
一致性哈希的分析與實(shí)現(xiàn)
哈希函數(shù),想必大家都不陌生。通過哈希函數(shù)我們可以將數(shù)據(jù)映射成一個(gè)數(shù)字(哈希值),然后可用于將數(shù)據(jù)打亂。例如,在HashMap中則是通過哈希函數(shù)使得每個(gè)桶中的數(shù)據(jù)盡量均勻。那一致性哈希又是什么?它是用于解決什么問題?本文將從普通的哈希函數(shù)說起,看看普通哈希函數(shù)存在的問題,然后再看一致性哈希是如何解決,一步步進(jìn)行分析,并結(jié)合代碼實(shí)現(xiàn)來講解。
首先,設(shè)定這樣一個(gè)場景,我們每天有1千萬條業(yè)務(wù)數(shù)據(jù),還有100個(gè)節(jié)點(diǎn)可用于存放數(shù)據(jù)。那我們希望能將數(shù)據(jù)盡量均勻地存放在這100個(gè)節(jié)點(diǎn)上,這時(shí)候哈希函數(shù)就能派上用場了,下面我們按一天的數(shù)據(jù)量來說明。
首先,準(zhǔn)備下需要存放的數(shù)據(jù),以及節(jié)點(diǎn)的地址。為了簡單,這里的數(shù)據(jù)為隨機(jī)整型數(shù)字,節(jié)點(diǎn)的地址為從“192.168.1.0”開始遞增。
private?static?int?dataNum?=?10000000;
private?static?int?nodeNum?=?100;
private?static?List?datas?=?initData(dataNum);
private?static?List?nodes?=?initNode(nodeNum);
private?static?List?initData(int?n)? {
????List?datas?=?new?ArrayList<>();
????Random?random?=?new?Random();
????for?(int?i?=?0;?i?????????datas.add(random.nextInt());
????}
????return?datas;
}
private?static?List?initNode(int?n)? {
????List?nodes?=?new?ArrayList<>();
????for?(int?i?=?0;?i?????????nodes.add(String.format("192.168.1.%d",?i));
????}
????return?nodes;
} 接下來,我們看下通過“哈希+取模”得到數(shù)據(jù)相應(yīng)的節(jié)點(diǎn)地址。這里的hash方法使用Guava提供的哈希方法來實(shí)現(xiàn),后文也將繼續(xù)使用該hash方法。
public?static?String?normalHash(Integer?data,?List?nodes) ?{
????int?hash?=?hash(data);
????int?nodeIndex?=?hash?%?nodes.size();
????return?nodes.get(nodeIndex);
}
private?static?int?hash(Object?object)?{
????HashFunction?hashFunction?=?Hashing.murmur3_32();
????if?(object?instanceof?Integer)?{
????????return?Math.abs(hashFunction.hashInt((Integer)?object).asInt());
????}?else?if?(object?instanceof?String)?{
????????return?Math.abs(hashFunction.hashUnencodedChars((String)?object).asInt());
????}
????return?-1;
}最后,我們對(duì)數(shù)據(jù)的分布情況進(jìn)行統(tǒng)計(jì),觀察分布是否均勻,這里通過標(biāo)準(zhǔn)差來觀察。
public?static?void?normalHashMain()?{
????Map?nodeCount?=?new?HashMap<>();
????for?(Integer?data?:?datas)?{
????????String?node?=?normalHash(data,?nodes);
????????if?(nodeCount.containsKey(node))?{
????????????nodeCount.put(node,?nodeCount.get(node)?+?1);
????????}?else?{
????????????nodeCount.put(node,?1);
????????}
????}
????analyze(nodeCount,?dataNum,?nodeNum);
}
public?static?void?analyze(Map?nodeCount,?int?dataNum,?int?nodeNum) ?{
????double?average?=?(double)?dataNum?/?nodeNum;
????IntSummaryStatistics?s1
????????=?nodeCount.values().stream().mapToInt(Integer::intValue).summaryStatistics();
????int?max?=?s1.getMax();
????int?min?=?s1.getMin();
????int?range?=?max?-?min;
????double?standardDeviation
????????=?nodeCount.values().stream().mapToDouble(n?->?Math.abs(n?-?average)).summaryStatistics().getAverage();
????System.out.println(String.format("平均值:%.2f",?average));
????System.out.println(String.format("最大值:%d,(%.2f%%)",?max,?100.0?*?max?/?average));
????System.out.println(String.format("最小值:%d,(%.2f%%)",?min,?100.0?*?min?/?average));
????System.out.println(String.format("極差:%d,(%.2f%%)",?range,?100.0?*?range?/?average));
????System.out.println(String.format("標(biāo)準(zhǔn)差:%.2f,(%.2f%%)",?standardDeviation,?100.0?*?standardDeviation?/?average));
}
/**
平均值:100000.00
最大值:100818,(100.82%)
最小值:99252,(99.25%)
極差:1566,(1.57%)
標(biāo)準(zhǔn)差:240.08,(0.24%)
**/ 其中標(biāo)準(zhǔn)差較小,說明分布較為均勻,那我們的需求達(dá)到了。
接著,隨著業(yè)務(wù)的發(fā)展,你發(fā)現(xiàn)100個(gè)節(jié)點(diǎn)不夠用了,我們希望再增加10個(gè)節(jié)點(diǎn),來提高系統(tǒng)性能。而我們還將繼續(xù)采用之前的方法來分布數(shù)據(jù)。這時(shí)候就出現(xiàn)了一個(gè)新的問題,我們是通過“哈希+取模”來決定數(shù)據(jù)的相應(yīng)節(jié)點(diǎn),原來數(shù)據(jù)的哈希值是不會(huì)改變的,可是取模的時(shí)候節(jié)點(diǎn)的數(shù)量發(fā)生了變化,這將導(dǎo)致的結(jié)果就是原來的數(shù)據(jù)存在A節(jié)點(diǎn),現(xiàn)在可能需要遷移到B節(jié)點(diǎn),也就是數(shù)據(jù)遷移問題。下面我們來看下有多少數(shù)據(jù)將發(fā)生遷移。
private?static?int?newNodeNum?=?11;
private?static?List?newNodes?=?initNode(newNodeNum);
public?static?void?normalHashMigrateMain()?{
????int?migrateCount?=?0;
????for?(Integer?data?:?datas)?{
????????String?node?=?normalHash(data,?nodes);
????????String?newNode?=?normalHash(data,?newNodes);
????????if?(!node.equals(newNode))?{
????????????migrateCount++;
????????}
????}
????System.out.println(String.format("數(shù)據(jù)遷移量:%d(%.2f%%)",?migrateCount,?migrateCount?*?100.0?/?datas.size()));
}
/**
數(shù)據(jù)遷移量:9091127(90.91%)
**/ 有90%多的數(shù)據(jù)都需要進(jìn)行遷移,這是幾乎全部的量了。普通哈希的問題暴露出來了,當(dāng)將節(jié)點(diǎn)由100擴(kuò)展為110時(shí),會(huì)存在大量的遷移工作。在1997年MIT提出了一致性哈希算法,用于解決普通哈希的這一問題。
我們?cè)俜治鱿拢僭O(shè)hash值為10000,nodeNum為100,那按照index = hash % nodeNum得到的結(jié)果是0,而將100變?yōu)?10時(shí),取模的結(jié)果將改變?yōu)?00。如果我們將取模的除數(shù)增大至大于hash值,那hash值取模的結(jié)果將仍是其本身。也就是說,只要除數(shù)保證大于hash值,那取模的結(jié)果將不會(huì)改變。這里的hash值是int,4個(gè)字節(jié),那我們把除數(shù)固定為2^32-1,index = hash % (2^32-1)。取模的結(jié)果也將固定在0到2^32-1中,可將其構(gòu)成一個(gè)環(huán),如下所示。
 取模的結(jié)果范圍
取模的結(jié)果范圍現(xiàn)在的除數(shù)是2^32-1,hash值為10000,取模的結(jié)果為10000,而我們有100個(gè)節(jié)點(diǎn),該映射到哪個(gè)節(jié)點(diǎn)上呢?我們可以先將節(jié)點(diǎn)通過哈希映射到環(huán)上。為了繪圖方便,我們以3個(gè)節(jié)點(diǎn)為例,如下圖所示:
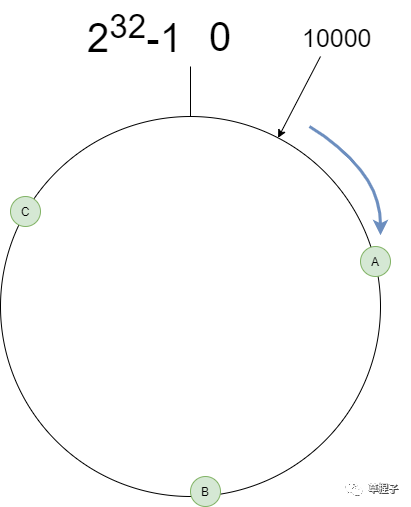 一致性哈希環(huán)
一致性哈希環(huán)10000落到環(huán)上后,如果沒有對(duì)應(yīng)的節(jié)點(diǎn),則按順時(shí)針方向找到下一個(gè)節(jié)點(diǎn),便為hash值對(duì)應(yīng)的節(jié)點(diǎn)。下面我們用Java的TreeMap來存節(jié)點(diǎn)的hash值,利用TreeMap的tailMap尋找節(jié)點(diǎn)。
我們使用和之前同樣的方法,測試下當(dāng)節(jié)點(diǎn)由100變?yōu)?10時(shí),數(shù)據(jù)需要遷移的情況,如下所示:
public?static?void?consistHashMigrateMain()?{
????int?migrateCount?=?0;
????SortedMap?circle?=?new?TreeMap<>();
????for?(String?node?:?nodes)?{
????????circle.put(hash(node),?node);
????}
????SortedMap?newCircle?=?new?TreeMap<>();
????for?(String?node?:?newNodes)?{
????????newCircle.put(hash(node),?node);
????}
????for?(Integer?data?:?datas)?{
????????String?node?=?consistHash(data,?circle);
????????String?newNode?=?consistHash(data,?newCircle);
????????if?(!node.equals(newNode))?{
????????????migrateCount++;
????????}
????}
????System.out.println(String.format("數(shù)據(jù)遷移量:%d(%.2f%%)",?migrateCount,?migrateCount?*?100.0?/?datas.size()));
}
public?static?String?consistHash(Integer?data,?SortedMap?circle) ?{
????int?hash?=?hash(data);
????//?從環(huán)中取大于等于hash值的部分
????SortedMap?subCircle?=?circle.tailMap(hash);
????int?index;
????//?如果在大于等于hash值的部分沒有節(jié)點(diǎn),則取環(huán)開始的第一個(gè)節(jié)點(diǎn)
????if?(subCircle.isEmpty())?{
????????index?=?circle.firstKey();
????}?else?{
????????index?=?subCircle.firstKey();
????}
????return?circle.get(index);
}
/**
數(shù)據(jù)遷移量:817678(8.18%)
**/ 可見需要遷移的數(shù)據(jù)由90%降到了8%,效果十分可觀。那我們?cè)倏聪聰?shù)據(jù)的分布情況,是否仍然均勻:
/**
平均值:100000.00
最大值:589675,(589.68%)
最小值:227,(0.23%)
極差:589448,(589.45%)
標(biāo)準(zhǔn)差:77421.44,(77.42%)
**/77%的標(biāo)準(zhǔn)差,一個(gè)字,崩!這是為啥?我們?cè)驹O(shè)想的是節(jié)點(diǎn)映射到環(huán)上時(shí),能將環(huán)均勻劃分,所以當(dāng)數(shù)據(jù)映射到環(huán)上時(shí),也將被均勻分布到節(jié)點(diǎn)上。而實(shí)際情況,由于節(jié)點(diǎn)地址相似,映射到環(huán)上的位置也將相近,所以造成分布的不均勻,如下圖所示:
 分布不均
分布不均由于A、B、C的地址相似,例如:
A:?192.168.1.0
B:?192.168.1.1
C:?192.168.1.2所以映射的位置相近,那我們可以復(fù)制幾份A、B、C,并且通過改變key,讓節(jié)點(diǎn)能更均勻的劃分環(huán)。比如我們?cè)诘刂泛竺孀芳?“-index” 的序號(hào),例如:
A0:?192.168.1.0-0
B0:?192.168.1.1-0
C0:?192.168.1.2-0
A1:?192.168.1.0-1
B1:?192.168.1.1-1
C1:?192.168.1.2-1雖然A0、B0、C0會(huì)相距較近,但是和A1、B1、C1的key具有差別,將能夠成功分開,這也正是虛擬節(jié)點(diǎn)的作用。達(dá)到的效果如下:
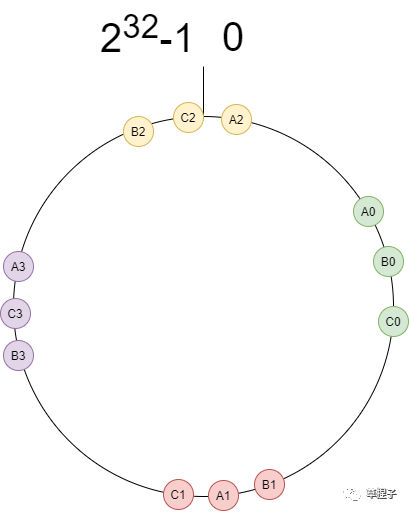 虛擬節(jié)點(diǎn)
虛擬節(jié)點(diǎn)下面我們通過代碼驗(yàn)證下實(shí)際效果:
private?static?int?vNodeNum?=?100;
public?static?void?consistHashVirtualNodeMain()?{
????Map?nodeCount?=?new?HashMap<>();
????SortedMap?circle?=?new?TreeMap<>();
????for?(String?node?:?nodes)?{
????????for?(int?i?=?0;?i?????????????circle.put(hash(node?+?"-"?+?i),?node);
????????}
????}
????for?(Integer?data?:?datas)?{
????????String?node?=?consistHashVirtualNode(data,?circle);
????????if?(nodeCount.containsKey(node))?{
????????????nodeCount.put(node,?nodeCount.get(node)?+?1);
????????}?else?{
????????????nodeCount.put(node,?1);
????????}
????}
????analyze(nodeCount,?dataNum,?nodeNum);
}
/**
平均值:100000.00
最大值:122931,(122.93%)
最小值:74434,(74.43%)
極差:48497,(48.50%)
標(biāo)準(zhǔn)差:7475.08,(7.48%)
**/ 可看到標(biāo)準(zhǔn)差已經(jīng)由77%降到7%,效果顯著。再多做幾組實(shí)驗(yàn),標(biāo)準(zhǔn)差隨著虛擬節(jié)點(diǎn)數(shù)的變化如下:
| 虛擬節(jié)點(diǎn)數(shù) | 標(biāo)準(zhǔn)差 |
|---|---|
| 10 | 21661.04,(21.66%) |
| 100 | 7475.08,(7.48%) |
| 1000 | 2498.36,(2.50%) |
| 10000 | 858.96,(0.86%) |
| 100000 | 363.98,(0.36%) |
結(jié)果中,隨著虛擬節(jié)點(diǎn)數(shù)的增加,標(biāo)準(zhǔn)差逐步下降。可見虛擬節(jié)點(diǎn)能達(dá)到均勻分布數(shù)據(jù)的效果。
一句話總結(jié)下:
一致性哈希可用于解決哈希函數(shù)在擴(kuò)容時(shí)的數(shù)據(jù)遷移的問題,而一致性哈希的實(shí)現(xiàn)中需要借助虛擬節(jié)點(diǎn)來均勻分布數(shù)據(jù)。
最后,大家可以再思考兩個(gè)問題:
虛擬節(jié)點(diǎn)越多越好嗎?會(huì)不會(huì)有什么負(fù)面影響?
Java中的HashMap在擴(kuò)容時(shí)如何優(yōu)化數(shù)據(jù)遷移問題?
文中的代碼已上傳至github,感興趣的同學(xué)可以自己試下:https://github.com/chaycao/Learn/tree/master/LearnConsistHash
有道無術(shù),術(shù)可成;有術(shù)無道,止于術(shù)
歡迎大家關(guān)注Java之道公眾號(hào)
好文章,我在看??