
淺談 Go 語言高性能哈希表的設計與實現(xiàn)
目錄
1. MatrixOne數(shù)據(jù)庫是什么?
2. 哈希表數(shù)據(jù)結構基礎
3. 哈希表基本設計與對性能的影響
????3.1 鏈地址法
????3.2 開放尋址法
????3.3 碰撞處理
????3.4 Max load factor
????3.5 Growth factor
????3.6 空閑桶探測方法
4. 一些常見的哈希表實現(xiàn)
????4.1C++?
????4.2std::unordered_map/boost::unordered_map
????4.3 go map
????4.4 swisstable
????4.5 ClickHouse的哈希表實現(xiàn)
5. 高效哈希表的設計與實現(xiàn)
????5.1 基本設計與參數(shù)選擇
????5.2 哈希函數(shù)
????5.3 特殊優(yōu)化
????5.4 具體實現(xiàn)代碼
6. 性能測試
????6.1 測試環(huán)境
????6.2 測試內容
????6.3 整數(shù)key結果
????6.4字符串key結果
7. 總結
1
MatrixOne數(shù)據(jù)庫是什么?
MatrixOne是一個新一代超融合異構數(shù)據(jù)庫,致力于打造單一架構處理TP、AP、流計算等多種負載的極簡大數(shù)據(jù)引擎。MatrixOne由Go語言所開發(fā),并已于2021年10月開源,目前已經(jīng)release到0.3版本。在MatrixOne已發(fā)布的性能報告中,與業(yè)界領先的OLAP數(shù)據(jù)庫Clickhouse相比也不落下風。作為一款Go語言實現(xiàn)的數(shù)據(jù)庫,居然可以與C++實現(xiàn)的頂級OLAP數(shù)據(jù)庫性能媲美,這其中就涉及到了很多方面的優(yōu)化,包括高性能哈希表的實現(xiàn),本文就將詳細說明MatrixOne是如何用Go實現(xiàn)高性能哈希表的。
Github地址:https://github.com/matrixorigin/matrixone
2
哈希表數(shù)據(jù)結構基礎
哈希表(Hashtable)是一種非常基礎的數(shù)據(jù)結構,對于數(shù)據(jù)庫的分組聚合和Join查詢的性能至關重要。以如下的分組聚合為例(備注,圖引自參考文獻1):
SELECT col, count(*) FROM table GROUP BY col
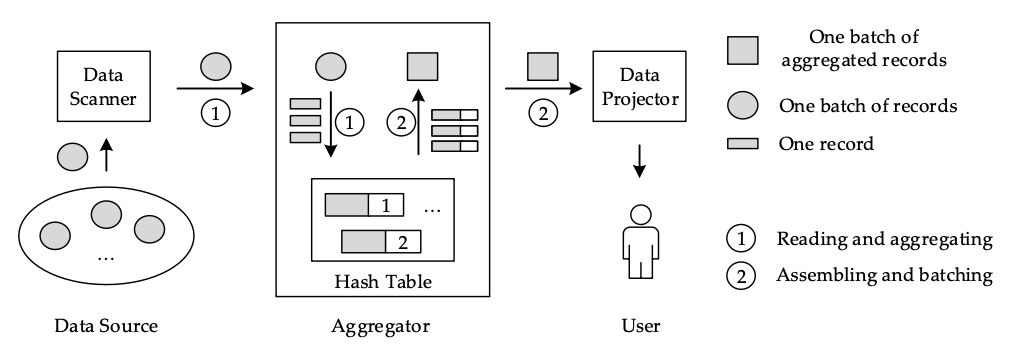
它包含兩個處理階段:第1階段是使用數(shù)據(jù)源的數(shù)據(jù)建立一個哈希表。哈希表中的每條記錄都與一個計數(shù)器有關。如果記錄是新插入的,相關的計數(shù)器被設置為1;否則,計數(shù)器被遞增。第二階段是將哈希表中的記錄集合成一種可用于進一步查詢處理的格式。
對于Join查詢而言,以如下SQL為例:
SELECT A.left_col, B.right_col FROM A JOIN B USING (key_col)
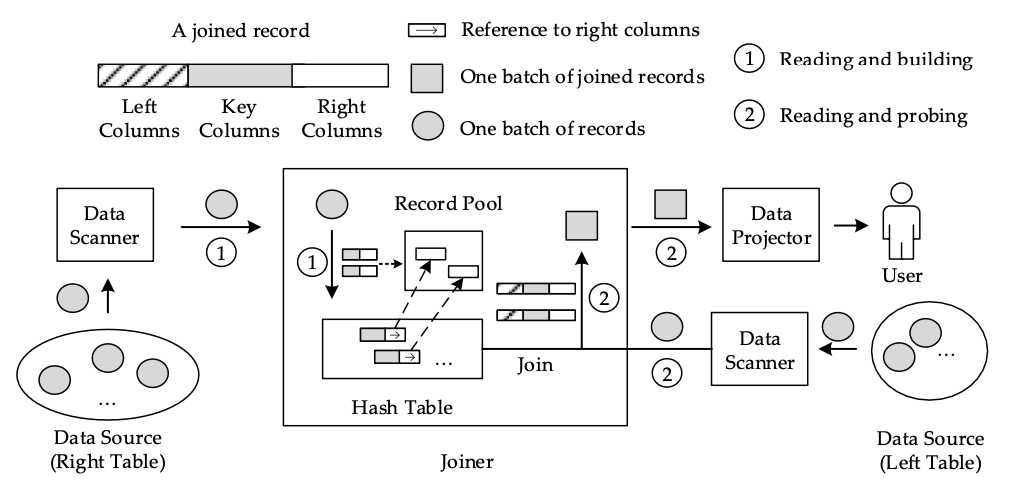
它同樣也有兩個階段:第一階段是使用Join語句右側表的數(shù)據(jù)建立一個哈希表,第二階段是從左側表中讀取數(shù)據(jù),并快速探測剛剛建立的哈希表。構建階段與上面的分組實現(xiàn)類似,但每個哈希表的槽位都存儲了對右邊列的引用。
由此可見,哈希表對于數(shù)據(jù)庫的SQL基礎能力起著很關鍵的作用 ,本文討論哈希表的基本設計與對性能的影響,比較各種常見哈希表實現(xiàn),然后介紹我們?yōu)镸atrixOne實現(xiàn)的哈希表的設計選擇與工程優(yōu)化,最后是性能測試結果。
我們預設讀者已經(jīng)對文中提到哈希表相關的概念有所了解,主要討論其對性能的影響,不做詳細科普。如果對基本概念并不了解,請從其他來源獲取相關知識,例如維基百科。
3
哈希表基本設計與對性能的影響
碰撞處理
不同的key經(jīng)哈希函數(shù)映射到同一個桶,稱作哈希碰撞。各種實現(xiàn)中最常見的碰撞處理機制是鏈地址法(chaining)和開放尋址法(open-addressing)。
鏈地址法
在哈希表中,每個桶存儲一個鏈表,把相同哈希值的不同元素放在鏈表中。這是C++標準容器通常采用的方式。
優(yōu)點:
實現(xiàn)最簡單直觀 空間浪費較少
開放尋址法
若插入時發(fā)生碰撞,從碰撞發(fā)生的那個哈希桶開始,按照一定的次序,找出一個空閑的桶。
優(yōu)點:
每次插入或查找操作只有一次指針跳轉,對CPU緩存更友好 所有數(shù)據(jù)存放在一塊連續(xù)內存中,內存碎片更少
當max load factor較大時,性能不如鏈地址法。然而當我們主動犧牲內存,選擇較小的max load factor時(例如0.5),形勢就發(fā)生逆轉,開放尋址法反而性能更好。因為這時哈希碰撞的概率大大減小,緩存友好的優(yōu)勢得以凸顯。
值得注意的是,C++標準容器實現(xiàn)不采用開放尋址法是由C++標準決定,而非根據(jù)性能考量(詳細可見這個boost文檔)。
Max load factor
對鏈地址法哈希表,指平均每個桶所含元素個數(shù)上限。
對開放尋址法哈希表,指已填充的桶個數(shù)占總的桶個數(shù)的最大比值。
max load factor越小,哈希碰撞的概率越小,同時浪費的空間也越多。
Growth factor
指當已填充的桶達到max load factor限定的上限,哈希表需要rehash時,內存擴張的倍數(shù)。growth factor越大,哈希表rehash的次數(shù)越少,但是內存浪費越多。
空閑桶探測方法
在開放尋址法中,若哈希函數(shù)返回的桶已經(jīng)被其他key占據(jù),需要通過預設規(guī)則去臨近的桶中尋找空閑桶。最常見有以下方法(假設一共|T|個桶,哈希函數(shù)為H(k)):
線性探測(linear probing):對i = 0, 1, 2...,依次探測第H(k, i) = H(k) + ci mod |T|個桶。 平方探測(quadratic probing):對i = 0, 1, 2...,依次探測H(k, i) = H(k) + c1i + c2i2 mod |T|。其中c2不能為0,否則退化成線性探測。 雙重哈希(double hashing):使用兩個不同哈希函數(shù),依次探測H(k, i) = (H1(k) + i * H2(k)) mod |T|。
線性探測法對比其他方法,平均需要探測的桶數(shù)量最多。但是線性探測法訪問內存總是順序連續(xù)訪問,最為緩存友好。因此,在沖突概率不大的時候(max load factor較小),線性探測法是最快的方式。
其他還有一些更精巧的探測方法,例如cuckoo hashing,hopscotch hashing,robin hood hashing(文章開頭給的維基百科頁面里都有介紹)。然而它們都是為max load factor較大(0.6以上)的情形設計的。在max load factor = 0.5的時候,實際測試中性能都不如最原始最直接的線性探測。
4
一些常見的哈希表實現(xiàn)
C++ std::unordered_map/boost::unordered_map
基于上面提到的原因,處理碰撞使用鏈地址法。默認max load factor = 1,growth factor = 2。設計簡單,不用多說。
go map
通過閱讀golang庫的代碼得知,golang內置的map采用鏈地址法。
swisstable
來自于Google推出的abseil庫,是一款性能十分優(yōu)秀的針對通用場景的哈希表實現(xiàn)。碰撞處理方式使用開放尋址,地址探測方法是在分塊內部做平方探測。parallel-hashmap,以及rust語言標準庫的哈希表實現(xiàn),都是基于swisstable。更多信息可參考此處。
ClickHouse的哈希表實現(xiàn)
采用開放尋址,線性探測。max load factor為0.5,growth factor在桶數(shù)量小于2^24時為4,否則為2。
針對key為字符串的情形,ClickHouse還有專門的根據(jù)字符串長度自適應的哈希表實現(xiàn),具體參見論文,這里不展開。
5
高效哈希表的設計與實現(xiàn)
MatrixOne是使用go語言開發(fā)的數(shù)據(jù)庫,市面上的知名哈希表實現(xiàn)我們都無緣直接使用,而在初始的實現(xiàn)中,我們采用了go語言自帶的map,結果高基數(shù)的分組(比如多屬性分組很容易做到高基數(shù))性能相比ClickHouse差距會接近一個數(shù)量級,低基數(shù)也慢不少,所以我們必須實現(xiàn)自己的版本。
基本設計與參數(shù)選擇
ClickHouse的哈希表在自帶的benchmark中表現(xiàn)出了最高的性能,因此借鑒其具體實現(xiàn)成為十分自然的選擇。我們照搬了ClickHouse的如下設計:
開放尋址 線性探測 max load factor = 0.5,growth factor = 4 整數(shù)哈希函數(shù)基于CRC32指令
具體原因前面已經(jīng)提到,當max load factor不大時,開放尋址法要優(yōu)于鏈地制法,同時線性探測法又優(yōu)于其他的探測方法。
并做了如下修改(優(yōu)化):
字符串哈希函數(shù)基于AESENC指令 插入、查找、擴張時批量計算哈希函數(shù) 擴張時直接遍歷舊表插入新表 ClickHouse是先把舊表整體memcpy到新表中,再遍歷調整位置。沒找到如此設計的原因,但是經(jīng)測試性能不如我們的方式。
哈希函數(shù)
哈希函數(shù)的作用是將任意的key映射到哈希表的一個地址,是哈希表插入和查找過程的第一步。數(shù)據(jù)庫場景中使用的哈希函數(shù),應該滿足:
速度盡量快 打散得盡量均勻(避免聚集),這樣使得碰撞概率盡量小,若哈希表做分區(qū)的話也可保證分得均勻 不需要考慮密碼學安全性
在ClickHouse的實現(xiàn)中,主要使用現(xiàn)代CPU(amd64或者arm64)自帶的CRC32指令來實現(xiàn)哈希函數(shù)。
inline?DB::UInt64?intHashCRC32(DB::UInt64?x)
{
#ifdef?__SSE4_2__
?return?_mm_crc32_u64(-1ULL,?x);
#elif?defined(__aarch64__)?&&?defined(__ARM_FEATURE_CRC32)
?return?__crc32cd(-1U,?x);
#else
????///?On?other?platforms?we?do?not?have?CRC32.?NOTE?This?can?be?confusing.
?return?intHash64(x);
#endif
}
經(jīng)實測,打散效果非常不錯,而且每個64位整數(shù)只需一條CPU指令,已經(jīng)達到理論極限,速度遠超xxhash, Murmur3等一系列沒有使用特殊指令的“普通”哈希函數(shù)。
我們的整數(shù)哈希函數(shù)也使用同樣的方法實現(xiàn)。
TEXT?·Crc32Int64Hash(SB),?NOSPLIT,?$0-16
?MOVQ???$-1,?SI
?CRC32Q?data+0(FP),?SI
?MOVQ???SI,?ret+8(FP)
?RET
值得注意的是,go語言不具有C/C++/rust的intrinsics函數(shù)庫,因此要使用某些特殊的指令,只能用go匯編自己實現(xiàn)。而且go匯編函數(shù)目前無法內聯(lián),因此為了最大化性能,需要把計算哈希函數(shù)的過程做成批量化。這點將在后續(xù)的文章中具體介紹。
包含CRC32指令的SSE4.2最早見于2008年發(fā)布的Nehalem架構CPU。因此我們假設用戶的CPU都支持這一指令,畢竟更老的設備用來跑AP數(shù)據(jù)庫似乎不太合適了。
對于字符串類型的哈希函數(shù),ClickHouse仍然通過CRC32指令實現(xiàn)。我們經(jīng)過調研,選擇基于AESENC指令來實現(xiàn)。AESENC包含在AES-NI指令集中,由Intel于2010年發(fā)布的Westmere架構中首次引入,單條指令執(zhí)行AES加密過程中的一個round。AESENC平均一條指令處理128位數(shù)據(jù),比CRC32更快,而且提供128位結果,適應更多應用場景(對比CRC32只有32位)。在實測中基于AESENC的哈希函數(shù)打散效果同樣優(yōu)秀。網(wǎng)絡上基于AESENC指令實現(xiàn)的哈希函數(shù)已經(jīng)有不少,例如nabhash,meowhash,aHash。我們自己的實現(xiàn)在這里(amd64)和這里(arm64)。
特殊優(yōu)化
我們針對字符串key,使用了一種非常規(guī)的設計:不在哈希表中保存原始的key,而是存兩個不同的基于AESENC指令的哈希函數(shù),其中一個64位的結果當作哈希值,另一個128位的結果當作“key”。192位再加上64位的value,每個桶寬度正好是32字節(jié),可完全與CPU的cacheline對齊。在碰撞處理中,不比較原始key,而是比較這192位的數(shù)據(jù)。不同的字符串兩個哈希值同時碰撞的概率極低,在AP系統(tǒng)中可以忽略不計。這樣做的優(yōu)勢是把變長字符串比較變成了定長的3個64位整數(shù)比較,而且還省掉一次指針跳轉開銷,大大加速碰撞檢測的過程。
代碼片段:
type?StringHashMapCell?struct?{
?HashState?[3]uint64
?Mapped????uint64
}
...
func?(ht?*StringHashMap)?findCell(state?*[3]uint64)?*StringHashMapCell?{
?mask?:=?ht.cellCnt?-?1
?idx?:=?state[0]?&?mask
?for?{
??cell?:=?&ht.cells[idx]
??if?cell.Mapped?==?0?||?cell.HashState?==?*state?{
???return?cell
??}
??idx?=?(idx?+?1)?&?mask
?}
?return?nil
}
具體實現(xiàn)代碼
https://github.com/matrixorigin/matrixone/tree/main/pkg/container/hashtable
6
性能測試
測試環(huán)境
CPU:AMD Ryzen 9 5900X 內存:DDR4-3200 32GB 操作系統(tǒng):Manjaro 21.2 內核版本:5.16.11 數(shù)據(jù):ClickHouse提供的一億行Yandex.Metrica數(shù)據(jù)集
測試內容
每個測試都是順序插入一億條記錄,再以相同順序查找一億條記錄。過程類似如下代碼所展示:
...
//?Insert
for?(auto?k?:?data)?{
?hash_map.emplace(k,?hash_map.size()?+?1);
}
...
//?Find
size_t?sum?=?0;
for?(auto?k?:?data)?{
?sum?+=?hash_map[k]
}
...
整數(shù)key結果
下表中記錄了一些哈希表實現(xiàn)對Yandex.Metrica數(shù)據(jù)集不同屬性insert/find所用的時間,單位毫秒(ms)。
| 屬性 | ParamPrice | CounterID | RegionID | FUniqID | UserID | URLHash | RefererHash | WatchID |
|---|---|---|---|---|---|---|---|---|
| 基數(shù) | 1109 | 6506 | 9040 | 15112668 | 17630976 | 20714865 | 21598756 | 99997493 |
| ClickHouse HashMap | 67 / 46 | 175 / 147 | 154 / 141 | 1235 / 873 | 1651 / 893 | 2051 / 1027 | 1945 / 1033 | 5389 / 2040 |
| google::dense_hash_map | 767 / 758 | 273 / 262 | 261 / 260 | 1861 / 1071 | 1909 / 1020 | 2134 / 1158 | 2203 / 1156 | 6181 / 2365 |
| absl::flat_hash_map | 227 / 223 | 236 / 230 | 230 / 231 | 1544 / 1263 | 1685 / 1354 | 2092 / 1504 | 1987 / 1521 | 6278 / 3166 |
| std::unordered_map | 298 / 301 | 323 / 356 | 443 / 443 | 4740 / 2277 | 4966 / 2459 | 5473 / 3058 | 5536 / 2849 | 24832 / 6348 |
| tsl::hopscotch_map | 166 / 162 | 376 / 250 | 167 / 167 | 2151 / 920 | 2225 / 1006 | 3055 / 1278 | 2830 / 1246 | 9473 / 3170 |
| tsl::robin_map | 247 / 281 | 240 / 225 | 276 / 254 | 1641 / 1152 | 2052 / 1132 | 2445 / 1320 | 2371 / 1295 | 7409 / 2651 |
| tsl::sparse_map | 425 / 405 | 550 / 419 | 441 / 415 | 3090 / 1906 | 3773 / 2232 | 4712 / 2760 | 4508 / 2605 | 18342 / 7025 |
| go map | 361 / 433 | 537 / 482 | 461 / 460 | 3039 / 1712 | 3186 / 1818 | 4527 / 2571 | 4175 / 2411 | 15774 / 6027 |
| MatrixOne Int64HashMap | 190 / 182 | 190 / 191 | 191 / 191 | 1112 / 759 | 1160 / 793 | 1445 / 907 | 1400 / 922 | 3205 / 1613 |
可以看出當基數(shù)非常小的時候,ClickHouse實現(xiàn)最快。在基數(shù)較大時,MatrixOrigin的實現(xiàn)最快,且基數(shù)越大領先得越多。
字符串key結果
| 屬性 | OriginalURL | Title | URL | Referer |
|---|---|---|---|---|
| 基數(shù) | 8510123 | 9425718 | 18342035 | 19720815 |
| ClickHouse StringHashMap | 2840 / 1685 | 3873 / 2844 | 5726 / 3713 | 4751 / 2987 |
| ClickHouse HashMapWithSavedHash | 2628 / 1708 | 3508 / 2905 | 5332 / 3679 | 4458 / 2963 |
| ClickHouse HashMap | 3931 / 1570 | 4203 / 2573 | 7137 / 3282 | 6159 / 2644 |
| go map | 5402 / 2440 | 9515 / 4564 | 12881 / 5741 | 10750 / 4624 |
| MatrixOne StringHashMap | 1743 / 1228 | 2434 / 1829 | 2520 / 1811 | 2563 / 1955 |
結果與整數(shù)key類似,基數(shù)越大我們的實現(xiàn)領先越多。
7
總結
以上性能測試結果已經(jīng)大大超出了我們最初的預期。我們從移植ClickHouse自帶哈希表出發(fā),預計由于語言差異,最終能達到C++原版70~80%的性能。隨著反復的迭代優(yōu)化,以及不斷嘗試改變ClickHouse原本的一些設計,最終在哈希表的插入和查找性能上竟然超越了C++版本。
這說明哪怕是一些非常基礎的通常被認為早已研究透了的數(shù)據(jù)結構,通過針對特定應用場景仔細的設計和部分使用匯編加速,也可讓go實現(xiàn)的版本在性能上一點不輸C/C++/rust版本。這也為我們堅持用go語言開發(fā)高性能數(shù)據(jù)庫提供了更多信心。
8
參考文獻
Tianqi Zheng, Zhibin Zhang, and Xueqi Cheng. 2020. SAHA: A String Adaptive Hash Table for Analytical Databases. Applied Sciences 10, 6 (2020). https: //doi.org/10.3390/app10061915
想要了解更多 Golang 相關的內容,歡迎掃描下方???關注?公眾號,回復關鍵詞 [實戰(zhàn)群]? ,就有機會進群和我們進行交流~