
徹底搞懂Python 垃圾回收機制!

來源:https://www.biaodianfu.com/garbage-collector.html
Python 作為一門解釋型語言,以代碼簡潔易懂著稱。我們可以直接對名稱賦值,而不必聲明類型。名稱類型的確定、內(nèi)存空間的分配與釋放都是由 Python 解釋器在運行時進行的。
Python 這一自動管理內(nèi)存功能極大的減小了程序員負擔。對于 Python 這種高級別的語言,開發(fā)者完成可以不用關(guān)心其內(nèi)部的垃圾回收機制。相輔相成的通過學習 Python 內(nèi)部的垃圾回收機制,并了解其原理,可以使得開發(fā)者能夠更好的寫代碼,更加 Pythonista。
目錄
Python內(nèi)存管理機制
Python的垃圾回收機制
????????2.3 分代回收(Generational garbage collector)
Python中的gc模塊
Python內(nèi)存管理機制
在 Python 中,內(nèi)存管理涉及到一個包含所有 Python 對象和數(shù)據(jù)結(jié)構(gòu)的私有堆(heap)。這個私有堆的管理由內(nèi)部的 Python 內(nèi)存管理器(Python memory manager) 保證。Python 內(nèi)存管理器有不同的組件來處理各種動態(tài)存儲管理方面的問題,如共享、分割、預(yù)分配或緩存。
在最底層,一個原始內(nèi)存分配器通過與操作系統(tǒng)的內(nèi)存管理器交互,確保私有堆中有足夠的空間來存儲所有與 Python 相關(guān)的數(shù)據(jù)。在原始內(nèi)存分配器的基礎(chǔ)上,幾個對象特定的分配器在同一堆上運行,并根據(jù)每種對象類型的特點實現(xiàn)不同的內(nèi)存管理策略。例如,整數(shù)對象在堆內(nèi)的管理方式不同于字符串、元組或字典,因為整數(shù)需要不同的存儲需求和速度與空間的權(quán)衡。因此,Python 內(nèi)存管理器將一些工作分配給對象特定分配器,但確保后者在私有堆的范圍內(nèi)運行。
Python 堆內(nèi)存的管理是由解釋器來執(zhí)行,用戶對它沒有控制權(quán),即使他們經(jīng)常操作指向堆內(nèi)內(nèi)存塊的對象指針,理解這一點十分重要。
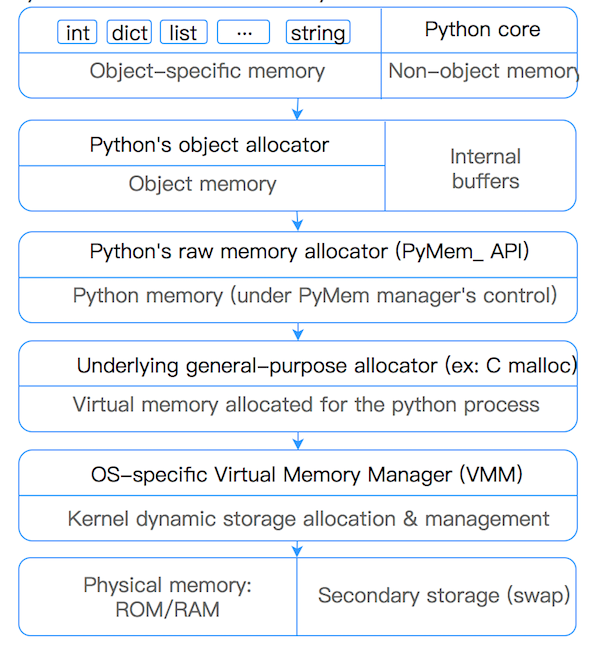
Python為了避免對于小對象(<=512bytes)出現(xiàn)數(shù)量過多的GC,導(dǎo)致的性能消耗。Python對于小對象采用子分配 (內(nèi)存池) 的方式進行內(nèi)存塊的管理。對于大對象使用標準C中的allocator來分配內(nèi)存。
Python對于小對象的allocator由大到小分為三個層級:arena、pool、block。
Block
Block是最小的一個層級,每個block僅僅可以容納包含一個固定大小的Python Object。大小從8-512bytes,以8bytes為步長,分為64類不同的block。
| Request in bytes | Size of allocated block | size class idx |
|---|---|---|
| 1-8 | 8 | 0 |
| 9-16 | 16 | 1 |
| 17-24 | 24 | 2 |
| 25-32 | 32 | 3 |
| 33-40 | 40 | 4 |
| 41-48 | 48 | 5 |
| … | … | … |
| 505-512 | 512 | 63 |
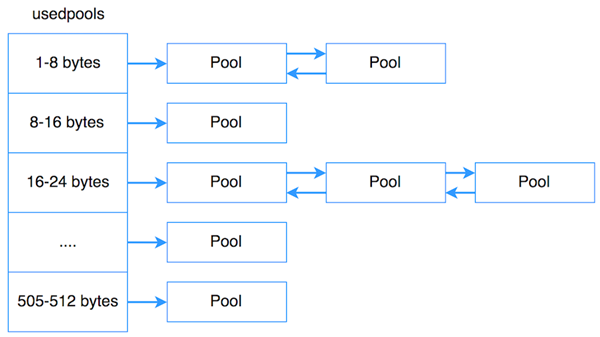
Pool
Pool具有相同大小的block組成集合稱為Pool。通常情況下,Pool的大小為4kb,與虛擬內(nèi)存頁的大小保存一致。限制Pool中block有固定的大小,有如下好處是: 當一個對象在當前Pool中的某個block被銷毀時,Pool內(nèi)存管理可以將新生成的對象放入該block中。
/*?Pool?for?small?blocks.?*/
struct?pool_header?{
????union?{?block?*_padding;
????????????uint?count;?}?ref;??????????/*?number?of?allocated?blocks????*/
????block?*freeblock;???????????????????/*?pool's?free?list?head?????????*/
????struct?pool_header?*nextpool;???????/*?next?pool?of?this?size?class??*/
????struct?pool_header?*prevpool;???????/*?previous?pool???????""????????*/
????uint?arenaindex;????????????????????/*?index?into?arenas?of?base?adr?*/
????uint?szidx;?????????????????????????/*?block?size?class?index????????*/
????uint?nextoffset;????????????????????/*?bytes?to?virgin?block?????????*/
????uint?maxnextoffset;?????????????????/*?largest?valid?nextoffset??????*/
};
具有相同大小的Pool通過雙向鏈表來連接,sidx用來標識Block的類型。arenaindex標識當前Pool屬于哪個Arena。ref.conut標識當前Pool使用了多少個Block。freeblock:標識當前Pools中可用block的指針。freeblock實際是單鏈表實現(xiàn),當一塊block為空狀態(tài)時,則將該block插入到freeblock鏈表的頭部。
每個Pool都有三個狀態(tài):
used:部分使用,即Pool不滿,也不為空 full:滿,即所有Pool中的Block都已被分配 empty:空, 即所有Pool中的Block都未被分配
usedpool為了很好的高效的管理Pool,Python額外使用了array,usedpool來管理。即如下圖所示,usedpool按序存儲著每個特性大小的Pool的頭指針,相同大小的Pool按照雙向鏈表來連接。當分配新的內(nèi)存空間時,創(chuàng)建一個特定大小的Pool,只需要使用usedpools找到頭指針,遍歷即可,當沒有內(nèi)存空間時,只需要在Pool的雙向鏈表的頭部插入新的Pool即可。
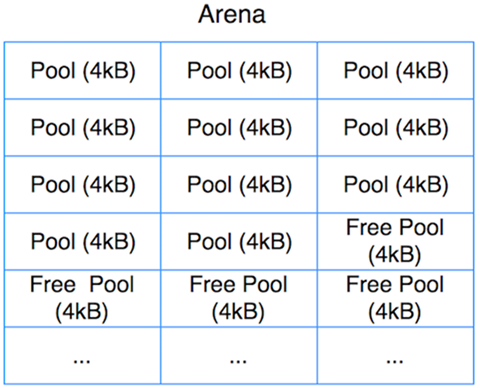
Arena
Pools和Blocks都不會直接去進行內(nèi)存分配(allocate), Pools和Blocks會使用從arena那邊已經(jīng)分配好的內(nèi)存空間。Arena:是分配在堆上256kb的塊狀內(nèi)存,提供了64個Pool。
struct?arena_object?{
????uintptr_t?address;
????block*?pool_address;
????uint?nfreepools;
????uint?ntotalpools;
????struct?pool_header*?freepools;
????struct?arena_object*?nextarena;
????struct?arena_object*?prevarena;
};
所有的arenas也使用雙鏈表進行連接(prevarena, nextarena字段). nfreepools和ntotalpools存儲著當前可用pools的信息。freepools指針指向當前可用的pools。arena結(jié)構(gòu)簡單,職責即為按需給pools分配內(nèi)存,當一個arena為空時,則將該arena的內(nèi)存歸還給操作系統(tǒng)。
Python的垃圾回收機制
Python采用的是引用計數(shù)機制為主,標記-清除和分代收集兩種機制為輔的策略。
引用計數(shù)(reference counting)
Python語言默認采用的垃圾收集機制是“引用計數(shù)法 Reference Counting”,該算法最早George E. Collins在1960的時候首次提出,50年后的今天,該算法依然被很多編程語言使用。
引用計數(shù)法的原理是:每個對象維護一個ob_ref字段,用來記錄該對象當前被引用的次數(shù),每當新的引用指向該對象時,它的引用計數(shù)ob_ref加1,每當該對象的引用失效時計數(shù)ob_ref減1,一旦對象的引用計數(shù)為0,該對象立即被回收,對象占用的內(nèi)存空間將被釋放。
它的缺點是需要額外的空間維護引用計數(shù),這個問題是其次的,不過最主要的問題是它不能解決對象的“循環(huán)引用”,因此,也有很多語言比如Java并沒有采用該算法做來垃圾的收集機制。
Python中一切皆對象,也就是說,在Python中你用到的一切變量,本質(zhì)上都是類對象。實際上每一個對象的核心就是一個結(jié)構(gòu)體PyObject,它的內(nèi)部有一個引用計數(shù)器ob_refcnt,程序在運行的過程中會實時的更新ob_refcnt的值,來反映引用當前對象的名稱數(shù)量。當某對象的引用計數(shù)值為0,說明這個對象變成了垃圾,那么它會被回收掉,它所用的內(nèi)存也會被立即釋放掉。
typedef?struct?_object?{
????int?ob_refcnt;//引用計數(shù)
????struct?_typeobject?*ob_type;
}?PyObject;
導(dǎo)致引用計數(shù)+1的情況:
對象被創(chuàng)建,例如a=23 對象被引用,例如b=a 對象被作為參數(shù),傳入到一個函數(shù)中,例如func(a) 對象作為一個元素,存儲在容器中,例如list1=[a,a]
導(dǎo)致引用計數(shù)-1的情況
對象的別名被顯式銷毀,例如del a 對象的別名被賦予新的對象,例如a=24 一個對象離開它的作用域,例如f函數(shù)執(zhí)行完畢時,func函數(shù)中的局部變量(全局變量不會) 對象所在的容器被銷毀,或從容器中刪除對象
我們可以通過sys包中的getrefcount()來獲取一個名稱所引用的對象當前的引用計。sys.getrefcount()本身會使得引用計數(shù)加一.
循環(huán)引用
引用計數(shù)的另一個現(xiàn)象就是循環(huán)引用,相當于有兩個對象a和b,其中a引用了b,b引用了a,這樣a和b的引用計數(shù)都為1,并且永遠都不會為0,這就意味著這兩個對象永遠都不會被回收了,這就是循環(huán)引用 , a與b形成了一個引用循環(huán) , 示例如下 :
a?=?[1,?2]??#?計數(shù)為?1
b?=?[2,?3]??#?計數(shù)為?1
a.append(b)??#?計數(shù)為?2
b.append(a)??#?計數(shù)為?2
del?a??#?計數(shù)為?1
del?b??#?計數(shù)為?1
除了上述兩個對象互相引用之外 , 還可以引用自身 :
list3?=?[1,2,3]
list3.append(list3)
循環(huán)引用導(dǎo)致變量計數(shù)永不為 0,造成引用計數(shù)無法將其刪除。
引用計數(shù)法有其明顯的優(yōu)點,如高效、實現(xiàn)邏輯簡單、具備實時性,一旦一個對象的引用計數(shù)歸零,內(nèi)存就直接釋放了。不用像其他機制等到特定時機。將垃圾回收隨機分配到運行的階段,處理回收內(nèi)存的時間分攤到了平時,正常程序的運行比較平穩(wěn)。引用計數(shù)也存在著一些缺點:
邏輯簡單,但實現(xiàn)有些麻煩。每個對象需要分配單獨的空間來統(tǒng)計引用計數(shù),這無形中加大的空間的負擔,并且需要對引用計數(shù)進行維護,在維護的時候很容易會出錯。 在一些場景下,可能會比較慢。正常來說垃圾回收會比較平穩(wěn)運行,但是當需要釋放一個大的對象時,比如字典,需要對引用的所有對象循環(huán)嵌套調(diào)用,從而可能會花費比較長的時間。 循環(huán)引用。這將是引用計數(shù)的致命傷,引用計數(shù)對此是無解的,因此必須要使用其它的垃圾回收算法對其進行補充。
也就是說,Python 的垃圾回收機制,很大一部分是為了處理可能產(chǎn)生的循環(huán)引用,是對引用計數(shù)的補充。
標記清除(Mark and Sweep)
Python采用了“標記-清除”(Mark and Sweep)算法,解決容器對象可能產(chǎn)生的循環(huán)引用問題。(注意,只有容器對象才會產(chǎn)生循環(huán)引用的情況,比如列表、字典、用戶自定義類的對象、元組等。而像數(shù)字,字符串這類簡單類型不會出現(xiàn)循環(huán)引用。作為一種優(yōu)化策略,對于只包含簡單類型的元組也不在標記清除算法的考慮之列)
跟其名稱一樣,該算法在進行垃圾回收時分成了兩步,分別是:
標記階段,遍歷所有的對象,如果是可達的(reachable),也就是還有對象引用它,那么就標記該對象為可達; 清除階段,再次遍歷對象,如果發(fā)現(xiàn)某個對象沒有標記為可達,則就將其回收。
對象之間會通過引用(指針)連在一起,構(gòu)成一個有向圖,對象構(gòu)成這個有向圖的節(jié)點,而引用關(guān)系構(gòu)成這個有向圖的邊。從root object出發(fā),沿著有向邊遍歷對象,可達的(reachable)對象標記為活動對象,不可達(unreachable)的對象就是要被清除的非活動對象。所謂 root object,就是一些全局變量、調(diào)用棧、寄存器,這些對象是不可被刪除的。
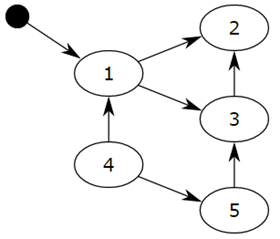
我們把小黑圈視為 root object,從小黑圈出發(fā),對象 1 可達,那么它將被標記,對象 2、3可間接可達也會被標記,而 4 和 5 不可達,那么 1、2、3 就是活動對象,4 和 5 是非活動對象會被 GC 回收。
如下圖所示,在標記清除算法中,為了追蹤容器對象,需要每個容器對象維護兩個額外的指針,用來將容器對象組成一個雙端鏈表,指針分別指向前后兩個容器對象,方便插入和刪除操作。Python解釋器(Cpython)維護了兩個這樣的雙端鏈表,一個鏈表存放著需要被掃描的容器對象,另一個鏈表存放著臨時不可達對象。
在圖中,這兩個鏈表分別被命名為“Object to Scan”和“Unreachable”。圖中例子是這么一個情況:link1,link2,link3組成了一個引用環(huán),同時link1還被一個變量A(其實這里稱為名稱A更好)引用。link4自引用,也構(gòu)成了一個引用環(huán)。
從圖中我們還可以看到,每一個節(jié)點除了有一個記錄當前引用計數(shù)的變量ref_count還有一個gc_ref變量,這個gc_ref是ref_count的一個副本,所以初始值為ref_count的大小。
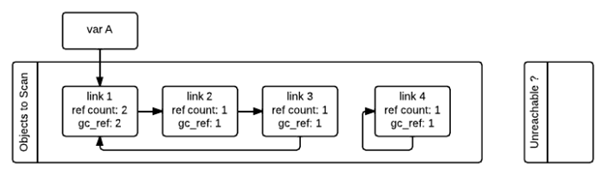
gc啟動的時候,會逐個遍歷“Object to Scan”鏈表中的容器對象,并且將當前對象所引用的所有對象的gc_ref減一。(掃描到link1的時候,由于link1引用了link2,所以會將link2的gc_ref減一,接著掃描link2,由于link2引用了link3,所以會將link3的gc_ref減一…..)像這樣將“Objects to Scan”鏈表中的所有對象考察一遍之后,兩個鏈表中的對象的ref_count和gc_ref的情況如下圖所示。這一步操作就相當于解除了循環(huán)引用對引用計數(shù)的影響。
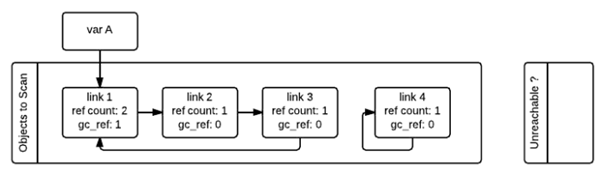
接著,gc會再次掃描所有的容器對象,如果對象的gc_ref值為0,那么這個對象就被標記為GC_TENTATIVELY_UNREACHABLE,并且被移至“Unreachable”鏈表中。下圖中的link3和link4就是這樣一種情況。
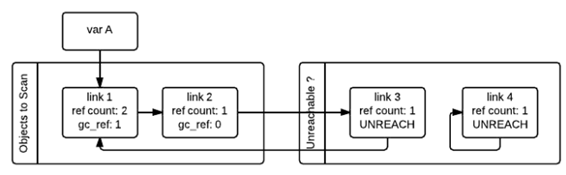
如果對象的gc_ref不為0,那么這個對象就會被標記為GC_REACHABLE。同時當gc發(fā)現(xiàn)有一個節(jié)點是可達的,那么他會遞歸式的將從該節(jié)點出發(fā)可以到達的所有節(jié)點標記為GC_REACHABLE,這就是下圖中l(wèi)ink2和link3所碰到的情形。
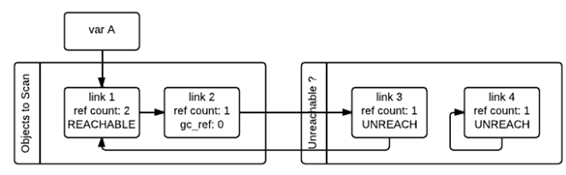
除了將所有可達節(jié)點標記為GC_REACHABLE之外,如果該節(jié)點當前在“Unreachable”鏈表中的話,還需要將其移回到“Object to Scan”鏈表中,下圖就是link3移回之后的情形。

第二次遍歷的所有對象都遍歷完成之后,存在于“Unreachable”鏈表中的對象就是真正需要被釋放的對象。如上圖所示,此時link4存在于Unreachable鏈表中,gc隨即釋放之。
上面描述的垃圾回收的階段,會暫停整個應(yīng)用程序,等待標記清除結(jié)束后才會恢復(fù)應(yīng)用程序的運行。
標記清除的優(yōu)點在于可以解決循環(huán)引用的問題,并且在整個算法執(zhí)行的過程中沒有額外的開銷。缺點在于當執(zhí)行標記清除時正常的程序?qū)蛔枞A硗庖粋€缺點在于,標記清除算法在執(zhí)行很多次數(shù)后,程序的堆空間會產(chǎn)生一些小的內(nèi)存碎片。
分代回收(Generational garbage collector)
分代回收技術(shù)是上個世紀80年代初發(fā)展起來的一種垃圾回收機制,也是Java 垃圾回收的核心算法。分代回收是基于這樣的一個統(tǒng)計事實,對于程序,存在一定比例的內(nèi)存塊的生存周期比較短;而剩下的內(nèi)存塊,生存周期會比較長,甚至會從程序開始一直持續(xù)到程序結(jié)束。
生存期較短對象的比例通常在 80%~90% 之間。因此,簡單地認為:對象存在時間越長,越可能不是垃圾,應(yīng)該越少去收集。這樣在執(zhí)行標記-清除算法時可以有效減小遍歷的對象數(shù),從而提高垃圾回收的速度,是一種以空間換時間的方法策略。
Python 將所有的對象分為 0,1,2 三代; 所有的新建對象都是 0 代對象; 當某一代對象經(jīng)歷過垃圾回收,依然存活,就被歸入下一代對象。
那么,按什么標準劃分對象呢?是否隨機將一個對象劃分到某個代即可呢?答案是否定的。實際上,對象分代里頭也是有不少學問的,好的劃分標準可顯著提升垃圾回收的效率。
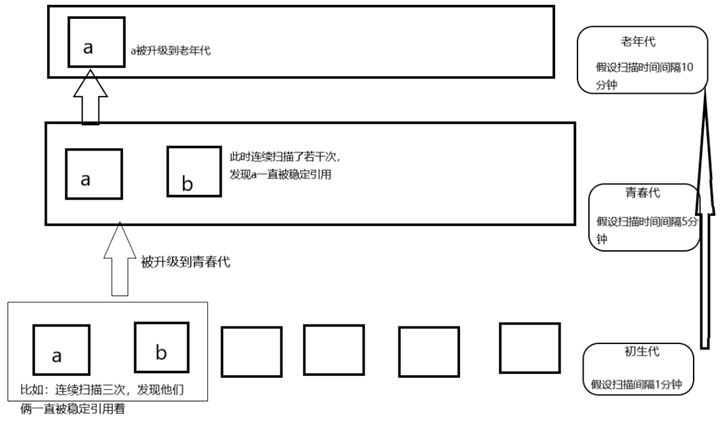
Python 內(nèi)部根據(jù)對象存活時間,將對象分為 3 代,每個代都由一個 gc_generation 結(jié)構(gòu)體來維護(定義于 Include/internal/mem.h):
struct?gc_generation?{?
????PyGC_Head?head;?
????int?threshold;?/*?collection?threshold?*/?
????int?count;?/*?count?of?allocations?or?collections?of?younger?generations?*/?
};
其中:
head,可收集對象鏈表頭部,代中的對象通過該鏈表維護 threshold,僅當 count 超過本閥值時,Python 垃圾回收操作才會掃描本代對象 count,計數(shù)器,不同代統(tǒng)計項目不一樣
Python 虛擬機運行時狀態(tài)由 Include/internal/pystate.h 中的 pyruntimestate 結(jié)構(gòu)體表示,它內(nèi)部有一個 _gc_runtime_state ( Include/internal/mem.h )結(jié)構(gòu)體,保存 GC 狀態(tài)信息,包括 3 個對象代。這 3 個代,在 GC 模塊( Modules/gcmodule.c ) _PyGC_Initialize 函數(shù)中初始化:
struct?gc_generation?generations[NUM_GENERATIONS]?=?{
????/*?PyGC_Head,?threshold,?count?*/
????{{{_GEN_HEAD(0),?_GEN_HEAD(0),?0}},?700?0},
????{{{_GEN_HEAD(1),?_GEN_HEAD(1),?0}},?10,?0},
????{{{_GEN_HEAD(2),?_GEN_HEAD(2),?0}},?10,?0},
};
為方便討論,我們將這 3 個代分別稱為:初生代、中生代 以及 老生代。當這 3 個代初始化完畢后,對應(yīng)的 gc_generation 數(shù)組大概是這樣的:
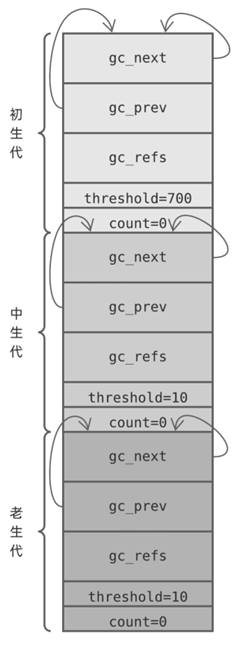
每個 gc_generation 結(jié)構(gòu)體鏈表頭節(jié)點都指向自己,換句話說每個可收集對象鏈表一開始都是空的,計數(shù)器字段 count 都被初始化為 0,而閥值字段 threshold 則有各自的策略。這些策略如何理解呢?
Python 調(diào)用 _PyObject_GC_Alloc 為需要跟蹤的對象分配內(nèi)存時,該函數(shù)將初生代 count 計數(shù)器加1,隨后對象將接入初生代對象鏈表,當 Python 調(diào)用 PyObject_GC_Del 釋放垃圾對象內(nèi)存時,該函數(shù)將初生代 count 計數(shù)器,1,_PyObject_GC_Alloc 自增 count 后如果超過閥值(700),將調(diào)用 collect_generations 執(zhí)行一次垃圾回收( GC )。 collect_generations 函數(shù)從老生代開始,逐個遍歷每個生代,找出需要執(zhí)行回收操作(,count>threshold )的最老生代。隨后調(diào)用 collect_with_callback 函數(shù)開始回收該生代,而該函數(shù)最終調(diào)用 collect 函數(shù)。 collect 函數(shù)處理某個生代時,先將比它年輕的生代計數(shù)器 count 重置為 0,然后將它們的對象鏈表移除,與自己的拼接在一起后執(zhí)行 GC 算法,最后將下一個生代計數(shù)器加1。
于是:
系統(tǒng)每新增 701 個需要 GC 的對象,Python 就執(zhí)行一次 GC 操作 每次 GC 操作需要處理的生代可能是不同的,由 count 和 threshold 共同決定 某個生代需要執(zhí)行 GC ( count>hreshold ),在它前面的所有年輕生代也同時執(zhí)行 GC 對多個代執(zhí)行 GC,Python 將它們的對象鏈表拼接在一起,一次性處理 GC 執(zhí)行完畢后,count 清零,而后一個生代 count 加 1
下面是一個簡單的例子:初生代觸發(fā) GC 操作,Python 執(zhí)行 collect_generations 函數(shù)。它找出了達到閥值的最老生代是中生代,因此調(diào)用 collection_with_callback(1),1 是中生代在數(shù)組中的下標。

collection_with_callback(1) 最終執(zhí)調(diào)用 collect(1) ,它先將后一個生代計數(shù)器加一;然后將本生代以及前面所有年輕生代計數(shù)器重置為零;最后調(diào)用 gc_list_merge 將這幾個可回收對象鏈表合并在一起:
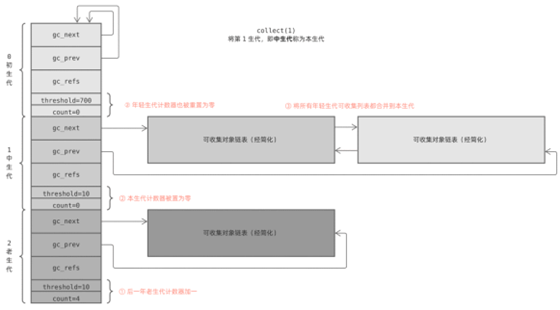
最后,collect 函數(shù)執(zhí)行標記清除算法,對合并后的鏈表進行垃圾回收。

這就是分代回收機制的全部秘密,它看似復(fù)雜,但只需略加總結(jié)就可以得到幾條直白的策略:
每新增 701 個需要 GC 的對象,觸發(fā)一次新生代 GC 每執(zhí)行 11 次新生代 GC ,觸發(fā)一次中生代 GC 每執(zhí)行 11 次中生代 GC ,觸發(fā)一次老生代 GC (老生代 GC 還受其他策略影響,頻率更低) 執(zhí)行某個生代 GC 前,年輕生代對象鏈表也移入該代,一起 GC 一個對象創(chuàng)建后,隨著時間推移將被逐步移入老生代,回收頻率逐漸降低
Python 中的 gc 模塊
gc 模塊是我們在Python中進行內(nèi)存管理的接口,一般情況Python程序員都不用關(guān)心自己程序的內(nèi)存管理問題,但是有的時候,比如發(fā)現(xiàn)自己程序存在內(nèi)存泄露,就可能需要用到gc模塊的接口來排查問題。
有的 Python 系統(tǒng)會關(guān)閉自動垃圾回收,程序自己判斷回收的時機,據(jù)說 instagram 的系統(tǒng)就是這樣做的,整體運行效率提高了10%。
常用函數(shù):
set_debug(flags) :設(shè)置gc的debug日志,一般設(shè)置為gc.DEBUG_LEAK可以看到內(nèi)存泄漏的對象。 collect([generation]) :執(zhí)行垃圾回收。會將那些有循環(huán)引用的對象給回收了。這個函數(shù)可以傳遞參數(shù),0代表只回收第0代的的垃圾對象、1代表回收第0代和第1代的對象,2代表回收第0、1、2代的對象。如果不傳參數(shù),那么會使用2作為默認參數(shù)。 get_threshold() :獲取gc模塊執(zhí)行垃圾回收的閾值。返回的是個元組,第0個是零代的閾值,第1個是1代的閾值,第2個是2代的閾值。 set_threshold(threshold0[, threshold1[, threshold2]) :設(shè)置執(zhí)行垃圾回收的閾值。 get_count() :獲取當前自動執(zhí)行垃圾回收的計數(shù)器。返回一個元組。第0個是零代的垃圾對象的數(shù)量,第1個是零代鏈表遍歷的次數(shù),第2個是1代鏈表遍歷的次數(shù)。
參考鏈接:
聊聊Python內(nèi)存管理 (https://andrewpqc.github.io/2018/10/08/python-memory-management/) gc — 垃圾回收器接口 (https://docs.python.org/zh-cn/3/library/gc.html)
