
PyTorch 的 Autograd詳解
 ?戳我,查看GAN的系列專輯~!
?戳我,查看GAN的系列專輯~!PyTorch 作為一個(gè)深度學(xué)習(xí)平臺(tái),在深度學(xué)習(xí)任務(wù)中比 NumPy 這個(gè)科學(xué)計(jì)算庫(kù)強(qiáng)在哪里呢?我覺(jué)得一是 PyTorch 提供了自動(dòng)求導(dǎo)機(jī)制,二是對(duì) GPU 的支持。由此可見(jiàn),自動(dòng)求導(dǎo) (autograd) 是 PyTorch,乃至其他大部分深度學(xué)習(xí)框架中的重要組成部分。
了解自動(dòng)求導(dǎo)背后的原理和規(guī)則,對(duì)我們寫(xiě)出一個(gè)更干凈整潔甚至更高效的 PyTorch 代碼是十分重要的。但是,現(xiàn)在已經(jīng)有了很多封裝好的 API,我們?cè)趯?xiě)一個(gè)自己的網(wǎng)絡(luò)的時(shí)候,可能幾乎都不用去注意求導(dǎo)這些問(wèn)題,因?yàn)檫@些 API 已經(jīng)在私底下處理好了這些事情。現(xiàn)在我們往往只需要,搭建個(gè)想要的模型,處理好數(shù)據(jù)的載入,調(diào)用現(xiàn)成的 optimizer 和 loss function,直接開(kāi)始訓(xùn)練就好了。仔細(xì)一想,好像連需要設(shè)置?requires_grad=True?的地方好像都沒(méi)有。有人可能會(huì)問(wèn),那我們?nèi)チ私庾詣?dòng)求導(dǎo)還有什么用啊?
原因有很多,可以幫我們更深入地了解 PyTorch 這些寬泛的理由我就不說(shuō)了,我舉一個(gè)例子:當(dāng)我們想使用一個(gè) PyTorch 默認(rèn)中并沒(méi)有的 loss function 的時(shí)候,比如目標(biāo)檢測(cè)模型 YOLO 的 loss,我們可能就得自己去實(shí)現(xiàn)。如果我們不熟悉基本的 PyTorch 求導(dǎo)機(jī)制的話,對(duì)于實(shí)現(xiàn)過(guò)程中比如 tensor 的 in-place 操作等很容易出錯(cuò),導(dǎo)致需要話很長(zhǎng)時(shí)間去 debug,有的時(shí)候即使定位到了錯(cuò)誤的位置,也不知道如何去修改。相反,如果我們理清楚了背后的原理,我們就能很快地修改這些錯(cuò)誤,甚至根本不會(huì)去犯這些錯(cuò)誤。鑒于現(xiàn)在官方支持的 loss function 并不多,而且深度學(xué)習(xí)領(lǐng)域日新月異,很多新的效果很好的 loss function 層出不窮,如果要用的話可能需要我們自己來(lái)實(shí)現(xiàn)。基于這個(gè)原因,我們了解一下自動(dòng)求導(dǎo)機(jī)制還是很有必要的。
本文所有代碼例子都基于 Python3 和 PyTorch 1.1, 也就是不會(huì)涉及 0.4 版本以前的 Variable 這個(gè)數(shù)據(jù)結(jié)構(gòu)。在文章中我們不會(huì)去分析一些非常底層的代碼,而是通過(guò)一系列實(shí)例來(lái)理解自動(dòng)求導(dǎo)機(jī)制。在舉例的過(guò)程中我盡量保持場(chǎng)景的一致性,不用每個(gè)例子都需要重新了解假定的變量。另外,本文篇幅比較長(zhǎng)。如果發(fā)現(xiàn)文章中有錯(cuò)誤或者沒(méi)有講清楚的地方,歡迎大家在評(píng)論區(qū)指正和討論。
目錄
計(jì)算圖 一個(gè)具體的例子 葉子張量 inplace 操作 動(dòng)態(tài)圖,靜態(tài)圖
計(jì)算圖
首先,我們先簡(jiǎn)單地介紹一下什么是計(jì)算圖(Computational Graphs),以方便后邊的講解。假設(shè)我們有一個(gè)復(fù)雜的神經(jīng)網(wǎng)絡(luò)模型,我們把它想象成一個(gè)錯(cuò)綜復(fù)雜的管道結(jié)構(gòu),不同的管道之間通過(guò)節(jié)點(diǎn)連接起來(lái),我們有一個(gè)注水口,一個(gè)出水口。我們?cè)谌肟谧⑷霐?shù)據(jù)的之后,數(shù)據(jù)就沿著設(shè)定好的管道路線緩緩流動(dòng)到出水口,這時(shí)候我們就完成了一次正向傳播。想象一下輸入的 tensor 數(shù)據(jù)在管道中緩緩流動(dòng)的場(chǎng)景,這就是為什么 TensorFlow 叫 TensorFlow?的原因!emmm,好像走錯(cuò)片場(chǎng)了,不過(guò)計(jì)算圖在 PyTorch 中也是類似的。至于這兩個(gè)非常有代表性的深度學(xué)習(xí)框架在計(jì)算圖上有什么區(qū)別,我們稍后再談。
計(jì)算圖通常包含兩種元素,一個(gè)是 tensor,另一個(gè)是 Function。張量 tensor 不必多說(shuō),但是大家可能對(duì) Function 比較陌生。這里 Function 指的是在計(jì)算圖中某個(gè)節(jié)點(diǎn)(node)所進(jìn)行的運(yùn)算,比如加減乘除卷積等等之類的,F(xiàn)unction 內(nèi)部有?forward()?和?backward()?兩個(gè)方法,分別應(yīng)用于正向、反向傳播。
a?=?torch.tensor(2.0,?requires_grad=True)
b?=?a.exp()
print(b)
#?tensor(7.3891,?grad_fn=)
在我們做正向傳播的過(guò)程中,除了執(zhí)行?forward()?操作之外,還會(huì)同時(shí)會(huì)為反向傳播做一些準(zhǔn)備,為反向計(jì)算圖添加 Function 節(jié)點(diǎn)。在上邊這個(gè)例子中,變量?b?在反向傳播中所需要進(jìn)行的操作是?
一個(gè)具體的例子
了解了基礎(chǔ)知識(shí)之后,現(xiàn)在我們來(lái)看一個(gè)具體的計(jì)算例子,并畫(huà)出它的正向和反向計(jì)算圖。假如我們需要計(jì)算這么一個(gè)模型:
l1 = input x w1
l2 = l1 + w2
l3 = l1 x w3
l4 = l2 x l3
loss = mean(l4)
這個(gè)例子比較簡(jiǎn)單,涉及的最復(fù)雜的操作是求平均,但是如果我們把其中的加法和乘法操作換成卷積,那么其實(shí)和神經(jīng)網(wǎng)絡(luò)類似。我們可以簡(jiǎn)單地畫(huà)一下它的計(jì)算圖:
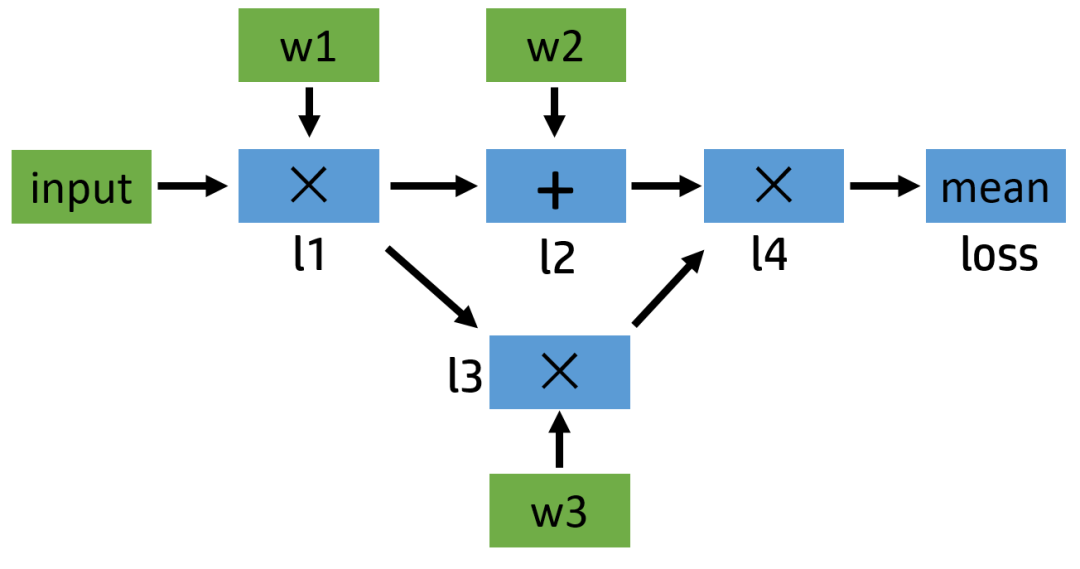
圖1:正向計(jì)算圖
下面給出了對(duì)應(yīng)的代碼,我們定義了input,w1,w2,w3?這三個(gè)變量,其中?input?不需要求導(dǎo)結(jié)果。根據(jù) PyTorch 默認(rèn)的求導(dǎo)規(guī)則,對(duì)于?l1?來(lái)說(shuō),因?yàn)橛幸粋€(gè)輸入需要求導(dǎo)(也就是?w1?需要),所以它自己默認(rèn)也需要求導(dǎo),即?requires_grad=True(如果對(duì)這個(gè)規(guī)則不熟悉,歡迎參考 我上一篇博文的第一部分 或者直接查看 官方 Tutorial 相關(guān)部分)。在整張計(jì)算圖中,只有?input?一個(gè)變量是?requires_grad=False?的。正向傳播過(guò)程的具體代碼如下:
input?=?torch.ones([2,?2],?requires_grad=False)
w1?=?torch.tensor(2.0,?requires_grad=True)
w2?=?torch.tensor(3.0,?requires_grad=True)
w3?=?torch.tensor(4.0,?requires_grad=True)
l1?=?input?*?w1
l2?=?l1?+?w2
l3?=?l1?*?w3
l4?=?l2?*?l3
loss?=?l4.mean()
print(w1.data,?w1.grad,?w1.grad_fn)
#?tensor(2.)?None?None
print(l1.data,?l1.grad,?l1.grad_fn)
#?tensor([[2.,?2.],
#?????????[2.,?2.]])?None?
print(loss.data,?loss.grad,?loss.grad_fn)
#?tensor(40.)?None?
正向傳播的結(jié)果基本符合我們的預(yù)期。我們可以看到,變量?l1?的?grad_fn?儲(chǔ)存著乘法操作符?w1?是用戶自己定義的,不是通過(guò)計(jì)算得來(lái)的,所以其?grad_fn?為空;同時(shí)因?yàn)檫€沒(méi)有進(jìn)行反向傳播,grad?的值也為空。接下來(lái),我們看一下如果要繼續(xù)進(jìn)行反向傳播,計(jì)算圖應(yīng)該是什么樣子:
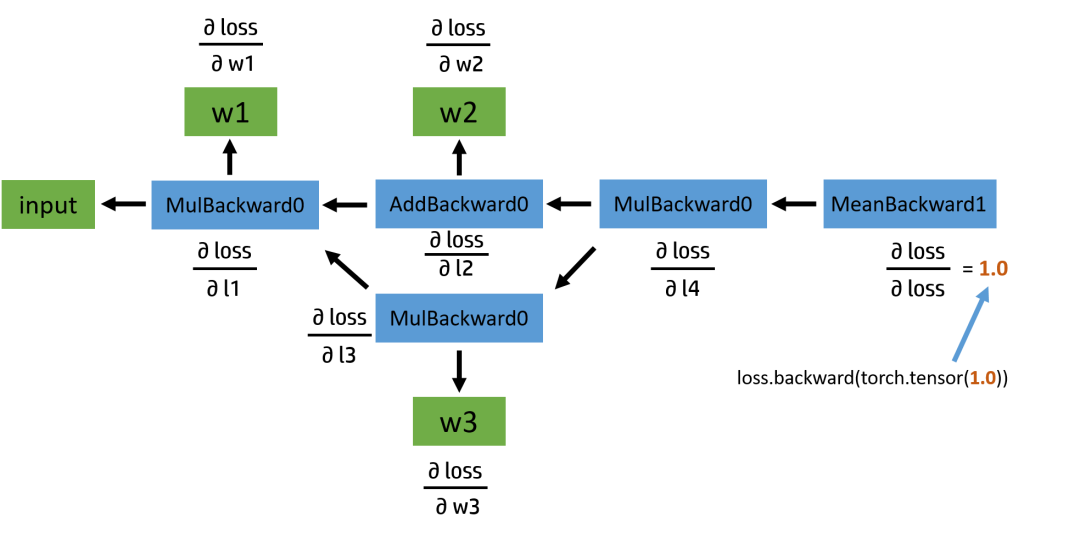
圖2:反向計(jì)算圖
反向圖也比較簡(jiǎn)單,從?loss?這個(gè)變量開(kāi)始,通過(guò)鏈?zhǔn)椒▌t,依次計(jì)算出各部分的導(dǎo)數(shù)。說(shuō)到這里,我們不妨先自己手動(dòng)推導(dǎo)一下求導(dǎo)的結(jié)果,再與程序運(yùn)行結(jié)果作對(duì)比。如果對(duì)這部分不感興趣的讀者,可以直接跳過(guò)。
再擺一下公式:
input = [1.0, 1.0, 1.0, 1.0]
w1 = [2.0, 2.0, 2.0, 2.0]
w2 = [3.0, 3.0, 3.0, 3.0]
w3 = [4.0, 4.0, 4.0, 4.0]
l1 = input x w1 = [2.0, 2.0, 2.0, 2.0]
l2 = l1 + w2 = [5.0, 5.0, 5.0, 5.0]
l3 = l1 x w3 = [8.0, 8.0, 8.0, 8.0]
l4 = l2 x l3 = [40.0, 40.0, 40.0, 40.0]
loss = mean(l4) = 40.0
首先??, 所以??對(duì)??的偏導(dǎo)分別為??;
接著??, 同時(shí)??;
現(xiàn)在看??對(duì)它的兩個(gè)變量的偏導(dǎo):??,
因此??, 其和為 10 ;
同理,再看一下求??導(dǎo)數(shù)的過(guò)程:
?,其和為 8。
其他的導(dǎo)數(shù)計(jì)算基本上都類似,因?yàn)檫^(guò)程太多,這里就不全寫(xiě)出來(lái)了,如果有興趣的話大家不妨自己繼續(xù)算一下。
接下來(lái)我們繼續(xù)運(yùn)行代碼,并檢查一下結(jié)果和自己算的是否一致:
loss.backward()
print(w1.grad,?w2.grad,?w3.grad)
#?tensor(28.)?tensor(8.)?tensor(10.)
print(l1.grad,?l2.grad,?l3.grad,?l4.grad,?loss.grad)
#?None?None?None?None?None
首先我們需要注意一下的是,在之前寫(xiě)程序的時(shí)候我們給定的?w?們都是一個(gè)常數(shù),利用了廣播的機(jī)制實(shí)現(xiàn)和常數(shù)和矩陣的加法乘法,比如?w2 + l1,實(shí)際上我們的程序會(huì)自動(dòng)把?w2?擴(kuò)展成 [[3.0, 3.0], [3.0, 3.0]],和?l1?的形狀一樣之后,再進(jìn)行加法計(jì)算,計(jì)算的導(dǎo)數(shù)結(jié)果實(shí)際上為 [[2.0, 2.0], [2.0, 2.0]],為了對(duì)應(yīng)常數(shù)輸入,所以最后?w2?的梯度返回為矩陣之和 8 。另外還有一個(gè)問(wèn)題,雖然?w?開(kāi)頭的那些和我們的計(jì)算結(jié)果相符,但是為什么?l1,l2,l3,甚至其他的部分的求導(dǎo)結(jié)果都為空呢?想要解答這個(gè)問(wèn)題,我們得明白什么是葉子張量。
葉子張量
對(duì)于任意一個(gè)張量來(lái)說(shuō),我們可以用?tensor.is_leaf?來(lái)判斷它是否是葉子張量(leaf tensor)。在反向傳播過(guò)程中,只有?is_leaf=True?的時(shí)候,需要求導(dǎo)的張量的導(dǎo)數(shù)結(jié)果才會(huì)被最后保留下來(lái)。
對(duì)于?requires_grad=False?的 tensor 來(lái)說(shuō),我們約定俗成地把它們歸為葉子張量。但其實(shí)無(wú)論如何劃分都沒(méi)有影響,因?yàn)閺埩康?is_leaf?屬性只有在需要求導(dǎo)的時(shí)候才有意義。
我們真正需要注意的是當(dāng)?requires_grad=True?的時(shí)候,如何判斷是否是葉子張量:當(dāng)這個(gè) tensor 是用戶創(chuàng)建的時(shí)候,它是一個(gè)葉子節(jié)點(diǎn),當(dāng)這個(gè) tensor 是由其他運(yùn)算操作產(chǎn)生的時(shí)候,它就不是一個(gè)葉子節(jié)點(diǎn)。我們來(lái)看個(gè)例子:
a?=?torch.ones([2,?2],?requires_grad=True)
print(a.is_leaf)
#?True
b?=?a?+?2
print(b.is_leaf)
#?False
#?因?yàn)?b?不是用戶創(chuàng)建的,是通過(guò)計(jì)算生成的
這時(shí)有同學(xué)可能會(huì)問(wèn)了,為什么要搞出這么個(gè)葉子張量的概念出來(lái)?原因是為了節(jié)省內(nèi)存(或顯存)。我們來(lái)想一下,那些非葉子結(jié)點(diǎn),是通過(guò)用戶所定義的葉子節(jié)點(diǎn)的一系列運(yùn)算生成的,也就是這些非葉子節(jié)點(diǎn)都是中間變量,一般情況下,用戶不會(huì)去使用這些中間變量的導(dǎo)數(shù),所以為了節(jié)省內(nèi)存,它們?cè)谟猛曛缶捅会尫帕恕?/p>
我們回頭看一下之前的反向傳播計(jì)算圖,在圖中的葉子節(jié)點(diǎn)我用綠色標(biāo)出了。可以看出來(lái),被叫做葉子,可能是因?yàn)橛坞x在主干之外,沒(méi)有子節(jié)點(diǎn),因?yàn)樗鼈兌际潜挥脩魟?chuàng)建的,不是通過(guò)其他節(jié)點(diǎn)生成。對(duì)于葉子節(jié)點(diǎn)來(lái)說(shuō),它們的?grad_fn?屬性都為空;而對(duì)于非葉子結(jié)點(diǎn)來(lái)說(shuō),因?yàn)樗鼈兪峭ㄟ^(guò)一些操作生成的,所以它們的?grad_fn?不為空。
我們有辦法保留中間變量的導(dǎo)數(shù)嗎?當(dāng)然有,通過(guò)使用?tensor.retain_grad()?就可以:
#?和前邊一樣
#?...
loss?=?l4.mean()
l1.retain_grad()
l4.retain_grad()
loss.retain_grad()
loss.backward()
print(loss.grad)
#?tensor(1.)
print(l4.grad)
#?tensor([[0.2500,?0.2500],
#?????????[0.2500,?0.2500]])
print(l1.grad)
#?tensor([[7.,?7.],
#?????????[7.,?7.]])
如果我們只是想進(jìn)行 debug,只需要輸出中間變量的導(dǎo)數(shù)信息,而不需要保存它們,我們還可以使用?tensor.register_hook,例子如下:
#?和前邊一樣
#?...
loss?=?l4.mean()
l1.register_hook(lambda?grad:?print('l1?grad:?',?grad))
l4.register_hook(lambda?grad:?print('l4?grad:?',?grad))
loss.register_hook(lambda?grad:?print('loss?grad:?',?grad))
loss.backward()
#?loss?grad:??tensor(1.)
#?l4?grad:??tensor([[0.2500,?0.2500],
#?????????[0.2500,?0.2500]])
#?l1?grad:??tensor([[7.,?7.],
#?????????[7.,?7.]])
print(loss.grad)
#?None
#?loss?的?grad?在?print?完之后就被清除掉了
這個(gè)函數(shù)的功能遠(yuǎn)遠(yuǎn)不止打印導(dǎo)數(shù)信息用以 debug,但是一般很少用,所以這里就不擴(kuò)展了,更多請(qǐng)參考知乎提問(wèn):pytorch中的鉤子(Hook)有何作用?
到此為止,我們已經(jīng)討論完了這個(gè)實(shí)例中的正向傳播和反向傳播的有關(guān)內(nèi)容了。回過(guò)頭來(lái)看, input 其實(shí)很像神經(jīng)網(wǎng)絡(luò)輸入的圖像,w1, w2, w3 則類似卷積核的參數(shù),而 l1, l2, l3, l4 可以表示4個(gè)卷積層輸出,如果我們把節(jié)點(diǎn)上的加法乘法換成卷積操作的話。實(shí)際上這個(gè)簡(jiǎn)單的模型,很像我們平時(shí)的神經(jīng)網(wǎng)絡(luò)的簡(jiǎn)化版,通過(guò)這個(gè)例子,相信大家多少也能對(duì)神經(jīng)網(wǎng)絡(luò)的正向和反向傳播過(guò)程有個(gè)大致的了解了吧。
inplace 操作
現(xiàn)在我們來(lái)看一下本篇的重點(diǎn),inplace operation。可以說(shuō),我們求導(dǎo)時(shí)候大部分的 bug,都出在使用了 inplace 操作上。現(xiàn)在我們以 PyTorch 不同的報(bào)錯(cuò)信息作為驅(qū)動(dòng),來(lái)講一講 inplace 操作吧。第一個(gè)報(bào)錯(cuò)信息:
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: balabala...
不少人可能會(huì)感到很熟悉,沒(méi)錯(cuò),我就是其中之一。之前寫(xiě)代碼的時(shí)候竟經(jīng)常報(bào)這個(gè)錯(cuò),原因是對(duì) inplace 操作不了解。要搞清楚為什么會(huì)報(bào)錯(cuò),我們先來(lái)了解一下什么是 inplace 操作:inplace 指的是在不更改變量的內(nèi)存地址的情況下,直接修改變量的值。我們來(lái)看兩種情況,大家覺(jué)得這兩種情況哪個(gè)是 inplace 操作,哪個(gè)不是?或者兩個(gè)都是 inplace?
#?情景?1
a?=?a.exp()
#?情景?2
a[0]?=?10
答案是:情景1不是 inplace,類似 Python 中的?i=i+1, 而情景2是 inplace 操作,類似?i+=1。依稀記得當(dāng)時(shí)做機(jī)器學(xué)習(xí)的大作業(yè),很多人都被其中一個(gè)?i+=1?和?i=i+1?問(wèn)題給坑了好長(zhǎng)時(shí)間。那我們來(lái)實(shí)際測(cè)試一下:
#?我們要用到?id()?這個(gè)函數(shù),其返回值是對(duì)象的內(nèi)存地址
#?情景?1
a?=?torch.tensor([3.0,?1.0])
print(id(a))?#?2112716404344
a?=?a.exp()
print(id(a))?#?2112715008904
#?在這個(gè)過(guò)程中?a.exp()?生成了一個(gè)新的對(duì)象,然后再讓?a
#?指向它的地址,所以這不是個(gè)?inplace?操作
#?情景?2
a?=?torch.tensor([3.0,?1.0])
print(id(a))?#?2112716403840
a[0]?=?10
print(id(a),?a)?#?2112716403840?tensor([10.,??1.])
#?inplace?操作,內(nèi)存地址沒(méi)變
PyTorch 是怎么檢測(cè) tensor 發(fā)生了 inplace 操作呢?答案是通過(guò)?tensor._version?來(lái)檢測(cè)的。我們還是來(lái)看個(gè)例子:
a?=?torch.tensor([1.0,?3.0],?requires_grad=True)
b?=?a?+?2
print(b._version)?#?0
loss?=?(b?*?b).mean()
b[0]?=?1000.0
print(b._version)?#?1
loss.backward()
#?RuntimeError:?one?of?the?variables?needed?for?gradient?computation?has?been?modified?by?an?inplace?operation?...
每次 tensor 在進(jìn)行 inplace 操作時(shí),變量?_version?就會(huì)加1,其初始值為0。在正向傳播過(guò)程中,求導(dǎo)系統(tǒng)記錄的?b?的 version 是0,但是在進(jìn)行反向傳播的過(guò)程中,求導(dǎo)系統(tǒng)發(fā)現(xiàn)?b?的 version 變成1了,所以就會(huì)報(bào)錯(cuò)了。但是還有一種特殊情況不會(huì)報(bào)錯(cuò),就是反向傳播求導(dǎo)的時(shí)候如果沒(méi)用到?b?的值(比如?y=x+1, y 關(guān)于 x 的導(dǎo)數(shù)是1,和 x 無(wú)關(guān)),自然就不會(huì)去對(duì)比?b?前后的 version 了,所以不會(huì)報(bào)錯(cuò)。
上邊我們所說(shuō)的情況是針對(duì)非葉子節(jié)點(diǎn)的,對(duì)于?requires_grad=True?的葉子節(jié)點(diǎn)來(lái)說(shuō),要求更加嚴(yán)格了,甚至在葉子節(jié)點(diǎn)被使用之前修改它的值都不行。我們來(lái)看一個(gè)報(bào)錯(cuò)信息:
RuntimeError: leaf variable has been moved into the graph interior
這個(gè)意思通俗一點(diǎn)說(shuō)就是你的一頓 inplace 操作把一個(gè)葉子節(jié)點(diǎn)變成了非葉子節(jié)點(diǎn)了。我們知道,非葉子節(jié)點(diǎn)的導(dǎo)數(shù)在默認(rèn)情況下是不會(huì)被保存的,這樣就會(huì)出問(wèn)題了。舉個(gè)小例子:
a?=?torch.tensor([10.,?5.,?2.,?3.],?requires_grad=True)
print(a,?a.is_leaf)
#?tensor([10.,??5.,??2.,??3.],?requires_grad=True)?True
a[:]?=?0
print(a,?a.is_leaf)
#?tensor([0.,?0.,?0.,?0.],?grad_fn=)?False
loss?=?(a*a).mean()
loss.backward()
#?RuntimeError:?leaf?variable?has?been?moved?into?the?graph?interior
我們看到,在進(jìn)行對(duì)?a?的重新 inplace 賦值之后,表示了 a 是通過(guò) copy operation 生成的,grad_fn?都有了,所以自然而然不是葉子節(jié)點(diǎn)了。本來(lái)是該有導(dǎo)數(shù)值保留的變量,現(xiàn)在成了導(dǎo)數(shù)會(huì)被自動(dòng)釋放的中間變量了,所以 PyTorch 就給你報(bào)錯(cuò)了。還有另外一種情況:
a?=?torch.tensor([10.,?5.,?2.,?3.],?requires_grad=True)
a.add_(10.)?#?或者?a?+=?10.
#?RuntimeError:?a?leaf?Variable?that?requires?grad?has?been?used?in?an?in-place?operation.
這個(gè)更厲害了,不等到你調(diào)用 backward,只要你對(duì)需要求導(dǎo)的葉子張量使用了這些操作,馬上就會(huì)報(bào)錯(cuò)。那是不是需要求導(dǎo)的葉子節(jié)點(diǎn)一旦被初始化賦值之后,就不能修改它們的值了呢?我們?nèi)绻谀撤N情況下需要重新對(duì)葉子變量賦值該怎么辦呢?有辦法!
#?方法一
a?=?torch.tensor([10.,?5.,?2.,?3.],?requires_grad=True)
print(a,?a.is_leaf,?id(a))
#?tensor([10.,??5.,??2.,??3.],?requires_grad=True)?True?2501274822696
a.data.fill_(10.)
#?或者?a.detach().fill_(10.)
print(a,?a.is_leaf,?id(a))
#?tensor([10.,?10.,?10.,?10.],?requires_grad=True)?True?2501274822696
loss?=?(a*a).mean()
loss.backward()
print(a.grad)
#?tensor([5.,?5.,?5.,?5.])
#?方法二
a?=?torch.tensor([10.,?5.,?2.,?3.],?requires_grad=True)
print(a,?a.is_leaf)
#?tensor([10.,??5.,??2.,??3.],?requires_grad=True)?True
with?torch.no_grad():
????a[:]?=?10.
print(a,?a.is_leaf)
#?tensor([10.,?10.,?10.,?10.],?requires_grad=True)?True
loss?=?(a*a).mean()
loss.backward()
print(a.grad)
#?tensor([5.,?5.,?5.,?5.])
修改的方法有很多種,核心就是修改那個(gè)和變量共享內(nèi)存,但?requires_grad=False?的版本的值,比如通過(guò)?tensor.data?或者?tensor.detach()(至于這二者更詳細(xì)的介紹與比較,歡迎參照我上一篇文章的第四部分)。我們需要注意的是,要在變量被使用之前修改,不然等計(jì)算完之后再修改,還會(huì)造成求導(dǎo)上的問(wèn)題,會(huì)報(bào)錯(cuò)的。
為什么 PyTorch 的求導(dǎo)不支持絕大部分 inplace 操作呢?從上邊我們也看出來(lái)了,因?yàn)檎娴暮?tricky。比如有的時(shí)候在一個(gè)變量已經(jīng)參與了正向傳播的計(jì)算,之后它的值被修改了,在做反向傳播的時(shí)候如果還需要這個(gè)變量的值的話,我們肯定不能用那個(gè)后來(lái)修改的值吧,但沒(méi)修改之前的原始值已經(jīng)被釋放掉了,我們?cè)趺崔k?一種可行的辦法就是我們?cè)?Function 做 forward 的時(shí)候每次都開(kāi)辟一片空間儲(chǔ)存當(dāng)時(shí)輸入變量的值,這樣無(wú)論之后它們?cè)趺葱薷模疾粫?huì)影響了,反正我們有備份在存著。但這樣有什么問(wèn)題?這樣會(huì)導(dǎo)致內(nèi)存(或顯存)使用量大大增加。因?yàn)槲覀儾淮_定哪個(gè)變量可能之后會(huì)做 inplace 操作,所以我們每個(gè)變量在做完 forward 之后都要儲(chǔ)存一個(gè)備份,成本太高了。除此之外,inplace operation 還可能造成很多其他求導(dǎo)上的問(wèn)題。
總之,我們?cè)趯?shí)際寫(xiě)代碼的過(guò)程中,沒(méi)有必須要用 inplace operation 的情況,而且支持它會(huì)帶來(lái)很大的性能上的犧牲,所以 PyTorch 不推薦使用 inplace 操作,當(dāng)求導(dǎo)過(guò)程中發(fā)現(xiàn)有 inplace 操作影響求導(dǎo)正確性的時(shí)候,會(huì)采用報(bào)錯(cuò)的方式提醒。但這句話反過(guò)來(lái)說(shuō)就是,因?yàn)橹灰?inplace 操作不當(dāng)就會(huì)報(bào)錯(cuò),所以如果我們?cè)诔绦蛑惺褂昧?inplace 操作卻沒(méi)報(bào)錯(cuò),那么說(shuō)明我們最后求導(dǎo)的結(jié)果是正確的,沒(méi)問(wèn)題的。這就是我們常聽(tīng)見(jiàn)的沒(méi)報(bào)錯(cuò)就沒(méi)有問(wèn)題。
動(dòng)態(tài)圖,靜態(tài)圖
可能大家都聽(tīng)說(shuō)過(guò),PyTorch 使用的是動(dòng)態(tài)圖(Dynamic Computational Graphs)的方式,而 TensorFlow 使用的是靜態(tài)圖(Static Computational Graphs)。所以二者究竟有什么區(qū)別呢,我們本節(jié)來(lái)就來(lái)討論這個(gè)事情。
所謂動(dòng)態(tài)圖,就是每次當(dāng)我們搭建完一個(gè)計(jì)算圖,然后在反向傳播結(jié)束之后,整個(gè)計(jì)算圖就在內(nèi)存中被釋放了。如果想再次使用的話,必須從頭再搭一遍,參見(jiàn)下邊這個(gè)例子。而以 TensorFlow 為代表的靜態(tài)圖,每次都先設(shè)計(jì)好計(jì)算圖,需要的時(shí)候?qū)嵗@個(gè)圖,然后送入各種輸入,重復(fù)使用,只有當(dāng)會(huì)話結(jié)束的時(shí)候創(chuàng)建的圖才會(huì)被釋放(不知道這里我對(duì) tf.Session 的理解對(duì)不對(duì),如果有錯(cuò)誤希望大佬們能指正一下),就像我們之前舉的那個(gè)水管的例子一樣,設(shè)計(jì)好水管布局之后,需要用的時(shí)候就開(kāi)始搭,搭好了就往入口加水,什么時(shí)候不需要了,再把管道都給拆了。
#?這是一個(gè)關(guān)于 PyTorch 是動(dòng)態(tài)圖的例子:
a?=?torch.tensor([3.0,?1.0],?requires_grad=True)
b?=?a?*?a
loss?=?b.mean()
loss.backward()?#?正常
loss.backward()?#?RuntimeError
#?第二次:從頭再來(lái)一遍
a?=?torch.tensor([3.0,?1.0],?requires_grad=True)
b?=?a?*?a
loss?=?b.mean()
loss.backward()?#?正常
從描述中我們可以看到,理論上來(lái)說(shuō),靜態(tài)圖在效率上比動(dòng)態(tài)圖要高。因?yàn)槭紫龋o態(tài)圖只用構(gòu)建一次,然后之后重復(fù)使用就可以了;其次靜態(tài)圖因?yàn)槭枪潭ú恍枰淖兊模栽谠O(shè)計(jì)完了計(jì)算圖之后,可以進(jìn)一步的優(yōu)化,比如可以將用戶原本定義的 Conv 層和 ReLU 層合并成 ConvReLU 層,提高效率。
但是,深度學(xué)習(xí)框架的速度不僅僅取決于圖的類型,還很其他很多因素,比如底層代碼質(zhì)量,所使用的底層 BLAS 庫(kù)等等等都有關(guān)。從實(shí)際測(cè)試結(jié)果來(lái)說(shuō),至少在主流的模型的訓(xùn)練時(shí)間上,PyTorch 有著至少不遜于靜態(tài)圖框架 Caffe,TensorFlow 的表現(xiàn)。具體對(duì)比數(shù)據(jù)可以參考:
https://github.com/ilkarman/DeepLearningFrameworks
大家不要急著糾正我,我知道,我現(xiàn)在就說(shuō):當(dāng)然,在 9102 年的今天,動(dòng)態(tài)圖和靜態(tài)圖直接的界限已經(jīng)開(kāi)始慢慢模糊。PyTorch 模型轉(zhuǎn)成 Caffe 模型越來(lái)越方便,而 TensorFlow 也加入了一些動(dòng)態(tài)圖機(jī)制。
除了動(dòng)態(tài)圖之外,PyTorch 還有一個(gè)特性,叫 eager execution。意思就是當(dāng)遇到 tensor 計(jì)算的時(shí)候,馬上就回去執(zhí)行計(jì)算,也就是,實(shí)際上 PyTorch 根本不會(huì)去構(gòu)建正向計(jì)算圖,而是遇到操作就執(zhí)行。真正意義上的正向計(jì)算圖是把所有的操作都添加完,構(gòu)建好了之后,再運(yùn)行神經(jīng)網(wǎng)絡(luò)的正向傳播。
正是因?yàn)?PyTorch 的兩大特性:動(dòng)態(tài)圖和 eager execution,所以它用起來(lái)才這么順手,簡(jiǎn)直就和寫(xiě) Python 程序一樣舒服,debug 也非常方便。除此之外,我們從之前的描述也可以看出,PyTorch 十分注重占用內(nèi)存(或顯存)大小,沒(méi)有用的空間釋放很及時(shí),可以很有效地利用有限的內(nèi)存。
總結(jié)
本篇文章主要討論了 PyTorch 的 Autograd 機(jī)制和使用 inplace 操作不當(dāng)可能會(huì)導(dǎo)致的各種報(bào)錯(cuò)。在實(shí)際寫(xiě)代碼的過(guò)程中,涉及需要求導(dǎo)的部分,不建議大家使用 inplace 操作。除此之外我們還比較了動(dòng)態(tài)圖和靜態(tài)圖框架,PyTorch 作為動(dòng)態(tài)圖框架的代表之一,對(duì)初學(xué)者非常友好,而且運(yùn)行速度上不遜于靜態(tài)圖框架,再加上現(xiàn)在通過(guò) ONNX 轉(zhuǎn)換為其他框架的模型用以部署也越來(lái)越方便,我覺(jué)得是一個(gè)非常稱手的深度學(xué)習(xí)工具。
最后,感謝閱讀,希望大家讀完之后有所收獲。
參考資料
猜您喜歡:
附下載 |?《可解釋的機(jī)器學(xué)習(xí)》中文版
附下載 |《TensorFlow 2.0 深度學(xué)習(xí)算法實(shí)戰(zhàn)》
附下載 |《計(jì)算機(jī)視覺(jué)中的數(shù)學(xué)方法》分享
《基于深度學(xué)習(xí)的表面缺陷檢測(cè)方法綜述》
《基于深度神經(jīng)網(wǎng)絡(luò)的少樣本學(xué)習(xí)綜述》