
在大規(guī)模 Kubernetes 集群上實(shí)現(xiàn)高 SLO 的方法
螞蟻金服高級(jí)開(kāi)發(fā)工程師 范康
導(dǎo)讀:隨著 Kubernetes 集群規(guī)模和復(fù)雜性的增加,集群越來(lái)越難以保證高效率、低延遲的交付 pod。本文將分享螞蟻金服在設(shè)計(jì) SLO?架構(gòu)和實(shí)現(xiàn)高 SLO 的方法和經(jīng)驗(yàn)。
態(tài)黑色音符")
Why SLO?
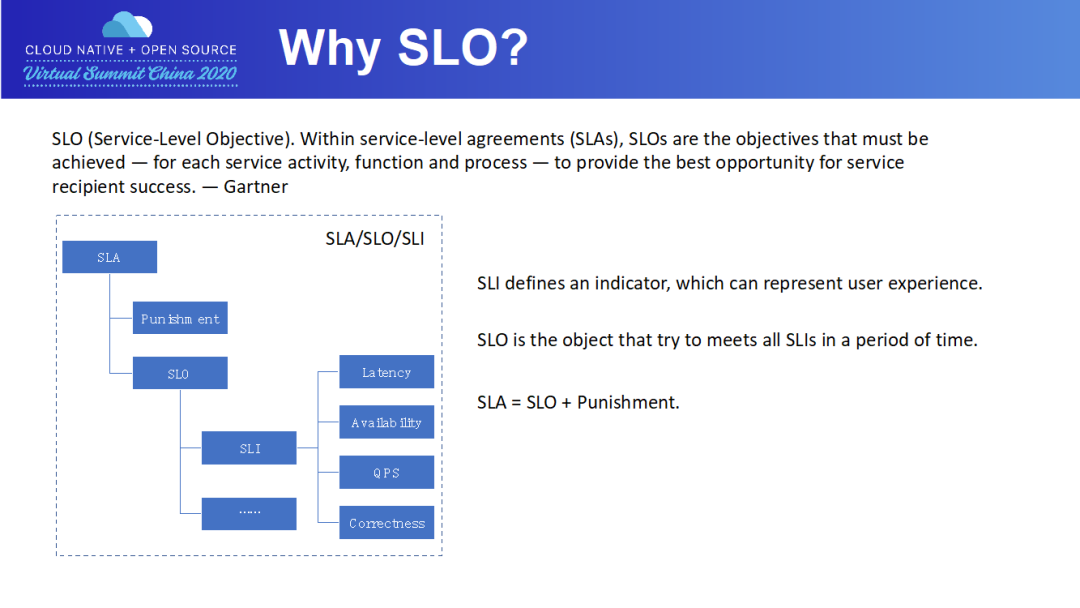
SLI 定義一個(gè)指標(biāo),來(lái)描述一個(gè)服務(wù)有多好算達(dá)到好的標(biāo)準(zhǔn)。比如 Pod 在 1min 內(nèi)交付。我們通常從遲延、可用性、吞吐率及成功率這些角度來(lái)制定 SLI。
SLO 定義了一個(gè)小目標(biāo),來(lái)衡量一個(gè) SLI 指標(biāo)在一段時(shí)間內(nèi)達(dá)到好的標(biāo)準(zhǔn)的比例。比如說(shuō),99% 的 Pod 在 1min 內(nèi)交付。當(dāng)一項(xiàng)服務(wù)公布了其 SLO 的以后,用戶方就會(huì)對(duì)該服務(wù)的質(zhì)量有了期望。
SLA 是 SLO 衍生出來(lái)的協(xié)議,常用于 SLO 定義的目標(biāo)比例沒(méi)有完成時(shí),服務(wù)方要賠多少錢。通常來(lái)說(shuō),SLA 的協(xié)議會(huì)具體白紙黑字形成有法律效率的合同,常用于服務(wù)供應(yīng)商和外部客戶之間(例如阿里云和阿里云的使用者)。一般來(lái)說(shuō)對(duì)于內(nèi)部服務(wù)之間的 SLO 被打破,通常不會(huì)是經(jīng)濟(jì)上的賠償,可能更多的是職責(zé)上的認(rèn)定。
What?we concern?about Larger?K8s?Cluster?
第一個(gè)問(wèn)題就是集群是否健康,所有組件是否正常工作,集群中 Pod 創(chuàng)建的失敗數(shù)量有多少,這是一個(gè)整體指標(biāo)的問(wèn)題。
第二個(gè)問(wèn)題就是集群中發(fā)生了什么,集群中是否有異常發(fā)生了,用戶在集群中做了些什么事情,這是一個(gè)追蹤能力的問(wèn)題。
第三個(gè)問(wèn)題就是有了異常后,是哪個(gè)組件出了問(wèn)題導(dǎo)致成功率降低,這是一個(gè)原因定位的問(wèn)題。
首先,我們要定義一套 SLO,來(lái)描述集群的可用性。
接著,我們必須有能力對(duì)集群中 Pod 的生命周期進(jìn)行追蹤;對(duì)于失敗的 Pod,還需要分析出失敗原因,以快速定位異常組件。
最后,我們要通過(guò)優(yōu)化手段,消除集群的異常。
SLls?on Large K8s Cluster
我們先來(lái)看下集群的一些指標(biāo)。

第一項(xiàng)指標(biāo):集群健康度。目前有 Healthy/Warning/Fatal 三個(gè)值來(lái)描述,Warning 和 Fatal 對(duì)應(yīng)著告警體系,比如 P2 告警發(fā)生,那集群就是 Warning;如果 P0 告警發(fā)生,那集群就是 Fatal,必須進(jìn)行處理。
第二項(xiàng)指標(biāo):成功率。這里的成功率是指 Pod 的創(chuàng)建成功率。Pod 成功率是一個(gè)非常重要的指標(biāo),螞蟻一周 Pod 創(chuàng)建量是百萬(wàn)級(jí)的,成功率的波動(dòng)會(huì)造成大量 Pod 的失敗;而且 Pod 成功率的下跌,是集群異常的最直觀反應(yīng)。
第三項(xiàng)指標(biāo):殘留 Terminating Pod 的數(shù)量。為什么不用刪除成功率呢?因?yàn)樵诎偃f(wàn)級(jí)別的時(shí)候,即使 Pod 刪除成功率達(dá)到 99.9%,那么 Terminating Pod 的數(shù)量也是千級(jí)別的。殘留如此多的 Pod,會(huì)占著應(yīng)用的容量,在生產(chǎn)環(huán)境中是不可接受的。
第四項(xiàng)指標(biāo):服務(wù)在線率。服務(wù)在線率是通過(guò)探針來(lái)衡量的,探針失敗,意味著集群不可用。服務(wù)在線率是會(huì)對(duì) Master 組件來(lái)設(shè)計(jì)的。
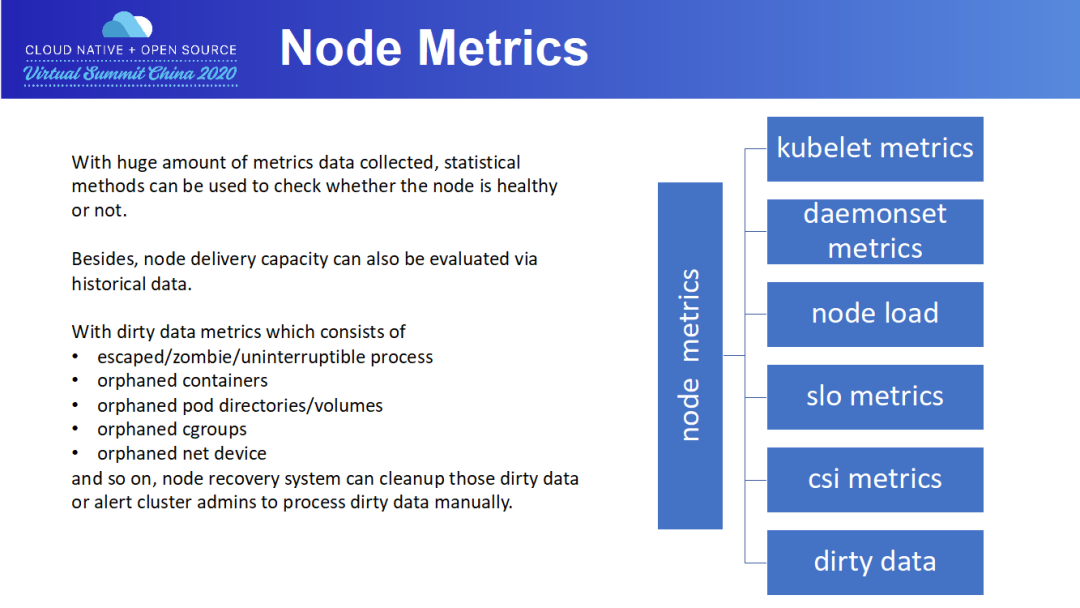
最后一項(xiàng)指標(biāo):故障機(jī)數(shù)量,這是一個(gè)節(jié)點(diǎn)維度的指標(biāo)。故障機(jī)通常是指那些無(wú)法正確交付 Pod 的物理機(jī),可能是磁盤滿了,可能是 load 太高了。集群故障機(jī)并須做到“快速發(fā)現(xiàn),快速隔離,及時(shí)修復(fù)”,畢竟故障機(jī)會(huì)對(duì)集群容量造成影響。
The success standard and reason classification

The infrastructure
Weekly Report 子系統(tǒng)給出當(dāng)前集群本周 pod 創(chuàng)建/刪除/升級(jí)的數(shù)據(jù)統(tǒng)計(jì),以及失敗案例原因匯總。
Terminating Pods Number 給出一段時(shí)間內(nèi)集群內(nèi)新增的無(wú)法通過(guò) K8s 機(jī)制刪除的 pods 列表和 pods 殘留原因。
Unhealthy Nodes 則給出一個(gè)周期內(nèi)集群所有節(jié)點(diǎn)的總可用時(shí)間占比,每個(gè)節(jié)點(diǎn)的可用時(shí)間,運(yùn)維記錄,以及不能自動(dòng)恢復(fù),需要人工介入恢復(fù)的節(jié)點(diǎn)列表。
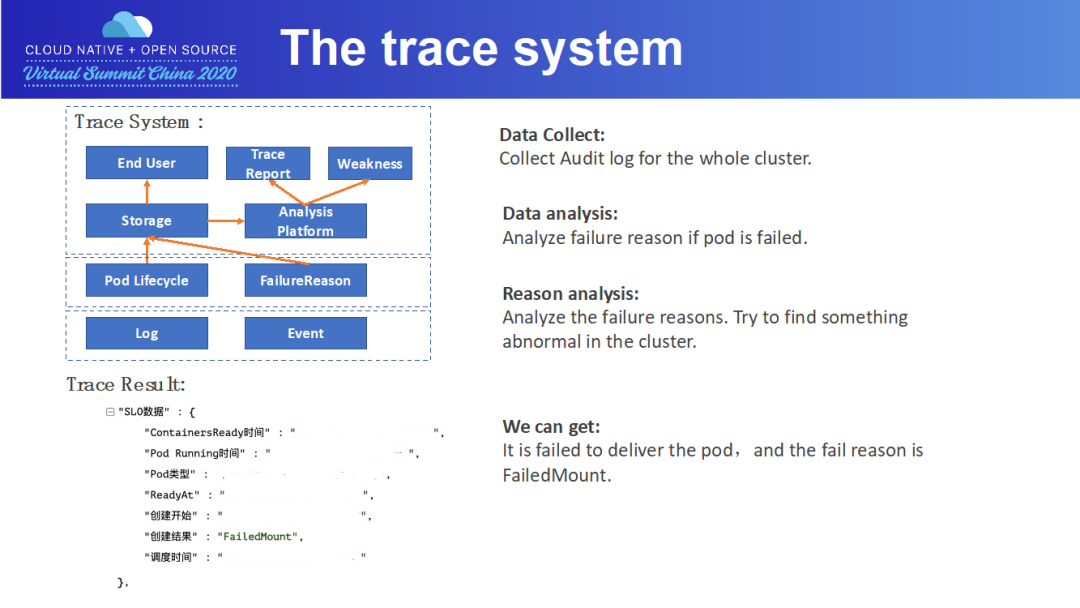
日志和事件采集模塊采集各 master 組件以及節(jié)點(diǎn)組件的運(yùn)行日志和 pod/node 事件,分別以 pod/node 為索引存儲(chǔ)日志和事件。
數(shù)據(jù)分析模塊分析還原出 pod 生命周期中各階段用時(shí),以及判斷 pod 失敗原因及節(jié)點(diǎn)不可用原因。
最后,由 Report 模塊向終端用戶暴露接口和 UI,向終端用戶展示 pod 生命周期以及出錯(cuò)原因。
The trace system
接下來(lái),以一個(gè) pod 創(chuàng)建失敗案例為例,向大家展示下 tracing 系統(tǒng)的工作流程。
Node Metrics
Unhealthy node
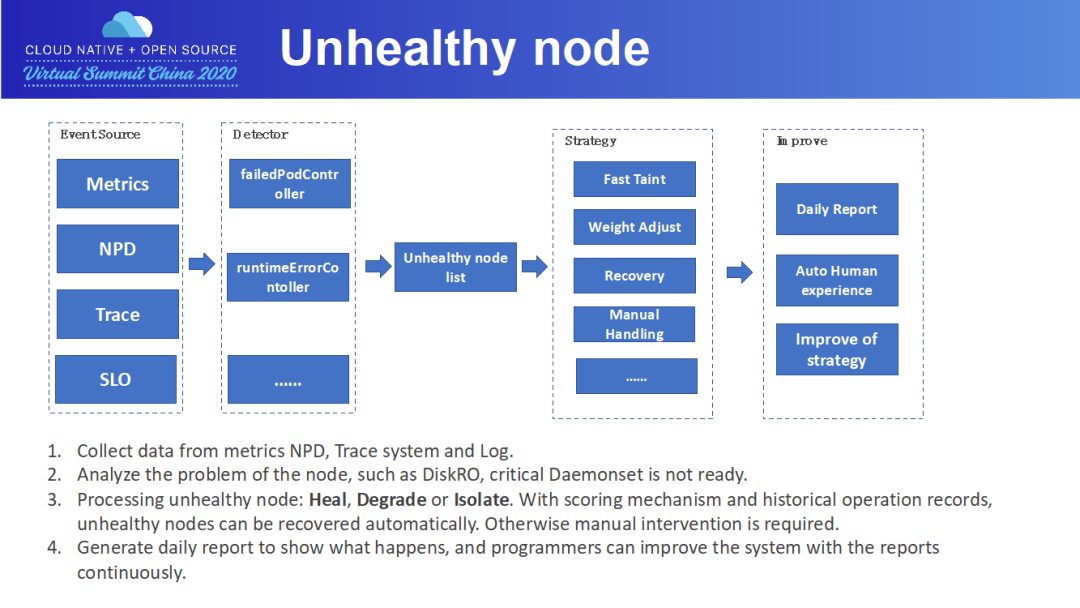
接下來(lái)描述故障機(jī)的處理流程。
某類 Volume 掛載失敗
NPD(Node Problem Detector),這是社區(qū)的一個(gè)框架
Trace 系統(tǒng),比如某個(gè)節(jié)點(diǎn)上 Pod 創(chuàng)建持續(xù)報(bào)鏡像下載失敗
SLO,比如單機(jī)上殘留大量 Pod
我們開(kāi)發(fā)了多個(gè) Controller 對(duì)這些某類故障進(jìn)行巡檢,形成故障機(jī)列表。一個(gè)故障機(jī)可以有好幾項(xiàng)故障。對(duì)于故障機(jī),會(huì)按照故障進(jìn)行不同的操作。主要的操作有:打 Taint,防止 Pod 調(diào)度上去;降低 Node 的優(yōu)先級(jí);直接自動(dòng)處理進(jìn)行恢復(fù)。對(duì)于一些特殊原因,比如磁盤滿,那就需要人工介入排查。
Tips on increasing SLO
接下來(lái),我們來(lái)分享下達(dá)到高 SLO 的一些方法。
第一點(diǎn),在提升成功率的進(jìn)程中,我們面臨的最大問(wèn)題就是鏡像下載的問(wèn)題。要知道,Pod 必須在規(guī)定時(shí)間內(nèi)交付,而鏡像下載通常需要非常多的時(shí)間。為此,我們通過(guò)計(jì)算鏡像下載時(shí)間,還專門設(shè)置了一個(gè) ImagePullCostTime 的錯(cuò)誤,即鏡像下載時(shí)間太長(zhǎng),導(dǎo)致 Pod 無(wú)法按時(shí)交付。
第二點(diǎn),對(duì)于提升單個(gè) Pod 成功率,隨著成功率的提升,難度也越來(lái)越難。可以引入一些 workload 進(jìn)行重試。在螞蟻,paas 平臺(tái)會(huì)不斷重試,直到 Pod 成功交付或者超時(shí)。當(dāng)然,在重試時(shí),之前的失敗的節(jié)點(diǎn)需要排除。
第三點(diǎn),關(guān)鍵的 Daemonset 一定要進(jìn)行檢查,如果關(guān)鍵 Daemonset 缺失,而把 Pod 調(diào)度上去,就非常容易出問(wèn)題,從而影響創(chuàng)建/刪除鏈路。這需要接入故障機(jī)體系。
第四點(diǎn),很多 Plugin,如 CSI Plugin,是需要向 Kubelet 注冊(cè)的。可能存在節(jié)點(diǎn)上一切正常,但向 Kubelet 注冊(cè)的時(shí)候失敗,這個(gè)節(jié)點(diǎn)同樣無(wú)法提供 Pod 交付的服務(wù),需要接入故障機(jī)體系。
最后一點(diǎn),由于集群中的用戶數(shù)量是非常多的,所以隔離非常重要。在權(quán)限隔離的基礎(chǔ)上,還需要做到 QPS 隔離,及容量的隔離,防止一個(gè)用戶的 Pod 把集群能力耗盡,從而保障其他用戶的利益。
 ?點(diǎn)擊屏末?|?閱讀原文?|?即刻學(xué)習(xí)
?點(diǎn)擊屏末?|?閱讀原文?|?即刻學(xué)習(xí)