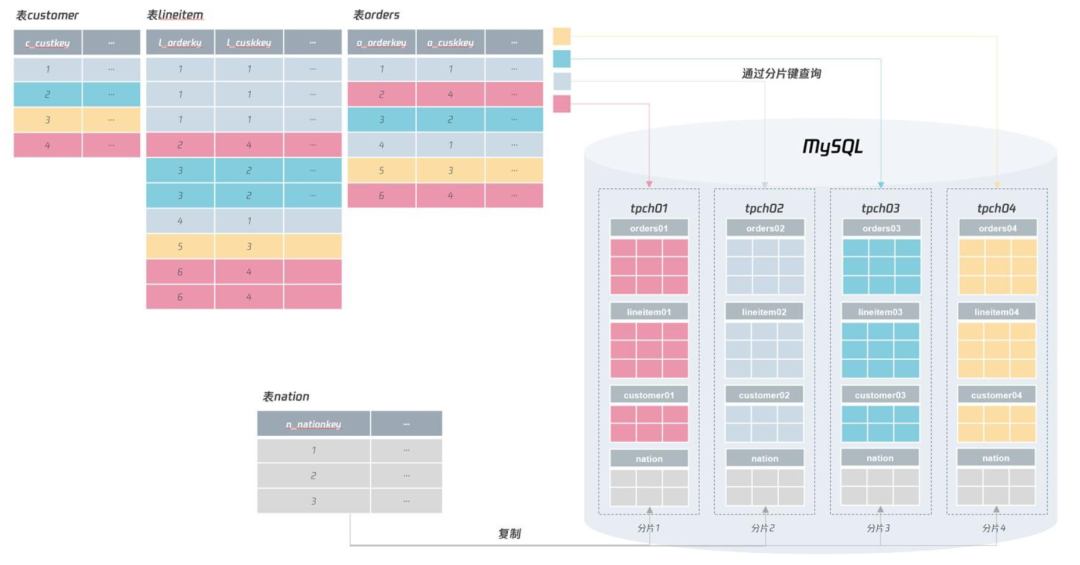
例如 tpch 庫(kù)中的表 nation,用于存儲(chǔ)國(guó)家信息,但是在我們前面的 SQL 關(guān)聯(lián)查詢中,又經(jīng)常會(huì)使用到這張表,對(duì)于這種全局表,可以在每個(gè)分片中存儲(chǔ),這樣就不用跨分片地進(jìn)行查詢了。如下面的設(shè)計(jì):
唯一索引
最后我們來談?wù)勎ㄒ凰饕脑O(shè)計(jì),與主鍵一樣,如果只是通過數(shù)據(jù)庫(kù)表本身唯一約束創(chuàng)建的索引,則無法保證在所有分片中都是唯一的。
所以,在分布式數(shù)據(jù)庫(kù)中,唯一索引一樣要通過類似主鍵的 UUID 的機(jī)制實(shí)現(xiàn),用全局唯一去替代局部唯一,但實(shí)際上,即便是單機(jī)的 MySQL 數(shù)據(jù)庫(kù)架構(gòu),我們也推薦使用全局唯一的設(shè)計(jì)。因?yàn)槟悴恢溃裁磿r(shí)候,你的業(yè)務(wù)就會(huì)升級(jí)到全局唯一的要求了。
總結(jié)
今天介紹了非常重要的分布式數(shù)據(jù)庫(kù)索引設(shè)計(jì),內(nèi)容非常干貨,是分布式架構(gòu)設(shè)計(jì)的重中之重,建議反復(fù)閱讀,抓住本文的重點(diǎn),總結(jié)來說:
-
分布式數(shù)據(jù)庫(kù)主鍵設(shè)計(jì)使用有序 UUID,全局唯一;
-
分布式數(shù)據(jù)庫(kù)唯一索引設(shè)計(jì)使用 UUID 的全局唯一設(shè)計(jì),避免局部索引導(dǎo)致的唯一問題;
-
分布式數(shù)據(jù)庫(kù)唯一索引若不是分片鍵,則可以在設(shè)計(jì)時(shí)保存分片信息,這樣查詢直接路由到一個(gè)分片即可;
-
對(duì)于分布式數(shù)據(jù)庫(kù)中的全局表,可以采用冗余機(jī)制,在每個(gè)分片上進(jìn)行保存。這樣能避免查詢時(shí)跨分片的查詢。
文末送書
為了感謝一路支持小富的小伙們,今天特地給大家送一點(diǎn)小福利。規(guī)則非常簡(jiǎn)單:在本文留言,按點(diǎn)贊數(shù)量排名,點(diǎn)贊數(shù)量最多的前3位,每人獲取1本書。(你可以發(fā)朋友圈集贊,或者發(fā)微信群集贊。但如果發(fā)現(xiàn)有人用機(jī)器刷點(diǎn)贊數(shù),立即取消資格,并且拉黑)
后面我會(huì)朋友圈公布中獎(jiǎng)名單(記得提前加我好友,提前加我好友,提前加我好友要不然領(lǐng)不到書),給你免費(fèi)包郵到家!這些書是由電子工業(yè)出版社提供的,感謝贊助。

▊ 《 深入理解Kafka與Pulsar:消息流平臺(tái)的實(shí)踐與剖析 》
梁國(guó)斌?著
本書詳細(xì)介紹了Kafka與Pulsar的使用方式,并深入分析了它們的實(shí)現(xiàn)機(jī)制。通過閱讀本書,讀者可以快速入門和使用Kafka與Pulsar,并深入理解它們的實(shí)現(xiàn)原理。
本書通過大量實(shí)踐示例介紹了Kafka與Pulsar的使用方式,包括管理腳本與客戶端(生產(chǎn)者、消費(fèi)者)的使用方式、關(guān)鍵的配置項(xiàng)、ACK提交方式等基礎(chǔ)應(yīng)用,以及安全機(jī)制、跨地域復(fù)制機(jī)制、連接器/流計(jì)算引擎、常用監(jiān)控管理平臺(tái)等高級(jí)應(yīng)用。這些內(nèi)容可以幫助讀者深入掌握Kafka與Pulsar的使用方式,并完成日常管理工作。另外,本書深入分析了Kafka與Pulsar的實(shí)現(xiàn)原理,包括客戶端(生產(chǎn)者、消費(fèi)者)的設(shè)計(jì)與實(shí)現(xiàn)、Broker網(wǎng)絡(luò)模型、主題(分區(qū))分配與負(fù)載均衡機(jī)制,以及磁盤存儲(chǔ)與性能優(yōu)化方案、數(shù)據(jù)同步機(jī)制、擴(kuò)容與故障轉(zhuǎn)移機(jī)制。最后,本書介紹了Kafka與Pulsar的事務(wù)機(jī)制,并深入分析了Kafka事務(wù)的實(shí)現(xiàn)及Kafka的分布式協(xié)作組件KRaft模塊。這部分內(nèi)容可以幫助讀者輕松理解Kafka與Pulsar的架構(gòu)設(shè)計(jì)與實(shí)現(xiàn)原理。
在看 、 點(diǎn)贊 、 轉(zhuǎn)發(fā) ,是對(duì)我最大的鼓勵(lì) 。
整理了些技術(shù)書籍,有需要的同學(xué)公眾號(hào)內(nèi)回復(fù)[? pdf ?]自取。
面試筆記、springcloud進(jìn)階實(shí)戰(zhàn)PDF,公眾號(hào)內(nèi)回復(fù)[? 1222 ?]自取。
技術(shù)群快滿了 ,想進(jìn)的同學(xué)可以加我好友,和大佬們一起吹吹技術(shù)。