
linux服務(wù)性能問題排查及jvm調(diào)優(yōu)思路
只要業(yè)務(wù)邏輯代碼寫正確,處理好業(yè)務(wù)狀態(tài)在多線程的并發(fā)問題,很少會(huì)有調(diào)優(yōu)方面的需求。最多就是在性能監(jiān)控平臺(tái)發(fā)現(xiàn)某些接口的調(diào)用耗時(shí)偏高,然后再發(fā)現(xiàn)某一SQL或第三方接口執(zhí)行超時(shí)之類的。如果你是負(fù)責(zé)中間件或IM通訊相關(guān)項(xiàng)目開發(fā),或許就需要偏向CPU、磁盤、網(wǎng)絡(luò)及內(nèi)存方面的問題排查及調(diào)優(yōu)技能
CPU過高,怎么排查問題 linux內(nèi)存 磁盤IO 網(wǎng)絡(luò)IO java 應(yīng)用內(nèi)存泄漏和頻繁 GC java 線程問題排查 常用 jvm 啟動(dòng)參數(shù)調(diào)優(yōu)
linux CPU 過高,怎么排查問題
CPU 指標(biāo)解析
平均負(fù)載 平均負(fù)載等于邏輯 CPU 個(gè)數(shù),表示每個(gè) CPU 都恰好被充分利用。如果平均負(fù)載大于邏輯 CPU 個(gè)數(shù),則負(fù)載比較重 進(jìn)程上下文切換 無法獲取資源而導(dǎo)致的自愿上下文切換 被系統(tǒng)強(qiáng)制調(diào)度導(dǎo)致的非自愿上下文切換 CPU 使用率 用戶 CPU 使用率,包括用戶態(tài) CPU 使用率(user)和低優(yōu)先級(jí)用戶態(tài) CPU 使用率(nice),表示 CPU 在用戶態(tài)運(yùn)行的時(shí)間百分比。用戶 CPU 使用率高,通常說明有應(yīng)用程序比較繁忙 系統(tǒng) CPU 使用率,表示 CPU 在內(nèi)核態(tài)運(yùn)行的時(shí)間百分比(不包括中斷),系統(tǒng) CPU 使用率高,說明內(nèi)核比較繁忙 等待 I/O 的 CPU 使用率,通常也稱為 iowait,表示等待 I/O 的時(shí)間百分比。iowait 高,說明系統(tǒng)與硬件設(shè)備的 I/O 交互時(shí)間比較長 軟中斷和硬中斷的 CPU 使用率,分別表示內(nèi)核調(diào)用軟中斷處理程序、硬中斷處理程序的時(shí)間百分比。它們的使用率高,表明系統(tǒng)發(fā)生了大量的中斷
查看系統(tǒng)的平均負(fù)載
$?uptime
?10:54:52?up?1124?days,?16:31,??6?users,??load?average:?3.67,?2.13,?1.79
10:54:52 是當(dāng)前時(shí)間;up 1124 days, 16:31 是系統(tǒng)運(yùn)行時(shí)間;6 users 則是正在登錄用戶數(shù)。而最后三個(gè)數(shù)字依次是過去 1 分鐘、5 分鐘、15 分鐘的平均負(fù)載(Load Average)。平均負(fù)載是指單位時(shí)間內(nèi),系統(tǒng)處于可運(yùn)行狀態(tài)和不可中斷狀態(tài)的平均進(jìn)程數(shù) 當(dāng)平均負(fù)載高于 CPU 數(shù)量 70% 的時(shí)候,就應(yīng)該分析排查負(fù)載高的問題。一旦負(fù)載過高,就可能導(dǎo)致進(jìn)程響應(yīng)變慢,進(jìn)而影響服務(wù)的正常功能 平均負(fù)載與 CPU 使用率關(guān)系 CPU 密集型進(jìn)程,使用大量 CPU 會(huì)導(dǎo)致平均負(fù)載升高,此時(shí)這兩者是一致的 I/O 密集型進(jìn)程,等待 I/O 也會(huì)導(dǎo)致平均負(fù)載升高,但 CPU 使用率不一定很高 大量等待 CPU 的進(jìn)程調(diào)度也會(huì)導(dǎo)致平均負(fù)載升高,此時(shí)的 CPU 使用率也會(huì)比較高
CPU 上下文切換
進(jìn)程上下文切換: 進(jìn)程的運(yùn)行空間可以分為內(nèi)核空間和用戶空間,當(dāng)代碼發(fā)生系統(tǒng)調(diào)用時(shí)(訪問受限制的資源),CPU 會(huì)發(fā)生上下文切換,系統(tǒng)調(diào)用結(jié)束時(shí),CPU 則再從內(nèi)核空間換回用戶空間。一次系統(tǒng)調(diào)用,兩次 CPU 上下文切換 系統(tǒng)平時(shí)會(huì)按一定的策略調(diào)用進(jìn)程,會(huì)導(dǎo)致進(jìn)程上下文切換 進(jìn)程在阻塞等到訪問資源時(shí),也會(huì)發(fā)生上下文切換 進(jìn)程通過睡眠函數(shù)掛起,會(huì)發(fā)生上下文切換 當(dāng)有優(yōu)先級(jí)更高的進(jìn)程運(yùn)行時(shí),為了保證高優(yōu)先級(jí)進(jìn)程的運(yùn)行,當(dāng)前進(jìn)程會(huì)被掛起 線程上下文切換: 同一進(jìn)程里的線程,它們共享相同的虛擬內(nèi)存和全局變量資源,線程上下文切換時(shí),這些資源不變 線程自己的私有數(shù)據(jù),比如棧和寄存器等,需要在上下文切換時(shí)保存切換 中斷上下文切換: 為了快速響應(yīng)硬件的事件,中斷處理會(huì)打斷進(jìn)程的正常調(diào)度和執(zhí)行,轉(zhuǎn)而調(diào)用中斷處理程序,響應(yīng)設(shè)備事件
查看系統(tǒng)的上下文切換情況:
vmstat 和 pidstat。vmvmstat 可查看系統(tǒng)總體的指標(biāo),pidstat則詳細(xì)到每一個(gè)進(jìn)程服務(wù)的指標(biāo)
$?vmstat?2?1?
procs?--------memory---------?--swap--?--io---?-system--?----cpu-----?
r?b?swpd?free????buff???cache??si?so??bi?bo?in?cs?us?sy?id?wa?st?
1?0????0?3498472?315836?3819540?0?0???0??1??2??0??3??1??96?0??0
--------
cs(context?switch)是每秒上下文切換的次數(shù)
in(interrupt)則是每秒中斷的次數(shù)
r(Running?or?Runnable)是就緒隊(duì)列的長度,也就是正在運(yùn)行和等待?CPU?的進(jìn)程數(shù).當(dāng)這個(gè)值超過了CPU數(shù)目,就會(huì)出現(xiàn)CPU瓶頸
b(Blocked)則是處于不可中斷睡眠狀態(tài)的進(jìn)程數(shù)
#?pidstat?-w
Linux?3.10.0-862.el7.x86_64?(8f57ec39327b)??????07/11/2021??????_x86_64_????????(6?CPU)
06:43:23?PM???UID???????PID???cswch/s?nvcswch/s??Command
06:43:23?PM?????0?????????1??????0.00??????0.00??java
06:43:23?PM?????0???????102??????0.00??????0.00??bash
06:43:23?PM?????0???????150??????0.00??????0.00??pidstat
------各項(xiàng)指標(biāo)解析---------------------------
PID???????進(jìn)程id
Cswch/s???每秒主動(dòng)任務(wù)上下文切換數(shù)量
Nvcswch/s 每秒被動(dòng)任務(wù)上下文切換數(shù)量。大量進(jìn)程都在爭(zhēng)搶 CPU 時(shí),就容易發(fā)生非自愿上下文切換
Command???進(jìn)程執(zhí)行命令
怎么排查 CPU 過高問題
先使用 top 命令,查看系統(tǒng)相關(guān)指標(biāo)。如需要按某指標(biāo)排序則 使用 top -o 字段名如:top -o %CPU。-o可以指定排序字段,順序從大到小
#?top?-o?%MEM
top?-?18:20:27?up?26?days,??8:30,??2?users,??load?average:?0.04,?0.09,?0.13
Tasks:?168?total,???1?running,?167?sleeping,???0?stopped,???0?zombie
%Cpu(s):??0.3?us,??0.5?sy,??0.0?ni,?99.1?id,??0.0?wa,??0.0?hi,??0.1?si,??0.0?st
KiB?Mem:??32762356?total,?14675196?used,?18087160?free,??????884?buffers
KiB?Swap:??2103292?total,????????0?used,??2103292?free.??6580028?cached?Mem
PID?USER??????PR??NI????VIRT????RES????SHR?S??%CPU??%MEM?????TIME+?COMMAND?????????
2323?mysql?????20???0?19.918g?4.538g???9404?S?0.333?14.52?352:51.44?mysqld???
1260?root??????20???0?7933492?1.173g??14004?S?0.333?3.753??58:20.74?java???
1520?daemon????20???0??358140???3980????776?S?0.333?0.012???6:19.55?httpd????
1503?root??????20???0???69172???2240???1412?S?0.333?0.007???0:48.05?httpd???????????????????????
???????????????????
---------各項(xiàng)指標(biāo)解析---------------------------------------------------
第一行統(tǒng)計(jì)信息區(qū)
????18:20:27?????????????????????當(dāng)前時(shí)間
????up?25?days,?17:29?????????????系統(tǒng)運(yùn)行時(shí)間,格式為時(shí):分
????1?user?????????????????????當(dāng)前登錄用戶數(shù)
????load?average:?0.04,?0.09,?0.13??系統(tǒng)負(fù)載,三個(gè)數(shù)值分別為?1分鐘、5分鐘、15分鐘前到現(xiàn)在的平均值
Tasks:進(jìn)程相關(guān)信息
????running???正在運(yùn)行的進(jìn)程數(shù)
????sleeping??睡眠的進(jìn)程數(shù)
????stopped???停止的進(jìn)程數(shù)
????zombie????僵尸進(jìn)程數(shù)
Cpu(s):CPU相關(guān)信息
????%us:表示用戶空間程序的cpu使用率(沒有通過nice調(diào)度)
????%sy:表示系統(tǒng)空間的cpu使用率,主要是內(nèi)核程序
????%ni:表示用戶空間且通過nice調(diào)度過的程序的cpu使用率
????%id:空閑cpu
????%wa:cpu運(yùn)行時(shí)在等待io的時(shí)間
????%hi:cpu處理硬中斷的數(shù)量
????%si:cpu處理軟中斷的數(shù)量
Mem??內(nèi)存信息??
????total?物理內(nèi)存總量
????used?使用的物理內(nèi)存總量
????free?空閑內(nèi)存總量
????buffers?用作內(nèi)核緩存的內(nèi)存量
Swap?內(nèi)存信息??
????total?交換區(qū)總量
????used?使用的交換區(qū)總量
????free?空閑交換區(qū)總量
????cached?緩沖的交換區(qū)總量
找到相關(guān)進(jìn)程后,我們則可以使用 top -Hp pid或pidstat -t -p pid命令查看進(jìn)程具體線程使用 CPU 情況,從而找到具體的導(dǎo)致 CPU 高的線程%us 過高,則可以在對(duì)應(yīng) java 服務(wù)根據(jù)線程ID查看具體詳情,是否存在死循環(huán),或者長時(shí)間的阻塞調(diào)用。java 服務(wù)可以使用 jstack 如果是 %sy 過高,則先使用 strace 定位具體的系統(tǒng)調(diào)用,再定位是哪里的應(yīng)用代碼導(dǎo)致的 如果是 %si 過高,則可能是網(wǎng)絡(luò)問題導(dǎo)致軟中斷頻率飆高 %wa 過高,則是頻繁讀寫磁盤導(dǎo)致的。
linux 內(nèi)存
查看內(nèi)存使用情況
使用 top 或者 free、vmstat 命令
# top
top - 18:20:27 up 26 days, 8:30, 2 users, load average: 0.04, 0.09, 0.13
Tasks: 168 total, 1 running, 167 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.3 us, 0.5 sy, 0.0 ni, 99.1 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st
KiB Mem: 32762356 total, 14675196 used, 18087160 free, 884 buffers
KiB Swap: 2103292 total, 0 used, 2103292 free. 6580028 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2323 mysql 20 0 19.918g 4.538g 9404 S 0.333 14.52 352:51.44 mysqld
1260 root 20 0 7933492 1.173g 14004 S 0.333 3.753 58:20.74 java
....
bcc-tools 軟件包里的 cachestat 和 cachetop、memleak achestat 可查看整個(gè)系統(tǒng)緩存的讀寫命中情況 cachetop 可查看每個(gè)進(jìn)程的緩存命中情況 memleak 可以用檢查 C、C++ 程序的內(nèi)存泄漏問題
free 命令內(nèi)存指標(biāo)
#?free?-m?
????????????????total?used???free???shared??buffers??cached?
Mem:????????????32107?30414??1692???0???????1962?????8489?
-/+?buffers/cache:????19962??12144?
Swap:???????????????0?????0?????0
shared 是共享內(nèi)存的大小, 一般系統(tǒng)不會(huì)用到,總是0 buffers/cache 是緩存和緩沖區(qū)的大小,buffers 是對(duì)原始磁盤塊的緩存,cache 是從磁盤讀取文件系統(tǒng)里文件的頁緩存 available 是新進(jìn)程可用內(nèi)存的大小
內(nèi)存 swap 過高
Swap 其實(shí)就是把一塊磁盤空間或者一個(gè)本地文件,當(dāng)成內(nèi)存來使用。swap 換出,把進(jìn)程暫時(shí)不用的內(nèi)存數(shù)據(jù)存儲(chǔ)到磁盤中,并釋放這些數(shù)據(jù)占用的內(nèi)存。swap 換入,在進(jìn)程再次訪問這些內(nèi)存的時(shí)候,把它們從磁盤讀到內(nèi)存中來
swap 和 內(nèi)存回收的機(jī)制 內(nèi)存的回收既包括了文件頁(內(nèi)存映射獲取磁盤文件的頁)又包括了匿名頁(進(jìn)程動(dòng)態(tài)分配的內(nèi)存) 對(duì)文件頁的回收,可以直接回收緩存,或者把臟頁寫回磁盤后再回收 而對(duì)匿名頁的回收,其實(shí)就是通過 Swap 機(jī)制,把它們寫入磁盤后再釋放內(nèi)存 swap 過高會(huì)造成嚴(yán)重的性能問題,頁失效會(huì)導(dǎo)致頻繁的頁面在內(nèi)存和磁盤之間交換 一般線上的服務(wù)器的內(nèi)存都很大,可以禁用 swap 可以設(shè)置 /proc/sys/vm/min_free_kbytes,來調(diào)整系統(tǒng)定期回收內(nèi)存的閾值,也可以設(shè)置 /proc/sys/vm/swappiness,來調(diào)整文件頁和匿名頁的回收傾向
linux 磁盤I/O 問題
文件系統(tǒng)和磁盤
磁盤是一個(gè)存儲(chǔ)設(shè)備(確切地說是塊設(shè)備),可以被劃分為不同的磁盤分區(qū)。而在磁盤或者磁盤分區(qū)上,還可以再創(chuàng)建文件系統(tǒng),并掛載到系統(tǒng)的某個(gè)目錄中。系統(tǒng)就可以通過這個(gè)掛載目錄來讀寫文件 磁盤是存儲(chǔ)數(shù)據(jù)的塊設(shè)備,也是文件系統(tǒng)的載體。所以,文件系統(tǒng)確實(shí)還是要通過磁盤,來保證數(shù)據(jù)的持久化存儲(chǔ) 系統(tǒng)在讀寫普通文件時(shí),I/O 請(qǐng)求會(huì)首先經(jīng)過文件系統(tǒng),然后由文件系統(tǒng)負(fù)責(zé),來與磁盤進(jìn)行交互。而在讀寫塊設(shè)備文件時(shí),會(huì)跳過文件系統(tǒng),直接與磁盤交互 linux 內(nèi)存里的 Buffers 是對(duì)原始磁盤塊的臨時(shí)存儲(chǔ),也就是用來緩存磁盤的數(shù)據(jù),通常不會(huì)特別大(20MB 左右)。內(nèi)核就可以把分散的寫集中起來(優(yōu)化磁盤的寫入) linux 內(nèi)存里的 Cached 是從磁盤讀取文件的頁緩存,也就是用來緩存從文件讀寫的數(shù)據(jù)。下次訪問這些文件數(shù)據(jù)時(shí),則直接從內(nèi)存中快速獲取,而不再次訪問磁盤
磁盤性能指標(biāo)
使用率,是指磁盤處理 I/O 的時(shí)間百分比。過高的使用率(比如超過 80%),通常意味著磁盤 I/O 存在性能瓶頸。 飽和度,是指磁盤處理 I/O 的繁忙程度。過高的飽和度,意味著磁盤存在嚴(yán)重的性能瓶頸。當(dāng)飽和度為 100% 時(shí),磁盤無法接受新的 I/O 請(qǐng)求。 IOPS(Input/Output Per Second),是指每秒的 I/O 請(qǐng)求數(shù) 吞吐量,是指每秒的 I/O 請(qǐng)求大小 響應(yīng)時(shí)間,是指 I/O 請(qǐng)求從發(fā)出到收到響應(yīng)的間隔時(shí)間
IO 過高怎么找問題,怎么調(diào)優(yōu)
查看系統(tǒng)磁盤整體 I/O
#?iostat?-x?-k?-d?1?1
Linux?4.4.73-5-default?(ceshi44)????????2021年07月08日??_x86_64_????????(40?CPU)
Device:??rrqm/s???wrqm/s??r/s????w/s????rkB/s???wkB/s??avgrq-sz?avgqu-sz?await?r_await?w_await??svctm??%util
sda??????0.08?????2.48????0.37???11.71??27.80???507.24??88.53???0.02?????1.34???14.96????0.90???0.09???0.10
sdb??????0.00?????1.20????1.28???16.67??30.91???647.83??75.61???0.17?????9.51????9.40????9.52???0.32???0.57
------?
rrqm/s:???每秒對(duì)該設(shè)備的讀請(qǐng)求被合并次數(shù),文件系統(tǒng)會(huì)對(duì)讀取同塊(block)的請(qǐng)求進(jìn)行合并
wrqm/s:???每秒對(duì)該設(shè)備的寫請(qǐng)求被合并次數(shù)
r/s:??????每秒完成的讀次數(shù)
w/s:??????每秒完成的寫次數(shù)
rkB/s:????每秒讀數(shù)據(jù)量(kB為單位)
wkB/s:????每秒寫數(shù)據(jù)量(kB為單位)
avgrq-sz:?平均每次IO操作的數(shù)據(jù)量(扇區(qū)數(shù)為單位)
avgqu-sz:?平均等待處理的IO請(qǐng)求隊(duì)列長度
await:????平均每次IO請(qǐng)求等待時(shí)間(包括等待時(shí)間和處理時(shí)間,毫秒為單位)
svctm:????平均每次IO請(qǐng)求的處理時(shí)間(毫秒為單位)
%util:????采用周期內(nèi)用于IO操作的時(shí)間比率,即IO隊(duì)列非空的時(shí)間比率
查看進(jìn)程級(jí)別 I/O
#?pidstat?-d
Linux?3.10.0-862.el7.x86_64?(8f57ec39327b)??????07/11/2021??????_x86_64_????????(6?CPU)
06:42:35?PM???UID???????PID???kB_rd/s???kB_wr/s?kB_ccwr/s??Command
06:42:35?PM?????0?????????1??????1.05??????0.00??????0.00??java
06:42:35?PM?????0???????102??????0.04??????0.05??????0.00??bash
------
kB_rd/s???每秒從磁盤讀取的KB
kB_wr/s???每秒寫入磁盤KB
kB_ccwr/s 任務(wù)取消的寫入磁盤的KB。當(dāng)任務(wù)截?cái)嗯K的pagecache的時(shí)候會(huì)發(fā)生
Command???進(jìn)程執(zhí)行命令
當(dāng)使用 pidstat -d 定位到哪個(gè)應(yīng)用服務(wù)時(shí),接下來則需要使用 strace 和 lsof 定位是哪些代碼在讀寫磁盤里的哪些文件,導(dǎo)致IO高的原因
$?strace?-p?18940?
strace:?Process?18940?attached?
...
mmap(NULL,?314576896,?PROT_READ|PROT_WRITE,?MAP_PRIVATE|MAP_ANONYMOUS,?-1,?0)?=?0x7f0f7aee9000?
mmap(NULL,?314576896,?PROT_READ|PROT_WRITE,?MAP_PRIVATE|MAP_ANONYMOUS,?-1,?0)?=?0x7f0f682e8000?
write(3,?"2018-12-05?15:23:01,709?-?__main"...,?314572844?
)?=?314572844?
munmap(0x7f0f682e8000,?314576896)???????=?0?
write(3,?"\n",?1)???????????????????????=?1?
munmap(0x7f0f7aee9000,?314576896)???????=?0?
close(3)????????????????????????????????=?0?
stat("/tmp/logtest.txt.1",?{st_mode=S_IFREG|0644,?st_size=943718535,?...})?=?0?
strace 命令輸出可以看到進(jìn)程18940 正在往文件 /tmp/logtest.txt.1 寫入300m
$?lsof?-p?18940?
COMMAND???PID?USER???FD???TYPE?DEVICE??SIZE/OFF????NODE?NAME?
java??18940?root??cwd????DIR???0,50??????4096?1549389?/?
…?
java??18940?root????2u???CHR??136,0???????0t0???????3?/dev/pts/0?
java??18940?root????3w???REG????8,1?117944320?????303?/tmp/logtest.txt?
----
FD?表示文件描述符號(hào),TYPE?表示文件類型,NODE?NAME?表示文件路徑
lsof 也可以看出進(jìn)程18940 以每次 300MB 的速度往 /tmp/logtest.txt 寫入
linux 網(wǎng)絡(luò)I/O 問題
當(dāng)一個(gè)網(wǎng)絡(luò)幀到達(dá)網(wǎng)卡后,網(wǎng)卡會(huì)通過 DMA 方式,把這個(gè)網(wǎng)絡(luò)包放到收包隊(duì)列中;然后通過硬中斷,告訴中斷處理程序已經(jīng)收到了網(wǎng)絡(luò)包。接著,網(wǎng)卡中斷處理程序會(huì)為網(wǎng)絡(luò)幀分配內(nèi)核數(shù)據(jù)結(jié)構(gòu)(sk_buff),并將其拷貝到 sk_buff 緩沖區(qū)中;然后再通過軟中斷,通知內(nèi)核收到了新的網(wǎng)絡(luò)幀。內(nèi)核協(xié)議棧從緩沖區(qū)中取出網(wǎng)絡(luò)幀,并通過網(wǎng)絡(luò)協(xié)議棧,從下到上逐層處理這個(gè)網(wǎng)絡(luò)幀
硬中斷:與系統(tǒng)相連的外設(shè)(比如網(wǎng)卡、硬盤)自動(dòng)產(chǎn)生的。主要是用來通知操作系統(tǒng)系統(tǒng)外設(shè)狀態(tài)的變化。比如當(dāng)網(wǎng)卡收到數(shù)據(jù)包的時(shí)候,就會(huì)發(fā)出一個(gè)硬中斷 軟中斷:為了滿足實(shí)時(shí)系統(tǒng)的要求,中斷處理應(yīng)該是越快越好。linux為了實(shí)現(xiàn)這個(gè)特點(diǎn),當(dāng)中斷發(fā)生的時(shí)候,硬中斷處理那些短時(shí)間就可以完成的工作,而將那些處理事件比較長的工作,交給軟中斷來完成
網(wǎng)絡(luò)I/O指標(biāo)
帶寬,表示鏈路的最大傳輸速率,單位通常為 b/s (比特 / 秒) 吞吐量,表示單位時(shí)間內(nèi)成功傳輸?shù)臄?shù)據(jù)量,單位通常為 b/s(比特 / 秒)或者 B/s(字節(jié) / 秒)吞吐量受帶寬限制,而吞吐量 / 帶寬,也就是該網(wǎng)絡(luò)的使用率 延時(shí),表示從網(wǎng)絡(luò)請(qǐng)求發(fā)出后,一直到收到遠(yuǎn)端響應(yīng),所需要的時(shí)間延遲。在不同場(chǎng)景中,這一指標(biāo)可能會(huì)有不同含義。比如,它可以表示,建立連接需要的時(shí)間(比如 TCP 握手延時(shí)),或一個(gè)數(shù)據(jù)包往返所需的時(shí)間(比如 RTT) PPS,是 Packet Per Second(包 / 秒)的縮寫,表示以網(wǎng)絡(luò)包為單位的傳輸速率。PPS 通常用來評(píng)估網(wǎng)絡(luò)的轉(zhuǎn)發(fā)能力,比如硬件交換機(jī),通常可以達(dá)到線性轉(zhuǎn)發(fā)(即 PPS 可以達(dá)到或者接近理論最大值)。而基于 Linux 服務(wù)器的轉(zhuǎn)發(fā),則容易受網(wǎng)絡(luò)包大小的影響 網(wǎng)絡(luò)的連通性 并發(fā)連接數(shù)(TCP 連接數(shù)量) 丟包率(丟包百分比)
查看網(wǎng)絡(luò)I/O指標(biāo)
查看網(wǎng)絡(luò)配置
#?ifconfig?em1
em1???????Link?encap:Ethernet??HWaddr?80:18:44:EB:18:98??
??????????inet?addr:192.168.0.44??Bcast:192.168.0.255??Mask:255.255.255.0
??????????inet6?addr:?fe80::8218:44ff:feeb:1898/64?Scope:Link
??????????UP?BROADCAST?RUNNING?MULTICAST??MTU:1500??Metric:1
??????????RX?packets:3098067963?errors:0?dropped:5379363?overruns:0?frame:0
??????????TX?packets:2804983784?errors:0?dropped:0?overruns:0?carrier:0
??????????collisions:0?txqueuelen:1000?
??????????RX?bytes:1661766458875?(1584783.9?Mb)??TX?bytes:1356093926505?(1293271.9?Mb)
??????????Interrupt:83
-----
TX 和 RX 部分的 errors、dropped、overruns、carrier 以及 collisions 等指標(biāo)不為?0?時(shí),
通常表示出現(xiàn)了網(wǎng)絡(luò) I/O 問題。
errors?表示發(fā)生錯(cuò)誤的數(shù)據(jù)包數(shù),比如校驗(yàn)錯(cuò)誤、幀同步錯(cuò)誤等
dropped?表示丟棄的數(shù)據(jù)包數(shù),即數(shù)據(jù)包已經(jīng)收到了?Ring?Buffer,但因?yàn)閮?nèi)存不足等原因丟包
overruns?表示超限數(shù)據(jù)包數(shù),即網(wǎng)絡(luò)?I/O?速度過快,導(dǎo)致?Ring?Buffer?中的數(shù)據(jù)包來不及處理(隊(duì)列滿)而導(dǎo)致的丟包
carrier?表示發(fā)生?carrirer?錯(cuò)誤的數(shù)據(jù)包數(shù),比如雙工模式不匹配、物理電纜出現(xiàn)問題等
collisions?表示碰撞數(shù)據(jù)包數(shù)
網(wǎng)絡(luò)吞吐和 PPS
#?sar?-n?DEV?1
Linux?4.4.73-5-default?(ceshi44)????????2022年03月31日??_x86_64_????????(40?CPU)
15時(shí)39分40秒?????IFACE???rxpck/s???txpck/s????rxkB/s????txkB/s???rxcmp/s???txcmp/s??rxmcst/s???%ifutil
15時(shí)39分41秒???????em1???1241.00???1022.00????600.48????590.39??????0.00??????0.00????165.00??????0.49
15時(shí)39分41秒????????lo????636.00????636.00???7734.06???7734.06??????0.00??????0.00??????0.00??????0.00
15時(shí)39分41秒???????em4??????0.00??????0.00??????0.00??????0.00??????0.00??????0.00??????0.00??????0.00
15時(shí)39分41秒???????em3??????0.00??????0.00??????0.00??????0.00??????0.00??????0.00??????0.00??????0.00
15時(shí)39分41秒???????em2?????26.00?????20.00??????6.63??????8.80??????0.00??????0.00??????0.00??????0.01
----
rxpck/s?和?txpck/s?分別是接收和發(fā)送的?PPS,單位為包?/?秒
rxkB/s?和?txkB/s?分別是接收和發(fā)送的吞吐量,單位是?KB/?秒
rxcmp/s?和?txcmp/s?分別是接收和發(fā)送的壓縮數(shù)據(jù)包數(shù),單位是包?/?秒
寬帶
#?ethtool?em1?|?grep?Speed?
Speed:?1000Mb/s
連通性和延遲
#?ping?www.baidu.com
PING?www.a.shifen.com?(14.215.177.38)?56(84)?bytes?of?data.
64?bytes?from?14.215.177.38:?icmp_seq=1?ttl=56?time=53.9?ms
64?bytes?from?14.215.177.38:?icmp_seq=2?ttl=56?time=52.3?ms
64?bytes?from?14.215.177.38:?icmp_seq=3?ttl=56?time=53.8?ms
64?bytes?from?14.215.177.38:?icmp_seq=4?ttl=56?time=56.0?ms
統(tǒng)計(jì) TCP 連接狀態(tài)工具 ss 和 netstat
[root@root?~]$>#ss?-ant?|?awk?'{++S[$1]}?END?{for(a?in?S)?print?a,?S[a]}'
LISTEN?96
CLOSE-WAIT?527
ESTAB?8520
State?1
SYN-SENT?2
TIME-WAIT?660
[root@root?~]$>#netstat?-n?|?awk?'/^tcp/?{++S[$NF]}?END?{for(a?in?S)?print?a,?S[a]}'
CLOSE_WAIT?530
ESTABLISHED?8511
FIN_WAIT2?3
TIME_WAIT?809
網(wǎng)絡(luò)請(qǐng)求變慢,怎么調(diào)優(yōu)
高并發(fā)下 TCP 請(qǐng)求變多,會(huì)有大量處于 TIME_WAIT 狀態(tài)的連接,它們會(huì)占用大量內(nèi)存和端口資源。此時(shí)可以優(yōu)化與 TIME_WAIT 狀態(tài)相關(guān)的內(nèi)核選項(xiàng) 增大處于 TIME_WAIT 狀態(tài)的連接數(shù)量 net.ipv4.tcp_max_tw_buckets ,并增大連接跟蹤表的大小 net.netfilter.nf_conntrack_max 減小 net.ipv4.tcp_fin_timeout 和 net.netfilter.nf_conntrack_tcp_timeout_time_wait ,讓系統(tǒng)盡快釋放它們所占用的資源 開啟端口復(fù)用 net.ipv4.tcp_tw_reuse。這樣,被 TIME_WAIT 狀態(tài)占用的端口,還能用到新建的連接中 增大本地端口的范圍 net.ipv4.ip_local_port_range 。這樣就可以支持更多連接,提高整體的并發(fā)能力 增加最大文件描述符的數(shù)量。可以使用 fs.nr_open 和 fs.file-max ,分別增大進(jìn)程和系統(tǒng)的最大文件描述符數(shù) SYN FLOOD 攻擊,利用 TCP 協(xié)議特點(diǎn)進(jìn)行攻擊而引發(fā)的性能問題,可以考慮優(yōu)化與 SYN 狀態(tài)相關(guān)的內(nèi)核選項(xiàng) 增大 TCP 半連接的最大數(shù)量 net.ipv4.tcp_max_syn_backlog ,或者開啟 TCP SYN Cookies net.ipv4.tcp_syncookies ,來繞開半連接數(shù)量限制的問題 減少 SYN_RECV 狀態(tài)的連接重傳 SYN+ACK 包的次數(shù) net.ipv4.tcp_synack_retries 加快 TCP 長連接的回收,優(yōu)化與 Keepalive 相關(guān)的內(nèi)核選項(xiàng) 縮短最后一次數(shù)據(jù)包到 Keepalive 探測(cè)包的間隔時(shí)間 net.ipv4.tcp_keepalive_time 縮短發(fā)送 Keepalive 探測(cè)包的間隔時(shí)間 net.ipv4.tcp_keepalive_intvl 減少 Keepalive 探測(cè)失敗后,一直到通知應(yīng)用程序前的重試次數(shù) net.ipv4.tcp_keepalive_probes
java 應(yīng)用內(nèi)存泄漏和頻繁 GC
區(qū)分內(nèi)存溢出、內(nèi)存泄漏、內(nèi)存逃逸
內(nèi)存泄漏:內(nèi)存被申請(qǐng)后始終無法釋放,導(dǎo)致內(nèi)存無法被回收使用,造成內(nèi)存空間浪費(fèi) 內(nèi)存溢出:指內(nèi)存申請(qǐng)時(shí),內(nèi)存空間不足 1-內(nèi)存上限過小 2-內(nèi)存加載數(shù)據(jù)太多 3-分配太多內(nèi)存沒有回收,出現(xiàn)內(nèi)存泄漏 內(nèi)存逃逸:是指程序運(yùn)行時(shí)的數(shù)據(jù),本應(yīng)在棧上分配,但需要在堆上分配,稱為內(nèi)存逃逸 java中的對(duì)象都是在堆上分配的,而垃圾回收機(jī)制會(huì)回收堆中不再使用的對(duì)象,但是篩選可回收對(duì)象,回收對(duì)象還有整理內(nèi)存都需要消耗時(shí)間。如果能夠通過逃逸分析確定對(duì)象不會(huì)逃出方法之外,那就可以讓這個(gè)對(duì)象在棧上分配內(nèi)存,對(duì)象所占用的內(nèi)存就可以隨棧幀出棧而銷毀,就減輕了垃圾回收的壓力 線程同步本身比較耗時(shí),如果確定一個(gè)變量不會(huì)逃逸出線程,無法被其它線程訪問到,那這個(gè)變量的讀寫就不會(huì)存在競(jìng)爭(zhēng),對(duì)這個(gè)變量的同步措施可以清除 java 虛擬機(jī)中的原始數(shù)據(jù)類型(int,long及reference類型等) 都不能再進(jìn)一步分解,它們稱為標(biāo)量。如果一個(gè)數(shù)據(jù)可以繼續(xù)分解,那它稱為聚合量,java 中最典型的聚合量是對(duì)象。如果逃逸分析證明一個(gè)對(duì)象不會(huì)被外部訪問,并且這個(gè)對(duì)象是可分解的,那程序運(yùn)行時(shí)可能不創(chuàng)建該對(duì)象,而改為直接創(chuàng)建它的若干個(gè)被方法使用到的成員變量來代替。拆散后的變量便可以被單獨(dú)分析與優(yōu)化,可以各自分別在棧幀或寄存器上分配空間,原本的對(duì)象就無需整體分配空間
內(nèi)存泄漏,該如何定位和處理
使用 jmap -histo:live [pid]和jmap -dump:format=b,file=filename [pid]前者可以統(tǒng)計(jì)堆內(nèi)存對(duì)象大小和數(shù)量,后者可以把堆內(nèi)存 dump 下來啟動(dòng)參數(shù)中指定 -XX:+HeapDumpOnOutOfMemoryError來保存OOM時(shí)的dump文件使用 JProfiler 或者 MAT 軟件查看 heap 內(nèi)存對(duì)象,可以更直觀地發(fā)現(xiàn)泄露的對(duì)象 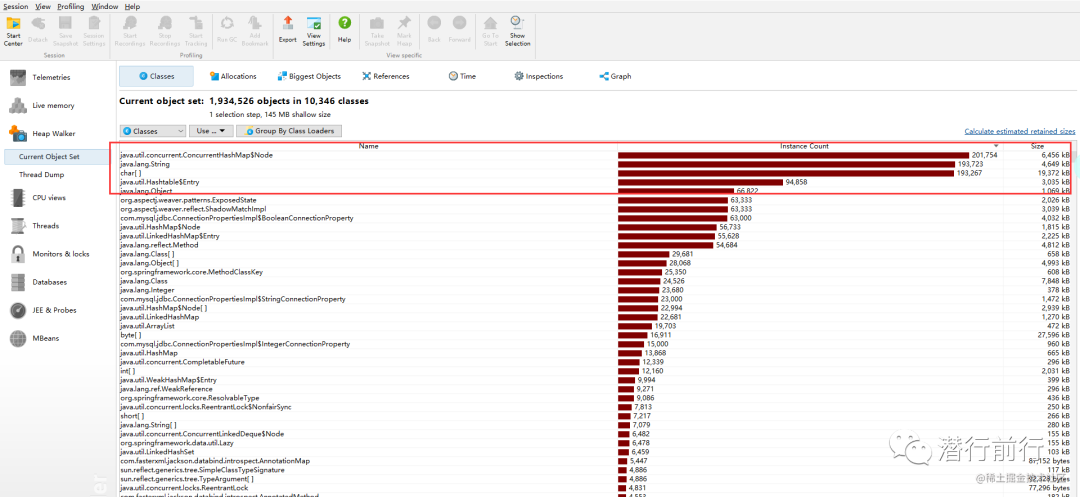
java線程問題排查
java 線程狀態(tài)
NEW:對(duì)應(yīng)沒有 Started 的線程,對(duì)應(yīng)新生態(tài) RUNNABLE:對(duì)于就緒態(tài)和運(yùn)行態(tài)的合稱 BLOCKED,WAITING,TIMED_WAITING:三個(gè)都是阻塞態(tài) sleep 和 join 稱為WAITING sleep 和 join 方法設(shè)置了超時(shí)時(shí)間的,則是 TIMED_WAITING wait 和 IO 流阻塞稱為BLOCKED TERMINATED:死亡態(tài)
線程出現(xiàn)死鎖或者被阻塞
jstack –l pid | grep -i –E 'BLOCKED | deadlock', 加上參數(shù) -l,jstack 命令可以快速打印出造成死鎖的代碼
#?jstack?-l?28764
Full?thread?dump?Java?HotSpot(TM)?64-Bit?Server?VM?(13.0.2+8?mixed?mode,?sharing):
.....
"Thread-0"?#14?prio=5?os_prio=0?cpu=0.00ms?elapsed=598.37s?tid=0x000001b3c25f7000?nid=0x4abc?waiting?for?monitor?entry??[0x00000061661fe000]
???java.lang.Thread.State:?BLOCKED?(on?object?monitor)
????????at?com.Test$DieLock.run(Test.java:52)
????????-?waiting?to?lock?<0x0000000712d7c230>?(a?java.lang.Object)
????????-?locked?<0x0000000712d7c220>?(a?java.lang.Object)
????????at?java.lang.Thread.run([email protected]/Thread.java:830)
???Locked?ownable?synchronizers:
????????-?None
"Thread-1"?#15?prio=5?os_prio=0?cpu=0.00ms?elapsed=598.37s?tid=0x000001b3c25f8000?nid=0x1984?waiting?for?monitor?entry??[0x00000061662ff000]
???java.lang.Thread.State:?BLOCKED?(on?object?monitor)
????????at?com.Test$DieLock.run(Test.java:63)
????????-?waiting?to?lock?<0x0000000712d7c220>?(a?java.lang.Object)
????????-?locked?<0x0000000712d7c230>?(a?java.lang.Object)
????????at?java.lang.Thread.run([email protected]/Thread.java:830)
.....
Found?one?Java-level?deadlock:
=============================
"Thread-0":
??waiting?to?lock?monitor?0x000001b3c1e4c480?(object?0x0000000712d7c230,?a?java.lang.Object),
??which?is?held?by?"Thread-1"
"Thread-1":
??waiting?to?lock?monitor?0x000001b3c1e4c080?(object?0x0000000712d7c220,?a?java.lang.Object),
??which?is?held?by?"Thread-0"
Java?stack?information?for?the?threads?listed?above:
===================================================
"Thread-0":
????????at?com.Test$DieLock.run(Test.java:52)
????????-?waiting?to?lock?<0x0000000712d7c230>?(a?java.lang.Object)
????????-?locked?<0x0000000712d7c220>?(a?java.lang.Object)
????????at?java.lang.Thread.run([email protected]/Thread.java:830)
"Thread-1":
????????at?com.Test$DieLock.run(Test.java:63)
????????-?waiting?to?lock?<0x0000000712d7c220>?(a?java.lang.Object)
????????-?locked?<0x0000000712d7c230>?(a?java.lang.Object)
????????at?java.lang.Thread.run([email protected]/Thread.java:830)
Found?1?deadlock.
從 jstack 輸出的日志可以看出線程阻塞在 Test.java:52 行,發(fā)生了死鎖
常用 jvm 調(diào)優(yōu)啟動(dòng)參數(shù)
-verbose:gc 輸出每次GC的相關(guān)情況 -verbose:jni? 輸出native方法調(diào)用的相關(guān)情況,一般用于診斷jni調(diào)用錯(cuò)誤信息 -Xms n 指定jvm堆的初始大小,默認(rèn)為物理內(nèi)存的1/64,最小為1M;可以指定單位,比如k、m,若不指定,則默認(rèn)為字節(jié) -Xmx n 指定jvm堆的最大值,默認(rèn)為物理內(nèi)存的1/4或者1G,最小為2M;單位與-Xms一致 -Xss n 設(shè)置單個(gè)線程棧的大小,一般默認(rèn)為512k -XX:NewRatio=4 設(shè)置年輕代(包括Eden和兩個(gè)Survivor區(qū))與年老代的比值(除去持久代)。設(shè)置為4,則年輕代與年老代所占比值為1:4,年輕代占整個(gè)堆棧的1/5 -Xmn 設(shè)置新生代內(nèi)存大小。整個(gè)堆大小=年輕代大小 + 年老代大小 + 持久代大小。持久代一般固定大小為64m,所以增大年輕代后,將會(huì)減小年老代大小。此值對(duì)系統(tǒng)性能影響較大,Sun官方推薦配置為整個(gè)堆的3/8 -XX:SurvivorRatio=4 設(shè)置年輕代中Eden區(qū)與Survivor區(qū)的大小比值。設(shè)置為4,則兩個(gè)Survivor區(qū)與一個(gè)Eden區(qū)的比值為2:4,一個(gè)Survivor區(qū)占整個(gè)年輕代的1/6 -XX:MaxTenuringThreshold=0 設(shè)置垃圾最大年齡。如果設(shè)置為0的話,則年輕代對(duì)象不經(jīng)過Survivor區(qū),直接進(jìn)入年老代。對(duì)于年老代比較多的應(yīng)用,可以提高效率。如果將此值設(shè)置為一個(gè)較大值,則年輕代對(duì)象會(huì)在Survivor區(qū)進(jìn)行多次復(fù)制,這樣可以增加對(duì)象再年輕代的存活時(shí)間,增加在年輕代即被回收的概率