
在表格數(shù)據(jù)上,為什么基于樹的模型仍然優(yōu)于深度學習?
轉(zhuǎn)載自公眾號:機器之心
機器之心報道


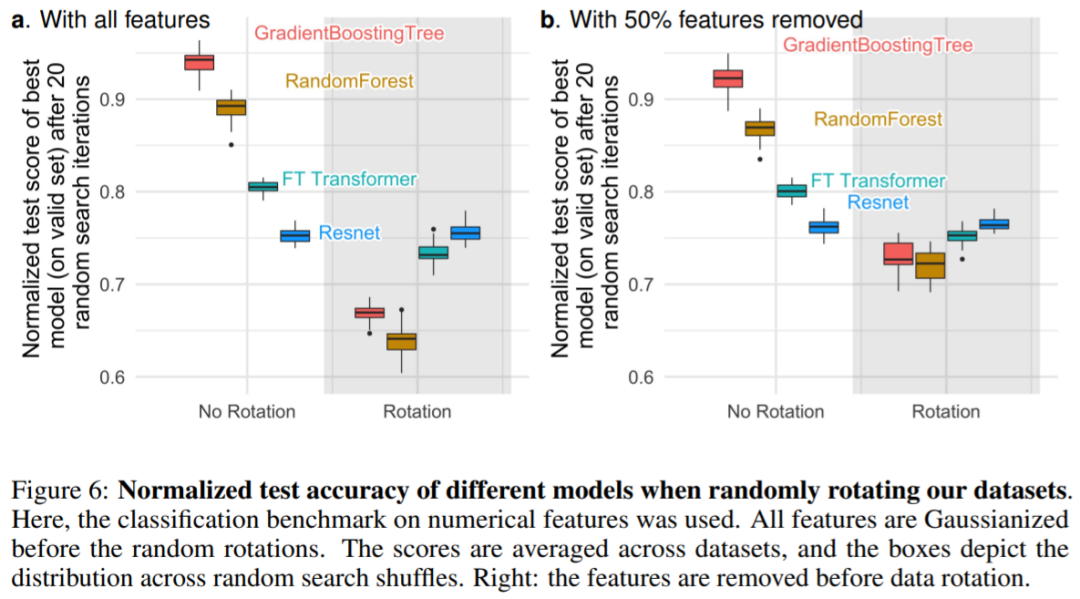
異構(gòu)列,列應該對應不同性質(zhì)的特征,從而排除圖像或信號數(shù)據(jù)集。 維度低,數(shù)據(jù)集 d/n 比率低于 1/10。 無效數(shù)據(jù)集,刪除可用信息很少的數(shù)據(jù)集。 I.I.D.(獨立同分布)數(shù)據(jù),移除類似流的數(shù)據(jù)集或時間序列。 真實世界數(shù)據(jù),刪除人工數(shù)據(jù)集,但保留一些模擬數(shù)據(jù)集。 數(shù)據(jù)集不能太小,刪除特征太少(< 4)和樣本太少(< 3 000)的數(shù)據(jù)集。 刪除過于簡單的數(shù)據(jù)集。 刪除撲克和國際象棋等游戲的數(shù)據(jù)集,因為這些數(shù)據(jù)集目標都是確定性的。

評論
圖片
表情