
一個接口超時問題,排查兩天 從應用排查到內(nèi)核....
點擊上方[全棧開發(fā)者社區(qū)]→右上角[...]→[設為星標?
點擊領取全棧資料:全棧資料

問題描述
最近在查一個問題,花費了近兩個星期,問題算是有了一個小結(jié),是時候總結(jié)一下了。
排查過程走了很多彎路,由于眼界和知識儲備問題,也進入了一些思維誤區(qū),希望此問題能以后再查詢此類問題時能有所警示和參考。
而且很多排查方法和思路都來自于部門 leader 和 組里大神給的提示和啟發(fā),總結(jié)一下也能對這些知識有更深的理解。
這個問題出現(xiàn)在典型的高并發(fā)場景下,現(xiàn)象是某個接口會偶爾超時。
查了幾個 case 的日志,發(fā)現(xiàn) httpClient 在請求某三方接口結(jié)束后輸出一條日志時間為 A,方法返回后將請求結(jié)果解析成為 JSON 對象后,再輸出的日志時間為 B, AB之間的時間差會特別大,100-700ms 不等,而 JSON 解析正常是特別快的,不應該超過 1ms。
GC
首先考慮導致這種現(xiàn)象的可能:
應用上有鎖導致方法被 block 住了,但 JSON 解析方法上并不存在鎖,排除這種可能。
JVM 上,GC 可能導致 STW。
系統(tǒng)上,如果系統(tǒng)負載很高,操作系統(tǒng)繁忙,線程調(diào)度出現(xiàn)問題可能會導致這種情況,但觀察監(jiān)控系統(tǒng)發(fā)現(xiàn)系統(tǒng)負載一直處于很低的水平,也排除了系統(tǒng)問題。
我們都知道 JVM 在 GC 時會導致 STW,進而導致所有線程都會暫停,接下來重點排查 GC 問題。
首先我們使用 jstat 命令查看了 GC 狀態(tài),發(fā)現(xiàn) fullGC 并不頻繁,系統(tǒng)運行了兩天才有 100 來次,而 minorGC 也是幾秒才會進行一次,且 gcTime 一直在正常范圍。
由于我們的 JVM 在啟動時添加了 -XX:+PrintGCApplicationStoppedTime 參數(shù),而這個參數(shù)的名字跟它的意義并不是完全相對的,在啟用此參數(shù)時,gclog 不僅會打印出 GC 導致的 STW,其他原因?qū)е碌?STW 也會被記錄到 gclog 中,于是 gclog 就可以成為一個重要的排查工具。
查看 gclog 發(fā)現(xiàn)確實存在異常狀況,如下圖:
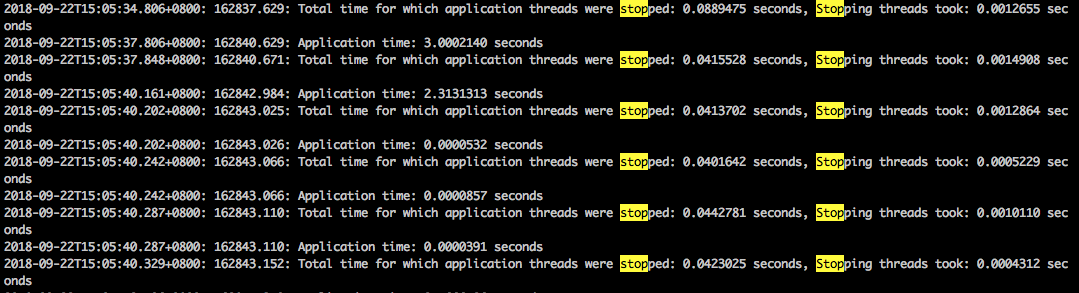
系統(tǒng) STW 有時會非常頻繁地發(fā)生,且持續(xù)時間也較長,其中間隔甚至不足 1ms。
也就是說一次停頓持續(xù)了幾十 ms 之后,系統(tǒng)還沒有開始運行,又會進行第二次 STW,如上圖的情況,系統(tǒng)應該會一次 hang 住 120ms,如果次數(shù)再頻繁一些,確實有可能會導致接口超時。
安全點
那么這么頻繁的 STW 是由什么產(chǎn)生的呢,minorGC 的頻率都沒有這么高。
我們知道,系統(tǒng)在 STW 前,會等待所有線程安全點,在安全點里,線程的狀態(tài)是確定的,其引用的 heap 也是靜止的,這樣,JVM 才能安心地進行 GC 等操作。
至于安全點的常見位置和安全點的實現(xiàn)方式網(wǎng)卡有很多文章介紹這里不再多提了,這里重點說一下安全點日志。
安全點日志是每次 JVM 在所有線程進入安全點 STW 后輸出的日志,日志記錄了進入安全點用了多久,STW 了多久,安全點內(nèi)的時間都是被哪個步驟消耗的,通過它我們可以分析出 JVM STW 的原因。
服務啟動時,使用?-XX:+UnlockDiagnosticVMOptions -XX:+PrintSafepointStatistics -XX:+LogVMOutput -XX:LogFile=./safepoint.log?參數(shù),可以將安全點日志輸出到 safepoint.log 中。
在安全點日志中,我發(fā)現(xiàn)有很多下圖類似的日志輸出:

從前面的 vmopt 列可以得知,進入安全點的原因是 RevokeBias, 查資料得知,這是在釋放 偏向鎖。
偏向鎖
偏向鎖是 JVM 對鎖的一種優(yōu)化,JVM 的開發(fā)人員統(tǒng)計發(fā)現(xiàn)絕大部分的鎖都是由同一個線程獲取,鎖爭搶的可能性很小,而系統(tǒng)調(diào)用一次加鎖釋放鎖的開銷相對很大,所以引入偏向鎖默認鎖不會被競爭,偏向鎖中的 “偏向” 便指向第一個獲取到鎖的線程。
在一個鎖在被第一次獲取后,JVM 并不需要用系統(tǒng)指令加鎖,而是使用偏向鎖來標志它,將對象頭中 MarkWord 的偏向鎖標識設置為1,將偏向線程設置為持續(xù)鎖的線程 ID,這樣,之后線程再次申請鎖時如果發(fā)現(xiàn)這個鎖已經(jīng) “偏向” 了當前線程,直接使用即可。
而且持有偏向鎖的線程不會主動釋放鎖,只有在出現(xiàn)鎖競爭時,偏向鎖才會釋放,進而膨脹為更高級別的鎖。
有利則有弊,偏向鎖在單線程環(huán)境內(nèi)確實能極大降低鎖消耗,但在多線程高并發(fā)環(huán)境下,線程競爭頻繁,而偏向鎖在釋放時,為了避免出現(xiàn)沖突,需要等到進入全局安全點才能進行,所以每次偏向鎖釋放會有更大的消耗。
明白了 JVM 為什么會頻繁進行 STW,再修改服務啟動參數(shù),添加?-XX:-UseBiasedLocking?參數(shù)禁用偏向鎖后,再觀察服務運行。
發(fā)現(xiàn)停頓問題的頻率下降了一半,但還是會出現(xiàn),問題又回到原點。
Log4j
定位
這時候就需要猜想排查了。
首先提出可能導致問題的點,再依次替換掉這些因素壓測,看能否復現(xiàn)來確定問題點。
考慮到的問題點有 HttpClient、Hystrix、Log4j2。
使用固定數(shù)據(jù)替換了三方接口的返回值,刪去了 Hystrix,甚至將邏輯代碼都刪掉,只要使用 Log4j2 輸出大量日志,問題就可以復現(xiàn),終于定位到了 Log4j2,原來是監(jiān)守自盜啊...
雖然定位到 Log4j2,但日志也不能不記啊,還是要查問題到底出在哪里。
使用 btrace 排查 log4j2 內(nèi)的鎖性能。
首先考慮 Log4j2 代碼里的鎖,懷疑是由于鎖沖突,導致輸出 log 時被 block 住了。
查看源碼,統(tǒng)計存在鎖的地方有三處:
rollover()方法,在檢測到日志文件需要切換時會鎖住進行日志文件的切分。encodeText()方法,日志輸出需要將各種字符集的日志都轉(zhuǎn)換為 byte 數(shù)組,在進行大日志輸出時,需要分塊進行。為了避免多線程塊之間的亂序,使用synchronized 關鍵字對方法加鎖。flush()方法,同樣是為了避免不同日志之間的穿插亂序,需要對此方法加鎖。
具體是哪一處代碼出現(xiàn)了問題呢,我使用 btrace 這一 Java 性能排查利器進行了排查。
使用 btrace 分別在這三個方法前后都注入代碼,將方法每次的執(zhí)行時間輸出,然后進行壓測,等待問題發(fā)生,最終找到了執(zhí)行慢的方法:encodeText()。
排查代碼并未發(fā)現(xiàn) encodeText 方法的異常(千錘百煉的代碼,當然看不出什么問題)。
使用 jmc 分析問題
這時,組內(nèi)大神建議我使用 jmc 來捕捉異常事件。給 docker-compose 添加以下參數(shù)來啟用環(huán)境的 JFR。
environment:??
???-?JFR=true??
???-?JMX_PORT=port??
???-?JMX_HOST=ip??
???-?JMX_LOGIN=user:pwd??
在記錄內(nèi)查找停頓時間附近的異常事件,發(fā)現(xiàn)耗時統(tǒng)計內(nèi)有一項長耗時引人注目:調(diào)用 RandomAccessFile.write() 方法竟然耗時 1063 ms,而這個時間段和線程 ID 則完全匹配。
查看這個耗時長的方法,它調(diào)用的是 native 方法 write()...
階段性小結(jié)
native 方法再查下去就是系統(tǒng)問題了,但是目前我們可以給出兩個對癥下藥的解決方案。
服務少記一些日志,日志太多的話才會導致這個問題。
使用 Log4j2 的異步日志,雖然有可能會在緩沖區(qū)滿或服務重啟時丟日志。
同時可以進行一個階段性的小結(jié)。
查問題的過程確實學習到了很多知識,讓我更熟悉了 Java 的生態(tài),但我覺得更重要的是排查問題的思路,于是我總結(jié)了一個排查問題的一般步驟,當作以后排查此類問題的 checkList。
盡量分析更多的問題 case。找出他們的共性,避免盯錯問題點。比如此次問題排查開始時,如果多看幾個 case 就會發(fā)現(xiàn),日志停頓在任何日志點都會出現(xiàn),由此就可以直接排除掉 HttpClient 和 Hystrix 的影響。
在可控的環(huán)境復現(xiàn)問題。在測試環(huán)境復現(xiàn)問題可能幫助我們隨時調(diào)整排查策略,極大地縮短排查周期。當然還需要注意的是一定要跟線上環(huán)境保持一致,不一致的環(huán)境很可能把你的思路帶歪,比如我在壓測復現(xiàn)問題時,由于堆內(nèi)存設置得太小,導致頻繁發(fā)生 GC,讓我錯認為是 GC 原因?qū)е碌耐nD。
對比變化,提出猜想。在服務出現(xiàn)問題時,我們總是先問最近上線了什么內(nèi)容,程序是有慣性的,如果沒有變化,系統(tǒng)一般會一直正常運行。當然變化不止是時間維度上的,我們還可以在多個服務之間對比差異。
排除法定位問題。一般我們會提出多個導致問題的可能性,排查時,保持一個變量在變化,再對比問題的發(fā)生,從而總結(jié)出變量對問題的影響。解決。當我們定位到問題之后,問題的解決一般都很簡單,可能只需要改一行代碼。
當然還有一個非常重要的點,貫穿始末,那就是數(shù)據(jù)支持,排查過程中一定要有數(shù)據(jù)作為支持。通過總量、百分比數(shù)據(jù)的前后對比來說服其他人相信你的理論,也就是用數(shù)據(jù)說話。
應用復現(xiàn)
Jdk 的 native 方法當然不是終點,雖然發(fā)現(xiàn) Jdk、docker、操作系統(tǒng) Bug 的可能性極小,但再往底層查卻很可能發(fā)現(xiàn)一些常見的配置錯誤。
為了便于復現(xiàn),我用 JMH 寫了一個簡單的 demo,控制速度不斷地通過 log4j2 寫入日志。將項目打包成 jar 包,就可以很方便地在各處運行了。
@BenchmarkMode(Mode.AverageTime)??
@OutputTimeUnit(TimeUnit.MICROSECONDS)??
@State(Scope.Benchmark)??
@Threads(5)??
public?class?LoggerRunner?{??
????public?static?void?main(String[]?args)?throws?RunnerException?{??
??
????????Options?options?=?new?OptionsBuilder()??
????????????????.include(LoggerRunner.class.getName())??
????????????????.warmupIterations(2)??
????????????????.forks(1)??
????????????????.measurementIterations(1000)??
????????????????.build();??
????????new?Runner(options).run();??
????}??
}??
我比較懷疑是 docker 的原因。
但是在 docker 內(nèi)外運行了 jar 包卻發(fā)現(xiàn)都能很簡單地復現(xiàn)日志停頓問題。而 jdk 版本眾多,我準備首先排查操作系統(tǒng)配置問題。
系統(tǒng)調(diào)用
這里需要使用到 strace 命令。
這個命令很早就使用過,但我還是不太習慣把 Java 和它聯(lián)系起來,幸好有部門的老司機指點,于是就使用 strace 分析了一波 Java 應用。
命令跟分析普通腳本一樣,strace -T -ttt -f -o strace.log java -jar log.jar, -T 選項可以將每一個系統(tǒng)調(diào)用的耗時打印到系統(tǒng)調(diào)用的結(jié)尾。
當然排查時使用 -p pid 附加到 tomcat 上也是可以的,雖然會有很多容易混淆的系統(tǒng)調(diào)用。
對比 jmh 壓測用例輸出的 log4j2.info() 方法耗時,發(fā)現(xiàn)了下圖中的狀況:

一次 write 系統(tǒng)調(diào)用竟然消耗了 147ms,很明顯地,問題出在 write 系統(tǒng)調(diào)用上。
文件系統(tǒng)
結(jié)構(gòu)
這時候就要好好回想一下操作系統(tǒng)的知識了。
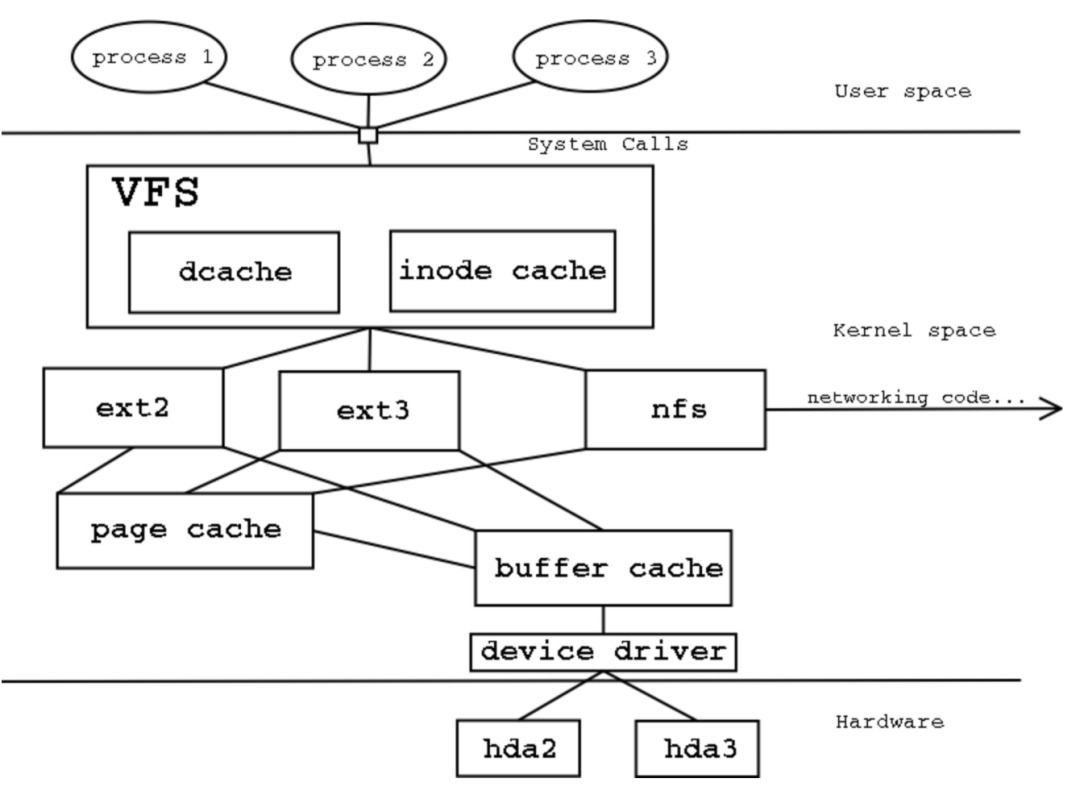
在 linux 系統(tǒng)中,萬物皆文件,而為了給不同的介質(zhì)提供一種抽象的接口,在應用層和系統(tǒng)層之間,抽象了一個虛擬文件系統(tǒng)層(virtual file system, VFS)。
上層的應用程序通過 系統(tǒng)調(diào)用 system call 操作虛擬文件系統(tǒng),進而反饋到下層的硬件層。
由于硬盤等介質(zhì)操作速度與內(nèi)存不在同一個數(shù)量級上,為了平衡兩者之間的速度,linux 便把文件映射到內(nèi)存中,將硬盤單位塊(block)對應到內(nèi)存中的一個 頁(page)上。
這樣,當需要操作文件時,直接操作內(nèi)存就可以了。
當緩沖區(qū)操作達到一定量或到達一定的時間后,再將變更統(tǒng)一刷到磁盤上。這樣便有效地減少了磁盤操作,應用也不必等待硬盤操作結(jié)束,響應速度得到了提升。
而 write 系統(tǒng)調(diào)用會將數(shù)據(jù)寫到內(nèi)存中的 page cache,將 page 標記為 臟頁(dirty) 后返回。
linux 的 writeback 機制
對于將內(nèi)存緩沖區(qū)的內(nèi)容刷到磁盤上,則有兩種方式:
首先,應用程序在調(diào)用 write 系統(tǒng)調(diào)用寫入數(shù)據(jù)時,如果發(fā)現(xiàn) page cache 的使用量大于了設定的大小,便會主動將內(nèi)存中的臟頁刷到硬盤上。在此期間,所有的 write 系統(tǒng)調(diào)用都會被阻塞。
系統(tǒng)當然不會容忍不定時的 write 阻塞,linux 還會定時啟動 pdflush 線程,判斷內(nèi)存頁達到一定的比例或臟頁存活時間達到設定的時間,將這些臟頁刷回到磁盤上,以避免被動刷緩沖區(qū),這種機制就是 linux 的 writeback 機制。
猜測
了解了以上基礎知識,那么對于 write 系統(tǒng)調(diào)用為什么會被阻塞,提出了兩種可能:
page cache 可用空間不足,導致觸發(fā)了主動的 flush,此時會阻塞所有對此 device 的 write。
寫入過程被其他事務阻塞。
首先對于第一種可能。查看系統(tǒng)配置 dirty_ratio 的大小:20。
此值是 page cache 占用系統(tǒng)可用內(nèi)存(real mem + swap)的最大百分比,我們的內(nèi)存為 32G,沒有啟用 swap,則實際可用的 page cache 大小約為 6G。
另外,與 pdflush 相關的系統(tǒng)配置:系統(tǒng)會每?vm.dirty_writeback_centisecs?(5s) 喚醒一次 pdflush 線程, 發(fā)現(xiàn)臟頁比例超過?vm.dirty_background_ratio?(10%) 或 臟頁存活時間超過?vm.dirty_expire_centisecs(30s) 時,會將臟頁刷回硬盤。
查看 /proc/meminfo 內(nèi) Dirty/Writeback 項的變化,并對比服務的文件寫入速度,結(jié)論是數(shù)據(jù)會被 pdflush 刷回到硬盤,不會觸發(fā)被動 flush 以阻塞 write 系統(tǒng)調(diào)用。
ext4 的 journal 特性
write 被阻塞的原因
繼續(xù)搜索資料,在一篇文章(Why buffered writes are sometimes stalled)中看到 write 系統(tǒng)調(diào)用被阻塞有以下可能:
http://yoshinorimatsunobu.blogspot.com/2014/03/why-buffered-writes-are-sometimes.html
要寫入的數(shù)據(jù)依賴讀取的結(jié)果時。但記錄日志不依賴讀文件;
wirte page 時有別的線程在調(diào)用 fsync() 等主動 flush 臟頁的方法。但由于鎖的存在,log 在寫入時不會有其他的線程操作;
格式為 ext3/4 的文件系統(tǒng)在記錄 journal log 時會阻塞 write。而我們的系統(tǒng)文件格式為 ext4。
journal
journal 是 文件系統(tǒng)保證數(shù)據(jù)一致性的一種手段,在寫入數(shù)據(jù)前,將即將進行的各個操作步驟記錄下來,一旦系統(tǒng)掉電,恢復時讀取這些日志繼續(xù)操作就可以了。
但批量的 journal commit 是一個事務,flush 時會阻塞 write 的提交。
我們可以使用?dumpe2fs /dev/disk | grep features?查看磁盤支持的特性,其中有 has_journal 代表文件系統(tǒng)支持 journal 特性。
ext4 格式的文件系統(tǒng)在掛載時可以選擇 (jouranling、ordered、writeback) 三種之一的 journal 記錄模式。
三種模式分別有以下特性:
journal:在將數(shù)據(jù)寫入文件系統(tǒng)前,必須等待 metadata 和 journal 已經(jīng)落盤了。
ordered:不記錄數(shù)據(jù)的 journal,只記錄 metadata 的 journal 日志,且需要保證所有數(shù)據(jù)在其 metadata journal 被 commit 之前落盤。ext4 在不添加掛載參數(shù)時使用此模式。
writeback: 數(shù)據(jù)可能在 metadata journal 被提交之后落盤,可能導致舊數(shù)據(jù)在系統(tǒng)掉電后恢復到磁盤中。
當然,我們也可以選擇直接禁用 journal,使用?tune2fs -O ^has_journal /dev/disk,只能操作未被掛載的磁盤。
猜測因為 journal 觸發(fā)了臟頁落盤,而臟頁落盤導致 write 被阻塞,所以解決 journal 問題就可以解決接口超時問題。
解決方案與壓測結(jié)果
以下是我總結(jié)的幾個接口超時問題的解決方案:
log4j2 日志模式改異步。但有可能會在系統(tǒng)重啟時丟失日志,另外在異步隊列 ringbuffer 被填滿未消費后,新日志會自動使用同步模式。
調(diào)整系統(tǒng)刷臟頁的配置,將檢查臟頁和臟頁過期時間設置得更短(1s 以內(nèi))。但理論上會略微提升系統(tǒng)負載(未明顯觀察到)。
掛載硬盤時使用
data=writeback選項修改 journal 模式。但可能導致系統(tǒng)重啟后文件包含已刪除的內(nèi)容。禁用 ext4 的 journal 特性。但可能會導致系統(tǒng)文件的不一致。
把 ext4 的 journal 日志遷移到更快的磁盤上,如 ssd、閃存等。操作復雜,不易維護。
使用 xfs、fat 等文件系統(tǒng)格式。特性不了解,影響不可知。
當然,對于這幾種方案,我也做了壓測,以下是壓測的結(jié)果:

所以,程序員還是要懂些操作系統(tǒng)知識的,不僅幫我們在應對這種詭異的問題時不至于束手無策,也可以在做一些業(yè)務設計時能有所參考。
打印進程內(nèi)核棧
前面我們查到是因為 journal 導致 write 系統(tǒng)調(diào)用被阻塞進而導致超時,但是總感覺證據(jù)還不夠充分,沒有一個完美的交待。
所以我們還需要繼續(xù)追蹤問題。
回到問題的原點,對于此問題,我能確定的資料只有穩(wěn)定復現(xiàn)的環(huán)境和不知道什么時候會觸發(fā) write system call 延遲的 jar 包。
考慮到 write system call 被阻塞可長達幾百 ms,我想我能抓出當前進程的內(nèi)核棧來看一下 write system call 此時被阻塞在什么位置。
具體步驟為:
多個線程不便于抓內(nèi)核棧,先將程序修改為單線程定量寫入。
使用 jar 包啟動一個進程,使用 ps 拿到進程號。
再通過
top -H -p pid拿到占用 cpu、內(nèi)存等資源最多的線程 ID,或使用 strace 啟動,查看其輸出里正在寫入的線程 ID。使用 watch 命令搭配 pstack 或
cat /proc/pid/stack不停打印進程內(nèi)核棧。具體命令為watch -n 0.1 "date +%s >> stack.log;cat /proc/pid/stack >> stack.log"找到
write system call被阻塞時的時間戳,在stack.log里查看當時的進程內(nèi)核棧。
可穩(wěn)定收集到 write system call 被阻塞時,進程內(nèi)核棧為:
?[]?call_rwsem_down_read_failed+0x14/0x30??
?[]?ext4_da_get_block_prep+0x1a4/0x4b0?[ext4]??
?[]?__block_write_begin+0x1a7/0x490??
?[]?ext4_da_write_begin+0x15c/0x340?[ext4]??
?[]?generic_file_buffered_write+0x11e/0x290??
?[]?__generic_file_aio_write+0x1d5/0x3e0??
?[]?generic_file_aio_write+0x5d/0xc0??
?[]?ext4_file_write+0xb5/0x460?[ext4]??
?[]?do_sync_write+0x8d/0xd0??
?[]?vfs_write+0xbd/0x1e0??
?[]?SyS_write+0x58/0xb0??
?[]?system_call_fastpath+0x16/0x1b??
?[]?0xffffffffffffffff
內(nèi)核棧分析
write system call 阻塞位置
通過內(nèi)核棧函數(shù)關鍵字找到了 OenHan 大神的博客:讀寫信號量與實時進程阻塞掛死問題。
https://oenhan.com/rwsem-realtime-task-hung
這篇文章描述的問題雖然跟我遇到的問題不同,但進程內(nèi)核棧的分析對我很有啟發(fā)。為了便于分析內(nèi)核函數(shù),我 clone 了一份 linux 3.10.0 的源碼,在本地查看。
搜索源碼可以證實,棧頂?shù)膮R編函數(shù)?ENTRY call_rwsem_down_read_failed?會調(diào)用?rwsem_down_read_failed(), 而此函數(shù)會一直阻塞在獲取 inode 的鎖。
struct?rw_semaphore?__sched?*rwsem_down_read_failed(struct?rw_semaphore?*sem)?{??
????????.....??
?/*?wait?to?be?given?the?lock?*/??
?while?(true)?{??
??set_task_state(tsk,?TASK_UNINTERRUPTIBLE);??
??if?(!waiter.task)??
???break;??
??schedule();??
?}??
??
?tsk->state?=?TASK_RUNNING;??
??
?return?sem;??
}??
延遲分配
知道了 write system call 阻塞的位置,還要查它會什么會阻塞在這里。
這時,棧頂?shù)暮瘮?shù)名?call_rwsem_down_read_failed?讓我覺得很奇怪,這不是 “write” system call 么,為什么會?down_read_failed?
直接搜索這個函數(shù)沒有什么資料,但向棧底方向,再搜索其他函數(shù)就有了線索了,原來這是在做系統(tǒng)磁盤塊的準備,于是就牽扯出了 ext4 的 delayed allocation 特性。
延遲分配(delayed allocation):ext4 文件系統(tǒng)在應用程序調(diào)用 write system call 時并不為緩存頁面分配對應的物理磁盤塊,當文件的緩存頁面真正要被刷新至磁盤中時,才會為所有未分配物理磁盤塊的頁面緩存分配盡量連續(xù)的磁盤塊。
這一特性,可以避免磁盤的碎片化,也可以避免存活時間極短文件的磁盤塊分配,能很大提升系統(tǒng)文件 I/O 性能。
而在 write 向內(nèi)存頁時,就需要查詢這些內(nèi)存頁是否已經(jīng)分配了磁盤塊,然后給未分配的臟頁打上延遲分配的標簽。
寫入的詳細過程可以查看 ext4 的延遲分配:
https://blog.csdn.net/kai_ding/article/details/9914629
此時需要獲取此 inode 的讀鎖,若出現(xiàn)鎖沖突,write system call 便會 hang 住。
在掛載磁盤時使用 -o nodelalloc 選項禁用掉延遲分配特性后再進行測試,發(fā)現(xiàn) write system call 被阻塞的情況確實消失了,證明問題確定跟延遲分配有關。
不算結(jié)論的結(jié)論
尋找寫鎖
知道了 write system call 阻塞在獲取讀鎖,那么一定是內(nèi)核里有哪些地方持有了寫鎖。
ipcs 命令可以查看系統(tǒng)內(nèi)核此時的進程間通信設施的狀態(tài),它打印的項目包括消息列表(-q)、共享內(nèi)存(-m)和信號量(-q)的信息,用 ipcs -q 打印內(nèi)核棧的函數(shù)查看 write system call 被阻塞時的信號量,卻沒有輸出任何信息。
仔細想了一下發(fā)現(xiàn)其寫鎖 i_data_sem 是一把讀寫鎖,而信號量是一種 非0即1 的PV量,雖然名字里帶有 sem,可它并不是用信號量實現(xiàn)的。
perf lock 可以用來分析系統(tǒng)內(nèi)核的鎖信息,但要使用它需要重新編譯內(nèi)核,添加 CONFIG_LOCKDEP、CONFIG_LOCK_STAT 選項。先不說我們測試機的重啟需要建提案等兩天,編譯完能不能啟動得來我真的沒有信心,第一次試圖使用 perf 分析 linux 性能問題就這么折戟了。
轉(zhuǎn)變方法
問題又卡住了,這時我也沒有太多辦法了,現(xiàn)在開始研究 linux 文件系統(tǒng)源碼是來不及了,但我還可以問。
在 stackOverflow 上問沒人理我:how metadata journal stalls write system call?,
https://stackoverflow.com/questions/52778498/how-metadata-journal-stalls-write-system-call
追著 OenHan 問了幾次也沒有什么結(jié)論:Linux內(nèi)核寫文件流程。
http://oenhan.com/linux-kernel-write#comment-201
雖然自己沒法測試 upstream linux,還是在 kernel bugzilla 上發(fā)了個帖子:ext4 journal stalls write system call。
https://bugzilla.kernel.org/show_bug.cgi?id=201461
終于有內(nèi)核大佬回復我:在 ext4_map_blocks() 函數(shù)中進行磁盤塊分配時內(nèi)核會持有寫鎖。
查看了源碼里的函數(shù)詳情,證實了這一結(jié)論:
/*??
?*?The?ext4_map_blocks()?function?tries?to?look?up?the?requested?blocks,??
?*?and?returns?if?the?blocks?are?already?mapped.??
?*??
?*?Otherwise?it?takes?the?write?lock?of?the?i_data_sem?and?allocate?blocks??
?*?and?store?the?allocated?blocks?in?the?result?buffer?head?and?mark?it??
?*?mapped.??
*/??
int?ext4_map_blocks(handle_t?*handle,?struct?inode?*inode,??
??????struct?ext4_map_blocks?*map,?int?flags)??
{??
.....??
?/*??
??*?New?blocks?allocate?and/or?writing?to?uninitialized?extent??
??*?will?possibly?result?in?updating?i_data,?so?we?take??
??*?the?write?lock?of?i_data_sem,?and?call?get_blocks()??
??*?with?create?==?1?flag.??
??*/??
?down_write((&EXT4_I(inode)->i_data_sem));??
.....??
}??
但又是哪里引用了 ext4_map_blocks() 函數(shù),長時間獲取了寫鎖呢?
再追問時大佬已經(jīng)頗有些無奈了,linux 3.10.0 的 release 已經(jīng)是 5年 前了,當時肯定也有一堆 bug 和缺陷,到現(xiàn)在已經(jīng)發(fā)生了很大變動,追查這個問題可能并沒有很大的意義了,我只好識趣停止了。
推論
其實再向下查這個問題對我來說也沒有太大意義了,缺少對源碼理解的積累,再看太多的資料也沒有什么收益。
就如向建筑師向小孩子講建筑設計,知道窗子要朝南,大門要靠近電梯這些知識并無意義,不了解建筑設計的原則,只專注于一些自己可以推導出來的理論點,根本沒辦法吸收到其中精髓。
那么只好走到最后一步,根據(jù)查到的資料和測試現(xiàn)象對問題原因做出推論,雖然沒有直接證據(jù),但肯定跟這些因素有關。
在 ext4 文件系統(tǒng)下,默認為 ordered journal 模式,所以寫 metadata journal 可能會迫使臟頁刷盤, 而在 ext4 啟用 delayed allocation 特性時,臟頁可能在落盤時發(fā)現(xiàn)沒有分配對應的磁盤塊而分配磁盤塊。在臟頁太多的情況下,分配磁盤塊慢時會持有 inode 的寫鎖時間過長,阻塞了 write 系統(tǒng)調(diào)用。
追求知識的每一步或多或少都有其中意義,查這個問題就迫使我讀了很多外語文獻,也了解了一部分文件系統(tǒng)設計思想。
覺得本文對你有幫助?請分享給更多人
關注「全棧開發(fā)者社區(qū)」加星標,提升全棧技能
本公眾號會不定期給大家發(fā)福利,包括送書、學習資源等,敬請期待吧!
如果感覺推送內(nèi)容不錯,不妨右下角點個在看轉(zhuǎn)發(fā)朋友圈或收藏,感謝支持。
好文章,留言、點贊、在看和分享一條龍