
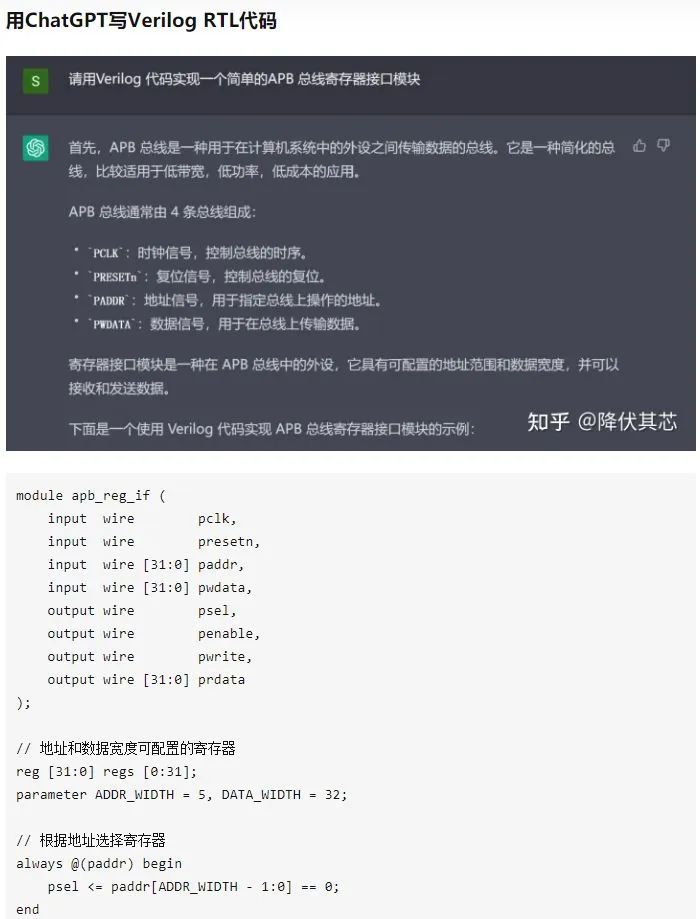
ChatGPT發(fā)展歷程、原理、技術(shù)架構(gòu)詳解和產(chǎn)業(yè)未來
在下方公眾號后臺回復(fù): 面試手冊 ,可獲取 PDF 手冊。
這幾天,ChatGPT徹底殺瘋了來源:Datawhale, 作者:陳巍博士,編輯:特大號
滿世界的人都在和ChatGPT撩騷
但很多小伙伴還是一頭霧水
這玩意到底是個啥?能干啥?
這里有篇雄文
詳細(xì)介紹了ChatGPT的來龍去脈 看完你也能成半個磚家啦以下為正文,作者陳巍博士
去年12月1日,OpenAI推出人工智能聊天原型ChatGPT,再次賺足眼球,為AI界引發(fā)了類似AIGC讓藝術(shù)家失業(yè)的大討論。
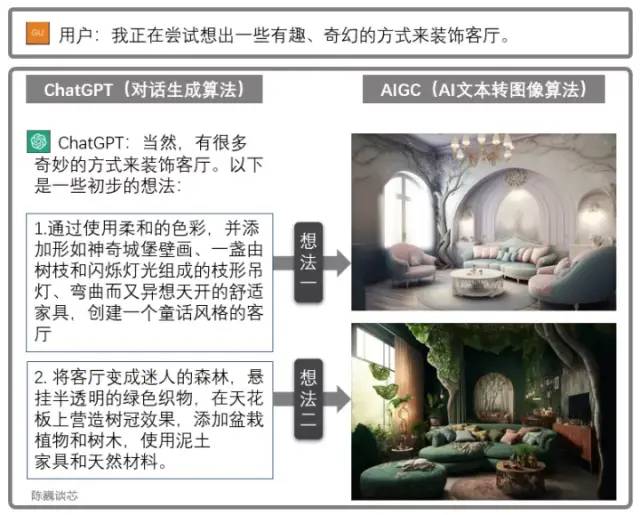
ChatGPT和AIGC的聯(lián)合使用
ChatGPT也可以與其他AIGC模型聯(lián)合使用,獲得更加炫酷實用的功能。例如上面通過對話生成客廳設(shè)計圖。這極大加強了AI應(yīng)用與客戶對話的能力,使我們看到了AI大規(guī)模落地的曙光。
一、ChatGPT的傳承與特點

▌1.1 OpenAI家族
我們首先了解下OpenAI是哪路大神。 OpenAI總部位于舊金山,由特斯拉的馬斯克、Sam Altman及其他投資者在2015年共同創(chuàng)立,目標(biāo)是開發(fā)造福全人類的AI技術(shù)。而馬斯克則在2018年時因公司發(fā)展方向分歧而離開。 此前,OpenAI 因推出 GPT系列自然語言處理模型而聞名。從2018年起,OpenAI就開始發(fā)布生成式預(yù)訓(xùn)練語言模型GPT(Generative Pre-trained Transformer),可用于生成文章、代碼、機器翻譯、問答等各類內(nèi)容。 每一代GPT模型的參數(shù)量都爆炸式增長,堪稱“越大越好”。2019年2月發(fā)布的GPT-2參數(shù)量為15億,而2020年5月的GPT-3,參數(shù)量達(dá)到了1750億。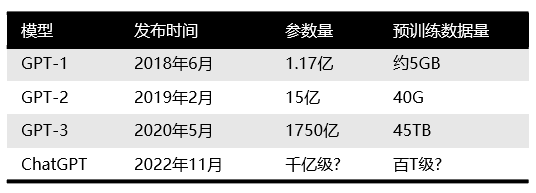
GPT家族主要模型對比
▌ 1.2 ChatGPT的主要特點
ChatGPT 是基于GPT-3.5(Generative Pre-trained Transformer 3.5)架構(gòu)開發(fā)的對話AI模型,是InstructGPT 的兄弟模型。 ChatGPT很可能是OpenAI 在GPT-4 正式推出之前的演練,或用于收集大量對話數(shù)據(jù)。
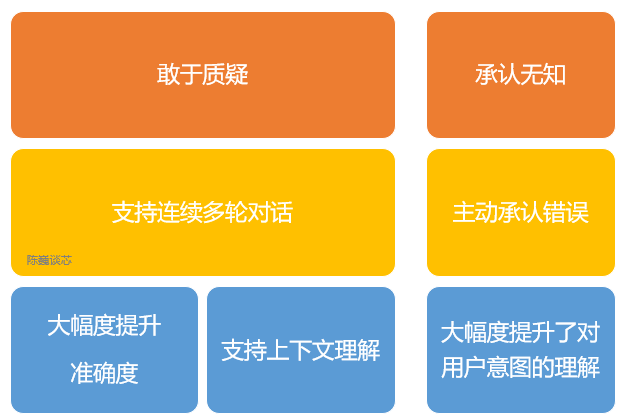
ChatGPT的主要特點
OpenAI使用 RLHF(Reinforcement Learning from Human Feedbac,人類反饋強化學(xué)習(xí)) 技術(shù)對 ChatGPT 進(jìn)行了訓(xùn)練,且加入了更多人工監(jiān)督進(jìn)行微調(diào)。 此外,ChatGPT 還具有以下特征: 1)可以主動承認(rèn)自身錯誤。若用戶指出其錯誤,模型會聽取意見并優(yōu)化答案。 2)ChatGPT 可以質(zhì)疑不正確的問題。例如被詢問 “哥倫布 2015 年來到美國的情景” 的問題時,機器人會說明哥倫布不屬于這一時代并調(diào)整輸出結(jié)果。 3)ChatGPT 可以承認(rèn)自身的無知,承認(rèn)對專業(yè)技術(shù)的不了解。 4)支持連續(xù)多輪對話。 與大家在生活中用到的各類智能音箱和“人工智障“不同,ChatGPT在對話過程中會記憶先前使用者的對話訊息,即上下文理解,以回答某些假設(shè)性的問題。 ChatGPT可實現(xiàn)連續(xù)對話,極大的提升了對話交互模式下的用戶體驗。 對于準(zhǔn)確翻譯來說(尤其是中文與人名音譯),ChatGPT離完美還有一段距離,不過在文字流暢度以及辨別特定人名來說,與其他網(wǎng)絡(luò)翻譯工具相近。 由于 ChatGPT是一個大型語言模型,目前還并不具備網(wǎng)絡(luò)搜索功能,因此它只能基于2021年所擁有的數(shù)據(jù)集進(jìn)行回答。 例如它不知道2022年世界杯的情況,也不會像蘋果的Siri那樣回答今天天氣如何、或幫你搜索信息。如果ChatGPT能上網(wǎng)自己尋找學(xué)習(xí)語料和搜索知識,估計又會有更大的突破。 即便學(xué)習(xí)的知識有限,ChatGPT 還是能回答腦洞大開的人類的許多奇葩問題。為了避免ChatGPT染上惡習(xí), ChatGPT 通過算法屏蔽,減少有害和欺騙性的訓(xùn)練輸入。查詢通過適度 API 進(jìn)行過濾,并駁回潛在的種族主義或性別歧視提示。
二、ChatGPT/GPT的原理
▌ 2.1 NLP
NLP/NLU領(lǐng)域已知局限包括對重復(fù)文本、對高度專業(yè)的主題的誤解,以及對上下文短語的誤解。 對于人類或AI,通常需接受多年的訓(xùn)練才能正常對話。 NLP類模型不僅要理解單詞的含義,還要理解如何造句和給出上下文有意義的回答,甚至使用合適的俚語和專業(yè)詞匯。
▌ 2.2 GPT v.s. BERT
與BERT模型類似,ChatGPT或GPT-3.5都是根據(jù)輸入語句,根據(jù)語言/語料概率來自動生成回答的每一個字(詞語)。 從數(shù)學(xué)或從機器學(xué)習(xí)的角度來看,語言模型是對詞語序列的概率相關(guān)性分布的建模,即利用已經(jīng)說過的語句(語句可以視為數(shù)學(xué)中的向量)作為輸入條件,預(yù)測下一個時刻不同語句甚至語言集合出現(xiàn)的概率分布。 ChatGPT 使用來自人類反饋的強化學(xué)習(xí)進(jìn)行訓(xùn)練,這種方法通過人類干預(yù)來增強機器學(xué)習(xí)以獲得更好的效果。 在訓(xùn)練過程中,人類訓(xùn)練者扮演著用戶和人工智能助手的角色,并通過近端策略優(yōu)化算法進(jìn)行微調(diào)。 由于ChatGPT更強的性能和海量參數(shù),它包含了更多的主題的數(shù)據(jù),能夠處理更多小眾主題。 ChatGPT現(xiàn)在可以進(jìn)一步處理回答問題、撰寫文章、文本摘要、語言翻譯和生成計算機代碼等任務(wù)。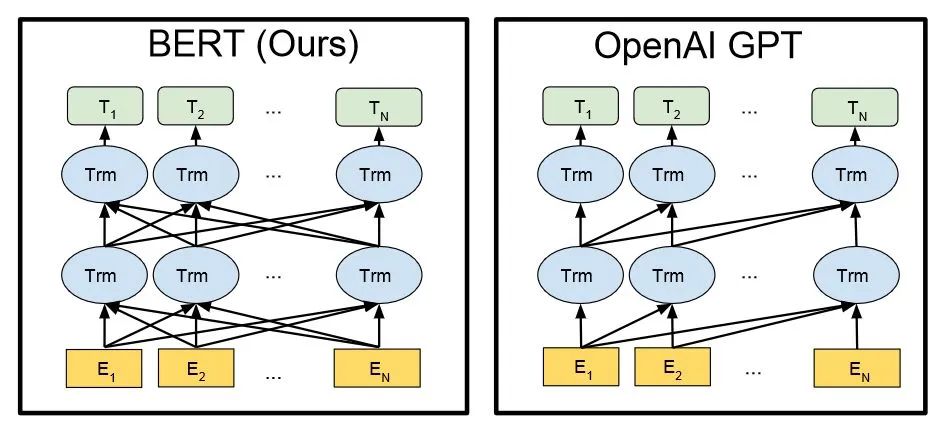 BERT與GPT的技術(shù)架構(gòu)(圖中En為輸入的每個字,Tn為輸出回答的每個字)
BERT與GPT的技術(shù)架構(gòu)(圖中En為輸入的每個字,Tn為輸出回答的每個字)
三、ChatGPT的技術(shù)架構(gòu)
▌ 3.1 GPT家族的演進(jìn)
說到ChatGPT,就不得不提到GPT家族。 ChatGPT之前有幾個知名的兄弟,包括GPT-1、GPT-2和GPT-3。這幾個兄弟一個比一個個頭大,ChatGPT與GPT-3更為相近。
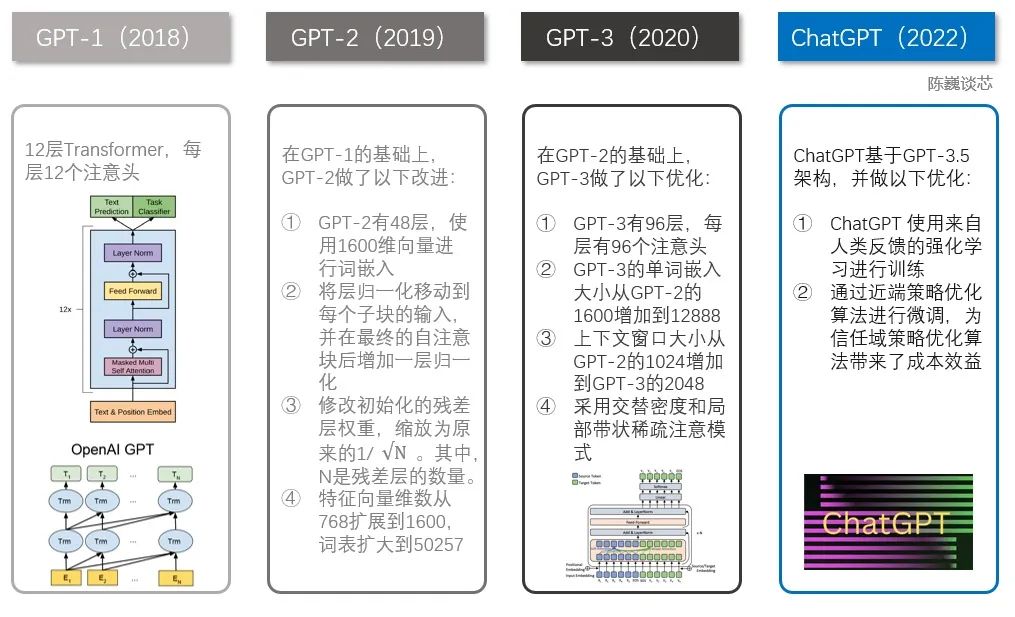
ChatGPT與GPT 1-3的技術(shù)對比
GPT家族與BERT模型都是知名的NLP模型,都基于Transformer技術(shù)。GPT-1只有12個Transformer層,而到了GPT-3,則增加到96層。▌ 3.2 人類反饋強化學(xué)習(xí)
InstructGPT/GPT3.5(ChatGPT的前身)與GPT-3的主要區(qū)別在于,新加入了被稱為RLHF(Reinforcement Learning from Human Feedback,人類反饋強化學(xué)習(xí))。 這一訓(xùn)練范式增強了人類對模型輸出結(jié)果的調(diào)節(jié),并且對結(jié)果進(jìn)行了更具理解性的排序。 在InstructGPT中,以下是“goodness of sentences”的評價標(biāo)準(zhǔn)。- 真實性:是虛假信息還是誤導(dǎo)性信息?
- 無害性:它是否對人或環(huán)境造成身體或精神上的傷害?
- 有用性:它是否解決了用戶的任務(wù)?
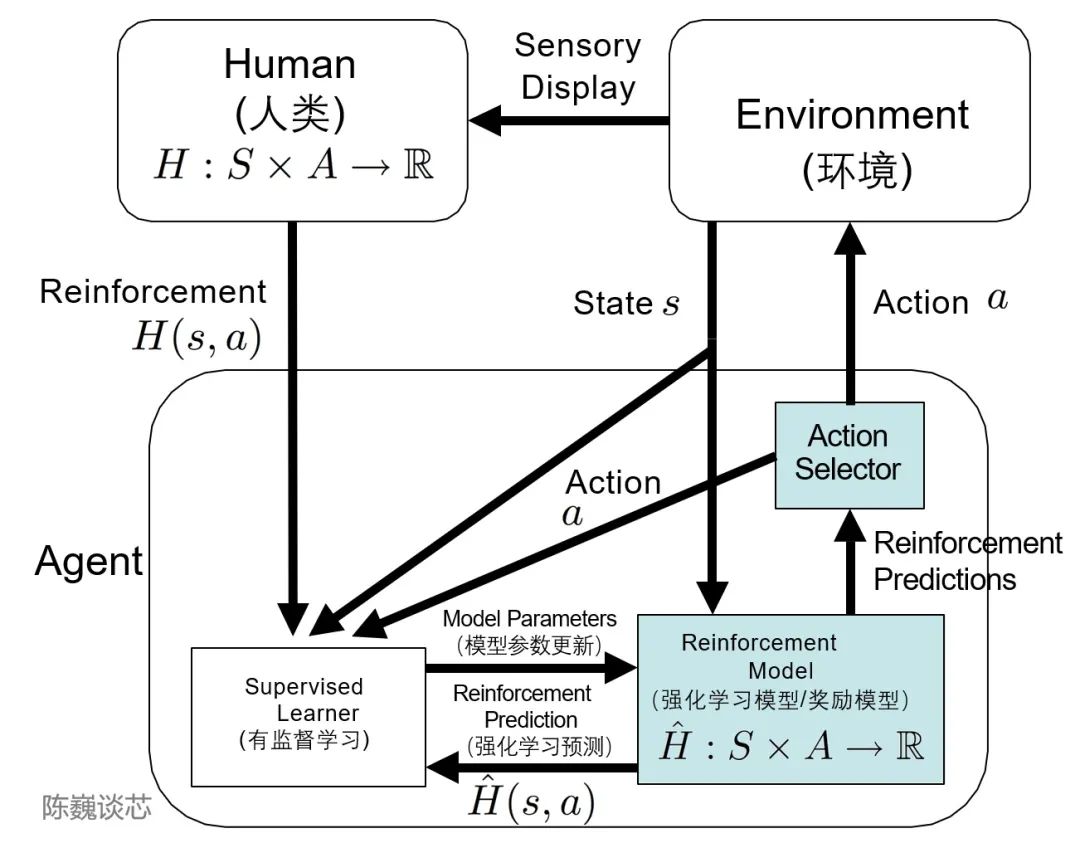
▌ 3.3 TAMER框架
這里不得不提到TAMER(Training an Agent Manually via Evaluative Reinforcement,評估式強化人工訓(xùn)練代理)這個框架。 該框架將人類標(biāo)記者引入到Agents的學(xué)習(xí)循環(huán)中,可以通過人類向Agents提供獎勵反饋(即指導(dǎo)Agents進(jìn)行訓(xùn)練),從而快速達(dá)到訓(xùn)練任務(wù)目標(biāo)。 引入人類標(biāo)記者的主要目的是加快訓(xùn)練速度。盡管強化學(xué)習(xí)技術(shù)在很多領(lǐng)域有突出表現(xiàn),但是仍然存在著許多不足,例如訓(xùn)練收斂速度慢,訓(xùn)練成本高等特點。 特別是現(xiàn)實世界中,許多任務(wù)的探索成本或數(shù)據(jù)獲取成本很高。如何加快訓(xùn)練效率,是如今強化學(xué)習(xí)任務(wù)待解決的重要問題之一。 而TAMER則可以將人類標(biāo)記者的知識,以獎勵信反饋的形式訓(xùn)練Agent,加快其快速收斂。 TAMER不需要標(biāo)記者具有專業(yè)知識或編程技術(shù),語料成本更低。通過TAMER+RL(強化學(xué)習(xí)),借助人類標(biāo)記者的反饋,能夠增強從馬爾可夫決策過程?(MDP) 獎勵進(jìn)行強化學(xué)習(xí) (RL) 的過程。
▌ 3.4 ChatGPT的訓(xùn)練
ChatGPT的訓(xùn)練過程分為以下三個階段: 第一階段:訓(xùn)練監(jiān)督策略模型 GPT 3.5本身很難理解人類不同類型指令中蘊含的不同意圖,也很難判斷生成內(nèi)容是否是高質(zhì)量的結(jié)果。 為了讓GPT 3.5初步具備理解指令的意圖,首先會在數(shù)據(jù)集中隨機抽取問題,由人類標(biāo)注人員,給出高質(zhì)量答案,然后用這些人工標(biāo)注好的數(shù)據(jù)來微調(diào) GPT-3.5模型(獲得SFT模型, Supervised Fine-Tuning)。 此時的SFT模型在遵循指令/對話方面已經(jīng)優(yōu)于 GPT-3,但不一定符合人類偏好。
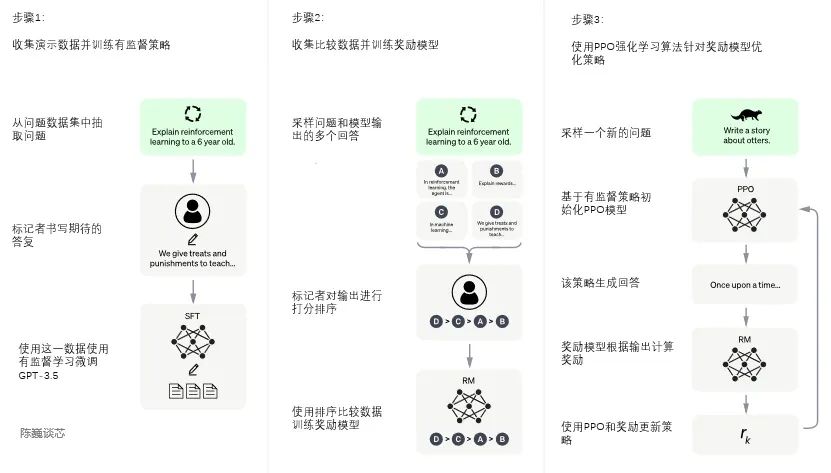
如果我們不斷重復(fù)第二和第三階段,通過迭代,會訓(xùn)練出更高質(zhì)量的ChatGPT模型。
四、ChatGPT的局限
只要用戶輸入問題,ChatGPT 就能給予回答,是否意味著我們不用再拿關(guān)鍵詞去喂 Google或百度,就能立即獲得想要的答案呢?
盡管ChatGPT表現(xiàn)出出色的上下文對話能力甚至編程能力,完成了大眾對人機對話機器人(ChatBot)從“人工智障”到“有趣”的印象改觀,我們也要看到,ChatGPT技術(shù)仍然有一些局限性,還在不斷的進(jìn)步。 1)ChatGPT在其未經(jīng)大量語料訓(xùn)練的領(lǐng)域缺乏“人類常識”和引申能力,甚至?xí)槐菊?jīng)的“胡說八道”。ChatGPT在很多領(lǐng)域可以“創(chuàng)造答案”,但當(dāng)用戶尋求正確答案時,ChatGPT也有可能給出有誤導(dǎo)的回答。例如讓ChatGPT做一道小學(xué)應(yīng)用題,盡管它可以寫出一長串計算過程,但最后答案卻是錯誤的。那我們是該相信ChatGPT的結(jié)果還是不相信呢?

五、ChatGPT的未來改進(jìn)方向
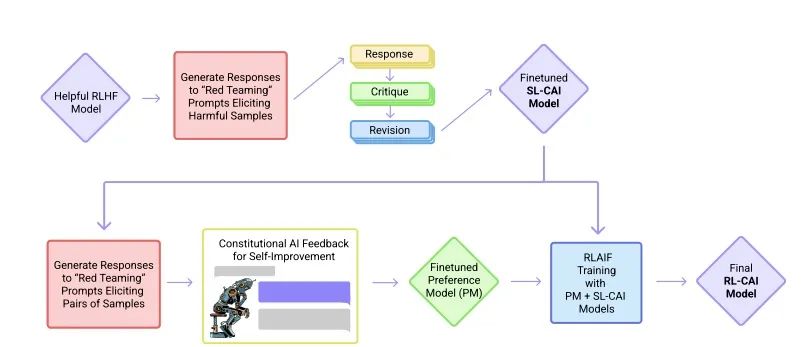
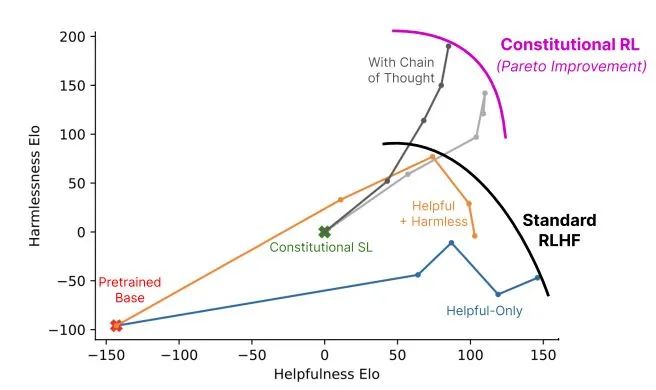
▌ 5.1 減少人類反饋的RLAIF
2020年底,OpenAI前研究副總裁Dario Amodei帶著10名員工創(chuàng)辦了一個人工智能公司Anthropic。 Anthropic 的創(chuàng)始團隊成員,大多為 OpenAI 的早期及核心員工,參與過OpenAI的GPT-3、多模態(tài)神經(jīng)元、人類偏好的強化學(xué)習(xí)等。 2022年12月,Anthropic再次發(fā)表論文《Constitutional AI: Harmlessness from AI Feedback》介紹人工智能模型Claude。(arxiv.org/pdf/2212.0807)
▌ 5.2 補足數(shù)理短板
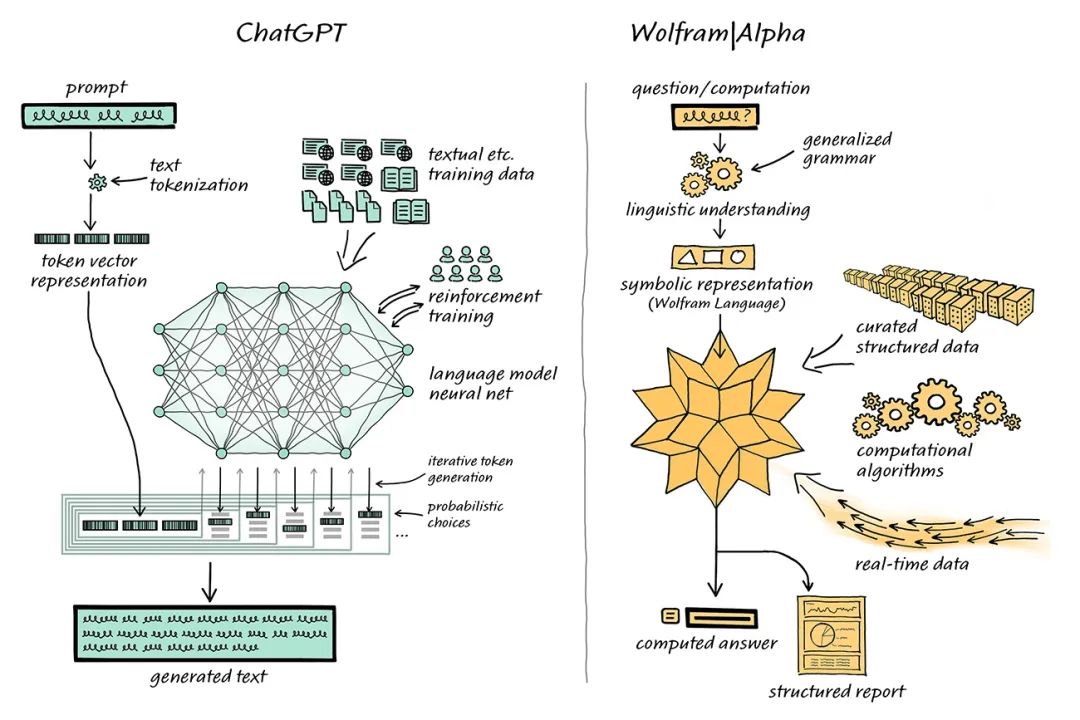
ChatGPT雖然對話能力強,但是在數(shù)理計算對話中容易出現(xiàn)一本正經(jīng)胡說八道的情況。 計算機學(xué)家Stephen Wolfram 為這一問題提出了解決方案。Stephen Wolfram 創(chuàng)造了的 Wolfram 語言和計算知識搜索引擎 Wolfram | Alpha,其后臺通過Mathematica實現(xiàn)。
▌ 5.3 ChatGPT的小型化
雖然ChatGPT很強大,但其模型大小和使用成本也讓很多人望而卻步。 有三類模型壓縮(model compression)可以降低模型的大小和成本。 第一種方法是量化(quantization),即降低單個權(quán)重的數(shù)值表示的精度。比如Tansformer從FP32降到INT8對其精度影響不大。 第二種模型壓縮方法是剪枝(pruning),即刪除網(wǎng)絡(luò)元素,包括從單個權(quán)重(非結(jié)構(gòu)化剪枝)到更高粒度的組件如權(quán)重矩陣的通道。這種方法在視覺和較小規(guī)模的語言模型中有效。 第三種模型壓縮方法是稀疏化。例如奧地利科學(xué)技術(shù)研究所 (ISTA)提出的SparseGPT (arxiv.org/pdf/2301.0077)可以將 GPT 系列模型單次剪枝到 50% 的稀疏性,而無需任何重新訓(xùn)練。對 GPT-175B 模型,只需要使用單個 GPU 在幾個小時內(nèi)就能實現(xiàn)這種剪枝。
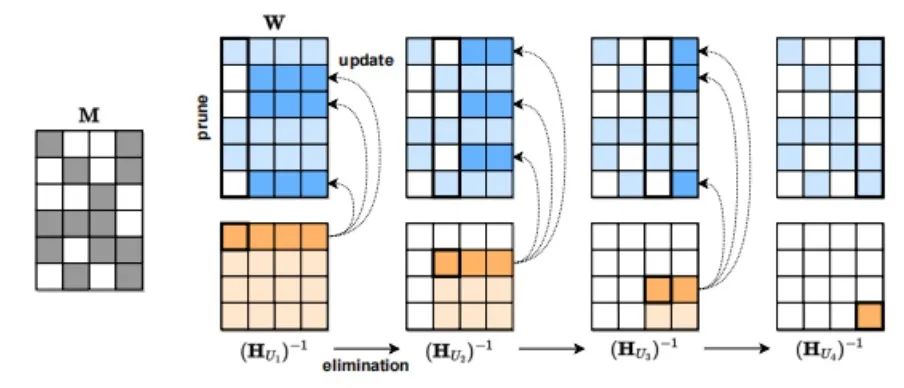
SparseGPT 壓縮流程
六、ChatGPT的產(chǎn)業(yè)未來與投資機會
▌ 6.1 AIGC
說到ChaGPT不得不提AIGC。 AIGC即利用人工智能技術(shù)來生成內(nèi)容。與此前Web1.0、Web2.0時代的UGC(用戶生產(chǎn)內(nèi)容)和PGC(專業(yè)生產(chǎn)內(nèi)容)相比,代表人工智能構(gòu)思內(nèi)容的AIGC,是新一輪內(nèi)容生產(chǎn)方式變革,而且AIGC內(nèi)容在Web3.0時代也將出現(xiàn)指數(shù)級增長。 ChatGPT 模型的出現(xiàn)對于文字/語音模態(tài)的 AIGC 應(yīng)用具有重要意義,會對AI產(chǎn)業(yè)上下游產(chǎn)生重大影響。▌ 6.2 受益場景
從下游相關(guān)受益應(yīng)用來看,包括但不限于無代碼編程、小說生成、對話類搜索引擎、語音陪伴、語音工作助手、對話虛擬人、人工智能客服、機器翻譯、芯片設(shè)計等。 從上游增加需求來看,包括算力芯片、數(shù)據(jù)標(biāo)注、自然語言處理(NLP)等。
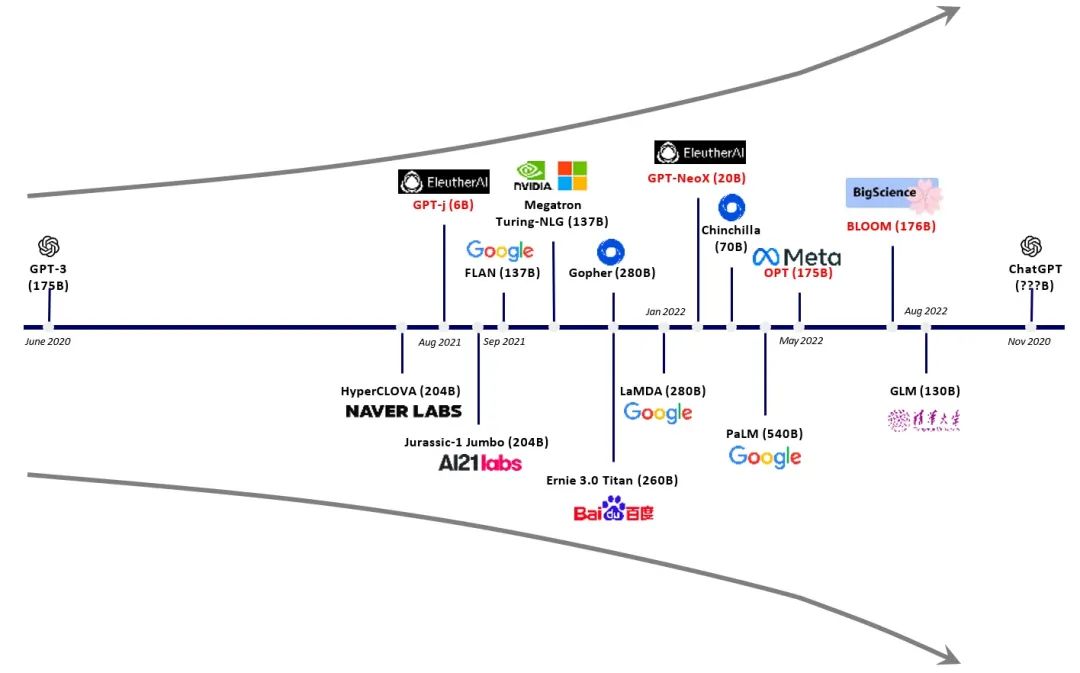
大模型呈爆發(fā)態(tài)勢(更多的參數(shù)/更大的算力芯片需求)
隨著算法技術(shù)和算力技術(shù)的不斷進(jìn)步,ChatGPT也會進(jìn)一步走向更先進(jìn)功能更強的版本,在越來越多的領(lǐng)域進(jìn)行應(yīng)用,為人類生成更多更美好的對話和內(nèi)容。 最后,作者問存算一體技術(shù)在ChatGPT領(lǐng)域的地位(作者本人目前在重點推進(jìn)存算一體芯片的產(chǎn)品落地),ChatGPT想了想,大膽的預(yù)言存算一體技術(shù)將在ChatGPT芯片中占據(jù)主導(dǎo)地位。(深得我心 )
)

參考文獻(xiàn):
-
ChatGPT: Optimizing Language Models for Dialogue?ChatGPT: Optimizing Language Models for Dialogue
-
GPT論文:Language Models are Few-Shot Learners Language Models are Few-Shot Learners
-
InstructGPT論文:Training language models to follow instructions with human feedback Training language models to follow instructions with human feedback
-
huggingface解讀RHLF算法:Illustrating Reinforcement Learning from Human Feedback (RLHF) Illustrating Reinforcement Learning from Human Feedback (RLHF)
-
RHLF算法論文:Augmenting Reinforcement Learning with Human Feedback cs.utexas.edu/~ai-lab/p
-
TAMER框架論文:Interactively Shaping Agents via Human Reinforcement cs.utexas.edu/~bradknox
-
PPO算法:Proximal Policy Optimization Algorithms Proximal Policy Optimization Algorithms
近期原創(chuàng):本文作者:陳巍博士,曾擔(dān)任華為系自然語言處理(NLP)企業(yè)的首席科學(xué)家,文章首發(fā)于「先進(jìn)AI技術(shù)深入解讀」。?
原文鏈接:https://zhuanlan.zhihu.com/p/590655677
寫了個監(jiān)控 ElasticSearch 進(jìn)程異常的腳本!
太強了!利用 Python 寫了一個監(jiān)控服務(wù)器資源利用率的腳本!
