
LZ77壓縮算法原理剖析
點(diǎn)擊上方“君子黎”,選擇“置頂/星標(biāo)公眾號”
干貨福利,第一時間送達(dá)!
1. 數(shù)據(jù)壓縮
數(shù)據(jù)壓縮(Data Compression),簡稱為壓縮,通常也被稱為編碼(coding)。它是信息論的一個分支,其主要目的是使要傳輸?shù)臄?shù)據(jù)量盡量最小化。從根本上講,它在保證能夠包含原有相同信息的前提下,使用比原始表示更少的位來對信息進(jìn)行重新編碼。它通過對數(shù)據(jù)進(jìn)行編碼、重組或修改以減少其大小的一個過程。
數(shù)據(jù)壓縮在數(shù)據(jù)存儲和數(shù)據(jù)傳輸領(lǐng)域有著重要的應(yīng)用。尤其是在Internet高速發(fā)展的今天,文件大小和網(wǎng)絡(luò)傳輸速度之間的微妙關(guān)系變得更加明顯。越來越多的企業(yè)和應(yīng)用需要存儲大量的數(shù)據(jù)文件,同時網(wǎng)絡(luò)交互、通信傳輸?shù)臄?shù)據(jù)報文也愈加頻繁。更大的數(shù)據(jù)和帶寬意味著需要更高的成本與代價,這無疑與人們追求更高利益化的理念相違背。而通過壓縮要存儲或傳輸?shù)臄?shù)據(jù)可以極大地降低存儲或通訊成本。對將要發(fā)送的數(shù)據(jù)壓縮后,體積變小了,隨之而來的是增加了通信信道的容量;而在數(shù)據(jù)變小之后,相同容量的存儲介質(zhì)間接地可以存儲更多的數(shù)據(jù)量。同時,更小的數(shù)據(jù),通過利用 存儲層次結(jié)構(gòu) 規(guī)則,可以將其放在計層次更高、速度更快的存儲層級,從而減少系統(tǒng)I/O通道的負(fù)載與壓力。
2. 壓縮算法
盡管壓縮算法類型十分繁多,但是從本質(zhì)上而言,可以歸納為兩大類,分別是:無損壓縮(Lossless Compression)和有損壓縮(Lossy Compression)。無損壓縮算法可以反轉(zhuǎn)以恢復(fù)到原始數(shù)據(jù),所以它是精確的;而有損算法在反轉(zhuǎn)時候會丟失部分細(xì)節(jié)或引入一些小錯誤,所以它不是精確的。
2.1 無損壓縮
無損壓縮算法的基本原理是,對于任何一個非隨機(jī)文件都將包含重復(fù)的信息,而這些信息是可以使用統(tǒng)計建模技術(shù)進(jìn)行壓縮,從而確定字符或短語出現(xiàn)的概念進(jìn)行壓縮。然后這些統(tǒng)計模型可用于根據(jù)特定字符或短語出現(xiàn)的概率生成代碼,并將最短的代碼分配給最常見的數(shù)據(jù),從而使大量文本中大量冗余的數(shù)據(jù)被移除。這些技術(shù)包括熵編碼、游標(biāo)編碼和字典進(jìn)行壓縮。
常用的無損壓縮算法程序有:Zip(使用于Windows系統(tǒng)上)、gzip(工作于類UNIX系統(tǒng)上)等。
2.2 有損壓縮
有損壓縮算法通常通過刪除需要大量數(shù)據(jù)以完全保真度的小細(xì)節(jié)來減少文件大小。由于該算法刪除了許多必要的數(shù)據(jù),所以是不能恢復(fù)到原始文件的,顯然,它實(shí)現(xiàn)了非常高的壓縮比。最常用于有損壓縮算法的場景是圖像和音視頻數(shù)據(jù)。
3. LZ算法
LZ算法是由Abraham Lempel和Jacob Ziv于1977年發(fā)明的算法,因此,該LZ算法也稱為LZ77算法(或LZ1)。此算法是第一個使用字典壓縮數(shù)據(jù)的算法。更具體點(diǎn)地說,LZ77算法使用了一個動態(tài)字典(Dynamic Dictionary),通常也稱為“滑動窗口(Sliding Window)。” 在第二年中,即1978年, Abraham Lempel和Jacob Ziv在基于LZ77算法的基礎(chǔ)上,發(fā)布了LZ78算法(也稱為LZ2),該算法同樣使用了字典,但是與LZ77不同的是,LZ78算法取消了動態(tài)字典生成;反之,它是根據(jù)解析輸入數(shù)據(jù)而生成靜態(tài)字典。
LZ算法是一種無損壓縮算法。在LZ77和LZ78的基礎(chǔ)上,衍生出了許多的無損壓縮算法,然而許多算法自面世以來,沒隔多久時間就消失了,只有少數(shù)的算法得到一直延續(xù)到今天且在廣泛使用。如下圖所示,該圖詳細(xì)地描述了無損壓縮算法的層次結(jié)構(gòu),以及分別在LZ77和LZ78算法版本上所衍生出來的其他算法版本。

從圖中可以看到基于LZ77的算法變體遠(yuǎn)多于LZ78。這是因為從LZ78上變體出來的LZW算法申請了專利,并開始起訴提供該算法的軟件服務(wù)商,基于專利保護(hù)的緣故,導(dǎo)致該算法的衍生版本不如LZ77多。
3.1 LZ算法的原理
當(dāng)使用LZ算法來對一個符號序列進(jìn)行壓縮時候,它采用如下的示意結(jié)構(gòu)。
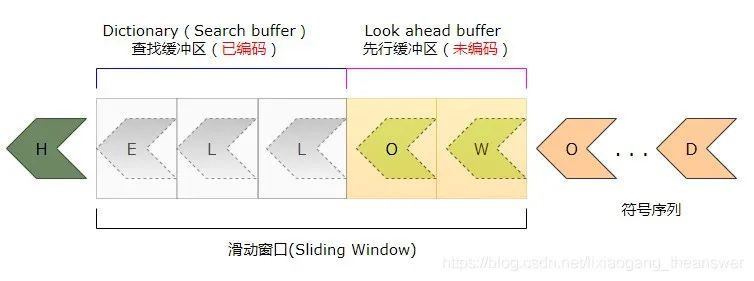
該結(jié)構(gòu)共包含了2個部分,分別是:查找緩沖區(qū)(Search buffer),也稱字典(所謂字典,就是已編碼好的部分)。先行緩沖區(qū)(Look ahead buffer),包括即將進(jìn)行編碼序列的一部分。這兩個部分組成了這個所謂的“滑動窗口(Sliding Window)。”
由于緩沖區(qū)具有固定的長度,所以,當(dāng)算法(編碼器)在運(yùn)行時候,它看起來像在文件中“滑動”,所以這個緩沖區(qū)被稱為“滑動窗口”。而該技術(shù)也被稱為“滑動窗口技術(shù)”。
查找緩沖區(qū)和先行緩沖區(qū)都有自己的固定大小,比如上圖中,其查找緩沖區(qū)大小是3字節(jié),而先行緩沖區(qū)是2字節(jié)。當(dāng)然,實(shí)際中肯定比這個大許多,這里只是為了方便舉例說明。對于LZ算法,滑動窗口的典型大小是4096字節(jié)。PostgreSQL數(shù)據(jù)庫中的TOAST技術(shù),也采用了LZ無損壓縮算法,其窗口大小也是4096字節(jié)。
//滑動窗口的固定大小 4096字節(jié)
#define PGLZ_HISTORY_SIZE 4096
3.2 LZ編碼過程
LZ壓縮算法使用一個三元組<o, l, c>來對字符串序列進(jìn)行編碼。其中o是offset(偏移量)的縮寫,l是length(長度)的縮寫,而c則是代表先行緩沖區(qū)中位于匹配項之后的字符(character)。也有的文獻(xiàn)資料稱之為碼字(Code Word)。
現(xiàn)在來詳細(xì)說明一個三元組<o, l, c>中這幾個數(shù)字對應(yīng)的實(shí)際含義。這里待編碼的字符串序列是“HELLOWORLD”。假定LZ窗口大小是5字節(jié),其中查找緩沖區(qū)是3字節(jié),而先行緩沖區(qū)為2字節(jié)。由于窗口大小是固定的,所以同一時刻(當(dāng)然,一開始時候,查找緩沖區(qū)沒有字符),查找緩沖區(qū)中最多有3個字節(jié)數(shù)據(jù),先行緩沖區(qū)最多容納2字節(jié)數(shù)據(jù)。
假如現(xiàn)在已經(jīng)對字符‘H’、'E'、'L'、'L'、'O'、'W'這6字符編碼完成,其中'L'、'O'、'W'字符位于查找緩沖區(qū)中,而先行緩沖區(qū)中的字符是'O'、'R'。如下圖所示:
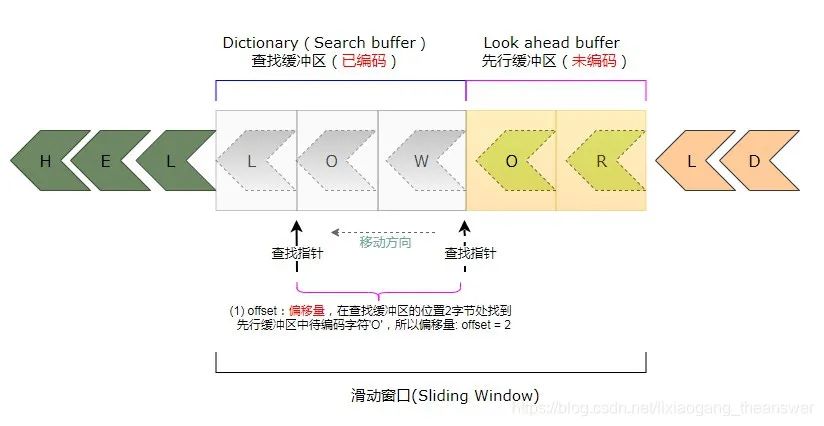
編碼器將會通過“查找指針”在查找緩沖區(qū)中不斷移動(移動方向如上圖黑色箭頭所示),來判斷是否有字符和先行緩沖區(qū)中的(第一個)待編碼字符相同。這里先行緩沖區(qū)中的待編碼字符是‘O’。通過判斷可知,在查找緩沖區(qū)中的第2個位置處有一個字符‘O’和先行緩沖區(qū)中的第一個符號相同,該(查找)指針與先行緩沖區(qū)的距離稱為“偏移量(offset)”,這里偏移量是2。
此時,LZ編碼器會繼續(xù)查看并判斷查找緩沖區(qū)中該“查找指針”位置之后的字符,是否與先行緩沖區(qū)中第一個字符之后的字符連續(xù)相匹配。在查找緩沖區(qū)中與先行緩沖區(qū)中連續(xù)相匹配的字符的數(shù)量,我們稱之為“匹配長度”。從上圖可以看到位于查找緩沖區(qū)中的查找指針后面的一個字符是‘W’,而先行緩沖區(qū)中第一個待編碼字符之后的字符是‘R’,不相匹配。所以這里的匹配長度length等于1。
先行緩沖區(qū)中匹配字符之后的第一個字符是‘R’,所以可以得到一個三元組:<2, 1, C(R)>。待字符‘O’編碼好之后,滑動窗口移動一個字符(字節(jié))。此時的查找緩沖區(qū)與先行緩沖區(qū)中的內(nèi)容如下圖所示:

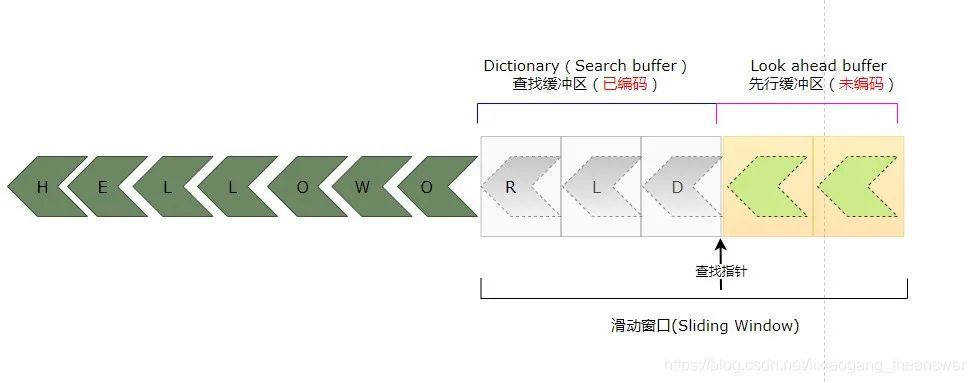
LZ編碼器繼續(xù)對先行緩沖區(qū)中的字符‘R’進(jìn)行編碼,重復(fù)上面的邏輯判斷過程。首先在查找緩沖區(qū)(Search Buffer)中通過移動查找指針,判斷是否有字符和先行緩沖區(qū)中的第一個字符(待編碼)相等,若有,則繼續(xù)判斷是否有連續(xù)的字符和先行緩沖區(qū)的字符相匹配,通過上圖可以看到,查找緩沖區(qū)中沒有與字符‘R’相等的符號。所以偏移量為0,其長度也為0,字符編碼是‘R’。所以得出其三元組為:<0, 0, C(L)>。得到如下圖所示的編碼。

最后,還剩下字符‘D’未編碼,通過前面的步驟可知,查找緩沖區(qū)中沒有與之匹配的字符,所以該三元組是<0, 0, C(D)>。最終完成對序列字符“HELLOWORLD”的編碼操作,如下圖所示:
 對于LZ編碼,其整個壓縮過程可以劃分為以下三個步驟:
對于LZ編碼,其整個壓縮過程可以劃分為以下三個步驟:
(1) 用搜索緩沖區(qū)中可用的模式查找從當(dāng)前位置開始的字符串的最長匹配。
(2) 輸出一個三元組<o, l, c>;
o:偏移量,表示為了找到匹配字符串的開始,我們需要向后移動的位置數(shù)。
l:表示匹配的長度。
c:字符,表示匹配后找到的字符。
(3) 向右移動查找指針 + 1。
3.3 LZ編碼過程中的三種可能性
通過上面對LZ編碼過程的描述,可以看出,編碼器使用LZ算法對一個符號序列進(jìn)行壓縮時候,可能會遇到以下幾種情形。
(1) 查找緩沖區(qū)里存在與先行緩沖區(qū)中待編碼的字符(即存在匹配項)。
(2) 查找緩沖區(qū)里沒有與先行緩沖區(qū)中待編碼字符匹配的字符。
(3) 查找緩沖區(qū)中有匹配字符串,且該字符串在先行緩沖區(qū)字符串中延伸。
前面(1)和(2)兩種情形好理解,即找到與未找到問題。對于第(3)項的理解,需要記住這樣一個事實(shí)。即對于LZ算法,僅要求匹配項的字符位置起點(diǎn)(即查找與先行緩沖區(qū)中的待編碼字符)位于查找緩沖區(qū)中,但是若匹配到先行緩沖區(qū)中的多個字符,則其終點(diǎn)可以延續(xù)到先行緩沖區(qū)中。借助這段話,再來理解情形(3),就相對容易許多。
3.4 LZ解碼過程
由于LZ算法是無損壓縮算法,這意味著我們能夠完全恢復(fù)原始的數(shù)據(jù),因此,我們不能從隨機(jī)的LZ三元組開始解壓縮。相反,我們必須得從初始的三元組開始解壓縮,因為LZ編碼的三元組是基于搜索緩沖區(qū)的。
假設(shè)我們已經(jīng)完成對字符‘H’、‘E’、‘L’、‘L’、‘O’、‘W’的編碼,如下圖所示。
注意,編碼與解碼過程中 其窗口(查找緩沖區(qū),先行緩沖區(qū))大小是固定的,否則,其解壓縮過程將會以失敗而告終。
現(xiàn)在依次對上面的三元組:<2, 1, C(R)>、<0, 0, C(L)>和<0, 0, C(D)>進(jìn)行解碼。
(1) 解碼<2, 1, C(R)>
由于其偏移量(offset)等于2,所以我們將查找指針(向左)移動兩位;而字符匹配的長度(length)是1,所以我們將查找指針?biāo)赶虻淖址麖?fù)制一個。其解碼過程如下圖所示:
該三元組解析完成之后,得到的窗口圖如下: (2) 解碼<0, 0, C(L)>
(2) 解碼<0, 0, C(L)>
由于偏移量(offset)等于0,且匹配字符長度為0,則表明在查找緩沖區(qū)中沒有與之匹配的內(nèi)容,且下一個字符是‘L’。所以則在已解碼的字符串后面增加一個字符‘L’,并將窗口移動一個字符。如下圖所示:
(3) 解碼<0, 0, C(D)>
和解碼<0, 0, C(L)>一樣,由于其偏移量和匹配長度都為0,所以其下一個字符是‘D’。則最終解碼(壓縮)得到的完整字符串是:HELLOWORLD。如下圖所示:

3.5 LZ算法實(shí)現(xiàn)
在github上有一份 LZ算法 的源碼實(shí)現(xiàn)。該算法中使用了二叉樹來作為編碼過程中的偏移量和長度等索引,以加快編碼、解碼的速度。針對這個LZ算法的源碼,后期將專門寫一篇文章來進(jìn)行分析、學(xué)習(xí)。
4. 數(shù)據(jù)壓縮優(yōu)缺點(diǎn)
沒有任何一件事物是完美的,數(shù)據(jù)壓縮亦是如此。既然有優(yōu)點(diǎn),肯定也有它的缺點(diǎn)所在。下面分別對數(shù)據(jù)壓縮的優(yōu)缺點(diǎn)進(jìn)行一個簡單的概述。
4.1 優(yōu)點(diǎn)
(1) 同一個數(shù)據(jù)文件,需要更少的磁盤空間。這意味著可以存儲更多的數(shù)據(jù)文件;
(2) 文件傳輸、讀寫速度更快。
4.2 缺點(diǎn)
(1) 增加了CPU的負(fù)載,對于一些較為復(fù)雜的壓縮算法,尤其如此。
(2) 增加了復(fù)雜性;
(3) 提高了傳輸誤差影響。
往期推薦
??分享、點(diǎn)贊、在看,給個3連擊唄!??