
在 Kubernetes 上構(gòu)建大規(guī)模 Flink 自服務(wù)平臺(tái)
 到目前為止,我們已經(jīng)使用 Flink 滿足了一系列的需求:
到目前為止,我們已經(jīng)使用 Flink 滿足了一系列的需求:-
實(shí)時(shí)決策,如欺詐/垃圾郵件檢測(cè)
-
實(shí)時(shí)數(shù)據(jù)增強(qiáng),如分類(lèi)數(shù)據(jù)管道
-
機(jī)器學(xué)習(xí)實(shí)時(shí)特性生成
-
我們實(shí)驗(yàn)平臺(tái)的 OLAP 事件攝取
Flink 平臺(tái)如何幫助我們處理數(shù)據(jù)和事件
在 EMR 上擴(kuò)展 Flink 平臺(tái)的挑戰(zhàn)
當(dāng)我們開(kāi)始使用 Flink 作為流式計(jì)算引擎時(shí),我們?cè)?AWS EMR?集群上部署了所有的 Flink 作業(yè)。在 EMR 集群上運(yùn)行 Flink 是一個(gè)很好的起點(diǎn),因?yàn)?EMR 集群默認(rèn)帶有 Flink 和 Hadoop 等大數(shù)據(jù)框架。在過(guò)去的 10 個(gè)月里,我們接入了超過(guò) 50 個(gè)產(chǎn)品團(tuán)隊(duì)運(yùn)行他們的 Flink 管道。在數(shù)據(jù)基礎(chǔ)設(shè)施團(tuán)隊(duì)內(nèi)部,我們?cè)黾恿?500 個(gè) Flink 數(shù)據(jù)攝取管道。為了滿足高需求,我們需要將作業(yè)所有權(quán)委托給產(chǎn)品團(tuán)隊(duì),并使我們的平臺(tái)可以自助。然而在 EMR 上運(yùn)行 Flink 無(wú)法滿足如此高的需求,此外,缺乏原生工具使 Flink 在 EMR 上的自助運(yùn)行變得困難。
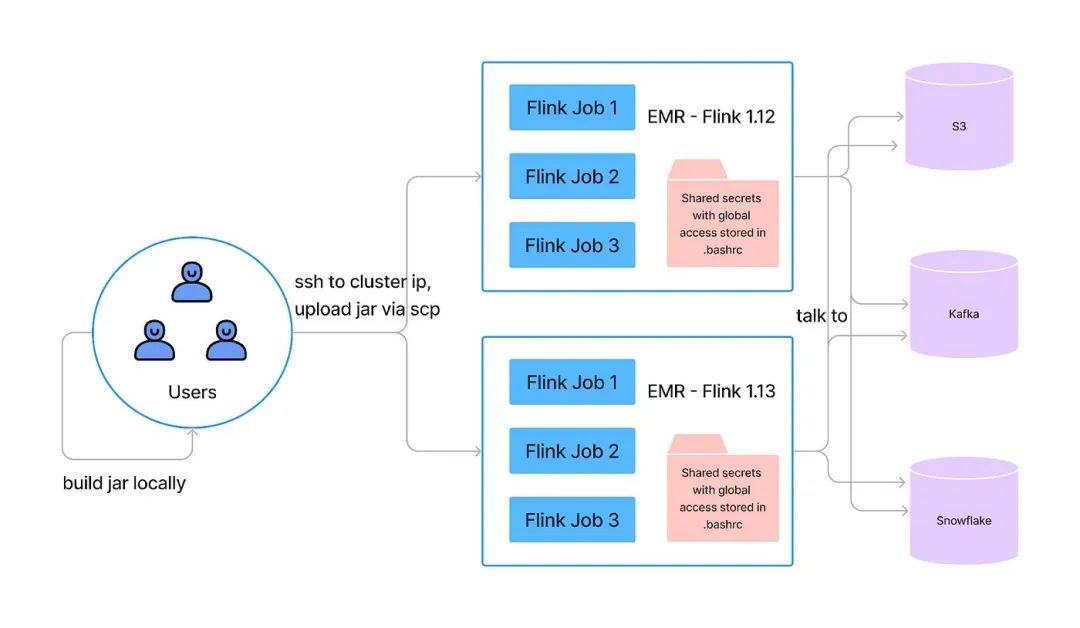
下圖展示了在 EMR 上的 Flink 流程,它有幾個(gè)主要問(wèn)題:-
缺乏服務(wù)的私密或配置管理,沒(méi)有服務(wù)級(jí)別的資源隔離。
-
AWS 權(quán)限模型只能應(yīng)用于 EMR 的集群級(jí)別,所以為了加速服務(wù)接入,所有服務(wù)都在運(yùn)行全局權(quán)限。
-
用戶必須通過(guò) SSH 與集群節(jié)點(diǎn)進(jìn)行交互進(jìn)行作業(yè)管理。集群上沒(méi)有安裝安全和審計(jì)工具。
-
EMR 或作業(yè)失敗恢復(fù)機(jī)制沒(méi)有良好的自動(dòng)擴(kuò)展機(jī)制支持。因此,F(xiàn)link 服務(wù)操作負(fù)擔(dān)較高。
-
單個(gè) EMR 集群不支持多個(gè) Flink 版本,我們的 Flink 服務(wù)運(yùn)行在 Flink 1.12 到 Flink 1.15 之間。因此,我們必須管理大約 75 個(gè) EMR 集群。
-
沒(méi)有 CI/CD 支持。在 EMR 上運(yùn)行的 Flink 不是容器化的,所以它不能與 Instacart 標(biāo)準(zhǔn)的 CI/CD 管道集成。
隨
著我們托管的 Flink 作業(yè)數(shù)量的增加,上述主要問(wèn)題對(duì)我們的實(shí)時(shí)數(shù)據(jù)管道構(gòu)成了可靠性威脅,并限制了我們的團(tuán)隊(duì)操作/支持能力。
 Kubernetes(也稱為 K8s)是一個(gè)開(kāi)源的容器編排平臺(tái),它使我們能夠輕松地部署、擴(kuò)展和管理應(yīng)用程序和服務(wù)。通過(guò) K8s,我們現(xiàn)在可以輕松管理應(yīng)用程序,同時(shí)也可以利用其內(nèi)置的容錯(cuò)和自動(dòng)擴(kuò)展能力。此外,它提供了大量的支持良好的工具。內(nèi)置的容錯(cuò)和自動(dòng)擴(kuò)展使得我們能夠快速地對(duì)負(fù)載變化做出反應(yīng),同時(shí)也確保了應(yīng)用程序始終在最佳狀態(tài)下運(yùn)行。利用 Kubernetes 工具可以幫助我們以最小的工作以標(biāo)準(zhǔn)的方式部署應(yīng)用程序。Flink 在 2019 年引入了對(duì) Kubernetes 的官方支持,這種方法近年來(lái)越來(lái)越受歡迎。Flink 社區(qū)在 2022 年初也正式推出了他們的 Flink K8s Operator 項(xiàng)目,這大大減少了人工運(yùn)維負(fù)擔(dān)和維護(hù)成本。下面是我們?cè)?EKS(Amazon Elastic Kubernetes Service)上的 Flink 平臺(tái)工作流:
Kubernetes(也稱為 K8s)是一個(gè)開(kāi)源的容器編排平臺(tái),它使我們能夠輕松地部署、擴(kuò)展和管理應(yīng)用程序和服務(wù)。通過(guò) K8s,我們現(xiàn)在可以輕松管理應(yīng)用程序,同時(shí)也可以利用其內(nèi)置的容錯(cuò)和自動(dòng)擴(kuò)展能力。此外,它提供了大量的支持良好的工具。內(nèi)置的容錯(cuò)和自動(dòng)擴(kuò)展使得我們能夠快速地對(duì)負(fù)載變化做出反應(yīng),同時(shí)也確保了應(yīng)用程序始終在最佳狀態(tài)下運(yùn)行。利用 Kubernetes 工具可以幫助我們以最小的工作以標(biāo)準(zhǔn)的方式部署應(yīng)用程序。Flink 在 2019 年引入了對(duì) Kubernetes 的官方支持,這種方法近年來(lái)越來(lái)越受歡迎。Flink 社區(qū)在 2022 年初也正式推出了他們的 Flink K8s Operator 項(xiàng)目,這大大減少了人工運(yùn)維負(fù)擔(dān)和維護(hù)成本。下面是我們?cè)?EKS(Amazon Elastic Kubernetes Service)上的 Flink 平臺(tái)工作流: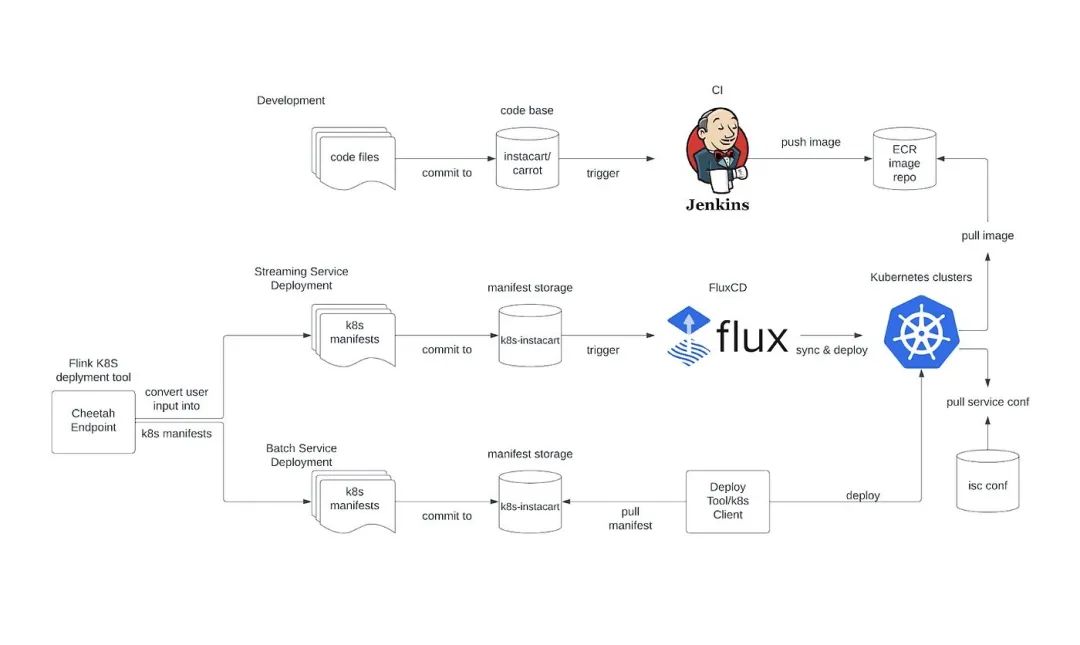
-
新的服務(wù)配置/接入是通過(guò)一個(gè)端點(diǎn)(Cheetah Endpoint)請(qǐng)求完成的,并由 Instacart Flink K8S 自定義控制器提供支持。Instacart Flink CRD 是 Instacart Flink 部署的抽象,它包含了所有需要的權(quán)限、Kubernetes 資源和一個(gè)默認(rèn)的 Flink 部署配置。自定義控制器接受我們的 Cheetah Endpoint 的這個(gè) CRD,然后將其部署到 Kubernetes 集群,并定期重新同步它們的狀態(tài)。
-
開(kāi)發(fā)流程與 Instacart 的標(biāo)準(zhǔn) CI 流程集成,這個(gè)流程自動(dòng)構(gòu)建應(yīng)用程序鏡像并將它們推送到我們的 ECR(Amazon Elastic Container Registry)倉(cāng)庫(kù)。
-
部署流程采用了 GitOps 的思想,它是通過(guò) FluxCD 集成完成的,F(xiàn)luxCD 會(huì)持續(xù)監(jiān)控我們的 K8s 清單倉(cāng)庫(kù)的變化。
-
服務(wù)的配置和 Secret 由 Instacart 的配置管理器(isc conf)管理。它提供了一個(gè)很好的用戶界面,可以通過(guò)精確名稱匹配或正則表達(dá)式進(jìn)行搜索/創(chuàng)建/替換。
-
服務(wù)管理,如故障恢復(fù)、檢查點(diǎn)恢復(fù)和運(yùn)行狀態(tài)檢查,是由 Flink K8s Operator 完成的。
-
每個(gè)服務(wù)都在其自己的命名空間和服務(wù)賬戶上運(yùn)行。服務(wù)的權(quán)限與命名空間和服務(wù)賬戶對(duì)綁定。
-
Flink 的 UI 可以通過(guò) NGINX ingress 訪問(wèn),日志被持久化在 Datadog 中。
-
Karpenter 用于集群節(jié)點(diǎn)管理。在引入 Karpenter 之前,必須為我們的多租戶集群分配多個(gè)節(jié)點(diǎn)組,以滿足某些復(fù)雜的 Flink 部署資源隔離需求,因?yàn)檫@些大型復(fù)雜的 Flink 部署的運(yùn)行狀態(tài)變化顯著地干擾了它們運(yùn)行的節(jié)點(diǎn)組的節(jié)點(diǎn)分配。Karpenter 通過(guò)引入即時(shí)節(jié)點(diǎn)的概念,從一開(kāi)始就分配合適大小的節(jié)點(diǎn),為 Flink 任務(wù)提供了更好的裝箱,而且由于它直接通過(guò) EC2 Fleet API 調(diào)用操作節(jié)點(diǎn),它比當(dāng)前基于自動(dòng)擴(kuò)展的托管節(jié)點(diǎn)組+集群自動(dòng)擴(kuò)展器有更好、更精細(xì)的對(duì)機(jī)器的控制。
影響和學(xué)習(xí)
之前我們有一個(gè) 8 頁(yè)的 Flink 管道接入指南,其中有幾個(gè)手動(dòng)步驟使過(guò)程容易出錯(cuò),這大大降低了我們開(kāi)發(fā)人員的生產(chǎn)力,并增加了我們的數(shù)據(jù)平臺(tái)工程師的支持時(shí)間。通過(guò)使用 Kubernetes 技術(shù)和我們自己開(kāi)發(fā)的 Instacart Flink K8s Operator,我們將 Flink 部署模型(AWS 權(quán)限、Kafka 權(quán)限、默認(rèn) Flink 設(shè)置)編碼成一個(gè)簡(jiǎn)單的模型。這將新的 Flink 管道接入時(shí)間從一周減少到幾分鐘。-
減少了運(yùn)營(yíng)成本。通過(guò)工具和自動(dòng)化,如 CI/CD、NGINX 控制器、Lacework、Teleport,我們能夠以最小的開(kāi)發(fā)努力顯著減少我們的運(yùn)維、支持和故障排除工作,同時(shí)也提供了良好的用戶開(kāi)發(fā)體驗(yàn)。總的來(lái)說(shuō),它為我們節(jié)省了大約 50 周的開(kāi)發(fā)工作,減少了 20% 的工程工作在運(yùn)維和支持上,以及 15% 的開(kāi)發(fā)生產(chǎn)力。
-
基礎(chǔ)設(shè)施成本節(jié)省。通過(guò)利用智能自動(dòng)擴(kuò)展機(jī)制,以及像節(jié)點(diǎn)親和性這樣的能力,我們能夠在單個(gè)混合節(jié)點(diǎn)類(lèi)型的集群上調(diào)度具有不同資源模式的負(fù)載。這在生產(chǎn)實(shí)例上節(jié)省了 50% 以上的基礎(chǔ)設(shè)施成本,在開(kāi)發(fā)實(shí)例上節(jié)省了 70%,在 EBS 卷上節(jié)省了 40%。
-
自動(dòng)故障恢復(fù),即使在流量高峰期也沒(méi)有任何事故。通過(guò)部署 Flink K8s Operator,我們能夠?qū)崿F(xiàn)自動(dòng)故障恢復(fù),無(wú)需人工干預(yù)。每年將大約 30 個(gè)關(guān)鍵警報(bào)減少到 0,這尤其有影響,因?yàn)樵S多這些關(guān)鍵警報(bào)都是在夜間發(fā)生的。
我們對(duì) Kubernetes 和 Kubernetes 工具所實(shí)現(xiàn)的成就感到非常興奮。
-
整個(gè) Flink 服務(wù)的接入和運(yùn)維應(yīng)該簡(jiǎn)化,不涉及 K8s 的細(xì)節(jié)。我們平臺(tái)上大部分用戶都不了解 Kubernetes,所以我們應(yīng)該盡可能地將 K8s 的細(xì)節(jié)抽象出來(lái)。
-
建立我們的實(shí)時(shí)系統(tǒng)時(shí),重要的是要有平臺(tái)思維和統(tǒng)一的技術(shù)和工具。短期解決方案與異構(gòu)技術(shù)使平臺(tái)效率低下,難以擴(kuò)展和操作。而 Kubernetes 目前是提供這種統(tǒng)一的最突出的解決方案。它提供了一種我們過(guò)去需要超過(guò) 3 個(gè)系統(tǒng)來(lái)管理的所有需要的東西的管理方式。Flink 的路線圖上 Kubernetes 的支持正在迅速迭代,這是使 Flink 更加云原生的一大步。我們?cè)?2022 年見(jiàn)證了 Flink K8s Operator 的重大演變,啟用了大量的新特性。
#04 致謝 特別感謝 Luiz Soares,他是我們的云基礎(chǔ)團(tuán)隊(duì)的主要工程師,他為在 EKS 上運(yùn)行的 Flink 平臺(tái)設(shè)置了所有基礎(chǔ)設(shè)施,并在整個(gè)項(xiàng)目中提供了寶貴的建議。還有 Ben Bader,他幫助在 Kubernetes 之上構(gòu)建了 Flink 開(kāi)發(fā)者體驗(yàn)工具,使得自助服務(wù)體驗(yàn)順暢。向我們的基礎(chǔ)設(shè)施工程師致敬,他們直接為這個(gè)項(xiàng)目做出了貢獻(xiàn):Christopher Cope,F(xiàn)rancois Campbell,Greg Lyons,Han Li,Jocelyn De La Rosa,Justin Poole,Peerakit Somsuk,Shen Zhu,Xiaobing Xia。感謝許多其他工程師為的貢獻(xiàn)使這個(gè)項(xiàng)目能夠成功,另外也要感謝 Instacart Cloud 團(tuán)隊(duì)和 Build and Deploy 團(tuán)隊(duì)的支持!
原文鏈接:https://tech.instacart.com/building-a-flink-self-serve-platform-on-kubernetes-at-scale-c11ef19aef10