
講講大廠面試必考的假設(shè)檢驗(yàn)

假設(shè)檢驗(yàn)的核心其實(shí)就是反證法。反證法是數(shù)學(xué)中的一個(gè)概念,就是你要證明一個(gè)結(jié)論是正確的,那么先假設(shè)這個(gè)結(jié)論是錯(cuò)誤的,然后以這個(gè)結(jié)論是錯(cuò)誤的為前提條件進(jìn)行推理,推理出來(lái)的結(jié)果與假設(shè)條件矛盾,這個(gè)時(shí)候就說(shuō)明這個(gè)假設(shè)是錯(cuò)誤的,也就是這個(gè)結(jié)論是正確的。以上就是反證法的一個(gè)簡(jiǎn)單思路。
了解完反證法以后,我們開(kāi)始正式的假設(shè)檢驗(yàn),這里還是引用一個(gè)大家都很熟悉的一個(gè)例子『女士品茶』。
女士品茶是一個(gè)很久遠(yuǎn)的故事,講述了在很久很久以前的一個(gè)下午,有一群人在那品茶,這個(gè)時(shí)候有位女士提出了一個(gè)有趣的點(diǎn),就是把茶加到奶里和把奶加到茶里面最后得到的『奶茶』的味道是不一樣的。大部分人都覺(jué)得這位女士在瞎說(shuō),只有其中一位男士提出了要用科學(xué)的方法去證明到底一樣不一樣(牛人想問(wèn)題角度永遠(yuǎn)都是那么獨(dú)特,多想想別人為什么那么說(shuō),而不是一上來(lái)就不經(jīng)思考的拒絕)。
接下來(lái),我們具體看一下這一位男士是怎么去證明的。首先他假設(shè)了把茶加到奶里和把奶加到茶里面得出來(lái)的『奶茶』味道是一樣的。然后隨機(jī)把這兩種『奶茶』端給女士,讓女士品,是先加的奶還是先加的茶,如果女士都能品對(duì),說(shuō)明確實(shí)有差異,如果品不對(duì),說(shuō)明是沒(méi)差異的。這里面就涉及到一個(gè)問(wèn)題,讓女士品多少杯呢,品一杯肯定是不行的,因?yàn)槿我庖槐聦?duì)(瞎蒙)的概率都有50%。下面是不同杯數(shù)對(duì)應(yīng)的猜對(duì)的概率(注意,這里是猜對(duì)而不是品對(duì))。
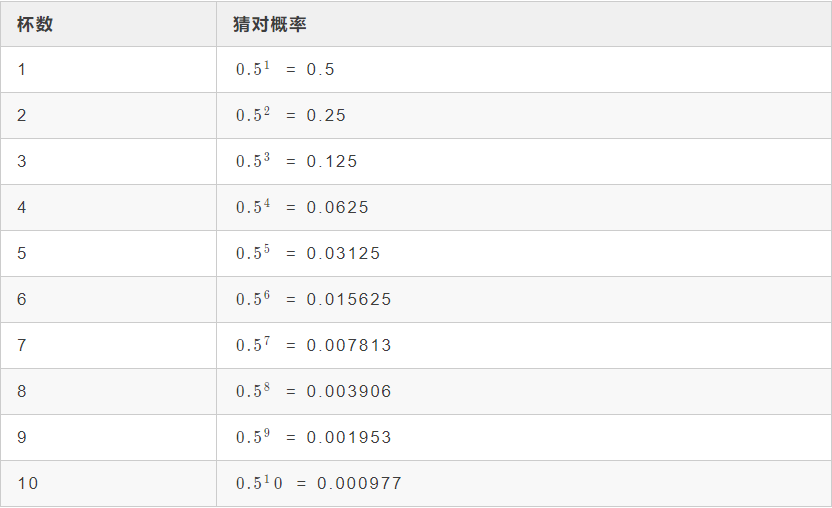
通過(guò)上表我們可以看出,連續(xù)4杯都猜對(duì)的概率不足0.1,連續(xù)10杯都猜對(duì)的概率不足0.001。如果把奶加到茶里和把茶加到奶里面得到的『奶茶』真沒(méi)有差別,也就是女士要想品對(duì),基本全靠猜,但是10杯全部猜對(duì)的概率不足0.001,我們把這種概率很小很小(這里需要定義一下,具體多小算小概率事件)的事件稱為小概率事件。我們認(rèn)為小概率事件一般是不會(huì)發(fā)生的,如果發(fā)生了,說(shuō)明我們的認(rèn)知就是錯(cuò)誤的,也就是說(shuō)女士品茶不是靠猜的,也就是把奶加到茶里和把茶加到奶里面得到的『奶茶』的確是有差別的。
我們把上面這個(gè)過(guò)程就叫做假設(shè)檢驗(yàn)。
了解完假設(shè)檢驗(yàn)的思想以后,我們來(lái)看一下具體步驟:
step1:提出零假設(shè)和備擇假設(shè);
零假設(shè)(H0)一般是我們要推翻的論點(diǎn),備擇假設(shè)(H1)則是我們要證明的論點(diǎn)。拿上面的女士品茶例子來(lái)講。
H0:把茶加到奶里和把奶加到茶里面得到的『奶茶』是一樣的。
H0:把茶加到奶里和把奶加到茶里面得到的『奶茶』是不一樣的。
step2:構(gòu)造檢驗(yàn)統(tǒng)計(jì)量,并找出在H0假設(shè)成立的前提下,該統(tǒng)計(jì)量所服從的分布;
檢驗(yàn)統(tǒng)計(jì)量是根據(jù)樣本觀測(cè)結(jié)果計(jì)算得到的樣本統(tǒng)計(jì)量,并以此對(duì)零假設(shè)和備擇假設(shè)做出決策。

圖片來(lái)源于網(wǎng)絡(luò)
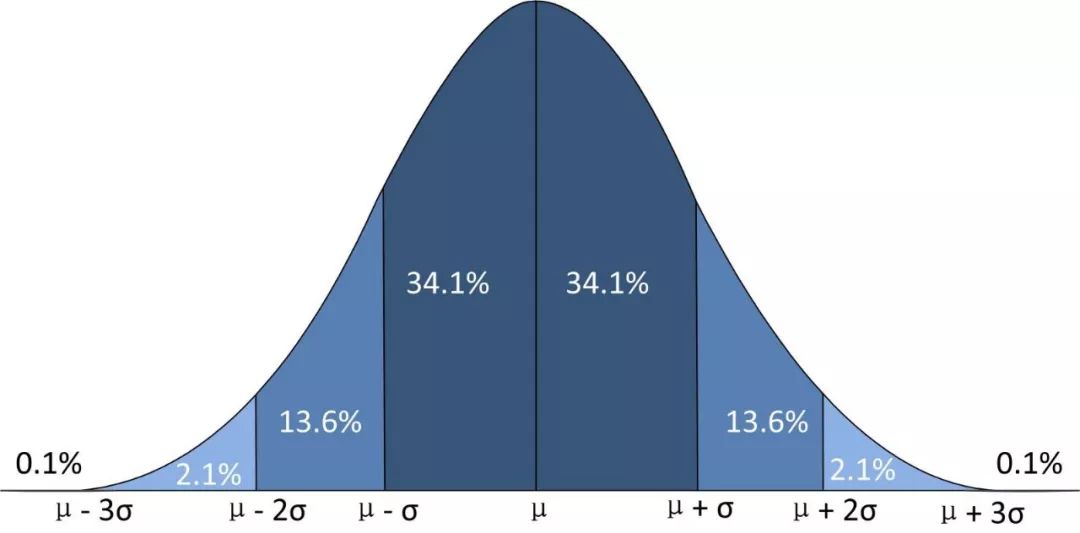
上面圖片中是三種不同的統(tǒng)計(jì)量以及其對(duì)應(yīng)的分布,分別叫做Z檢驗(yàn)、T建議、卡方檢驗(yàn)。Z檢驗(yàn):一般用于大樣本(即樣本容量大于30)平均值差異性檢驗(yàn)的方法。它是用標(biāo)準(zhǔn)正態(tài)分布的理論來(lái)推斷差異發(fā)生的概率,從而比較兩個(gè)平均數(shù)的差異是否顯著。在國(guó)內(nèi)也被稱作u檢驗(yàn)。
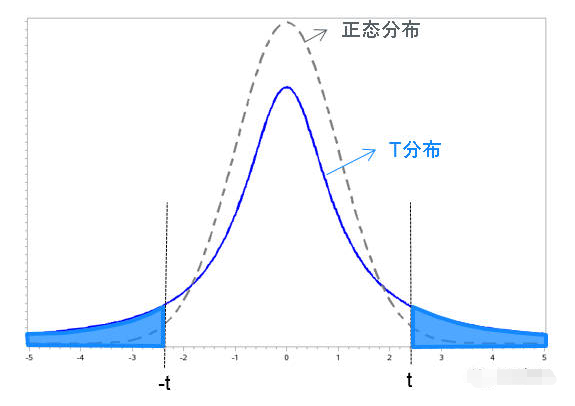
T檢驗(yàn):主要用于樣本含量較小(例如n < 30),總體標(biāo)準(zhǔn)差σ未知的正態(tài)分布。T檢驗(yàn)是用t分布理論來(lái)推論差異發(fā)生的概率,從而比較兩個(gè)平均數(shù)的差異是否顯著。
卡方檢驗(yàn):卡方檢驗(yàn)是統(tǒng)計(jì)樣本的實(shí)際觀測(cè)值與理論推斷值之間的偏離程度,實(shí)際觀測(cè)值與理論推斷值之間的偏離程度就決定卡方值的大小,如果卡方值越大,二者偏差程度越大;反之,二者偏差越小;若兩個(gè)值完全相等時(shí),卡方值就為0,表明理論值完全符合。
下面為三種檢驗(yàn)對(duì)應(yīng)的分布圖:
正態(tài)分布
根據(jù)不同檢驗(yàn)的特征,我們可以根據(jù)下圖來(lái)進(jìn)行選擇合適的檢驗(yàn)方式:
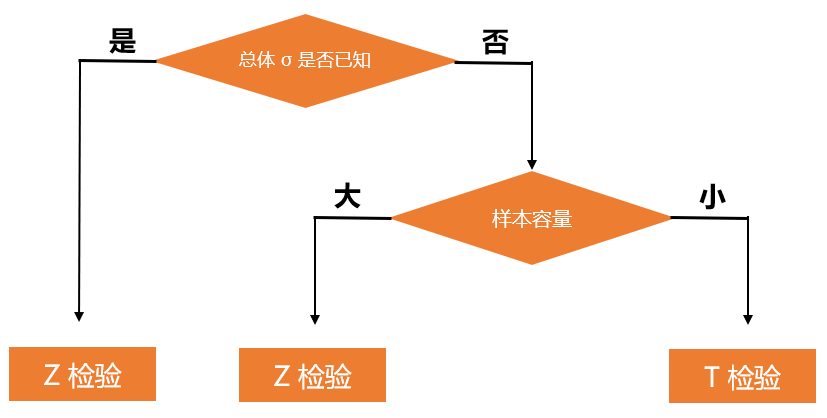
step3:根據(jù)要求的顯著性水平,求臨界值和拒絕域
還記得我們?cè)谇懊嫣岬降男「怕适录幔咳绻「怕适录l(fā)生了,就表示我們的零假設(shè)是錯(cuò)誤的,可是具體多小的概率才算是小概率呢?一般這個(gè)概率為0.05,也就是5%,如果一件事情發(fā)生的概率小于等于5%,我們就認(rèn)為這是一個(gè)小概率事件,0.05就是顯著性水平,用α表示。顯著性水平把概率分布分為兩個(gè)區(qū)間:拒絕區(qū)間和接受區(qū)間,最后計(jì)算出來(lái)的結(jié)果落在拒絕區(qū)間,我們就可以拒絕零假設(shè);如果落在了接受區(qū)間,我們就需要接受零假設(shè)。1-α稱為置信水平(置信度)。
現(xiàn)在我們知道了顯著性水平了,然后就可以根據(jù)顯著性水平求得臨界值和拒絕域了。那具體怎么求呢?這里的臨界值就是z值(正太分布用z值)或t值(t分布用t值),以臨界值為端點(diǎn)的區(qū)間稱為拒絕域。z值和t值直接根據(jù)顯著性水平然后到對(duì)應(yīng)的z值表和t值表中查詢即可。
下圖為雙側(cè)檢驗(yàn)和單側(cè)檢驗(yàn)對(duì)應(yīng)的α、1-α、臨界值、拒絕域、接受域的情況,其中α是表示陰影部分的面積,而不是x軸的值。
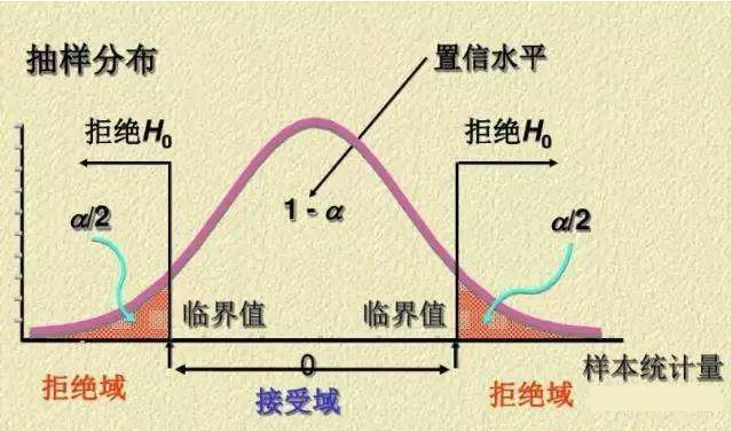
雙側(cè)檢驗(yàn)

到這里顯著性水平對(duì)應(yīng)的臨界值和拒絕域就算出來(lái)了。
step4:計(jì)算檢驗(yàn)統(tǒng)計(jì)量
根據(jù)我們?cè)谇懊孢x擇檢驗(yàn)統(tǒng)計(jì)量類型,計(jì)算對(duì)應(yīng)的檢驗(yàn)統(tǒng)計(jì)量的值。除此之外我們還可以根據(jù)樣本量得出P值,P值就是實(shí)際樣本中小概率事件的具體概率值。
step5:決策
比較計(jì)算出來(lái)的檢驗(yàn)統(tǒng)計(jì)量與臨界值和拒絕域,如果值落在了拒絕域內(nèi),那我們就要拒絕零假設(shè),否則接受零假設(shè)。
比較計(jì)算出來(lái)的P值和顯著性水平α值,如果P值小于等于α,則拒絕零假設(shè),否則接受原假設(shè)。
上面兩種方法分別叫做統(tǒng)計(jì)量檢驗(yàn)和P值檢驗(yàn)。
以上就是假設(shè)檢驗(yàn)的一般流程。除此之外,假設(shè)檢驗(yàn)里面還有兩種錯(cuò)誤,第一類錯(cuò)誤叫做棄真錯(cuò)誤,通俗一點(diǎn)就是漏診,就是本來(lái)是生病了(假設(shè)是正確的),但是你沒(méi)有檢測(cè)出來(lái),所以給拒絕掉了;第二類錯(cuò)誤是取偽錯(cuò)誤,通俗一點(diǎn)就是誤診,就是本來(lái)沒(méi)病(假設(shè)是錯(cuò)誤的),結(jié)果你診斷說(shuō)生病了(假設(shè)是正確的),所以就把假設(shè)給接受了。
| 最終判斷 | H0本來(lái)正確 | H0本來(lái)錯(cuò)誤 |
|---|---|---|
| 拒絕H0假設(shè) | 犯I型錯(cuò)誤 | 正確 |
| 接受H0假設(shè) | 正確 | 犯II錯(cuò)誤 |
I型錯(cuò)誤的值一般為0.05,II型錯(cuò)誤的值一般為0.1或0.2,除此之外還有一個(gè)指標(biāo)叫做功效(power),power = 1 - II型錯(cuò)誤的值,power 表示你有多大把握能夠正確的拒絕你的零假設(shè)H0。

比Excel,輕松學(xué)習(xí)SQL數(shù)據(jù)分析.jpg")
▊《對(duì)比Excel,輕松學(xué)習(xí)SQL數(shù)據(jù)分析》
張俊紅 著
學(xué)習(xí)SQL 的主要原因是工作需要。網(wǎng)上關(guān)于數(shù)據(jù)相關(guān)崗位的招聘都要求有熟練使用SQL 這一條,為什么會(huì)這樣呢?這是因?yàn)槲覀冐?fù)責(zé)的是與數(shù)據(jù)相關(guān)的工作,而獲取數(shù)據(jù)是我們工作的第一步,比如,你要通過(guò)數(shù)據(jù)做決策,但是現(xiàn)在公司的數(shù)據(jù)基本上不存儲(chǔ)在本地Excel 表中,而是存儲(chǔ)在數(shù)據(jù)庫(kù)中,想要從數(shù)據(jù)庫(kù)中獲取數(shù)據(jù)就需要使用SQL,所以熟練使用SQL 成了數(shù)據(jù)相關(guān)從業(yè)者入職的必要條件。本書(shū)的所有代碼和函數(shù)均以MySQL 8.0 為主。
(掃碼了解本書(shū)詳情)
如果喜歡本文 歡迎 在看丨留言丨分享至朋友圈 三連 熱文推薦
▼點(diǎn)擊閱讀原文,獲取本書(shū)詳情~