七行代碼實(shí)現(xiàn)OCR圖片轉(zhuǎn)文字
↑?關(guān)注 + 星標(biāo)?,每天學(xué)Python新技能
后臺回復(fù)【大禮包】送你Python自學(xué)大禮包

tesseract簡介
OCR,即Optical Character Recognition,光學(xué)字符識別,是指通過掃描字符,然后通過其形狀將其翻譯成電子文本的過程。
下載安裝包
tesseract下載地址:https://digi.bib.uni-mannheim.de/tesseract/
進(jìn)入下載頁面。
可以看到有各種.exe文件的下載列表,根據(jù)自己需求下載(其中文件名中帶有dev的為開發(fā)版本,不帶dev的為穩(wěn)定版本,可以選擇下載不帶dev的版本,例如可以選擇下載tesseract-ocr-setup-4.0.0-alpha.20170804。)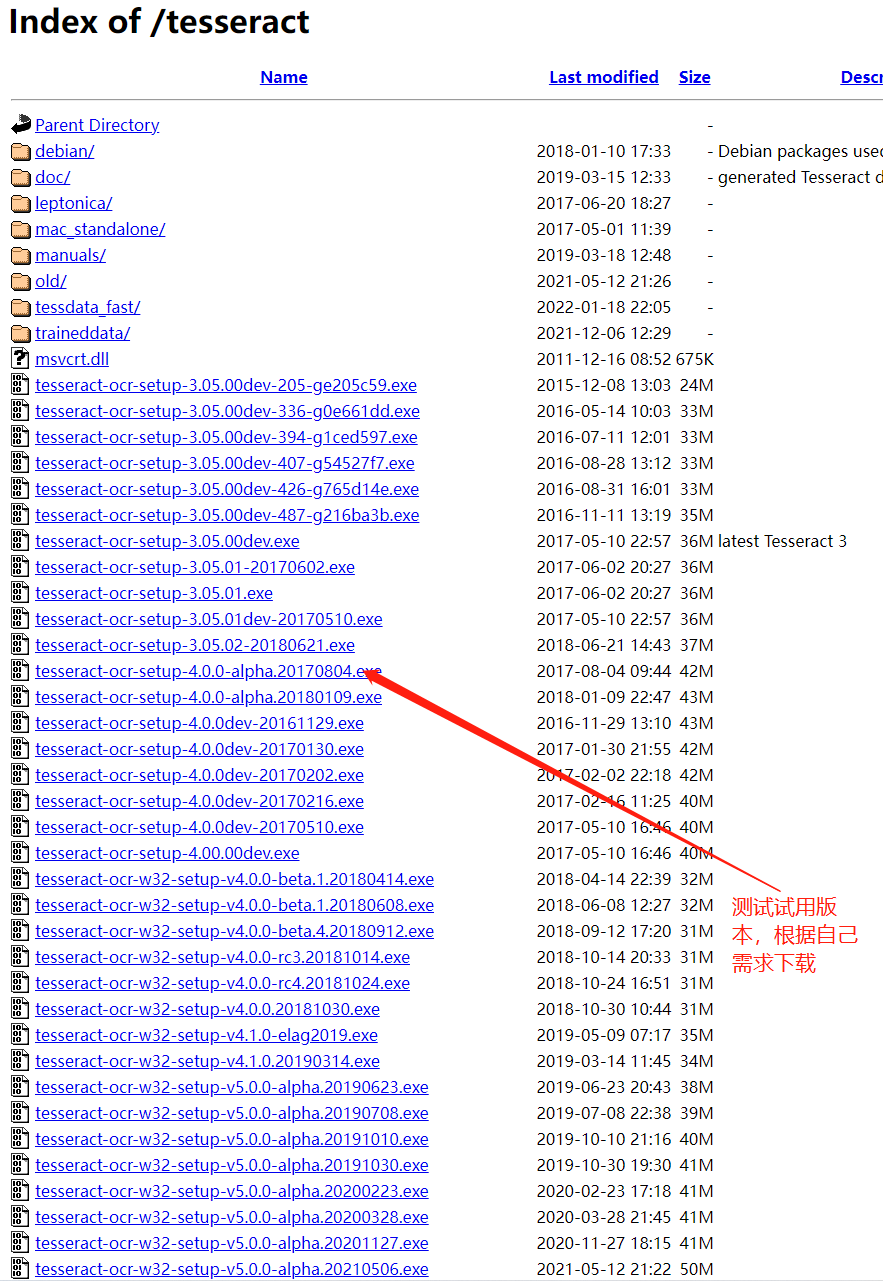
安裝
下載后傻瓜式安裝即可。
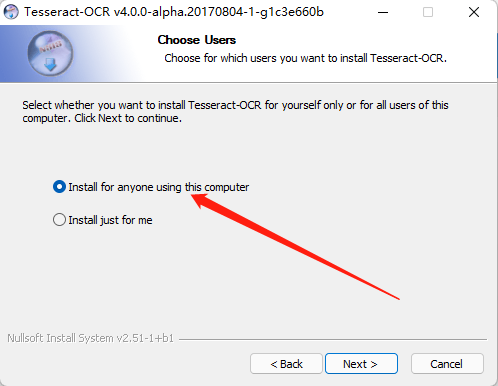
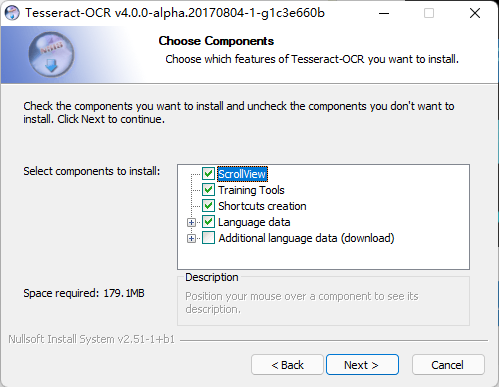
這里選擇語言包,簡體中文(但勾選語言包較多時(shí)下載較慢,本人建議直接安裝,安裝后根據(jù)需要再去下載語言包。)
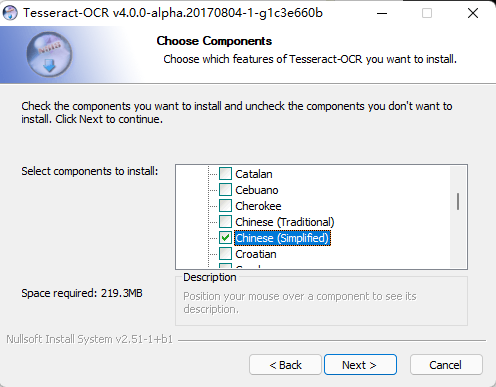
選擇合適的安裝路徑完成安裝。

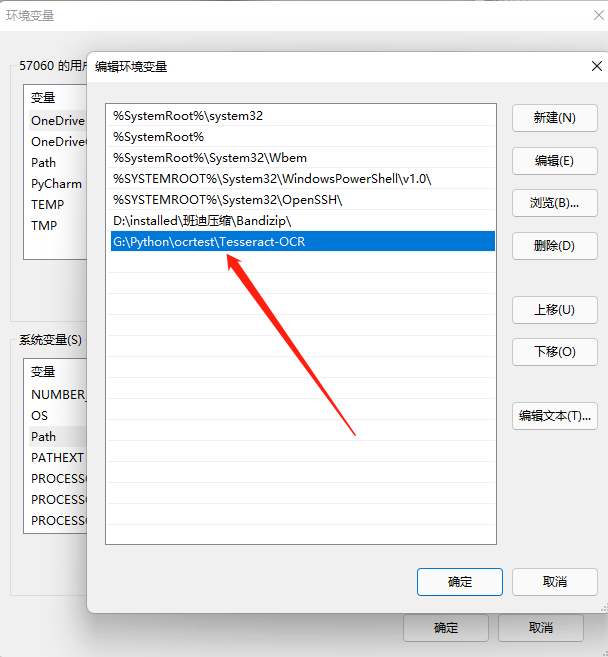
環(huán)境變量配置
設(shè)置環(huán)境變量,進(jìn)入環(huán)境變量中,找path,新建路徑。如圖:
測試
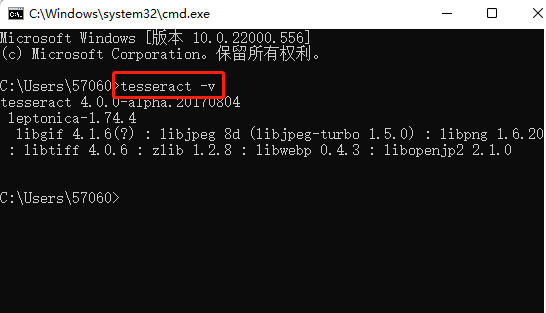
查看是否安裝成功,打開cmd,輸入tesseract?-v回車,若顯示版本號即為安裝成功。如圖:
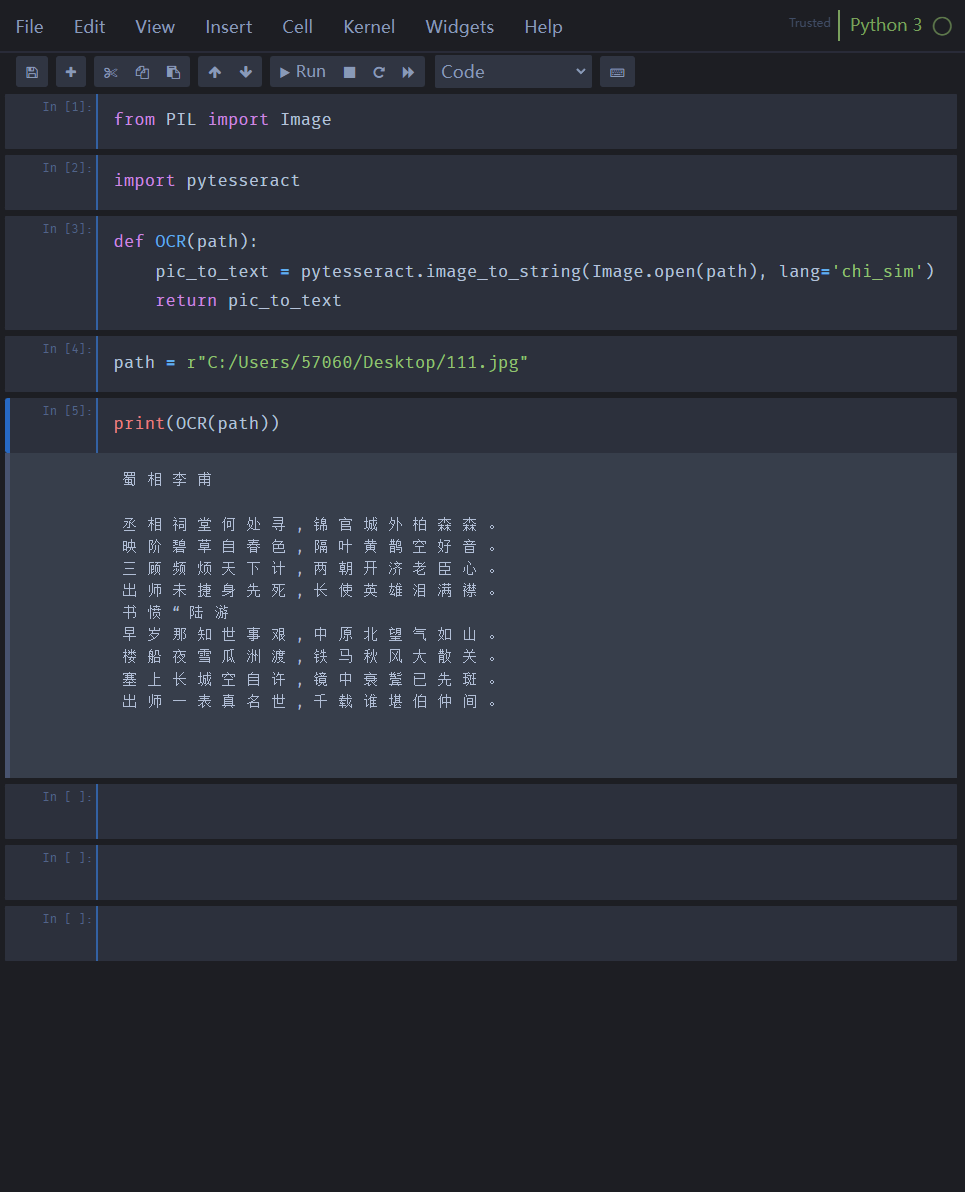
測試文件
我在網(wǎng)上隨便找了兩首古詩竟是文字識別測試,如下

python庫
所需第三方庫安裝方式
# pytesseract安裝:
pip?install?pytesseract
# PIL安裝:
pip?install?pillow測試結(jié)果
短短七行代碼即可實(shí)現(xiàn)圖片轉(zhuǎn)文字,結(jié)果如下:
問題匯總
Tesseract在安裝過程中出現(xiàn)Download error Status of equ: Send Request Error. Click OK to continue!!!已解決
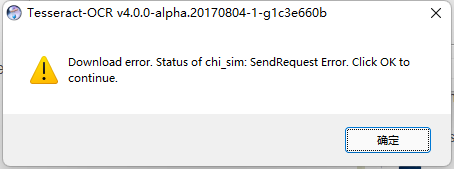
出錯(cuò)的原因應(yīng)該是,墻的問題,,請求失敗,嘗試管理員身份還是失敗,,,既然download失敗,那么就換種方式下載
Github上下載自己需要的語言包
https://tesseract-ocr.github.io/tessdoc/Data-Files?,
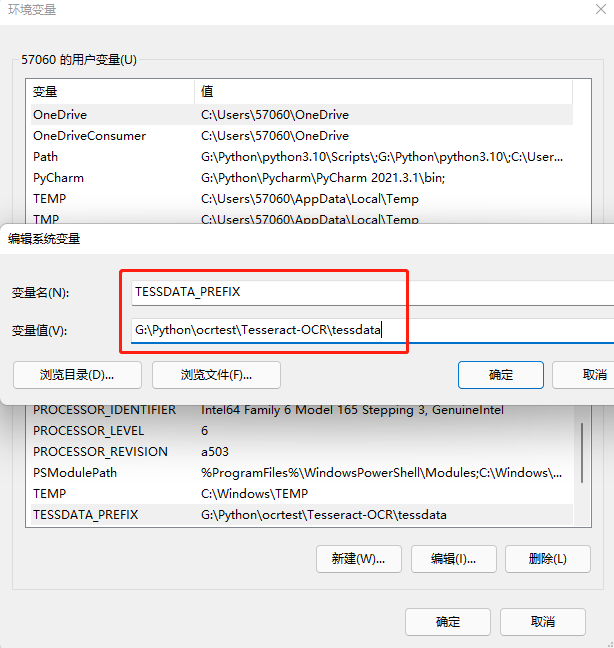
獲取到語言包后直接解壓,并且再次配置環(huán)境變量如下:
點(diǎn)擊我的電腦–>屬性–>高級設(shè)置—>環(huán)境變量---->path下面的—>新建—>變量名:TESSDATA_PREFIX---->變量值:前面的加上\tessdata
將下載好的語言包解壓,打開tessdata文件夾

然后將其復(fù)制到tessdata中。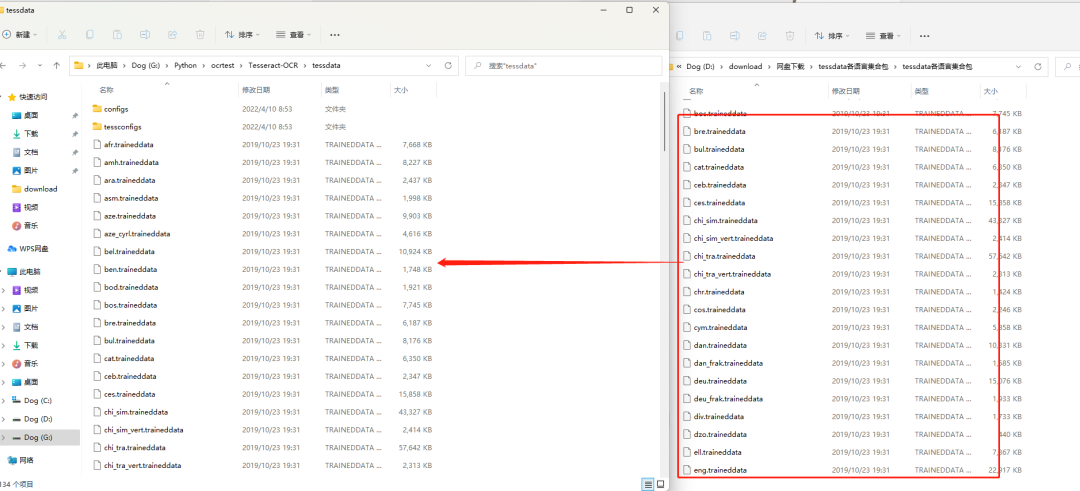
最后,重啟一下電腦!!!!
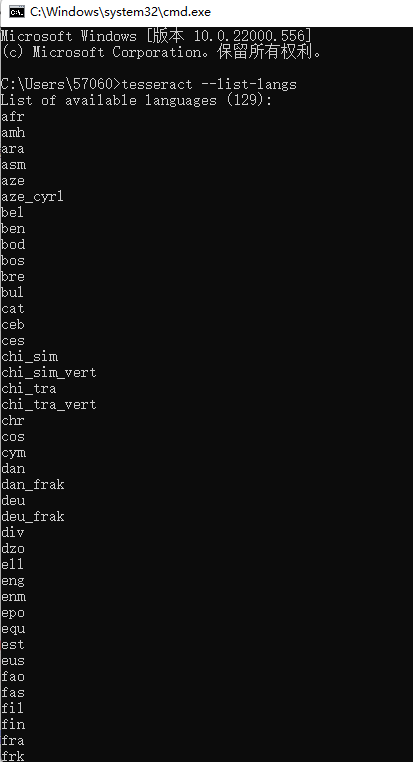
然后win+R 快捷打開cmd,輸入tesseract --list-langs 就可,就可以看到所有的語言類型了。