
分庫分表解決方案

中大型項(xiàng)目中,一旦遇到數(shù)據(jù)量比較大,小伙伴應(yīng)該都知道就應(yīng)該對數(shù)據(jù)進(jìn)行拆分了。有垂直和水平兩種。
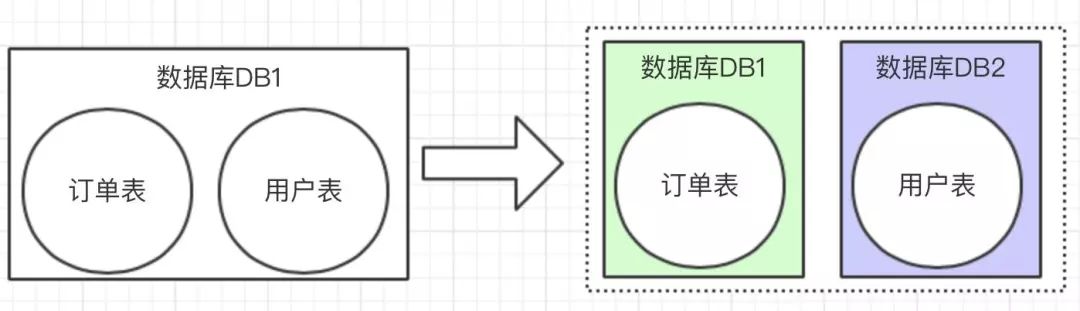
垂直拆分比較簡單,也就是本來一個(gè)數(shù)據(jù)庫,數(shù)據(jù)量大之后,從業(yè)務(wù)角度進(jìn)行拆分多個(gè)庫。如下圖,獨(dú)立的拆分出訂單庫和用戶庫。
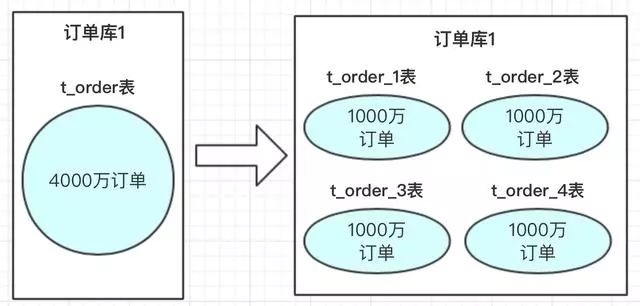
水平拆分的概念,是同一個(gè)業(yè)務(wù)數(shù)據(jù)量大之后,進(jìn)行水平拆分。
二、分庫分表方案
分庫分表方案中有常用的方案,hash取模和range范圍方案;分庫分表方案最主要就是路由算法,把路由的key按照指定的算法進(jìn)行路由存放。下邊來介紹一下兩個(gè)方案的特點(diǎn)。
1、hash取模方案
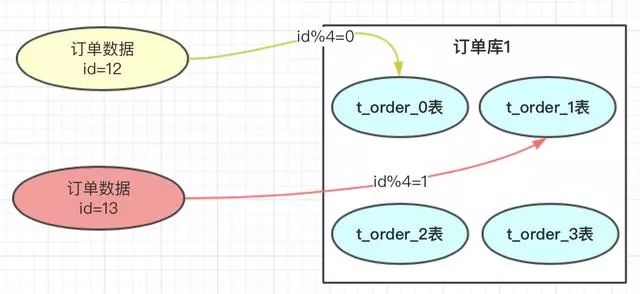
在我們設(shè)計(jì)系統(tǒng)之前,可以先預(yù)估一下大概這幾年的訂單量,如:4000萬。每張表我們可以容納1000萬,也我們可以設(shè)計(jì)4張表進(jìn)行存儲。
那具體如何路由存儲的呢?hash的方案就是對指定的路由key(如:id)對分表總數(shù)進(jìn)行取模,上圖中,id=12的訂單,對4進(jìn)行取模,也就是會得到0,那此訂單會放到0表中。id=13的訂單,取模得到為1,就會放到1表中。為什么對4取模,是因?yàn)榉直砜倲?shù)是4。
優(yōu)點(diǎn):
熱點(diǎn)的含義:熱點(diǎn)的意思就是對訂單進(jìn)行操作集中到1個(gè)表中,其他表的操作很少。 訂單有個(gè)特點(diǎn)就是時(shí)間屬性,一般用戶操作訂單數(shù)據(jù),都會集中到這段時(shí)間產(chǎn)生的訂單。如果這段時(shí)間產(chǎn)生的訂單 都在同一張訂單表中,那就會形成熱點(diǎn),那張表的壓力會比較大。
缺點(diǎn):
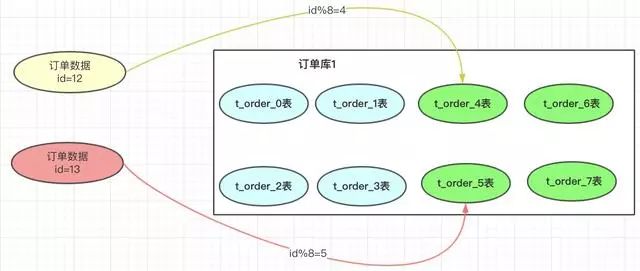
一旦我們增加了分表的總數(shù),取模的基數(shù)就會變成8,以前id=12的訂單按照此方案就會到4表中查詢,但之前的此訂單時(shí)在0表的,這樣就導(dǎo)致了數(shù)據(jù)查不到。就是因?yàn)槿∧5幕鶖?shù)產(chǎn)生了變化。
當(dāng)然做數(shù)據(jù)遷移可以結(jié)合自己的公司的業(yè)務(wù),做一個(gè)工具進(jìn)行,不過也帶來了很多工作量,每次擴(kuò)容都要做數(shù)據(jù)遷移
2、range范圍方案
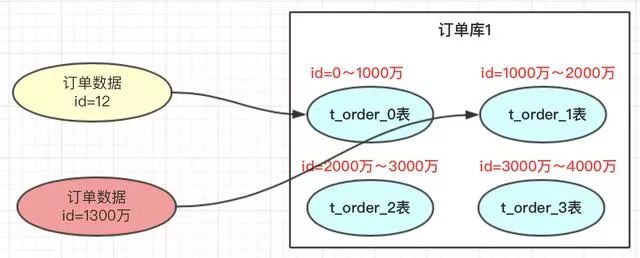
優(yōu)點(diǎn)
缺點(diǎn)
3、總結(jié):
range方案:不需要遷移數(shù)據(jù),但有熱點(diǎn)問題。
那有什么方案可以做到兩者的優(yōu)點(diǎn)結(jié)合呢?,即不需要遷移數(shù)據(jù),又能解決數(shù)據(jù)熱點(diǎn)的問題呢?

三、方案思路
hash是可以解決數(shù)據(jù)均勻的問題,range可以解決數(shù)據(jù)遷移問題,那我們可以不可以兩者相結(jié)合呢?利用這兩者的特性呢?
我們考慮一下數(shù)據(jù)的擴(kuò)容代表著,路由key(如id)的值變大了,這個(gè)是一定的,那我們先保證數(shù)據(jù)變大的時(shí)候,首先用range方案讓數(shù)據(jù)落地到一個(gè)范圍里面。這樣以后id再變大,那以前的數(shù)據(jù)是不需要遷移的。
四、方案設(shè)計(jì)
我們先定義一個(gè)group組概念,這組里面包含了一些分庫以及分表,如下圖
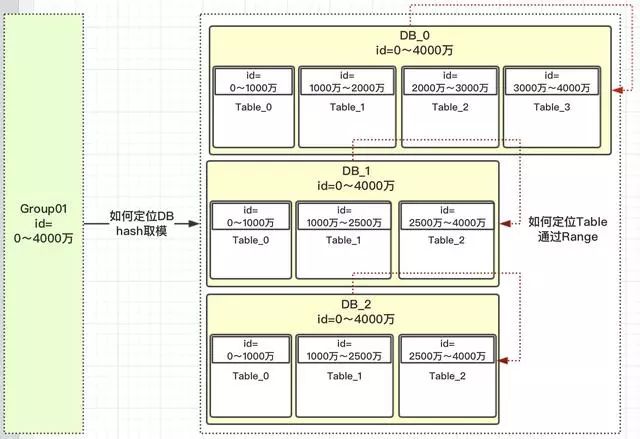
1)id=0~4000萬肯定落到group01組中 2)group01組有3個(gè)DB,那一個(gè)id如何路由到哪個(gè)DB? 3)根據(jù)hash取模定位DB,那模數(shù)為多少?模數(shù)要為所有此group組DB中的表數(shù),上圖總表數(shù)為10。為什么要去表的總數(shù)?而不是DB總數(shù)3呢? 4)如id=12,id%10=2;那值為2,落到哪個(gè)DB庫呢?這是設(shè)計(jì)是前期設(shè)定好的,那怎么設(shè)定的呢? 5)一旦設(shè)計(jì)定位哪個(gè)DB后,就需要確定落到DB中的哪張表呢?

五、核心主流程
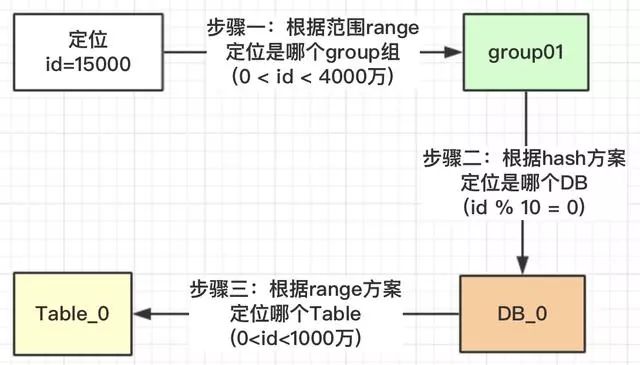
上面我們也提了疑問,為什么對表的總數(shù)10取模,而不是DB的總數(shù)3進(jìn)行取模?我們看一下為什么DB_0是4張表,其他兩個(gè)DB_1是3張表?
在我們安排服務(wù)器時(shí),有些服務(wù)器的性能高,存儲高,就可以安排多存放些數(shù)據(jù),有些性能低的就少放點(diǎn)數(shù)據(jù)。如果我們?nèi)∧J前凑誅B總數(shù)3,進(jìn)行取模,那就代表著【0,4000萬】的數(shù)據(jù)是平均分配到3個(gè)DB中的,那就不能夠?qū)崿F(xiàn)按照服務(wù)器能力適當(dāng)分配了。
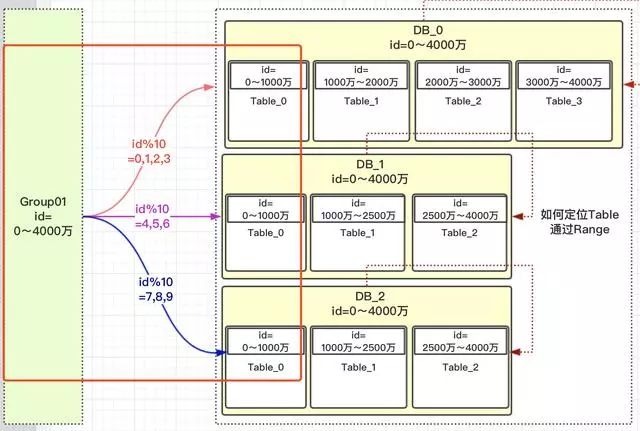
DB_0承擔(dān)了4/10的數(shù)據(jù)量,DB_1承擔(dān)了3/10的數(shù)據(jù)量,DB_2也承擔(dān)了3/10的數(shù)據(jù)量。整個(gè)Group01承擔(dān)了【0,4000萬】的數(shù)據(jù)量。
注意:小伙伴千萬不要被DB_1或DB_2中table的范圍也是0~4000萬疑惑了,這個(gè)是范圍區(qū)間,也就是id在哪些范圍內(nèi),落地到哪個(gè)表而已。

六、如何擴(kuò)容
其實(shí)上面設(shè)計(jì)思路理解了,擴(kuò)容就已經(jīng)出來了;那就是擴(kuò)容的時(shí)候再設(shè)計(jì)一個(gè)group02組,定義好此group的數(shù)據(jù)范圍就ok了。

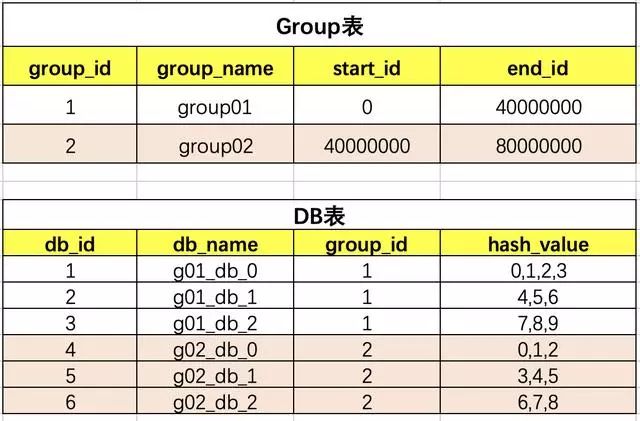
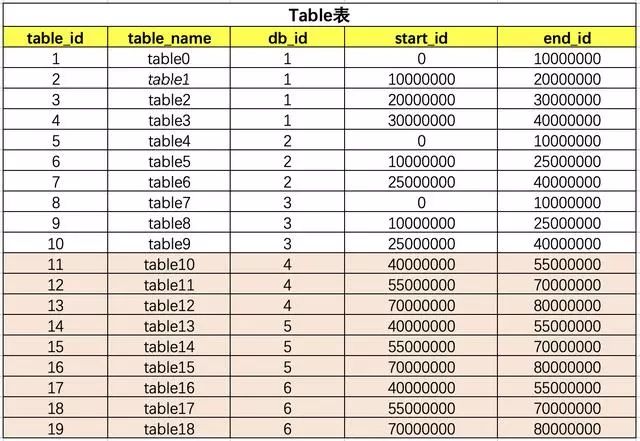
table和db的關(guān)系

一旦需要擴(kuò)容,小伙伴是不是要增加一下group02關(guān)聯(lián)關(guān)系,那應(yīng)用服務(wù)需要重新啟動(dòng)嗎?
簡單點(diǎn)的話,就凌晨配置,重啟應(yīng)用服務(wù)就行了。但如果是大型公司,是不允許的,因?yàn)榱璩恳灿杏唵蔚摹D窃趺崔k呢?本地jvm緩存怎么更新呢?
其實(shí)方案也很多,可以使用用zookeeper,也可以使用分布式配置,這里是比較推薦使用分布式配置中心的,可以將這些數(shù)據(jù)配置到分布式配置中心去。