
詳解 ZooKeeper 數(shù)據(jù)持久化

本文作者:HelloGitHub-老荀
Hi,這里是 HelloGitHub 推出的 HelloZooKeeper 系列,免費開源、有趣、入門級的 ZooKeeper 教程,面向有編程基礎(chǔ)的新手。
項目地址:https://github.com/HelloGitHub-Team/HelloZooKeeper
前一篇文章我們介紹了 ZK 是如何進(jìn)行選舉的,這篇我們開始學(xué)習(xí) ZK 是如何將數(shù)據(jù)持久化到磁盤中的。
一、優(yōu)秀員工小S(Sync)
我們通過之前的文章有介紹過,小S(Sync)負(fù)責(zé)對辦事處的數(shù)據(jù)進(jìn)行歸檔,所以今天他就是我們的主角,讓我們一起深入了解他的日常工作吧

為了喚醒大家的遠(yuǎn)古記憶,我放一張之前的圖片
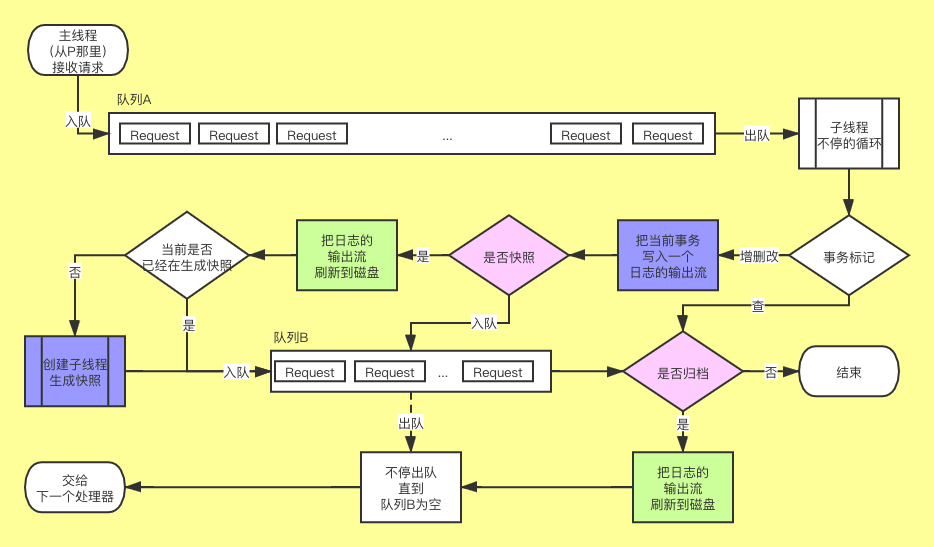
今天我們會重點講一下圖中的藍(lán)色部分,不過在此之前還是得先從整體架構(gòu)上介紹下 ZK 的數(shù)據(jù)管理,ZK 的數(shù)據(jù)大致是分為了兩部分,一個是內(nèi)存,一個就是磁盤文件。
1.1 內(nèi)存
雖然今天我們的主角是磁盤文件,但是內(nèi)存還是稍微再提一下下,幫助大家記憶的同時也能有一個比較全面的視角去認(rèn)知 ZK 整體的數(shù)據(jù)管理。
ZK 在內(nèi)存中的存儲就是之前故事中有提到的兩個賬本:小紅本和小黃本。如果排除作為回調(diào)通知記錄的小黃本,那 ZK 的內(nèi)存中就是小紅本對應(yīng)的哈希表而已,但是小黃本中的數(shù)據(jù)依然非常重要,所以需要將兩者作為整體一起看待,以及之前我有說過小F(Final)掌管了這兩個賬本,作為業(yè)務(wù)處理的最后一個負(fù)責(zé)人,小S(Sync) 從時間上來說是優(yōu)先于小F(Final)先處理的,所以 ZK 的設(shè)計是優(yōu)先將數(shù)據(jù)存入磁盤,再去修改內(nèi)存中的數(shù)據(jù)保證盡可能的提升數(shù)據(jù)的可靠性。下面我們繼續(xù)了解磁盤文件(還真就提一下下!)
1.2 磁盤文件
ZK 的開發(fā)者給 ZK 設(shè)計了兩種磁盤文件,對應(yīng)的路徑分別是 zoo.cfg 配置中的 dataDir 和 dataLogDir 這兩項目錄的配置。為了之后的描述清楚,我給這兩種磁盤文件起了名字:dataDir 對應(yīng) snapshot,dataLogDir 對應(yīng) log,log 就是的是小S(Sync)工作中的歸檔,snapshot 就是的是小S(Sync)工作中的快照。
log 是負(fù)責(zé)順序記錄每一個寫請求到文件,snapshot 則是直接將整個內(nèi)存對象持久化至文件中。假設(shè)我現(xiàn)在 zoo.cfg 的配置是這樣:
dataDir=/tmp/zookeeper/snapshot
dataLogDir=/tmp/zookeeper/log
當(dāng) ZK 啟動后會基于上面兩個路徑繼續(xù)創(chuàng)建 version-2 子路徑,之后的文件都會在該子路徑下創(chuàng)建
/tmp
└── zookeeper
├── snapshot
└── version-2
└── ...
└── log
└── version-2
└── ...
二、文件的創(chuàng)建和寫入
兩種文件分別是在什么時候被寫入磁盤的呢?寫入的內(nèi)容又是哪些呢?我們接下來對兩種文件一一進(jìn)行分析。
2.1 log 文件
log 文件名的格式是這樣 log.{zxid} zxid 對應(yīng)當(dāng)時創(chuàng)建該文件時的最大 zxid,假設(shè)現(xiàn)在創(chuàng)建時 zxid 為 0,那目錄結(jié)構(gòu)會是這樣:
/tmp
└── zookeeper
└── log
└── version-2
└── log.0
這個 log.0 文件創(chuàng)建的時機你也可以簡單的理解為當(dāng)服務(wù)端收到第一個寫請求的時候,而且當(dāng)創(chuàng)建完成后,并不能直接將數(shù)據(jù)寫入,而是要先寫一些文件頭的字段,比如大名鼎鼎的魔數(shù),版本號等元信息。
而 log 文件的魔數(shù)是 ZKLG(4 個字節(jié)),版本號固定為 2(4 個字節(jié)),還要記錄一個 dbId 固定為 0(8 個字節(jié)) (當(dāng)前沒用,可能之后會派用處吧),所以前 16 個字節(jié)是固定這樣的:
Z K L G 2 0
5A4B4C47 00000002 00000000 00000000
那之后的業(yè)務(wù)數(shù)據(jù)是如何記錄的呢?
每一個寫請求都可以分為四個部分:校驗和、請求頭、請求數(shù)據(jù)、簽名,校驗和是通過后面三個字段計算出來的,小S每次收到寫請求后都會按照這樣的順序?qū)?yīng)請求的四個字段寫入 log 文件,由于不同的業(yè)務(wù)請求數(shù)據(jù)不固定,而且數(shù)據(jù)長度也比較大,這里就不給大家展示具體的值(如果大家想要知道這硬核的存儲過程,不妨給我留言,我以后單獨做下,嘗試逐個字節(jié)解釋)

然后是 zookeeper.txnLogSizeLimitInKb 這個環(huán)境變量配置,默認(rèn)是 -1,這個配置限制了 log 單個文件大小(單位是 KB),每次小S(Sync)歸檔的時候(圖中右下角粉色部分“是否歸檔”),將數(shù)據(jù)統(tǒng)一刷到磁盤后,如果用戶手動配置了該參數(shù),就會檢查當(dāng)前 log 文件大小是否超過了該參數(shù)大小,如果超過了就會進(jìn)行 rollLog,相當(dāng)于下一次的寫請求會創(chuàng)建一個新的 log 文件。除此之外,當(dāng)小S(Sync)每次快照的時候會強制執(zhí)行一次 rollLog。
2.2 snapshot 文件
snapshot 文件名的格式是這樣 snapshot.{zxid} zxid 對應(yīng)當(dāng)是創(chuàng)建該文件時的最大 zxid,假設(shè)現(xiàn)在創(chuàng)建是最大 zxid 是 0,那目錄結(jié)構(gòu)會是這樣:
/tmp
└── zookeeper
└── snapshot
└── version-2
└── snapshot.0
而關(guān)于是否快照(圖中中間區(qū)域粉色部分“是否快照”),之前有簡單介紹過是和隨機數(shù)有關(guān),這次我們深入了解下。
首先有兩個配置 zookeeper.snapCount (默認(rèn) 100000)和 zookeeper.snapSizeLimitInKb(默認(rèn) 4194304 單位是KB,相當(dāng)于 4 GB)在啟動后會基于這兩個配置分別生成兩個隨機數(shù),假設(shè)上述的配置是按照默認(rèn)的設(shè)置,這兩個隨機數(shù)的范圍就是:
randRoll = [0, 50000]
randSize = [0, 4194304 * 1024 / 2]
可以簡單的認(rèn)為就是上述兩個配置的一半之內(nèi)的隨機數(shù),至于 randSize 為什么要乘以 1024 因為最終文件計算大小是以 byte 作為單位的。
而是否快照就是取決于上面兩個隨機數(shù),有兩個條件:
當(dāng)前寫請求的數(shù)量達(dá)到了 zookeeper.snapCount的一半并加上randRoll的數(shù)量當(dāng)前 log 文件的大小達(dá)到了 zookeeper.snapSizeLimitInKb的一半并加上randSize的大小
上述條件滿足任意一個條件后就會重置上面的兩個隨機數(shù),并開始生成快照,生成快照這個過程是啟動一個子線程去創(chuàng)建的。
snapshot 和 log 還有個不同的地方就是,snapshot 文件 ZK 提供了三種不同的壓縮實現(xiàn),GZIP、SNAPPY、CHECKED,通過 zookeeper.snapshot.compression.method 進(jìn)行配置,默認(rèn)是 CHECKED,就是原始按照字節(jié)順序?qū)懭耄硗鈨蓚€這里就不展開了。那我們接下來看看 snapshot 文件是怎么記的吧。
和 log 文件一樣,也要先記一些文件的頭部字段,而 snapshot 文件的魔數(shù)是 ZKSN(4 個字節(jié)),版本號固定為 2(4 個字節(jié)),還要記錄一個 dbId 固定為 -1(8 個字節(jié)) (當(dāng)前沒用,可能之后會派用處吧),所以前 16 個字節(jié)是固定這樣的:
Z K S N 2 -1
5A4B534E 00000002 FFFFFFFF FFFFFFFF
然后緊跟其后的部分客戶端的會話信息,客戶端的數(shù)量,然后循環(huán)記錄每一個客戶端的 sessionId、超時時間,然后是小紅本里的所有信息了包括但不限于 ACL,節(jié)點的統(tǒng)計數(shù)據(jù),節(jié)點的數(shù)據(jù),子節(jié)點的信息等。最后一部分就是校驗和和簽名。和 log 一樣,如果大家有興趣的話,我之后單獨再做一篇逐個字節(jié)講解的。
三、從文件中恢復(fù)
如果只是單單存文件,那這文件也沒什么用,所以文件另一個重要用途就是幫助 ZK 恢復(fù)服務(wù)端的信息。
在 ZK 啟動的時候就會嘗試讀取 dataDir 和 dataLogDir 這兩個目錄下的文件,假設(shè)在這兩個路徑下的文件是:
/tmp
└── zookeeper
├── snapshot
└── version-2
└── snapshot.5
└── snapshot.37
└── snapshot.100
└── log
└── version-2
└── log.0
└── log.6
└── log.38
└── log.90
└── log.108
我這里例子中的文件名的后綴數(shù)字是我隨便舉例只是為了說明恢復(fù)的過程,實際未必是這樣,切記。
現(xiàn)在 ZK 服務(wù)端啟動后,會先從 snapshot 的目錄中找到 zxid 最大的那個文件,然后根據(jù)它的內(nèi)容恢復(fù)小紅本
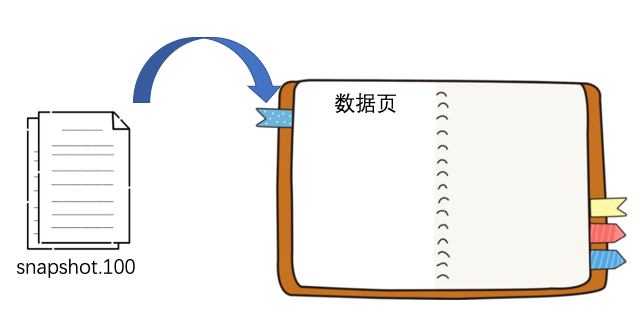
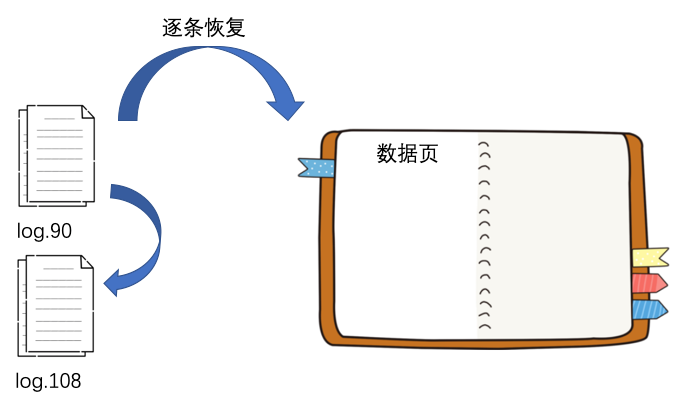
恢復(fù)完后就會去 log 文件目錄下尋找所有比 100 要大的 log 文件以及比 100 要略小一點的 log 文件,本例子中就是 log.90 和 log.108 這兩個文件。
你可能會問為什么要找小于 100 的 log.90 這個文件呢?因為文件名中的 90 只是說明這個文件建立的時候,最大的 zxid 是 90,但是文件中記錄的寫請求是很有可能會大于 100 的,所以 log.90 也需要被找到。
然后就是從 log.90 這個文件開始恢復(fù),先從 zxid 比 100 大的寫請求開始讀取并執(zhí)行該寫請求,然后繼續(xù)讀取 log.108,等待所有符合條件的 log 文件讀取后,整個 ZK 的數(shù)據(jù)就恢復(fù)完成了。
四、總結(jié)
今天我們介紹了關(guān)于 ZK 持久化的知識:
ZK 會持久化到磁盤的文件有兩種:log 和 snapshot log 負(fù)責(zé)記錄每一個寫請求 snapshot 負(fù)責(zé)對當(dāng)前整個內(nèi)存數(shù)據(jù)進(jìn)行快照 恢復(fù)數(shù)據(jù)的時候,會先讀取最新的 snapshot 文件 然后在根據(jù) snapshot 最大的 zxid 去搜索符合條件的 log 文件,再通過逐條讀取寫請求來恢復(fù)剩余的數(shù)據(jù)
今天的內(nèi)容還是比較簡單的,為我們下一篇文章打好了基礎(chǔ)~下一篇我們開始介紹之前選舉中沒有介紹的內(nèi)容:選舉完成后,F(xiàn)ollower 和 Observer 是如何同 Leader 同步數(shù)據(jù)的?

老規(guī)矩,如果你有任何對文章中的疑問也可以是建議或者是對 ZK 原理部分的疑問,歡迎來倉庫中提問,或者閱讀原文來語雀話題討論。
地址:https://github.com/HelloGitHub-Team/HelloZooKeeper

??「點擊關(guān)注」更多驚喜等待你!