
千萬不要為了“分庫分表”而“分庫分表”
回復(fù)“1024”獲取?2000+?道互聯(lián)網(wǎng)大廠面試題
數(shù)據(jù)庫瓶頸
不管是IO瓶頸還是CPU瓶頸,最終都會導致數(shù)據(jù)庫的活躍連接數(shù)增加,進而逼近甚至達到數(shù)據(jù)庫可承載的活躍連接數(shù)的閾值。在業(yè)務(wù)service來看, 就是可用數(shù)據(jù)庫連接少甚至無連接可用,接下來就可以想象了(并發(fā)量、吞吐量、崩潰)。
IO瓶頸
第一種:磁盤讀IO瓶頸,熱點數(shù)據(jù)太多,數(shù)據(jù)庫緩存放不下,每次查詢會產(chǎn)生大量的IO,降低查詢速度->分庫和垂直分表 第二種:網(wǎng)絡(luò)IO瓶頸,請求的數(shù)據(jù)太多,網(wǎng)絡(luò)帶寬不夠 ->分庫
CPU瓶頸
第一種:SQl問題:如SQL中包含join,group by, order by,非索引字段條件查詢等,增加CPU運算的操作->SQL優(yōu)化,建立合適的索引,在業(yè)務(wù)Service層進行業(yè)務(wù)計算。 第二種:單表數(shù)據(jù)量太大,查詢時掃描的行太多,SQl效率低,增加CPU運算的操作。->水平分表。
分庫分表
水平分庫
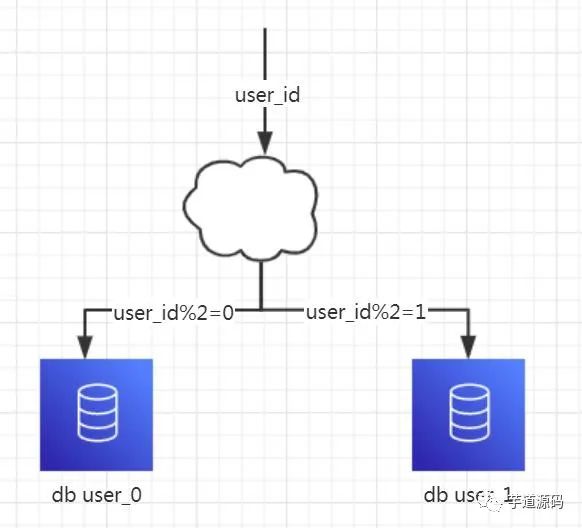
1、概念:以字段為依據(jù),按照一定策略(hash、range等),將一個庫中的數(shù)據(jù)拆分到多個庫中。2、結(jié)果:
每個庫的結(jié)構(gòu)都一樣 每個庫中的數(shù)據(jù)不一樣,沒有交集 所有庫的數(shù)據(jù)并集是全量數(shù)據(jù) 3、場景:系統(tǒng)絕對并發(fā)量上來了,分表難以根本上解決問題,并且還沒有明顯的業(yè)務(wù)歸屬來垂直分庫的情況下。4、分析:庫多了,io和cpu的壓力自然可以成倍緩解
水平分表
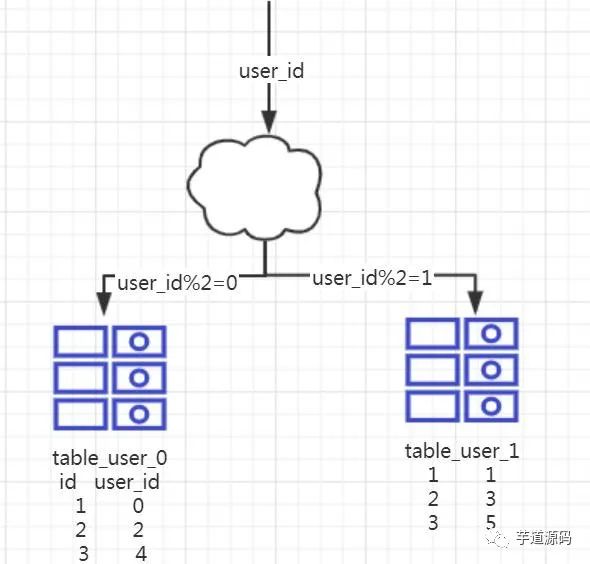
1、概念:以字段為依據(jù),按照一定策略(hash、range等),講一個表中的數(shù)據(jù)拆分到多個表中。2、結(jié)果:
每個表的結(jié)構(gòu)都一樣 每個表的數(shù)據(jù)不一樣,沒有交集,所有表的并集是全量數(shù)據(jù)。3、場景:系統(tǒng)絕對并發(fā)量沒有上來,只是單表的數(shù)據(jù)量太多,影響了SQL效率,加重了CPU負擔,以至于成為瓶頸,可以考慮水平分表。4、分析:單表的數(shù)據(jù)量少了,單次執(zhí)行SQL執(zhí)行效率高了,自然減輕了CPU的負擔。
垂直分庫
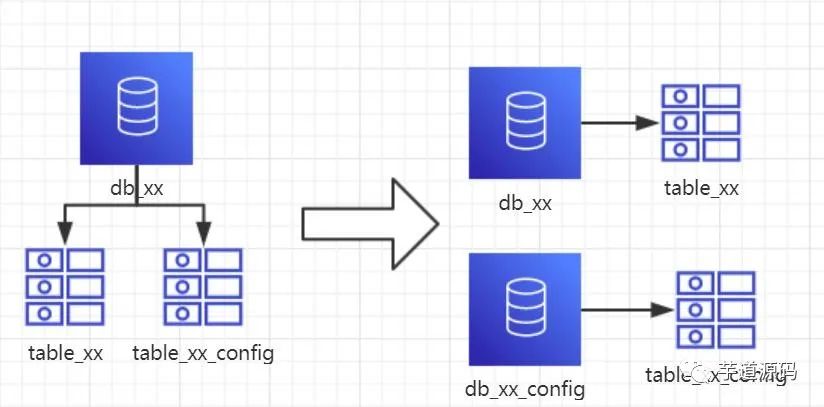
1、概念:以表為依據(jù),按照業(yè)務(wù)歸屬不同,將不同的表拆分到不同的庫中。2、結(jié)果:
每個庫的結(jié)構(gòu)都不一樣 每個庫的數(shù)據(jù)也不一樣,沒有交集 所有庫的并集是全量數(shù)據(jù) 3、場景:系統(tǒng)絕對并發(fā)量上來了,并且可以抽象出單獨的業(yè)務(wù)模塊的情況下。4、分析:到這一步,基本上就可以服務(wù)化了。例如:隨著業(yè)務(wù)的發(fā)展,一些公用的配置表、字典表等越來越多,這時可以將這些表拆到單獨的庫中,甚至可以服務(wù)化。再者,隨著業(yè)務(wù)的發(fā)展孵化出了一套業(yè)務(wù)模式,這時可以將相關(guān)的表拆到單獨的庫中,甚至可以服務(wù)化。
垂直分表
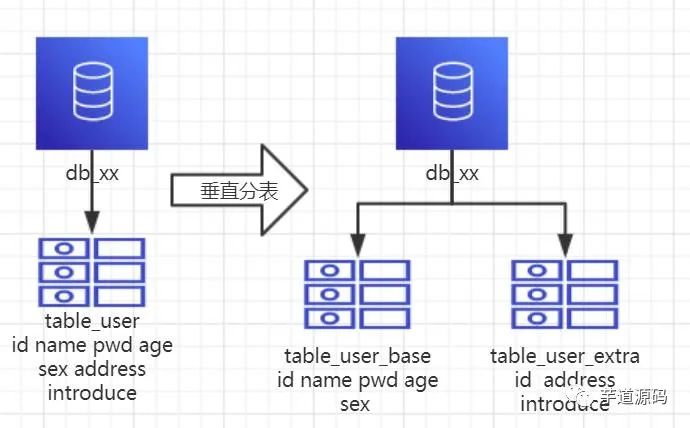
1、概念:以字段為依據(jù),按照字段的活躍性,將表中字段拆到不同的表中(主表和擴展表)。2、結(jié)果:
每個表的結(jié)構(gòu)不一樣。 每個表的數(shù)據(jù)也不一樣,一般來說,每個表的字段至少有一列交集,一般是主鍵,用于關(guān)聯(lián)數(shù)據(jù)。 所有表的并集是全量數(shù)據(jù)。3、場景:系統(tǒng)絕對并發(fā)量并沒有上來,表的記錄并不多,但是字段多,并且熱點數(shù)據(jù)和非熱點數(shù)據(jù)在一起,單行數(shù)據(jù)所需的存儲空間較大,以至于數(shù)據(jù)庫緩存的數(shù)據(jù)行減少,查詢時回去讀磁盤數(shù)據(jù)產(chǎn)生大量隨機讀IO,產(chǎn)生IO瓶頸。4、分析:可以用列表頁和詳情頁來幫助理解。垂直分表的拆分原則是將熱點數(shù)據(jù)(可能經(jīng)常會查詢的數(shù)據(jù))放在一起作為主表,非熱點數(shù)據(jù)放在一起作為擴展表,這樣更多的熱點數(shù)據(jù)就能被緩存下來,進而減少了隨機讀IO。拆了之后,要想獲取全部數(shù)據(jù)就需要關(guān)聯(lián)兩個表來取數(shù)據(jù)。但記住千萬別用join,因為Join不僅會增加CPU負擔并且會將兩個表耦合在一起(必須在一個數(shù)據(jù)庫實例上)。關(guān)聯(lián)數(shù)據(jù)應(yīng)該在service層進行,分別獲取主表和擴展表的數(shù)據(jù),然后用關(guān)聯(lián)字段關(guān)聯(lián)得到全部數(shù)據(jù)。
分庫分表工具
sharding-jdbc(當當) TSharding(蘑菇街) Atlas(奇虎360) Cobar(阿里巴巴) MyCAT(基于Cobar) Oceanus(58同城) Vitess(谷歌) 各種工具的利弊自查
分庫分表帶來的問題
分庫分表能有效緩解單機和單表帶來的性能瓶頸和壓力,突破網(wǎng)絡(luò)IO、硬件資源、連接數(shù)的瓶頸,同時也帶來一些問題,下面將描述這些問題和解決思路。
事務(wù)一致性問題
分布式事務(wù)
當更新內(nèi)容同時存在于不同庫找那個,不可避免會帶來跨庫事務(wù)問題。跨分片事務(wù)也是分布式事務(wù),沒有簡單的方案,一般可使用“XA協(xié)議”和“兩階段提交”處理。分布式事務(wù)能最大限度保證了數(shù)據(jù)庫操作的原子性。但在提交事務(wù)時需要協(xié)調(diào)多個節(jié)點,推后了提交事務(wù)的時間點,延長了事務(wù)的執(zhí)行時間,導致事務(wù)在訪問共享資源時發(fā)生沖突或死鎖的概率增高。隨著數(shù)據(jù)庫節(jié)點的增多,這種趨勢會越來越嚴重,從而成為系統(tǒng)在數(shù)據(jù)庫層面上水平擴展的枷鎖。
最終一致性
對于那些性能要求很高,但對一致性要求不高的系統(tǒng),往往不苛求系統(tǒng)的實時一致性,只要在允許的時間段內(nèi)達到最終一致性即可,可采用事務(wù)補償?shù)姆绞健Ec事務(wù)在執(zhí)行中發(fā)生錯誤立刻回滾的方式不同,事務(wù)補償是一種事后檢查補救的措施,一些常見的實現(xiàn)方法有:對數(shù)據(jù)進行對賬檢查,基于日志進行對比,定期同標準數(shù)據(jù)來源進行同步等。
跨節(jié)點關(guān)聯(lián)查詢join問題
切分之前,系統(tǒng)中很多列表和詳情表的數(shù)據(jù)可以通過join來完成,但是切分之后,數(shù)據(jù)可能分布在不同的節(jié)點上,此時join帶來的問題就比較麻煩了,考慮到性能,盡量避免使用Join查詢。解決的一些方法:
全局表
全局表,也可看做“數(shù)據(jù)字典表”,就是系統(tǒng)中所有模塊都可能依賴的一些表,為了避免庫join查詢,可以將這類表在每個數(shù)據(jù)庫中都保存一份。這些數(shù)據(jù)通常很少修改,所以不必擔心一致性的問題。
字段冗余
一種典型的反范式設(shè)計,利用空間換時間,為了性能而避免join查詢。例如,訂單表在保存userId的時候,也將userName也冗余的保存一份,這樣查詢訂單詳情順表就可以查到用戶名userName,就不用查詢買家user表了。但這種方法適用場景也有限,比較適用依賴字段比較少的情況,而冗余字段的一致性也較難保證。
數(shù)據(jù)組裝
在系統(tǒng)service業(yè)務(wù)層面,分兩次查詢,第一次查詢的結(jié)果集找出關(guān)聯(lián)的數(shù)據(jù)id,然后根據(jù)id發(fā)起器二次請求得到關(guān)聯(lián)數(shù)據(jù),最后將獲得的結(jié)果進行字段組裝。這是比較常用的方法。
ER分片
關(guān)系型數(shù)據(jù)庫中,如果已經(jīng)確定了表之間的關(guān)聯(lián)關(guān)系(如訂單表和訂單詳情表),并且將那些存在關(guān)聯(lián)關(guān)系的表記錄存放在同一個分片上,那么就能較好地避免跨分片join的問題,可以在一個分片內(nèi)進行join。在1:1或1:n的情況下,通常按照主表的ID進行主鍵切分。
跨節(jié)點分頁、排序、函數(shù)問題
跨節(jié)點多庫進行查詢時,會出現(xiàn)limit分頁、order by 排序等問題。分頁需要按照指定字段進行排序,當排序字段就是分頁字段時,通過分片規(guī)則就比較容易定位到指定的分片;當排序字段非分片字段時,就變得比較復(fù)雜.需要先在不同的分片節(jié)點中將數(shù)據(jù)進行排序并返回,然后將不同分片返回的結(jié)果集進行匯總和再次排序,最終返回給用戶如下圖:
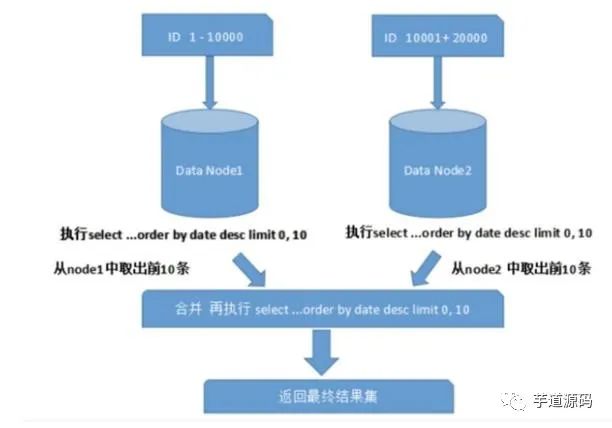
上圖只是取第一頁的數(shù)據(jù),對性能影響還不是很大。但是如果取得頁數(shù)很大,情況就變得復(fù)雜的多,因為各分片節(jié)點中的數(shù)據(jù)可能是隨機的,為了排序的準確性,需要將所有節(jié)點的前N頁數(shù)據(jù)都排序好做合并,最后再進行整體排序,這樣的操作很耗費CPU和內(nèi)存資源,所以頁數(shù)越大,系統(tǒng)性能就會越差。在使用Max、Min、Sum、Count之類的函數(shù)進行計算的時候,也需要先在每個分片上執(zhí)行相應(yīng)的函數(shù),然后將各個分片的結(jié)果集進行匯總再次計算。
全局主鍵避重問題
在分庫分表環(huán)境中,由于表中數(shù)據(jù)同時存在不同數(shù)據(jù)庫中,主鍵值平時使用的自增長將無用武之地,某個分區(qū)數(shù)據(jù)庫自生成ID無法保證全局唯一。因此需要單獨設(shè)計全局主鍵,避免跨庫主鍵重復(fù)問題。這里有一些策略:
UUID
UUID標準形式是32個16進制數(shù)字,分為5段,形式是8-4-4-4-12的36個字符。UUID是最簡單的方案,本地生成,性能高,沒有網(wǎng)絡(luò)耗時,但是缺點明顯,占用存儲空間多,另外作為主鍵建立索引和基于索引進行查詢都存在性能問題,尤其是InnoDb引擎下,UUID的無序性會導致索引位置頻繁變動,導致分頁。
結(jié)合數(shù)據(jù)庫維護主鍵ID表
在數(shù)據(jù)庫中建立sequence表:
CREATE?TABLE?`sequence`?(
??`id`?bigint(20)?unsigned?NOT?NULL?auto_increment,
??`stub`?char(1)?NOT?NULL?default?'',
??PRIMARY?KEY??(`id`),
??UNIQUE?KEY?`stub`?(`stub`)
)?ENGINE=MyISAM;
stub字段設(shè)置為唯一索引,同一stub值在sequence表中只有一條記錄,可以同時為多張表生辰全局ID。使用MyISAM引擎而不是InnoDb,已獲得更高的性能。MyISAM使用的是表鎖,對表的讀寫是串行的,所以不用擔心并發(fā)時兩次讀取同一個ID。當需要全局唯一的ID時,執(zhí)行:
REPLACE?INTO?sequence?(stub)?VALUES?('a');
SELECT?LAST_INSERT_ID();
此方案較為簡單,但缺點較為明顯:存在單點問題,強依賴DB,當DB異常時,整個系統(tǒng)不可用。配置主從可以增加可用性。另外性能瓶頸限制在單臺Mysql的讀寫性能。另有一種主鍵生成策略,類似sequence表方案,更好的解決了單點和性能瓶頸問題。這一方案的整體思想是:建立2個以上的全局ID生成的服務(wù)器,每個服務(wù)器上只部署一個數(shù)據(jù)庫,每個庫有一張sequence表用于記錄當前全局ID。表中增長的步長是庫的數(shù)量,起始值依次錯開,這樣就能將ID的生成散列到各個數(shù)據(jù)庫上
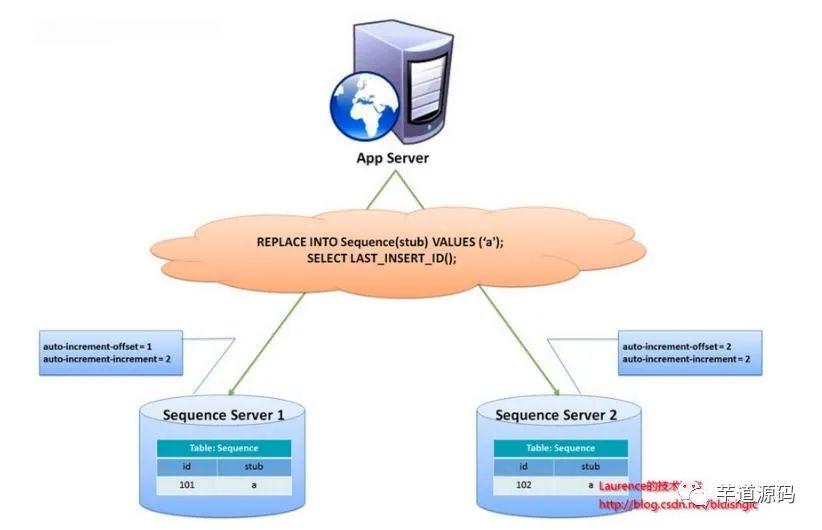
這種方案將生成ID的壓力均勻分布在兩臺機器上,同時提供了系統(tǒng)容錯,第一臺出現(xiàn)了錯誤,可以自動切換到第二臺獲取ID。但有幾個缺點:系統(tǒng)添加機器,水平擴展較復(fù)雜;每次獲取ID都要讀取一次DB,DB的壓力還是很大,只能通過堆機器來提升性能。
Snowflake分布式自增ID算法
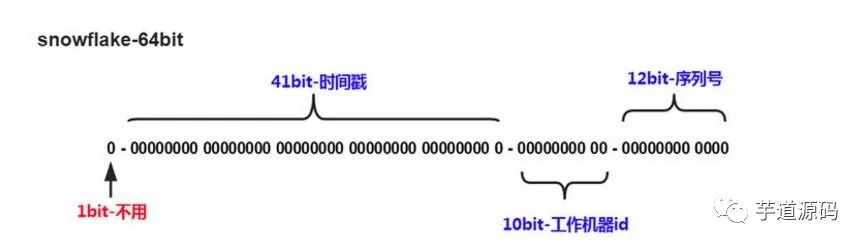
Twitter的snowfalke算法解決了分布式系統(tǒng)生成全局ID的需求,生成64位Long型數(shù)字,組成部分:
第一位未使用 接下來的41位是毫秒級時間,41位的長度可以表示69年的時間 5位datacenterId,5位workerId。10位長度最多支持部署1024個節(jié)點 最后12位是毫秒內(nèi)計數(shù),12位的計數(shù)順序號支持每個節(jié)點每毫秒產(chǎn)生4096個ID序列。
數(shù)據(jù)遷移、擴容問題
當業(yè)務(wù)高速發(fā)展、面臨性能和存儲瓶頸時,才會考慮分片設(shè)計,此時就不可避免的需要考慮歷史數(shù)據(jù)的遷移問題。一般做法是先讀出歷史數(shù)據(jù),然后按照指定的分片規(guī)則再將數(shù)據(jù)寫入到各分片節(jié)點中。此外還需要根據(jù)當前的數(shù)據(jù)量個QPS,以及業(yè)務(wù)發(fā)展速度,進行容量規(guī)劃,推算出大概需要多少分片(一般建議單個分片的單表數(shù)據(jù)量不超過1000W)
什么時候考慮分庫分表
能不分就不分
并不是所有表都需要切分,主要還是看數(shù)據(jù)的增長速度。切分后在某種程度上提升了業(yè)務(wù)的復(fù)雜程度。不到萬不得已不要輕易使用分庫分表這個“大招”,避免“過度設(shè)計”和“過早優(yōu)化”。分庫分表之前,先盡力做力所能及的優(yōu)化:升級硬件、升級網(wǎng)絡(luò)、讀寫分離、索引優(yōu)化等。當數(shù)據(jù)量達到單表瓶頸后,在考慮分庫分表。
數(shù)據(jù)量過大,正常運維影響業(yè)務(wù)訪問
這里的運維是指:
對數(shù)據(jù)庫備份,如果單表太大,備份時需要大量的磁盤IO和網(wǎng)絡(luò)IO 對一個很大的表做DDL,MYSQL會鎖住整個表,這個時間會很長,這段時間業(yè)務(wù)不能訪問此表,影響很大。 大表經(jīng)常訪問和更新,就更有可能出現(xiàn)鎖等待。
隨著業(yè)務(wù)發(fā)展,需要對某些字段垂直拆分
這里就不舉例了。在實際業(yè)務(wù)中都可能會碰到,有些不經(jīng)常訪問或者更新頻率低的字段應(yīng)該從大表中分離出去。
數(shù)據(jù)量快速增長
隨著業(yè)務(wù)的快速發(fā)展,單表中的數(shù)據(jù)量會持續(xù)增長,當性能接近瓶頸時,就需要考慮水平切分,做分庫分表了。
END

