
機器學習中各種樹模型總結
來自于點擊下方卡片,關注“新機器視覺”公眾號
視覺/圖像重磅干貨,第一時間送達
作者:ChrisCao@知乎
https://zhuanlan.zhihu.com/p/75468124編輯:好奇心log
一. 決策樹
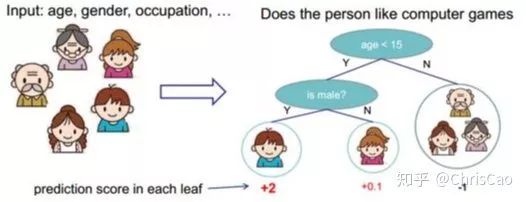
1.ID3算法:以信息增益為準則來選擇最優(yōu)劃分屬性
 ?信息熵越小,數(shù)據(jù)集?
?信息熵越小,數(shù)據(jù)集? ?的純度越大
?的純度越大 ?上建立決策樹,數(shù)據(jù)有?
?上建立決策樹,數(shù)據(jù)有? ?個類別:
?個類別:
 ?表示第K類樣本的總數(shù)占數(shù)據(jù)集D樣本總數(shù)的比例。
?表示第K類樣本的總數(shù)占數(shù)據(jù)集D樣本總數(shù)的比例。2.C4.5基于信息增益率準則 選擇最有分割屬性的算法
 ?,?
?,?
3.CART:以基尼系數(shù)為準則選擇最優(yōu)劃分屬性,可用于分類和回歸
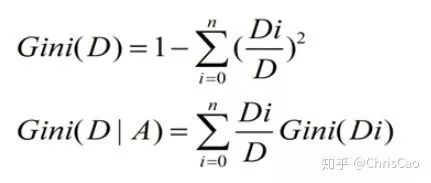
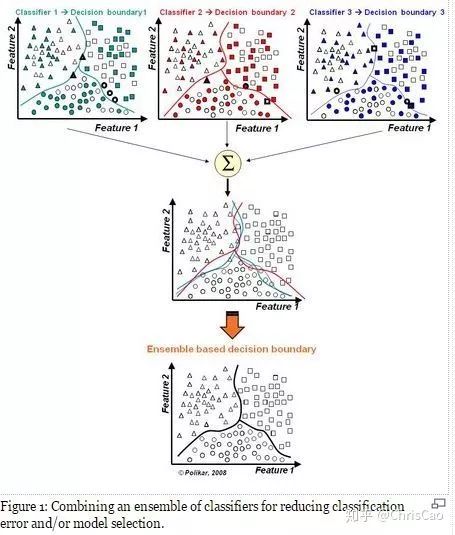
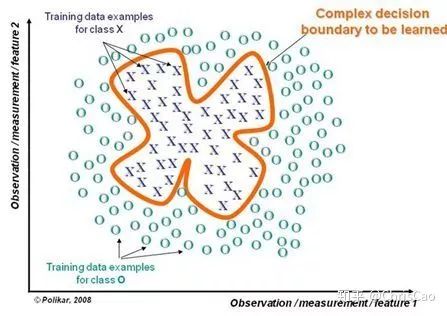
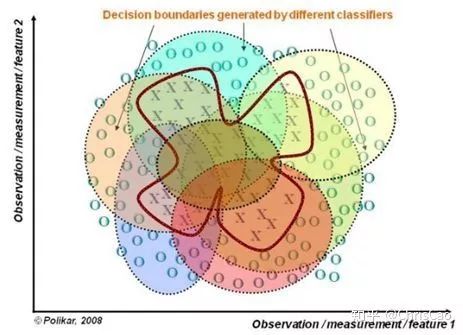
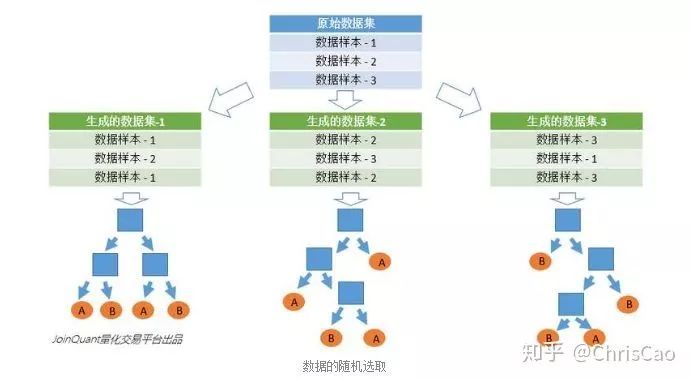
二.隨機森林
1.構建組合分類器的好處:
三、GBDT和XGBoost
1.在講GBDT和XGBoost之前先補充Bagging和Boosting的知識。
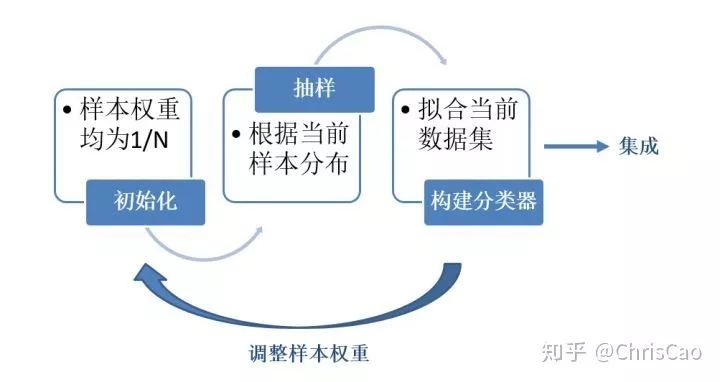
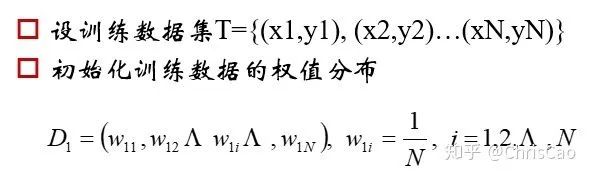

 ?計算的是當前數(shù)據(jù)下,模型的分類誤差率,模型的系數(shù)值是基于分類誤差率的
?計算的是當前數(shù)據(jù)下,模型的分類誤差率,模型的系數(shù)值是基于分類誤差率的

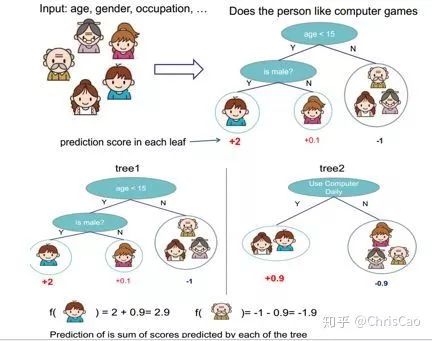
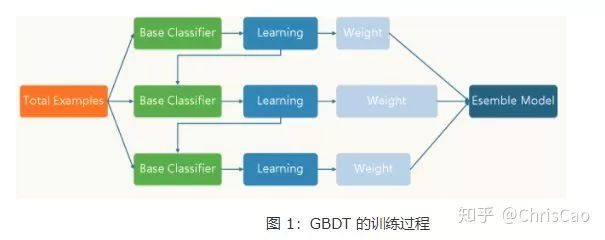
2.GBDT

3.XGBoost


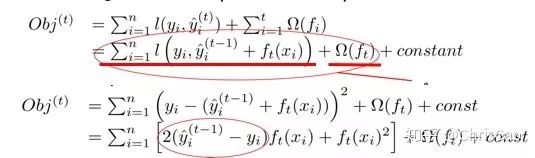
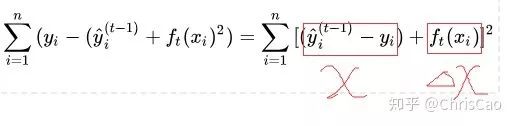

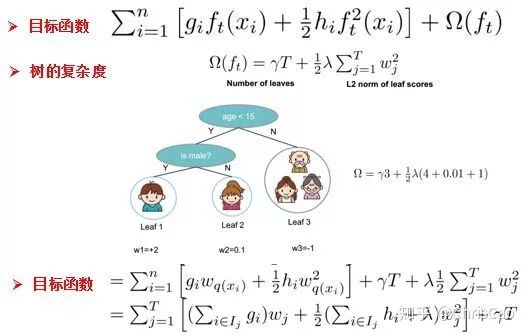
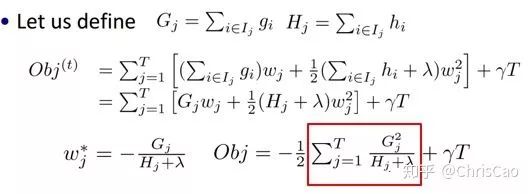

point的候選,遍歷所有的候選分裂點來找到最佳分裂點。
評論
圖片
表情