
MySQL 索引 -- 從頭擼一遍

先來(lái)一道經(jīng)典的服務(wù)端面試題,看下你會(huì)嗎
“如果有這樣一個(gè)查詢
select * from table where a=1 group by b order by c;如果每個(gè)字段都有一個(gè)單列索引,索引會(huì)生效嗎?如果是復(fù)合索引,能說(shuō)下幾種情況嗎?
這篇文章算是一個(gè) MySQL 索引的知識(shí)梳理,包括索引的一些概念、B 樹(shù)的結(jié)構(gòu)、和索引的原理以及一些索引策略的知識(shí),祝好
一、索引基礎(chǔ)回顧
索引是什么
MYSQL 官方對(duì)索引的定義為:索引(Index)是幫助 MySQL 高效獲取數(shù)據(jù)的數(shù)據(jù)結(jié)構(gòu),所以說(shuō)索引的本質(zhì)是:數(shù)據(jù)結(jié)構(gòu)
索引的目的在于提高查詢效率,可以類比字典、 火車站的車次表、圖書的目錄等 。
可以簡(jiǎn)單的理解為“排好序的快速查找數(shù)據(jù)結(jié)構(gòu)”,數(shù)據(jù)本身之外,數(shù)據(jù)庫(kù)還維護(hù)者一個(gè)滿足特定查找算法的數(shù)據(jù)結(jié)構(gòu),這些數(shù)據(jù)結(jié)構(gòu)以某種方式引用(指向)數(shù)據(jù),這樣就可以在這些數(shù)據(jù)結(jié)構(gòu)上實(shí)現(xiàn)高級(jí)查找算法。這種數(shù)據(jù)結(jié)構(gòu),就是索引。
常見(jiàn)的索引模型其實(shí)有很多,哈希表、有序數(shù)組,各種搜索樹(shù)都可以實(shí)現(xiàn)索引結(jié)構(gòu)
下圖是一種可能的索引方式示例(二叉搜索樹(shù))
上圖左邊是一張簡(jiǎn)單的
學(xué)生成績(jī)表,只有學(xué)號(hào) id 和成績(jī) score 兩列(最左邊的是數(shù)據(jù)的物理地址)比如我們想要快速查指定成績(jī)的學(xué)生,通過(guò)構(gòu)建一個(gè)右邊的二叉搜索樹(shù)當(dāng)索引,索引節(jié)點(diǎn)就是成績(jī)數(shù)據(jù),節(jié)點(diǎn)指向?qū)?yīng)數(shù)據(jù)記錄物理地址的指針,這樣就可以運(yùn)用二叉查找在一定的復(fù)雜度內(nèi)獲取到對(duì)應(yīng)的數(shù)據(jù),從而快速檢索出符合條件的學(xué)生信息。
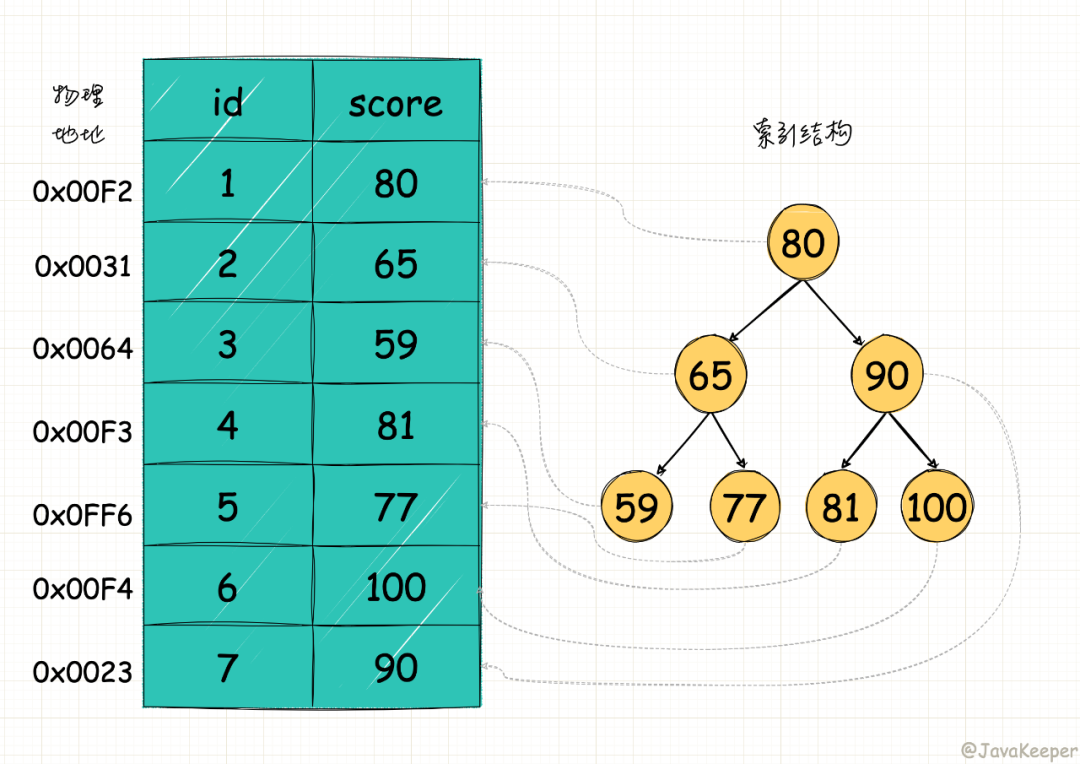
索引本身也很大,不可能全部存儲(chǔ)在內(nèi)存中,一般以索引文件的形式存儲(chǔ)在磁盤上
優(yōu)勢(shì)
索引大大減少了服務(wù)器需要掃描的數(shù)據(jù)量(提高數(shù)據(jù)檢索效率) 索引可以幫助服務(wù)器避免排序和臨時(shí)表(降低數(shù)據(jù)排序的成本,降低 CPU 的消耗) 索引可以將隨機(jī) I/O 變?yōu)轫樞?I/O(降低數(shù)據(jù)庫(kù) IO 成本)

劣勢(shì)
索引也是一張表,保存了主鍵和索引字段,并指向?qū)嶓w表的記錄,所以也需要占用內(nèi)存 雖然索引大大提高了查詢速度,同時(shí)卻會(huì)降低更新表的速度,如對(duì)表進(jìn)行 INSERT、UPDATE 和 DELETE。因?yàn)楦卤頃r(shí),MySQL 不僅要保存數(shù)據(jù),還要保存一下索引文件每次更新添加了索引列的字段,都會(huì)調(diào)整因?yàn)楦滤鶐?lái)的鍵值變化后的索引信息
索引分類
下邊是官網(wǎng)的一個(gè)表格:https://dev.mysql.com/doc/refman/8.0/en/create-index.html
我們從 3 個(gè)角度看下索引的分類
從邏輯角度
主鍵索引:主鍵索引是一種特殊的唯一索引,不允許有空值 普通索引或者單列索引:每個(gè)索引只包含單個(gè)列,一個(gè)表可以有多個(gè)單列索引 多列索引(復(fù)合索引、聯(lián)合索引):復(fù)合索引指多個(gè)字段上創(chuàng)建的索引,只有在查詢條件中使用了創(chuàng)建索引時(shí)的第一個(gè)字段,索引才會(huì)被使用。 唯一索引或者非唯一索引 Full-Text 全文索引:它查找的是文本中的關(guān)鍵詞,而不是直接比較索引中的值 空間索引:空間索引是對(duì)空間數(shù)據(jù)類型的字段建立的索引
數(shù)據(jù)結(jié)構(gòu)角度
Hash 索引:主要就是通過(guò) Hash 算法,將數(shù)據(jù)庫(kù)字段數(shù)據(jù)轉(zhuǎn)換成定長(zhǎng)的 Hash 值,與這條數(shù)據(jù)的行指針一并存入 Hash 表的對(duì)應(yīng)位置;如果發(fā)生 Hash 碰撞,則在對(duì)應(yīng) Hash 鍵下以鏈表形式存儲(chǔ)。查詢時(shí),就再次對(duì)待查關(guān)鍵字再次執(zhí)行相同的 Hash 算法,得到 Hash 值,到對(duì)應(yīng) Hash 表對(duì)應(yīng)位置取出數(shù)據(jù)即可,Memory 引擎又是支持非唯一哈希索引的,如果發(fā)生 Hash 碰撞,會(huì)以鏈表的方式存放多個(gè)記錄在同一哈希條目中。使用 Hash 索引的數(shù)據(jù)庫(kù)并不多, 目前有 Memory 引擎和 NDB 引擎支持 Hash 索引。
缺點(diǎn)是,只支持等值比較查詢,像 = 、 in() 這種,不支持范圍查找,比如 where id > 10 這種,也不能排序。
B+ 樹(shù)索引(下文會(huì)詳細(xì)講)
從物理存儲(chǔ)角度
聚集索引(clustered index)
非聚集索引(non-clustered index),也叫輔助索引(secondary index)
聚集索引和非聚集索引都是 B+ 樹(shù)結(jié)構(gòu)
二、MySQL 索引結(jié)構(gòu)
索引可以有很多種結(jié)構(gòu)類型,這樣可以為不同的場(chǎng)景提供更好的性能。
首先要明白索引(index)是在存儲(chǔ)引擎(storage engine)層面實(shí)現(xiàn)的,而不是 server 層面。不是所有的存儲(chǔ)引擎都支持所有的索引類型。即使多個(gè)存儲(chǔ)引擎支持某一索引類型,它們的實(shí)現(xiàn)和行為也可能有所差別。
像有的 二* 面試官上來(lái)就會(huì)問(wèn):
MySQL 為什么不用 Hash 結(jié)構(gòu)做索引?我會(huì)直接來(lái)一句,不好意思,MySQL 也會(huì)用 Hash 做索引,Memory 存儲(chǔ)引擎就支持 Hash 索引。只是場(chǎng)景用的少,Hash 結(jié)構(gòu)更適用于只有等值查詢的場(chǎng)景
為什么不用二叉搜索樹(shù)呢?這就很簡(jiǎn)單了,二叉樹(shù)的叉叉上只有兩個(gè)數(shù),數(shù)據(jù)量太多的話,那得多少層呀。
磁盤 IO
介紹索引結(jié)構(gòu)之前,我們先了解下磁盤IO與預(yù)讀[1]
磁盤讀取數(shù)據(jù)靠的是機(jī)械運(yùn)動(dòng),每次讀取數(shù)據(jù)花費(fèi)的時(shí)間可以分為尋道時(shí)間、旋轉(zhuǎn)延遲、傳輸時(shí)間三個(gè)部分
尋道時(shí)間指的是磁臂移動(dòng)到指定磁道所需要的時(shí)間,主流磁盤一般在 5ms 以下; 旋轉(zhuǎn)延遲就是我們經(jīng)常聽(tīng)說(shuō)的磁盤轉(zhuǎn)速,比如一個(gè)磁盤 7200 轉(zhuǎn),表示每分鐘能轉(zhuǎn) 7200 次,也就是說(shuō) 1 秒鐘能轉(zhuǎn) 120 次,旋轉(zhuǎn)延遲就是 1/120/2 = 4.17ms;傳輸時(shí)間指的是從磁盤讀出或?qū)?shù)據(jù)寫入磁盤的時(shí)間,一般在零點(diǎn)幾毫秒,相對(duì)于前兩個(gè)時(shí)間可以忽略不計(jì)。 那么訪問(wèn)一次磁盤的時(shí)間,即一次磁盤 IO 的時(shí)間約等于
5+4.17 = 9ms左右,聽(tīng)起來(lái)還挺不錯(cuò)的,但要知道一臺(tái) 500 -MIPS 的機(jī)器每秒可以執(zhí)行 5 億條指令,因?yàn)橹噶钜揽康氖请姷男再|(zhì),換句話說(shuō)執(zhí)行一次 IO 的時(shí)間可以執(zhí)行 40 萬(wàn)條指令,數(shù)據(jù)庫(kù)動(dòng)輒十萬(wàn)百萬(wàn)乃至千萬(wàn)級(jí)數(shù)據(jù),每次 9 毫秒的時(shí)間,顯然是個(gè)災(zāi)難。下圖是計(jì)算機(jī)硬件延遲的對(duì)比圖,供大家參考:考慮到磁盤 IO 是非常高昂的操作,計(jì)算機(jī)操作系統(tǒng)做了一些優(yōu)化,當(dāng)一次 IO 時(shí),不光把當(dāng)前磁盤地址的數(shù)據(jù),而是把相鄰的數(shù)據(jù)也都讀取到內(nèi)存緩沖區(qū)內(nèi),因?yàn)榫植款A(yù)讀性原理告訴我們,當(dāng)計(jì)算機(jī)訪問(wèn)一個(gè)地址的數(shù)據(jù)的時(shí)候,與其相鄰的數(shù)據(jù)也會(huì)很快被訪問(wèn)到。每一次 IO 讀取的數(shù)據(jù)我們稱之為**一頁(yè)(page)**。具體一頁(yè)有多大數(shù)據(jù)跟操作系統(tǒng)有關(guān),一般為 4k 或 8k,也就是我們讀取一頁(yè)內(nèi)的數(shù)據(jù)時(shí)候,實(shí)際上才發(fā)生了一次 IO,這個(gè)理論對(duì)于索引的數(shù)據(jù)結(jié)構(gòu)設(shè)計(jì)非常有幫助。


那是不應(yīng)該有一種數(shù)據(jù)結(jié)構(gòu),可以在每次查找數(shù)據(jù)時(shí)把磁盤 IO 次數(shù)控制在一個(gè)很小的數(shù)量級(jí), B+ 樹(shù)就這樣應(yīng)用而生。
心里有點(diǎn) B 樹(shù)
有一點(diǎn)面試經(jīng)驗(yàn)的同學(xué),可能都碰到過(guò)這么一道面試題:MySQL InnoDB ?索引為什么用 B+ 樹(shù),不用 B 樹(shù)
B-Tree == B Tree,他兩是一個(gè)東西,沒(méi)有 B 減樹(shù) 這玩意
先大概(仔細(xì))看下維基百科的概述:
在 B 樹(shù)中,內(nèi)部(非葉子)節(jié)點(diǎn)可以擁有可變數(shù)量的子節(jié)點(diǎn)(數(shù)量范圍預(yù)先定義好)。當(dāng)數(shù)據(jù)被插入或從一個(gè)節(jié)點(diǎn)中移除,它的子節(jié)點(diǎn)數(shù)量發(fā)生變化。為了維持在預(yù)先設(shè)定的數(shù)量范圍內(nèi),內(nèi)部節(jié)點(diǎn)可能會(huì)被合并或者分離。因?yàn)樽庸?jié)點(diǎn)數(shù)量有一定的允許范圍,所以B 樹(shù)不需要像其他自平衡查找樹(shù)那樣頻繁地重新保持平衡,但是由于節(jié)點(diǎn)沒(méi)有被完全填充,可能浪費(fèi)了一些空間。子節(jié)點(diǎn)數(shù)量的上界和下界依特定的實(shí)現(xiàn)而設(shè)置。例如,在一個(gè) 2-3 B樹(shù)(通常簡(jiǎn)稱2-3樹(shù)),每一個(gè)內(nèi)部節(jié)點(diǎn)只能有 2 或 3 個(gè)子節(jié)點(diǎn)。
B 樹(shù)中每一個(gè)內(nèi)部節(jié)點(diǎn)會(huì)包含一定數(shù)量的鍵,鍵將節(jié)點(diǎn)的子樹(shù)分開(kāi)。例如,如果一個(gè)內(nèi)部節(jié)點(diǎn)有 3 個(gè)子節(jié)點(diǎn)(子樹(shù)),那么它就必須有兩個(gè)鍵:a1 和 a2 。左邊子樹(shù)的所有值都必須小于 a1 ,中間子樹(shù)的所有值都必須在 a1 和 a2 之間,右邊子樹(shù)的所有值都必須大于 a2 。
在存取節(jié)點(diǎn)數(shù)據(jù)所耗時(shí)間遠(yuǎn)超過(guò)處理節(jié)點(diǎn)數(shù)據(jù)所耗時(shí)間的情況下,B樹(shù)在可選的實(shí)現(xiàn)中擁有很多優(yōu)勢(shì),因?yàn)榇嫒」?jié)點(diǎn)的開(kāi)銷被分?jǐn)偟嚼飳庸?jié)點(diǎn)的多次操作上。這通常出現(xiàn)在當(dāng)節(jié)點(diǎn)存儲(chǔ)在二級(jí)存儲(chǔ)器如硬盤存儲(chǔ)器上。通過(guò)最大化內(nèi)部里層節(jié)點(diǎn)的子節(jié)點(diǎn)的數(shù)量,樹(shù)的高度減小,存取節(jié)點(diǎn)的開(kāi)銷被縮減。另外,重新平衡樹(shù)的動(dòng)作也更少出現(xiàn)。子節(jié)點(diǎn)的最大數(shù)量取決于,每個(gè)子節(jié)點(diǎn)必需存儲(chǔ)的信息量,和完整磁盤塊的大小或者二次存儲(chǔ)器中類似的容量。雖然 2-3 樹(shù)更易于解釋,實(shí)際運(yùn)用中,B樹(shù)使用二級(jí)存儲(chǔ)器,需要大量數(shù)目的子節(jié)點(diǎn)來(lái)提升效率。
而 B+ 樹(shù) 又是 B 樹(shù)的變種,B+ 樹(shù)結(jié)構(gòu),所有的數(shù)據(jù)都存放在葉子節(jié)點(diǎn)上,且把葉子節(jié)點(diǎn)通過(guò)指針連接到一起,形成了一條數(shù)據(jù)鏈表,以加快相鄰數(shù)據(jù)的檢索效率。
推薦一個(gè)數(shù)據(jù)結(jié)構(gòu)可視化網(wǎng)站:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html,可以用來(lái)生成各種數(shù)據(jù)結(jié)構(gòu)
將 [11,13,15,16,20,23,25,30,23,27] 用 B 樹(shù) 和 B+ 樹(shù)存儲(chǔ),看下結(jié)構(gòu)

B 樹(shù)和 B+ 樹(shù)區(qū)別
B-Tree 和 B+Tree ?都是為磁盤等外存儲(chǔ)設(shè)備設(shè)計(jì)的一種平衡查找樹(shù)。
| 關(guān)鍵詞 | B-樹(shù) | B+樹(shù) | 備注 |
|---|---|---|---|
| 最大分支,最小分支 | 每個(gè)結(jié)點(diǎn)最多有m個(gè)分支(子樹(shù)),最少?m/2?(中間結(jié)點(diǎn))個(gè)分支或者2個(gè)分支(是根節(jié)點(diǎn)非葉子結(jié)點(diǎn))。 | 同左 | m階對(duì)應(yīng)的就是就是最大分支 |
| n個(gè)關(guān)鍵字與分支的關(guān)系 | 分支等于n+1 | 分支等于n | 無(wú) |
| 關(guān)鍵字個(gè)數(shù)(B+樹(shù)關(guān)鍵字個(gè)數(shù)要多) | 大于等于?m/2?-1小于等于m-1 | 大于等于?m/2?小于等于m | B+樹(shù)關(guān)鍵字個(gè)數(shù)要多,+體現(xiàn)在的地方。 |
| 葉子結(jié)點(diǎn)相同點(diǎn) | 每個(gè)節(jié)點(diǎn)中的元素互不相等且按照從小到大排列;所有的葉子結(jié)點(diǎn)都位于同一層。 | 同左 | 無(wú) |
| 葉子結(jié)點(diǎn)不相同 | 不包含信息 | 葉子結(jié)點(diǎn)包含信息,指針指向記錄。 | 無(wú) |
| 葉子結(jié)點(diǎn)之間的關(guān)系 | 無(wú) | B+樹(shù)上有一個(gè)指針指向關(guān)鍵字最小的葉子結(jié)點(diǎn),所有葉子節(jié)點(diǎn)之間鏈接成一個(gè)線性鏈表 | 無(wú) |
| 非葉子結(jié)點(diǎn) | 一個(gè)關(guān)鍵字對(duì)應(yīng)一個(gè)記錄的存儲(chǔ)地址 | 只起到索引的作用 | 無(wú) |
| 存儲(chǔ)結(jié)構(gòu) | 相同 | 同左 | 無(wú) |
為什么要用 B+ 樹(shù)
心里有了磁盤 IO 和 B ?樹(shù)的概念,接下來(lái)就順理成章了。磁盤 IO 次數(shù)越少,那查詢效率肯定就越高。而 IO 次數(shù)又取決于 B+ 樹(shù)的高度
我們以 InnoDB 存儲(chǔ)引擎來(lái)說(shuō)明。
系統(tǒng)從磁盤讀取數(shù)據(jù)到內(nèi)存時(shí)是以磁盤塊(block)為基本單位的,位于同一個(gè)磁盤塊中的數(shù)據(jù)會(huì)被一次性讀取出來(lái),而不是需要什么取什么。
InnoDB 存儲(chǔ)引擎中有頁(yè)(Page)的概念,頁(yè)是其磁盤管理的最小單位。InnoDB 存儲(chǔ)引擎中默認(rèn)每個(gè)頁(yè)的大小為16KB,可通過(guò)參數(shù) innodb_page_size 將頁(yè)的大小設(shè)置為 4K、8K、16K,在 MySQL 中可通過(guò)如下命令查看頁(yè)的大小:show variables like 'innodb_page_size';
而系統(tǒng)一個(gè)磁盤塊的存儲(chǔ)空間往往沒(méi)有這么大,因此 InnoDB 每次申請(qǐng)磁盤空間時(shí)都會(huì)是若干地址連續(xù)磁盤塊來(lái)達(dá)到頁(yè)的大小 16KB。InnoDB 在把磁盤數(shù)據(jù)讀入到磁盤時(shí)會(huì)以頁(yè)為基本單位,在查詢數(shù)據(jù)時(shí)如果一個(gè)頁(yè)中的每條數(shù)據(jù)都能有助于定位數(shù)據(jù)記錄的位置,這將會(huì)減少磁盤 I/O 次數(shù),提高查詢效率。
舉個(gè)例子
索引是為了更快的查詢到數(shù)據(jù),MySQL 數(shù)據(jù)行可能會(huì)很多內(nèi)容
以范圍查找為例簡(jiǎn)單看下,B Tree 結(jié)構(gòu)查詢 [10-25] 的數(shù)據(jù)(從根節(jié)點(diǎn)開(kāi)始,隨機(jī)查找一樣的道理,只是我畫的圖只有 2 層,說(shuō)服力強(qiáng)的不是那么明顯罷了)
加載根節(jié)點(diǎn),第一個(gè)節(jié)點(diǎn)元素15,大于10【磁盤 I/O 操作第 1 次】 通過(guò)根節(jié)點(diǎn)的左子節(jié)點(diǎn)地址加載,找到 11,13【磁盤 I/O 操作第 2 次】 重新加載根節(jié)點(diǎn),找到中間節(jié)點(diǎn)數(shù)據(jù) 16,20【磁盤 I/O 操作第 3 次】 再次加載根節(jié)點(diǎn),23 小于 25,再加載右子節(jié)點(diǎn),找到 25,結(jié)束【磁盤 I/O 操作第 4 次】
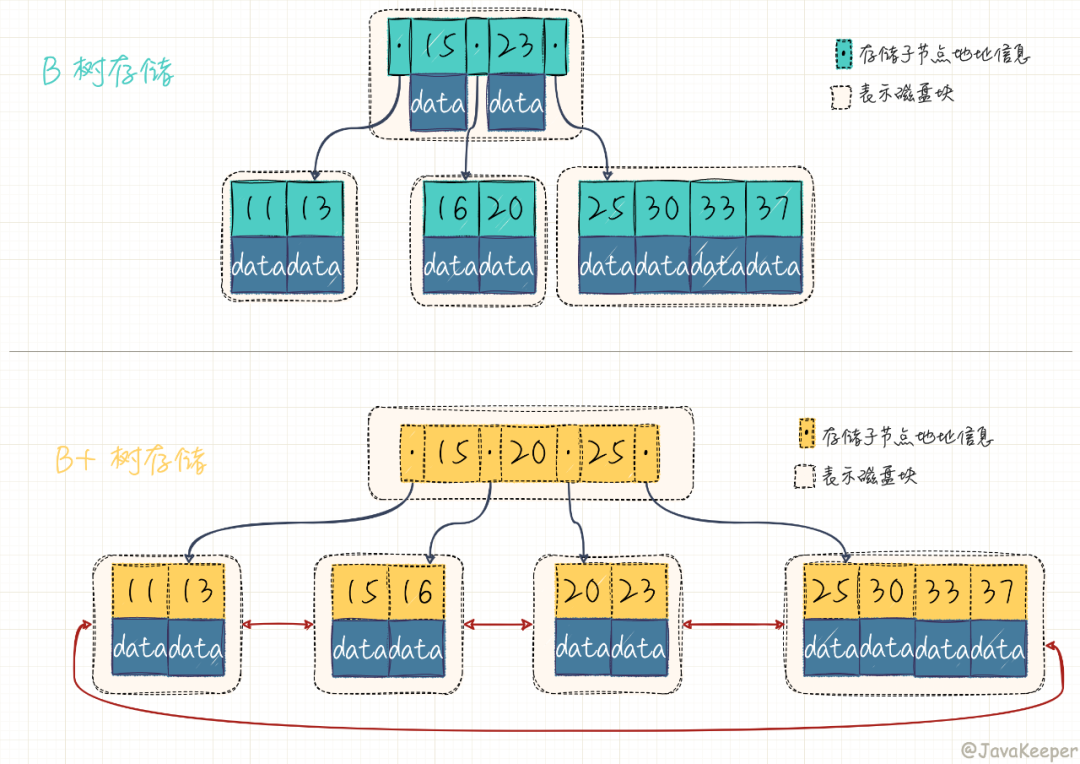
而 B+ 樹(shù)對(duì)范圍查找就簡(jiǎn)單了,數(shù)據(jù)都在最下邊的葉子節(jié)點(diǎn)下,而且鏈起來(lái)了,我只需找到第一個(gè)然后遍歷就行(暫且不考慮頁(yè)分裂等其他問(wèn)題)。
解答
為什么 MySQL 索引要用 B+ 樹(shù)不是 B 樹(shù)?
B+Tree 是在 B-Tree 基礎(chǔ)上的一種優(yōu)化,使其更適合實(shí)現(xiàn)外存儲(chǔ)索引結(jié)構(gòu)。
用 B+ 樹(shù)不用 B 樹(shù)考慮的是 IO 對(duì)性能的影響,B 樹(shù)的每個(gè)節(jié)點(diǎn)都存儲(chǔ)數(shù)據(jù),而 B+ 樹(shù)只有葉子節(jié)點(diǎn)才存儲(chǔ)數(shù)據(jù),所以查找相同數(shù)據(jù)量的情況下,B 樹(shù)的高度更高,IO 更頻繁。數(shù)據(jù)庫(kù)索引是存儲(chǔ)在磁盤上的,當(dāng)數(shù)據(jù)量大時(shí),就不能把整個(gè)索引全部加載到內(nèi)存了,只能逐一加載每一個(gè)磁盤頁(yè)(對(duì)應(yīng)索引樹(shù)的節(jié)點(diǎn))。其中在 ?MySQL 底層對(duì) B+ 樹(shù)進(jìn)行進(jìn)一步優(yōu)化:在葉子節(jié)點(diǎn)中是雙向鏈表,且在鏈表的頭結(jié)點(diǎn)和尾節(jié)點(diǎn)也是循環(huán)指向的。
B-Tree 結(jié)構(gòu)圖每個(gè)節(jié)點(diǎn)中不僅要包含數(shù)據(jù)的 key 值,還有 data 值。而每一個(gè)頁(yè)的存儲(chǔ)空間是有限的,如果 data 數(shù)據(jù)較大時(shí)將會(huì)導(dǎo)致每個(gè)節(jié)點(diǎn)(即一個(gè)頁(yè))能存儲(chǔ)的 key 的數(shù)量很小,當(dāng)存儲(chǔ)的數(shù)據(jù)量很大時(shí)同樣會(huì)導(dǎo)致 B-Tree 的深度較大,增大查詢時(shí)的磁盤 I/O 次數(shù),進(jìn)而影響查詢效率。在 B+Tree 中,所有數(shù)據(jù)記錄節(jié)點(diǎn)都是按照鍵值大小順序存放在同一層的葉子節(jié)點(diǎn)上,而非葉子節(jié)點(diǎn)上只存儲(chǔ) key 值信息,這樣可以大大加大每個(gè)節(jié)點(diǎn)存儲(chǔ)的 key 值數(shù)量,降低 B+Tree 的高度。
IO 次數(shù)取決于 B+ 數(shù)的高度 h,假設(shè)當(dāng)前數(shù)據(jù)表的數(shù)據(jù)為 N,每個(gè)磁盤塊的數(shù)據(jù)項(xiàng)的數(shù)量是 m,則有
h=㏒(m+1)N,當(dāng)數(shù)據(jù)量 N 一定的情況下,m 越大,h 越小;而m = 磁盤塊的大小 / 數(shù)據(jù)項(xiàng)的大小,磁盤塊的大小也就是一個(gè)數(shù)據(jù)頁(yè)的大小,是固定的,如果數(shù)據(jù)項(xiàng)占的空間越小,數(shù)據(jù)項(xiàng)的數(shù)量越多,樹(shù)的高度越低。這就是為什么每個(gè)數(shù)據(jù)項(xiàng),即索引字段要盡量的小,比如 int 占 4 字節(jié),要比 bigint 8 字節(jié)少一半。這也是為什么 B+ 樹(shù)要求把真實(shí)的數(shù)據(jù)放到葉子節(jié)點(diǎn)而不是內(nèi)層節(jié)點(diǎn),一旦放到內(nèi)層節(jié)點(diǎn),磁盤塊的數(shù)據(jù)項(xiàng)會(huì)大幅度下降,導(dǎo)致樹(shù)增高。當(dāng)數(shù)據(jù)項(xiàng)等于 1 時(shí)將會(huì)退化成線性表。
三、MyISAM 和 InnoDB 索引原理
MyISAM 主鍵索引與輔助索引的結(jié)構(gòu)
MyISAM 引擎的索引文件和數(shù)據(jù)文件是分離的。MyISAM 引擎索引結(jié)構(gòu)的葉子節(jié)點(diǎn)的數(shù)據(jù)域,存放的并不是實(shí)際的數(shù)據(jù)記錄,而是數(shù)據(jù)記錄的地址。索引文件與數(shù)據(jù)文件分離,這樣的索引稱為"非聚簇索引"。MyISAM 的主索引與輔助索引區(qū)別并不大,主鍵索引就是一個(gè)名為 PRIMARY 的唯一非空索引。
術(shù)語(yǔ) “聚簇” 表示數(shù)據(jù)行和相鄰的鍵值緊湊的存儲(chǔ)在一起
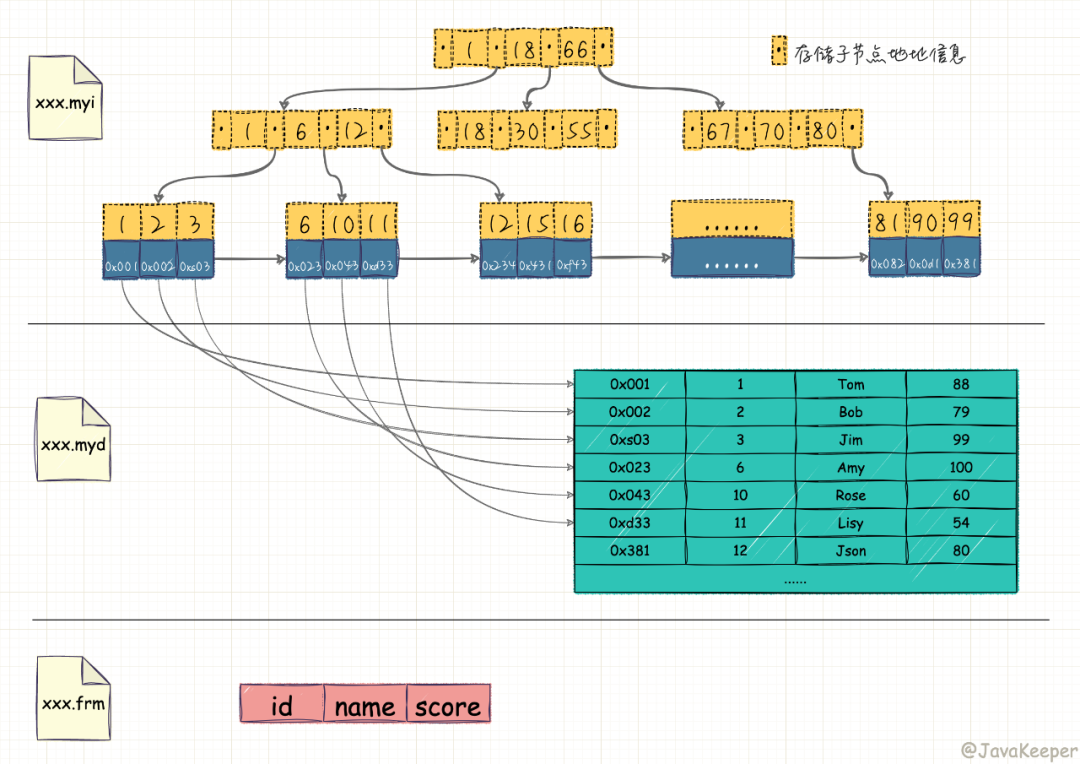
在 MyISAM 中,索引(含葉子節(jié)點(diǎn))存放在單獨(dú)的 .myi 文件中,葉子節(jié)點(diǎn)存放的是數(shù)據(jù)的物理地址偏移量(通過(guò)偏移量訪問(wèn)就是隨機(jī)訪問(wèn),速度很快)。
主索引是指主鍵索引,鍵值不可能重復(fù);輔助索引則是普通索引,鍵值可能重復(fù)。
通過(guò)索引查找數(shù)據(jù)的流程:先從索引文件中查找到索引節(jié)點(diǎn),從中拿到數(shù)據(jù)的文件指針,再到數(shù)據(jù)文件中通過(guò)文件指針定位了具體的數(shù)據(jù)。
輔助索引類似。
InnoDB 主鍵索引與輔助索引的結(jié)構(gòu)
InnoDB 引擎索引結(jié)構(gòu)的葉子節(jié)點(diǎn)的數(shù)據(jù)域,存放的就是實(shí)際的數(shù)據(jù)記錄(對(duì)于主索引,此處會(huì)存放表中所有的數(shù)據(jù)記錄;對(duì)于輔助索引此處會(huì)引用主鍵,檢索的時(shí)候通過(guò)主鍵到主鍵索引中找到對(duì)應(yīng)數(shù)據(jù)行),或者說(shuō),InnoDB 的數(shù)據(jù)文件本身就是主鍵索引文件,這樣的索引被稱為"“聚簇索引”,一個(gè)表只能有一個(gè)聚簇索引。
主鍵索引:
我們知道 InnoDB 索引是聚集索引,它的索引和數(shù)據(jù)是存入同一個(gè) .idb 文件中的,因此它的索引結(jié)構(gòu)是在同一個(gè)樹(shù)節(jié)點(diǎn)中同時(shí)存放索引和數(shù)據(jù),如下圖中最底層的葉子節(jié)點(diǎn)有三行數(shù)據(jù),對(duì)應(yīng)于數(shù)據(jù)表中的 id、name、score 數(shù)據(jù)項(xiàng)。
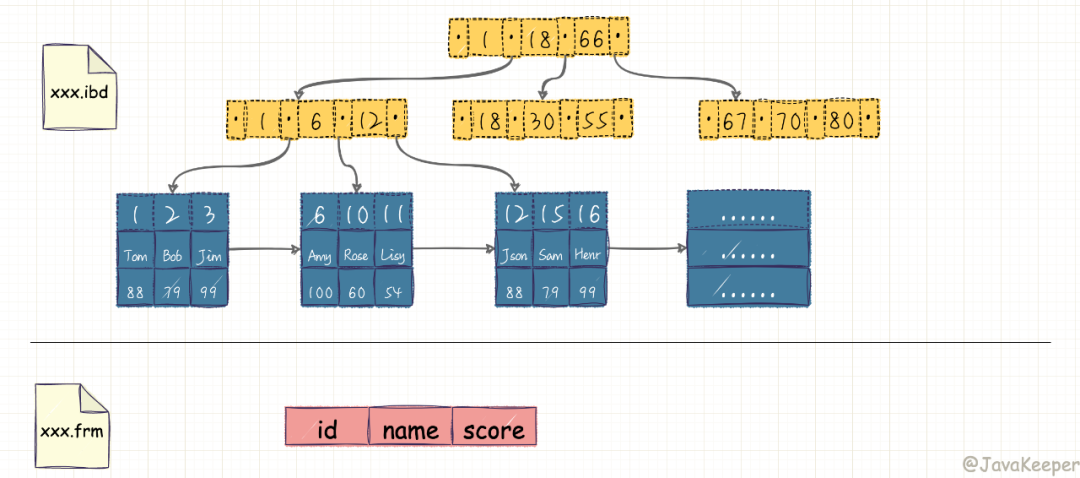
在 Innodb 中,索引分葉子節(jié)點(diǎn)和非葉子節(jié)點(diǎn),非葉子節(jié)點(diǎn)就像新華字典的目錄,單獨(dú)存放在索引段中,葉子節(jié)點(diǎn)則是順序排列的,在數(shù)據(jù)段中。
InnoDB 的數(shù)據(jù)文件可以按照表來(lái)切分(只需要開(kāi)啟innodb_file_per_table),切分后存放在xxx.ibd中,不切分存放在 xxx.ibdata中。
從 MySQL 5.6.6 版本開(kāi)始,它的默認(rèn)值就是 ON 了。
擴(kuò)展點(diǎn):建議將這個(gè)值設(shè)置為 ON。因?yàn)椋粋€(gè)表單獨(dú)存儲(chǔ)為一個(gè)文件更容易管理,而且在你不需要這個(gè)表的時(shí)候,通過(guò) drop table 命令,系統(tǒng)就會(huì)直接刪除這個(gè)文件。而如果是放在共享表空間中,即使表刪掉了,空間也是不會(huì)回收的。
所以會(huì)碰到這種情況,數(shù)據(jù)庫(kù)占用空間太大后,把一個(gè)最大的表刪掉了一半的數(shù)據(jù),表文件的大小還是沒(méi)變~
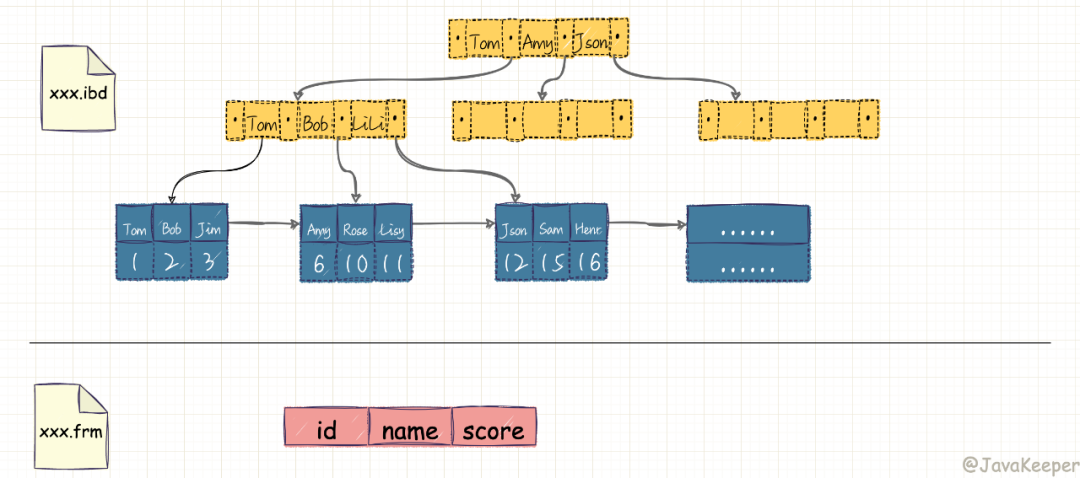
輔助(非主鍵)索引:
這次我們以示例中學(xué)生表中的 name 列建立輔助索引,它的索引結(jié)構(gòu)跟主鍵索引的結(jié)構(gòu)有很大差別,在最底層的葉子結(jié)點(diǎn)有兩行數(shù)據(jù),第一行的字符串是輔助索引,按照 ASCII 碼進(jìn)行排序,第二行的整數(shù)是主鍵的值。
這就意味著,對(duì) name 列進(jìn)行條件搜索,需要兩個(gè)步驟:
在輔助索引上檢索 name,到達(dá)其葉子節(jié)點(diǎn)獲取對(duì)應(yīng)的主鍵; 使用主鍵在主索引上再進(jìn)行對(duì)應(yīng)的檢索操作
這也就是所謂的“回表查詢”
InnoDB 索引結(jié)構(gòu)需要注意的點(diǎn)
數(shù)據(jù)文件本身就是索引文件 表數(shù)據(jù)文件本身就是按 B+Tree 組織的一個(gè)索引結(jié)構(gòu)文件 聚集索引中葉節(jié)點(diǎn)包含了完整的數(shù)據(jù)記錄 InnoDB 表必須要有主鍵,并且推薦使用整型自增主鍵
正如我們上面介紹 InnoDB 存儲(chǔ)結(jié)構(gòu),索引與數(shù)據(jù)是共同存儲(chǔ)的,不管是主鍵索引還是輔助索引,在查找時(shí)都是通過(guò)先查找到索引節(jié)點(diǎn)才能拿到相對(duì)應(yīng)的數(shù)據(jù),如果我們?cè)谠O(shè)計(jì)表結(jié)構(gòu)時(shí)沒(méi)有顯式指定索引列的話,MySQL 會(huì)從表中選擇數(shù)據(jù)不重復(fù)的列建立索引,如果沒(méi)有符合的列,則 MySQL 自動(dòng)為 InnoDB 表生成一個(gè)隱含字段作為主鍵,并且這個(gè)字段長(zhǎng)度為 6 個(gè)字節(jié),類型為整型。
三、索引策略
哪些情況需要?jiǎng)?chuàng)建索引
主鍵自動(dòng)建立唯一索引
頻繁作為查詢條件的字段
查詢中與其他表關(guān)聯(lián)的字段,外鍵關(guān)系建立索引
單鍵/組合索引的選擇問(wèn)題,who? 高并發(fā)下傾向創(chuàng)建組合索引
查詢中排序的字段,排序字段通過(guò)索引訪問(wèn)大幅提高排序速度
查詢中統(tǒng)計(jì)或分組字段
哪些情況不要?jiǎng)?chuàng)建索引
表記錄太少 經(jīng)常增刪改的表 數(shù)據(jù)重復(fù)且分布均勻的表字段,只應(yīng)該為最經(jīng)常查詢和最經(jīng)常排序的數(shù)據(jù)列建立索引(如果某個(gè)數(shù)據(jù)類包含太多的重復(fù)數(shù)據(jù),建立索引沒(méi)有太大意義) 頻繁更新的字段不適合創(chuàng)建索引(會(huì)加重IO負(fù)擔(dān)) where 條件里用不到的字段不創(chuàng)建索引
高效索引[2]
獨(dú)立的列
如果查詢中的列不是獨(dú)立的,MySQL 就不會(huì)使用索引。“獨(dú)立的列”是指索引不能是表達(dá)式的一部分,也不能是函數(shù)的參數(shù)。
比如:
EXPLAIN SELECT * FROM mydb.sys_user where user_id = 2;
在 sys_user 表中,user_id 是主鍵,有主鍵索引,索引 explain 出來(lái)結(jié)果就是:

可見(jiàn)這次查詢使用了PRIMARY KEY來(lái)優(yōu)化查詢,如果變成這樣:
EXPLAIN SELECT * FROM mydb.sys_user where user_id + 1 = 2;
結(jié)果就是:

前綴索引
前綴索引其實(shí)就是對(duì)文本的前幾個(gè)字符(具體是幾個(gè)字符在建立索引時(shí)指定)建立索引,這樣建立起來(lái)的索引占用空間更小,所以查詢更快。
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
ALTER TABLE table_name ADD index index_name(column_name(prefix_length));
對(duì)于內(nèi)容很長(zhǎng)的列,比如 blob, text 或者很長(zhǎng)的 varchar 列,必須使用前綴索引,MySQL 不允許索引這些列的完整長(zhǎng)度。
所以問(wèn)題就在于要選擇合適長(zhǎng)度的前綴,即 prefix_length。前綴太短,選擇性太低,前綴太長(zhǎng),索引占用空間太大。
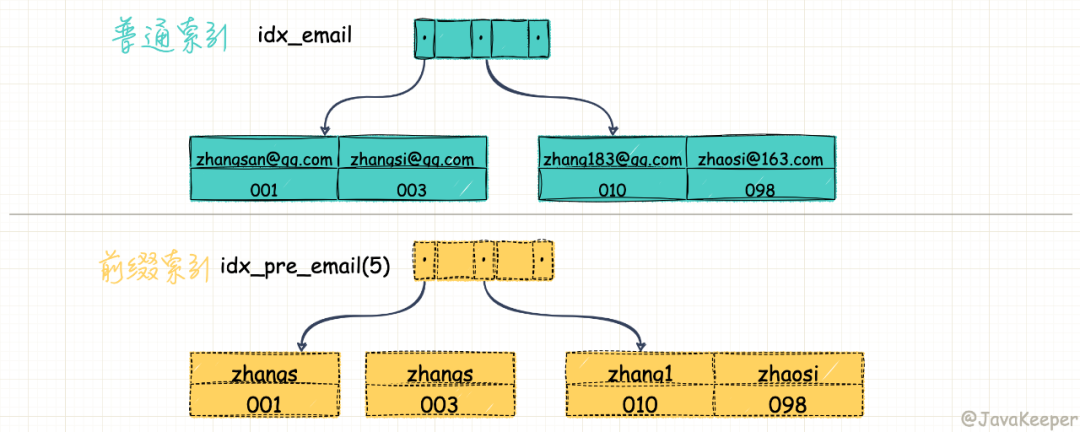
比如上圖中,兩個(gè)不同的索引同樣執(zhí)行下面的語(yǔ)句
select id,name,email from user where emai='[email protected]'
執(zhí)行效果會(huì)有很大的差別,普通索引 idx_email 找到滿足條件的記錄后,再返回主鍵索引取出數(shù)據(jù)即可,而前綴索引會(huì)多次查到 zhangs,然后返回主鍵索引取出數(shù)據(jù)進(jìn)行對(duì)比,會(huì)掃描多次數(shù)據(jù)行。
如果前綴索引取前 7 個(gè)字節(jié)構(gòu)建的話 idx_pre_email(7),就只需要掃描一行。
所以使用前綴索引,定義好長(zhǎng)度,就可以做到既節(jié)省空間,又不用額外增加太多的查詢成本。
為了決定前綴的合適長(zhǎng)度,需要找到最常見(jiàn)的值的列表,然后和最常見(jiàn)的前綴列進(jìn)行比較。
前綴索引是一種能使索引更小、更快的有效辦法,但另一方面也有缺點(diǎn):MySQL 無(wú)法使用前綴索引做 ORDER BY 和 GROUP BY,也無(wú)法使用前綴索引做『覆蓋索引』。
一個(gè)常見(jiàn)的場(chǎng)景是針對(duì)很長(zhǎng)的十六進(jìn)制唯一 ID 使用前綴索引。
身份證號(hào)這樣的數(shù)據(jù)如何索引?
使用倒序存儲(chǔ):如果你存儲(chǔ)身份證號(hào)的時(shí)候把它倒過(guò)來(lái)存,每次查詢的時(shí)候,你可以這么寫
select field_list from t where id_card = reverse('input_id_card_string');使用 hash 字段。你可以在表上再創(chuàng)建一個(gè)整數(shù)字段,來(lái)保存身份證的校驗(yàn)碼,同時(shí)在這個(gè)字段上創(chuàng)建索引。
alter table t add id_card_crc int unsigned, add index(id_card_crc);
--查詢
select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
覆蓋索引
覆蓋索引(Covering Index),或者叫索引覆蓋, 也就是平時(shí)所說(shuō)的不需要回表操作
就是 select 的數(shù)據(jù)列只用從索引中就能夠取得,不必讀取數(shù)據(jù)行,MySQL 可以利用索引返回 select 列表中的字段,而不必根據(jù)索引再次讀取數(shù)據(jù)文件,換句話說(shuō)查詢列要被所建的索引覆蓋。
索引是高效找到行的一個(gè)方法,但是一般數(shù)據(jù)庫(kù)也能使用索引找到一個(gè)列的數(shù)據(jù),因此它不必讀取整個(gè)行。畢竟索引葉子節(jié)點(diǎn)存儲(chǔ)了它們索引的數(shù)據(jù),當(dāng)能通過(guò)讀取索引就可以得到想要的數(shù)據(jù),那就不需要讀取行了。一個(gè)索引包含(覆蓋)滿足查詢結(jié)果的數(shù)據(jù)就叫做覆蓋索引。
判斷標(biāo)準(zhǔn)
使用 explain,可以通過(guò)輸出的 extra 列來(lái)判斷,對(duì)于一個(gè)索引覆蓋查詢,顯示為 using index,MySQL 查詢優(yōu)化器在執(zhí)行查詢前會(huì)決定是否有索引覆蓋查詢
多列索引(復(fù)合索引、聯(lián)合索引)
組合索引(concatenated index):由多個(gè)列構(gòu)成的索引,如 create index idx_emp on emp(col1, col2, col3, ……),則我們稱 idx_emp 索引為組合索引。
在多個(gè)列上建立獨(dú)立的單列索引大部分情況下并不能提高 MySQL 的查詢性能。對(duì)于下面的查詢 where 條件,這兩個(gè)單列索引都是不好的選擇:
SELECT user_id,user_name FROM mydb.sys_user where user_id = 1 or user_name = 'zhang3';
MySQL 5.0 版本之前,MySQL 會(huì)對(duì)這個(gè)查詢使用全表掃描,除非改寫成兩個(gè)查詢 UNION 的方式。
MySQL 5.0 和后續(xù)版本引入了一種叫做“索引合并”的策略,查詢能夠同時(shí)使用這兩個(gè)單列索引進(jìn)行掃描,并將結(jié)果合并。這種算法有三個(gè)變種:OR 條件的聯(lián)合(union),AND 條件的相交(intersection),組合前兩種情況的聯(lián)合及相交。索引合并策略有時(shí)候是一種優(yōu)化的結(jié)果,但實(shí)際上更多時(shí)候說(shuō)明了表上的索引建得很糟糕:
當(dāng)出現(xiàn)服務(wù)器對(duì)多個(gè)索引做相交操作時(shí)(多個(gè)AND條件),通常意味著需要一個(gè)包含所有相關(guān)列的多列索引,而不是多個(gè)獨(dú)立的單列索引。
當(dāng)出現(xiàn)服務(wù)器對(duì)多個(gè)索引做聯(lián)合操作時(shí)(多個(gè)OR條件),通常需要耗費(fèi)大量的 CPU 和內(nèi)存資源在算法的緩存、排序和合并操作上。特別是當(dāng)其中有些索引的選擇性不高,需要合并掃描返回的大量數(shù)據(jù)的時(shí)候。
如果在 explain 中看到有索引合并,應(yīng)該好好檢查一下查詢和表的結(jié)構(gòu),看是不是已經(jīng)是最優(yōu)的。
最左前綴原則
在組合索引中有一個(gè)重要的概念:引導(dǎo)列(leading column),在上面的例子中,col1 列為引導(dǎo)列。當(dāng)我們進(jìn)行查詢時(shí)可以使用 ”where col1 = ? ”,也可以使用 ”where col1 = ? and col2 = ?”,這樣的限制條件都會(huì)使用索引,但是”where col2 = ? ”查詢就不會(huì)使用該索引。所以限制條件中包含先導(dǎo)列時(shí),該限制條件才會(huì)使用該組合索引。
舉個(gè)栗子:
當(dāng) B+ 樹(shù)的數(shù)據(jù)項(xiàng)是復(fù)合的數(shù)據(jù)結(jié)構(gòu),比如(name,age,sex)的時(shí)候,B+ 樹(shù)是按照從左到右的順序來(lái)建立搜索樹(shù)的,比如當(dāng)(張三,20,F)這樣的數(shù)據(jù)來(lái)檢索的時(shí)候,B+ 樹(shù)會(huì)優(yōu)先比較 name 來(lái)確定下一步的所搜方向,如果 name 相同再依次比較 age 和 sex,最后得到檢索的數(shù)據(jù);但當(dāng) (20,F) 這樣的沒(méi)有 name 的數(shù)據(jù)來(lái)的時(shí)候,B+ 樹(shù)就不知道下一步該查哪個(gè)節(jié)點(diǎn),因?yàn)榻⑺阉鳂?shù)的時(shí)候 name 就是第一個(gè)比較因子,必須要先根據(jù) name 來(lái)搜索才能知道下一步去哪里查詢。比如當(dāng) (張三,F) 這樣的數(shù)據(jù)來(lái)檢索時(shí),B+ 樹(shù)可以用 name 來(lái)指定搜索方向,但下一個(gè)字段 age 的缺失,所以只能把名字等于張三的數(shù)據(jù)都找到,然后再匹配性別是 F 的數(shù)據(jù)了, 這個(gè)是非常重要的性質(zhì),即索引的最左匹配特性。
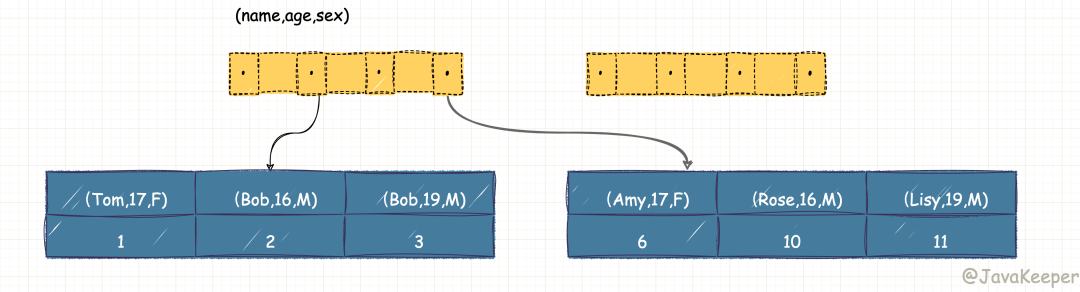
可以看到,索引項(xiàng)是按照索引定義里面出現(xiàn)的字段順序排序的。
當(dāng)你的邏輯需求是查到所有名字是“Bob”的人時(shí),可以快速定位到 ID = 2,然后向后遍歷得到所有需要的結(jié)果。
如果你要查的是所有名字第一個(gè)字母是“B”的人,你的 SQL 語(yǔ)句的條件是"where name like ‘B %’"。這時(shí),你也能夠用上這個(gè)索引,查找到第一個(gè)符合條件的記錄是 ID=2,然后向后遍歷,直到不滿足條件為止。
可以看到,不只是索引的全部定義,只要滿足最左前綴,就可以利用索引來(lái)加速檢索。這個(gè)最左前綴可以是聯(lián)合索引的最左 N 個(gè)字段,也可以是字符串索引的最左 M 個(gè)字符。
那么就會(huì)出現(xiàn)一個(gè)問(wèn)題:在建立聯(lián)合索引的時(shí)候,如何安排索引內(nèi)的字段順序。
這里我們的評(píng)估標(biāo)準(zhǔn)是,索引的復(fù)用能力。因?yàn)榭梢灾С肿钭笄熬Y,所以當(dāng)已經(jīng)有了 (a,b) 這個(gè)聯(lián)合索引后,一般就不需要單獨(dú)在 a 上建立索引了。因此,第一原則是,如果通過(guò)調(diào)整順序,可以少維護(hù)一個(gè)索引,那么這個(gè)順序往往就是需要優(yōu)先考慮采用的。
索引下推
上一段我們說(shuō)到滿足最左前綴原則的時(shí)候,最左前綴可以用于在索引中定位記錄。這時(shí),你可能要問(wèn),那些不符合最左前綴的部分,會(huì)怎么樣呢?
我們還是以聯(lián)合索引(name,age,sex)為例。如果現(xiàn)在有一個(gè)需求:檢索出表中“名字第一個(gè)字是 B,而且年齡是 19 歲的所有男孩”。那么,SQL 語(yǔ)句是這么寫的:
mysql> select * from tuser where name like 'B %' and age=19 and sex=F;
你已經(jīng)知道了前綴索引規(guī)則,所以這個(gè)語(yǔ)句在搜索索引樹(shù)的時(shí)候,只能用 “B”,找到第一個(gè)滿足條件的記錄 ID = 2。當(dāng)然,這還不錯(cuò),總比全表掃描要好。(組合索引滿足最左匹配,但是遇到非等值判斷時(shí)匹配停止)
然后呢?
當(dāng)然是判斷其他條件是否滿足。
在 MySQL 5.6 之前,只能從 ID = 2 開(kāi)始一個(gè)個(gè)回表。到主鍵索引上找出數(shù)據(jù)行,再對(duì)比字段值。
而 MySQL 5.6 引入的索引下推優(yōu)化(index condition pushdown), 可以在索引遍歷過(guò)程中,對(duì)索引中包含的字段先做判斷,直接過(guò)濾掉不滿足條件的記錄,減少回表次數(shù)。
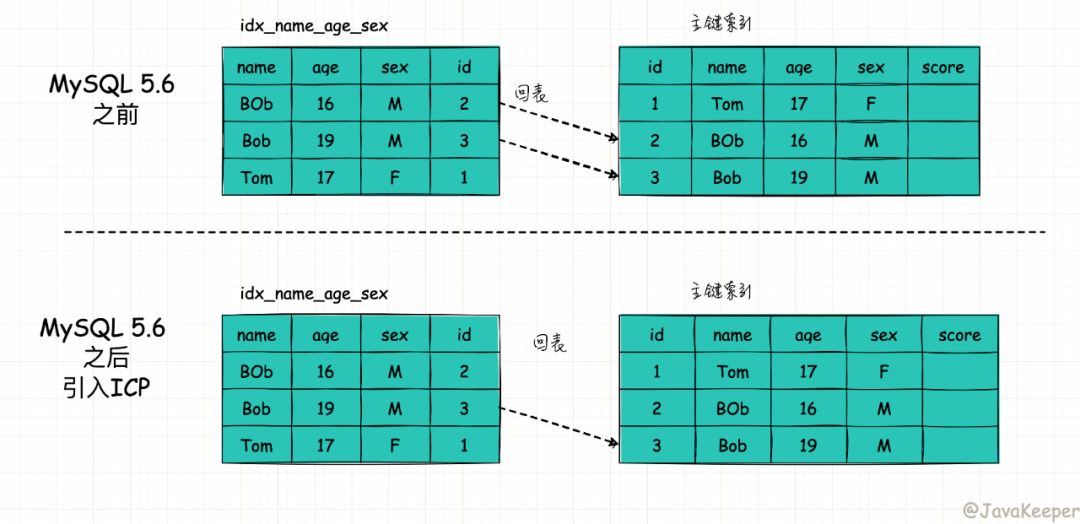
索引下推在非主鍵索引上的優(yōu)化,可以有效減少回表的次數(shù),大大提升了查詢的效率
使用索引掃描來(lái)做排序
MySQL 有兩種方式可以生成有序的結(jié)果,通過(guò)排序操作或者按照索引順序掃描,如果 explain 的 type 列的值為 index,則說(shuō)明 MySQL 使用了索引掃描來(lái)做排序(不要和 extra 列的 Using index 搞混了,那個(gè)是使用了覆蓋索引查詢)。
掃描索引本身是很快的,因?yàn)橹恍枰獜囊粭l索引記錄移動(dòng)到緊接著的下一條記錄,但如果索引不能覆蓋查詢所需的全部列,那就不得不每掃描一條索引記錄就回表查詢一次對(duì)應(yīng)的整行,這基本上都是隨機(jī) I/O,因此按索引順序讀取數(shù)據(jù)的速度通常要比順序地全表掃描慢,尤其是在 I/O 密集型的工作負(fù)載時(shí)。
MySQL 可以使用同一個(gè)索引既滿足排序,又用于查找行,因此,如果可能,設(shè)計(jì)索引時(shí)應(yīng)該盡可能地同時(shí)滿足這兩種任務(wù),這樣是最好的。
只有當(dāng)索引的列順序和 order by 子句的順序完全一致,并且所有列的排序方向(倒序或升序,創(chuàng)建索引時(shí)可以指定 ASC 或 DESC)都一樣時(shí),MySQL 才能使用索引來(lái)對(duì)結(jié)果做排序,如果查詢需要關(guān)聯(lián)多張表,則只有當(dāng) order by 子句引用的字段全部為第一個(gè)表時(shí),才能使用索引做排序,order by 子句和查找型查詢的限制是一樣的,需要滿足索引的最左前綴的要求,否則 MySQL 都需要執(zhí)行排序操作,而無(wú)法使用索引排序。
壓縮(前綴壓縮)索引
MyISAM 使用前綴壓縮來(lái)減少索引的大小,從而讓更多的索引可以放入內(nèi)存中,這在某些情況下能極大地提高性能。
默認(rèn)只壓縮字符串,但通過(guò)參數(shù)設(shè)置也可以對(duì)整數(shù)做壓縮。
重復(fù)索引和冗余索引
MySQL 允許在相同列上創(chuàng)建多個(gè)索引,無(wú)論是有意的還是無(wú)意的。有意的用途沒(méi)想明白~
重復(fù)索引是指在相同的列上按照相同的順序創(chuàng)建的相同類型的索引。應(yīng)該避免這樣創(chuàng)建重復(fù)索引,發(fā)現(xiàn)以后也應(yīng)該立即移除。
冗余索引和重復(fù)索引有一些不同。如果創(chuàng)建了索引(A,B),再創(chuàng)建索引(A)就是冗余索引,因?yàn)檫@只是前一個(gè)索引的前綴索引。因此索引(A,B)也可以當(dāng)做索引(A)來(lái)使用(這種冗余只是對(duì) B-Tree 索引來(lái)說(shuō)的)。但是如果再創(chuàng)建索引(B,A),則不是冗余索引,索引(B)也不是,因?yàn)锽不是索引(A,B)的最左前綴。另外,其他不同類型的索引(例如哈希索引或者全文索引)也不會(huì)是 B-Tree 索引的冗余索引,而無(wú)論覆蓋的索引列是什么。
未使用的索引
除了冗余索引和重復(fù)索引,可能還會(huì)有一些服務(wù)器永遠(yuǎn)不使用的索引,這樣的索引完全是累贅,建議考慮刪除,有兩個(gè)工具可以幫助定位未使用的索引:
在 percona server 或者 mariadb 中先打開(kāi) userstat=ON 服務(wù)器變量,默認(rèn)是關(guān)閉的,然后讓服務(wù)器運(yùn)行一段時(shí)間,再通過(guò)查詢
information_schema.index_statistics就能查到每個(gè)索引的使用頻率。使用 percona toolkit 中的 pt-index-usage 工具,該工具可以讀取查詢?nèi)罩荆?duì)日志中的每個(gè)查詢進(jìn)行explain 操作,然后打印出關(guān)于索引和查詢的報(bào)告,這個(gè)工具不僅可以找出哪些索引是未使用的,還可以了解查詢的執(zhí)行計(jì)劃。
四、索引優(yōu)化
導(dǎo)致 SQL 執(zhí)行慢的原因
硬件問(wèn)題。如網(wǎng)絡(luò)速度慢,內(nèi)存不足,I/O 吞吐量小,磁盤空間滿了等
沒(méi)有索引或者索引失效
數(shù)據(jù)過(guò)多(分庫(kù)分表)
服務(wù)器調(diào)優(yōu)及各個(gè)參數(shù)設(shè)置(調(diào)整my.cnf)
索引優(yōu)化
全值匹配我最愛(ài) 最佳左前綴法則,比如建立了一個(gè)聯(lián)合索引(a,b,c),那么其實(shí)我們可利用的索引就有(a) ?(a,b)(a,c)(a,b,c) 不在索引列上做任何操作(計(jì)算、函數(shù)、(自動(dòng)or手動(dòng))類型轉(zhuǎn)換),會(huì)導(dǎo)致索引失效而轉(zhuǎn)向全表掃描 存儲(chǔ)引擎不能使用索引中范圍條件右邊的列 盡量使用覆蓋索引(只訪問(wèn)索引的查詢(索引列和查詢列一致)),減少 select * is null ,is not null 也無(wú)法使用索引 like "xxxx%"是可以用到索引的,like "%xxxx"則不行(like "%xxx%" 同理)。like 以通配符開(kāi)頭('%abc...')索引失效會(huì)變成全表掃描的操作,字符串不加單引號(hào)索引失效 少用or,用它來(lái)連接時(shí)會(huì)索引失效(這個(gè)其實(shí)不是絕對(duì)的,or 走索引與否,還和優(yōu)化器的預(yù)估有關(guān),5.0 之后出現(xiàn)的 index merge 技術(shù)就是優(yōu)化這個(gè)的) <,<=,=,>,>=,BETWEEN,IN 可用到索引,<>,not in ,!= 則不行,會(huì)導(dǎo)致全表掃描
建索引的幾大原則[3]
最左前綴匹配原則,非常重要的原則,MySQL 會(huì)一直向右匹配直到遇到范圍查詢(>、<、between、like)就停止匹配,比如
a = 1 and b = 2 and c > 3 and d = 4如果建立(a,b,c,d)順序的索引,d 是用不到索引的,如果建立(a,b,d,c)的索引則都可以用到,a,b,d 的順序可以任意調(diào)整。= 和 in 可以亂序,比如
a = 1 and b = 2 and c = 3建立(a,b,c)索引可以任意順序,MySQL 的查詢優(yōu)化器會(huì)幫你優(yōu)化成索引可以識(shí)別的形式。盡量選擇區(qū)分度高的列作為索引,區(qū)分度的公式是
count(distinct col)/count(*),表示字段不重復(fù)的比例,比例越大我們掃描的記錄數(shù)越少,唯一鍵的區(qū)分度是 1,而一些狀態(tài)、性別字段可能在大數(shù)據(jù)面前區(qū)分度就是 0,那可能有人會(huì)問(wèn),這個(gè)比例有什么經(jīng)驗(yàn)值嗎?使用場(chǎng)景不同,這個(gè)值也很難確定,一般需要 join 的字段我們都要求是 0.1 以上,即平均 1 條掃描 10 條記錄。索引列不能參與計(jì)算,保持列“干凈”,比如
from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很簡(jiǎn)單,b+ 樹(shù)中存的都是數(shù)據(jù)表中的字段值,但進(jìn)行檢索時(shí),需要把所有元素都應(yīng)用函數(shù)才能比較,顯然成本太大。所以語(yǔ)句應(yīng)該寫成create_time = unix_timestamp(’2014-05-29’)。盡量的擴(kuò)展索引,不要新建索引。比如表中已經(jīng)有 a 的索引,現(xiàn)在要加(a,b)的索引,那么只需要修改原來(lái)的索引即可。
Reference
https://zh.wikipedia.org/wiki/B%E6%A0%91 https://medium.com/@mena.meseha/what-is-the-difference-between-mysql-innodb-b-tree-index-and-hash-index-ed8f2ce66d69 https://www.javatpoint.com/b-tree https://blog.csdn.net/Abysscarry/article/details/80792876 《MySQL 實(shí)戰(zhàn) 45 講》 《高性能 MySQL》

