
超干貨!徹底搞懂Golang內(nèi)存管理和垃圾回收

導(dǎo)語 | 現(xiàn)代高級編程語言管理內(nèi)存的方式分自動和手動兩種。手動管理內(nèi)存的典型代表是C和C++,編寫代碼過程中需要主動申請或者釋放內(nèi)存;而Java和Go等語言使用自動的內(nèi)存管理系統(tǒng),由內(nèi)存分配器和垃圾收集器來代為分配和回收內(nèi)存,開發(fā)者只需關(guān)注業(yè)務(wù)代碼而無需關(guān)注底層內(nèi)存分配和回收,雖然語言幫我們處理了這部分,但是還是有必要去了解一下底層的架構(gòu)設(shè)計和執(zhí)行邏輯,這樣可以更好的掌握一門語言,本文主要以go內(nèi)存管理為切入點再到go垃圾回收,系統(tǒng)地講解了go自動內(nèi)存管理系統(tǒng)的設(shè)計和原理。
一、TCMalloc
go內(nèi)存管理是借鑒了TCMalloc的設(shè)計思想,TCMalloc全稱Thead-Caching Malloc,是google開發(fā)的內(nèi)存分配器,為了方便理解下面的go內(nèi)存管理,有必要要先熟悉一下TCMalloc。
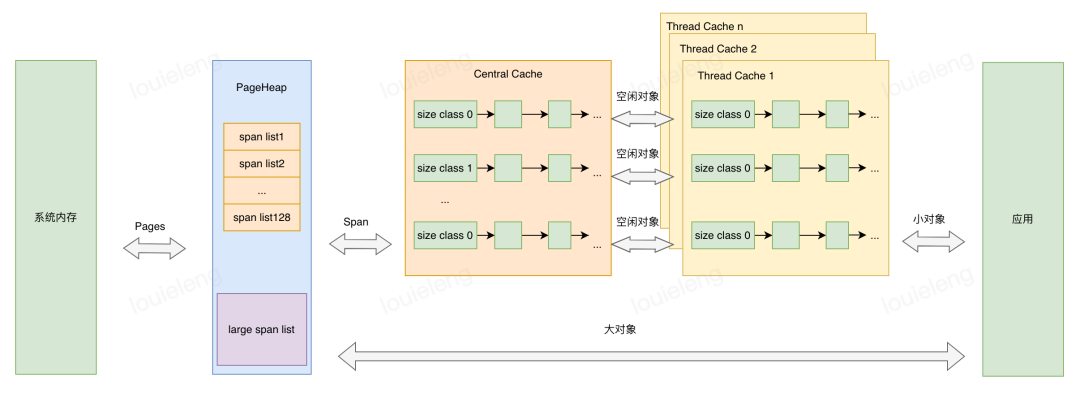
(一)Page
操作系統(tǒng)對內(nèi)存管理以頁為單位,TCMalloc也是這樣,只不過TCMalloc里的Page大小與操作系統(tǒng)里的大小并不一定相等,而是倍數(shù)關(guān)系。
(二) Span
一組連續(xù)的Page被稱為Span,比如可以有4個頁大小的Span,也可以有8個頁大小的Span,Span比Page高一個層級,是為了方便管理一定大小的內(nèi)存區(qū)域,Span是TCMalloc中內(nèi)存管理的基本單位。
(三) ThreadCache
每個線程各自的Cache,一個Cache包含多個空閑內(nèi)存塊鏈表,每個鏈表連接的都是內(nèi)存塊,同一個鏈表上內(nèi)存塊的大小是相同的,也可以說按內(nèi)存塊大小,給內(nèi)存塊分了個類,這樣可以根據(jù)申請的內(nèi)存大小,快速從合適的鏈表選擇空閑內(nèi)存塊。由于每個線程有自己的ThreadCache,所以ThreadCache訪問是無鎖的。
(四)CentralCache
是所有線程共享的緩存,也是保存的空閑內(nèi)存塊鏈表,鏈表的數(shù)量與ThreadCache中鏈表數(shù)量相同,當ThreadCache內(nèi)存塊不足時,可以從CentralCache取,當ThreadCache內(nèi)存塊多時,可以放回CentralCache。由于CentralCache是共享的,所以它的訪問是要加鎖的。
(五)PageHeap
PageHeap是堆內(nèi)存的抽象,PageHeap存的也是若干鏈表,鏈表保存的是Span,當CentralCache沒有內(nèi)存的時,會從PageHeap取,把1個Span拆成若干內(nèi)存塊,添加到對應(yīng)大小的鏈表中,當CentralCache內(nèi)存多的時候,會放回PageHeap。
(六)TCMalloc對象分配
小對象直接從ThreadCache分配,若ThreadCache不夠則從CentralCache中獲取內(nèi)存,CentralCache內(nèi)存不夠時會再從PageHeap獲取內(nèi)存,大對象在PageHeap中選擇合適的頁組成span用于存儲數(shù)據(jù)。
二、GO內(nèi)存管理
經(jīng)過上一節(jié)對TCMalloc內(nèi)存管理的描述,對接下來理解go的內(nèi)存管理會有大致架構(gòu)的熟悉,go內(nèi)存管理架構(gòu)取之TCMalloc不過在細節(jié)上有些出入,先來看一張go內(nèi)存管理的架構(gòu)圖:
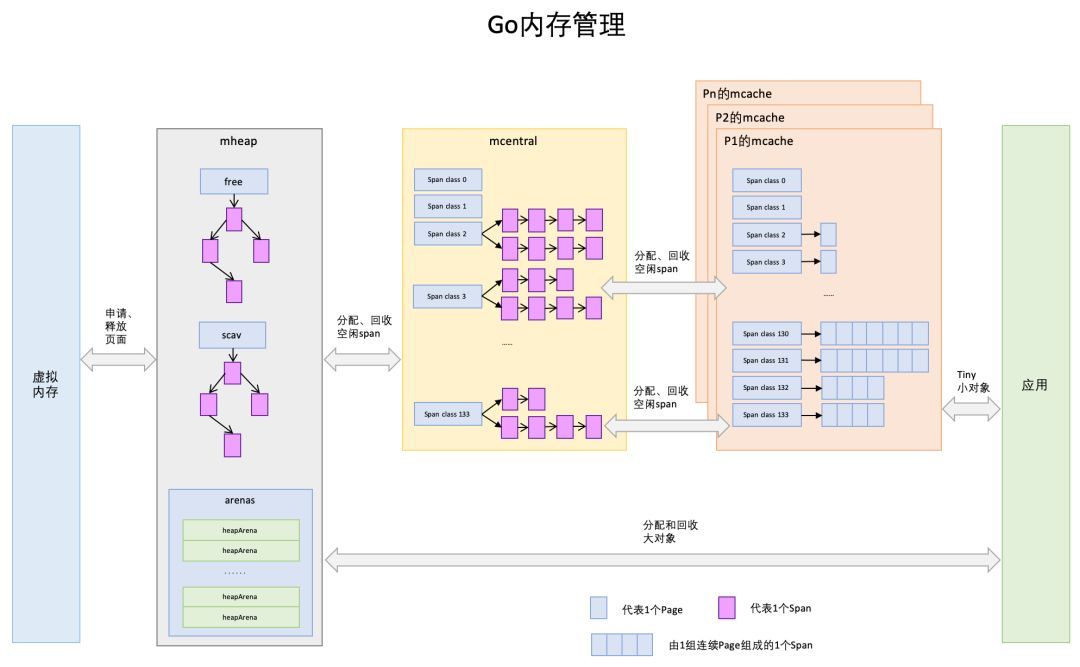
(一)Page
和TCMalloc中page相同,上圖中最下方淺藍色長方形代表一個page。
(二)Span
與TCMalloc中的Span相同,Span是go內(nèi)存管理的基本單位,代碼中為mspan,一組連續(xù)的Page組成1個Span,所以上圖一組連續(xù)的淺藍色長方形代表的是一組Page組成的1個Span,另外,1個淡紫色長方形為1個Span。
(三)mcache
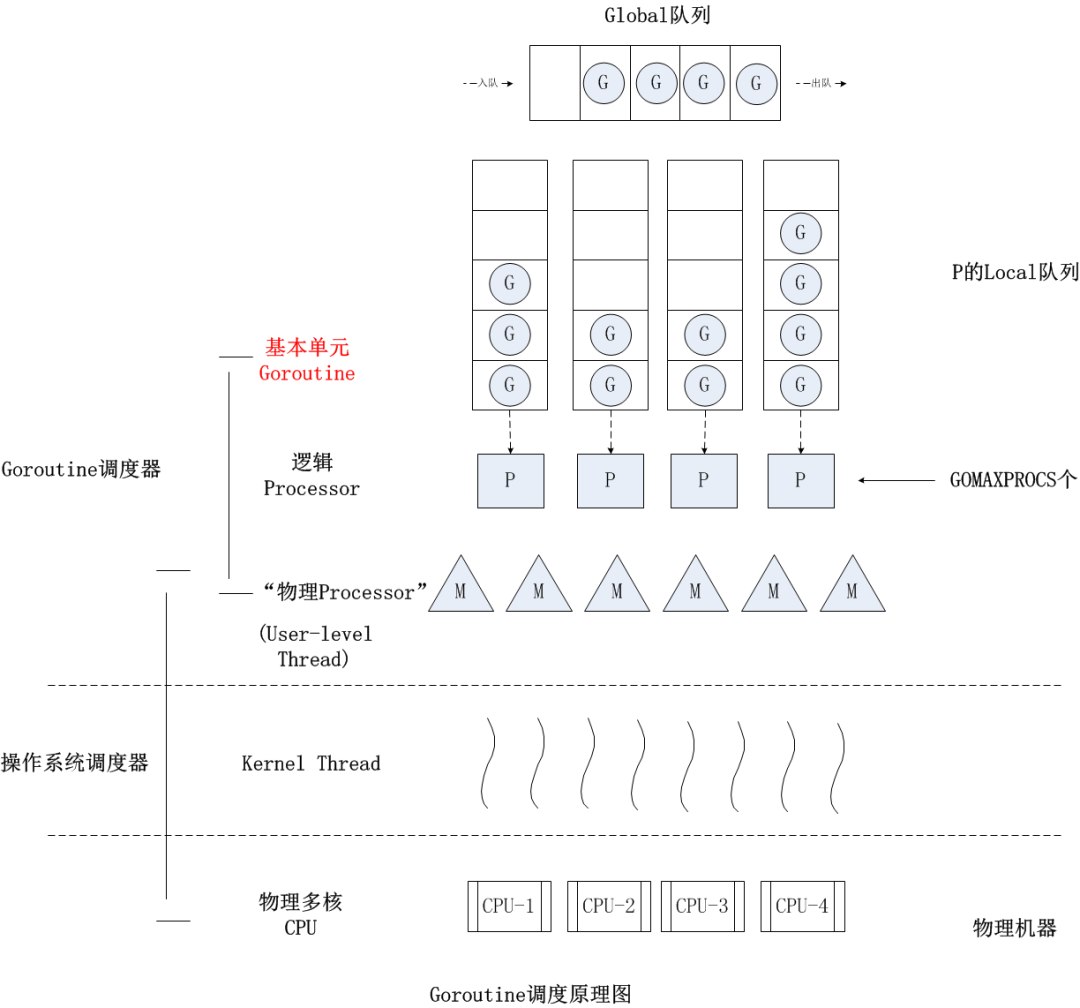
mcache與TCMalloc中的ThreadCache類似,mcache保存的是各種大小的Span,并按Span class分類,小對象直接從mcache分配內(nèi)存,它起到了緩存的作用,并且可以無鎖訪問。但mcache與ThreadCache也有不同點,TCMalloc中是每個線程1個ThreadCache,Go中是每個P擁有1個mcach,因為在Go程序中,當前最多有GOMAXPROCS個線程在運行,所以最多需要GOMAXPROCS個mcache就可以保證各線程對mcache的無鎖訪問,下圖是G,P,M三者之間的關(guān)系:
(四)mcentral
mcentral與TCMalloc中的CentralCache類似,是所有線程共享的緩存,需要加鎖訪問,它按Span class對Span分類,串聯(lián)成鏈表,當mcache的某個級別Span的內(nèi)存被分配光時,它會向mcentral申請1個當前級別的Span。但mcentral與CentralCache也有不同點,CentralCache是每個級別的Span有1個鏈表,mcache是每個級別的Span有2個鏈表。
(五)mheap
mheap與TCMalloc中的PageHeap類似,它是堆內(nèi)存的抽象,把從OS(系統(tǒng))申請出的內(nèi)存頁組織成Span,并保存起來。當mcentral的Span不夠用時會向mheap申請,mheap的Span不夠用時會向OS申請,向OS的內(nèi)存申請是按頁來的,然后把申請來的內(nèi)存頁生成Span組織起來,同樣也是需要加鎖訪問的。但mheap與PageHeap也有不同點:mheap把Span組織成了樹結(jié)構(gòu),而不是鏈表,并且還是2棵樹,然后把Span分配到heapArena進行管理,它包含地址映射和span是否包含指針等位圖,這樣做的主要原因是為了更高效的利用內(nèi)存:分配、回收和再利用。
(六)內(nèi)存分配
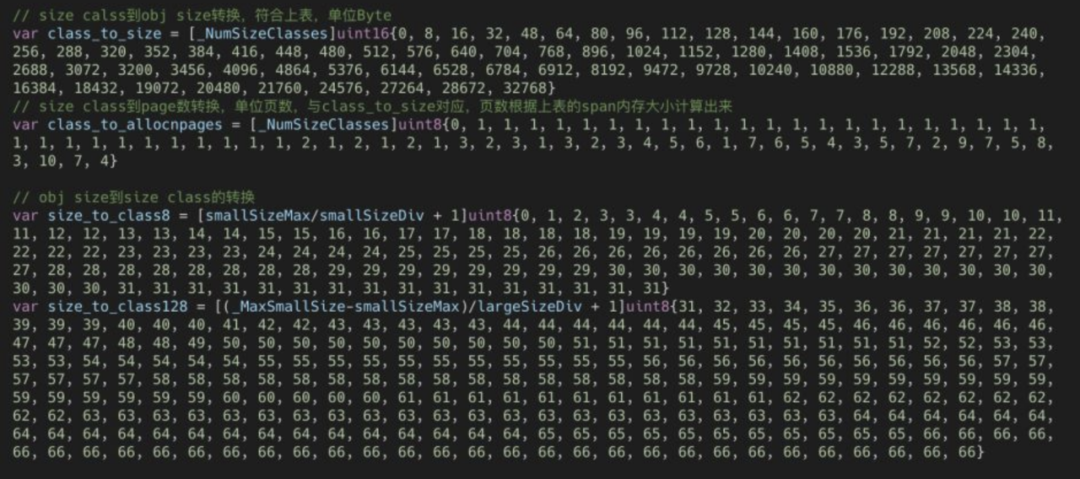
Go中的內(nèi)存分類并不像TCMalloc那樣分成小、中、大對象,但是它的小對象里又細分了一個Tiny對象,Tiny對象指大小在1Byte到16Byte之間并且不包含指針的對象。小對象和大對象只用大小劃定,無其他區(qū)分,其中小對象大小在16Byte到32KB之間,大對象大小大于32KB。span規(guī)格分類 上面說到go的內(nèi)存管理基本單位是span,且span有不同的規(guī)格,要想?yún)^(qū)分出不同的的span,我們必須要有一個標識,每個span通過spanclass標識屬于哪種規(guī)格的span,golang的span規(guī)格一共有67種,具體如下:
//from runtime.gosizeclasses.go// class bytes/obj bytes/span objects tail waste max waste// 1 8 8192 1024 0 87.50%// 2 16 8192 512 0 43.75%// 3 32 8192 256 0 46.88%// 4 48 8192 170 32 31.52%// 5 64 8192 128 0 23.44%// 6 80 8192 102 32 19.07%// 7 96 8192 85 32 15.95%// 8 112 8192 73 16 13.56%// 9 128 8192 64 0 11.72%// 10 144 8192 56 128 11.82%// 11 160 8192 51 32 9.73%// 12 176 8192 46 96 9.59%// 13 192 8192 42 128 9.25%// 14 208 8192 39 80 8.12%// 15 224 8192 36 128 8.15%// 16 240 8192 34 32 6.62%// 17 256 8192 32 0 5.86%// 18 288 8192 28 128 12.16%// 19 320 8192 25 192 11.80%// 20 352 8192 23 96 9.88%// 21 384 8192 21 128 9.51%// 22 416 8192 19 288 10.71%// 23 448 8192 18 128 8.37%// 24 480 8192 17 32 6.82%// 25 512 8192 16 0 6.05%// 26 576 8192 14 128 12.33%// 27 640 8192 12 512 15.48%// 28 704 8192 11 448 13.93%// 29 768 8192 10 512 13.94%// 30 896 8192 9 128 15.52%// 31 1024 8192 8 0 12.40%// 32 1152 8192 7 128 12.41%// 33 1280 8192 6 512 15.55%// 34 1408 16384 11 896 14.00%// 35 1536 8192 5 512 14.00%// 36 1792 16384 9 256 15.57%// 37 2048 8192 4 0 12.45%// 38 2304 16384 7 256 12.46%// 39 2688 8192 3 128 15.59%// 40 3072 24576 8 0 12.47%// 41 3200 16384 5 384 6.22%// 42 3456 24576 7 384 8.83%// 43 4096 8192 2 0 15.60%// 44 4864 24576 5 256 16.65%// 45 5376 16384 3 256 10.92%// 46 6144 24576 4 0 12.48%// 47 6528 32768 5 128 6.23%// 48 6784 40960 6 256 4.36%// 49 6912 49152 7 768 3.37%// 50 8192 8192 1 0 15.61%// 51 9472 57344 6 512 14.28%// 52 9728 49152 5 512 3.64%// 53 10240 40960 4 0 4.99%// 54 10880 32768 3 128 6.24%// 55 12288 24576 2 0 11.45%// 56 13568 40960 3 256 9.99%// 57 14336 57344 4 0 5.35%// 58 16384 16384 1 0 12.49%// 59 18432 73728 4 0 11.11%// 60 19072 57344 3 128 3.57%// 61 20480 40960 2 0 6.87%// 62 21760 65536 3 256 6.25%// 63 24576 24576 1 0 11.45%// 64 27264 81920 3 128 10.00%// 65 28672 57344 2 0 4.91%// 66 32768 32768 1 0 12.50%
由上表可見最大的對象是32KB大小,超過32KB大小的由特殊的class表示,該class ID為0,每個class只包含一個對象。所以上面只有列出了1-66。內(nèi)存大小轉(zhuǎn)換,下面還要三個數(shù)組,分別是:class_to_size,size_to_class和class_to_allocnpages3個數(shù)組,對應(yīng)下圖上的3個箭頭:
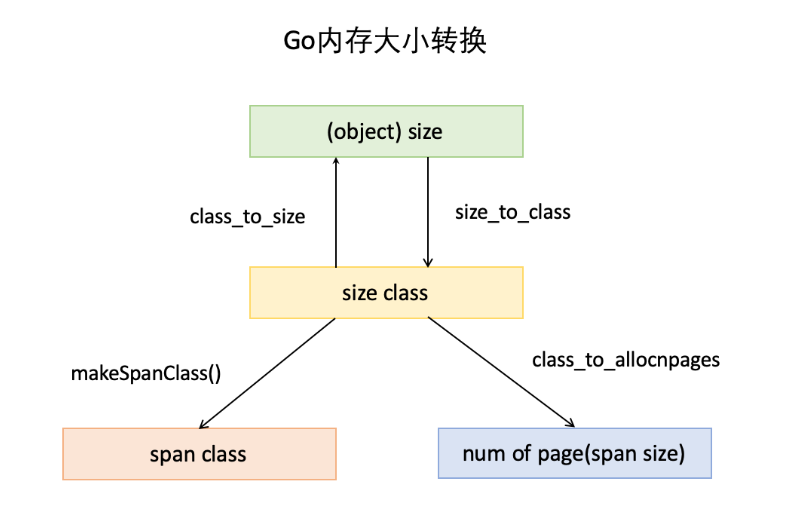
以第一列為例,類別1的對象大小是8bytes,所以class_to_size[1]=8;span大小是8KB,為1頁,所以class_to_allocnpages[1]=1,下圖是go源碼中大小轉(zhuǎn)換數(shù)組。
為對象尋找span,尋找span的流程如下:
計算對象所需內(nèi)存大小size。
根據(jù)size到size class映射,計算出所需的size class。
根據(jù)size class和對象是否包含指針計算出span class。
獲取該span class指向的span。
以分配一個包含指針大小為20Byte的對象為例,根據(jù)映射表:
// class bytes/obj bytes/span objects tail waste max waste// 1 8 8192 1024 0 87.50%// 2 16 8192 512 0 43.75%// 3 32 8192 256 0 46.88%
size class 3,它的對象大小范圍是(16,32]Byte,20Byte剛好在此區(qū)間,所以此對象的size class為3,Size class到span class的計算如下:
// noscan為false代表對象包含指針func makeSpanClass(sizeclass uint8, noscan bool) spanClass {return spanClass(sizeclass<<1) | spanClass(bool2int(noscan))}
所以,對應(yīng)的span class為:
span class = 3 << 1 | 0 = 6所以該對象需要的是span class 7指向的span,自此,小對象內(nèi)存分配完成。
//from runtime.gomalloc.govar sizeclass uint8//step1: 確定規(guī)格sizeClassif size <= smallSizeMax-8 {sizeclass = size_to_class8[divRoundUp(size, smallSizeDiv)]} else {sizeclass = size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]}size = uintptr(class_to_size[sizeclass])// size class到span classspc := makeSpanClass(sizeclass, noscan)//step2: 分配對應(yīng)spanClass 的 spanspan = c.alloc[spc]v := nextFreeFast(span)if v == 0 {v, span, shouldhelpgc = c.nextFree(spc)}x = unsafe.Pointer(v)if needzero && span.needzero != 0 {memclrNoHeapPointers(unsafe.Pointer(v), size)}
大對象(>32KB)的分配則簡單多了,直接在mheap上進行分配,首先計算出需要的內(nèi)存頁數(shù)和span class級別,然后優(yōu)先從free中搜索可用的span,如果沒有找到,會從scav中搜索可用的span,如果還沒有找到,則向OS申請內(nèi)存,再重新搜索2棵樹,必然能找到span。如果找到的span比需求的span大,則把span進行分割成2個span,其中1個剛好是需求大小,把剩下的span再加入到free中去。
三、垃圾回收
(一)標記-清除
標記-清除算法是第一種自動內(nèi)存管理,基于追蹤的垃圾收集算法。算法思想在70年代就提出了,是一種非常古老的算法。內(nèi)存單元并不會在變成垃圾立刻回收,而是保持不可達狀態(tài),直到到達某個閾值或者固定時間長度。這個時候系統(tǒng)會掛起用戶程序,也就是STW,轉(zhuǎn)而執(zhí)行垃圾回收程序。垃圾回收程序?qū)λ械拇婊顔卧M行一次全局遍歷確定哪些單元可以回收。算法分兩個部分:標記(mark)和清除(sweep)。標記階段表明所有的存活單元,清掃階段將垃圾單元回收。可視化可以參考下圖。
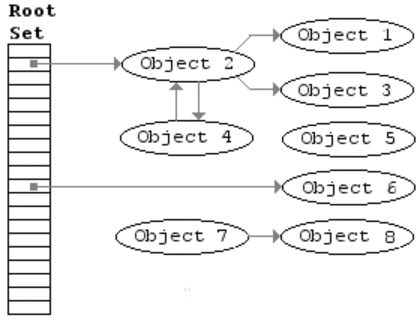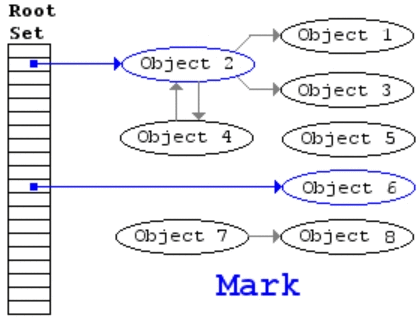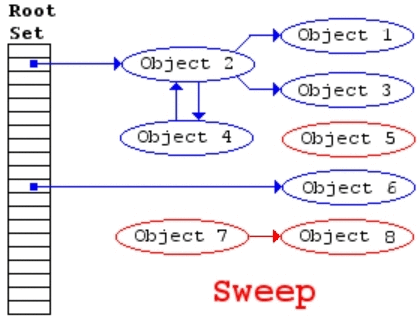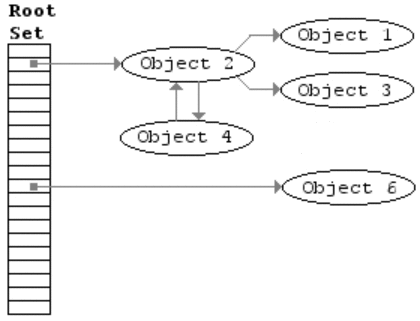
標記-清除算法的優(yōu)點也就是基于追蹤的垃圾回收算法具有的優(yōu)點:避免了引用計數(shù)算法的缺點(不能處理循環(huán)引用,需要維護指針)。缺點也很明顯,需要STW。
(二)三色可達性分析
三色標記算法是對標記階段的改進,原理如下:
起初所有對象都是白色。
從根出發(fā)掃描所有可達對象,標記為灰色,放入待處理隊列。
從隊列取出灰色對象,將其引用對象標記為灰色放入隊列,自身標記為黑色。
重復(fù)上一步,直到灰色對象隊列為空。此時白色對象即為垃圾,進行回收。
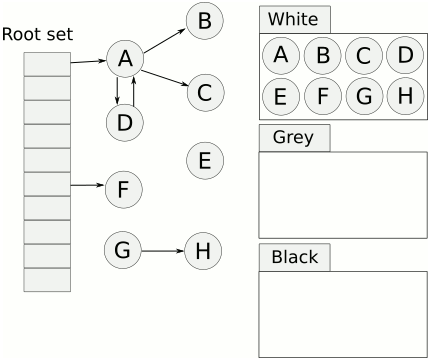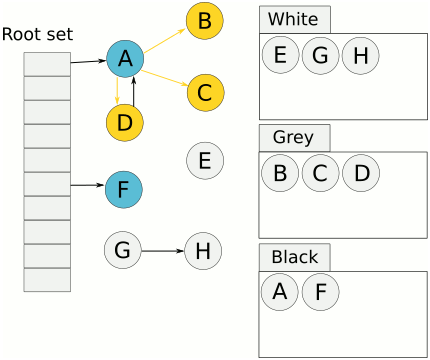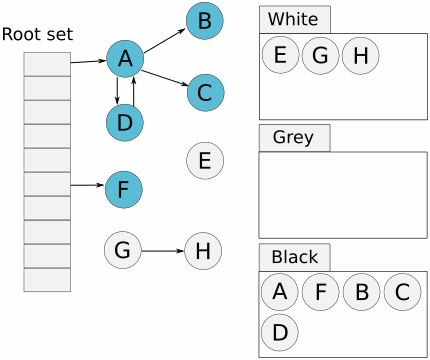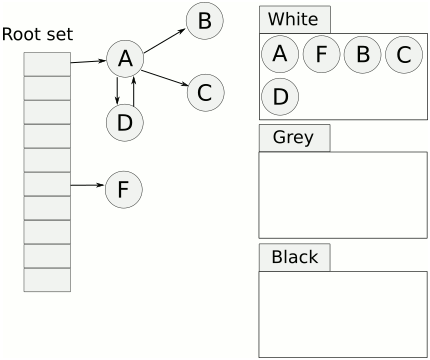
三色標記的一個明顯好處是能夠讓用戶程序和mark并發(fā)的進行,不過三色標記清除算法本身是不可以并發(fā)或者增量執(zhí)行的,它需要STW,而如果并發(fā)執(zhí)行,用戶程序可能在標記執(zhí)行的過程中修改對象的指針,導(dǎo)致可能將本該死亡的對象標記為存活和本該存活的對象標記為死亡,為了解決這種問題,go v1.8之后使用混合寫屏障技術(shù)支持并發(fā)和增量執(zhí)行,將垃圾收集的時間縮短至0.5ms以內(nèi)。
(三)gc觸發(fā)
在堆上分配大于32K byte對象的時候進行檢測此時是否滿足垃圾回收條件,如果滿足則進行垃圾回收
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {...shouldhelpgc := false// 分配的對象小于 32K byteif size <= maxSmallSize {...} else {shouldhelpgc = true...}...// gcShouldStart() 函數(shù)進行觸發(fā)條件檢測if shouldhelpgc && gcShouldStart(false) {// gcStart() 函數(shù)進行垃圾回收gcStart(gcBackgroundMode, false)}}
上面是自動垃圾回收,還有一種主動垃圾回收,通過調(diào)用runtime.GC(),這是阻塞式的。
// GC runs a garbage collection and blocks the caller until the// garbage collection is complete. It may also block the entire// program.func GC() {gcStart(gcForceBlockMode, false)}
系統(tǒng)gc觸發(fā)條件:觸發(fā)條件主要關(guān)注下面代碼中的中間部分:forceTrigger||memstats.heap_live>=memstats.gc_trigger。forceTrigger是forceGC的標志,后面半句的意思是當前堆上的活躍對象大于我們初始化時候設(shè)置的GC觸發(fā)閾值,在malloc以及free的時候heap_live會一直進行更新。
// gcShouldStart returns true if the exit condition for the _GCoff// phase has been met. The exit condition should be tested when// allocating.//// If forceTrigger is true, it ignores the current heap size, but// checks all other conditions. In general this should be false.func gcShouldStart(forceTrigger bool) bool {return gcphase == _GCoff && (forceTrigger || memstats.heap_live >= memstats.gc_trigger) && memstats.enablegc && panicking == 0 && gcpercent >= 0}//初始化的時候設(shè)置 GC 的觸發(fā)閾值func gcinit() {_ = setGCPercent(readgogc())memstats.gc_trigger = heapminimum...}// 啟動的時候通過 GOGC 傳遞百分比 x// 觸發(fā)閾值等于 x * defaultHeapMinimum (defaultHeapMinimum 默認是 4M)func readgogc() int32 {p := gogetenv("GOGC")if p == "off" {return -1}if n, ok := atoi32(p); ok {return n}return 100}
(四)gc過程
下列源碼是基于go 1.8,由于源碼過長,所以這里盡量只關(guān)注主流程
gcStart
// gcStart 是 GC 的入口函數(shù),根據(jù) gcMode 做處理。// 1. gcMode == gcBackgroundMode(后臺運行,也就是并行), _GCoff -> _GCmark// 2. 否則 GCoff -> _GCmarktermination,這個時候就是主動 GCfunc gcStart(mode gcMode, forceTrigger bool) {...//在后臺啟動 mark workerif mode == gcBackgroundMode {gcBgMarkStartWorkers()}...// Stop The Worldsystemstack(stopTheWorldWithSema)...if mode == gcBackgroundMode {// GC 開始前的準備工作//處理設(shè)置 GCPhase,setGCPhase 還會 開始寫屏障setGCPhase(_GCmark)gcBgMarkPrepare() // Must happen before assist enable.gcMarkRootPrepare()// Mark all active tinyalloc blocks. Since we're// allocating from these, they need to be black like// other allocations. The alternative is to blacken// the tiny block on every allocation from it, which// would slow down the tiny allocator.gcMarkTinyAllocs()// Start The Worldsystemstack(startTheWorldWithSema)} else {...}}
Mark
func gcStart(mode gcMode, forceTrigger bool) {...//在后臺啟動 mark workerif mode == gcBackgroundMode {gcBgMarkStartWorkers()}}func gcBgMarkStartWorkers() {// Background marking is performed by per-P G's. Ensure that// each P has a background GC G.for _, p := range &allp {if p == nil || p.status == _Pdead {break}if p.gcBgMarkWorker == 0 {go gcBgMarkWorker(p)notetsleepg(&work.bgMarkReady, -1)noteclear(&work.bgMarkReady)}}}// gcBgMarkWorker 是一直在后臺運行的,大部分時候是休眠狀態(tài),通過 gcController 來調(diào)度func gcBgMarkWorker(_p_ *p) {for {// 將當前 goroutine 休眠,直到滿足某些條件gopark(...)...// mark 過程systemstack(func() {// Mark our goroutine preemptible so its stack// can be scanned. This lets two mark workers// scan each other (otherwise, they would// deadlock). We must not modify anything on// the G stack. However, stack shrinking is// disabled for mark workers, so it is safe to// read from the G stack.casgstatus(gp, _Grunning, _Gwaiting)switch _p_.gcMarkWorkerMode {default:throw("gcBgMarkWorker: unexpected gcMarkWorkerMode")case gcMarkWorkerDedicatedMode:gcDrain(&_p_.gcw, gcDrainNoBlock|gcDrainFlushBgCredit)case gcMarkWorkerFractionalMode:gcDrain(&_p_.gcw, gcDrainUntilPreempt|gcDrainFlushBgCredit)case gcMarkWorkerIdleMode:gcDrain(&_p_.gcw, gcDrainIdle|gcDrainUntilPreempt|gcDrainFlushBgCredit)}casgstatus(gp, _Gwaiting, _Grunning)})...}}
Mark階段的標記代碼主要在函數(shù)gcDrain()中實現(xiàn)
// gcDrain scans roots and objects in work buffers, blackening grey// objects until all roots and work buffers have been drained.func gcDrain(gcw *gcWork, flags gcDrainFlags) {...// Drain root marking jobs.if work.markrootNext < work.markrootJobs {for !(preemptible && gp.preempt) {job := atomic.Xadd(&work.markrootNext, +1) - 1if job >= work.markrootJobs {break}markroot(gcw, job)if idle && pollWork() {goto done}}}// 處理 heap 標記// Drain heap marking jobs.for !(preemptible && gp.preempt) {...//從灰色列隊中取出對象var b uintptrif blocking {b = gcw.get()} else {b = gcw.tryGetFast()if b == 0 {b = gcw.tryGet()}}if b == 0 {// work barrier reached or tryGet failed.break}//掃描灰色對象的引用對象,標記為灰色,入灰色隊列scanobject(b, gcw)}}
Sweep
func gcSweep(mode gcMode) {...//阻塞式if !_ConcurrentSweep || mode == gcForceBlockMode {// Special case synchronous sweep....// Sweep all spans eagerly.for sweepone() != ^uintptr(0) {sweep.npausesweep++}// Do an additional mProf_GC, because all 'free' events are now real as well.mProf_GC()mProf_GC()return}// 并行式// Background sweep.lock(&sweep.lock)if sweep.parked {sweep.parked = falseready(sweep.g, 0, true)}unlock(&sweep.lock)}
對于并行式清掃,在GC初始化的時候就會啟動 bgsweep(),然后在后臺一直循環(huán)
func bgsweep(c chan int) {sweep.g = getg()lock(&sweep.lock)sweep.parked = truec <- 1goparkunlock(&sweep.lock, "GC sweep wait", traceEvGoBlock, 1)for {for gosweepone() != ^uintptr(0) {sweep.nbgsweep++Gosched()}lock(&sweep.lock)if !gosweepdone() {// This can happen if a GC runs between// gosweepone returning ^0 above// and the lock being acquired.unlock(&sweep.lock)continue}sweep.parked = truegoparkunlock(&sweep.lock, "GC sweep wait", traceEvGoBlock, 1)}}func gosweepone() uintptr {var ret uintptrsystemstack(func() {ret = sweepone()})return ret}
不管是阻塞式還是并行式,最終都會調(diào)用sweepone()。上面說過go內(nèi)存管理都是基于span的,mheap_是一個全局的變量,所有分配的對象都會記錄在mheap_中。在標記的時候,我們只要找到對對象對應(yīng)的span進行標記,清掃的時候掃描span,沒有標記的span就可以回收了。
// sweeps one span// returns number of pages returned to heap, or ^uintptr(0) if there is nothing to sweepfunc sweepone() uintptr {...for {s := mheap_.sweepSpans[1-sg/2%2].pop()...if !s.sweep(false) {// Span is still in-use, so this returned no// pages to the heap and the span needs to// move to the swept in-use list.npages = 0}}}// Sweep frees or collects finalizers for blocks not marked in the mark phase.// It clears the mark bits in preparation for the next GC round.// Returns true if the span was returned to heap.// If preserve=true, don't return it to heap nor relink in MCentral lists;// caller takes care of it.func (s *mspan) sweep(preserve bool) bool {...}
參考資料:
1.《go語言設(shè)計與實現(xiàn)》
作者簡介
冷易
騰訊后臺開發(fā)工程師
騰訊后臺開發(fā)工程師,目前負責騰訊醫(yī)藥平臺后端開發(fā)工作,精通java、go底層設(shè)計架構(gòu),有豐富的高并發(fā)性能優(yōu)化,分布式系統(tǒng)開發(fā)經(jīng)驗。
推薦閱讀
C++異步:structured concurrency實現(xiàn)解析!
萬卷共知,一書一頁總關(guān)情,TVP讀書會帶你突圍閱讀迷障!

溫馨提示:因公眾號平臺更改了推送規(guī)則,公眾號推送的文章文末需要點一下“贊”和“在看”,新的文章才會第一時間出現(xiàn)在你的訂閱列表里噢~