異常檢測(cè)算法之(LOF)-Local Outlier Factor

本篇和大家介紹一個(gè)經(jīng)典的異常檢測(cè)算法:局部離群因子(Local Outlier Factor),簡(jiǎn)稱LOF算法。
背景
Local Outlier Factor(LOF)是基于密度的經(jīng)典算法(Breuning et. al. 2000), 文章發(fā)表于 SIGMOD 2000, 到目前已經(jīng)有 3000+ 的引用。
在 LOF 之前的異常檢測(cè)算法大多是基于統(tǒng)計(jì)方法的,或者是借用了一些聚類算法用于異常點(diǎn)的識(shí)別(比如 ,DBSCAN,OPTICS)。這些方法都有一些不完美的地方:
基于統(tǒng)計(jì)的方法:通常需要假設(shè)數(shù)據(jù)服從特定的概率分布,這個(gè)假設(shè)往往是不成立的。 聚類方法:通常只能給出 0/1 的判斷(即:是不是異常點(diǎn)),不能量化每個(gè)數(shù)據(jù)點(diǎn)的異常程度。
相比較而言,基于密度的LOF算法要更簡(jiǎn)單、直觀。它不需要對(duì)數(shù)據(jù)的分布做太多要求,還能量化每個(gè)數(shù)據(jù)點(diǎn)的異常程度(outlierness)。
下面開始正式介紹LOF算法。
LOF 算法
首先,基于密度的離群點(diǎn)檢測(cè)方法有一個(gè)基本假設(shè):非離群點(diǎn)對(duì)象周圍的密度與其鄰域周圍的密度類似,而離群點(diǎn)對(duì)象周圍的密度顯著不同于其鄰域周圍的密度。
什么意思呢?看下面圖片感受下。
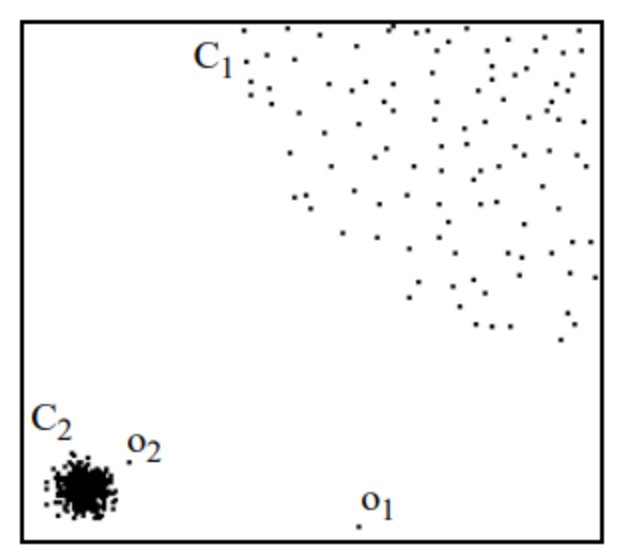
集群 C1 包含了 400 多個(gè)點(diǎn),集群 C2 包含 100 個(gè)點(diǎn)。C1 和 C2 都是一類集群點(diǎn),區(qū)別是 C1 位置比較集中,或者說(shuō)密度比較大。而像 o1、o2點(diǎn)均為異常點(diǎn),因?yàn)榛谖覀兊募僭O(shè),這兩個(gè)點(diǎn)周圍的密度顯著不同于周圍點(diǎn)的密度。
LOF 就是基于密度來(lái)判斷異常點(diǎn)的,通過(guò)給每個(gè)數(shù)據(jù)點(diǎn)都分配一個(gè)依賴于鄰域密度的離群因子 LOF,進(jìn)而判斷該數(shù)據(jù)點(diǎn)是否為離群點(diǎn)。 如果 ,則該點(diǎn)為離群點(diǎn),如果 ,則該點(diǎn)為正常數(shù)據(jù)點(diǎn)。
那什么是LOF呢?
了解LOF前,必須先知道一下幾個(gè)基本概念,因?yàn)長(zhǎng)OF是基于這幾個(gè)概念而來(lái)的。
1. k鄰近距離
在距離數(shù)據(jù)點(diǎn) 最近的幾個(gè)點(diǎn)中,第 個(gè)最近的點(diǎn)跟點(diǎn) 之間的距離稱為點(diǎn) 的 K-鄰近距離,記為 k-distance (p),公式如下:
點(diǎn) 為距離點(diǎn) 最近的第 個(gè)點(diǎn)。

比如上圖中,距離點(diǎn) 最近的第 個(gè)點(diǎn)是點(diǎn) 。
這里的距離計(jì)算可以采用歐式距離、漢明距離、馬氏距離等等。比如用歐式距離的計(jì)算公式如下:
這里的重點(diǎn)是找到第 個(gè)最近的那個(gè)點(diǎn),然后帶公式計(jì)算距離。
2. k距離領(lǐng)域
以點(diǎn) 為圓心,以k鄰近距離 為半徑畫圓,這個(gè)圓以內(nèi)的范圍就是k距離領(lǐng)域,公式如下:
還是上圖所示,假設(shè)k=4,那么點(diǎn) 1-6 均是鄰域范圍內(nèi)的點(diǎn)。
3. 可達(dá)距離
這個(gè)可達(dá)距離大家需要留意點(diǎn),點(diǎn) 到點(diǎn) 的第 可達(dá)距離:
這里計(jì)算 到點(diǎn) 的第 可達(dá)距離,但是要以點(diǎn) 為中心,取一個(gè)最大值,也就是在點(diǎn) 與 的距離、距離點(diǎn) 最近的第 個(gè)點(diǎn)距離中取較大的一個(gè),如圖下所示。

距離 遠(yuǎn),那么兩者之間的可達(dá)距離就是它們的實(shí)際距離。如果距離足夠近,如點(diǎn) ,實(shí)際距離將被 的 距離代替。所有 接近 的統(tǒng)計(jì)波動(dòng) 可以顯著減少,這可以通過(guò)參數(shù) 來(lái)控制, 值越高,同一鄰域內(nèi)的點(diǎn)的可達(dá)距離越相似。
4. 局部可達(dá)密度
先給出公式。
數(shù)據(jù)點(diǎn) 的局部可達(dá)密度就是基于 的最近鄰的平均可達(dá)距離的倒數(shù)。距離越大,密度越小。
5. 局部異常因子
根據(jù)局部可達(dá)密度的定義,如果一個(gè)數(shù)據(jù)點(diǎn)跟其他點(diǎn)比較疏遠(yuǎn)的話,那么顯然它的局部可達(dá)密度就小。但LOF算法衡量一個(gè)數(shù)據(jù)點(diǎn)的異常程度,并不是看它的絕對(duì)局部密度,而是看它跟周圍鄰近的數(shù)據(jù)點(diǎn)的相對(duì)密度。
這樣做的好處是可以允許數(shù)據(jù)分布不均勻、密度不同的情況。局部異常因子即是用局部相對(duì)密度來(lái)定義的。數(shù)據(jù)點(diǎn) 的局部相對(duì)密度(局部異常因子)為點(diǎn) 鄰域內(nèi)點(diǎn)的平均局部可達(dá)密度跟數(shù)據(jù)點(diǎn) 的局部可達(dá)密度的比值,即:
LOF算法流程
了解了 LOF 的定義以后,整個(gè)算法也就顯而易見了:
對(duì)于每個(gè)數(shù)據(jù)點(diǎn),計(jì)算它與其它所有點(diǎn)的距離,并按從近到遠(yuǎn)排序;
對(duì)于每個(gè)數(shù)據(jù)點(diǎn),找到它的 k-nearest-neighbor,計(jì)算 LOF 得分;
如果LOF值越大,說(shuō)明越異常,反之如果越小,說(shuō)明越趨于正常。

LOF優(yōu)缺點(diǎn)
優(yōu)點(diǎn)
LOF 的一個(gè)優(yōu)點(diǎn)是它同時(shí)考慮了數(shù)據(jù)集的局部和全局屬性。異常值不是按絕對(duì)值確定的,而是相對(duì)于它們的鄰域點(diǎn)密度確定的。當(dāng)數(shù)據(jù)集中存在不同密度的不同集群時(shí),LOF表現(xiàn)良好,比較適用于中等高維的數(shù)據(jù)集。
缺點(diǎn)
LOF算法中關(guān)于局部可達(dá)密度的定義其實(shí)暗含了一個(gè)假設(shè),即:不存在大于等于 k 個(gè)重復(fù)的點(diǎn)。
當(dāng)這樣的重復(fù)點(diǎn)存在的時(shí)候,這些點(diǎn)的平均可達(dá)距離為零,局部可達(dá)密度就變?yōu)闊o(wú)窮大,會(huì)給計(jì)算帶來(lái)一些麻煩。在實(shí)際應(yīng)用時(shí),為了避免這樣的情況出現(xiàn),可以把 k-distance 改為 k-distinct-distance,不考慮重復(fù)的情況。或者,還可以考慮給可達(dá)距離都加一個(gè)很小的值,避免可達(dá)距離等于零。
另外,LOF 算法需要計(jì)算數(shù)據(jù)點(diǎn)兩兩之間的距離,造成整個(gè)算法時(shí)間復(fù)雜度為 。為了提高算法效率,后續(xù)有算法嘗試改進(jìn)。FastLOF (Goldstein,2012)先將整個(gè)數(shù)據(jù)隨機(jī)的分成多個(gè)子集,然后在每個(gè)子集里計(jì)算 LOF 值。對(duì)于那些 LOF 異常得分小于等于 1 的,從數(shù)據(jù)集里剔除,剩下的在下一輪尋找更合適的 nearest-neighbor,并更新 LOF 值。
Python 實(shí)現(xiàn) LOF
有兩個(gè)庫(kù)可以計(jì)算LOF,分別是PyOD和Sklearn,下面分別介紹。
使用pyod自帶的方法生成200個(gè)訓(xùn)練樣本和100個(gè)測(cè)試樣本的數(shù)據(jù)集。正態(tài)樣本由多元高斯分布生成,異常樣本是使用均勻分布生成的。
訓(xùn)練和測(cè)試數(shù)據(jù)集都有 5 個(gè)特征,10% 的行被標(biāo)記為異常。并且在數(shù)據(jù)中添加了一些隨機(jī)噪聲,讓完美分離正常點(diǎn)和異常點(diǎn)變得稍微困難一些。
from?pyod.utils.data?import?generate_data
import?numpy?as?np
X_train,?y_train,?X_test,?y_test?=?\
????????generate_data(n_train=200,
??????????????????????n_test=100,
??????????????????????n_features=5,
??????????????????????contamination=0.1,
??????????????????????random_state=3)?
X_train?=?X_train?*?np.random.uniform(0,?1,?size=X_train.shape)
X_test?=?X_test?*?np.random.uniform(0,1,?size=X_test.shape)
PyOD
下面將訓(xùn)練數(shù)據(jù)擬合了 LOF 模型并將其應(yīng)用于合成測(cè)試數(shù)據(jù)。
在 PyOD 中,有兩個(gè)關(guān)鍵方法:decision_function 和 predict。
decision_function:返回每一行的異常分?jǐn)?shù) predict:返回一個(gè)由 0 和 1 組成的數(shù)組,指示每一行被預(yù)測(cè)為正常 (0) 還是異常值 (1)
from?pyod.models.lof?import?LOF
clf_name?=?'LOF'
clf?=?LOF()
clf.fit(X_train)
test_scores?=?clf.decision_function(X_test)
roc?=?round(roc_auc_score(y_test,?test_scores),?ndigits=4)
prn?=?round(precision_n_scores(y_test,?test_scores),?ndigits=4)
print(f'{clf_name}?ROC:{roc},?precision?@?rank?n:{prn}')
>>?LOF?ROC:0.9656,?precision?@?rank?n:0.8
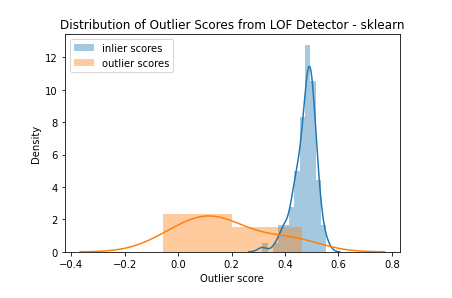
可以通過(guò) LOF 模型方法查看 LOF 分?jǐn)?shù)的分布。在下圖中看到正常數(shù)據(jù)(藍(lán)色)的分?jǐn)?shù)聚集在 1.0 左右。離群數(shù)據(jù)點(diǎn)(橙色)的得分均大于 1.0,一般高于正常數(shù)據(jù)。

Sklearn
在scikit-learn中實(shí)現(xiàn) LOF 進(jìn)行異常檢測(cè)時(shí),有兩種模式選擇:異常檢測(cè)模式 (novelty=False) 和 novelty檢測(cè)模式 (novelty=True)。
在異常檢測(cè)模式下,只有fit_predict生成離群點(diǎn)預(yù)測(cè)的方法可用。可以使用negative_outlier_factor_屬性檢索訓(xùn)練數(shù)據(jù)的異常值分?jǐn)?shù),但無(wú)法為未見過(guò)的數(shù)據(jù)生成分?jǐn)?shù)。模型會(huì)根據(jù)contamination參數(shù)(默認(rèn)值為 0.1)自動(dòng)選擇異常值的閾值。
import?matplotlib.pyplot?as?plt
detector?=?LOF()
scores?=?detector.fit(X_train).decision_function(X_test)
sns.distplot(scores[y_test==0],?label="inlier?scores")
sns.distplot(scores[y_test==1],?label="outlier?scores").set_title("Distribution?of?Outlier?Scores?from?LOF?Detector")
plt.legend()
plt.xlabel("Outlier?score")
在novelty檢測(cè)模式下,只有decision_function用于生成異常值可用。fit_predict方法不可用,但predict方法可用于生成異常值預(yù)測(cè)。
clf?=?LocalOutlierFactor(novelty=True)
clf?=?clf.fit(X_train)
test_scores?=?clf.decision_function(X_test)
test_scores?=?-1*test_scores
roc?=?round(roc_auc_score(y_test,?test_scores),?ndigits=4)
prn?=?round(precision_n_scores(y_test,?test_scores),?ndigits=4)
print(f'{clf_name}?ROC:{roc},?precision?@?rank?n:{prn}')
該模式下模型的異常值分?jǐn)?shù)被反轉(zhuǎn),異常值的分?jǐn)?shù)低于正常值。