作者 | _陳哈哈
來源 | blog.csdn.net/qq_39390545/article/details/106946166
記得去年我在往MySQL存入emoji表情????時,一直出錯,無法導入。后來找到辦法 -- 通過把 utf8 改成 utf8mb4 就可以了,并沒有深究。
一年后,我看到一篇文章講到emoji文字占4個字節(jié),通常要用utf-8去接收才行,其他編碼可能會出錯。我突然想到去年操作MySQL把utf8改成utf8mb4的事兒。嗯?他本身不就是utf8編碼么!那我當時還改個錘子?難道,MySQL的utf8不是真正的UTF-8編碼嗎??! 臥槽這。。MySQL有bug!帶著疑問查詢了很多相關材料,才發(fā)現(xiàn)這竟然是MySQL的一個歷史遺留問題~~ 我笑了,沒想到這么牛B的MySQL也會有這段往事。將emoji文字直接寫入SQL中,執(zhí)行 insert 語句報錯;INSERT INTO `csjdemo`.`student` (`ID`, `NAME`, `SEX`, `AGE`, `CLASS`, `GRADE`, `HOBBY`)
VALUES ('20', '陳哈哈??', '男', '20', '181班', '9年級', '看片兒');
[Err] 1366 - Incorrect string value: '\xF0\x9F\x98\x93' for column 'NAME' at row 1
改了數(shù)據(jù)庫編碼、系統(tǒng)編碼以及表字段的編碼格式 → utf8mb4 之后,就可以了:INSERT INTO `student` (`ID`, `NAME`, `SEX`, `AGE`, `CLASS`, `GRADE`, `HOBBY`)
VALUES (null, '陳哈哈????', '男', '20', '181班', '9年級', '看片兒');
MySQL 的“utf8”實際上不是真正的 UTF-8。在MySQL中,“utf8”編碼只支持每個字符最多三個字節(jié),而真正的 UTF-8 是每個字符最多四個字節(jié)。
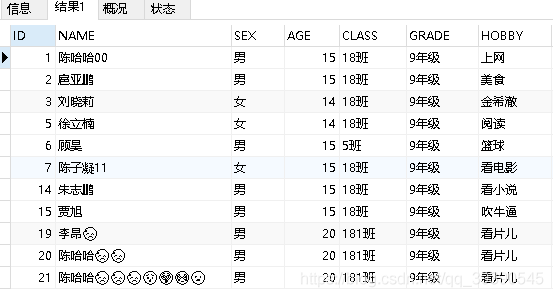
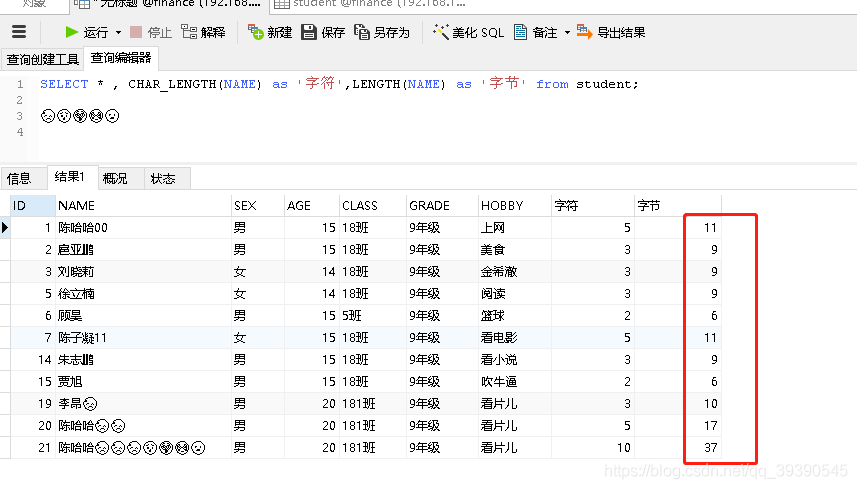
在utf8編碼中,中文是占3個字節(jié),其他數(shù)字、英文、符號占一個字節(jié)。但emoji符號占4個字節(jié),一些較復雜的文字、繁體字也是4個字節(jié)。所以導致寫入失敗,應該改成utf8mb4。如上圖中所示,這是編碼改成utf8mb4后入庫的數(shù)據(jù),大家可以清晰的對比一下所占的字符數(shù)、字節(jié)數(shù)。正因如此,4字節(jié)的內(nèi)容往utf8編碼中插入,肯定是不行的,插不進去啊,是吧(大潘攤手)。MySQL 一直沒有修復這個 bug,他們在 2010 年發(fā)布了一個叫作“utf8mb4”的字符集,巧妙的繞過了這個問題。當然,他們并沒有對新的字符集廣而告之(可能是因為這個 bug 讓他們覺得很尷尬),以致于現(xiàn)在網(wǎng)絡上仍然在建議開發(fā)者使用“utf8”,但這些建議都是錯誤的。1. utf8mb4 才是真正的UTF-8
是的,MySQL 的“utf8mb4”才是真正的“UTF-8”。MySQL 的“utf8”是一種“專屬的編碼”,它能夠編碼的 Unicode 字符并不多。在這里Mark一下:所有在使用“utf8”的 MySQL 和 MariaDB 用戶都應該改用“utf8mb4”,永遠都不要再使用“utf8”。我們都知道,計算機使用 0 和 1 來存儲文本。比如字符“C”被存成“01000011”,那么計算機在顯示這個字符時需要經(jīng)過兩個步驟:計算機讀取“01000011”,得到數(shù)字 67,因為 67 被編碼成“01000011”。
計算機在 Unicode 字符集中查找 67,找到了“C”。
我的電腦將“C”映射成 Unicode 字符集中的 67。
我的電腦將 67 編碼成“01000011”,并發(fā)送給 Web 服務器。
幾乎所有的網(wǎng)絡應用都使用了 Unicode 字符集,因為沒有理由使用其他字符集。Unicode 字符集包含了上百萬個字符。最簡單的編碼是 UTF-32,每個字符使用 32 位。這樣做最簡單,因為一直以來,計算機將 32 位視為數(shù)字,而計算機最在行的就是處理數(shù)字。但問題是,這樣太浪費空間了。UTF-8 可以節(jié)省空間,在 UTF-8 中,字符“C”只需要 8 位,一些不常用的字符,比如“??”需要 32 位。其他的字符可能使用 16 位或 24 位。一篇類似本文這樣的文章,如果使用 UTF-8 編碼,占用的空間只有 UTF-32 的四分之一左右。2. utf8 的簡史
為什么 MySQL 開發(fā)者會讓“utf8”失效? 我們或許可以從MySQL版本提交日志中尋找答案。MySQL 從 4.1 版本開始支持 UTF-8,也就是 2003 年,而今天使用的 UTF-8 標準(RFC 3629)是隨后才出現(xiàn)的。舊版的 UTF-8 標準(RFC 2279)最多支持每個字符 6 個字節(jié)。2002 年 3 月 28 日,MySQL 開發(fā)者在第一個 MySQL 4.1 預覽版中使用了 RFC 2279。同年 9 月,他們對 MySQL 源代碼進行了一次調(diào)整:“UTF8 現(xiàn)在最多只支持 3 個字節(jié)的序列”。是誰提交了這些代碼?他為什么要這樣做?這個問題不得而知。在遷移到 Git 后(MySQL 最開始使用的是 BitKeeper),MySQL 代碼庫中的很多提交者的名字都丟失了。2003 年 9 月的郵件列表中也找不到可以解釋這一變更的線索。2002年,MySQL做出了一個決定:如果用戶可以保證數(shù)據(jù)表的每一行都使用相同的字節(jié)數(shù),那么 MySQL 就可以在性能方面來一個大提升。為此,用戶需要將文本列定義為“CHAR”,每個“CHAR”列總是擁有相同數(shù)量的字符。如果插入的字符少于定義的數(shù)量,MySQL 就會在后面填充空格,如果插入的字符超過了定義的數(shù)量,后面超出部分會被截斷。MySQL 開發(fā)者在最開始嘗試 UTF-8 時使用了每個字符6個字節(jié),CHAR(1) 使用6個字節(jié),CHAR(2)使用12個字節(jié),并以此類推。應該說,他們最初的行為才是正確的,可惜這一版本一直沒有發(fā)布。但是文檔上卻這么寫了,而且廣為流傳,所有了解 UTF-8 的人都認同文檔里寫的東西。不過很顯然,MySQL 開發(fā)者或廠商擔心會有用戶做這兩件事:我的猜測是 MySQL 開發(fā)者本來想幫助那些希望在空間和速度上雙贏的用戶,但他們搞砸了“utf8”編碼。所以結(jié)果就是沒有贏家。那些希望在空間和速度上雙贏的用戶,當他們在使用“utf8”的 CHAR 列時,實際上使用的空間比預期的更大,速度也比預期的慢。而想要正確性的用戶,當他們使用“utf8”編碼時,卻無法保存像“??”這樣的字符,因為“??”是4個字節(jié)的。在這個不合法的字符集發(fā)布了之后,MySQL 就無法修復它,因為這樣需要要求所有用戶重新構(gòu)建他們的數(shù)據(jù)庫。最終,MySQL 在 2010 年重新發(fā)布了“utf8mb4”來支持真正的 UTF-8。主要是目前網(wǎng)絡上幾乎所有的文章都把 “utf8” 當成是真正的 UTF-8,包括之前我寫的文章以及做的項目(捂臉);因此希望更多的朋友能夠看到這篇文章。所以,大家以后再搭建MySQL、MariaDB數(shù)據(jù)庫時,記得將數(shù)據(jù)庫相應編碼都改為utf8mb4。終有一天,接你班兒的程序員發(fā)或你的領導現(xiàn)這個問題后,一定會在心里默默感到你的技術牛B。