
Thanos 與 VictoriaMetrics,誰才是打造大型 Prometheus 監(jiān)控系統(tǒng)的王者?
更多精彩內(nèi)容歡迎訂閱我的博客:https://fuckcloudnative.io/
Prometheus 長期存儲(chǔ)的成熟方案,其中 VictoriaMetrics 也開源了其集群版本[3],功能更加強(qiáng)大。這兩種解決方案都提供了以下功能:長期存儲(chǔ),可以保留任意時(shí)間的監(jiān)控?cái)?shù)據(jù)。 對(duì)多個(gè) Prometheus 實(shí)例采集的數(shù)據(jù)進(jìn)行全局聚合查詢。 可水平擴(kuò)展。
本文就來對(duì)比一下這兩種方案的差異性和優(yōu)缺點(diǎn),主要從寫入和讀取這兩個(gè)方面來比較,每一個(gè)方面的比較都包含以下幾個(gè)角度:
配置和操作的復(fù)雜度 可靠性和可用性 數(shù)據(jù)一致性 性能 可擴(kuò)展性
先來看一下這兩種方案的架構(gòu)。
1. 架構(gòu)
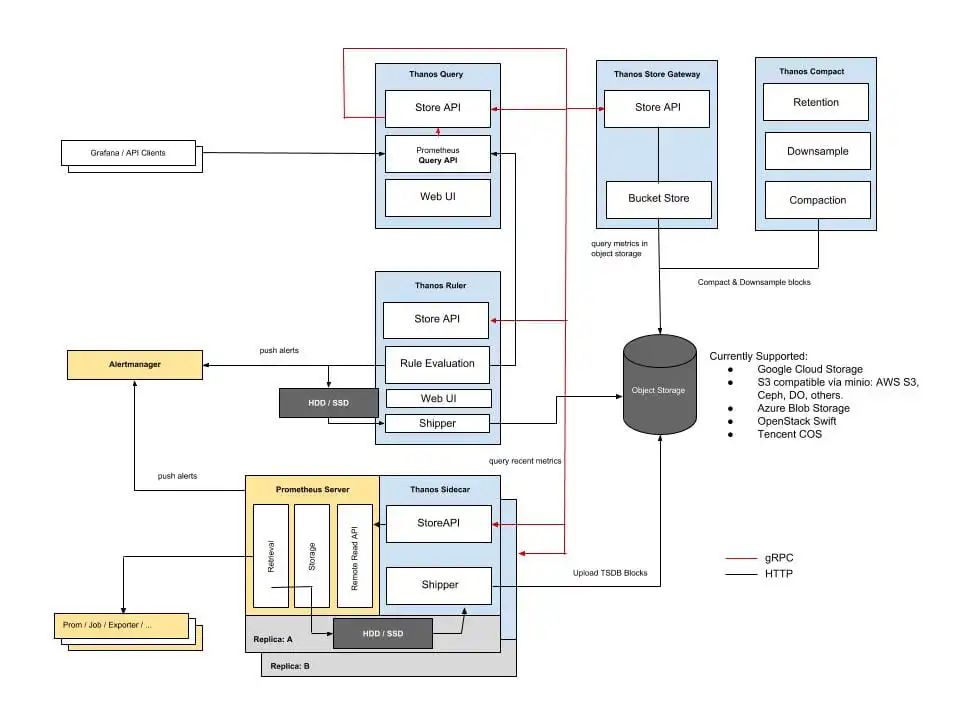
Thanos
Thanos[4] 包含以下幾個(gè)核心組件:
Sidecar [5] : 每個(gè) Prometheus 實(shí)例都包含一個(gè)
Sidecar,它與 Prometheus 實(shí)例運(yùn)行在同一個(gè) Pod 中。它有兩個(gè)作用:1) 將本地超過 2 小時(shí)的監(jiān)控?cái)?shù)據(jù)上傳到對(duì)象存儲(chǔ),如 Amazon S3 或 Google 云存儲(chǔ)。2) 將本地監(jiān)控?cái)?shù)據(jù)(小于 2 小時(shí))提供給 Thanos Query 查詢。Store[6] Gateway : 將對(duì)象存儲(chǔ)的數(shù)據(jù)提供給 Thanos Query 查詢。
Query[7] : 實(shí)現(xiàn)了 Prometheus 的查詢 API[8],將 Sidecar 和對(duì)象存儲(chǔ)提供的數(shù)據(jù)進(jìn)行聚合最終返回給查詢數(shù)據(jù)的客戶端(如
Grafana)。Compact[9] : 默認(rèn)情況下,Sidecar 以 2 小時(shí)為單位將監(jiān)控?cái)?shù)據(jù)上傳到對(duì)象存儲(chǔ)中。
Compactor會(huì)逐漸將這些數(shù)據(jù)塊合并成更大的數(shù)據(jù)塊,以提高查詢效率,減少所需的存儲(chǔ)大小。Ruler[10] : 通過查詢
Query獲取全局?jǐn)?shù)據(jù),然后對(duì)監(jiān)控?cái)?shù)據(jù)評(píng)估記錄規(guī)則[11]和告警規(guī)則,決定是否發(fā)起告警。還可以根據(jù)規(guī)則配置計(jì)算新指標(biāo)并存儲(chǔ),同時(shí)也通過 Store API 將數(shù)據(jù)暴露給Query,同樣還可以將數(shù)據(jù)上傳到對(duì)象存儲(chǔ)以供長期保存。由于Query和底層組件的可靠性較低,Ruler?組件通常故障率較高[12]:Ruler 組件在架構(gòu)上做了一些權(quán)衡取舍,強(qiáng)依賴查詢的可靠性,這可能對(duì)大多數(shù)場景都不利。對(duì)于 Prometheus 來說,都是直接從本地讀取告警規(guī)則和記錄規(guī)則,所以不太可能出現(xiàn)失敗的情況。而對(duì)于
Ruler來說,規(guī)則的讀取來源是分布式的,最有可能直接查詢 Thanos Query,而 Thanos Query 是從遠(yuǎn)程 Store APIs 獲取數(shù)據(jù)的,所以就有可能遇到查詢失敗的情況。Receiver[13] : 這是一個(gè)實(shí)驗(yàn)性組件,適配了 Prometheus 的 remote write API,也就是所有 Prometheus 實(shí)例可以實(shí)時(shí)將數(shù)據(jù) push 到
Receiver。在 Thanos v0.5.0 時(shí),該組件還沒有正式發(fā)布。
最后再來看一眼 Thanos 的整體架構(gòu)圖:
VictoriaMetrics
VictoriaMetrics 集群版包含以下幾個(gè)核心組件:
vmstorage : 存儲(chǔ)數(shù)據(jù)。 vminsert : 通過 remote write API[14] 接收來自 Prometheus 的數(shù)據(jù)并將其分布在可用的 vmstorage節(jié)點(diǎn)上。vmselect : 從 vmstorage節(jié)點(diǎn)獲取并聚合所需數(shù)據(jù),返回給查詢數(shù)據(jù)的客戶端(如 Grafana)。
每個(gè)組件可以使用最合適的硬件配置獨(dú)立擴(kuò)展到多個(gè)節(jié)點(diǎn)。
整體架構(gòu)圖如下:
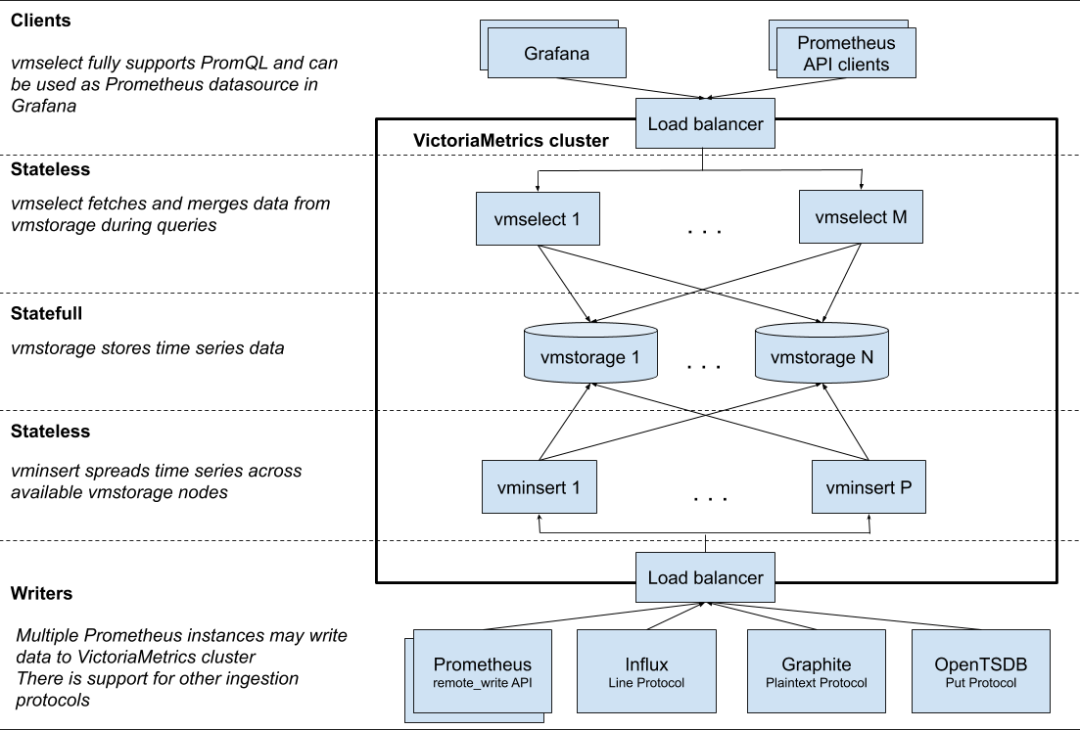
圖中的 VictoriaMetrics 集群和 Load balancer 都可以通過 helm[15] 部署在 Kubernetes 中。對(duì)于大部分中小型集群來說,不需要水平擴(kuò)展的功能,可以直接使用單機(jī)版的 VictoriaMetrics。更多信息請參考垂直擴(kuò)展基準(zhǔn)[16]。
了解這兩種方案的架構(gòu)后,開始進(jìn)入對(duì)比環(huán)節(jié)。
注意:下文提到的
VictoriaMetrics如沒有特殊說明,均指的是集群版。
2. 寫入對(duì)比
配置和操作的復(fù)雜度
Thanos 需要通過以下步驟來建立寫入過程:
禁用每個(gè) Prometheus 實(shí)例的本地?cái)?shù)據(jù)壓縮。具體做法是將
--storage.tsdb.min-block-duration和--storage.tsdb.max-block-duration這兩個(gè)參數(shù)的值設(shè)置為相同的值。Thanos 要求關(guān)閉壓縮是因?yàn)?Prometheus 默認(rèn)會(huì)以
2,25,25*5的周期進(jìn)行壓縮,如果不關(guān)閉,可能會(huì)導(dǎo)致 Thanos 剛要上傳一個(gè) block,這個(gè) block 卻被壓縮中,導(dǎo)致上傳失敗。更多詳情請參考這個(gè) issue[17]。如果--storage.tsdb.retainer.time參數(shù)的值遠(yuǎn)遠(yuǎn)高于 2 小時(shí),禁用數(shù)據(jù)壓縮可能會(huì)影響 Prometheus 的查詢性能。在所有的 Prometheus 實(shí)例中插入
Sidecar,這樣Sidecar就可以將監(jiān)控?cái)?shù)據(jù)上傳到對(duì)象存儲(chǔ)。設(shè)置 Sidecar 監(jiān)控。
為每個(gè)對(duì)象存儲(chǔ)的 bucket 配置壓縮器,即 Compact[18] 組件。
VictoriaMetrics 需要在 Prometheus 中添加遠(yuǎn)程存儲(chǔ)的配置[19],以將采集到的樣本數(shù)據(jù)通過 Remote Write 的方式寫入遠(yuǎn)程存儲(chǔ) VictoriaMetrics 中,不需要在 Prometheus 中插入 Sidecar,也不需要禁用本地?cái)?shù)據(jù)壓縮。詳情請參考官方文檔[20]。
可靠性和可用性
Thanos Sidecar 以 2 小時(shí)為單位將本地監(jiān)控?cái)?shù)據(jù)上傳到分布式對(duì)象存儲(chǔ),這就意味著如果本地磁盤損壞或者數(shù)據(jù)被意外刪除,就有可能會(huì)丟失每個(gè) Prometheus 實(shí)例上最近 2 小時(shí)添加的數(shù)據(jù)。
從查詢組件到 Sidecar 的查詢可能會(huì)對(duì) Sidecar 數(shù)據(jù)的上傳產(chǎn)生負(fù)面影響,因?yàn)轫憫?yīng)查詢和上傳的任務(wù)都是在同一個(gè) Sidecar 進(jìn)程中執(zhí)行的。但理論上可以將負(fù)責(zé)響應(yīng)查詢的任務(wù)和上傳的任務(wù)分別運(yùn)行在不同的 Sidecar 中。
對(duì)于 VictoriaMetrics 來說,每個(gè) Prometheus 實(shí)例都會(huì)實(shí)時(shí)通過 remote_write API 將所有監(jiān)控?cái)?shù)據(jù)復(fù)制到遠(yuǎn)程存儲(chǔ) VictoriaMetrics。在抓取數(shù)據(jù)和將數(shù)據(jù)寫入遠(yuǎn)程存儲(chǔ)之間可能會(huì)有幾秒鐘的延遲,所以如果本地磁盤損壞或者數(shù)據(jù)被意外刪除,只會(huì)丟失每個(gè) Prometheus 實(shí)例上最近幾秒鐘添加的數(shù)據(jù)。
從 Prometheus v2.8.0+ 開始,Prometheus 會(huì)直接從預(yù)寫日志(WAL,write-ahead log)中復(fù)制數(shù)據(jù)到遠(yuǎn)程存儲(chǔ),所以不會(huì)因?yàn)榕c遠(yuǎn)程存儲(chǔ)的臨時(shí)連接錯(cuò)誤或遠(yuǎn)程存儲(chǔ)臨時(shí)不可用而丟失數(shù)據(jù)。具體的原理是,如果與遠(yuǎn)程存儲(chǔ)的連接出現(xiàn)問題,Prometheus 會(huì)自動(dòng)停止在預(yù)寫日志(WAL)的位置,并嘗試重新發(fā)送失敗的那一批樣本數(shù)據(jù),從而避免了數(shù)據(jù)丟失的風(fēng)險(xiǎn)。同時(shí),由于出現(xiàn)問題時(shí) Prometheus 不會(huì)繼續(xù)往下讀取預(yù)寫日志(WAL),所以不會(huì)消耗更多的內(nèi)存。
數(shù)據(jù)一致性
Thanos 的 Compactor 和 Store Gateway 存在競爭關(guān)系,可能會(huì)導(dǎo)致數(shù)據(jù)不一致或查詢失敗。例如:
如果 Thanos sidecar 或 compactor 在上傳數(shù)據(jù)的過程中崩潰了,如何確保讀取數(shù)據(jù)的客戶端(如 Compactor 和 Store Gateway)都能夠優(yōu)雅地處理這個(gè)問題? 分布式對(duì)象存儲(chǔ)對(duì)于一個(gè)新上傳的對(duì)象提供寫后讀寫一致性(read-after-write consistency);對(duì)于已存在對(duì)象的復(fù)寫提供最終讀寫一致性(eventual consistency)。舉個(gè)例子,假設(shè)我們有一個(gè)嶄新的文件,PUT 之后馬上 GET ,OK,沒有問題,這就是寫后讀寫一致性;假設(shè)我們上傳了一個(gè)文件,之后再 PUT 一個(gè)和這個(gè)文件的 key 一樣,但是內(nèi)容不同的新文件,之后再 GET。這個(gè)時(shí)候 GET 請求的結(jié)果很可能還是舊的文件。對(duì)于 Thanos compactor 來說,它會(huì)上傳壓縮的數(shù)據(jù)塊,刪除源數(shù)據(jù)塊,那么在下一次同步迭代后,它可能會(huì)獲取不到更新的數(shù)據(jù)塊(最終讀寫一致性),從而又重新壓縮了一次數(shù)據(jù)塊并上傳,出現(xiàn)數(shù)據(jù)重疊的現(xiàn)象。 對(duì)于 Store Gateway 來說,它每 3 分鐘同步一次數(shù)據(jù),查詢組件可能會(huì)試圖獲取刪除的源數(shù)據(jù)塊,從而失敗。
更多詳情請參考 Read-Write coordination free operational contract for object storage[21]。
VictoriaMetrics 可以保持?jǐn)?shù)據(jù)的強(qiáng)一致性,詳情可參考它的存儲(chǔ)架構(gòu)[22]。
性能
Thanos 的寫入性能不錯(cuò),因?yàn)?Sidecar 只是將 Prometheus 創(chuàng)建的本地?cái)?shù)據(jù)塊上傳到對(duì)象存儲(chǔ)中。其中 Query 組件的重度查詢可能會(huì)影響 Sidecar 數(shù)據(jù)上傳的速度。對(duì)于 Compactor 組件來說,如果新上傳的數(shù)據(jù)塊超出了 Compactor 的性能,可能會(huì)對(duì)對(duì)象存儲(chǔ) bucket 帶來不利。
而 VictoriaMetrics 使用的是遠(yuǎn)程存儲(chǔ)的方式,Prometheus 會(huì)使用額外的 CPU 時(shí)間來將本地?cái)?shù)據(jù)復(fù)制到遠(yuǎn)程存儲(chǔ),這與 Prometheus 執(zhí)行的其他任務(wù)(如抓取數(shù)據(jù)、規(guī)則評(píng)估等)所消耗的 CPU 時(shí)間相比,可以忽略不計(jì)。同時(shí),在遠(yuǎn)程存儲(chǔ)數(shù)據(jù)接收端,VictoriaMetrics 可以按需分配合理的 CPU 時(shí)間,足以保障性能。參考 Measuring vertical scalability for time series databases in Google Cloud[23]。
可擴(kuò)展性
Thanos Sidecar 在數(shù)據(jù)塊上傳過程中依賴于對(duì)象存儲(chǔ)的可擴(kuò)展性。S3 和 GCS 的擴(kuò)展性都很強(qiáng)。
VictoriaMetrics 的擴(kuò)展只需要增加 vminsert 和 vmstorage 的容量即可,容量的增加可以通過增加新的節(jié)點(diǎn)或者更換性能更強(qiáng)的硬件來實(shí)現(xiàn)。
3. 讀取對(duì)比
配置和操作的復(fù)雜度
Thanos 需要通過以下步驟來建立讀取過程:
Sidecar [24] 為每個(gè) Prometheus 實(shí)例啟用 Store API,以 將本地監(jiān)控?cái)?shù)據(jù)(小于 2 小時(shí))提供給 Thanos Query查詢。Store[25] Gateway 將對(duì)象存儲(chǔ)的數(shù)據(jù)暴露出來提供給 Thanos Query 查詢。 Query[26] 組件的查詢動(dòng)作會(huì)覆蓋到所有的 Sidecar和Store Gateway,以便利用 Prometheues 的查詢 API[27] 實(shí)現(xiàn)全局查詢。如果 Query 組件和 Sidecar 組件位于不同數(shù)據(jù)中心,在它們之間建立安全可靠連接可能會(huì)很困難。
VictoriaMetrics 提供了開箱即用的 Prometheues 查詢 API[28],所以不需要在 VictoriaMetrics 集群外設(shè)置任何額外的組件。只需要將 `Grafana` 中的數(shù)據(jù)源指向 VictoriaMetrics[29] 即可。
可靠性和可用性
Thanos 的 Query 組件需要和所有的 Sidecar 和 Store Gateway 建立連接,從而為客戶端(如 Grafana)的查詢請求計(jì)算完整的數(shù)據(jù)。如果 Prometheus 實(shí)例跨多個(gè)數(shù)據(jù)中心,可能會(huì)嚴(yán)重影響查詢的可靠性。
如果對(duì)象存儲(chǔ)中存在容量很大的 bucket,Store Gateway 的啟動(dòng)時(shí)間會(huì)很長,因?yàn)樗枰趩?dòng)前從 bucket 中加載所有元數(shù)據(jù),詳情可以參考這個(gè) issue[30]。如果 Thanos 需要升級(jí)版本,這個(gè)問題帶來的負(fù)面影響會(huì)非常明顯。
VictoriaMetrics 的查詢過程只涉及到集群內(nèi)部的 vmselect 和 vmstorage 之間的本地連接,與 Thanos 相比,這種本地連接具有更高的可靠性和可用性。
VictoriaMetrics 所有組件的啟動(dòng)時(shí)間都很短,因此可以快速升級(jí)。
數(shù)據(jù)一致性
Thanos 默認(rèn)情況下[31]允許在部分 Sidecar 或 Store Gateway 不可用時(shí)只返回部分查詢結(jié)果[32]。
VictoriaMetrics 也可以在部分 vmstorage 節(jié)點(diǎn)不可用時(shí)只返回部分查詢結(jié)果,從而優(yōu)先考慮可用性而不是一致性。具體的做法是啟用 -search.denyPartialResponse 選項(xiàng)。
總的來說,VictoriaMetrics 返回部分查詢結(jié)果的可能性更低,因?yàn)樗目捎眯愿摺?/p>
性能
Thanos Query 組件的查詢性能取決于查詢性能最差的 Sidecar 或 Store Gateway 組件,因?yàn)?Query 組件返回查詢結(jié)果之前會(huì)等待所有 Sidecar 和 Store Gateway 組件的響應(yīng)。
通常 Sidecar 或 Store Gateway 組件的查詢性能不是均衡的,這取決于很多因素:
每個(gè) Promnetheus 實(shí)例抓取的數(shù)據(jù)容量。 Store Gateway 背后每個(gè)對(duì)象存儲(chǔ) bucket的容量。每個(gè) Prometheus + Sidecar 和 Store Gateway 的硬件配置。 Query組件和 Sidecar 或 Store Gateway 之間的網(wǎng)絡(luò)延遲。如果Query和 Sidecar 位于不同的數(shù)據(jù)中心,延遲可能會(huì)相當(dāng)高。對(duì)象存儲(chǔ)的操作延遲。通常對(duì)象存儲(chǔ)延遲( S3、GCS)比塊存儲(chǔ)延遲(GCE磁盤、EBS)高得多。
VictoriaMetrics 的查詢性能受到 vmselect 和 vmstorage 的實(shí)例數(shù)量及其資源配額的限制。只需增加實(shí)例數(shù),或者分配更多的資源配額,即可擴(kuò)展查詢性能。vminsert 會(huì)將 Prometheus 寫入的數(shù)據(jù)均勻地分布到可用的 vmstorage 實(shí)例中,所以 vmstorage 的性能是均衡的。VictoriaMetrics 針對(duì)查詢速度做了優(yōu)化[33],所以與 Thanos 相比,它應(yīng)該會(huì)提供更好的查詢性能。
可擴(kuò)展性
Thanos 的 Query 組件是無狀態(tài)服務(wù),可用通過水平擴(kuò)展來分擔(dān)查詢負(fù)載。Store Gateway 也支持多副本水平擴(kuò)展,對(duì)每一個(gè)對(duì)象存儲(chǔ) bucket 而言,多個(gè) Store Gateway 副本也可以分擔(dān)查詢負(fù)載。但是要擴(kuò)展 Sidecar 后面的單個(gè) Prometheus 實(shí)例的性能是相當(dāng)困難的,所以 Thanos 的查詢性能受到性能最差的 Prometheus + Sidecar 的限制。
VictoriaMetrics 在查詢方面提供了更好的擴(kuò)展性,因?yàn)?vmselect 和 vmstorage 組件的實(shí)例可以獨(dú)立擴(kuò)展到任何數(shù)量。集群內(nèi)的網(wǎng)絡(luò)帶寬可能會(huì)成為限制擴(kuò)展性的因素,VictoriaMetrics 針對(duì)低網(wǎng)絡(luò)帶寬的使用進(jìn)行了優(yōu)化,以減少這一限制因素。
4. 高可用對(duì)比
Thanos 需要在不同的數(shù)據(jù)中心(或可用區(qū))運(yùn)行多個(gè) Query 組件,如果某個(gè)區(qū)域不可用,那么另一個(gè)區(qū)域的 Query 組件將會(huì)繼續(xù)負(fù)責(zé)響應(yīng)查詢。當(dāng)然,這種情況下基本上只能返回部分查詢結(jié)果,因?yàn)椴糠?Sidecar 或 Store Gateway 組件很有可能就位于不可用區(qū)。
VictoriaMetrics 可以在不同的數(shù)據(jù)中心(或可用區(qū))運(yùn)行多個(gè)集群,同時(shí)可以配置 Prometheus 將數(shù)據(jù)復(fù)制到所有集群,具體可以參考官方文檔的示例[34]。如果某個(gè)區(qū)域不可用,那么另一個(gè)區(qū)域的 VictoriaMetrics 仍然繼續(xù)接收新數(shù)據(jù),并能返回所有的查詢結(jié)果。
5. 托管成本對(duì)比
Thanos 選擇將數(shù)據(jù)存放到對(duì)象存儲(chǔ)中,最常用的 GCS 和 S3 的每月計(jì)費(fèi)情況如下:
GCS : 價(jià)格區(qū)間位于 $4/TB的 coldline storage 和$36/TB的標(biāo)準(zhǔn)存儲(chǔ)之間。此外,對(duì)于出口網(wǎng)絡(luò):內(nèi)部流量$10/TB,外部流量$80-$230/TB。對(duì)于存儲(chǔ) API 的調(diào)用(讀寫):每百萬次調(diào)用 10。具體參考價(jià)格詳情[35]。S3 : 價(jià)格區(qū)間位于 $4/TB的 glacier storage 和$23/TB的標(biāo)準(zhǔn)存儲(chǔ)之間。此外,對(duì)于出口網(wǎng)絡(luò):內(nèi)部流量$2-$10/TB,外部流量$50-$90/TB。對(duì)于存儲(chǔ) API 的調(diào)用(讀寫):每百萬次調(diào)用 100。具體參考價(jià)格詳情[36]。
總體看下來,Thanos 的托管成本不僅取決于數(shù)據(jù)大小,還取決于出口流量和 API 調(diào)用的數(shù)量。
VictoriaMetrics 只需要將數(shù)據(jù)存放到塊存儲(chǔ),最常用的 GCE 和 EBS 的每月計(jì)費(fèi)情況如下:
GCE 磁盤 : 價(jià)格區(qū)間位于 $40/TB的 HDD 和$240/TB的 SSD。具體參考價(jià)格詳情[37]。EBS : 價(jià)格區(qū)間位于 $45/TB的 HDD 和$125/TB的 SSD。具體參考價(jià)格詳情[38]。
VictoriaMetrics 針對(duì) HDD 做了優(yōu)化,所以基本上沒必要使用昂貴的 SSD。VictoriaMetrics 采用高性能的數(shù)據(jù)壓縮方式,使存入存儲(chǔ)的數(shù)據(jù)量比 Thanos 多達(dá) 10x,詳情參考這篇文章[39]。這就意味著與 Thanos 相比,VictoriaMetrics 需要更少的磁盤空間,存儲(chǔ)相同容量數(shù)據(jù)的成本更低。
總結(jié)
Thanos 和 VictoriaMetrics 分別使用了不同的方法來提供長期存儲(chǔ)、聚合查詢和水平擴(kuò)展性。
VictoriaMetrics 通過標(biāo)準(zhǔn)的 remote_write API[40] 接收來自 Prometheus 實(shí)例寫入的數(shù)據(jù),然后將其持久化(如 GCE HDD 磁盤[41]、Amazon EBS[42] 或其他磁盤)。而 Thanos 則需要禁用每個(gè) Prometheus 實(shí)例的本地?cái)?shù)據(jù)壓縮,并使用非標(biāo)準(zhǔn)的 Sidecar將數(shù)據(jù)上傳至S3或GCS。同時(shí)還需要設(shè)置Compactor,用于將對(duì)象存儲(chǔ) bucket 上的小數(shù)據(jù)塊合并成大數(shù)據(jù)塊。VictoriaMetrics 開箱即實(shí)現(xiàn)了全局查詢視圖的 Prometheus query API[43]。由于 Prometheus 會(huì)實(shí)時(shí)將抓取到的數(shù)據(jù)復(fù)制到遠(yuǎn)程存儲(chǔ),所以它不需要在集群外建立任何外部連接來實(shí)現(xiàn)全局查詢。Thanos 需要設(shè)置 Store Gateway、SIdecar和Query組件才能實(shí)現(xiàn)全局查詢。對(duì)于大型的 Thanos 集群來說,在Query組件和位于不同數(shù)據(jù)中心(可用區(qū)域)的Sidecar之間提供可靠安全的連接是相當(dāng)困難的。Query組件的性能會(huì)受到性能最差的Sidecar或Store Gateway的影響。VictoriaMetrics 集群可以快速部署到 Kubernetes 中,因?yàn)樗?span style="font-weight: bold;color: #eb6161;">架構(gòu)非常簡單[44]。而 Thanos 在 Kubernetes 中的部署和配置非常復(fù)雜。
本文由 VictoriaMetrics 核心開發(fā)者所著,所以可能會(huì)更傾向于 VictoriaMetrics,但作者盡量做到了公平對(duì)比。如果你有任何疑問,歡迎找原作者交流(si bi)。
原文鏈接:https://medium.com/faun/comparing-thanos-to-victoriametrics-cluster-b193bea1683
參考資料
Thanos: https://github.com/improbable-eng/thanos
[2]VictoriaMetrics: https://github.com/VictoriaMetrics/VictoriaMetrics
[3]集群版本: https://github.com/VictoriaMetrics/VictoriaMetrics/tree/cluster
[4]Thanos: https://github.com/improbable-eng/thanos
[5]Sidecar : https://thanos.io/tip/components/sidecar/
[6]Store: https://thanos.io/tip/components/store/
[7]Query: https://thanos.io/tip/components/query/
[8]Prometheus 的查詢 API: https://prometheus.io/docs/prometheus/latest/querying/api/
[9]Compact: https://thanos.io/tip/components/compact/
[10]Ruler: https://thanos.io/tip/components/rule/
[11]記錄規(guī)則: https://prometheus.io/docs/prometheus/latest/configuration/recording_rules/
[12]Ruler 組件通常故障率較高: https://thanos.io/tip/components/rule/#risk
Receiver: https://thanos.io/proposals/201812_thanos-remote-receive/
[14]remote write API: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_write
[15]helm: https://github.com/VictoriaMetrics/VictoriaMetrics/blob/cluster/README.md#helm
[16]垂直擴(kuò)展基準(zhǔn): https://medium.com/@valyala/measuring-vertical-scalability-for-time-series-databases-in-google-cloud-92550d78d8ae
[17]這個(gè) issue: https://github.com/improbable-eng/thanos/issues/206
[18]Compact: https://thanos.io/tip/components/compact/
[19]遠(yuǎn)程存儲(chǔ)的配置: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_write
[20]官方文檔: https://github.com/VictoriaMetrics/VictoriaMetrics/blob/master/README.md#prometheus-setup
[21]Read-Write coordination free operational contract for object storage: https://thanos.io/tip/proposals/201901-read-write-operations-bucket/
[22]存儲(chǔ)架構(gòu): https://medium.com/@valyala/how-victoriametrics-makes-instant-snapshots-for-multi-terabyte-time-series-data-e1f3fb0e0282
[23]Measuring vertical scalability for time series databases in Google Cloud: https://medium.com/@valyala/measuring-vertical-scalability-for-time-series-databases-in-google-cloud-92550d78d8ae
[24]Sidecar : https://thanos.io/tip/components/sidecar/
[25]Store: https://thanos.io/tip/components/store/
[26]Query: https://thanos.io/tip/components/query/
[27]Prometheues 的查詢 API: https://prometheus.io/docs/prometheus/latest/querying/api/
[28]Prometheues 查詢 API: https://prometheus.io/docs/prometheus/latest/querying/api/
[29]將 Grafana 中的數(shù)據(jù)源指向 VictoriaMetrics: https://github.com/VictoriaMetrics/VictoriaMetrics/blob/master/README.md#grafana-setup
這個(gè) issue: https://github.com/improbable-eng/thanos/issues/814
[31]默認(rèn)情況下: https://github.com/improbable-eng/thanos/blob/37f89adfd678c0e263a136da34aafe213e88bc24/cmd/thanos/query.go#L93
[32]只返回部分查詢結(jié)果: https://thanos.io/tip/components/query/#partial-response
[33]VictoriaMetrics 針對(duì)查詢速度做了優(yōu)化: https://medium.com/@valyala/measuring-vertical-scalability-for-time-series-databases-in-google-cloud-92550d78d8ae
[34]官方文檔的示例: https://github.com/VictoriaMetrics/VictoriaMetrics/blob/master/README.md#high-availability
[35]價(jià)格詳情: https://cloud.google.com/storage/pricing
[36]價(jià)格詳情: https://aws.amazon.com/s3/pricing/
[37]價(jià)格詳情: https://cloud.google.com/compute/pricing#persistentdisk
[38]價(jià)格詳情: https://aws.amazon.com/ebs/pricing/
[39]這篇文章: https://medium.com/faun/victoriametrics-achieving-better-compression-for-time-series-data-than-gorilla-317bc1f95932
[40]remote_write API: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_write
[41]GCE HDD 磁盤: https://cloud.google.com/compute/docs/disks/#pdspecs
[42]Amazon EBS: https://aws.amazon.com/ebs/
[43]Prometheus query API: https://prometheus.io/docs/prometheus/latest/querying/api/
[44]架構(gòu)非常簡單: https://github.com/VictoriaMetrics/VictoriaMetrics/blob/cluster/README.md#architecture-overview


你可能還喜歡
點(diǎn)擊下方圖片即可閱讀


云原生是一種信仰??

掃碼關(guān)注公眾號(hào)
后臺(tái)回復(fù)?k8s?獲取史上最方便快捷的 Kubernetes 高可用部署工具,只需一條命令,連 ssh 都不需要!


點(diǎn)擊?"閱讀原文"?獲取更好的閱讀體驗(yàn)!
??給個(gè)「在看」,是對(duì)我最大的支持??