
計算機視覺面試復(fù)習(xí)筆記(三):深度學(xué)習(xí)基礎(chǔ)面試常見問題總結(jié)

極市導(dǎo)讀
?本文介紹深度學(xué)習(xí)基礎(chǔ)面經(jīng)知識點的第三部分深度神經(jīng)網(wǎng)絡(luò)面臨的挑戰(zhàn)。?>>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿
三、 深度學(xué)習(xí)基礎(chǔ)面試常見問題總結(jié)
1. 為什么需要做特征歸一化、標(biāo)準(zhǔn)化?
使不同量綱的特征處于同一數(shù)值量級,減少方差大的特征的影響,使模型更準(zhǔn)確。
加快學(xué)習(xí)算法的收斂速度。
2. 常用的歸一化和標(biāo)準(zhǔn)化的方法有哪些?
線性歸一化(min-max標(biāo)準(zhǔn)化)
x’ = (x-min(x)) / (max(x)-min(x)),其中max是樣本數(shù)據(jù)的最大值,min是樣本數(shù)據(jù)的最小值
適用于數(shù)值比較集中的情況,可使用經(jīng)驗值常量來來代替max,min
標(biāo)準(zhǔn)差歸一化(z-score 0均值標(biāo)準(zhǔn)化)
x’=(x-μ) / σ,其中μ為所有樣本的均值,σ為所有樣本的標(biāo)準(zhǔn)差
經(jīng)過處理后符合標(biāo)準(zhǔn)正態(tài)分布,即均值為0,標(biāo)準(zhǔn)差為1
非線性歸一化
使用非線性函數(shù)log、指數(shù)、正切等,如y = 1-e^(-x),在x∈[0, 6]變化較明顯, 用在數(shù)據(jù)分化比較大的場景
3. 介紹一下空洞卷積的原理和作用
空洞卷積也叫做膨脹卷積、擴張卷積,最初的提出是為了解決圖像分割在用下采樣(池化、卷積)增加感受野時帶來的特征圖縮小,后再上采樣回去時造成的精度上的損失。空洞卷積通過引入了一個擴張率的超參數(shù),該參數(shù)定義了卷積核處理數(shù)據(jù)時各值的間距。
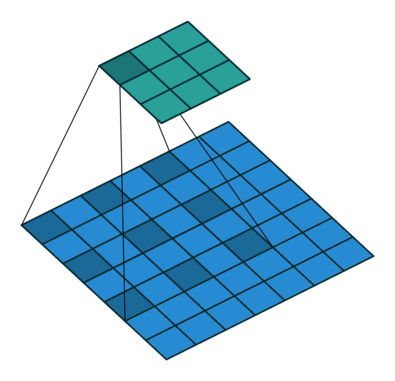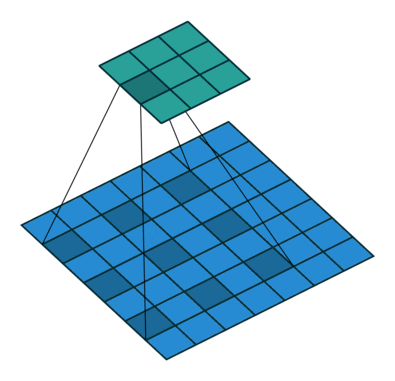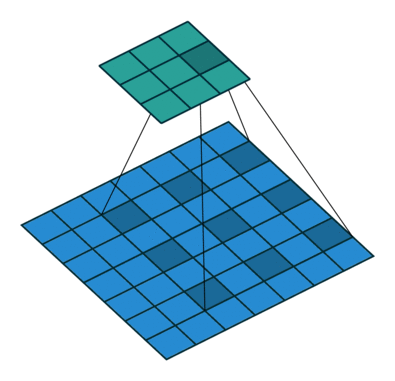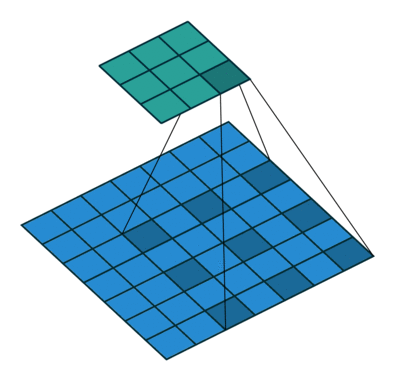
以在增加感受野的同時保持特征圖的尺寸不變,從而代替下采樣和上采樣,通過調(diào)整擴張率得到不同的感受野不大小:
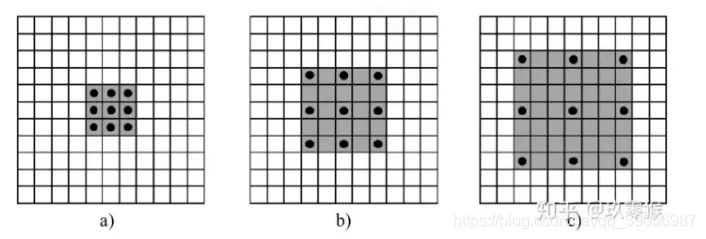
a是普通的卷積過程(dilation rate = 1),卷積后的感受野為3
b是dilation rate = 2的空洞卷積,卷積后的感受野為5
c是dilation rate = 3的空洞卷積,卷積后的感受野為8可以這么說,普通卷積是空洞卷積的一種特殊情況
4. 為什么線性回歸使用mse作為損失函數(shù)?
在使用線性回歸的時候的基本假設(shè)是噪聲服從正態(tài)分布,當(dāng)噪聲符合正態(tài)分布N(0,delta2)時,因變量則符合正態(tài)分布N(ax(i)+b,delta2),其中預(yù)測函數(shù)y=ax(i)+b。這個結(jié)論可以由正態(tài)分布的概率密度函數(shù)得到。也就是說當(dāng)噪聲符合正態(tài)分布時,其因變量必然也符合正態(tài)分布。因此,我們使用mse的時候?qū)嶋H上是假設(shè)y服從正態(tài)分布的。
5. 怎么判斷模型是否過擬合,有哪些防止過擬合的策略?
在構(gòu)建模型的過程中,通常會劃分訓(xùn)練集、測試集。
當(dāng)模型在訓(xùn)練集上精度很高,在測試集上精度很差時,模型過擬合;當(dāng)模型在訓(xùn)練集和測試集上精度都很差時,模型欠擬合。
預(yù)防過擬合策略:
(1)增加訓(xùn)練數(shù)據(jù):獲取更多數(shù)據(jù),也可以使用圖像增強、增樣等;
(2)使用合適的模型:適當(dāng)減少網(wǎng)絡(luò)的層數(shù)、降低網(wǎng)絡(luò)參數(shù)量;
(3)Dropout:隨機抑制網(wǎng)絡(luò)中一部分神經(jīng)元,使的每次訓(xùn)練都有一批神經(jīng)元不參與模型訓(xùn)練;
(4)L1、L2正則化:訓(xùn)練時限制權(quán)值的大小,增加懲罰機制,使得網(wǎng)絡(luò)更稀疏;
(5)數(shù)據(jù)清洗:去除問題數(shù)據(jù)、錯誤標(biāo)簽和噪聲數(shù)據(jù);
(6)限制網(wǎng)絡(luò)訓(xùn)練時間:在訓(xùn)練時將訓(xùn)練集和驗證集損失分別輸出,當(dāng)訓(xùn)練集損失持續(xù)下降,而驗證集損失不再下降時,網(wǎng)絡(luò)就開始出現(xiàn)過擬合現(xiàn)象,此時就可以停止訓(xùn)練了;
(7)在網(wǎng)絡(luò)中使用BN層(Batch Normalization)也可以一定程度上防止過擬合(原理不介紹,感興趣的同學(xué)可以去了解)。
6. 除了SGD和Adam之外,你還知道哪些優(yōu)化算法?
主要有三大類:
基本梯度下降法,包括 GD,BGD,SGD;
動量優(yōu)化法,包括 Momentum,NAG 等;
自適應(yīng)學(xué)習(xí)率優(yōu)化法,包括 Adam,AdaGrad,RMSProp 等
7. 闡述一下感受野的概念
感受野指的是卷積神經(jīng)網(wǎng)絡(luò)每一層輸出的特征圖上每個像素點映射回輸入圖像上的區(qū)域的大小,神經(jīng)元感受野的范圍越大表示其接觸到的原始圖像范圍就越大,也就意味著它能學(xué)習(xí)更為全局,語義層次更高的特征信息,相反,范圍越小則表示其所包含的特征越趨向局部和細(xì)節(jié)。因此感受野的范圍可以用來大致判斷每一層的抽象層次,并且我們可以很明顯地知道網(wǎng)絡(luò)越深,神經(jīng)元的感受野越大。
卷積層的感受野大小與其之前層的卷積核尺寸和步長有關(guān),與padding無關(guān)。
計算公式為:Fj-1 = Kj + (Fj - 1)*Sj(最后一層特征圖的感受野大小是其計算卷積核大小)
8. 下采樣的作用是什么?通常有哪些方式?
下采樣層有兩個作用,一是減少計算量,防止過擬合;二是增大感受野,使得后面的卷積核能夠?qū)W到更加全局的信息。下采樣的方式主要有兩種:
采用stride為2的池化層,如Max-pooling和Average-pooling,目前通常使用Max-pooling,因為他計算簡單而且能夠更好的保留紋理特征;
采用stride為2的卷積層,下采樣的過程是一個信息損失的過程,而池化層是不可學(xué)習(xí)的,用stride為2的可學(xué)習(xí)卷積層來代替pooling可以得到更好的效果,當(dāng)然同時也增加了一定的計算量。
9. 上采樣的原理和常用方式
在卷積神經(jīng)網(wǎng)絡(luò)中,由于輸入圖像通過卷積神經(jīng)網(wǎng)絡(luò)(CNN)提取特征后,輸出的尺寸往往會變小,而有時我們需要將圖像恢復(fù)到原來的尺寸以便進(jìn)行進(jìn)一步的計算(如圖像的語義分割),這個使圖像由小分辨率映射到大分辨率的操作,叫做上采樣,它的實現(xiàn)一般有三種方式:
插值,一般使用的是雙線性插值,因為效果最好,雖然計算上比其他插值方式復(fù)雜,但是相對于卷積計算可以說不值一提,其他插值方式還有最近鄰插值、三線性插值等;
轉(zhuǎn)置卷積又或是說反卷積,通過對輸入feature map間隔填充0,再進(jìn)行標(biāo)準(zhǔn)的卷積計算,可以使得輸出feature map的尺寸比輸入更大;
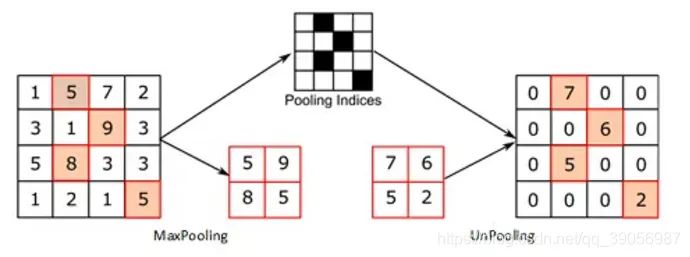
Max Unpooling,在對稱的max pooling位置記錄最大值的索引位置,然后在unpooling階段時將對應(yīng)的值放置到原先最大值位置,其余位置補0;
10. 模型的參數(shù)量指的是什么?怎么計算?
參數(shù)量指的是網(wǎng)絡(luò)中可學(xué)習(xí)變量的數(shù)量,包括卷積核的權(quán)重weights,批歸一化(BN)的縮放系數(shù)γ,偏移系數(shù)β,有些沒有BN的層可能有偏置bias,這些都是可學(xué)習(xí)的參數(shù),即在模型訓(xùn)練開始前被賦予初值,在訓(xùn)練過程根據(jù)鏈?zhǔn)椒▌t不斷迭代更新,整個模型的參數(shù)量主要是由卷積核的權(quán)重weights的數(shù)量決定,參數(shù)量越大,則該結(jié)構(gòu)對平臺運行的內(nèi)存要求越高。
參數(shù)量的計算方式:
Kh × Kw × Cin × Cout (Conv卷積網(wǎng)絡(luò))
Cin × Cout (FC全連接網(wǎng)絡(luò))
11. 模型的FLOPs(計算量)指的是什么?怎么計算?
神經(jīng)網(wǎng)絡(luò)的前向推理過程基本上都是乘累加計算,所以它的計算量也是指的前向推理過程中乘加運算的次數(shù),通常用FLOPs來表示,即floating point operations(浮點運算數(shù))。計算量越大,在同一平臺上模型運行延時越長,尤其是在移動端/嵌入式這種資源受限的平臺上想要達(dá)到實時性的要求就必須要求模型的計算量盡可能地低,但這個不是嚴(yán)格成正比關(guān)系,也跟具體算子的計算密集程度(即計算時間與IO時間占比)和該算子底層優(yōu)化的程度有關(guān)。
FLOPs的計算方式:
Kh × Kw × Cin × Cout × H × W = params × H × W (Conv卷積網(wǎng)絡(luò))
Cin x Cout (FC全連接網(wǎng)絡(luò))
計算量 = 輸出的feature map * 當(dāng)前層filter 即(H × W × Cout) × (K × K × Cin)
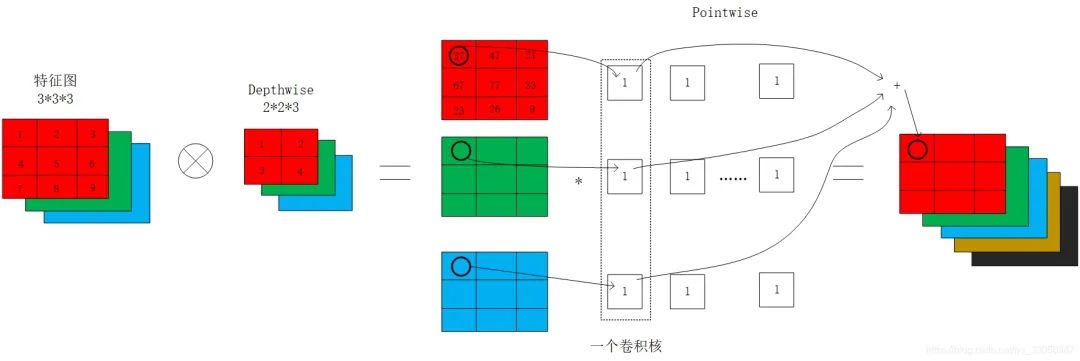
12. 深度可分離卷積的概念和作用
深度可分離卷積將傳統(tǒng)的卷積分兩步進(jìn)行,分別是depthwise和pointwise。首先按照通道進(jìn)行計算按位相乘的計算,深度可分離卷積中的卷積核都是單通道的,輸出不能改變feature map的通道數(shù),此時通道數(shù)不變;然后依然得到將第一步的結(jié)果,使用1*1的卷積核進(jìn)行傳統(tǒng)的卷積運算,此時通道數(shù)可以進(jìn)行改變。
Focus模塊,將W、H信息集中到通道空間,輸入通道擴充了4倍,作用是可以使信息不丟失的情況下提高計算力。具體操作為把一張圖片每隔一個像素拿到一個值,類似于鄰近下采樣,這樣我們就拿到了4張圖,4張圖片互補,長的差不多,但信息沒有丟失,拼接起來相當(dāng)于RGB模式下變?yōu)?2個通道,通道多少對計算量影響不大,但圖像縮小,大大減少了計算量。
計算量的前后對比:
Kh × Kw × Cin × Cout × H × W
變成了 Kh × Kw × Cin × H × W + 1 × 1 × Cin × Cout × H × W
通過深度可分離卷積,當(dāng)卷積核大小為3時,深度可分離卷積比傳統(tǒng)卷積少8到9倍的計算量。
13. 轉(zhuǎn)置卷積的原理
轉(zhuǎn)置卷積又稱反卷積(Deconvolution),它和空洞卷積的思路正好相反,是為上采樣而生,也應(yīng)用于語義分割當(dāng)中,而且他的計算也和空洞卷積正好相反,先對輸入的feature map間隔補0,卷積核不變,然后使用標(biāo)準(zhǔn)的卷積進(jìn)行計算,得到更大尺寸的feature map。
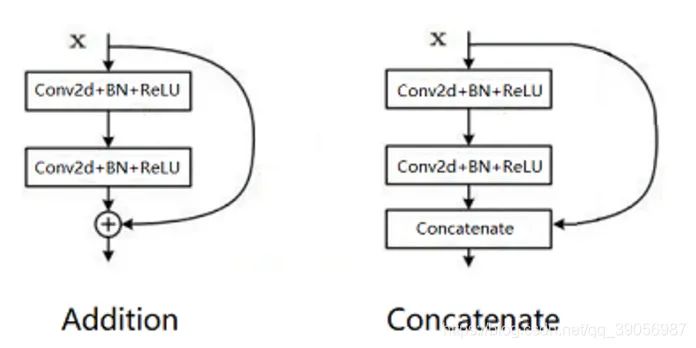
14. 神經(jīng)網(wǎng)絡(luò)中Addition / Concatenate區(qū)別是什么?
Addition和Concatenate分支操作統(tǒng)稱為shortcut,Addition是在ResNet中提出,兩個相同維度的feature map相同位置點的值直接相加,得到新的相同維度feature map,這個操作可以融合之前的特征,增加信息的表達(dá),Concatenate操作是在Inception中首次使用,被DenseNet發(fā)揚光大,和addition不同的是,它只要求兩個feature map的HW相同,通道數(shù)可以不同,然后兩個feature map在通道上直接拼接,得到一個更大的feature map,它保留了一些原始的特征,增加了特征的數(shù)量,使得有效的信息流繼續(xù)向后傳遞。
15. 你知道哪些常用的激活函數(shù)?
ReLu系列:ReLU、ReLU6和leaky ReLU;ReLU6與ReLU相比也只是在正向部分多了個閾值,大于6的值等于6,而leaky ReLU和ReLU正向部分一樣,都是大于0等于原始值,但負(fù)向部分卻是等于原始值的1/10,浮點運算的話乘個0.1就好了。
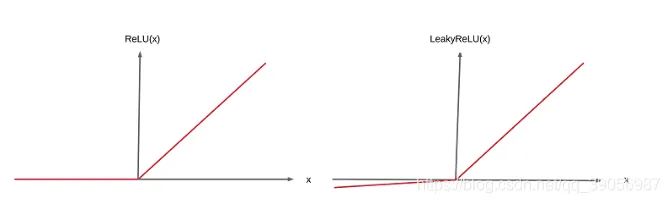
ReLU函數(shù)的優(yōu)點:
解決了梯度消失的問題;
計算速度和收斂速度非常快;
ReLU函數(shù)的缺點:
低維特征向高維轉(zhuǎn)換時會部分丟失;
均值為非零;
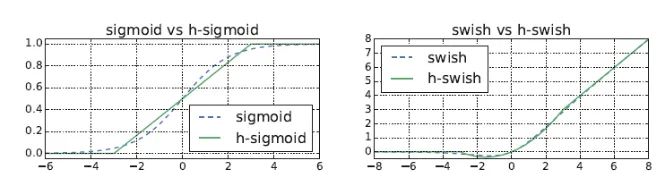
Sigmoid系列: Sigmoid、swish、h-sigmoid、h-swish;sigmoid對低性能的硬件來說非常不友好,因為涉及到大量的exp指數(shù)運算和除法運算,于是有研究人員針對此專門設(shè)計了近似的硬件友好的函數(shù)h-sigmoid和h-swish函數(shù),這里的h指的就是hardware的意思:
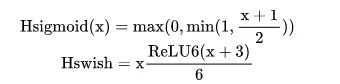
Sigmoid函數(shù)的優(yōu)點:
輸出為 0 到 1 之間的連續(xù)實值,此輸出范圍和概率范圍一致,因此可以用概率的方式解釋輸出;
將線性函數(shù)轉(zhuǎn)變?yōu)榉蔷€性函數(shù);
Sigmoid函數(shù)的缺點:
冪運算相對來講比較耗時;
輸出均值為非 0;容易出現(xiàn)梯度消失的問題;
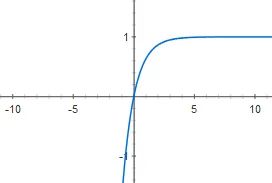
tanh
tanh函數(shù)的優(yōu)點:
Tanh 函數(shù)的導(dǎo)數(shù)比 Sigmoid 函數(shù)導(dǎo)數(shù)值更大、梯度變化更快,在訓(xùn)練過程中收斂速度更快;使得輸出均值為 0,可以提高訓(xùn)練的效率;將線性函數(shù)轉(zhuǎn)變?yōu)榉蔷€性函數(shù);
tanh函數(shù)的缺點:冪運算相對來講比較耗時;容易出現(xiàn)梯度消失;
16. 神經(jīng)網(wǎng)絡(luò)中1*1卷積有什么作用?
降維,減少計算量;在ResNet模塊中,先通過11卷積對通道數(shù)進(jìn)行降通道,再送入33的卷積中,能夠有效的減少神經(jīng)網(wǎng)絡(luò)的參數(shù)量和計算量;
升維;用最少的參數(shù)拓寬網(wǎng)絡(luò)通道,通常在輕量級的網(wǎng)絡(luò)中會用到,經(jīng)過深度可分離卷積后,使用1*1卷積核增加通道的數(shù)量,例如mobilenet、shufflenet等;
實現(xiàn)跨通道的交互和信息整合;增強通道層面上特征融合的信息,在feature map尺度不變的情況下,實現(xiàn)通道升維、降維操作其實就是通道間信息的線性組合變化,也就是通道的信息交互整合的過程;
1*1卷積核可以在保持feature map尺度(不損失分辨率)不變的情況下,大幅增加非線性特性(利用后接的非線性激活函數(shù))。卷積神經(jīng)網(wǎng)絡(luò)中用1*1 卷積有什么作用或者好處呢?
17. BN(Batch Normalization)的原理和作用是什么?
將一個batch的數(shù)據(jù)變換到均值為0、方差為1的正態(tài)分布上,從而使數(shù)據(jù)分布一致,每層的梯度不會隨著網(wǎng)絡(luò)結(jié)構(gòu)的加深發(fā)生太大變化,從而避免發(fā)生梯度消失或者梯度爆炸,能夠加快模型收斂,同時還有防止過擬合的效果。
實現(xiàn)過程
計算訓(xùn)練階段mini_batch數(shù)量激活函數(shù)前結(jié)果的均值和方差,然后對其進(jìn)行歸一化,最后對其進(jìn)行縮放和平移。
作用
限制參數(shù)對隱層數(shù)據(jù)分布的影響,使其始終保持均值為0,方差為1的分布;
削弱了前層參數(shù)和后層參數(shù)之間的聯(lián)系,使得當(dāng)前層稍稍獨立于其他層,加快收斂速度;有輕微的正則化效果。
18. 隨機梯度下降相比全局梯度下降好處是什么?
當(dāng)處理大量數(shù)據(jù)時,比如SSD或者faster-rcnn等目標(biāo)檢測算法,每個樣本都有大量候選框參與訓(xùn)練,這時使用隨機梯度下降法能夠加快梯度的計算;
每次只隨機選取一個樣本來更新模型參數(shù),因此每次的學(xué)習(xí)是非常快速的,并且可以進(jìn)行在線更新。
22. 如果在網(wǎng)絡(luò)初始化時給網(wǎng)絡(luò)賦予0的權(quán)重,這個網(wǎng)絡(luò)能正常訓(xùn)練嘛?
不能,因為初始化權(quán)重是0,每次傳入的不同數(shù)據(jù)得到的結(jié)果是相同的。網(wǎng)絡(luò)無法更新
19. 無監(jiān)督學(xué)習(xí)方法有哪些?
強化學(xué)習(xí)、K-means 聚類、自編碼、受限波爾茲曼機
20. 增大感受野的方法?
空洞卷積、池化操作、較大卷積核尺寸的卷積操作
21. 神經(jīng)網(wǎng)絡(luò)的正則化方法?/過擬合的解決方法?
數(shù)據(jù)增強(鏡像對稱、隨機裁剪、旋轉(zhuǎn)圖像、剪切圖像、局部彎曲圖像、色彩轉(zhuǎn)換)
early stopping(比較訓(xùn)練損失和驗證損失曲線,驗證損失最小即為最優(yōu)迭代次數(shù))
L2正則化(權(quán)重參數(shù)的平方和)
L1正則化(權(quán)重參數(shù)的絕對值之和)
dropout 正則化(設(shè)置keep_pro參數(shù)隨機讓當(dāng)前層神經(jīng)元失活)
22. 梯度消失和梯度爆炸的原因是什么?
原因:激活函數(shù)的選擇。
梯度消失:令bias=0,則神經(jīng)網(wǎng)絡(luò)的輸出結(jié)果等于各層權(quán)重參數(shù)的積再與輸入數(shù)據(jù)集相乘,若參數(shù)值較小時,則權(quán)重參數(shù)呈指數(shù)級減小。
梯度爆炸:令bias=0,則神經(jīng)網(wǎng)絡(luò)的輸出結(jié)果等于各層權(quán)重參數(shù)的積再與輸入數(shù)據(jù)集相乘,若參數(shù)值較大時,則權(quán)重參數(shù)呈指數(shù)級增長。
23. 深度學(xué)習(xí)為什么在計算機視覺領(lǐng)域這么好?
以目標(biāo)檢測為例,傳統(tǒng)的計算機視覺方法需首先基于經(jīng)驗手動設(shè)計特征,然后使用分類器分類,這兩個過程都是分開的。而深度學(xué)習(xí)里的卷積網(wǎng)絡(luò)可實現(xiàn)對局部區(qū)域信息的提取,獲得更高級的特征,當(dāng)神經(jīng)網(wǎng)絡(luò)層數(shù)越多時,提取的特征會更抽象,將更有助于分類,同時神經(jīng)網(wǎng)路將提取特征和分類融合在一個結(jié)構(gòu)中。
24. 為什么神經(jīng)網(wǎng)絡(luò)種常用relu作為激活函數(shù)?
在前向傳播和反向傳播過程中,ReLU相比于Sigmoid等激活函數(shù)計算量小;
在反向傳播過程中,Sigmoid函數(shù)存在飽和區(qū),若激活值進(jìn)入飽和區(qū),則其梯度更新值非常小,導(dǎo)致出現(xiàn)梯度消失的現(xiàn)象。而ReLU沒有飽和區(qū),可避免此問題;
ReLU可令部分神經(jīng)元輸出為0,造成網(wǎng)絡(luò)的稀疏性,減少前后層參數(shù)對當(dāng)前層參數(shù)的影響,提升了模型的泛化性能;
25. 卷積層和全連接層的區(qū)別是什么?
卷積層是局部連接,所以提取的是局部信息;全連接層是全局連接,所以提取的是全局信息;
當(dāng)卷積層的局部連接是全局連接時,全連接層是卷積層的特例;
26. 什么是正則化?L1正則化和L2正則化有什么區(qū)別?
所謂的正則化,就是在原來 Loss Function 的基礎(chǔ)上,加了一些正則化項,或者叫做模型復(fù)雜度懲罰項,正則化機器學(xué)習(xí)中一種常用的技術(shù),其主要目的是控制模型復(fù)雜度,減小過擬合。
兩者的區(qū)別:
L1范式:它的優(yōu)良性質(zhì)是能產(chǎn)生稀疏性,導(dǎo)致 W 中許多項變成零。稀疏的解除了計算量上的好處之外,更重要的是更具有“可解釋性”。
L2范式:使得模型的解偏向于范數(shù)較小的 W,通過限制 W 范數(shù)的大小實現(xiàn)了對模型空間的限制,從而在一定程度上避免了過擬合。不過 嶺回歸并不具有產(chǎn)生稀疏解的能力,得到的系數(shù)仍然需要數(shù)據(jù)中的所有特征才能計算預(yù)測結(jié)果,從計算量上來說并沒有得到改觀。
27. 常用的模型壓縮方式有哪些?
使用輕量型的特征提取網(wǎng)絡(luò),例如:mobileNet、shuffleNet、GhostNet系列等等;通道、層剪枝;模型蒸餾;模型量化。
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“CVPR21檢測”獲取CVPR2021目標(biāo)檢測論文下載~

#?CV技術(shù)社群邀請函?#

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳)
即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與?10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
